Что такое robots txt: Использование файла robots.txt — Вебмастер. Справка
Использование файла robots.txt — Вебмастер. Справка
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем. В robots.txt можно ограничить индексирование роботами страниц сайта, что может снизить нагрузку на сайт и ускорить его работу.
Примечание. Ограниченные в robots.txt страницы могут участвовать в поиске Яндекса. Чтобы удалить страницы из поиска, укажите директиву noindex в HTML-коде страницы или настройте HTTP-заголовок. Не ограничивайте такие странице в robots.txt, чтобы робот Яндекса смог их проиндексировать и обнаружить ваши указания. Подробно см. в разделе Как удалить страницы из поиска.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
- Требования к файлу robots.txt
- Рекомендации по наполнению файла
- Использование кириллицы
- Как создать robots.txt
- Вопросы и ответы
 txt, если:
txt, если:Размер файла не превышает 500 КБ.
Это TXT-файл с названием robots — robots.txt.
Файл размещен в корневом каталоге сайта.
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK. Проверьте ответ сервера
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots. txt правила. txt правила. |
| Disallow | Запрещает обход разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay | Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |

* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы Disallow: /bin/ # запрещает ссылки из "Корзины с товарами". Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска Disallow: /admin/ # запрещает ссылки из панели администратора Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта Clean-param: ref /some_dir/get_book.pl
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно: User-agent: Yandex Disallow: /корзина Sitemap: сайт.рф/sitemap.xml #Верно: User-agent: Yandex Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
В текстовом редакторе создайте файл с именем robots.txt и укажите в нем нужные вам директивы.
Проверьте файл в Вебмастере.
Положите файл в корневую директорию вашего сайта.
Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.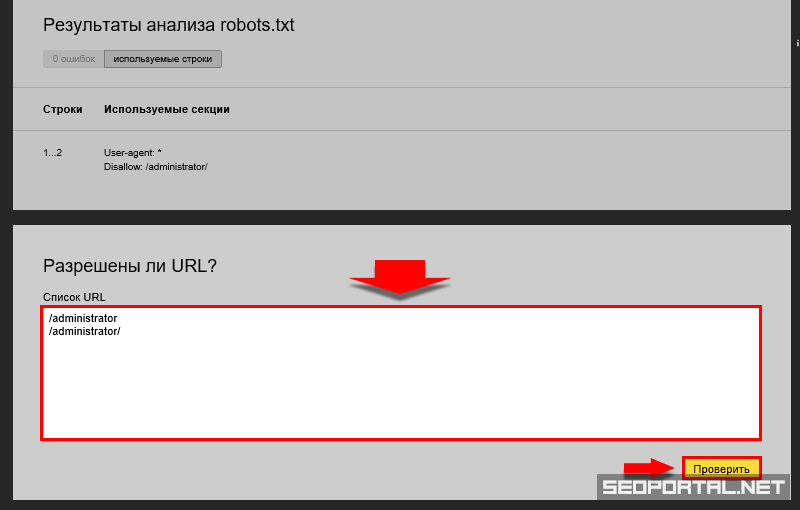 txt для робота, проверьте ответ сервера.
txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
Зачем вам нужен файл robots.txt, и как его создать?
Файл robots.txt, он же стандарт исключений для роботов — это текстовый файл, в котором хранятся определенные указания для роботов поисковых систем.
Прежде, чем сайт попадает в поисковую выдачу и занимает там определенное место, его исследуют роботы. Именно они передают информацию поисковым системам, и далее ваш ресурс отображается в поисковой строке.
Robots.txt выполняет важную функцию — он может защитить весь сайт или некоторые его разделы от индексации. Особенно это актуально для интернет-магазинов и других ресурсов, через которые совершаются онлайн-оплаты. Вам же не хочется, чтобы кредитные счета ваших клиентов вдруг стали известны всему интернету? Для этого и существует файл robots.txt.
Про директивы
Поисковые роботы по умолчанию сканируют все ссылки подряд, если только не установить им ограничений. Для этого в файле robots.txt составляют определенные команды или инструкции к действию. Такие инструкции называются директивами.
Главная директива-приветствие, с которой начинается индексация файла — это user-agent
Она может выглядеть так:
User-agent: Yandex
Или так:
User-agent: *
Или вот так:
User-agent: GoogleBot
User-agent обращается к конкретному роботу, и дальнейшие руководства к действию будут относиться только к нему.
Так, в первом случае инструкции будут касаться только роботов Яндекс, во втором — роботов всех поисковых систем, в последнем — команды предназначены главному роботу Google.
Резонно спросить: зачем обращаться к роботам по отдельности? Дело в том, что разные поисковые “посланцы” по разному подходят к индексации файла. Так, роботы Google беспрекословно соблюдают директиву sitemap (о ней написано ниже), в то время как роботы Яндекса относятся к ней нейтрально. А вот директива clean-param, которая позволяет исключать дубли страниц, работает исключительно для поисковиков Яндекс.
Однако, если у вас простой сайт с несложными разделами, рекомендуем не делать исключений и обращаться ко всем роботам сразу, используя символ *.
Вторая по значимости директива — disallow
Она запрещает роботам сканировать определенные страницы. Как правило, с помощью disallow закрывают административные файлы, дубликаты страниц и конфиденциальные данные.
На наш взгляд, любая персональная или корпоративная информация должна охраняться более строго, то есть требовать аутентификации.
Директива может выглядеть так:
User-agent: *
Disallow: /wp-admin/
Или так:
User-Agent: Googlebot
Disallow: */index.php
Disallow: */section.php
В первом примере мы закрыли от индексации системную панель сайта, а во втором запретили роботам сканировать страницы index.php и section.php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
Следующая директива — allow
В противовес предыдущей, это команда разрешает индексировать информацию.
Может показаться странным: зачем что-то разрешать, если поисковой робот по умолчанию готов всё сканировать? Оказывается, это нужно для выборочного доступа. К примеру, вы хотите запретить раздел сайта с названием /korobka/.
Тогда команда будет выглядеть так:
User-agent: *
Disallow: /korobka/
Но в то же время в разделе коробки есть сумка и зонт, который вы не прочь показать другим пользователям.
Тогда:
User-agent: *
Disallow: /korobka/
Allow: /korobka/sumka/
Allow: /korobka/zont/
Таким образом, вы закрыли общий раздел korobka, но открыли доступ к страницам с сумкой и зонтом.
