На следующем уровне возможно внедрение в систему внешних плат ЦП с улучшенными вычислительными возможностями. Как правило, в подключаемых процессорах реализуются специальные функции, такие как обработка сетевых пакетов, обработка мультимедийных данных, криптография и т. д. Производи тельность специализированных приложений за счет этих функций может быть повышена в 5-10 раз.
Чтобы повысить производительность в сто, тысячу или миллион раз, необходимо свести воедино многочисленные процессоры и обеспечить их эффективное взаимодействие. Этот принцип реализуется в виде больших мультипроцессорных систем и мультикомпьютеров (кластерных компьютеров). Естественно, объединение тысяч процессоров в единую систему порождает новые проблемы, которые нужно решать.
Наконец, в последнее время появилась возможность интеграции через Интернет целых организаций. В результате формируются слабо связанные распределенные вычислительные сетки, или решетки. Такие системы только начинают развиваться, но их потенциал весьма высок.
Когда два процессора или обрабатывающих элемента находятся рядом и обмениваются большими объемами данных с небольшими задержками, они называются сильно связанными (tightly coupled). Соответственно, когда два процессора или обрабатывающих элемента располагаются далеко друг от друга и обмениваются небольшими объемами данных с большими задержками, они называются слабо связанными (loosely coupled). В данной главе мы обсудим принципы разработки систем этих форм параллелизма и рассмотрим ряд примеров. Начав с сильно связанных систем, для которых характерен внутрипроцессорный параллелизм, мы постепенно перейдем к слабо связанным системам и в завершающей части главы поговорим о распределенных вычислительных системах. Примерный спектр рассматриваемых тем иллюстрирует рис. 8.1.
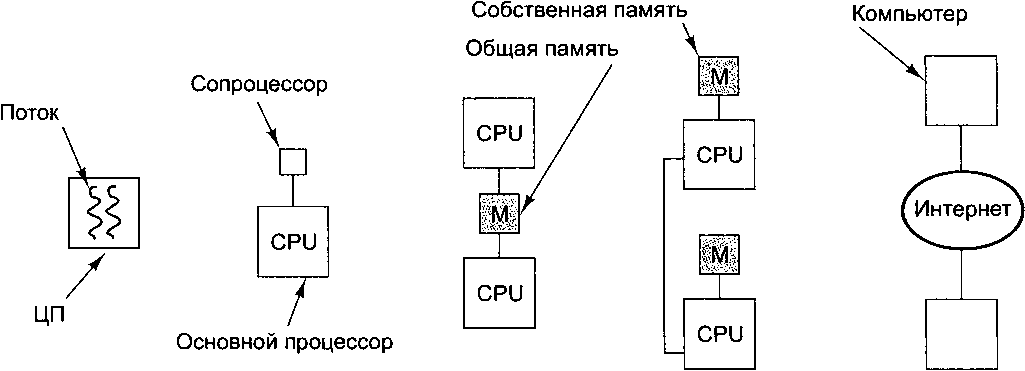
Сильно связанные системы Слабо связанные системы
а б в г д
Рис. 8.1. Внутрипроцессорный параллелизм (а); сопроцессор (б); мультипроцессор (е); мультикомпьютер (г); слабо связанная распределенная вычислительная система (д)
Параллелизм постоянно оказывается темой горячих дискуссий, в связи с чем в этой главе необычно много ссылок — в основном, на недавние работы по заданной теме. Дополнительные ссылки на работы ознакомительного характера можно найти в соответствующем разделе главы 9.
Внутрипроцессорный параллелизм
Один из очевидных способов увеличить производительность микросхемы состоит в том, чтобы заставить ее выполнять больше операций в единицу времени. В этом разделе мы рассмотрим некоторые приемы повышения быстродействия за счет параллелизма на уровне микросхемы, в частности, параллелизм на уровне команд, многопоточность и размещение на микросхеме нескольких процессоров. Все эти методики хоть и отличаются друг от друга, но в той или иной степени помогают решить задачу. Их роднит базовый принцип — «уплотнение» операций во времени.
Параллелизм на уровне команд
Низкоуровневый параллелизм достигается, в частности, вызовом нескольких команд за один тактовый цикл. Процессоры, в которых реализуется этот принцип, делятся на две категории: суперскалярные и VLIW. Те и другие уже упоминались в предыдущих главах, но сейчас этот материал нелишне повторить.