Файл роботс: Использование файла robots.txt — Вебмастер. Справка
Использование файла robots.txt — Вебмастер. Справка
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
При очередном обходе сайта робот Яндекса загружает файл robots.txt. Если при последнем обращении к файлу, страница или раздел сайта запрещены, робот не проиндексирует их.
- Требования к файлу robots.txt
- Рекомендации по наполнению файла
- Использование кириллицы
- Как создать robots.txt
- Вопросы и ответы
Роботы Яндекса корректно обрабатывают robots.txt, если:
Размер файла не превышает 500 КБ.
Это TXT-файл с названием robots — robots.txt.
Файл размещен в корневом каталоге сайта.
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK.

Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots.txt правила. |
| Disallow | Запрещает индексирование разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay | Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |
* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы Disallow: /bin/ # запрещает ссылки из "Корзины с товарами".
 Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска
Disallow: /admin/ # запрещает ссылки из панели администратора
Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта
Clean-param: ref /some_dir/get_book.pl
Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска
Disallow: /admin/ # запрещает ссылки из панели администратора
Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта
Clean-param: ref /some_dir/get_book.plРоботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно: User-agent: Yandex Disallow: /корзина Sitemap: сайт.рф/sitemap.xml #Верно: User-agent: Yandex Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
В текстовом редакторе создайте файл с именем robots.
txt и укажите в нем нужные вам директивы.Проверьте файл в Вебмастере.
Положите файл в корневую директорию вашего сайта.
 txt и укажите в нем нужные вам директивы.
txt и укажите в нем нужные вам директивы.Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
Сайт или отдельные страницы запрещены в файле robots.txt, но продолжают отображаться в поиске
Как правило, после установки запрета на индексирование каким-либо способом исключение страниц из поиска происходит в течение двух недель. Вы можете ускорить этот процесс.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
Что такое robots.txt и зачем вообще нужен индексный файл
Файл robots.txt вместе с xml-картой несёт, пожалуй, самую важную информацию о ресурсе: он показывает роботам поисковых систем, как именно «читать» сайт, какие страницы важны, а какие следует пропустить. Еще robots.txt — первая страница, на которую стоит смотреть, если на сайт внезапно упал трафик.
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать. Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt.
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822.
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.

При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается. Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Зачем нужен файл robots.
 txt
txtНапример, иногда роботам не стоит посещать:
- страницы с личной информацией пользователей на сайте;
- страницы с разнообразными формами отправки информации;
- сайты-зеркала;
- страницы с результатами поиска.
Важно: даже если страница находится в файле robots.txt, существует вероятность, что она появится в выдаче, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
Так роботы поисковых систем видят сайт с файлом robots.txt и без него:
Без robots.txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
Так робот поисковых систем видит файл robots.txt:
Google обнаружил файл robots.txt на сайте и нашел правила, по которым следует сканировать страницы сайта
Как создать файл robots.txt
С помощью блокнота, Notepad, Sublime, либо любого другого текстового редактора.
В содержании файла должны быть прописаны инструкция User-agent и правило Disallow, к тому же есть еще несколько второстепенных правил.
User-agent — визитка для роботов
User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в файле robots.txt. На данный момент известно 302 поисковых робота. Чтобы не прописывать всех по отдельности, стоит использовать запись:
Она говорит о том, что мы указываем правила в robots.txt для всех поисковых роботов.
Для Google главным роботом является Googlebot. Если мы хотим учесть только его, запись в файле будет такой:
В этом случае все остальные роботы будут сканировать контент на основании своих директив по обработке пустого файла robots.txt.
Для Yandex главным роботом является… Yandex:
Другие специальные роботы:
- Mediapartners-Google — для сервиса AdSense;
- AdsBot-Google — для проверки качества целевой страницы;
- YandexImages — индексатор Яндекс.Картинок;
- Googlebot-Image — для картинок;
- YandexMetrika — робот Яндекс.Метрики;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YaDirectFetcher — робот Яндекс. Директа;
- Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
- YandexMarket— робот Яндекс.Маркета;
- YandexNews — робот Яндекс.Новостей;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы;
- YandexPagechecker — валидатор микроразметки;
- YandexCalendar — робот Яндекс.Календаря.
 Директа;
Директа;Disallow — расставляем «кирпичи»
Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
Такая запись открывает для сканирования весь сайт:
А эта запись говорит о том, что абсолютно весь контент на сайте запрещен для сканирования:
Ее стоит использовать, если сайт находится в процессе доработок, и вы не хотите, чтобы он в нынешнем состоянии засветился в выдаче.
