нашего
сайта:

| Статус нашего сайта: |
|
ICQ Information Center |
 ICQ SHOP ICQ SHOP5-значные 6-значные 7-значные 8-значные 9-значные Rippers List ОПЛАТА СТАТЬИ СЕКРЕТЫ HELP CENTER OWNED LIST РОЗЫСК!New! ICQ РЕЛИЗЫ Протоколы ICQ LOL ;-) Настройка компьютера Аватарки Смайлики СОФТMail Checkers Bruteforces ICQTeam Soft 8thWonder Soft Other Progs ICQ Patches Miranda ICQ ФорумАрхив! ВАШ АККАУНТ
РекламаНаш канал:irc.icqinfo.ru |
Таненбаум Э.- Архитектура компьютера. стр.502На практике приблизиться к теоретически возможной пропускной способности очень трудно. Причины этого могут быть самыми разными. Например, каждый пакет всегда содержит служебные данные, относящиеся к компоновке, созданию заголовка, отправке. При отправке 1024 пакетов по 4 байта каждый мы никогда не достигнем той же пропускной способности, что и при отправке одного пакета на 4096 байт. Однако для сокращения времени запаздывания лучше использовать маленькие пакеты, поскольку большие надолго блокируют линии и коммутаторы. В результате имеет место конфликт между способами достижения низкого времени запаздывания и высокой пропускной способности. Для одних прикладных задач важнее время запаздывания, для других — пропускная способность. Но в любом случае важно понимать, что пропускную способность всегда можно увеличить за счет дополнительных материальных затрат (добавив больше проводов или установив более широкие провода), а вот что касается сокращения времени запаздывания, финансовые вливания здесь не помогут. Поэтому обычно лучше с самого начала позаботиться о минимальном времени запаздывания, а уже потом думать о пропускной способности. Программные метрики Аппаратные метрики, такие как время запаздывания и пропускная способность, показывают, на что способно аппаратное обеспечение. Но пользователей интересует совсем другое. Они хотят знать, насколько быстрее будут работать их программы на параллельном компьютере по сравнению с однопроцессорным. Для них ключевой метрикой является ускорение: насколько быстрее работает программа в ^-процессорной системе по сравнению с однопроцессорной. Результаты обычно иллюстрируются графически (рис. 8.40.). 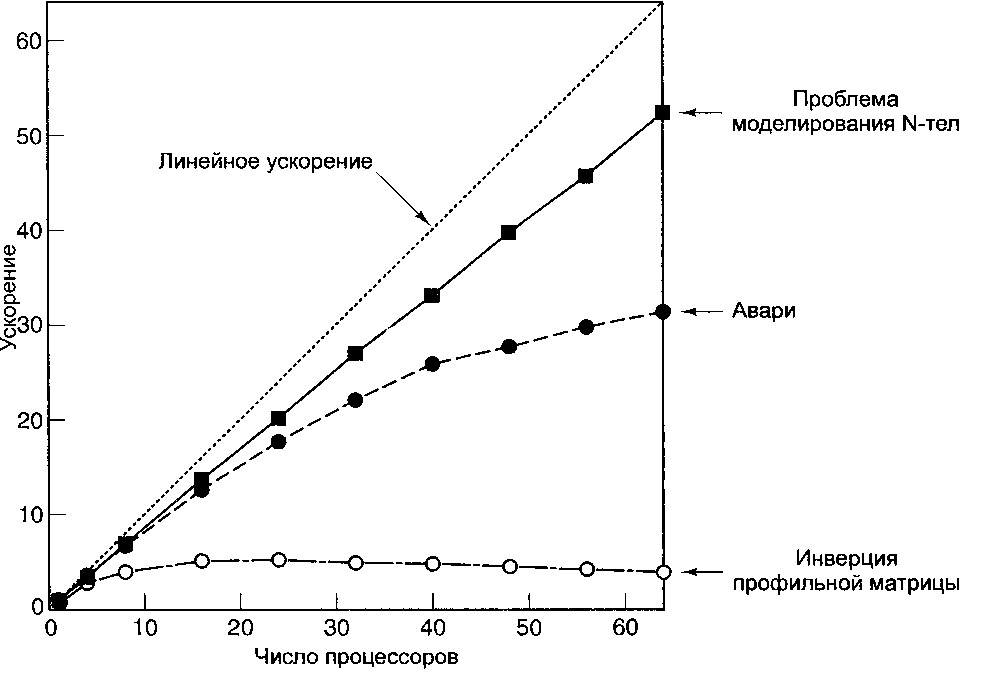 Рис. 8.40. На практике программы не могут достичь идеального ускорения (показано пунктирной линией) Здесь мы видим несколько разных параллельных программ, которые работают на мультикомпьютере, состоящем из 64 процессоров Pentium Pro. Каждая кривая показывает ускорение одной программы с k процессорами как функцию от k. Пунктирной линией обозначено идеальное ускорение, при котором использование k процессоров заставляет программу работать в k раз быстрее для любого к. Лишь немногие программы достигают идеального ускорения, хотя существуют довольно много программ, которые приближаются к идеалу. Проблема моделирования N тел за счет параллелизма решается гораздо быстрее, Авари (африканская игра) тоже обсчитывается быстрее, а вот ускорить инвертирование заданной профильной матрицы более чем в пять раз нельзя, сколько бы процессоров мы не использовали. Программы и результаты обсуждаются в [17]. Есть ряд причин, по которым практически невозможно достичь идеального ускорения: практически во всех программах есть фрагменты, принципиально выполняемые последовательно, например, инициализация, считывание исходных данных или получение результатов. Увеличение числа процессоров здесь не поможет. Предположим, что на однопроцессорном компьютере программа работает Г секунд, причем доля (/) от этого времени выполняется последовательно, а доля (1 -/) потенциально может выполняться параллельно, как показано на рис. 8.41, а. Если параллельный код можно запустить на п процессорах, то время выполнения этого кода в лучшем случае сократится с(1-/)Гдо(1 -/)Т/п, как показано на рис. 8.41, б. В результате общее время выполнения программы (и последовательного, и параллельного кода) составит /Т + (1 - /)Т/п. Ускорение — это время выполнения исходной программы (Г), разделенное на это новое время: |