Цпа сеть: Что такое CPA и как работают CPA-сети
Товарный бизнес через CPA-сеть: кейс рекламодателя — E-pepper.ru
Представьте, что ваш товарный бизнес больше не нуждается в решении таких вопросов, как продвижение товара в интернете или привлечение качественного трафика на сайт. Вы лишь отслеживаете подтвержденные заявки в CRM и отправляете заказы покупателям. Это вполне реально, если рекламодателю, который хочет продвигать свой продукт, сотрудничать с партнерской CPA-сетью. Татьяна Кулагина из компании M1-Shop на конкретном примере объясняет, почему такая схема упрощает работу ритейлера.
Как происходит продвижение товара?
Людей, которые готовы продвигать товар называют «веб-мастера». Они знают тонкости настройки рекламных кампаний на различных площадках и в социальных сетях. Товарный бизнесмен, который хочет реализовать свой продукт — «рекламодатель». Партнерская сеть — посредник, связывающий их между собой.
Схема работы:
- Рекламодатель регистрирует свой товар в партнерской сети, договариваясь о фиксированной выплате с каждого подтверждённого заказа.

- Партнерская сеть подключает веб-мастеров, которые будут приводить клиентов на сайт рекламодателя.
- Веб-мастер зарабатывает на разнице между затратами на трафик и выплатой партнёрской сети за каждый подтверждённый заказ.
- CPA-сеть получает процент от оборота веб-мастера.
- Рекламодатель получает средства с продажи своего товара.
Таким образом, рекламодатель может не погружаться тонкости интернет-рекламы и получать клиентов, оплачивая фиксированную стоимость только тех заказов, которые покупатель подтвердит по телефону.
Средний чек и выкуп
Для того чтобы рекламодателю было выгодно работать с CPA-сетью, в M1-shop есть собственный колл-центр, работающий над повышением процента подтвержденных заявок и среднего чека. Операторы не просто будут подтверждать заказы, а продавать дополнительные товары, увеличивая корзину вашего покупателя.
Результаты работы колл-центра М1-Shop:
Так как заработок партнерской сети напрямую зависит от заработка рекламодателя, вы можете воспользоваться рядом преимуществ, чтобы увеличить свой доход, а именно:
-
Бесплатный расчет экономики товара для привлечения максимальной прибыли
-
Поиск выгодного закупа
-
Бесплатная разработка промо под первый запущенный товар
-
Гарантия запланированного среднего чека
-
Бесплатное сопровождение клиента до выкупа на первые 100 заказов
Кейс рекламодателя М1-shop
Товар — средство для обновления древесины WoodClean
В феврале 2020-ого года, в еженедельной подборке новых идей от M1-Shop, нам поступило предложение рассмотреть оффер — средство для обновления древесины.
После поиска и монтажа подходящих промоматериалов, совместно с M1-Shop мы просчитали экономику и получили следующие показатели:
Далее мы нашли подходящее сырье для производства товара и приняли решение запускать товар на тест.
Первоначально оффер был запущен только для ограниченного количества веб-мастеров, для того чтобы протестировать конверсию и процент выкупов. Спустя 1 неделю на оффер пришло около 157 подтвержденных заказов (апрувов):
Через две недели мы стали получать первые выкупы, а количество апрувов увеличилось до 444:
После получения статистики выкупов убедились, что оффер соответствует заложенным при расчёте экономики показателям и открыли товар для всех веб-мастеров. Уже через несколько дней Woodclean попал в десятку самых востребованных товаров М1:
В период с 15. 02.20 — 22.06.20 на оффер пришло более 2150-ти заказов. Оффер держится в топе и привлекает к себе всё больше и больше внимания активных вебмастеров.
02.20 — 22.06.20 на оффер пришло более 2150-ти заказов. Оффер держится в топе и привлекает к себе всё больше и больше внимания активных вебмастеров.
Кому и когда лучше запускать оффер в партнерской сети
Не так важно, давно вы занимаетесь товарным бизнесом или же только начинаете свой путь, когда вы оставляете заявку, менеджер может вам помочь определиться с товаром, поиском закупа и расчетом всей экономики. Такая схема работы подойдет и компаниям, работающим с ограниченным ассортиментом специализированных товаров. В таком случае CPA-сеть поможет привлечь не только покупателей, но и потенциальный трафик, который можно будет реализовать при расширении ассортимента.
Если у вас остались вопросы, вы всегда можете задать их личному менеджеру в телеграм. А для всех наших читателей, которые назовут промокод
CPA-сети: что это такое и как на них зарабатывать
Реклама в Интернете отвоевывает все большую нишу в современном маркетинге, и главный ее инструмент – партнерские сети CPA.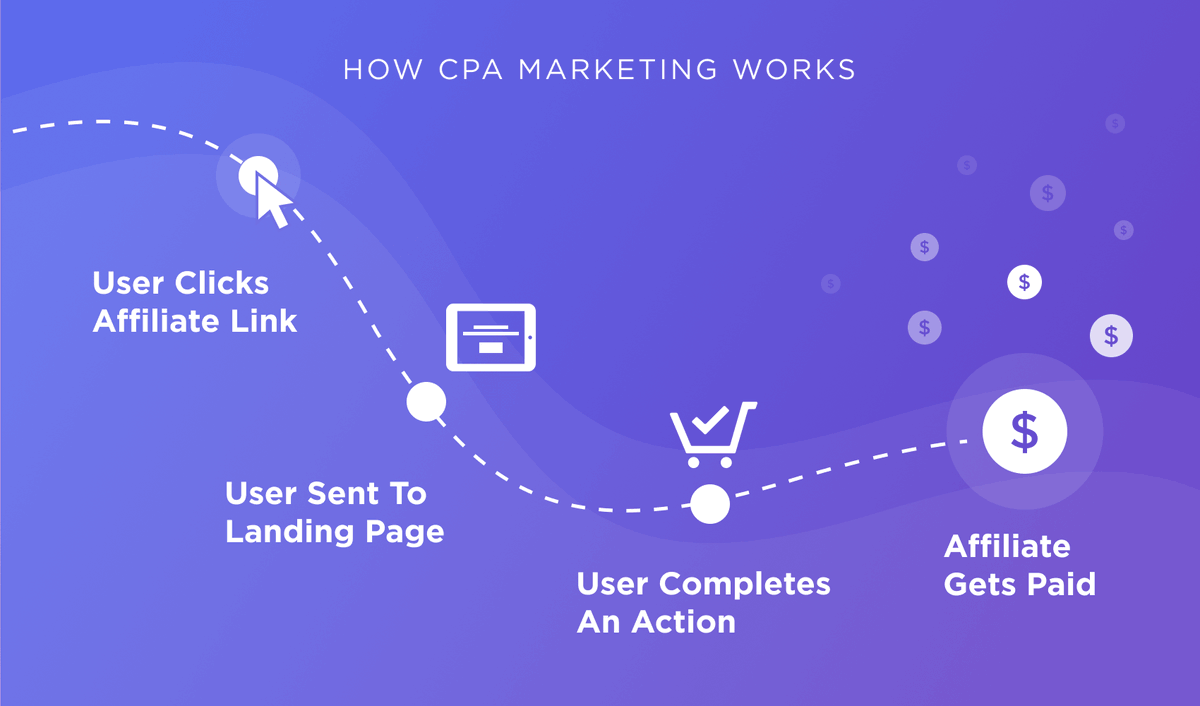 Это посредники, объединяющие рекламодателей и распространителей рекламы, называемых паблишерами.
Это посредники, объединяющие рекламодателей и распространителей рекламы, называемых паблишерами.
Партнерские программы не только помогают им найти друг друга и начать взаимовыгодное сотрудничество, но и выполняют другие важные функции. Предлагаем разобраться в этом вопросе подробнее.
Как работают CPA-партнерки
У начинающих веб-мастеров и осваивающихся в сети рекламодателей часто возникают вопросы: «CPA-сети – что это? В чем смысл системы Cost Per Action и почему она столь популярна?»
В основе системы лежит оплата за целевое действие, когда веб-мастер подводит потенциального клиента к его выполнению и рекламодатель видит результат, за который платит.
Посредник
Учетом и подсчетом выполненных действий, их переведением в денежный эквивалент и выдачей заработка паблишеру занимаются CPA-сети. Они же заключают бумажные договоры с рекламодателями, разрабатывают с ними условия партнерской кампании и несут ответственность за подбор веб-мастеров.
Заказчик
Сети дают профессиональные советы, но конечный вид оффера (объявления) зависит лишь от рекламодателя. В такое объявление входят все условия партнерства: тип действия, которое должен выполнить пользователь, временные ограничения, запреты по типу или географии трафика, позволенные рекламные методики, партнерская ссылка для слива трафика и, конечно, сумма вознаграждения.
Исполнитель
Веб-мастер, в свою очередь, волен выбирать между несколькими способами реализации кампании или совмещать их. К примеру, можно использовать арбитраж трафика. Работая по этой схеме, нужно купить размещение баннера или реферальной ссылки в поисковиках или соцсетях. Арбитраж подразумевает затраты, но надежно поставляет таргетированный трафик, и при правильном подходе прибыль значимо превышает потери.
Некоторые специалисты выбирают в качестве инструмента email-рассылку, используя тщательно подобранные базы клиентов и сервисы вроде Campaign Monitor, MailChimp, Печкин-mail. Однако в этом направлении есть большая угроза уподобиться спаму, а это противоречит принципам CPA, хоть и развито в его теневом сегменте.
Однако в этом направлении есть большая угроза уподобиться спаму, а это противоречит принципам CPA, хоть и развито в его теневом сегменте.
Популярны среди CPA-специалистов и социальные сети. Обладая хорошими навыками SMM-менеджера и располагая несколькими крупными группами или популярными страницами, с их помощью можно получать рекордное количество трафика.
Ну и основа всей CPA-парнерки – получение трафика от собственных сайтов. Такой способ предполагает большие вложения времени и наличие специфических навыков вроде SEO, но отличается своей стабильностью. В теневом сегменте подобным целям служат дорвеи, но низкокачественный контент на временных площадках не одобряют ни поисковики, ни клиенты, его сторонится и большинство рекламодателей.
В том, как работают CPA-партнерки, несложно разобраться, но сделать это проще уже в процессе сотрудничества.
Специфика CPA-партнерства
Говоря о секретах прибыльной работы с CPA-партнерками следует отметить, что непрозрачные договорные отношения, царящие в этом сегменте рынка, сильно влияют на выгодность кампаний как для исполнителя, так и для заказчика.
Хорошему переговорщику удастся заключить оффер на максимально выгодных для него условиях. Рекламодателю стоит в подробностях расписать все условия и ограничения, а также внимательно проверять качество трафика.
Несколько парадоксально, но начинающему веб-мастеру как раз следует избегать слишком детализированных офферов. Чем проще поставлена задача, тем легче будет соблюсти все условия. Выбирайте продукты и услуги, только будучи уверенными в том, что сможете заинтересовать ими свою аудиторию.
Примеры CPA-сетей:
- KissMyAds;
- Shakes;
- Admitad;
- Leads.Black;
- GdeSlon и др.
Партнерство – эффективный способ продвижения продукта в сети, однако CPA-маркетинг не завершается лишь на нем. Читайте на нашем портале и о других аффилированных методиках.
Подписывайтесь на новости RACE в Facebook и VK!
Между рекламодателем и веб-мастером: что такое CPA-сети и как они работают
Поговорили с представителями крупных CPA-сетей, работающих на украинском рынке, о том, в каких нишах они работают и с какими рекламодателями сотрудничают.
Также обсудили активности, которые CPA-сети организовывают для веб-мастеров, и какие отраслевые мероприятия они посещают. Эксперты поделились трендами affiliate-маркетинга, которые они наблюдают в Украине.
Отвечают Александр Бойко, Head of CPA в Finline.ua, Александр Кривошеев, Country Manager Ukraine в Admitad, Эдуард Бутенин, Ukraine Сountry Manager в LeadGid, Владимир Сахаров, Co-Founder в SalesDoubler, и Константин Николов, CEO SellAction.
Marketing Media Review
Печатное издание MMR — лучший офлайн-канал украинского маркетолога. Обновленный сайт MMR.ua — быстрорастущий проект с исключительной аудиторией профессионалов
Александр Бойко
Руководитель Finline
CPA-сеть соединяет интересы рекламодателя (продавца услуг / продуктов) и веб-мастеров (площадки / витрины / сайты, где рекламируются услуги / продукты для конечных клиентов). Рекламодатель через посредников (веб-мастеров) получает клиентов, веб-мастер зарабатывает комиссию за привлеченных клиентов.
СРА-сеть контролирует качество и количество трафика для рекламодателей, дает ассортимент продуктов / услуг, статистику веб-мастерам, а также ведет взаиморасчеты. Веб-мастер в СРА-сети видит все предложения от всех рекламодателей со статистикой, выбирает, с кем работать, а деньги получает агрегировано от СРА-сети. Аналогично рекламодатель платит одной СРА-сети за продажи всех веб-мастеров и не сопровождает технические и финансовые процессы.
Удобство таких сетей в том, что веб-мастерам не приходится самостоятельно выискивать рекламодателей, заключать договора со всеми компаниями и следить за статистикой. Работая через CPA-сети, веб-мастер сокращает свои операционные затраты и понимает по статистике, какие предложения выбрать.
