Файл robots: Robots.txt — Как создать правильный robots.txt
Robots.txt — Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebotНиже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Как создать правильный файл robots.txt, настройка, директивы

Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Файл robots.txt — настройка и директивы robots.txt, запрещаем индексацию страниц
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.

Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!
Создаем правильный файл robots.txt — настраиваем индексацию, директивы
- Зачем robots.txt в SEO?
- Создаем robots самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Disallow
- Разрешение индексации Allow
- Директива host robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Robots — это обыкновенный текстовой файл (.txt), который располагается в корне сайта наряду c index.php и другими системными файлами. Его можно загрузить через FTP или создать в файловом менеджере у хост-провайдера. Создается данный файл как обыкновенный текстовой документ с самым простым форматом — TXT. Далее файлу присваивается имя ROBOTS. Выглядит это следующим образом:

(robots.txt в корневой папке WordPress)
После создание самого файла нужно убедиться, что он доступен по ссылке ваш домен/robots.txt. Именно по этому адресу поисковая система будет искать данный файл.
В большинстве систем управления сайтами роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.

Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/
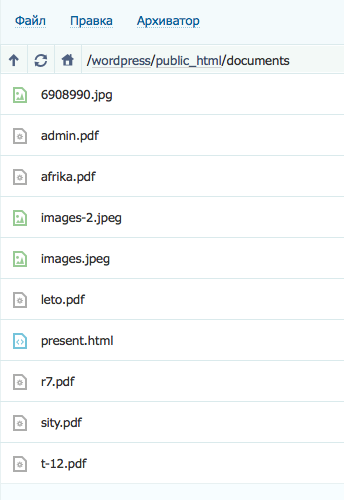
Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &amp;=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&amp;page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»
Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
Правильный файл robots.txt для сайта
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron.phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index.phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml

Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt

Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
что это такое, для чего нужен, как его создать, чем грозит отсутствие этого файла
Тематический трафик – альтернативный подход в продвижении бизнеса

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Robots.txt — это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это — указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие — нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Роботы поисковых систем начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.

Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение .txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.

Такой вариант, наоборот, означает полный запрет индексации для всех.

Запрет на просмотр всего содержимого определенной папки-каталога

Для блокировки одного файла нужно указать его абсолютный путь

Директивы Sitemap, Host

В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.

Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.

Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.

Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
Файл robots.txt-полное руководство
148
Файл robots.txt является одним из основных способов сообщить поисковой системе к каким частям веб-сайта у нее есть доступ. Все ведущие поисковые системы поддерживают основные функциональные возможности, указанные в этом файле, а некоторые из них реагируют на дополнительный набор правил, который также может оказаться полезным.