Важно снять это правило, как только сайт будет готов к тому, чтобы его увидели пользователи. К сожалению, об этом забывают многие вебмастера.
Пример. Как прописать правило Disallow, чтобы дать инструкции роботам не просматривать содержимое папки /papka/:
Чтобы роботы не сканировали конкретный URL:
Чтобы роботы не сканировали конкретный файл:
Чтобы роботы не сканировали все файлы определенного разрешения на сайте:
Данная строка запрещает индексировать все файлы с расширением .gif
Allow — направляем роботов
Allow разрешает сканировать какой-либо файл/директиву/страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы с /catalog, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:
Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для страницы подходит несколько правил, робот выбирает последнее правило в отсортированном списке.
Host — выбираем зеркало сайта
Host — одно из обязательных для robots.txt правил, оно сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
Зеркало сайта — точная или почти точная копия сайта, доступная по разным адресам.
Робот не будет путаться при нахождении зеркал сайта и поймет, что главное зеркало указано в файле robots.txt. Адрес сайта указывается без приставки «https://», но если сайт работает на HTTPS, приставку «https://» указать нужно.
Как необходимо прописать это правило:
Пример файла robots.txt, если сайт работает на протоколе HTTPS:
Sitemap — медицинская карта сайта
Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу https://site.ua/sitemap.xml. При каждом обходе робот будет смотреть, какие изменения вносились в этот файл, и быстро освежать информацию о сайте в базах данных поисковой системы.
Инструкция должна быть грамотно вписана в файл:
Crawl-delay — секундомер для слабых серверов
Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта. Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Clean-param — охотник за дублирующимся контентом
Clean-param помогает бороться с get-параметрами для избежания дублирования контента, который может быть доступен по разным динамическим адресам (со знаками вопроса). Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Допустим, страница доступна по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае файл robots.txt будет выглядеть так:
Здесь ref указывает, откуда идет ссылка, поэтому она записывается в самом начале, а уже потом указывается остальная часть адреса.
Но прежде чем перейти к эталонному файлу, необходимо еще узнать о некоторых знаках, которые применяются при написании файла robots. txt.
txt.
Символы в robots.txt
Основные символы файла — «/, *, $, #».
С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами. Например, если стоит один слеш в правиле Disallow, мы запрещаем сканировать весь сайт. С помощью двух знаков слэш можно запретить сканирование какой-либо отдельной директории, например: /catalog/.
Такая запись говорит, что мы запрещаем сканировать все содержимое папки catalog, но если мы напишем /catalog, запретим все ссылки на сайте, которые будут начинаться на /catalog.
Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» ограничивает действия знака звездочки. Если необходимо запретить все содержимое папки catalog, но при этом нельзя запретить урлы, которые содержат /catalog, запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые вебмастер оставляет для себя или других вебмастеров. Робот не будет их учитывать при сканировании сайта.
Робот не будет их учитывать при сканировании сайта.
Например:
Как выглядит идеальный robots.txt
Такой файл robots.txt можно разместить почти на любом сайте:
Файл открывает содержимое сайта для индексирования, прописан хост и указана карта сайта, которая позволит поисковым системам всегда видеть адреса, которые должны быть проиндексированы. Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Но не спешите копировать содержимое файл к себе — для каждого сайта должны быть прописаны уникальные правила, которые зависит от типа сайта и CMS. поэтому тут стоит вспомнить все правила при заполнении файла robots.txt.
Как проверить файл robots.txt
Если хотите узнать, правильно ли заполнили файл robots.txt, проверьте его в инструментах вебмастеров Google и Яндекс. Просто введите исходный код файла robots.txt в форму по ссылке и укажите проверяемый сайт.
Как не нужно заполнять файл robots.txt
Часто при заполнении индексного файла допускаются досадные ошибки, причем они связаны с обычной невнимательностью или спешкой. Чуть ниже — чарт ошибок, которые я встречала на практике.
Чуть ниже — чарт ошибок, которые я встречала на практике.
1. Перепутанные инструкции:
Правильный вариант:
2. Запись нескольких папок/директорий в одной инструкции Disallow:
Такая запись может запутать поисковых роботов, они могут не понять, что именно им не следует индексировать: то ли первую папку, то ли последнюю, — поэтому нужно писать каждое правило отдельно.
3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то иначе.
4. Нельзя оставлять пустым правило User-agent — нужно сказать, какой робот должен учитывать прописанные в файле правила.
5. Лишние знаки в файле (слэши, звездочки).
6. Добавление в файл страниц, которых не должно быть в индексе.
