Антиплагиат английских текстов: 4 сервиса проверки плагиата на английском языке — Записки преподавателя
как найти плагиат с английского языка в русских научных статьях / Хабр
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту).
«
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю.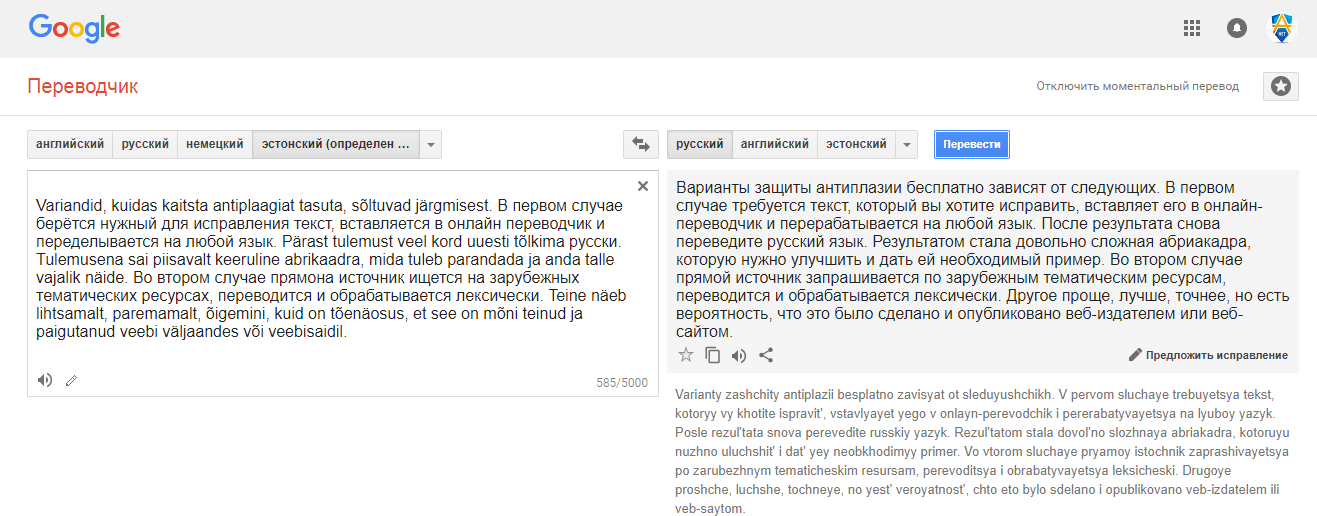
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.
Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.

Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно.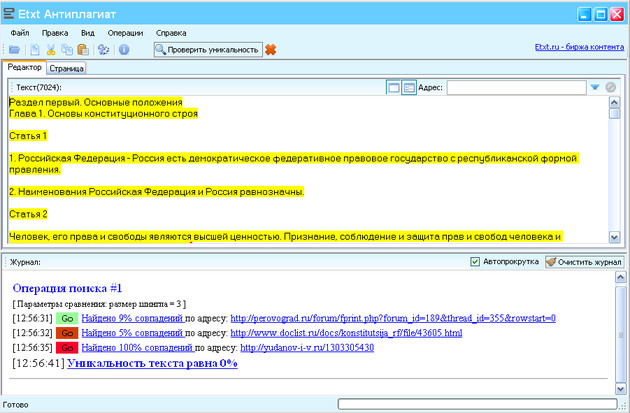
Реализовав машинный переводчик, мы столкнулись с первой трудностью – перевод всегда неоднозначен. Один и тот же смысл может быть выражен разными словами, может меняться структура предложения и порядок слов. А так как перевод делается автоматически, то сюда накладываются ещё и ошибки машинного перевода.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org
и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.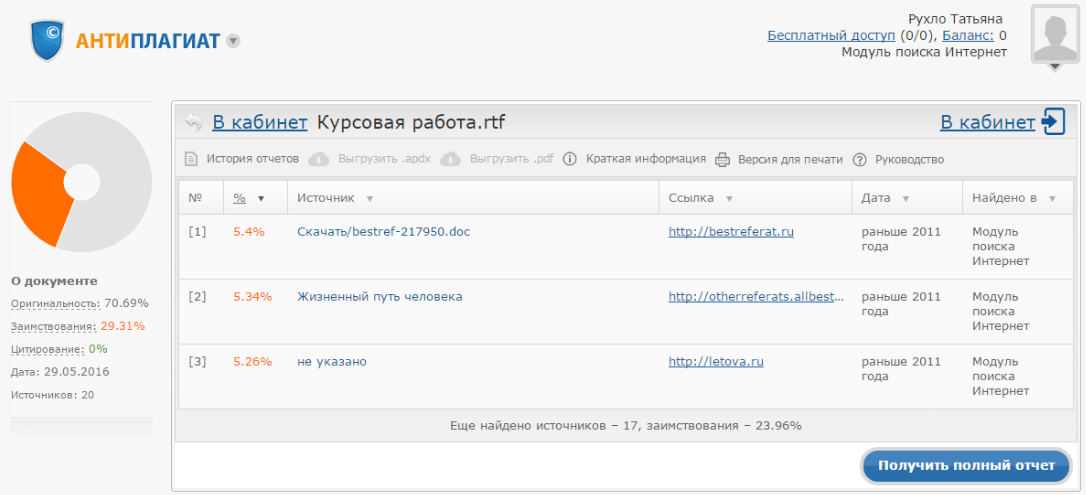
Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:
Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
И тут мы решили уйти от старой схемы поиска, основанной на сопоставлении слов. Нам однозначно нужен был другой алгоритм детектирования заимствований, который, с одной стороны, мог бы сопоставлять фрагменты текстов «по смыслу», а с другой, оставался таким же быстрым, как алгоритм шинглов.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?
Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности.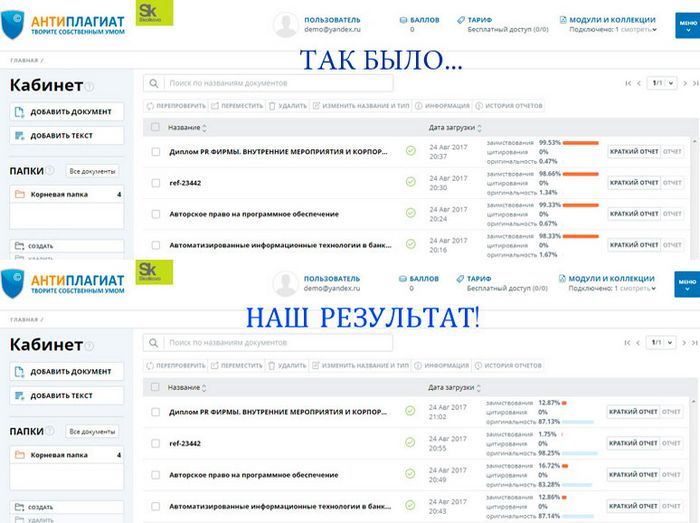 Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку.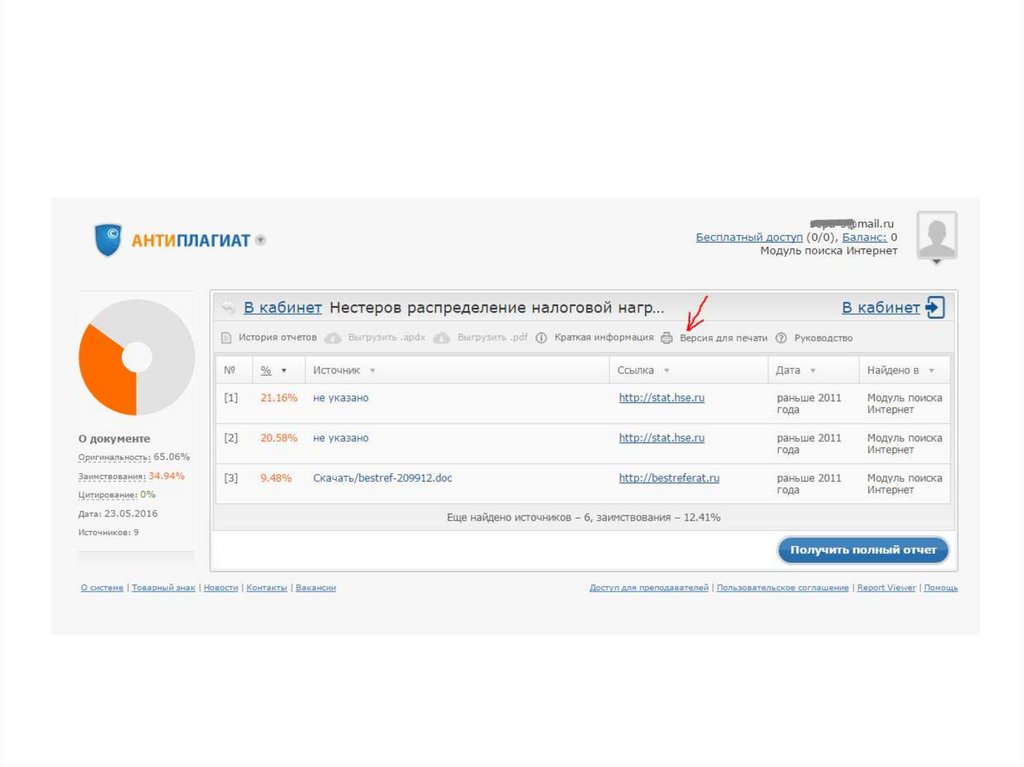 Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
| Тип срабатывания | Количество |
|---|---|
| Заимствование | 2627 |
| Переводные заимствования (текст переведен с английского языка и выдан за оригинальный) |
921 |
| Заимствования «наоборот» – из русского языка в английский (определялось по дате публикаций) | 1706 |
| Легальные заимствования | 2355 |
| Двуязычные статьи (работы одного и того же автора на двух языках) |
788 |
| Цитаты законов (использование формулировок законов) |
1567 |
| Cамоцитирование (переводное цитирование автором своей же англоязычной работы) |
660 |
| Ошибочные срабатывания (из-за некорректного перевода или ошибки нейронной сети) |
507 |
| Другое (проверяемые статьи содержали фрагменты на английском языке, или сложно отнести к какой-либо категории) |
1540 |
| Всего | 7689 |
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:
Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.
Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.
Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.
Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
Как проверить научную статью на плагиат? Допустимый процент плагиата
Проверка научной статьи на плагиат – обязательное требование, которое выполняется перед отправкой работы на публикацию в журнал.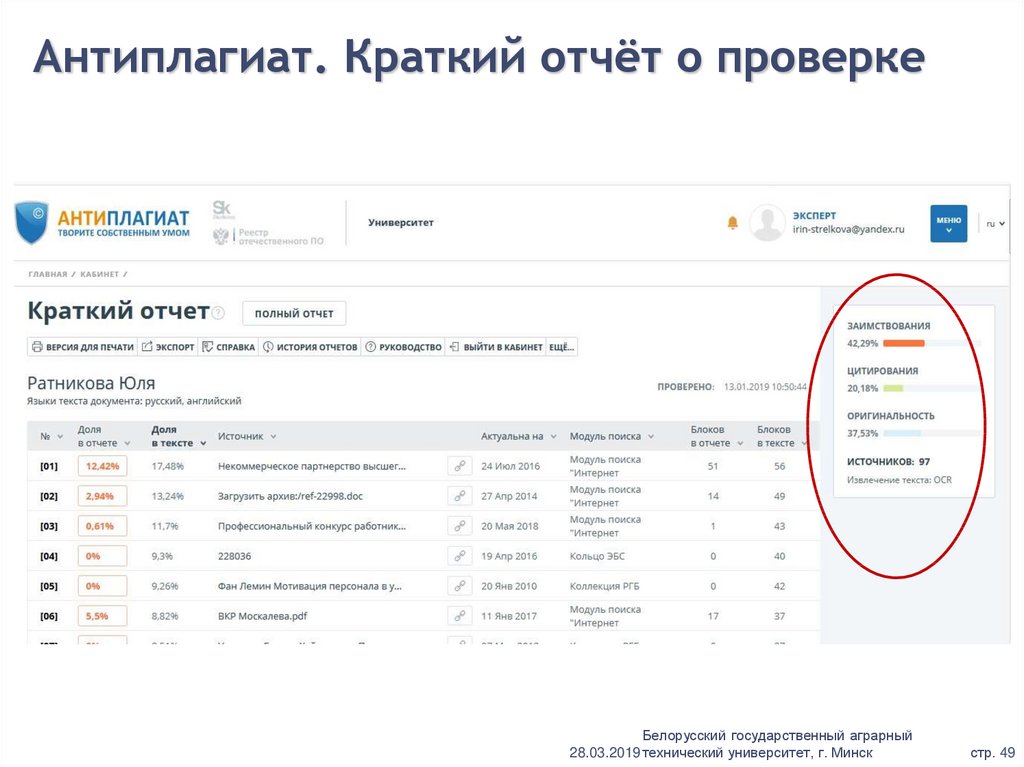 Делается это для того, чтобы избежать дублирования собственных или заимствованных мыслей в научных публикациях.