Самое интересное, что рекламодатель платит за рекламу только тогда, когда заявленное целевое действие (например, покупка, регистрация на сайте, установка приложения и т.д.) уже совершено. За счет этого легче прогнозировать затраты на маркетинг и правильно планировать бюджет. Подключаясь к CPA-сети, рекламодатель получает доступ к более чем 600 тыс. веб-мастеров, а это те же маркетологи, блогеры, специалисты по SEO-продвижению, контекстной и таргетированной рекламе.
Подключаясь к CPA-сети, рекламодатель получает доступ к более чем 600 тыс. веб-мастеров, а это те же маркетологи, блогеры, специалисты по SEO-продвижению, контекстной и таргетированной рекламе.
Affiliate-сеть можно назвать платформой, на которой собираются специалисты по интернет-маркетингу, которые работают на себя.
При этом они сами предлагают рекламодателю свои услуги на его условиях.Модель оплаты CPA — это вершина эволюции digital advertising. Главная ее ценность в том, что сеть дает рекламодателям возможность использовать площадки и форматы, недоступные в стандартных каналах. Волшебство в том, что самостоятельно CPA-сеть не генерирует трафик. Для этого мы сотрудничаем с тысячами веб-мастеров, которые являются владельцами сайтов, групп в соцсетях, Youtube-каналов или умеют круто настраивать различные виды интернет-рекламы для рекламодателей, которые готовы платить деньги за целевое действие на своем web-ресурсе.
Наша задача — обеспечить корректный учет статистики, бесперебойную систему коммуникации, выплат и обязательств обеих сторон.
СPA-сеть — это уникальный B2B продукт, который забирает на себя самые муторные, съедающие время и нервы процессы, такие как подбор продукта для своей площадки, выплаты, урегулирование рабочих и иногда конфликтных ситуаций как на стороне рекламодателя, так и на стороне веб-мастера.
В настоящее время, как по технологиям, так и по содержанию — это мощный инструмент, с помощью которого можно реализовать программу лояльности для клиентов, привлечь трафик из новых источников, повысить средний чек, снизить количество невыкупленных заказов и многое другое. Я бы отнес его к must have решению множества задач маркетинга для бизнеса в интернете.
Ниши Admitad —e-commerce, финансы, мобайл, онлайн-сервисы, travel.
У Admitad более 1 600 рекламодателей и 596 900 веб-мастеров.
С Admitad работают Karabas, Moyo, Сhicco, Stylus, Intertop,
 com, Цитрус, AliExpress, Radisson Blu, Gold.ua, Альфа-банк,
com, Цитрус, AliExpress, Radisson Blu, Gold.ua, Альфа-банк,Monobank, Dinero и
другие крупные компании.
Владимир Сахаров
Co-Founder в SalesDoubler
На данный момент SalesDoubler работает в трех перспективных направлениях:
1. PDL (pay day loans) — микрокредитирование, в этом направлении мы безусловный лидер в Украине. Используя накопленный опыт, мы врываемся в международный рынок, где наши веб-мастера успешно занимаются генерацией трафика.
2. Travel — активно развивающаяся вертикаль, приоритетная в последние несколько лет.
Представлены как локальные рекламодатели из Украины и СНГ, так и всемирно известные travel-бренды.
3. FMCG — это та ниша, где мы сотрудничаем с компаниями мирового уровня.
Сотрудничаем с сотнями рекламодателей, с которыми работают тысячи вебмастеров.
В вертикали PDL наши клиенты — MyCredit, Moneyveo, Dinero. Международные офферы пока держим в секрете (ждем скорейший анонс), в FMCG — это McDonalds, Lay’s, Nestlé, Новая Почта, а в категории Travel — FlixBus, Skyscanner, Etihad, Qatar и другие авиакомпании.

SellAction работает с интернет-магазинами, сервисными компаниями, финансовым сектором, играми.
Активных рекламодателей на данный момент 250, веб-мастеров уже более 28 000.
Среди наших рекламодателей — Rozetka.ua, AliExpress, Lamoda, Fotos (F.ua), Wargaming, Nestle, Intertop и многие другие.
Leadgid сконцентрирована на работе с банками, МФО и продуктами, близкими к данной сфере, по всему миру. Через нас проходит 700 000 лидов в день.
Всего в LeadGid порядка 1500 вебмастеров и 500
рекламодателей. Если брать во внимание только Украину, на данный момент мы
работаем более чем с 50 крупнейшими рекламодателями Украины в сфере
кредитования и более 100 активными веб-мастерами, которые предоставляют один из
лучших по качеству трафик в стране.
Среди наших партнеров Альфа-банк, Monobank, Dinero, Moneyveo, Ccloan, Miloan, CreditPlus, Mycredit.
Компания Finline.ua относится к узкопрофильным CPA-сетям. Мы специализируемся на финансовых офферах (предложениях от рекламодателей) — кредиты наличными, кредитные карты, микрокредиты на карту онлайн, депозиты для физических лиц.
Мы больше 8 лет сотрудничаем с ведущими финансовыми учреждениями Украины. Нашими партнерами являются более 80 финансовых организаций и 500 веб-мастеров.
С нами сотрудничают лидеры финансового рынка Украины, такие как ПриватБанк, Альфа-банк, Moneyveo, ПУМБ, Dinero.
Третий год подряд мы проводим конференцию по партнерскому маркетингу в финансовой сфере FinAdTech в разных локациях. В этом году впервые провели FinAdTech в Киеве. Нас посетило 200 человек (в несколько раз больше, чем мы планировали изначально). FinAdTech 2020 также пройдет в Киеве весной следующего года.
Благодаря вебинарам мы предлагаем веб-мастерам познакомиться с тенденциями рынка. К примеру, прошлый был посвящен юридическим вопросам. А для стимуляции веб-мастеров у нас регулярно проходят конкурсы совместно с рекламодателями с крупным призовым фондом.
Ежегодно Admitad совместно с рекламодателями проводит два финансовых марафона: летний – MoneyRun и зимний. Кроме того, мы регулярно проводим конкурсы и акции для веб-мастеров, как самостоятельно, так и в сотрудничестве с рекламодателями.![]()
У нас активно работает Admitad Academy, в которой мы обучаем веб-мастеров тонкостям affiliate-маркетинга, работе с новыми каналами трафика и вдохновляем их пробовать свои силы в новых нишах.
Мы постоянно обучаем наших веб-мастеров, помогаем разобраться в новых нишах, проводим для них встречи, семинары. Каждый год мы проводим игры и акции для веб-мастеров, стимулируем тестирование новых офферов и, конечно же, развлекаем и даем возможность больше заработать. Обычно такие акции спонсируются 50/50 СРА-сетью и рекламодателями, но инициатором чаще всего является СРА-сеть.
Мы формируем базу обучающих материалов, надеемся опубликовать всё до конца года. Данный шаг позволит как начинающим, так и уже гуру партнерского маркетинга повысить квалификацию и увеличить свои доходы.
С партнерами, которые работают с нами уже сейчас, мы регулярно проводим встречи, поддерживаем диалог, решаем множество проблем, помогаем оптимизировать бизнес-процессы, договариваемся об улучшении условий и промо-акциях, формируем рекомендации и многое другое. Иногда помогаем с привлечением инвестиций через партнеров для развития и роста качественных проектов.
Иногда помогаем с привлечением инвестиций через партнеров для развития и роста качественных проектов.
Основная активность — это качественный, всеохватывающий отдел поддержки. Наши affiliate-менеджеры буквально 24/7 готовы помочь веб-мастерам. Также мы регулярно посещаем конференции в качестве спонсоров и спикеров, создаем мануалы по старту для новичков, организовываем совместные неформальные мероприятия.
С 2017 года в Киеве проходит Admitad Expert – конференция, посвященная развитию affiliate-маркетинга, на которой собирается более 400 топовых веб-мастеров и ведущих рекламодателей. В этом году конференция Admitad Expert состоится 18 октября.
В 2019 году мы впервые организовали международную СРА-тусовку Admitad BBQ Party. Дважды в год проводим тематические бизнес-завтраки, посвященные нишам e-commerce и финансы.
Кроме того, мы – активные участники таких нишевых конференций, как CPAconf, 8P, MAC и др.
Конечно, от нашей сети, на многие мероприятия в сфере маркетинга и рекламы ездят наши представители.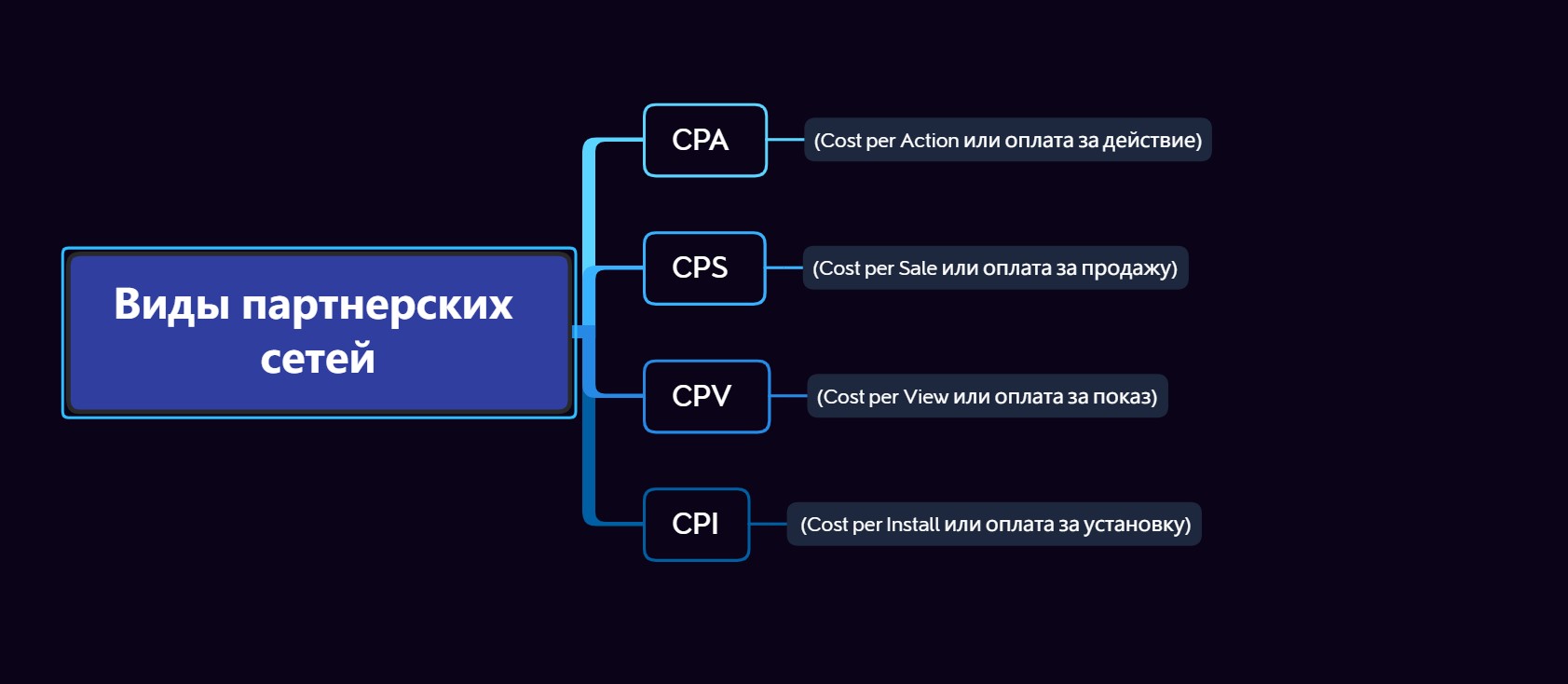 Последнее, что мы посетили, была конференция 8Р в Одессе.
Последнее, что мы посетили, была конференция 8Р в Одессе.
Финансовый рынок, как и рынок IT, не стоит на месте. Чтобы быть в тренде, необходимо постоянно развиваться и следить за инновациями. Мы регулярно посещаем как тематические конференции для банков и финансовых компаний, так и конференции по интернет=маркетингу и ивенты для веб-мастеров: BankOnline, SEMPRO, CPAConf, 8P.
Мы очень ценим и любим качественный нетворкинг, поэтому такие мероприятия, как MAC, 8P, Dvoma, SemPro, FutureLab и другие — отличная возможность не только быть в курсе всех событий в affiliate-маркетинге, но и продвигать собственный бренд, коммуницировать с нашими партнерами в подходящей обстановке.
Мы стараемся посещать все конференции, на которых затрагивается сфера нашей деятельности. Это отличный повод пообщаться с рекламодателями и веб-мастерами в более близкой обстановке и обсудить актуальные, свежие вопросы и тенденции. В этом году мы как гости или спонсоры посетили как масштабные события, например, SEMPRO, так и более камерные, как, например, ITNP. И, конечно, мы посетили NutraTech — митап партнерской сети Webvork.
И, конечно, мы посетили NutraTech — митап партнерской сети Webvork.
Affiliate-маркетинг только набирает обороты в нашей стране. Привлечение клиентов в интернете — это второй по величине канал для массового сегмента после TV, который привлекает многих легкостью входа — ваш бюджет может быть от 20 000 грн. В Украине все больше молодых людей рассматривают affiliate-маркетинг как основной вид дохода, это связано с возможностью зарабатывать деньги в любой точке мира, не выходя из дома.
Основные тренды в affiliate-маркетинге:
1. Сквозная аналитика — трафик — продажа онлайн. Мы интегрированы по API с банками и микрофинансовыми компаниями и получаем статистику от них онлайн.