Нестандартное применение robots.txt
Кроме прямых функций индексный файл может стать площадкой для творчества и способом найти новых сотрудников.
Вот сайт, в котором robots.txt сам является маленьким сайтом с рабочими элементами и даже рекламным блоком.
Хотите что-то поинтереснее? Ловите ссылку на robots.txt со встроенной игрой и музыкальным сопровождением.
Многие бренды используют robots.txt, чтобы еще раз заявить о себе:
В качестве площадки для поиска специалистов файл используют в основном SEO-агентства. А кто же еще может узнать о его существовании? 🙂
А у Google есть специальный файл humans.txt, чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.
Когда у вебмастера появляется достаточно свободного времени, он часто тратит его на модернизацию robots.txt:
Хотите, чтобы все страницы вашего сайта заходили в индекс быстро? Мы выберем для вас оптимальную стратегию SEO-продвижения:
Хочу быстро найти клиентов онлайн
Выводы
С помощью Robots.txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.
Правила, они же директивы, они же инструкции файла robots.txt:
- User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в robots.txt.
- Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
- Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу https://site.ua/sitemap.xml.
- Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта.
- Host сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
- Allow разрешает сканировать какой-либо файл/директиву/страницу.
- Clean-param помогает бороться с get-параметрами для избежания дублирования контента.
Знаки при составлении robots.txt:
- Знак доллара «$» ограничивает действия знака звездочки.
- С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами.
- Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
- Решетка «#» используется, чтобы обозначить комментарии, которые пишет вебмастер для себя или других вебмастеров.

Используйте индексный файл с умом — и сайт всегда будет в выдаче.
Что такое файл robots.txt? Рекомендации по синтаксису Robot.txt
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).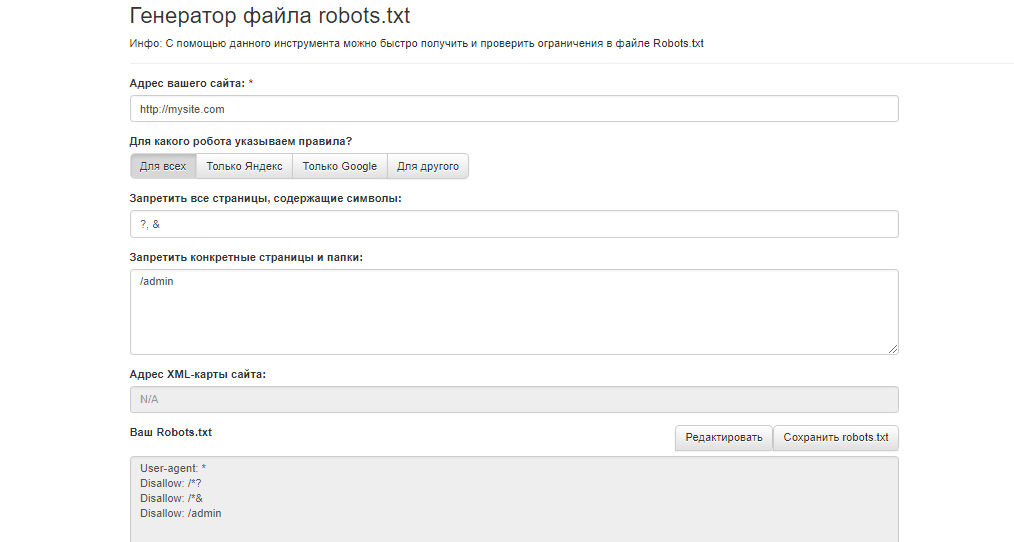
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции по обходу указываются путем «запрета» или «разрешения» поведения определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [имя user-agent]Disallow: [строка URL не сканируется]
Вместе эти две строки считаются полным файлом robots.txt — хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив агента пользователя отображается как отдельный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами агента пользователя каждое правило запрещает или разрешает Только применяется к агентам пользователя, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, сканер будет обращать внимание (и следовать указаниям) только на наиболее конкретные группа инструкций.
Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, сканер будет обращать внимание (и следовать указаниям) только на наиболее конкретные группа инструкций.
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе пользовательских агентов: *.
Пример robots.txt:
Вот несколько примеров robots.txt в действии для сайта www.example.com:
URL-адрес файла robots.txt: www.example.com/robots.txt Блокировка всех поисковых роботов для всего контентаUser-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt означает, что все поисковые роботы не будут сканировать какие-либо страницы на www. example. com, включая домашнюю страницу.
example. com, включая домашнюю страницу.