Делается это для того, чтобы избежать дублирования собственных или заимствованных мыслей в научных публикациях.
Для прохождения проверки пользуются разными сервисами – платными и бесплатными, работающими через браузер и требующими установки на компьютер, есть специализированные программы для научных работ.
Какими сервисами лучше пользоваться, какой процент плагиата допустим, как избежать плагиата – обо всем этом узнаете из статьи.
Содержание статьи
- Что такое плагиат и зачем проверять статьи на плагиат?
- Какими сервисами проверяют научные статьи на плагиат?
- Допустимые проценты плагиата
- Как избежать плагиата – 5 рекомендаций
- Заключение
Плагиатом называют присвоение чужих идей, мыслей, результатов исследований через умышленное заимствование текста другого автора без ссылки на его научный труд. Проблема незаконного копирования не теряет своей актуальности по сей день, несмотря на наличие современных способов проверки научных статей на плагиат в виде онлайн-программ.
Перед тем как отправить работу в печать необходимо проверить ее на антиплагиат. Проверке подлежат любые научные труды – рефераты, курсовые, дипломные работы, монографии, диссертации, статьи. Такое требование обусловлено несколькими причинами:
- Недобросовестные авторы, которые намеренно присваивают себе результаты чужих трудов.
- Неправильное цитирование или отсутствие ссылок на оригинальный текст.
- Повторение мыслей других ученых, которые уже были опубликованы ранее, частично или в полном объеме.
- Дублирование собственных уже опубликованных идей, именуемое самоцитированием, так же не допускается в большинстве журналов.
Рекомендуется самостоятельно выполнять проверку научной статьи на плагиат до ее отправки в издательство, чтобы избежать отказа в публикации из-за низкого процента уникальности.
Какими сервисами проверяют научные статьи на плагиат?
Если раньше при подозрении научного труда на плагиат ученым приходилось перечитывать множество книг и журналов в поисках оригинального текста, то сегодня все гораздо проще и быстрее. Проверка научной статьи на плагиат осуществляется через специальные программы, которые автоматически находят совпадения отдельных фрагментов или целого текста с опубликованными ранее источниками.
Проверка научной статьи на плагиат осуществляется через специальные программы, которые автоматически находят совпадения отдельных фрагментов или целого текста с опубликованными ранее источниками.
Среди бесплатных сервисов проверки выделяют text.ru, content-watch.ru, etxt.biz, advego.com. Их преимущество в доступности, для проверки небольшой статьи часто даже не требуется регистрация. Но существенный недостаток в том, что они не ориентированы на поиск среди научных текстовых баз, а охватывают коммерческие и информационные интернет-площадки. Прямые цитаты часто остаются незамеченными, а как неуникальными отмечаются какие-то общие фразы и часто употребляемые выражения. Это приводит к тому, что достоверно оценить уникальность научной работы становится сложно.
Подробней узнать о бесплатных сервисах проверки можно из статьи «Проверка текста на антиплагиат бесплатно».
Если сузить поиск программ до ориентированных на научные статьи, стоит обратить внимание на следующие:
- Antiplagiat.
 ru – популярный сервис у аспирантов, профессоров, независимых исследователей России со свободным доступом для каждого. Есть бесплатная версия, но достоверный результат проверки научной статьи на плагиат можно получить только при приобретении платного пакета. Стоит он недорого, есть выгодные предложения для частных лиц и корпоративных пользователей. В платной версии есть возможность просмотра работ, с которыми найдены совпадения.
ru – популярный сервис у аспирантов, профессоров, независимых исследователей России со свободным доступом для каждого. Есть бесплатная версия, но достоверный результат проверки научной статьи на плагиат можно получить только при приобретении платного пакета. Стоит он недорого, есть выгодные предложения для частных лиц и корпоративных пользователей. В платной версии есть возможность просмотра работ, с которыми найдены совпадения. - Антиплагиат.ВУЗ – система применяется для проверки уникальности рефератов, курсовых и других студенческих работ преподавателями. Каждый аспирант и преподаватель учебного заведения, где используется программа, может получить к ней доступ. Строгая система антиплагиата хорошо зарекомендовала себя при проверке научных текстов.
- Unicheck.com – авторитетная международная программа, которую следует использовать для проверки иностранных научных работ. В бесплатном доступе проверка нескольких страниц, для полного доступа нужен пакет, купить который можно через PayPal.

Очевидное преимущество подобных платных сервисов в том, что они предназначены для поиска плагиата среди научных текстов. То есть результат будет достоверным, где совпадения обнаруживаются по цитатам и заимствованиям, а не по общеупотребляемым фразам.
Большинство платных сервисов, предлагающих проверку научных статей на плагиат, дают возможность приобрести корпоративный пакет. В таком случае пользоваться программой смогут все сотрудники кафедры, аспиранты или другие сообщества, оформившие подписку.
Допустимые проценты плагиатаНет единых указаний к допустимому проценту уникальности научной статьи, каждое издательство выдвигает собственные требования. Поэтому перед подачей материалов на публикацию необходимо изучить условия приема работ в конкретном журнале. Одни сборники пишут определенное значение, которому должны соответствовать все публикуемые тексты. Другие просто отмечают, что статья должна быть оригинальной, авторской, а не заимствованной у других авторов или уже опубликованная ранее.
Главное, что должен знать каждый начинающий ученый – плагиат недопустим, ни при каких обстоятельствах нельзя выдавать чужие труды за свои.
Если исследователя уличат в плагиате, пострадает его репутация, с ним откажутся сотрудничать научные сообщества.
В отдельных случаях грозит юридическая ответственность, если факт незаконного заимствования удастся доказать.
Большинство издательств допускает наличие совпадений в тексте, если это научные данные, термины, вырезки из закона, которые сложно переформулировать. В этом случае все ссылки должны быть правильно оформлены, с указанием авторства неуникального фрагмента. Допустимой нормой неуникального текста считается 15-20%, но это могут быть лишь отдельные фразы, а не целые абзацы плагиата.
Если в результате проверки статья оказалась неуникальной, необходимо доработать ее, убрав или перефразировав подсвеченные фрагменты. После этого нужно опять проверить текст.