2. Технологичность — новые сервисы, процессы для клиентов и веб-мастеров. К примеру, мы даем веб-мастерам frame, который легко интегрировать в сайт, и он автоматически подбирает кредиторов под профиль клиента в онлайн.
3. Использование SMS, IVR, push-уведомений, чат-ботов для максимальной монетизации трафика. Веб-мастерам мы подключаем опции домонетизации по модели revenue share.
Веб-мастерам мы подключаем опции домонетизации по модели revenue share.
Ниша активно растет, конкуренция тоже. Некоторые рекламодатели запускают собственные партнерские программы, но большинство веб-мастеров выбирают работу через СРА-сети за удобство, крутой уровень поддержки, экспертизу и технологические инструменты. Веб-мастера постоянно находят новые нестандартные источники, бизнес-модели и технологии генерации трафика. Все больше веб-мастеров из одиночек вырастают в команды и полноценные, часто достаточно крупные, бизнесы.
Основа рынка — МФО, они более мобильны в плане продвижения своего продукта и более активно рассматривают позитивные изменения как для веб-мастера, так и для непосредственно конечного клиента. Но это не значит, что банковские продукты работают хуже, у них просто другой подход. Мы всячески пытаемся привнести опыт работы в других гео на наш рынок. С этим бывают трудности, потому как глобально меняться всегда трудно и страшно, но постепенная и продуктивная работа в данном направлении дает свои результаты.
Рынок affiliate в Украине как раз находится в стадии становления и формирования. Есть ощутимая необходимость в стимулировании роста веб-мастеров, появлении, создании новых площадок. Если раньше, чтобы заработать в партнерской сети, нужно было делать какой-то сайт, разбираться с множеством нюансов, то сейчас есть варианты, как это можно сделать быстрее и в разы проще. Например, обратиться к актуальным трендам генерации трафика: Telegram-каналы, YouTube и Instagram.
Могу выделить такие тренды:
1. Увеличение мобильного трафика и объемов продаж через mobile благодаря запуску в стране технологий 3G и 4G.
2. Рост популярности видеоконтента, который активно используется для привлечения трафика рекламодателями и веб-мастерами.
3. Развитие новых каналов трафика: мессенджеры, онлайн-трансляции, модель СРА-offline, SMS, YouTube, Instagram, сарафанное радио, терминалы и голосовой поиск.
Говоря о перспективах роста affiliate-маркетинга в Украине, стоит отметить два направления: e-commerce и финансы.
CPA-сеть: кому подходит такая раскрутка
Что такое CPA-партнерка
CPA — это партнерская сеть, чья цель — генерация трафика на определенные интернет-ресурсы. Но трафик здесь — не главное. Отличие CPA-сетей от привычной баннерной рекламы в интернете в том, что вы платите не за размещение рекламы или ее показ и не за переходы. Нет, вы оплачиваете результат — необходимое действие пользователя, который зашел на сайт. Как вы понимаете, это намного выгоднее, чем просто “сливать” бюджет в бесконечную прокрутку рекламных объявлений, которые не всегда несут результат.
Предметом оплаты может быть что угодно из следующего списка:
- покупка товара или заказ услуги,
- подписка на рассылку с сайта,
- заполнение формы,
- предоставление своих контактных данных для дальнейшей консультации и многое другое.
Как видите, сотрудничество с CPA-сетью выгодно тем, кому нужно не просто раскрутить, но и монетизировать свой интернет-ресурс. Давайте разберемся подробнее, какому бизнесу это может быть полезным.
Давайте разберемся подробнее, какому бизнесу это может быть полезным.
Кому выгодно сотрудничество с CPA
В соответствии со спецификой CPA-сетей, такой формат привлечения посетителей выгоден, если есть конкретный показатель выгодности рекламы. Так, если у вас информационный портал и нужны просмотры — дешевле купить рекламу, которая будет создавать трафик из подходящей целевой аудитории. В то же время, вы можете сотрудничать с CPA-сетью в качестве поставщика трафика и заработать на этом.
Что же касается рекламы через CPA-сеть — то это отличный вариант в таких случаях:
- Интернет-магазины, которые могут оценивать эффективность CPA в сделанных после перехода покупках.
- Сайты, предлагающие услуги — в том случае, если на посадочной странице можно сразу записаться на необходимую услугу или оплатить ее. Отличный вариант для парикмахерских, косметологических услуг, массажных салонов и т.д.
- Лендинги — их цель напрямую сведена к совершению покупки, а раскрутка органическими методами невозможна.

- Мобильные приложения — в этом случае оплата происходит за скачивания и установку.
- HR-компании — в качестве показателя выступят отклики на вакансию или заполненные формы.
- Компании, занимающиеся опросами и исследованиями мнений или собирающие базы данных потенциальных клиентов — тут оплата происходит за количество оставленных ответов или контактных данных.
Как видите, CPA сети — надежный способ привлечь трафик на сайт. Более того: вы будете уверены, что за трафиком стоят живые посетители, они входят в целевую аудиторию и принесут вам свои деньги или нужные данные.
На правах рекламыНашли ошибку в тексте? Выделите ее и нажмите Ctrl + Enter
Оценка текста
читайте также
CPA-сеть «Где Слон?» запустила программу лояльности на рынке партнерского маркетинга
Проект «Тонна» разрабатывался больше полугода на базе Kokoc Group — группы маркетинговых компаний, к которой относится CPA-сеть. Благодаря программе лояльности клиенты сети могут накапливать баллы и тратить их на развитие своего бизнеса. Стать участником программы может любая компания, которая запустила оффер в «Где Слон?», или вебмастер, который приводит трафик на любой из офферов рекламодателей сети. «Тонна» реализована в личном кабинете сети «Где Слон?» и предполагает ежемесячное автоматическое начисление бонусов в зависимости от суммы счетов рекламодателя или подтвержденного оборота вебмастера по итогам месяца. Чем больше счета или больше оборот в системе, тем больше возможностей для развития.
Благодаря программе лояльности клиенты сети могут накапливать баллы и тратить их на развитие своего бизнеса. Стать участником программы может любая компания, которая запустила оффер в «Где Слон?», или вебмастер, который приводит трафик на любой из офферов рекламодателей сети. «Тонна» реализована в личном кабинете сети «Где Слон?» и предполагает ежемесячное автоматическое начисление бонусов в зависимости от суммы счетов рекламодателя или подтвержденного оборота вебмастера по итогам месяца. Чем больше счета или больше оборот в системе, тем больше возможностей для развития. Еще один способ получения бонусных баллов — выполнение заданий от партнерки. Например, можно порекомендовать нового рекламодателя или посоветовать соискателя. Накопленные бонусы предлагается потратить на услуги продвижения бизнеса: SEO, SMM, performance-маркетинг, видеопроизводство, создание сайтов, аналитику и др. Исполнители услуг, агентства и сервисы, которые так же, как и «Где Слон?», входят в Kokoc Group, и дружественные группе рекламные компании. В дальнейшем каталог будет пополняться другими услугами, востребованные бизнесом.
В дальнейшем каталог будет пополняться другими услугами, востребованные бизнесом.
Даниил Сильвестров, CEO «Где Слон?»: «Мы считаем, что такое взаимовыгодное сотрудничество позволит взглянуть на понятие “партнерский маркетинг” по-другому. И понятие СРА у себя в компании мы расшифровываем иначе: Cost Per Attention — вот и вся суть. Внимание = энергия, а когда энергия направлена на партнерство, выигрывают все участники. Это и есть настоящий партнерский маркетинг».
Внимание = энергия, а когда энергия направлена на партнерство, выигрывают все участники. Это и есть настоящий партнерский маркетинг».
CPA-сети – что это? Плюсы трафика от CPA-рекламы для бизнеса
В наше время, работая в интернете, при абсолютно небольших усилиях можно зарабатывать приличные деньги. Одним из таких самых популярных видов заработка является работа с CPA сетями. Впрочем, как и для любой специальности, работа с такими сетями требует некоторых знаний.
Понятие CPA-сети
CPA – это аббревиатура от английского «Cost Per Action» (переводится как «оплата за действие»).
CPA-сети или, как чаще их называют, сети с предусмотренной оплатой за выполненное действие – это системы, выступающие в качестве посредника при использовании рекламы, предлагающие производить оплату только за назначенное действие пользователя. Иными словами, CPA-сеть выступает в виде посредника между рекламодателем и владельцем сайта. Можно сказать, что CPA – это плата за конкретное действие: покупка, регистрация, подписка, заполнение различных анкет. Стоит отметить, что CPA-бизнес основывается на партнёрских отношениях.
Можно сказать, что CPA – это плата за конкретное действие: покупка, регистрация, подписка, заполнение различных анкет. Стоит отметить, что CPA-бизнес основывается на партнёрских отношениях.
Часто встречается такая аббревиатура, как PPA. Однако, и в том, и в другом случае, CPA и PPA – это плата за действие.
В ЧЁМ ЗАКЛЮЧАЕТСЯ СУТЬ РАБОТЫ С CPA-СЕТЯМИ?
Чтобы получить первые дивиденды от работы с этими сетями, прежде всего, вам нужно найти сеть-партнёра и зарегистрироваться в ней. После того, как вы станете участником CPA-сети, вам откроется доступ к полному списку предложений о сотрудничестве. Это так называемые офферы.
При выборе потенциального партнёра из такого списка, вам будет необходимо получить индивидуальную ссылку на сайт рекламодателя или исполнителя. Через такую реферальную ссылку будет проходить учёт статистики прямых переходов и учитываться трафик CPA. Именно по этой ссылке в будущем заинтересованные пользователи будут переходить на продвигаемый ресурс. Важно учитывать тот факт, что такая ссылка должна быть размещена на сайте с регулярной аудиторией, которой будет интересен данный контент и которая в будущем перерастёт в потенциальных покупателей.
Важно учитывать тот факт, что такая ссылка должна быть размещена на сайте с регулярной аудиторией, которой будет интересен данный контент и которая в будущем перерастёт в потенциальных покупателей.
Вне зависимости от того, имеете ли вы собственный сайт или только собираетесь его создать под конкретного выбранного рекламодателя, полученная вами ссылка должна быть размещена на одном из самых видных мест. Также не забывайте, если вы намерены разработать интернет-страницу с нуля, вам потребуется некоторое время и средства для обретения популярности среди пользователей.
СУЩЕСТВУЮТ 2 ВИДА ОПЛАТЫ ТРАФИКА CPA РЕКЛАМОДАТЕЛЕМ:
- по количеству переходов уникальных посетителей по реферальной ссылке;
- по количеству совершённых покупок.
- CPA-сеть – занимается привлечением рекламодателей и подбором рекламы;
- рекламодатель – назначает определённое действие, вид оплаты, а также цену за выполненную работу;
- паблишер – занимается выбором оффера, настройкой сайта под требования работодателя и обеспечивает бесперебойный поток потенциальных клиентов на сайт рекламодателя.
КАЖДАЯ ИЗ СТОРОН CPA-БИЗНЕСА ВЫПОЛНЯЕТ СВОИ ОПРЕДЕЛЕННЫЕ ФУНКЦИИ
Собственно, в этом и заключаются базовые правила, на основании которых работают CPA-сайты.
ПОНЯТИЕ CPA-ПАРТНЁРКИ
Часто на просторах интернета можно встретить такое понятие как партнёрка. Работа с рассмотренными сетями – не исключение. Под этим понятием подразумевается партнёрская работа, при которой рекламодатель увеличивает свои продажи, а сайт-посредник даёт возможность дополнительного заработка для владельца ресурса.
Если верить статистике, маркетинг CPA-сетей даёт возможность включить в одну такую сеть сотни программ партнёров разных магазинов с абсолютно разными направлениями и товарами. Иными словами, хозяину сайта не нужно заниматься постоянным поиском рекламодателя, так как этой функцией занимается сеть.
Кроме всего прочего, при регистрации вы указываете один определённый счёт, на котором в течение всего времени партнёрства будет концентрироваться оплата вашей работы. То есть, если вы работаете сразу с несколькими партнёрами, нет необходимости предоставлять счёт разным рекламодателям, они всегда видят его и совершают оплату за размещение рекламы или совершённые действия на такой единый счёт.
КАК МОЖНО ПРИВЛЕКАТЬ CPA-ТРАФИК?
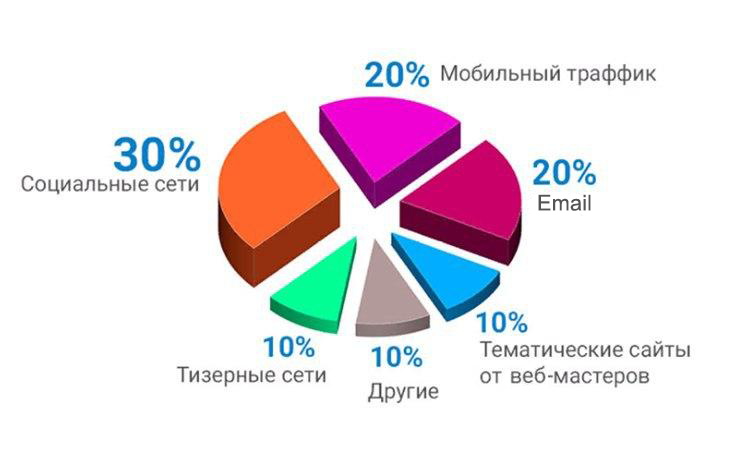
При работе с предложениями о сотрудничестве, не стоит забывать о существующих ограничениях, которые, в основном, касаются трафика сайтов-партнёров. Разрешается привлечение уникальных посетителей с помощью таких публикаций:
- контекстная, тизерная и баннерная реклама;
- пользователи соцсетей;
- пользователи поисковых систем;
К запрещённым видам рекламы с целью привлечения CPA-трафика относятся:
- замотивированные пользователи;
- рассылка через электронную почту;
- всплывающие окна на веб-страницах.