Агент пользователя: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам просканировать все страницы на www.example.com, включая главную страницу.
Блокировка определенного поискового робота из определенной папкиАгент пользователя: Googlebot Запретить: /example-subfolder/
Этот синтаксис указывает только сканеру Google (имя пользовательского агента Googlebot) не сканировать любые страницы, которые содержать строку URL www.example.com/example-subfolder/.
Блокировка определенного поискового робота на определенной веб-страницеАгент пользователя: Bingbot Запретить: /example-subfolder/blocked-page.html сканирование конкретной страницы по адресу www.example.com/example-subfolder/blocked-page.html.Как работает файл robots.
Поисковые системы выполняют две основные функции:
- Просматривают веб-страницы в поисках контента;
- Индексация этого контента, чтобы его можно было предоставить тем, кто ищет информацию.
Для обхода сайтов поисковые системы следуют ссылкам, чтобы перейти с одного сайта на другой — в конечном счете, сканируя многие миллиарды ссылок и веб-сайтов. Такое поведение сканирования иногда называют «пауками».
После перехода на веб-сайт, но до его сканирования поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.
Другие необходимые сведения о файле robots.txt:
(более подробно обсуждается ниже)
 txt?
txt?  txt), он продолжит сканирование другой информации на сайте.
txt), он продолжит сканирование другой информации на сайте. -
Чтобы найти файл robots.txt, его необходимо поместить в каталог верхнего уровня веб-сайта.
-
Robots.txt чувствителен к регистру: файл должен иметь имя «robots.txt» (не Robots.txt, robots.TXT или другое).
-
Некоторые пользовательские агенты (роботы) могут игнорировать ваш файл robots.txt. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или скребки адресов электронной почты.
-
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого сайта (если этот сайт имеет файл robots.txt!). Это означает, что любой может видеть, какие страницы вы сканируете или не хотите, поэтому не используйте их для сокрытия личной информации пользователя.
-
Каждый поддомен в корневом домене использует отдельные файлы robots.txt. Это означает, что и у blog.example.com, и у example.com должны быть свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
-
Обычно рекомендуется указывать местоположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:

Идентификация критических предупреждений robots.txt с помощью Moz Pro
Функция сканирования сайта Moz Pro проверяет ваш сайт на наличие проблем и выделяет срочные ошибки, которые могут помешать вам появиться в Google. Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Начать мою бесплатную пробную версию
Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt . Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. Среди них:
Среди них:
-
Агент пользователя: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
-
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Запретить:».
-
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
-
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
-
Карта сайта: Используется для вызова местоположения любой карты сайта XML, связанной с этим URL-адресом.
Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
 Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo. Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно блокировать или разрешать, файлы robots.txt могут оказаться довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL-адресов. Google и Bing поддерживают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Этими двумя символами являются звездочка (*) и знак доллара ($).
- * — это подстановочный знак, представляющий любую последовательность символов.
- $ соответствует концу URL-адреса.
Куда идет файл robots.txt на сайте?
Всякий раз, когда они заходят на сайт, поисковые системы и другие поисковые роботы (например, поисковый робот Facebook, Facebot) знают, что нужно искать файл robots.txt. Но они будут искать этот файл только в одном конкретном месте : в основном каталоге (обычно это ваш корневой домен или домашняя страница).
Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует по адресу , скажем, example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots. Чтобы ваш файл robots.txt был найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем вам robots.txt?
Файлы robots.txt контролируют доступ поисковых роботов к определенным областям вашего сайта. Хотя это может быть очень опасным, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение дублирования контента в поисковой выдаче (обратите внимание, что метароботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей инженерной группы)
- Предотвращение отображения страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексации поисковыми системами определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. д.)
- Указание задержки сканирования, чтобы предотвратить перегрузку ваших серверов, когда сканеры загружают несколько фрагментов контента одновременно
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, возможно, вам вообще не нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл robots Moz находится по адресу moz.com/robots.txt.
Если страница .txt не отображается, у вас в настоящее время нет (действующей) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создать его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов robots? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Лучшие практики SEO
-
Убедитесь, что вы не блокируете какой-либо контент или разделы вашего веб-сайта, которые вы хотите сканировать.
-
Ссылки на страницы, заблокированные robots.txt, не будут переходить. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. е. страницы, не заблокированные с помощью robots.txt, мета-роботов или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой вес ссылок не может быть передан с заблокированной страницы на место назначения ссылки. Если у вас есть страницы, на которые вы хотите передать право собственности, используйте другой механизм блокировки, отличный от robots.txt.