Как избежать плагиата – 5 рекомендацийПри поиске совпадений в тексте разные программы проверки научных статей на плагиат используют различные подходы. Существуют методы цитирования, анализа «множества слов», фрагментарный и статистический анализ. Сервис находит совпадения по отдельным фразам, выборочному набору слов, ссылкам на справочные данные и так далее.
Существуют методы цитирования, анализа «множества слов», фрагментарный и статистический анализ. Сервис находит совпадения по отдельным фразам, выборочному набору слов, ссылкам на справочные данные и так далее.
Часто бывают ситуации, когда система выдает авторский текст за неуникальный. Это происходит, если исследователю нужно указывать в своей работе результаты исследований других ученых, приходится использовать специфические термины и условные обозначения, таблицы, справочные данные. Тогда даже написанный своими словами научный труд может не пройти проверку на плагиат.
Чтобы избежать высокого уровня заимствований в статье, существует несколько рекомендаций:
- Приводите мысли других авторов в виде пересказа, а не цитаты. Перефразируйте идею своими словами, оставив ссылку на оригинальный текст.
- Если нужно отразить чужие результаты исследований, данные статистики, оформите их как таблицу, диаграмму или рисунок, сделайте скриншот.
- Не допускайте дублирования мыслей, меняйте порядок слов в словосочетаниях, которые часто повторяются, используйте синонимы.

- Избегайте употребления шаблонных выражений, поговорок, общих фраз, которые можно встретить не только в научных, но и в коммерческих публикациях.
- Пользуйтесь автоматическим переносом слов, тогда системы проверки будут воспринимать переносимое слово как два разных.
Не стоит увлекаться перефразированием чужих идей и результатов в собственном научном труде. Даже если программа покажет, что текст уникальный, это не гарантирует, что плагиат отсутствует. Злоупотребление дублированием приведет к нарушению научной этики, несмотря на отсутствие выявленных заимствованных фрагментов.
Не нужно рассчитывать и на то, что копирование информации из печатного издания защитит от плагиата. Практически все книги и сборники есть как в напечатанном, так и в электронном формате.
Издательство может провести «ручную» проверку научной статьи на плагиат. В случае обнаружения умышленного перефразирования работа будет отклонена, а с самим автором вряд ли захотят сотрудничать в дальнейшем. Ведь главная цель любого труда – это научная новизна.
Ведь главная цель любого труда – это научная новизна.
Выполнять проверку научной статьи на плагиат нужно обязательно перед тем, как отправить работу на публикацию в журнал. Сейчас активно борются с присвоением авторства чужих трудов, при обнаружении факта умышленного заимствования страдает репутация ученого, с ним отказываются сотрудничать, предусмотрена юридическая ответственность.
Для проверки научных работ на уникальность пользуются специальными сервисами-антиплагиатами. Есть бесплатные и платные программы, общего назначения и ориентированные на научные публикации. Системы автоматически осуществляют поиск совпадений в текстах разными методами.
Даже авторскую статью программа может показать неуникальной, если автор использует в работе специфические термины, результаты чужих исследований, общие фразы и повторения. Старайтесь писать статью своими словами, правильно оформляйте цитаты, обязательно ссылайтесь на оригинальный текст, если система нашла совпадения с ним. Плагиат недопустим в любом виде.
Плагиат недопустим в любом виде.
Присоединяйтесь, чтобы моментально узнавать о новых статьях в нашем научном блоге, акциях и получать только полезные материалы!
10 бесплатных сайтов проверки на плагиат для учителей
Плагиат — это проблема, с которой сталкиваются учителя разных дисциплин и на разных уровнях. Это обескураживает и отнимает много времени (Ламберт). Эта форма мошенничества может происходить по-разному. Студенты могут брать отрывки из онлайн-журналов, статей или образцов документов. Они могут «перефразировать», заменяя случайное слово. Иногда бывшие студенты передают старые сочинения, а иногда нынешние студенты находят способы украсть у своих сверстников. Наконец, в ситуациях с высокими ставками студенты могут заплатить кому-то за написание оригинальной статьи для них.
У учителей есть много возможностей для выявления текстов, которые крадут предложения из онлайн-источников, и даже есть инструменты, которые проверяют повторно используемые задания учениками. Многие из этих инструментов бесплатны и играют важную роль в выявлении и устранении плагиата.
Многие из этих инструментов бесплатны и играют важную роль в выявлении и устранении плагиата.
Сдают ли ваши ученики свои задания с помощью системы управления обучением? Некоторые школы подписываются на службы, которые проверяют на плагиат, когда учащийся загружает задание в LMS. Вы можете проверять партии заданий на плагиат и получать уведомления о любых проблемах еще до того, как начнете оценивать.
Если ваши учащиеся впервые пишут исследовательские работы, у них могут возникнуть проблемы с различением, когда близкая парафраза переходит в плагиат или когда сообщаемая речь должна быть заключена в кавычки. Усовершенствованные средства проверки на плагиат могут помочь учащимся заметить использование, которое, по их мнению, либо останется незамеченным, либо которое, по их искреннему мнению, было надлежащим образом интегрировано.
1. Турнитин Золотым стандартом всесторонней проверки на плагиат является Turnitin. Если в вашей школе есть подписка, вам повезло! Turnitin проверяет задания по целому ряду баз данных. Представленные работы также будут сравниваться друг с другом, поэтому нынешний студент не сможет повторно использовать эссе, написанное бывшим студентом. Цены на комплексный пакет Turnitin не разглашаются; будьте готовы указать потребности вашего учебного заведения при запросе предложения.
Если в вашей школе есть подписка, вам повезло! Turnitin проверяет задания по целому ряду баз данных. Представленные работы также будут сравниваться друг с другом, поэтому нынешний студент не сможет повторно использовать эссе, написанное бывшим студентом. Цены на комплексный пакет Turnitin не разглашаются; будьте готовы указать потребности вашего учебного заведения при запросе предложения.
Узнать больше: Trunitin
2. КопилейкиКак и Turinitin, Copyleaks сравнивает тексты с онлайн-ресурсами и другими студенческими заданиями. Он также предлагает бесплатную версию, которая позволяет вам получить представление о его приборной панели и функциях.