CPA-БИЗНЕС: ПЛЮСЫ И МИНУСЫ
К безусловным плюсам cost per action для рекламодателей стоит отнести:
- Фиксированную стоимость на рекламу, что полностью упрощает работу при планировании маркетинговых целей;
- Существенное упрощение поиска тематических рекламных площадок и отсутствие потребности в договорах;
- Отсутствие необходимости оплаты каждому владельцу сайта по отдельности;
- Низкая цена конверсионности CPA-сетей по отношению к контекстной рекламе или SEO.

Для обладателей сайтов, блогов и групп в социальных сетях:
- Возможность работы с несколькими предложениями в соответствии с тематикой;
- Широкие возможности для дополнительного заработка, ввиду большей выгодности CPA-партнёрки перед рекламой на сайтах-поисковиках.
Однако, в любой работе существуют минусы как для рекламодателя, так и для сайтов-партнёров.
Для рекламодателей:
- Владельцам небольших компаний крайне сложно найти для себя выгодного партнёра, так как для сетей наибольший интерес представляют рекламодатели, которые стабильно и много платят;
- Существенная конкуренция среди рекламодателей, из-за которой приходится регулярно поднимать выплаты;
- Существование недобросовестных партнёров, которые при помощи мошеннических действий приводят незаинтересованных клиентов, соответственно конверсия от такого трафика практически нулевая;
Для владельцев:
- Договорные отношения между заказчиком и исполнителем далеки от прозрачности и гарантий качества работы и оплаты;
- Слабая работа некоторых CPA-сетей ввиду постоянных перебоев с выплатами и проблем с коммуникациями.

В качестве вывода стоит сказать, что отлаженная работа CPA для бизнеса – это возможность получить максимальный эффект от рекламы при минимальных вложениях. Вы оплачиваете не количество показов или кликов на переход, а конкретное действие, а значит, можете для себя точно рассчитать маркетинговый бюджет.
CPA-сеть «Где Слон?» запустила бонусную программу для продвижения в диджитал
CPA-сеть «Где Слон?» запустила уникальную для рынка партнерского маркетинга программу лояльности. Проект «Тонна» более полугода разрабатывался на базе группы маркетинговых компаний Kokoc Group . Благодаря ему клиенты сети могут накапливать баллы и тратить их на развитие своего бизнеса.
Стать участником программы может любая компания, запустившая оффер в «Где Слон?», или вебмастер, который приводит трафик на любой из офферов рекламодателей сети. «Тонна» реализована в личном кабинете CPA-сети и предполагает ежемесячное автоматическое начисление бонусов в зависимости от суммы счетов рекламодателя или подтвержденного оборота вебмастера по итогам месяца. Чем больше счета или оборот в системе, тем масштабнее возможности для развития.
Чем больше счета или оборот в системе, тем масштабнее возможности для развития.
Александр Шокуров, управляющий партнер Kokoc Group:
Ничего похожего на «Тонну» на рынке CPA-сетей мы не видели, в России точно. Одна из причин — невозможно предложить такое разнообразие маркетинговых услуг, не будучи интегрированным в развитую экосистему. «Где Слон?» уже пять лет является частью Kokoc Group, поэтому база для такого интересного предложения есть. Удалось собрать большой каталог самых разных эффективных инструментов для продвижения бизнеса. Причем в составлении принимали участие не только бренды группы компаний, но и другие агентства, наши партнеры по Kokoc Clan. Планируем включать в программу лояльности еще больше их услуг.
Еще один способ получения бонусных баллов — выполнение заданий от «партнерки». Например, можно порекомендовать нового рекламодателя или посоветовать соискателя. Накопленные бонусы предлагается потратить на услуги продвижения бизнеса: SEO, SMM, performance-маркетинг, видеопроизводство, создание сайтов и аналитику. Исполнители услуг — агентства и сервисы, которые так же, как и «Где Слон?», входят в Kokoc Group, а также дружественные группе рекламные компании. В компании отмечают, что в дальнейшем каталог будет пополняться другими сервисами, востребованными бизнесом.
Даниил Сильвестров, CEO «Где Слон?»:
Мы считаем, что такое взаимовыгодное сотрудничество позволит взглянуть на понятие «партнерский маркетинг» по-другому. И понятие СРА у себя в компании мы расшифровываем иначе, чем его традиционно понимают: Cost per attention — вот и вся суть. Внимание приравнивается энергии, а когда энергия направлена на партнерство, выигрывают все участники. Это и есть настоящий партнерский маркетинг.
В состав Kokoc Group входят 30 агентств и сервисов, работающих в области интернет-маркетинга. «Где Слон?» — одна из крупнейших партнерских сетей в России, соединяющая рекламодателей и вебмастеров. Платформа предоставляет интернет-магазинам, туристическим площадкам и онлайн-сервисам возможность проводить рекламные кампании в интернете с оплатой за конкретные действия.
Основы сетевых процессоров
Сетевая «сантехника», такая как маршрутизаторы и коммутаторы, предъявляет необычные требования к процессорам; отсюда и рост числа сетевых процессоров. Вот снимок современного состояния NPU, в котором рассказывается, что делает сетевой процессор и какие функции могут стать наиболее популярными.
Сетевые процессоры прошли путь от преувеличенных предвестников сетевого мира до игнорируемой и умирающей технологии и превратились в прочный и процветающий бизнес.По мере того, как восстановление связи продолжается быстрыми темпами, сетевые процессоры нашли место в качестве важного инструмента для любого проектировщика сетевого оборудования. В связи с ростом объемов поставок и дизайна, сейчас самое время взглянуть на этот новый тип процессоров. Сетевые процессоры из преувеличенных предвестников сетевого мира превратились в игнорируемую и умирающую технологию, в прочный и процветающий бизнес.
Что такое сетевой процессор?
Проще говоря, сетевой процессор — это программируемый микропроцессор, оптимизированный для обработки сетевых пакетов данных.В частности, он предназначен для обработки задач, обычно связанных с верхними уровнями семислойной сетевой модели OSI, показанной в таблице 1: синтаксический анализ заголовка, сопоставление с образцом, манипуляции с битовыми полями, поиск в таблицах, модификация пакетов и перемещение данных. Будет доступно множество независимых пакетов, обеспечивающих возможности для параллельной обработки. Скорость передачи данных для сетевых процессоров варьируется от 1,2 Гбит / с (двойная скорость передачи данных OC-12) до 40 Гбит / с.
Таблица 1: Уровни OSI и TCP / IP
| Уровень OSI | Имя слоя | Общие протоколы |
| Слой 7 | Приложение | HTTP, SMTP, FTP |
| Слой 6 | Презентация | Нет |
| Слой 5 | Сессия | SSL, iSCSI |
| Слой 4 | Транспорт | TCP, UDP |
| Слой3 | Сеть | IP |
| Уровень 2 | Канал передачи данных | Ethernet MAC |
| Слой 1 | Физические | 10Base-T, 100Base-T |
Программируемость программного обеспечения — важная характеристика сетевых процессоров, поскольку она обеспечивает гибкость в широком диапазоне приложений. Несмотря на то, что все сетевые процессоры являются программируемыми, по определению, не все из них могут быть запрограммированы пользователем. Некоторые поставщики ограничивают доступ к базовому набору инструкций и архитектуре своего сетевого процессора (NPU), предпочитая вместо этого выполнять все программирование самостоятельно.
Несмотря на то, что все сетевые процессоры являются программируемыми, по определению, не все из них могут быть запрограммированы пользователем. Некоторые поставщики ограничивают доступ к базовому набору инструкций и архитектуре своего сетевого процессора (NPU), предпочитая вместо этого выполнять все программирование самостоятельно.
Не сетевой процессор
Многие микросхемы являются коммуникационными процессорами, но не сетевыми. Коммуникационные процессоры, такие как микросхемы PowerQUICC от Freescale, тесно связаны с сетевыми процессорами, но служат приложениям с более низкой скоростью передачи данных.Скорость передачи данных для коммуникационных процессоров составляет от нескольких мегабит в секунду до 1 Гбит / с (например, один гигабитный канал Ethernet). Хотя эта разделительная линия может показаться произвольной и, безусловно, изменится со временем, есть некоторые другие важные, хотя и тонкие, различия между этими двумя типами процессоров.
Коммуникационные процессоры стоят дешевле. Их более низкие цены означают, что они имеют большую степень интеграции, чем большинство сетевых процессоров. Например, коммуникационные процессоры обычно содержат ядро процессора RISC, которое выполняет стандартный набор инструкций MIPS, PowerPC или ARM.Напротив, большинство NPU не включают в себя такой процессор. В коммуникационном процессоре обработка уровня 3 и выше обычно обрабатывается этим процессором RISC, тогда как NPU обычно обрабатывают уровни 3 и выше с помощью проприетарных механизмов обработки пакетов. Многие коммуникационные процессоры объединяют обработку Уровня 1 и Уровня 2; большинство NPU этого не делают. Эти различия в цене и производительности между коммуникационными процессорами и NPU означают, что разработчики систем обычно используют их для самых разных приложений.
Их более низкие цены означают, что они имеют большую степень интеграции, чем большинство сетевых процессоров. Например, коммуникационные процессоры обычно содержат ядро процессора RISC, которое выполняет стандартный набор инструкций MIPS, PowerPC или ARM.Напротив, большинство NPU не включают в себя такой процессор. В коммуникационном процессоре обработка уровня 3 и выше обычно обрабатывается этим процессором RISC, тогда как NPU обычно обрабатывают уровни 3 и выше с помощью проприетарных механизмов обработки пакетов. Многие коммуникационные процессоры объединяют обработку Уровня 1 и Уровня 2; большинство NPU этого не делают. Эти различия в цене и производительности между коммуникационными процессорами и NPU означают, что разработчики систем обычно используют их для самых разных приложений.
Третий класс сетевых микросхем, специализированные ASIC, вообще не программируются. Производители микросхем иногда называют эти процессоры пакетов или движки пересылки. Эти зашитые ASIC конкурируют с NPU, в основном, в верхней части диапазона производительности NPU.
Наконец, сопроцессорные микросхемы, такие как механизмы классификации, поисковые системы и диспетчеры трафика, на самом деле не являются NPU, потому что они обрабатывают только часть всей задачи обработки пакетов. Кроме того, эти устройства, как правило, не программируются, хотя часто в некоторой степени настраиваются.NPU может содержать сопроцессоры или даже полагаться на внешние сопроцессоры, но сами эти сопроцессоры не являются NPU.
Общие характеристики
Один сетевой поток данных содержит большое количество отдельных пакетов, каждый из которых может обрабатываться независимо. Фактически, Интернет-протокол (IP) позволяет обрабатывать отдельные пакеты в одном потоке данных в любом порядке; получатель должен иметь возможность снова вернуть пакеты в порядок. Это сильно отличается от, скажем, байт-кода Java, который состоит из серии инструкций, которые должны обрабатываться последовательно.
Благодаря этой независимости обработка пакетов является идеальным приложением для массива процессоров.
Однако вместо того, чтобы комбинировать стандартные процессоры CISC или RISC, производители NPU еще больше урезали свои процессоры.Обработка пакетов — довольно простая задача, состоящая в основном из извлечения данных из битового потока и выполнения некоторого сопоставления с образцом или поиска в таблице, поэтому процессору пакетов не нужны сложные арифметические операции, причудливые режимы адресации или блоки преобразования памяти. Громоздкие схемы, такие как блоки с плавающей запятой (FPU) и блоки управления памятью (MMU), обычно не нужны. Кеши инструкций могут быть меньше, и кеши данных, как правило, полностью исключаются, поскольку большинство сетевых данных не повторяются и не используются повторно.
Кеши инструкций могут быть меньше, и кеши данных, как правило, полностью исключаются, поскольку большинство сетевых данных не повторяются и не используются повторно.
Мы назовем эти оптимизированные сетевые процессоры пакетными механизмами , хотя сами поставщики NPU используют различные термины, такие как микродвигатели и канальные процессоры . Отказавшись от универсальных функций ЦП и сосредоточив внимание только на основах, разработчики NPU могут разместить единый пакетный движок всего на нескольких квадратных миллиметрах кремния. Затем они могут обильно посыпать эти крошечные двигатели на стандартный кремниевый чип размером всего 100 мм2 или около того.Некоторые NPU объединяют 64 или более пакетных машин на одном чипе размером с Pentium 4.
Для дальнейшего использования большого количества доступных пакетов механизмы обработки пакетов обычно являются многопоточными. В этом подходе каждый механизм имеет один или несколько пакетов «на удержании», пока он обрабатывает текущий пакет. Если по какой-либо причине текущий пакет останавливается, например, при длительном доступе к памяти, механизм быстро переключается на один из пакетов на удержании. Таким образом, движок не тратит время на ожидание в памяти; вместо этого он может работать с почти максимальной эффективностью.