Sitemap — еще одна важная директива. По названию можно предположить, что эта инструкция как-то связана с картой сайта. И это верно.
Если вы хотите, чтобы при сканировании вашего сайта поисковые роботы в первую очередь заходили в определенные разделы, нужно в корневом каталоге сайта разместить вашу карту — файл sitemap. В отличие от robots.txt, этот файл хранится в формате xml.
Если представить, что поисковой робот — это турист, который попал в ваш город (он же сайт), логично предположить, что ему понадобится карта. С ней он будет лучше ориентироваться на местности и знать, какие места посетить (то есть проиндексировать) в первую очередь. Директива sitemap послужит роботу указателем — мол, карта вон там.
Как создать и проверить robots.txt
Стандарт исключений для роботов обычно создают в простом текстовом редакторе (например, в Блокноте). Файлу дают название robots и сохраняют формате txt.
Далее его надо поместить в корневой каталог сайта. Если вы все сделаете правильно, то он станет доступен по адресу “название вашего сайта”/robots.txt.
Самостоятельно прописать директивы и во всем разобраться вам помогут справочные сервисы. Воспользуйтесь любыми на выбор: Яндекс или Google. С их помощью за 1 час даже неопытный пользователь сможет разобраться в основах.
Когда файл будет готов, его обязательно стоит проверить на наличие ошибок. Для этого у главных поисковых систем есть специальные веб-мастерские. Сервис для проверки robots.txt от Яндекс:
https://webmaster.yandex.ru/tools/robotstxt/
Сервис для проверки robots.txt от Google:
https://www. google.com/webmasters/tools/home?hl=ru
google.com/webmasters/tools/home?hl=ru
Когда забываешь про robots.txt
Как вы уже поняли, файл robots совсем не сложно создать. Однако, многие даже крупные компании почему-то забывают добавлять его в корневую структуру сайта. В результате — попадание нежелательной информации в просторы интернета или в руки мошенников плюс огромный общественный резонанс.
Так, в июле 2018 года СМИ говорили об утечке в Сбербанке: в поисковую выдачу Яндекс попала персональная информация клиентов банка — со скриншотами паспортов, личными счетами и номерами билетов.
Не стоит пренебрегать элементарными правилами безопасности сайта и ставить под сомнение репутацию своей компании. Лучше не рисковать и позаботиться о правильной работе robots.txt. Пусть этот маленький файл станет вашим надежным другом в деле поисковой оптимизации сайтов.
Дальше: 20 способов ускорить загрузку сайта в 2018 году
Что такое файл robots.
 txt? Рекомендации по синтаксису Robot.txt
txt? Рекомендации по синтаксису Robot.txtЧто такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции по обходу указываются путем «запрета» или «разрешения» поведения определенных (или всех) пользовательских агентов.
User-agent: [имя user-agent]Disallow: [строка URL не сканируется]
Вместе эти две строки считаются полным файлом robots.txt — хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив агента пользователя отображается как отдельный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами агента пользователя каждое правило запрещает или разрешает Только применяется к агентам пользователя, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, сканер будет обращать внимание (и следовать указаниям) только на наиболее конкретные группа инструкций.
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots. txt. Все остальные пользовательские агенты будут следовать директивам в группе пользовательских агентов: *.
txt. Все остальные пользовательские агенты будут следовать директивам в группе пользовательских агентов: *.
Пример robots.txt:
Вот несколько примеров robots.txt в действии для сайта www.example.com:
URL-адрес файла robots.txt: www.example.com/robots.txt Блокировка всех поисковых роботов для всего контентаUser-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt означает, что все поисковые роботы не будут сканировать какие-либо страницы на www.example. com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контентуАгент пользователя: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам просканировать все страницы на www.example.com, включая главную страницу.
Блокировка определенного поискового робота из определенной папкиАгент пользователя: Googlebot Запретить: /example-subfolder/
Этот синтаксис указывает только сканеру Google (имя пользовательского агента Googlebot) не сканировать любые страницы, которые содержать строку URL www. example.com/example-subfolder/.
example.com/example-subfolder/.
Агент пользователя: Bingbot Запретить: /example-subfolder/blocked-page.html сканирование конкретной страницы по адресу www.example.com/example-subfolder/blocked-page.html.Как работает файл robots.txt?
Поисковые системы выполняют две основные функции:
- Просматривают веб-страницы в поисках контента;
- Индексация этого контента, чтобы его можно было предоставить тем, кто ищет информацию.
Для обхода сайтов поисковые системы следуют ссылкам, чтобы перейти с одного сайта на другой — в конечном счете, сканируя многие миллиарды ссылок и веб-сайтов. Такое поведение сканирования иногда называют «пауками».
После перехода на веб-сайт, но до его сканирования поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы.
Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другие необходимые сведения о файле robots.txt:
(более подробно обсуждается ниже)
Чтобы найти файл robots.txt, его необходимо поместить в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен иметь имя «robots.txt» (не Robots.txt, robots.TXT или другое).
Некоторые пользовательские агенты (роботы) могут игнорировать ваш файл robots.txt. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или скребки адресов электронной почты.

Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого сайта (если этот сайт имеет файл robots.txt!). Это означает, что любой может видеть, какие страницы вы сканируете или не хотите, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый поддомен в корневом домене использует отдельные файлы robots.txt. Это означает, что и у blog.example.com, и у example.com должны быть свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать местоположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
Идентификация критических предупреждений robots.txt с помощью Moz Pro
Функция сканирования сайта Moz Pro проверяет ваш сайт на наличие проблем и выделяет срочные ошибки, которые могут помешать вам появиться в Google. Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Начать мою бесплатную пробную версию
Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt . Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. Среди них:
Агент пользователя: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Запретить:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.

Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
Карта сайта: Используется для вызова местоположения любой карты сайта XML, связанной с этим URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно блокировать или разрешать, файлы robots.txt могут оказаться довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL-адресов. Google и Bing поддерживают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Этими двумя символами являются звездочка (*) и знак доллара ($).
- * — это подстановочный знак, представляющий любую последовательность символов.
- $ соответствует концу URL-адреса.
Куда идет файл robots.txt на сайте?
Всякий раз, когда они заходят на сайт, поисковые системы и другие поисковые роботы (например, поисковый робот Facebook, Facebot) знают, что нужно искать файл robots.txt. Но они будут искать этот файл только в одном конкретном месте : в основном каталоге (обычно это ваш корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует по адресу , скажем, example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots.

Чтобы ваш файл robots.txt был найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем вам robots.txt?
Файлы robots.txt контролируют доступ поисковых роботов к определенным областям вашего сайта. Хотя это может быть очень опасным, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение дублирования контента в поисковой выдаче (обратите внимание, что метароботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей инженерной группы)
- Предотвращение отображения страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексации поисковыми системами определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т.
 д.)
д.) - Указание задержки сканирования, чтобы предотвратить перегрузку ваших серверов, когда сканеры загружают несколько фрагментов контента одновременно
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, возможно, вам вообще не нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл robots Moz находится по адресу moz.com/robots.txt.
Если страница .txt не отображается, у вас в настоящее время нет (действующей) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создать его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов robots? В этом сообщении блога рассматриваются некоторые интерактивные примеры.