Чтобы попробовать, перейдите по этой ссылке и переместите ползунок до упора влево. В отличие от ежемесячной подписки, которая для небольшой школы стоит около 10 долларов, бесплатная версия не позволяет загружать пакетные файлы. Он предоставляет отчеты об оригинальности с процентом оригинала, выделяя дословные совпадения и «перефразы», которые заменяют только случайное слово.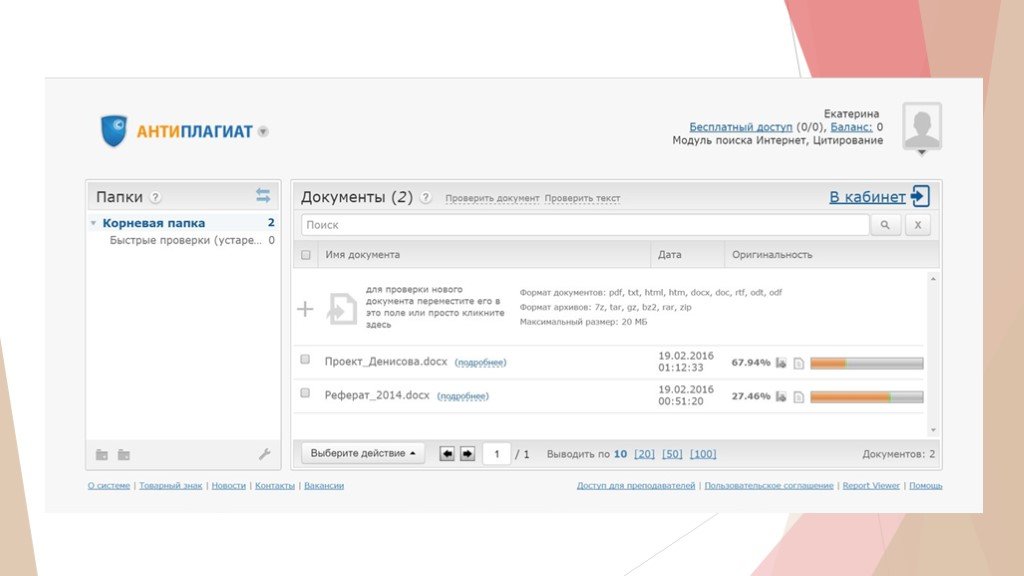
Как Turnitin, так и Copyleaks являются комплексными службами обнаружения плагиата, которые расскажут вам о передовых методах плагиата в дополнение к прямому копированию путем вырезания и вставки.
3. Премиум-функции Google ClassroomЕсли в вашем учебном заведении используется версия Google for Education «Плюс», у вас уже есть средство проверки на плагиат; вам просто нужно выбрать поле «Проверить плагиат» под рубрикой при создании задания. Если у вас есть GSuite, вы сможете попробовать эту функцию, но существует ограничение на количество заданий, которые вы можете проверить.
После того, как ваши ученики отправят свои работы, инструмент будет отмечать отрывки для вас, когда вы открываете разные отправленные материалы. Проверка также будет содержать ссылку на исходный веб-сайт. В приведенном выше видео показано, как включить функцию проверки на плагиат и использовать ее при просмотре работ учащихся.
Проверка также будет содержать ссылку на исходный веб-сайт. В приведенном выше видео показано, как включить функцию проверки на плагиат и использовать ее при просмотре работ учащихся.
Подробнее: Google Classroom
Лучшие сайты проверки на плагиат для отдельных материаловЕсли в вашем учебном заведении нет подписки на программу проверки на плагиат, у вас все равно есть множество инструментов, если вы готовы потратить время на проверку эссе по отдельности. Некоторые студенты могут попытаться отрицать плагиат, поэтому будет полезно иметь отчет и исходный текст, чтобы показать, что у вас действительно есть доказательства, когда вы встречаетесь со своим студентом.
1. Грамматика Возможно, вы знакомы с бесплатным расширенным инструментом обратной связи от Grammarly. За 12 долларов в месяц вы можете добавить в расширение проверку на плагиат и ряд других функций, обновив его до премиум-версии.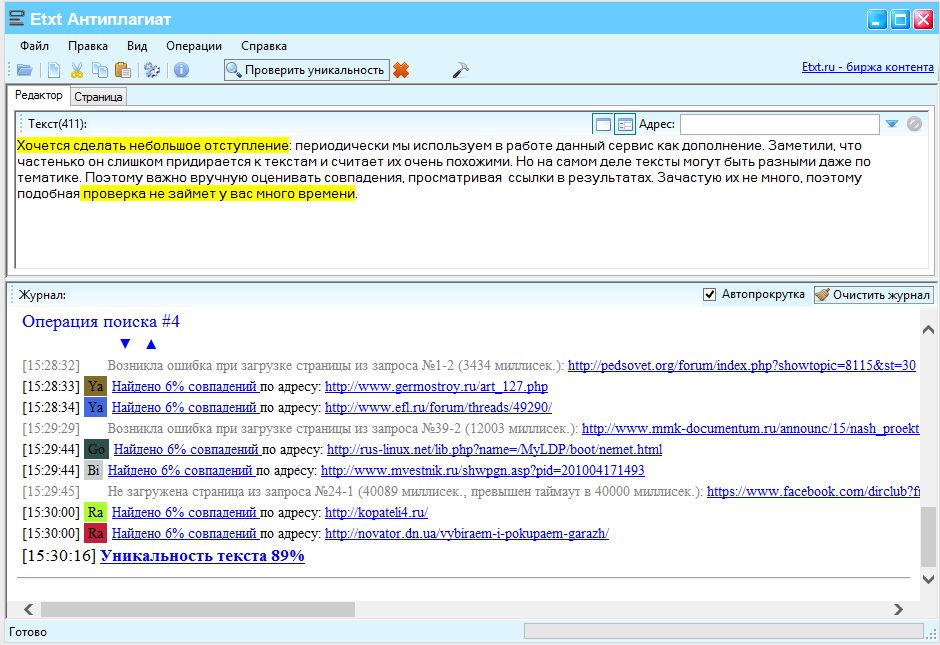
Когда вы вызываете задание учащегося в своем браузере, вы сможете заметить случаи плагиата. В идеале вы можете использовать эту функцию (возможно, посредством совместного использования экрана) во время конференции со студентами по их черновикам и помочь им избежать непреднамеренного плагиата.
У Grammarly также есть бесплатный веб-сайт для проверки на плагиат. Он сравнивает текст со статьями ProQuest, но в бесплатной версии только сообщается, использовался ли текст без указания авторства; он не показывает, какие предложения были скопированы.
Подробнее: Grammarly
2. ПлатформаПосле регистрации Plagramme предлагает выбор между стандартным сканированием, сканированием премиум-класса или сканированием с оплатой за документ. Легко загрузить файл и отсканировать его, но в бесплатном отчете указывается только наличие плагиата без указания проблемных мест.