-
Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex. -
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность сделать это позволяет вам точно настроить сканирование содержимого вашего сайта.
-
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день. Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить URL-адрес robots.txt в Google.
Robots.
txt против мета-роботов против x-роботов Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это настоящий текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они на самом деле являются, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как meta и x-robots могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте обучение
- Robots Meta Directives
- Каноникализация
- Перенаправление
- Robots Exclusion Protocol
- Руководство для начинающих в SEO. Moz Pro определяет, блокирует ли ваш файл robots.txt доступ поисковой системы к вашему веб-сайту. Попробуйте >>
The Web Robots Pages
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для предоставления инструкций по свой сайт веб-роботам; это называется Исключение роботов Протокол .
Это работает следующим образом: робот хочет просмотреть URL-адрес веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это сделать, он сначала проверяет наличие http://www.example.com/robots.txt и находит:
Агент пользователя: * Запретить: /
«User-agent: *» означает, что этот раздел относится ко всем роботам. «Запретить: /» сообщает роботу, что он не должен посещать страницы на сайте.
При использовании файла /robots.txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш файл /robots.txt. Особенно вредоносные роботы, которые сканируют web на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами не обратит внимания.
- файл /robots.txt является общедоступным. Любой может видеть, какие разделы вашего сервера, который вы не хотите использовать роботами.
Так что не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
- Могу ли я заблокировать только плохих роботов?
- Почему этот робот проигнорировал мой /robots.txt?
- Каковы последствия файла /robots.txt для безопасности?
Детали
/robots.txt является стандартом де-факто и никому не принадлежит. орган стандартов. Есть два исторических описания:
- оригинал 1994 г. Стандарт для роботов Документ об исключении.
- Спецификация Internet Draft 1997 г. Метод для Интернета Управление роботами
Кроме того, есть внешние ресурсы:
- HTML 4.01 Спецификация, Приложение B.4.1
- Википедия - Стандарт исключения роботов
Стандарт /robots.txt активно не разрабатывается. См. Что насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать /robots.txt на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, см.
также FAQ.Как создать файл /robots.txt
Куда поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет файл "/robots.txt" для URL, он удаляет компонент пути из URL (все, начиная с первой косой черты), и помещает "/robots.txt" на свое место.
Например, для "http://www.example.com/shop/index.html будет удалите "/shop/index.html" и замените его на "/robots.txt", и в итоге получится "http://www.example.com/robots.txt".
Итак, как владелец веб-сайта, вы должны поместить его в нужное место на своем веб-сайте. веб-сервер, чтобы этот результирующий URL-адрес работал. Обычно это одно и то же место, где вы размещаете приветствие "index.html" вашего веб-сайта страница. Где именно это находится и как туда поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: "robots.txt", а не "Robots.TXT.
Смотрите также:
- Какую программу следует использовать для создания файла /robots. txt?
- Как использовать /robots.txt на виртуальном хосте?
- Как использовать /robots.txt на общем хосте?
Что положить
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись, имеющую вид:
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /~joe/
В этом примере исключены три каталога.
Обратите внимание, что вам нужна отдельная строка «Запретить» для каждого префикса URL, который вы хотите исключить -- вы не можете сказать "Disallow: /cgi-bin/ /tmp/" на одна линия. Кроме того, в записи может не быть пустых строк, так как они используются для разделения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается либо в User-agent, либо в Disallow линии. '*' в поле User-agent — это специальное значение, означающее «любой робот". В частности, у вас не может быть таких строк, как "User-agent: *bot*", «Запретить: /tmp/*» или «Запретить: *.
gif».То, что вы хотите исключить, зависит от вашего сервера. Все, что прямо не запрещено, считается справедливым игра, чтобы получить. Вот несколько примеров:
Исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Чтобы разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или вообще не используйте его)
Исключить всех роботов из части сервера
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /мусор/
Для исключения одного робота
Агент пользователя: BadBot Запретить: /
Для одного робота
Агент пользователя: Google Запретить: Пользовательский агент: * Запретить: /
Чтобы исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». простой способ - поместить все файлы, которые нужно запретить, в отдельный директории, произнесите "stuff" и оставьте один файл на уровне выше этот каталог:
Пользовательский агент: * Запретить: /~joe/stuff/
В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.
 Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует по адресу , скажем, example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots.
Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует по адресу , скажем, example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots.  д.)
д.) 
 txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.  txt против мета-роботов против x-роботов
txt против мета-роботов против x-роботов 

 также FAQ.
также FAQ. txt?
txt? gif».
gif».
Об авторе