Если по какой-либо причине текущий пакет останавливается, например, при длительном доступе к памяти, механизм быстро переключается на один из пакетов на удержании. Таким образом, движок не тратит время на ожидание в памяти; вместо этого он может работать с почти максимальной эффективностью.
Многопоточный процессор обычно имеет дополнительные копии набора регистров программиста, каждая из которых хранит состояние отдельного пакета. Переключение пакетов (или потоков) означает просто указание на другой набор регистров и обычно выполняется за один цикл. Некоторые NPU заставляют программиста (или компилятора) вставлять инструкции переключения потоков; другие переключаются автоматически при каждом доступе к памяти.
Хотя пакетные механизмы часто представляют собой урезанные процессоры RISC, они также могут иметь некоторые дополнительные функции для повышения производительности пакетов.Инструкции по битовой манипуляции — один из распространенных примеров. В зависимости от конкретного сетевого протокола заголовки пакетов могут иметь поля, которые не выровнены по байтам или состоят только из одного или нескольких битов. Стандартные процессоры RISC работают только с 32-битными выровненными словами, поэтому эти специальные инструкции могут значительно упростить анализ заголовков и манипуляции с ними.
Стандартные процессоры RISC работают только с 32-битными выровненными словами, поэтому эти специальные инструкции могут значительно упростить анализ заголовков и манипуляции с ними.
Многие NPU включают сопроцессоры, такие как механизмы хеширования, поисковые системы, механизмы классификации или механизмы политик. Эти сопроцессоры обычно не программируются, поэтому они не выполняют никаких инструкций.Хотя их функции можно каким-то образом настраивать, они являются дополнениями к микросхеме с фиксированными функциями.
Наконец, некоторые NPU включают в себя процессор общего назначения в дополнение к пакетным машинам. Мы назовем его управляющим процессором , поскольку он обычно управляет микросхемой, предоставляет интерфейс для плоскости управления и выполняет некоторую обработку исключений. Внешний хост-процессор почти всегда используется для выполнения основной части кода плоскости управления.
Микроархитектура
Одна из задач, стоящих перед разработчиками NPU, — как организовать всю эту вычислительную мощность. Хотя современное производство кремний позволяет втиснуть десятки небольших пакетных машин на один кристалл, сложно подключить более 16 машин к одной памяти с помощью встроенной шины или кросс-шины. Добавление слишком большого количества двигателей к шине может вызвать конфликты, задержки и электрические проблемы, замедляя работу всего чипа.
Хотя современное производство кремний позволяет втиснуть десятки небольших пакетных машин на один кристалл, сложно подключить более 16 машин к одной памяти с помощью встроенной шины или кросс-шины. Добавление слишком большого количества двигателей к шине может вызвать конфликты, задержки и электрические проблемы, замедляя работу всего чипа.
Одно из решений — ограничить количество машин пакетов до 16, увеличивая при этом производительность каждой машины. Самые ранние механизмы обработки пакетов были простыми скалярными (по одной инструкции за раз) RISC-процессорами.Некоторые новые разработки перешли на пакетные механизмы VLIW (очень длинное командное слово), чтобы повысить производительность каждого пакетного механизма. Суперскалярные методы, которые вы видите в ПК и серверных процессорах, таких как Opteron, Pentium 4 или SPARC, менее эффективны, чем VLIW, и не нужны, если не важна совместимость программного обеспечения.
Другой подход состоит в том, чтобы конвейерные механизмы обработки пакетов выполнялись таким образом, чтобы каждая группа механизмов выполняла специализированную задачу. EZchip NP-1 и Agere APP750, если назвать два примера, имеют одну группу механизмов, которые подключаются к памяти таблицы поиска, а другая группа подключается к очередям пакетов.Таким образом уменьшается количество подключений к любому конкретному внутреннему ресурсу. Одним из недостатков является то, что это ограничивает потенциальные приложения теми, которые хорошо соответствуют выбранной конструкции конвейера. Например, эти конвейерные микросхемы хорошо разработаны для обработки IP-пакетов, но им труднее выполнять функции более высокого уровня, такие как iSCSI и завершение TCP.
EZchip NP-1 и Agere APP750, если назвать два примера, имеют одну группу механизмов, которые подключаются к памяти таблицы поиска, а другая группа подключается к очередям пакетов.Таким образом уменьшается количество подключений к любому конкретному внутреннему ресурсу. Одним из недостатков является то, что это ограничивает потенциальные приложения теми, которые хорошо соответствуют выбранной конструкции конвейера. Например, эти конвейерные микросхемы хорошо разработаны для обработки IP-пакетов, но им труднее выполнять функции более высокого уровня, такие как iSCSI и завершение TCP.
Возможны другие методы. Bay Microsystems сочетает конвейерную обработку с пакетными механизмами VLIW. Xelerated Technologies направляет механизмы VLIW в поток данных, что увеличивает эффективность.ClearSpeed использует метод «одна инструкция, несколько данных» (SIMD) для организации сотен упрощенных механизмов обработки пакетов.
Хотя совместимость программного обеспечения гораздо менее важна, чем в бизнесе ПК, некоторые архитектуры NPU теперь имеют значительный объем программного обеспечения, включая собственный библиотечный код поставщика, сторонние предложения и программное обеспечение, созданное заказчиком. В результате производители с установленной архитектурой NPU заинтересованы в сохранении совместимости программного обеспечения в будущих продуктах.Поставщики могут сохранить совместимость, изменив тактовую частоту и, в архитектурах с моделью программирования с одним изображением, описанной ниже, количество механизмов обработки пакетов. Однако стремление к совместимости предотвращает любые радикальные архитектурные изменения, такие как переход от RISC к VLIW или от параллельной архитектуры к конвейерной архитектуре, которые могут повысить производительность за пределы 10 Гбит / с. С другой стороны, новые участники NPU не имеют этих ограничений совместимости, поэтому они с большей вероятностью выберут более инновационную или агрессивную архитектуру, повышающую эффективность и масштабируемость.
В результате производители с установленной архитектурой NPU заинтересованы в сохранении совместимости программного обеспечения в будущих продуктах.Поставщики могут сохранить совместимость, изменив тактовую частоту и, в архитектурах с моделью программирования с одним изображением, описанной ниже, количество механизмов обработки пакетов. Однако стремление к совместимости предотвращает любые радикальные архитектурные изменения, такие как переход от RISC к VLIW или от параллельной архитектуры к конвейерной архитектуре, которые могут повысить производительность за пределы 10 Гбит / с. С другой стороны, новые участники NPU не имеют этих ограничений совместимости, поэтому они с большей вероятностью выберут более инновационную или агрессивную архитектуру, повышающую эффективность и масштабируемость.
Фиксированный или программируемый
Еще один фактор, который необходимо учитывать при выборе NPU, — это использование сопроцессоров с фиксированной функцией для повышения производительности механизмов обработки пакетов. AMCC, например, использует только шесть скалярных пакетных движков в своем симплексном NPU 10 Гбит / с, поэтому у компании есть возможность добавить больше движков в будущие чипы. AMCC может обойтись таким небольшим количеством программируемых механизмов, потому что его механизмы политик с фиксированными функциями, поисковые системы и диспетчеры трафика выполняют большую часть задачи обработки пакетов.
AMCC, например, использует только шесть скалярных пакетных движков в своем симплексном NPU 10 Гбит / с, поэтому у компании есть возможность добавить больше движков в будущие чипы. AMCC может обойтись таким небольшим количеством программируемых механизмов, потому что его механизмы политик с фиксированными функциями, поисковые системы и диспетчеры трафика выполняют большую часть задачи обработки пакетов.
Логика с фиксированными функциями обычно более эффективна для любой конкретной задачи, чем программируемые механизмы обработки пакетов, поэтому использование сопроцессоров может повысить производительность. Очевидный недостаток — снижение гибкости; приложения должны соответствовать возможностям блоков с фиксированной функцией.
Более тонкая проблема — относительная сложность дизайна. Логика с фиксированной функцией обычно реализует сложные конечные автоматы; эта сложность возрастает по мере того, как разработчики системы добавляют больше функций и опций. С другой стороны, вы можете реплицировать один пакетный движок много раз и можете запрограммировать его для множества задач.
Следует разумно использовать логику с фиксированными функциями. Рассмотрим устройство, реализующее маршрутизацию IPv4 и IPv6, а также многопротокольную коммутацию меток. В таком случае один программируемый механизм может обрабатывать все три протокола более эффективно, чем три отдельных конечных автомата. Однако имеет смысл встроить такую функцию, как синтаксический анализ заголовка, которую можно легко настроить для всех трех протоколов.
Наконец, поставщики NPU должны учитывать, что у многих сетевых заказчиков есть уникальные потребности, которые можно удовлетворить только с помощью программируемости.Гибкое программируемое устройство может легче поддерживать любые алгоритмы, протоколы или услуги, которые заказчик может захотеть реализовать. Высоко программируемый NPU будет обслуживать максимально широкий рынок. С другой стороны, хорошо спроектированный NPU с соответствующим использованием блоков с фиксированной функцией, вероятно, будет более эффективным для основных приложений.
Спектр программируемости
Из-за различий в выборе конструкции сетевые процессоры предлагают различные уровни программируемости, как показано на Рисунке 1.На одном конце спектра находится логика полностью фиксированных функций «сетевой ASIC». По мере добавления программируемых процессорных элементов дизайн перемещается вправо. Полностью программируемый NPU с небольшим количеством блоков фиксированной функции, если они вообще есть, находится в крайнем правом углу.
Рисунок 1: Спектр программируемости между NPU
Архитектура IXP Intel является хорошим примером полностью программируемой конструкции, использующей пакетный движок для выполнения почти всей работы. EZchip имеет хорошо программируемую микросхему NPU, но ее микросхема диспетчера трафика не программируется, поэтому весь продукт менее программируемый, чем у Intel.Чипы AMCC nP также используют диспетчер трафика с фиксированной функцией, и даже NPU сочетает ограниченную мощность пакетного движка с большим количеством сопроцессоров. Сетевые ASIC, такие как Prestera-MX от Marvell, вообще не имеют пакетных машин; это все зашито.
Сетевым клиентам, у которых есть необычные или частные требования, может потребоваться возможность программирования. Эти клиенты будут искать продукты в правой части этого спектра. Вы можете возразить, что эти микросхемы так же хорошо подходят другим клиентам, которые могут использовать столько или меньше возможностей программирования, сколько им нужно, но у этого подхода есть проблемы.
Одним из недостатков программируемости является нагрузка, которую она возлагает на клиента. Семейство микросхем Intel IXP требует от 8 до 10 раз больше программного обеспечения, чем AMCC, для выполнения тех же задач. Задачи, которые выполняются на оборудовании AMCC, должны быть записаны в программном обеспечении для IXP. Даже если поставщик NPU предоставит много справочного кода, у клиента IXP все равно будет больше кода для сборки, тестирования и отладки, чем у клиента AMCC. В крайнем случае, встроенная ASIC полностью устраняет необходимость в программном обеспечении NPU, хотя некоторое программное обеспечение хост-процессора все еще требуется.
Благодаря эффективности логики с фиксированными функциями, зашитые ASIC также могут обеспечить преимущества в стоимости, мощности и интеграции. Например, Prestera-MX обеспечивает полнодуплексную пропускную способность 10 Гбит / с — включая контроллеры доступа к среде (MAC), поисковые системы и управление исходящим трафиком — в одном кристалле стоимостью около 600 долларов США и потреблении всего 7 Вт. За исключением уникальной архитектуры PISC (Packet Instruction Set Computer) Xelerated, для всех доступных программируемых решений требуется как минимум в два раза больше микросхем, более чем в два раза дороже и в два раза больше мощности.
Однако большинство клиентов недовольны отсутствием гибкости аппаратных ASIC. Возможность программирования позволяет клиентам легко отличать свое оборудование от того, что может предложить другой поставщик, использующий тот же NPU; с зашитой ASIC возможности для дифференциации более ограничены. Программируемые NPU также обеспечивают своего рода страховку для клиентов, которые не могут предсказать, какие новые функции могут потребоваться через два года. Без возможности программирования оборудование в полевых условиях (или в длительных циклах разработки) может устареть.
Хотя некоторые OEM-производители выберут аппаратные ASIC, большинство из них, скорее всего, будут искать баланс между программируемостью и производительностью, который отвечает потребностям их проектов. Поставщики NPU предлагают ряд альтернатив; большинство клиентов найдут по крайней мере тот, который обеспечивает правильный баланс.
Внешние интерфейсы
Типичный NPU имеет четыре основных внешних интерфейса, как показано на Рисунке 2. Первый — это линейный интерфейс , который часто подключается к внешним микросхемам MAC или фреймерам.Некоторые NPU включают в себя встроенные MAC-адреса или устройства формирования кадров (или и то, и другое), и в этом случае линейный интерфейс может подключаться напрямую к внешним устройствам PHY (физического уровня). Пропускная способность этого интерфейса имеет решающее значение, поскольку она ограничивает максимальный объем данных, который NPU может принять. Кроме того, протоколы и гибкость этого интерфейса определяют типы микросхем, к которым интерфейс может подключаться, и протоколы (например, Gigabit Ethernet, OC-48), которые он может поддерживать. Обратите внимание, что большинство NPU будут поддерживать дополнительные протоколы с использованием внешней связующей логики (например, ASIC или FPGA), но это увеличивает стоимость системы и, что более важно, время разработки.