Подробнее: Платформа
3. Детектор плагиата Если вам нравится идея создания отчета с оценкой оригинальности, но в вашем учебном заведении нет подписки на программу проверки на плагиат, вы можете вставить студенческую работу в Детектор плагиата. Этот онлайн-инструмент выполнит сканирование на плагиат и предоставит процент предложений, которые поступают из внешних источников без цитирования.
Этот онлайн-инструмент выполнит сканирование на плагиат и предоставит процент предложений, которые поступают из внешних источников без цитирования.
Это не лучшее решение для анализа заданий в большом количестве, но оно может помочь вам подготовиться к конференции со студентом, занимающимся плагиатом, если вам нужно будет указать и уточнить предложения, которые он или она использовали недопустимым образом.
Подробнее: Детектор плагиата
4. Небольшие SEO-инструментыЕще одна бесплатная программа проверки — Small SEO Tools. Этот сканер плагиата был разработан для малого бизнеса, но его отчеты также будут полезны учителям. В нем перечислены все предложения, которые не были процитированы должным образом, а также ссылка на исходный текст.
Узнайте больше: Малые SEO-инструменты
5. текст Если вы ищете бесплатный инструмент, который могут использовать студенты, quetext предоставляет как анализ плагиата, так и инструмент цитирования. Он хорошо справляется с выделением отрывков с небольшими изменениями. Он не загружается быстро, но будьте терпеливы: отчеты весьма полезны.
Он хорошо справляется с выделением отрывков с небольшими изменениями. Он не загружается быстро, но будьте терпеливы: отчеты весьма полезны.
Подробнее: quetext
6. Поиск в GoogleНекоторые учащиеся находят типовые эссе с помощью поисковой системы Google, и вы тоже можете. Вставьте подозрительное предложение в адресную строку Chrome или в строку поиска на Google.com и заключите его в кавычки. Если вы получите точное попадание, обязательно добавьте адрес сайта в закладки или сделайте скриншот. Этот подход также дает эссе, которые изначально были написаны на иностранном языке и переведены с помощью Google Translate.
7. Проверка истории версий Если ваши учащиеся отправят документы Google, вы сможете узнать, когда файл был создан и кто над ним работал, перейдя к истории версий документа. Это может быть полезно, если вы сильно подозреваете, что студент заплатил кому-то за написание важного задания.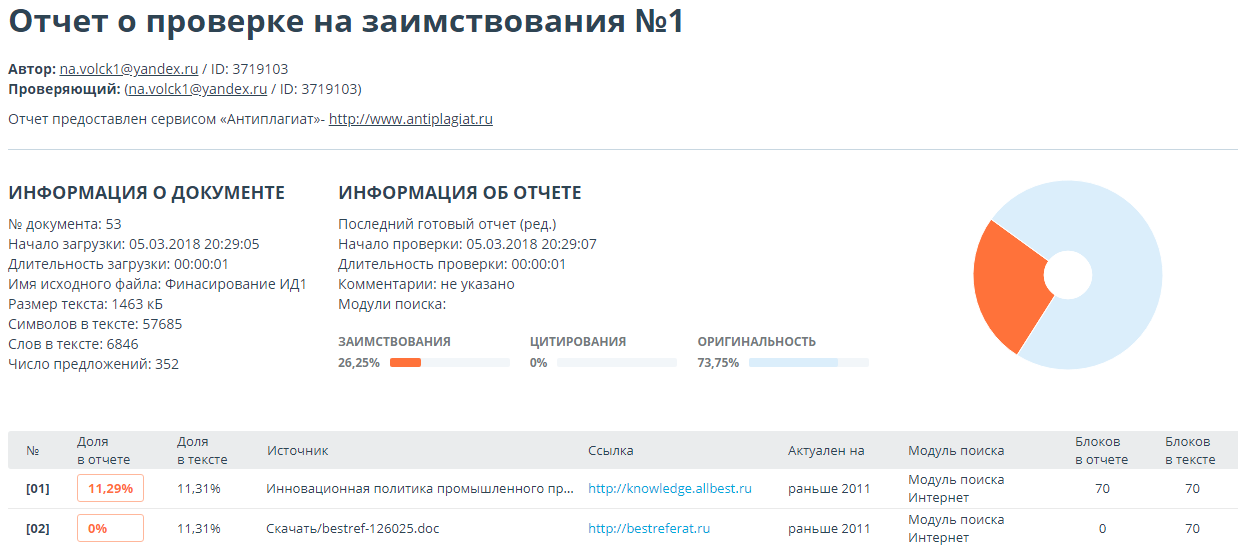
Это можно сделать на вкладке «Файл». Некоторые учащиеся, возможно, действительно одолжили устройство друга или члена семьи, когда писали, так что это не является неопровержимым доказательством мошенничества.
Подумайте, согласуется ли текст с предыдущей работой учащегося, и обсудите свои подозрения со своим начальником, прежде чем выдвигать обвинения, чтобы убедиться, что вы следуете правилам вашей школы.
Предотвращение, обнаружение и устранение плагиатаПлагиат — это распространенная проблема, связанная с академическим письмом, и преподаватели должны быть готовы выявить ее и решить. Кроме того, учителя должны делать все возможное, чтобы помочь учащимся использовать внешние источники без плагиата (2016, Cambridge University Press, ELT). В идеале ваша школа должна предоставить готовый к использованию инструмент для проверки на плагиат, но даже если его нет, существуют различные методы обнаружения некоторых видов плагиата.
Имейте в виду, что разные школы борются с плагиатом по-разному, поэтому убедитесь, что вы знакомы с политикой вашей школы, и обязательно сообщите об этом своим ученикам в начале семестра. Будет ли студент отчитываться перед академическими делами? Будет ли статья получать нулевой кредит или разрешены повторные действия? Существует ли общешкольный список нарушений? Каков протокол вашей школы для сообщения о плагиате и предъявления ученику ваших доказательств или подозрений?
Будет ли студент отчитываться перед академическими делами? Будет ли статья получать нулевой кредит или разрешены повторные действия? Существует ли общешкольный список нарушений? Каков протокол вашей школы для сообщения о плагиате и предъявления ученику ваших доказательств или подозрений?
Теперь у вас есть инструменты для выявления плагиата; убедитесь, что у вас есть административная поддержка, прежде чем предпринимать определенные действия. Проверки на плагиат не полностью остановят студентов от кражи из внешних источников, но вы можете использовать их, чтобы установить ожидание того, что источники должны быть подтверждены.
