нашего
сайта:

| Статус нашего сайта: |
|
ICQ Information Center |
 ICQ SHOP ICQ SHOP5-значные 6-значные 7-значные 8-значные 9-значные Rippers List ОПЛАТА СТАТЬИ СЕКРЕТЫ HELP CENTER OWNED LIST РОЗЫСК!New! ICQ РЕЛИЗЫ Протоколы ICQ LOL ;-) Настройка компьютера Аватарки Смайлики СОФТMail Checkers Bruteforces ICQTeam Soft 8thWonder Soft Other Progs ICQ Patches Miranda ICQ ФорумАрхив! ВАШ АККАУНТ
РекламаНаш канал:irc.icqinfo.ru |
Таненбаум Э.- Архитектура компьютера. стр.266Модели памяти Во всех компьютерах память разделена на ячейки, которые имеют последовательные адреса. В настоящее время наиболее распространенный размер ячейки — 8 бит, но раньше использовались ячейки от 1 до 60 бит (см. табл. 2.1). Ячейка из 8 бит называется байтом. Причиной применения именно 8-разрядных ячеек памяти является ASCII-символ, который занимает 7 бит, а вместе с битом четности — 8. Если в будущем будет доминировать кодировка UNICODE, то ячейки памяти, возможно, станут 16-разрядными. Вообще говоря, число 24 лучше, чем 23, поскольку 4 — степень двойки, а 3 — нет. Байты обычно группируются в 4-байтные (32-разрядные) или 8-байтные (64-разрядные) слова с командами манипулирования целыми словами. Многие архитектуры требуют, чтобы слова были выровнены в своих естественных границах. Так, 4-байтное слово может начинаться с адреса 0, 4, 8 и т. д., но не с адреса 1 или 2. Точно так же слово из 8 байт может начинаться с адреса 0, 8 или 16, но не с адреса 4 или 6. Механизм размещения 8-байтных слов в памяти иллюстрирует рис. 5.2. Выравнивание адресов требуется довольно часто, поскольку при этом память работает наиболее эффективно. Например, процессор Pentium 4, который вызывает из памяти по 8 байт за обращение, использует 36-разрядные физические адреса, но содержит только 33 адресных бита. Следовательно, Pentium 4 даже не сможет обратиться к невыровненной памяти, поскольку младшие 3 бита явным образом не определены. Эти биты всегда равны 0, и все адреса памяти кратны значению 8 байт. Однако требование относительно выравнивания адресов иногда вызывает некоторые проблемы. В процессоре Pentium 4 программы могут обращаться к словам, начиная с любого адреса, — это качество восходит к модели 8088 с шиной данных шириной 1 байт, в которой не требовалось, чтобы ячейки располагались в 8-байтных границах. Если программа в процессоре Pentium 4 считывает 4-байтное слово с адреса 7, аппаратное обеспечение должно сделать одно обращение к памяти, чтобы вызвать байты с 0 по 7, а второе — чтобы вызвать байты с 8 по 15. Затем центральный процессор извлекает требуемые 4 байта из 16, считанных из памяти, и компонует их в нужном порядке, чтобы сформировать 4-байтное слово. 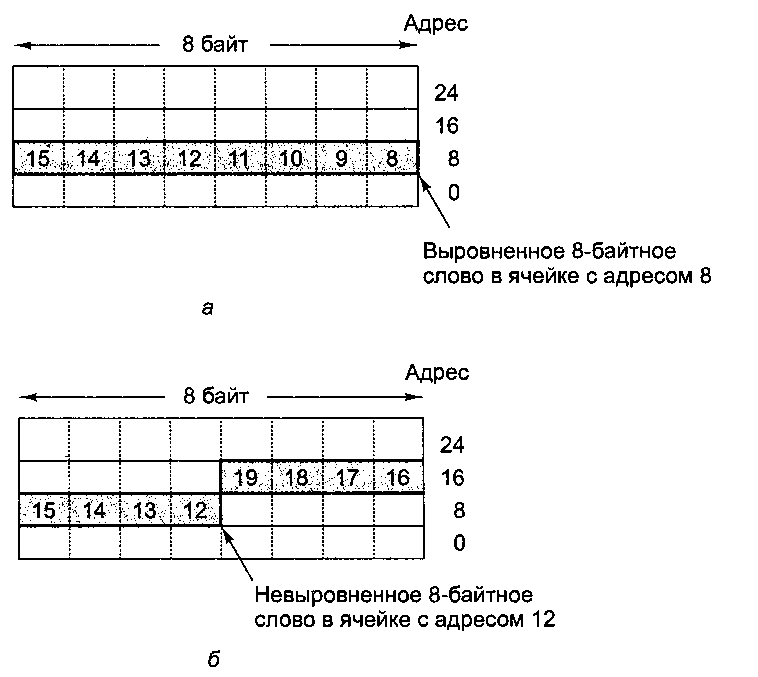 Рис. 5.2. Расположение слова из 8 байт в памяти: выровненное слово (а); невыровненное слово (б). Некоторые машины требуют, чтобы слова в памяти были выровнены Возможность считывать слова с произвольными адресами требует усложнения микросхемы, которая после этого становится больше и дороже. Разработчики были бы рады избавиться от такой микросхемы и просто потребовать, чтобы все программы обращались к памяти пословно, а не побайтно. Однако на традиционный вопрос разработчиков: «Кому нужны древние программы, написанные еще для машин 8088 и совершенно неправильно работающие с памятью?» — следует не менее традиционный ответ продавцов: «Нашим покупателям». Большинство машин имеют единое линейное адресное пространство, которое простирается от адреса 0 до какого-то максимума, обычно 232 или 264 байт. В некоторых машинах содержатся раздельные адресные пространства для команд и данных, так что при вызове команды с адресом 8 и вызове данных с адресом 8 происходит обращение к разным адресным пространствам. Такая система гораздо сложнее, чем единое адресное пространство, но зато она имеет два преимущества. Во-первых, все с теми же 32-разрядными адресами появляется возможность иметь 232 байт для программ и дополнительные 232 байт для данных. Во-вторых, поскольку запись всегда автоматически происходит только в пространство данных, случайная перезапись программы становится невозможной, и, следовательно, устраняется один из источников программных ошибок. |