Рисунок 2: Блок-схема типичного NPU
Второй интерфейс — это интерфейс фабрики , который соединяет NPU с внешней коммутационной фабрикой или, в некоторых случаях, напрямую с другим NPU. Этот интерфейс важен для построения линейной карты, но может не использоваться в других проектах. Интерфейс фабрики должен иметь по крайней мере такую же полосу пропускания, как и линейный интерфейс, потому что почти все пакеты в линейной карте должны перемещаться через оба интерфейса. Фактически, у него должна быть достаточная дополнительная пропускная способность, обычно не менее 25%, для поддержки заголовков фабрики, внутриполосной связи и других накладных расходов фабрики.
Интерфейс памяти часто состоит из нескольких отдельных физических соединений. Один или несколько типов обычно подключаются к памяти пакетов , где заголовки пакетов и полезные данные хранятся во время обработки. Память пакетов также хранит пакеты, поставленные в очередь для согласования скорости или, в качестве приложений обслуживания, для поддержки нескольких уровней приоритета. Как показывает практика, пакетная память должна быть 256 МБ для OC-48, 1 ГБ для OC-192 (или 10 ГБ Ethernet) и 4 ГБ для скорости передачи данных OC-768.Для этих больших массивов NPU обычно используют дешевую DRAM, а не быструю, но дорогую SRAM. Постоянная пропускная способность этой памяти должна как минимум вдвое превышать пропускную способность линии, потому что каждый пакет должен быть записан в память пакетов, а затем считан обратно.
Таблица пересылки обычно хранится в отдельной памяти таблицы , обычно реализуемой с помощью высокоскоростной SRAM. Таблица маршрутизации может иметь размер от нескольких сотен килобайт до нескольких мегабайт, но, как правило, она намного меньше, чем пакетная память, чтобы снизить стоимость.Маршрутизаторы уровня 3 могут использовать 32-битные записи таблицы для IPv4, но более сложные приложения могут использовать записи размером 300 бит и более, особенно при поддержке IPv6. Для каждого пакета требуется от одного до трех обращений к таблице, поэтому память таблицы должна обеспечивать достаточную пропускную способность, чтобы поддерживать эту скорость на «скорости провода» (исходная скорость сетевого кабеля или волокна).
Большинство NPU имеют одну или несколько памяти для хранения инструкций (называемых хранилищем управления), которые будут выполнять различные механизмы обработки пакетов и процессоры управления.В большинстве случаев управляющая память пакетных машин находится внутри микросхемы NPU, поскольку код быстрого пути обычно состоит всего из нескольких тысяч инструкций. Многие NPU также имеют ПЗУ, содержащее загрузочный код.
Наконец, большинство NPU имеют интерфейс хоста , который подключается к внешнему микропроцессору хоста. Обычно это интерфейс PCI, поскольку многие встроенные процессоры подключаются к PCI напрямую или через стандартный набор микросхем. Для увеличения пропускной способности некоторые NPU предлагают 66 МГц PCI в дополнение к стандартной версии 33 МГц.PCI Express в конечном итоге может вытеснить PCI, особенно в высокопроизводительных NPU.
Для NPU требования к полосе пропускания интерфейса хост-процессор сильно различаются в зависимости от приложения. Некоторым линейным картам не нужен какой-либо локальный хост-процессор, вместо этого они полагаются на централизованный процессор уровня управления, находящийся в другом месте системы. Продукты, которые выполняют завершение TCP, могут использовать интерфейс хост-процессор как средство для передачи пакетных данных. Не существует простого практического правила для соотношения пропускной способности хост-процессора и пропускной способности пакетных данных.
Рекомендации по программному обеспечению
Модель программирования NPU также важна. Большинство NPU предлагают модель от выполнения до завершения , в которой один пакетный механизм полностью обрабатывает пакет. В этой модели пакеты могут быть назначены механизмам обработки пакетов программным или аппаратным обеспечением.
Другие NPU используют конвейерную модель , в которой пакет передается от обработчика пакетов к обработчику пакетов по мере его обработки. Такой подход упрощает конструкцию оборудования, но требует разделения программного обеспечения обработки пакетов на этапы примерно одинаковой длины.Это может быть сложно, особенно когда используется несколько сетевых протоколов. Аппаратный конвейер также труднее адаптировать к необычным или неожиданным приложениям.
Большинство NPU предлагают модель программирования с одним образом , которая скрывает сложность оборудования от программиста. Эти NPU требуют, чтобы все механизмы обработки пакетов и потоки выполняли один и тот же код, что упрощает разработку программного обеспечения. Это наиболее часто встречается в проектах с завершением работ. Некоторые конвейерные NPU имеют несколько обработчиков пакетов на каждом этапе и используют один образ кода на каждом этапе.
Другие NPU используют симметричный мультипроцессор (SMP) модели , который позволяет каждому пакетному механизму выполнять свое собственное программное обеспечение. Модель SMP требует, чтобы программное обеспечение назначало пакеты нескольким механизмам обработки пакетов и иным образом координировало их. Эта модель предлагает максимальную гибкость, позволяя использовать механизмы обработки пакетов либо параллельно, либо последовательно (другими словами, «программный конвейер»). Программисты также могут назначать некоторые механизмы обработки пакетов одной задаче, в то время как другие обрабатывают другую задачу.Но модель SMP приводит к более сложным программным продуктам, которые обычно требуют настройки производительности.
Учитывая количество NPU на рынке, простота программирования является важным фактором при выборе продукта. Некоторые поставщики считают, что лучше всего писать код плоскости данных непосредственно в сборке, поскольку производительность кода неизбежно должна быть оптимизирована вручную. Другие считают, что написание на языке высокого уровня улучшает возможность повторного использования программного обеспечения и, что более важно, ускоряет выход на рынок.
Преимущества ассемблерного кода — производительность и компактность.Для большинства современных приложений код плоскости данных состоит всего из нескольких тысяч строк, большая часть из которых может быть предоставлена поставщиком NPU в библиотеке. Однако по мере добавления дополнительных протоколов и сервисов код плоскости данных будет становиться более сложным.
Большинство поставщиков NPU предлагают компиляторы для своих пакетных машин, в то время как некоторые производители требуют, чтобы клиенты программировали на языке ассемблера. Большинство компиляторов реализуют подмножество C или, по крайней мере, используют синтаксис, подобный C, но они не поддерживают стандартные библиотеки C. Кроме того, хранилища управления пакетной машиной очень малы, от 1000 до 16000 инструкций.Следовательно, существующий код C не может быть легко перенесен на NPU. По крайней мере, компиляторы предлагают программистам знакомый язык для более быстрого запуска и создания прототипов. Тем не менее, даже с компилятором часто требуется некоторая оптимизация на уровне сборки.
Имейте в виду, что кодирование на языке высокого уровня — не панацея. Для большинства NPU даже код высокого уровня должен напрямую обращаться к сопроцессорам на кристалле и быть оптимизирован для соответствия внутренней архитектуре кристалла (например, конвейерной или параллельной).Эти проблемы снижают производительность; они также предотвращают простой перенос кода с одного NPU на другой. Хотя многим программистам может быть удобнее работать с синтаксисом, подобным Си, чем с мнемоникой языка ассемблера, им все же необходимо изучить микроархитектуру целевого NPU и написать код непосредственно для него.
Наиболее успешные поставщики NPU предлагают клиентам выбор, поставляя как компилятор, так и ассемблер, а также оптимизированные библиотеки кода для общих функций плоскости данных. Некоторые клиенты могут затем кодировать непосредственно на языке ассемблера, в то время как другие могут использовать компилятор.
ПоставщикиNPU также предоставляют готовый код, чтобы помочь своим клиентам быстрее выйти на рынок. Предоставляя базовые функции плоскости данных, они позволяют клиентам сконцентрироваться на функциях более высокого уровня, которые могут обеспечить дифференциацию. Предложения сильно различаются: от базового эталонного кода IP-пересылки до готового к производству кода для DiffServ, MPLS и ATM. Количество и качество кода библиотеки поставщика может быть важным фактором при выборе NPU.
Преимущества, недостатки
Основными конкурентами NPU являются микропроцессоры общего назначения и специализированные ASIC.В предыдущих сетевых системах производители использовали микропроцессоры для выполнения функций маршрутизации в устройствах низкого уровня из-за их низкой стоимости, общедоступности и простоты программирования. Однако микропроцессоры не обладают достаточной производительностью для устройств с высокой пропускной способностью, поэтому в этих устройствах использовались специальные ASIC.
ASIC обеспечивают полный контроль над дизайном. Используя ASIC, поставщик сетевых технологий может создавать продукты с высокой дифференциацией. С другой стороны, ASIC имеют длительные циклы проектирования, длительные циклы отладки и высокие затраты на разработку.Разработка ASIC обычно будет критическим путем для этих систем. Новые разработки ASIC занимают от 9 до 18 месяцев и стоят миллионы долларов. Любые ошибки требуют доработки чипа (спинов), которые добавляют месяцы к расписанию. В результате разработка ASIC является наиболее рискованной частью разработки системы.
Как и стандартные микропроцессоры, сетевые процессоры программируются и доступны в готовом виде, но при этом могут соответствовать производительности ASIC в ресурсоемких сетевых приложениях. Покупая сторонний NPU, производитель оборудования обходит весь цикл проектирования ASIC и связанный с ним риск.Вместо этого поставщик NPU несет эту стоимость.
NPU заменяют ASIC с фиксированной функцией программируемой конструкцией, обеспечивая дополнительные преимущества. Программируемое устройство сокращает цикл проектирования и его легче модифицировать для поддержки новых или развивающихся стандартов. Программируемость не только ускоряет время выхода на рынок, но и позволяет модернизировать маршрутизатор на базе NPU на месте с использованием нового протокола — чего нельзя сделать с проводным решением.
Для полевых обновлений с целью добавления новых протоколов требуется NPU с объемом обработки.Если при первоначальном развертывании продукта используется вся вычислительная мощность NPU, дополнительные функции и протоколы не могут работать с использованием только программного обеспечения. Дизайнер должен оставить достаточно места для желаемого срока службы продукта. Запас места также может сократить время вывода на рынок первоначального дизайна. Если доступен компилятор, программное обеспечение можно написать на C (создавая менее эффективный код) и оптимизировать позже, когда для новых функций потребуются циклы обработки.
Однако сетевой процессор не всегда является идеальным решением.Хотя NPU могут сократить циклы проектирования оборудования, они увеличивают объем работ по разработке программного обеспечения. У некоторых клиентов есть обширные ресурсы для проектирования ASIC, но относительно ограниченный штат разработчиков программного обеспечения. Широкомасштабное использование NPU будет означать перебалансировку этих ресурсов. По этим и другим причинам ASIC никогда полностью не исчезнут из сетевого оборудования.
В отличие от встроенных процессоров, которые широко поддерживаются сторонними инструментами разработки, NPU приходится программировать с использованием собственных инструментов производителя.Для начальных проектов изучение архитектуры NPU и набора инструментов может существенно удлинить общий цикл разработки системы. Однако, если у поставщика оборудования будет существующая кодовая база, последующие циклы проектирования будут намного короче. Теперь, когда несколько поставщиков NPU предлагают ряд совместимых чипов, производитель оборудования может повторно использовать свое программное обеспечение в продуктах низкого, среднего и высокого уровня.
Линли Гвеннап — главный аналитик Linley Group (www.linleygroup.com), компания по анализу технологий, специализирующаяся на сетевых полупроводниках. До Линли можно добраться по адресу.
Продолжить чтение
Как контролировать использование ЦП и сети (Windows)
- 2 минуты на чтение
В этой статье
Поскольку Nano Server не имеет интерактивной консоли, администрирование должно выполняться удаленно.
Подключиться к Nano Server удаленно.
Для удаленного доступа к серверу Nano Server выполните действия, описанные в разделе Как получить доступ к серверу Nano Server.
Для мониторинга загрузки ЦП
Командлет
Get-Counterможно использовать для получения данных монитора производительности. Дополнительные сведения и примеры см. В справке по командлету.Для мониторинга загрузки ЦП в режиме реального времени, 2 секунды между выборками и остановка после 33 выборок:
Get-Counter -Counter "\ Processor (_Total) \% Processor Time" -SampleInterval 2 -MaxSamples 33Для непрерывного выполнения (с интервалом в 2 секунды):
Get-Counter -Counter "\ Processor (_Total) \% Processor Time" -SampleInterval 2 -ContinuousДля непрерывной работы (без задержки):
Get-Counter -Counter "\ Processor (_Total) \% Processor Time" -ContinuousДля мониторинга использования памяти
Чтобы просмотреть оставшуюся память:
Get-Counter -Counter "\ Память \ Доступные МБ"Для отображения оставшейся памяти каждые 15 секунд, непрерывно:
Get-Counter -Counter "\ Memory \ Available MBytes" -SampleInterval 15 -ContinuousДля мониторинга использования сети
Вы можете использовать Performance Monitor (PerfMon) удаленно для мониторинга производительности и ресурсов Nano Server.Запустите PerfMon из любой командной строки (или введите «Монитор производительности» в меню «Пуск»), щелкните правой кнопкой мыши «Производительность», выберите «Подключиться к другому компьютеру» и введите IP-адрес компьютера Nano Server, который вы хотите отслеживать.