Лучшие практики SEO
Убедитесь, что вы не блокируете какой-либо контент или разделы вашего веб-сайта, которые вы хотите сканировать.
Ссылки на страницы, заблокированные robots.txt, не будут переходить. Это означает, что 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. е. страницы, не заблокированные через robots.txt, meta robots или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой вес ссылок не может быть передан с заблокированной страницы на место назначения ссылки. Если у вас есть страницы, на которые вы хотите передать право собственности, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.
 txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность сделать это позволяет вам точно настроить сканирование содержимого вашего сайта.
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день. Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить URL-адрес robots.txt в Google.
Robots.
 txt против мета-роботов против x-роботов
txt против мета-роботов против x-роботовТак много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это настоящий текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они на самом деле являются, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как meta и x-robots могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
- Мета-директивы роботов
- Канонизация
- Перенаправление
- Протокол исключения роботов
- Руководство для начинающих по SEO: как работают поисковые системы: сканирование, индексирование ing и Ranking
Примените свои навыки на практике
Moz Pro определяет, блокирует ли ваш файл robots.txt доступ поисковой системы к вашему веб-сайту. Попробуйте >>
Robots.txt и SEO: полное руководство
Что такое robots.
 txt?
txt?Robots.txt — это файл, указывающий поисковым роботам не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) распознают и выполняют запросы Robots.txt.
Почему файл robots.txt важен?
Большинству веб-сайтов не нужен файл robots.txt.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они НЕ будут автоматически индексировать страницы, которые не важны, или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотели бы использовать файл robots.txt.
Блокировать непубличные страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать. Например, у вас может быть промежуточная версия страницы. Или страница входа. Эти страницы должны существовать. Но вы же не хотите, чтобы на них попадали случайные люди. Это тот случай, когда вы должны использовать robots.
 txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.
txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.Максимальный краулинговый бюджет. Если вам трудно проиндексировать все ваши страницы, у вас может быть проблема с краулинговым бюджетом. Блокируя неважные страницы с помощью файла robots.txt, робот Googlebot может тратить больше вашего краулингового бюджета на страницы, которые действительно важны.
Предотвращение индексации ресурсов: Использование метадиректив может работать так же хорошо, как Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают с мультимедийными ресурсами, такими как PDF-файлы и изображения. Вот где в игру вступает robots.txt.
Суть? Robots.txt указывает поисковым роботам не сканировать определенные страницы вашего сайта.
Вы можете проверить, сколько страниц вы проиндексировали в Google Search Console.
Если число соответствует количеству страниц, которые вы хотите проиндексировать, вам не нужно возиться с файлом Robots.
 txt.
txt.Но если это число выше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не должны быть проиндексированы), то пришло время создать файл robots.txt для вашего веб-сайта.
Передовой опыт
Создание файла robots.txt
Первым делом необходимо создать файл robots.txt.
Будучи текстовым файлом, вы можете создать его с помощью блокнота Windows.
И неважно, как вы в конечном итоге сделаете свой файл robots.txt, формат будет точно таким же:
User-agent: X
Disallow: YUser-agent — это конкретный бот, с которым вы разговариваете.
И все, что идет после «запретить», — это страницы или разделы, которые вы хотите заблокировать.
Вот пример:
User-agent: googlebot
Disallow: /imagesЭто правило предписывает роботу Googlebot не индексировать папку изображений вашего веб-сайта.
Вы также можете использовать звездочку (*), чтобы обратиться ко всем без исключения ботам, которые заходят на ваш сайт.

Вот пример:
User-agent: *
Disallow: /images«*» указывает всем и каждому паукам НЕ сканировать вашу папку с изображениями.
Это лишь один из многих способов использования файла robots.txt. В этом полезном руководстве от Google содержится дополнительная информация о различных правилах, которые вы можете использовать, чтобы заблокировать или разрешить ботам сканировать разные страницы вашего сайта.
Сделайте так, чтобы файл robots.txt было легко найти
Когда у вас есть файл robots.txt, пришло время запустить его.
Технически вы можете поместить файл robots.txt в любой основной каталог вашего сайта.
Но чтобы повысить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https://example.com/robots.txt
(Обратите внимание, что ваш файл robots.txt чувствителен к регистру .Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка на ошибки и ошибки
ДЕЙСТВИТЕЛЬНО важно, чтобы ваш файл robots.
 txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.
txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Он показывает вам ваш файл robots.txt… и любые ошибки и предупреждения, которые он находит:
Как видите, мы блокируем пауков от сканирования нашей страницы администратора WP.
Мы также используем robots.txt, чтобы заблокировать сканирование страниц с автоматически сгенерированными тегами WordPress (для ограничения дублирования контента).
Robots.txt и мета-директивы
Зачем использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега «noindex»?
Как я упоминал ранее, тег noindex сложно применить к мультимедийным ресурсам, таким как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots.


Об авторе