СсылкиИздательство Кембриджского университета ELT. (2016, 16 февраля). Плагиат — Почему студенты делают это и как вы можете помочь [Видео]. YouTube. https://www.youtube.com/watch?v=oCT7iamerdo
Copyleaks. (2022). Цены на образование Copyleaks. Программное обеспечение для борьбы с плагиатом Copyleaks, откройте для себя программное обеспечение для борьбы с плагиатом в Интернете. Получено 11 января 2022 г. с https://copyleaks.com/pricing/product/education/step/1
Получено 11 января 2022 г. с https://copyleaks.com/pricing/product/education/step/1
Домбровски, Куинн. (2009, 9 январяй). список участников [Изображение]. Куинн Дамбровски под лицензией CC 2.0 https://www.flickr.com/photos/53326337@N00/3183174451
Google. (2022). Включите отчеты об оригинальности — помощь в классе. Google. Получено 11 января 2022 г. с https://support.google.com/edu/classroom/answer/9335816?hl=en
GotCredit. (20015, 16 марта). Загрузить ключ [изображение]. GotCredit под лицензией CC by 2.0 https://www.flickr.com/photos/144008357@N08/33715643736
Grammarly. (2022). Поднимите свое письмо. грамматически. Получено 11 января 2022 г. с https://www.grammarly.com/plans 9.0003
Джинкс!. (2008, 7 февраля). Очерки!! [Изображение]. Джинкс! под лицензией CC by 2.0 https://www.flickr.com/photos/7567658@N04/2247468044
Jonson, Jen. (2021, 19 февраля). Google Classroom Originality Reports Проверка на плагиат — как использовать и чем она отличается от Turnitin [видео]. YouTube. https://www.youtube.com/watch?v=Xrrei9jeib4
YouTube. https://www.youtube.com/watch?v=Xrrei9jeib4
wiredforlego. (2011, 4 июля). Вставить Копировать Вставить Копировать [Изображение]. wiredforlego под лицензией CC by 2.0 https://www.flickr.com/photos/14136614@N03/5904308311
Могут ли средства защиты от плагиата обнаруживать, когда чат-боты с искусственным интеллектом пишут студенческие эссе?
Могут ли средства защиты от плагиата обнаруживать, когда чат-боты с искусственным интеллектом пишут студенческие эссе?
TweetShareПосле запуска в прошлом месяце, ChatGPT, последний чат-бот, выпущенный OpenAI, начал распространяться онлайн.
Алекс, второкурсник университета в Питтсбурге, начал экспериментировать с чат-ботом примерно через неделю после его выпуска, узнав о нем в Твиттере. Через пару дней он был очень взволнован качеством написанного. Он говорит, что чат-бот был хорош, действительно хорош. («Алекс» — это имя, которое этот человек предоставил EdSurge. Он согласился говорить только анонимно, опасаясь последствий за признание в академической нечестности. )
)
Он нашел чат-бота на неделе выпускных экзаменов, когда все безумно торопились закончить бумаги. Алекс говорит, что большинству людей было интересно спросить у чат-бота шутки или истории, но он «сразу же был заинтригован идеей использовать его для написания статьи».
Однако после того, как он опробовал несколько подсказок сочинений, которые ему поручили, он заметил некоторые проблемы. Надпись может быть неловкой. Это будет повторять фразы или включать неточные цитаты. Эти мелочи складывались, из-за чего казалось, что текст написан не человеком. Но Алекс начал подгонять текст, экспериментируя с разбивкой и варьируя типы подсказок, которые он скармливал чат-боту. Казалось, что это снимает часть неблагодарной беготни (или, как могут утверждать некоторые профессора, работы) с написания эссе, требуя лишь небольшой предварительной работы и небольшого редактирования: «Вы можете, по крайней мере, писать статьи на 30 процентов быстрее». он говорит.
В конце концов, он говорит, что документы, которые он и бот создавали вместе, легко прошли проверку на плагиат. Он восхвалял чат-бота перед друзьями. «Я был как Иисус, который ходил, проповедуя доброе слово, уча людей, как его использовать», — так он выразился.
Он восхвалял чат-бота перед друзьями. «Я был как Иисус, который ходил, проповедуя доброе слово, уча людей, как его использовать», — так он выразился.
Что-то фундаментальное изменилось: «У меня буквально кружилась голова и я смеялся, и я подумал: «Чувак, посмотри на это», и все изменилось навсегда», — говорит он.
Он был не единственным, кого он знал, используя ИИ. Но другие были менее осторожны в этом процессе, отметил он. Они очень доверяют алгоритмическому письму, сдавая эссе, не просматривая их сначала.
Финансист, Алекс тоже учуял возможность. Его карманы были не совсем вровень. Итак, на раннем этапе, прежде чем это стало популярным, Алекс продал несколько газет — по его оценкам, около пяти — за «пару сотен баксов». Неплохая цена за пару часов работы.
Игра в кошки-мышки
За последние несколько недель в популярной прессе появилось множество статей, подробно описывающих, как студенты используют ChatGPT для написания своих работ. Журнал Atlantic резко поставил вопрос: «Эссе колледжа мертво».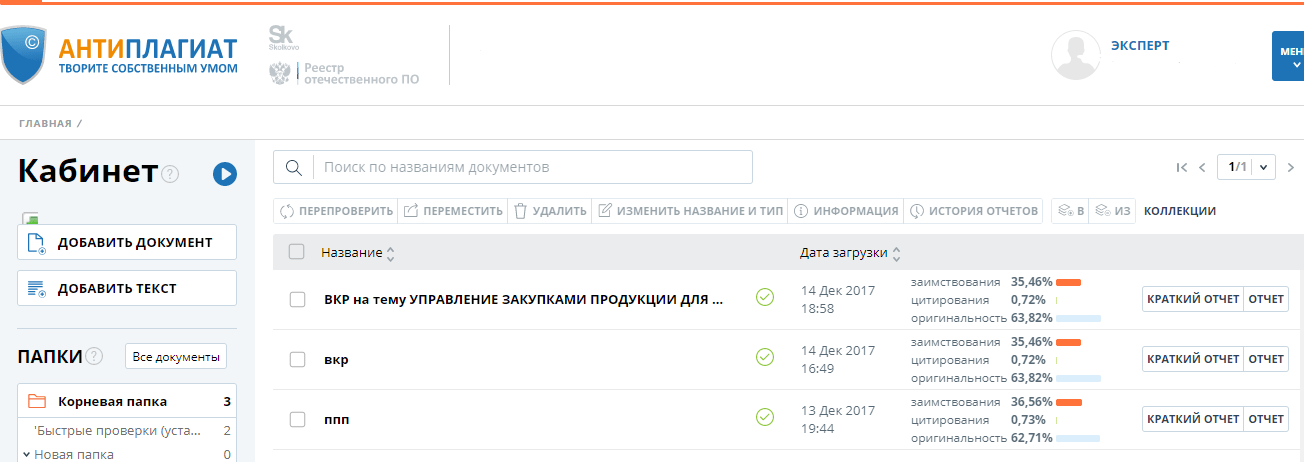
И этот инструмент представляет собой проблему не только для тех, кто преподает английский язык. Чат-бот с искусственным интеллектом, по-видимому, также может дать ответы на некоторые вопросы по финансам и математике.