Инструменты управления сервером
Вы можете использовать инструменты управления сервером (SMT) на основе браузера для мониторинга ЦП, диска, сети и памяти, а также многих других функций. Посмотрите этот блог и сопутствующее видео, чтобы познакомиться с SMT: http: // blogs.technet.com/b/nanoserver/archive/2016/02/09/server-management-tools-is-now-live.aspx
5 наиболее распространенных узких мест производительности системы ЦП
Узкие места в производительности могут привести к замедлению работающего компьютера или сервера до обхода. Термин «узкое место» относится как к перегруженной сети , так и к состоянию вычислительного устройства, в котором один компонент не может идти в ногу с остальной частью системы, что снижает общую производительность.Устранение проблем с узкими местами обычно приводит к возврату системы к работоспособному уровню производительности; однако для устранения проблем с узкими местами необходимо сначала определить неэффективный компонент.
Эти пять причин снижения производительности являются одними из самых распространенных:
1. Загрузка ЦП
Согласно Microsoft, «узкие места процессора возникают, когда процессор настолько загружен, что не может отвечать на запросы времени». Проще говоря, ЦП перегружен и не может своевременно выполнять задачи.
Узкое место ЦПпроявляется в двух формах: процессор, работающий на более чем 80% мощности в течение длительного периода времени, и слишком длинная очередь процессоров. Узкие места в использовании ЦП часто возникают из-за недостатка системной памяти и постоянных прерываний со стороны устройств ввода-вывода. Решение этих проблем с помощью простого теста на узкое место ЦП приводит к увеличению мощности ЦП, увеличению объема оперативной памяти и повышению эффективности программного кодирования.
2. Использование памяти
Узкое место в памяти означает, что в системе недостаточно или недостаточно быстрой оперативной памяти.Эта ситуация снижает скорость, с которой ОЗУ может передавать информацию ЦП, что замедляет общие операции. В случаях, когда системе не хватает памяти, компьютер начнет выгружать хранилище на более медленный жесткий диск или твердотельный накопитель, чтобы все работало. В качестве альтернативы, если ОЗУ не может передавать данные в ЦП достаточно быстро, устройство будет испытывать как замедление, так и низкую загрузку ЦП.
Для решения проблемы обычно требуется установка большей емкости и / или более быстрой оперативной памяти.В случаях, когда существующая оперативная память слишком медленная, ее необходимо заменить, а узкие места в емкости можно устранить, просто добавив дополнительную память. В других случаях проблема может возникать из-за ошибки программирования, называемой «утечкой памяти», что означает, что программа не освобождает память для использования системой снова, когда закончила использовать ее. Для решения этой проблемы требуется исправление программы.
3. Использование сети
Узкие места в сети возникают, когда для связи между двумя устройствами не хватает пропускной способности или вычислительной мощности, необходимой для быстрого выполнения задачи.Согласно Microsoft, узкие места в сети возникают, когда есть перегруженный сервер, перегруженное сетевое коммуникационное устройство и когда сама сеть теряет целостность. Решение проблем использования сети обычно включает обновление или добавление серверов, а также обновление сетевого оборудования, такого как маршрутизаторы, концентраторы и точки доступа.
4. Ограничение программного обеспечения
Иногда падение производительности из-за узких мест происходит из-за самого программного обеспечения. В некоторых случаях программы могут быть созданы для одновременного выполнения только ограниченного числа задач, поэтому программа не будет использовать какие-либо дополнительные ресурсы ЦП или ОЗУ, даже если они доступны.Кроме того, программа не может быть написана для работы с несколькими потоками ЦП, поэтому в многоядерном процессоре используется только одно ядро. Эти проблемы решаются путем переписывания и исправления программного обеспечения.
5. Использование диска
Самым медленным компонентом внутри компьютера или сервера обычно является долговременное хранилище, которое включает в себя жесткие диски и твердотельные накопители, и часто является неизбежным узким местом компьютера. Даже самые быстрые решения для долгосрочного хранения имеют физические ограничения скорости, что делает это узкое место одним из наиболее сложных для устранения неполадок.Во многих случаях скорость использования диска можно повысить за счет уменьшения проблем фрагментации и увеличения скорости кэширования данных в ОЗУ. На физическом уровне устраните недостаточную пропускную способность, переключившись на более быстрые устройства хранения и расширив конфигурации RAID.
Эксперты Apica предлагают инструменты нагрузочного тестирования и мониторинга для онлайн-платформ вашего бизнеса, которые превосходно помогают выявлять узкие места в производительности, которые снижают производительность, и проводить тесты узких мест в системе. Если вы хотите получить максимальную отдачу от своих платформ, свяжитесь с экспертами Apica сегодня.
Фото в Facebook: https://stevecutts.wordpress.com/tag/buffering/
типов инстансов Amazon EC2 — Amazon Web Services
Характеристики экземпляра
Инстансы Amazon EC2 предоставляют ряд дополнительных функций, которые помогут вам развертывать, управлять и масштабировать ваши приложения.
Экземпляры Burstable Performance
Amazon EC2 позволяет выбирать между инстансами с фиксированной производительностью (например,грамм. M5, C5 и R5) и экземпляры Burstable Performance (например, T3). Экземпляры с изменяемой производительностью обеспечивают базовый уровень производительности ЦП с возможностью увеличения производительности выше базового.
T Неограниченное количество инстансов может поддерживать высокую производительность ЦП до тех пор, пока в этом нуждается рабочая нагрузка. Для большинства рабочих нагрузок общего назначения инстансы T Unlimited обеспечат достаточную производительность без каких-либо дополнительных затрат. Почасовая цена инстанса T автоматически покрывает все промежуточные всплески использования, когда средняя загрузка ЦП инстанса T равна или меньше базовой линии в течение 24-часового окна.Если инстансу необходимо работать с более высокой загрузкой ЦП в течение длительного периода, это можно сделать за фиксированную дополнительную плату в размере 5 центов за каждый виртуальный ЦП в час.
Базовая производительность инстансовT и возможность пакетной загрузки регулируются кредитами ЦП. Каждый экземпляр T непрерывно получает кредиты ЦП, скорость которых зависит от размера экземпляра. Инстансы T накапливают кредиты ЦП, когда они простаивают, и используют кредиты ЦП, когда они активны. Кредит ЦП обеспечивает производительность полного ядра ЦП в течение одной минуты.
Например, экземпляр t2.small непрерывно получает кредиты со скоростью 12 кредитов ЦП в час. Эта возможность обеспечивает базовую производительность, эквивалентную 20% ядра ЦП (20% x 60 минут = 12 минут). Если экземпляр не использует полученные кредиты, они сохраняются на его балансе ЦП до максимум 288 кредитов ЦП. Когда экземпляру t2.small требуется увеличить нагрузку на ядро более чем на 20%, он использует кредитный баланс ЦП для автоматической обработки этого всплеска.
Если включен T2 Unlimited, экземпляр t2.small может превысить базовый уровень даже после того, как его кредитный баланс ЦП опустится до нуля. Для подавляющего большинства рабочих нагрузок общего назначения, где средняя загрузка ЦП находится на уровне или ниже базовой производительности, базовая почасовая цена t2.small покрывает все всплески ЦП. Если экземпляр работает со средней загрузкой ЦП 25% (на 5% выше базового уровня) в течение 24 часов после того, как его кредитный баланс ЦП обнуляется, с него будет взиматься дополнительная плата в размере 6 центов (5 центов / виртуальный ЦП в час. x 1 виртуальный ЦП x 5% x 24 часа).
Многие приложения, такие как веб-серверы, среды разработки и небольшие базы данных, не требуют постоянно высоких уровней ЦП, но получают значительную выгоду от полного доступа к очень быстрым ЦП, когда они им нужны. Экземпляры T разработаны специально для этих случаев использования. Если вам нужна стабильно высокая производительность ЦП для таких приложений, как кодирование видео, веб-сайты большого объема или приложения HPC, мы рекомендуем использовать экземпляры с фиксированной производительностью. Инстансы T предназначены для работы так, как если бы у них были выделенные высокоскоростные ядра Intel, доступные, когда вашему приложению действительно нужна производительность ЦП, при этом защищая вас от переменной производительности или других распространенных побочных эффектов, которые обычно возникают из-за превышения подписки в других средах.
Несколько вариантов хранения
Amazon EC2 позволяет выбирать между несколькими вариантами хранения в зависимости от ваших требований. Amazon EBS — это надежный том хранилища на уровне блоков, который можно подключить к одному работающему инстансу Amazon EC2. Вы можете использовать Amazon EBS в качестве основного устройства хранения данных, требующих частого и детального обновления. Например, Amazon EBS является рекомендуемым вариантом хранилища при запуске базы данных на Amazon EC2.Тома Amazon EBS сохраняются независимо от срока службы инстанса Amazon EC2. После того, как том присоединен к экземпляру, вы можете использовать его как любой другой физический жесткий диск. Amazon EBS предоставляет три типа томов, которые наилучшим образом соответствуют потребностям ваших рабочих нагрузок: универсальные (SSD), выделенные IOPS (SSD) и магнитные. General Purpose (SSD) — это новый тип тома EBS общего назначения с поддержкой SSD, который мы рекомендуем клиентам по умолчанию. Тома общего назначения (SSD) подходят для широкого спектра рабочих нагрузок, включая базы данных малого и среднего размера, среды разработки и тестирования, а также загрузочные тома.Тома с выделенным IOPS (SSD) предлагают хранилище с постоянной производительностью и малой задержкой и предназначены для приложений с интенсивным вводом-выводом, таких как большие реляционные базы данных или базы данных NoSQL. Магнитные тома обеспечивают самую низкую стоимость гигабайта из всех типов томов EBS. Магнитные тома идеально подходят для рабочих нагрузок, в которых доступ к данным осуществляется нечасто, и приложений, для которых важна минимальная стоимость хранения.
Многие инстансы Amazon EC2 также могут включать хранилище с дисков, которые физически подключены к главному компьютеру.Это дисковое хранилище называется хранилищем экземпляров. Хранилище инстансов предоставляет временное хранилище на уровне блоков для инстансов Amazon EC2. Данные в томе хранилища инстансов сохраняются только в течение срока службы связанного инстанса Amazon EC2.
Помимо хранилища на уровне блоков через Amazon EBS или хранилище экземпляров, вы также можете использовать Amazon S3 для высоконадежного и высокодоступного объектного хранилища. Дополнительные сведения о вариантах хранения Amazon EC2 см. В документации Amazon EC2.
Инстансы, оптимизированные для EBS
За дополнительную небольшую почасовую плату клиенты могут запускать отдельные типы инстансов Amazon EC2 как инстансы, оптимизированные для EBS.Для экземпляров M6g, M5, M4, C6g, C5, C4, R6g, P3, P2, G3 и D2 эта функция включена по умолчанию без дополнительных затрат. Инстансы, оптимизированные для EBS, позволяют инстансам EC2 полностью использовать IOPS, выделенные на томе EBS. Инстансы, оптимизированные для EBS, обеспечивают выделенную пропускную способность между Amazon EC2 и Amazon EBS с вариантами от 500 до 4000 мегабит в секунду (Мбит / с) в зависимости от типа используемого инстанса. Выделенная пропускная способность сводит к минимуму конкуренцию между вводом-выводом Amazon EBS и другим трафиком из вашего инстанса EC2, обеспечивая наилучшую производительность для ваших томов EBS.Инстансы, оптимизированные для EBS, предназначены для использования со всеми томами EBS. При подключении к инстансам, оптимизированным для EBS, объемы Provisioned IOPS могут обеспечивать задержку в несколько миллисекунд и предназначены для обеспечения производительности в пределах 10% от выделенного IOPS в 99,9% случаев. Мы рекомендуем использовать тома с выделенным IOPS с оптимизированными для EBS экземплярами или экземплярами, которые поддерживают кластерную сеть для приложений с высокими требованиями к вводу-выводу хранилища.
Кластерная сеть
Выбранные экземпляры EC2 поддерживают кластерную сеть при запуске в общую группу размещения кластера.Группа размещения кластера обеспечивает сетевое взаимодействие с малой задержкой между всеми экземплярами в кластере. Пропускная способность, которую может использовать экземпляр EC2, зависит от типа экземпляра и его характеристик сетевой производительности. Межэкземплярный трафик в одном регионе может использовать до 5 Гбит / с для однопоточного и до 100 Гбит / с для многопоточного трафика в каждом направлении (полный дуплекс). Трафик в сегменты S3 в одном регионе и из них также может использовать всю доступную совокупную пропускную способность экземпляра. При запуске в группе размещения экземпляры могут использовать до 10 Гбит / с для однопоточного трафика и до 100 Гбит / с для многопоточного трафика.Сетевой трафик в Интернет ограничен 5 Гбит / с (полный дуплекс). Кластерные сети идеально подходят для высокопроизводительных аналитических систем и многих научных и инженерных приложений, особенно тех, которые используют стандарт библиотеки MPI для параллельного программирования.
Характеристики процессора Intel
ИнстансыAmazon EC2 с процессором Intel могут предоставлять доступ к следующим функциям процессора:
- Новые инструкции Intel AES (AES-NI): Набор инструкций шифрования Intel AES-NI улучшает исходный алгоритм Advanced Encryption Standard (AES), обеспечивая более быструю защиту данных и большую безопасность.Все инстансы EC2 текущего поколения поддерживают эту функцию процессора.
- Intel Advanced Vector Extensions (Intel AVX, Intel AVX2 и Intel AVX-512): Intel AVX и Intel AVX2 — 256-битные, а Intel AVX-512 — 512-битные расширения набора команд, разработанные для приложений, использующих плавающую точку ( FP) интенсивный. Инструкции Intel AVX повышают производительность таких приложений, как обработка изображений и аудио / видео, научное моделирование, финансовая аналитика, а также 3D-моделирование и анализ.Эти функции доступны только в экземплярах, запущенных с HVM AMI.
