Для/= 0 мы можем получить линейное ускорение, но для/> 0 идеальное ускорение недостижимо, поскольку в программе имеется последовательная часть. Это явление носит название закона Амдала.
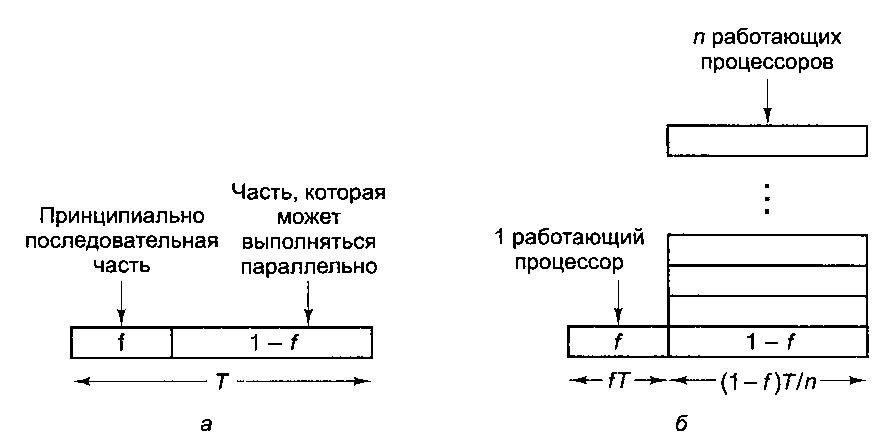
Рис. 8.41. Помимо последовательной части программа содержит ту часть, которая может выполняться параллельно (а); результат параллельной обработки части программы (б)
Закон Амдала — только одна из причин, по которой идеальное ускорение недостижимо. Определенную роль в этом играют и время запаздывания в линиях связи, и ограниченная пропускная способность, и недостатки алгоритмов. Даже если бы у нас было 1000 процессоров, не все программы можно написать так, чтобы все их использовать, а издержки, связанные с запуском стольких процессоров, могут быть весьма значительными. Больше того, многие известные алгоритмы почти не поддаются параллельной обработке, поэтому их приходится заменять квазиоптимальными алгоритмами. В то же время для многих приклад ных задач весьма желательно было бы заставить программу работать в п раз быстрее, даже если для этого потребуются 2п процессоров. В конце концов, процессоры не такие уж и дорогие.
Приемы повышения производительности
Самый очевидный способ поднять производительность системы — добавить процессоры. Однако добавлять процессоры нужно таким образом, чтобы в системе не появлялись узкие места. Система, после добавления процессоров в которую имеет место соответствующий прирост производительности, называется масштабируемой.
Рассмотрим 4 процессора, связанные общей шиной (рис. 8.42, а). Представьте, что мы расширили систему до 16 процессоров, добавив еще 12 (рис. 8.42, б). Если пропускная способность шины составляет Ь Мбайт/с, то, увеличив в 4 раза число процессоров, мы сократим доступную каждому процессору пропускную способность с Ь/4 до Ь/16 Мбайт/с. Такую систему нельзя назвать масштабируемой.
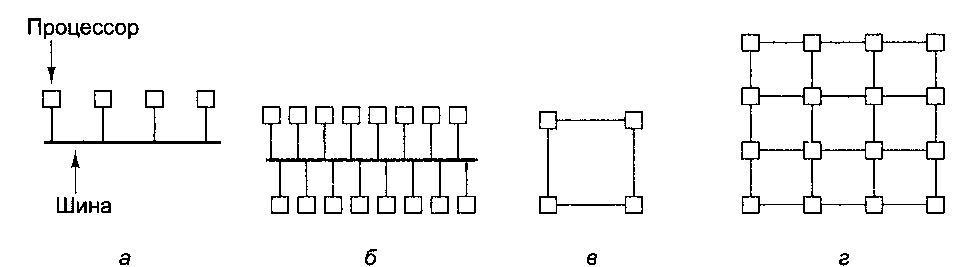
Рис. 8.42. Система из 4 процессоров, связанных общей шиной (а); система из 16 процессоров, связанных общей шиной (б); коммуникационная решетка из 4 процессоров (е); коммуникационная решетка из 16 процессоров (г)
А теперь проделаем то же самое с коммуникационной решеткой (рис. 8.42, в и г). В такой топологии добавление новых процессоров означает появление новых линий связи, поэтому при масштабировании системы совокупная пропускная способность каждого процессора не снижается, как в случае с шиной. Фактически отношение числа линий связи к числу процессоров увеличивается от 1,0 при наличии 4 процессоров (4 линии связи) до 1,5 при наличии 16 процессоров (24 линии связи), поэтому с добавлением новых процессоров совокупная пропускная способность каждого процессора растет.
Естественно, пропускная способность — не единственный параметр. Добавление процессоров к шине не увеличивает диаметр сети или время запаздывания, в то время как добавление процессоров к решетке, напротив, увеличивает. Диаметр решетки размером пхп равен 2(п - 1), поэтому в худшем случае время запаздывания растет примерно как квадратный корень от числа процессоров. Для 400 процессоров диаметр равен 38, для 1600 процессоров — 78, поэтому если увеличить число процессоров в 4 раза, то диаметр и, следовательно, среднее время запаздывания вырастут приблизительно вдвое.