Но, как и в случае с Интернетом, который предоставил данные, на которых обучался чат-бот, вывод ChatGPT может быть рискованным. Это означает, что ответы на эссе, которые он готовит для студентов, часто содержат утверждения, которые не соответствуют действительности, а иногда просто выдумывают. Он также пишет расово-нечувствительные и женоненавистнические вещи.
Но история Алекса показывает, что небольшой человеческий вклад может исправить такие проблемы, что поднимает вопрос, который интересует многих профессоров: могут ли инструменты обнаружения плагиата обнаружить эти творения ИИ?
Оказывается, создатели TurnItIn, одного из наиболее широко используемых инструментов для обнаружения плагиата, даже не потеют. «Мы абсолютно уверены, что для текущего поколения систем генерации письма с помощью ИИ обнаружение возможно», — говорит Эрик Ван, вице-президент компании по искусственному интеллекту.
Плагиат развивается, но теоретически его все еще можно обнаружить, утверждает он. Это потому, что в отличие от человеческого письма, которое имеет тенденцию быть своеобразным, машинное письмо предназначено для использования слов с высокой вероятностью, говорит Ван. Ему просто не хватает человеческого прикосновения.
Проще говоря, эссе, написанные чат-ботами, невероятно предсказуемы. Слова, которые пишет машина, — это слова, которые вы ожидаете и там, где вы их ожидаете. И это оставляет, как говорит Ван, «статистический артефакт», который вы можете проверить. И компания заявляет, что в следующем году она сможет помочь преподавателям поймать некоторые читы с помощью алгоритмических инструментов, таких как ChatGPT.
Кого ты называешь неоригинальным?
Независимо от того, считаете ли вы, что признание эссе в колледже мертвым, является преждевременным диагнозом или нет, опасения реагируют на реальную тенденцию.
Обман, ну, это в моде.
По мере того, как студенты выгорают от беспрецедентного стресса и неопределенности, в которые они попали, они, кажется, все больше склоняются к более коротким путям. Университеты сообщают, что с начала пандемии мошенничество в некоторых случаях удвоилось или даже утроилось. Например: в 2020-2021 учебном году, в разгар пандемии, Университет Содружества Вирджинии сообщил о 1077 случаях академических проступков, что более чем в три раза больше.
Университеты сообщают, что с начала пандемии мошенничество в некоторых случаях удвоилось или даже утроилось. Например: в 2020-2021 учебном году, в разгар пандемии, Университет Содружества Вирджинии сообщил о 1077 случаях академических проступков, что более чем в три раза больше.
Цифры показывают, что мошенничество резко увеличилось, но фактические цифры могут быть занижены, говорит Дерек Ньютон, который ведет The Cheat Sheet, информационный бюллетень, посвященный академическому мошенничеству. По словам Ньютона, люди не хотят признаваться в обмане. Он добавляет, что большинство исследований академической добросовестности основаны на самоотчетах, и может быть трудно доказать чей-то обман. Но он говорит, что ясно, что мошенничество «взорвалось».
С чем это связано? Поскольку колледжи поспешили обучать больше студентов, они обратились к онлайн-программам. По словам Ньютона, это создает хорошие условия для списывания, поскольку сокращает количество человеческих взаимодействий между людьми и увеличивает чувство анонимности среди студентов. Также увеличилось использование «сайтов помощи с домашними заданиями» — компаний, которые предоставляют ответы по запросу и места, где студенты могут делиться ответами на экзамены, что, по его словам, увеличивает масштабы мошенничества.
Также увеличилось использование «сайтов помощи с домашними заданиями» — компаний, которые предоставляют ответы по запросу и места, где студенты могут делиться ответами на экзамены, что, по его словам, увеличивает масштабы мошенничества.
Проблема? Студенты учатся не так много, и, по мнению Ньютона, в колледжах нет той ценности, которую колледжи должны приносить студентам. По его словам, поскольку студенты редко обманывают только один раз, рост числа обманов снижает ответственность и качество в профессиях, для которых готовят студентов колледжи (в том числе в таких областях, как инженерное дело). «Поэтому я рассматриваю эту проблему как трижды плохую: это плохо для студентов. Это плохо для школ. И это плохо для всех нас».
Алекс, второкурсник из Питтсбурга, немного по-другому видит отношения между чат-ботом и учеником.
Он говорит, что это «симбиотические отношения», когда машина учится у вас, когда вы ее используете. По крайней мере, так, как он это делает. «Это помогает его оригинальности», — говорит он, потому что он изучает причуды своего пользователя.
Но это также поднимает вопрос о том, что представляет собой оригинальность.
Он не спорит, что делает правильно. «Очевидно, что все это неэтично», — признает он. «Я говорю вам прямо сейчас, что совершил академическую нечестность».
Однако он утверждает, что студенты уже давно используют такие инструменты, как Grammarly, которые предлагают конкретные рекомендации по переработке прозы. И многие студенты уже обращаются к Интернету за исходным материалом для своих эссе. Для него мы всего лишь новая реальность, с которой академическим кругам приходится считаться.
Алекс догадывается, что слухи о том, как использовать ChatGPT для написания статей, быстро распространяются среди студентов. «На самом деле это невозможно остановить, — утверждает он.
Даже некоторые руководители колледжей, кажется, готовы изменить методы обучения, чтобы справиться с задачами искусственного интеллекта.
«Меня воодушевляет давление, которое #ChatGPT оказывает на школы и преподавателей», — написал на этой неделе в Твиттере Бернард Булл, президент Университета Конкордия в Небраске.

Об авторе