- Технология Intel Turbo Boost: Технология Intel Turbo Boost обеспечивает повышенную производительность при необходимости. Процессор может автоматически запускать ядра с частотой, превышающей базовую рабочую частоту, чтобы помочь вам сделать больше быстрее.
- Intel Deep Learning Boost (Intel DL Boost): Новый набор встроенных процессорных технологий, предназначенных для ускорения сценариев использования глубокого обучения искусственного интеллекта.Масштабируемые процессоры Intel Xeon Scalable 2-го поколения дополняют Intel AVX-512 новой векторной инструкцией нейронной сети (VNNI / INT8), которая значительно увеличивает производительность логического вывода глубокого обучения по сравнению с процессорами Intel Xeon Scalable предыдущего поколения (с FP32) для распознавания / сегментации изображений, объектов обнаружение, распознавание речи, языковой перевод, системы рекомендаций, обучение с подкреплением и другие. VNNI может быть несовместим со всеми дистрибутивами Linux. Пожалуйста, проверьте документацию перед использованием.
Не все функции процессора доступны во всех типах инстансов, просмотрите матрицу типов инстансов для получения более подробной информации о том, какие функции и какие типы инстансов доступны.
Пример использования ЦП
Один из основных вопросов, обсуждаемых в наши дни в области сетевых технологий, заключается в том, лучше ли загружать сетевые функции на центральный процессор или лучше переложить эти функции на межсетевое оборудование.
Технологию соединенияOnloading проще построить, но проблема заключается в загрузке ЦП; Поскольку ЦП должен управлять и выполнять сетевые операции, он имеет меньшую доступность для приложений, что является его основной целью.
Offloading, с другой стороны, направлен на преодоление узких мест в производительности ЦП путем выполнения сетевых функций, а также сложных коммуникационных операций, таких как коллективные операции или операции агрегирования данных, с данными во время их перемещения внутри кластера. В наши дни данные распределяются так, что возникает узкое место в производительности из-за ожидания поступления данных в ЦП для анализа. Вместо этого данными можно манипулировать, где бы они ни находились в сети, с помощью интеллектуальных сетевых устройств, которые разгружают функции ЦП.Это дает дополнительное преимущество, заключающееся в увеличении доступности ЦП для вычислительных функций, повышая общую эффективность системы.
Проблема загрузки ЦП является одним из основных пунктов разногласий между двумя вариантами. То, как вы измеряете использование ЦП и какой тип теста вы используете для теста, может дать очень вводящие в заблуждение результаты.
Например, распространенной ошибкой является использование обычного теста задержки или теста скорости передачи сообщений для определения загрузки ЦП; однако эти тесты обычно требуют от ЦП постоянного поиска данных (то есть опроса данных в памяти), из-за чего создается впечатление, что ЦП загружен на 100%, хотя на самом деле он вообще не работает.Использование такого теста для определения загрузки ЦП даст ложный результат. В реальном мире процессоры не проверяют данные постоянно.
Итак, как правильно измерить загрузку ЦП? В идеале для определения загрузки ЦП можно использовать тест пропускной способности данных или другой тест, не использующий опрос данных. В качестве альтернативы, если используется тест скорости передачи сообщений, тест должен быть настроен так, чтобы избежать циклов опроса данных, чтобы получить реалистичные результаты. В конечном счете, лучший вариант — сравнить количество фактически выполненных инструкций ЦП с количеством инструкций ЦП, которые могли быть выполнены в течение теста.Это дает точный процент использования ЦП.
Еще один важный элемент, который следует учитывать, — это тип измеряемых накладных расходов. Например, если тест предназначен для измерения влияния сетевого протокола на загрузку ЦП, тест должен проверять только передачу данных между двумя серверами и не включать дополнительные накладные расходы, такие как MPI, который находится на уровне программного обеспечения. Если цель состоит в том, чтобы измерить накладные расходы программной инфраструктуры, такой как MPI, следует использовать тест MPI, но в этом случае необходимо использовать правильные MPI с правильной разгрузкой, если они существуют.Не все MPI поддерживают различную аппаратную разгрузку, поэтому важно остерегаться условий тестирования.
Итак, теперь, когда ясно, как точно измерить загрузку ЦП, остается вопрос: что лучше: разгрузка или загрузка? Мы провели несколько тестов пропускной способности между серверами, подключенными к EDR InfiniBand и проприетарной альтернативе Omni-Path.
Тесты включали передачу данных типа «отправка-прием» с максимальной скоростью, поддерживаемой каждым межсоединением (~ 100 Гбит / с), при измерении загрузки ЦП (таблица 1).При скорости передачи данных 100 Гбит / с InfiniBand потреблял всего 0,8 процента загрузки ЦП, в то время как Omni-Path требовал 59 процентов загрузки ЦП для той же задачи. Таким образом, доступность ЦП для приложения в случае InfiniBand составляет 99,2 процента, в то время как для Omni-Path приложениям доступно только 40,4 процента циклов ЦП. Кроме того, мы измерили частоту ЦП в каждом из случаев, поскольку ЦП может снизить свою частоту для экономии энергии, когда нет необходимости работать на полной скорости.В случае InfiniBand частота ЦП могла упасть до 59 процентов от номинальной частоты, чтобы обеспечить энергосбережение. В случае Omni-Path, с другой стороны, ЦП работал на полной скорости, поэтому энергосбережения достичь не удалось.
Таблица 1 — Сравнение загрузки ЦП
Инструмент, который использовался для просмотра статистики ЦП, представлял собой набор инструментов Intel Performance Counter Monitor. Инструмент предоставляет более богатый набор измерений, которые предоставляют подробный статус системы.Используя этот инструмент, мы обнаружили, что Omni-Path на самом деле не достигает скорости 100 Гбит / с, но немного не достигает скорости 95 Гбит / с. Статистика AFREQ сообщала о частоте ЦП, которая была динамически установлена во время теста. Мы также смогли просмотреть количество итераций и активных циклов, используемых для различных протоколов межсоединений (таблица 2).
Таблица 2 — Статистика инструмента Intel Performance Counter Monitor
Более того, когда InfiniBand реализуется на интеллектуальных устройствах в рамках архитектуры Co-Design, он может дополнительно снизить накладные расходы на ЦП, также разгрузив операции MPI.Конечно, чтобы измерить это, тест должен обязательно включать программный уровень в тест, чтобы получить точный реальный результат. В будущем мы планируем провести различные дополнительные тесты на разных уровнях приложений, чтобы продемонстрировать значительные преимущества InfiniBand.
В конечном счете, InfiniBand реализует разгрузку специально для того, чтобы уменьшить накладные расходы на ЦП, и, как показывает приведенное здесь тестирование, он работает точно так, как был разработан. Если кто-то показывает результаты, свидетельствующие об обратном, стоит изучить обстоятельства тестирования, чтобы лучше понять, как были достигнуты результаты.По всей вероятности, результаты вводят в заблуждение и не точно отражают реальные условия.
Как обрабатывать предупреждения о высокой загрузке ЦП
Наблюдать за высокой загрузкой ЦП на сетевом устройстве всегда неприятно. Чем тяжелее работает устройство, тем больше вероятность того, что что-то пойдет не так.
Иногда ожидается дополнительное использование, например, когда кластер хранения выполняет резервное копирование вне площадки. Но в других случаях не сразу понятно, что это могло быть.
Сегодня мы рассмотрим несколько распространенных причин высокой загрузки ЦП на сетевых устройствах и способы их устранения.
Что вам сообщает ваше устройство?
Практически каждому, кто какое-то время работал на компьютере, приходилось открывать диспетчер задач, чтобы узнать, какой процесс замедляет их работу. Многие сетевые устройства тоже позволяют это делать.
Например, на устройстве Cisco, работающем под управлением IOS, вы можете запустить «показать процессы cpu sorted 5sec», чтобы просмотреть отсортированный список процессов, потребляющих наибольшую или наименьшую нагрузку на ЦП за пятисекундный интервал.
Google включает пять основных названий процессов с такими ключевыми словами, как «high cpu». Вопросы, на которые вы хотите ответить:
- Считается ли процент использования, который вы видите, нормальным?
- Что сделали другие для решения этой проблемы?
Были ли изменения в конфигурации в последнее время?
Одна из первых вещей, которую нужно определить, — это были ли недавно внесены какие-либо изменения в конфигурацию устройства. Есть несколько способов выяснить это:
- Перейдите к панели управления устройства в Auvik.Перейдите в Документацию> Конфигурации. Посмотрите, не производилась ли недавняя резервная копия конфигурации. Если есть, используйте функцию сравнения Auvik, чтобы увидеть, что было вставлено, удалено или изменено в конфигурации устройства.
- Если у вас включено предупреждение о резервном копировании конфигурации для рассматриваемой учетной записи клиента, проверьте свой почтовый ящик или PSA на предмет недавно сгенерированных предупреждений для этого устройства.
Если изменения были внесены, возможно, они влияют на загрузку ЦП. Используйте функцию восстановления конфигурации Auvik, чтобы отменить изменения.Или вручную отмените изменения с помощью графического интерфейса или интерфейса командной строки устройства.
Уменьшается ли загрузка ЦП? В противном случае, скорее всего, дело не в изменении конфигурации. Перейдем к следующей возможной причине.
Были ли изменения уровня 1 в последнее время?
Проверьте топологию вашей сети. Ищите предупреждения, такие как «Несоответствие статуса интерфейса» на коммутаторе за последние несколько дней или недель. Кабели были перемещены?
Что нужно учитывать:
- Ищите подозрительные устройства, которые выглядят неуместно.Они толкают много трафика?
- Если были внесены изменения в проводку, попробуйте отменить их во время соответствующего периода обслуживания, чтобы увидеть, коррелирует ли это со снижением загрузки ЦП.
Вам нужно увеличение?
Если количество устройств в сети или объем трафика неуклонно растет, очевидно, что это устройство будет облагаться более высокими налогами. Это может быть случай:
- Увеличение пропускной способности
- Обработка пакетов, например формирователи QoS и контроль
- Заполнение таблицы маршрутизации
- Вспомогательные службы, такие как DNS, DHCP или списки контроля доступа.
- Можно что-нибудь еще куда нибудь выгрузить? Например, если ваш перегруженный брандмауэр обрабатывает DNS и DHCP для большого количества подсетей, можно ли переложить часть этой работы на коммутатор уровня 3?
- Процессы с тяжелым шифрованием, такие как SNMPv3 или большое количество сеансов SSH с устройством.
Если какая-либо из этих вещей является виновником, вам в конечном итоге потребуется выделить больше ресурсов на существующую платформу или делегировать службы другим устройствам или машинам.
Вы видите узкие места?
Когда пакеты не проходят свободно, они ставятся в очередь. Большой объем буферизации занимает центральный процессор. Общие причины постановки в очередь включают большие объемы трафика от быстрого интерфейса, пытающегося пройти через гораздо более медленный.
Медленное подключение к Интернету, которое всегда исчерпано, вызовет большую буферизацию. Вашему клиенту может быть рекомендовано обновить ссылку. Если это локальный канал, можно рассмотреть возможность увеличения размера канала за счет агрегации каналов или объединения сетевых адаптеров.
Команды, такие как «показать память» и «показать буферы», могут помочь подтвердить подозрения на наличие узкого места.
Вы видите широковещательные штормы?
Всплески трафика от таких протоколов, как ARP или Ethernet, могут очень быстро увеличить нагрузку на ЦП. Например, если вы видите много широковещательного трафика на определенном интерфейсе, возможно, стоит выполнить зеркалирование порта для затронутого интерфейса, а затем проанализировать трафик с помощью такого инструмента, как Wireshark.
В зависимости от того, что вы найдете, вы можете попробовать следующее:
- Включите управление штормом Ethernet на ваших интерфейсах, чтобы автоматически отключать затронутые порты при обнаружении большого объема трафика.Это помогает предотвратить сбой в сети.
- Уменьшите динамический кэш ARP, особенно если вы находитесь в среде с большим оттоком устройств.
Были ли в последнее время изменения связующего дерева?
Протокол связующего дерева предотвращает образование петель уровня 2.
Обычно связующее дерево — это процесс, который выполняется программно и не использует аппаратную разгрузку. Чем больше виртуальных локальных сетей и активных интерфейсов выделено на коммутаторе, тем больше процессорного времени требуется для согласования и перенаправления трафика при изменении топологии.
Если вы видите большое количество изменений связующего дерева в сети, вероятно, это усложняет работу вашего процессора.
Включить разгрузку ЦП
Некоторые устройства позволяют выполнять определенные функции с помощью программного обеспечения (с использованием ЦП устройства) или аппаратного обеспечения (с использованием микросхем ASIC). По возможности переносите задачи с ЦП на другое выделенное оборудование.
Обратитесь в службу поддержки вашего поставщика
Если вы выполнили расследование и все еще не знаете причину высокой загрузки ЦП, группа поддержки устройства может пролить свет на это.Иногда возникают программные ошибки или очень специфическая конфигурация устройства, из-за которой что-то убегает. Они постараются воспроизвести проблему самостоятельно и определить первопричину и решение.
Страница не найдена
ДокументыМоя библиотека
раз- Моя библиотека

Об авторе