Это руководство охватывает все особенности использования файла robots.txt в рамках вашего веб-сайта, но хотя все кажется простым, любые ошибки в нем могут серьезно навредить сайту, так что обязательно прочитайте всю статью и убедитесь в том, что все понятно перед тем как погрузиться в написание robots.txt.
«+» краулинговый бюджет
«-» страница остается в результатах поиска
«-» нельзя воспользоваться ценностью ссылки
Проверка файла robots.txt
Что представляет собой файл robots.txt?
Файл robots.txt – текстовый файл, который просматривается веб-пауками и следует строго определенному синтаксису. Этих пауков еще называют роботами. Имя файла и его синтаксис должны быть строго определенны уже просто потому, что он должен быть доступен для считывания компьютерам. Это означает, что права на ошибку попросту нет – все как в двоичной системе исчисления – результат либо 1, либо 0.
Файл robots.txt, ещё называемый стандартом исключений для роботов, представляет собой результат консенсуса между разработчиками первых поисковых роботов. Он не является официально принятым ни одной из организаций по стандартизации, но все основные поисковые системы его придерживаются.
Какие функции выполняет файл robots.txt?
Поисковые системы проводят индексацию страниц в Интернете, используя веб-краулеры, которые перемещаются по ссылкам с сайта A на сайт B, с сайта B на сайт C и т.д. Перед тем как поисковый паук перейдет на любую страницу, ранее не посещаемого им домена, он откроет файл домена robots.txt, благодаря которому поисковая система определит какие URL-адреса на сайте разрешено индексировать.
Поисковые системы кэшируют содержимое файла robots.txt, но как правило обновляют сведения до нескольких раз в день, поэтому изменения вступают в силу довольно быстро.
Где следует размещать файл robots.txt?
Файл robots.txt всегда следует размещать в корневом каталоге вашего домена. Таким образом, если адрес вашего домена www.example.com, файл должен располагаться по адресу http://www.example.com/robots.txt. Но помните! В случае, если ваш домен отвечает на запрос без www., нужно убедиться в том, что по выдаваемому адресу находится тот же самый файл robots.txt! То же самое относится к http и https. Если поисковая система захочет перейти по URL-адресу http://example.com/test, она получит доступ к http://example.com/robots.txt. Если она захочет перейти по тому же адресу, но посредством https, она также получит доступ к файлу robots.txt вашего https сайта, которым является https://example.com/robots.txt.
Кроме того, очень важно, чтобы в названии вашего файла robots.txt не было ошибок. Имя чувствительно к регистру, поэтому вводите его правильно, в противном случае файл не будет выполнять свои функции.
Плюсы и минусы использования файла robots.txt
«+» краулинговый бюджет
Поисковый паук посещает веб-сайт с «разрешением» на сканирование определенного количества страниц, и в SEO это известно, как краулинговый бюджет. Это означает, что при блокировании вами разделов сайта от паука поисковой системы, вы позволите использовать ваш краулинговый бюджет среди других разделов. На первых порах может быть весьма полезно оперативно заблокировать поисковые системы от сканирования некоторых разделов, особенно для сайтов, на которых необходимо провести большую SEO чистку.
Блокировка параметров запроса
Краулинговый бюджет исключительно важен в ситуации, когда ваш сайт, для осуществления фильтрации и сортировки, использует множество параметров строчных запросов. Допустим у вас есть 10 разных параметров запроса, у каждого из них есть свои значения, которые можно как угодно комбинировать. Это приводит к сотням, если не тысячам, возможных URL-адресов. Блокировка всех параметров запроса от сканирования поможет вам сделать так, чтобы поисковая система осуществляла сканирование лишь основных URL-адресов на сайте и не попала в огромную ловушку, созданную вами в случае отказа от блокировки этих параметров.
Эта строка блокирует все URL-адреса вашего сайта, содержащие строчный запрос:
Disallow: /*?*
«-» страница остается в результатах поиска
Несмотря на то, что вы можете воспользоваться файлом robots.txt, чтобы сообщить пауку о запрещенных для сканирования страницах вашего сайта, вы не можете использовать этот файл, чтобы запретить поисковой системе отображать определенные URL-адреса в результатах поиска – иначе говоря, блокировка не будет препятствовать индексации. Если поисковая система найдет достаточно ссылок на этот URL-адрес, она включит его в результаты поиска, просто не будет знать, что находится на странице.
Если хотите заблокировать отображение страницы в результатах поиска наверняка, вам нужно использовать мета-тег robots со значением параметра content=“noindex”. Это значит, что для поиска тега с noindex, поисковой системе нужно иметь возможность доступа к соответствующей странице, поэтому не вздумайте заблокировать ее с помощью robots.txt.
«-» нельзя воспользоваться ценностью ссылки
Если поисковая система не способна просканировать страницу, она не может указывать на ценность конкретной ссылки другим ссылкам на этой странице, а если способна просканировать (не индексировать) – тогда может. Когда страница заблокирована файлом robots.txt, ссылка теряет любую ценность.
Синтаксис файлов robots.txt
Файл robots.txt для WordPress
У нас есть целая статья, посвященная тому, как настроить файл robots.txt для WordPress наилучшим образом. Не забывайте о том, что этот файл можно редактировать.
Файл robots.txt состоит из одного или более наборов инструкций, каждый из которых начинается со строки user-agent. “User-agent” является именем определенного паука, которому адресованы эти наборы. Также можно ограничиться одним набор инструкций для всех поисковых систем, используя метод wild-card для user-agent или определенные наборы инструкций для определенных поисковых систем. Паук поисковой системы всегда будет выбирать набор инструкций, с наибольшим соответствием его названию. Эти наборы выглядят следующим образом (мы расскажем об этом ниже):
User-agent: *
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: bingbot
Disallow: /not-for-bing/
Директивы вроде Allow и Disallow не чувствительны к регистру, так что вам решать строчными или прописными буквами их записывать. Со значениями дела обстоят наоборот, /photo/ и /Photo/ будут восприниматься по-разному. Нам нравится начинать директивы с заглавной буквы, поскольку это упрощает чтение файла (для человека).
Директива User-agent
Каждый набор инструкций (директив) начинается с user-agent, который определяет конкретного паука. Поле агента пользователя сопоставляется с аналогичным полем (как правило больших размеров) конкретного паука. Так, к примеру, у популярнейшего паука от Google, user-agent имеет следующее значение:
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
Таким образом, если вы хотите определять действия такого паука, относительно простой строчки User-agent: Googlebot будет достаточно.
У большинства поисковых систем паук не один. У них определен свой паук для: индексации, рекламных приложений, графики, видео и т.д.
Поисковые системы всегда будут руководствоваться наиболее конкретными наборами инструкций, которые смогут найти. Скажем у вас есть 3: один для *, второй для Googlebot и третий для Googlebot-News. Если бот наткнется на ту, пользовательский агент которой Googlebot-Video, он станет придерживаться ограничений, установленных Googlebot. Бот с пользовательским агентом Googlebot-News будет руководствоваться более специфическими директивами Googlebot-News.
Самые популярные пользовательские агенты для поисковых роботов
Вот список пользовательских агентов, которые можно указать в файле robots.txt, для достижения «гармонии» с наиболее распространенными поисковыми системами:
| Поисковая система | Область применения | Пользовательский агент (user-agent) |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot | |
| Images | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | General | slurp |
| Yandex | General | yandex |
Директива Disallow
Второй строкой в любом наборе инструкций является Disallow. У вас может быть более одной подобной строки, с помощью которых вы определите к каким разделам сайта конкретные пауки не могут получить доступ. Пустая строка Disallow означает отсутствие запретов с вашей стороны, проще говоря у паука остается возможность доступа к любым разделам вашего сайта.
В приведенном ниже примере всем поисковым системам, которые “прислушиваются” к файлу robots.txt, запрещается сканирование вашего сайта.
User-agent: *
Disallow: /
А в этом примере, в котором всего-то на один символ меньше, любой поисковой системе дозволено провести его полное сканирование.
User-agent: *
Disallow:
В очередном примере, указанном ниже, поисковой системе Google запрещено сканировать на вашем сайте директорию Photo и все что в ней находится.
User-agent: googlebot
Disallow: /Photo
Это означает, что все подкаталоги в директории /Photo избегут сканирования. Но поскольку строки в коде чувствительны к регистру, поисковой системе Google не будет запрещен доступ к директории /photo.
Как применять метод wildcard (регулярные выражениями)
Стандарт файла robots.txt «официально» не поддерживает регулярные выражения (wild-card метод), однако все основные поисковые системы их отлично понимают, что дает вам возможность ограничивать доступ к группам файлов, воспользовавшись следующими строками:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
В приведенном выше примере, символ * можно представить в виде любого соответствующего имени файла. Обратите внимание на то, что оставшаяся часть строки все еще чувствительна к регистру, таким образом вторая строка в примере не запретит сканирование файла с названием /copyrighted-images/example.JPG.
Некоторые поисковые системы, вроде Google, допускают использование более сложных регулярных выражений, но имейте ввиду, что есть и такие, которые могут не понять такой логики. Наибольшая польза, которую можно из всего этого извлечь заключается в функции символа $, указывающего на окончание URL-адреса. В следующем примере все наглядно показано:
Disallow: /*.php$
Запись означает, что адрес /index.php индексировать запрещено, а адрес /index.php?p=1 разрешено. Конечно же пользу от этого можно извлечь лишь в очень специфических обстоятельствах, а еще это довольно опасно: легко можно открыть доступ к вещам, открывать доступ, к которым на самом деле не хотелось.
Нестандартные директивы robots.txt
Наряду с директивами Disallow и User-agent существует ряд других доступных для использования. Они не поддерживаются всеми краулерами, поэтому вам следует учитывать имеющиеся ограничения.
Директива Allow
Говорить о ней начали уже давно, несмотря на отсутствие оригинальной «спецификации». Похоже, что большинство поисковых систем ее понимают, что позволяет писать простые и очень читабельные инструкции вроде этих:
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Единственным способом добиться такого результата без использования директивы allow является индивидуальное применение директивы disallow к каждому файлу, размещенному в каталоге wp-admin.
Директива host
Поддерживаемая Yandex (и не поддерживаемая Google, чтобы там не писали в некоторых статьях), эта директива позволяет определить какой из адресов example.com или www.example.com будет отображать поисковая система. Желаемого результата можно добиться, просто вписав следующую строку:
host: example.com
Но поскольку ее поддерживает лишь Yandex, мы бы не советовали на нее полагаться, тем более что данная директива, к тому же не позволяет выбрать схему (http или https). Более правильным решением, подходящим для всех поисковых систем, является 301 редирект имен всех хостов, которые вы не хотите индексировать на желаемый в плане индексации адрес. Мы перенаправляем наш www. сайт на сайт без www.
Директива crawl-delay
Поисковики Yahoo!, Bing и Yandex, что касается индексации, порой могут быть откровенно «голодными», но к счастью все они откликаются на директиву crawl-delay, которая несколько их сдерживает. И хотя алгоритмы прочтения директивы для этих поисковых систем отличаются, конечный результат в целом один и тот же.
Строка, указанная ниже даст поисковым системам Yahoo! и Bing указание ожидать 10 секунд после каждого действия направленного на индексацию страницы, Yandex же будет получать доступ к странице раз в 10 секунд. Это семантические различия, но все же любопытные. Вот пример строки crawl-delay:
crawl-delay: 10
Пользуясь директивой crawl-delay соблюдайте осторожность. Устанавливая ее значение на 10 секунд, вы позволите этим поисковым системам индексировать лишь 8640 страниц в день. Это может показаться достаточным для небольшого сайта, но для больших это не так уж и много. С другой стороны, практически полное отсутствие трафика от этих поисковиков, хорошо скажется на пропускной способности сайта.
Директива sitemap для XML Sitemaps
С помощью директивы sitemap можно сообщить поисковым системам (в особенности таким как Bing, Yandex и Google) где находятся файлы XML sitemap. Разумеется, вы также можете открыть доступ к XML sitemaps для каждой поисковой системы, пользуясь соответствующими инструментариями для веб-мастеров, и мы это настоятельно рекомендуем, поскольку подобное программное обеспечение предоставит большое количество ценной информации о вашем сайте. Если вы не хотите прислушиваться к нашему совету, тогда хорошим и быстрым альтернативным решением будет внести строку sitemap в свой файл robots.txt.
Проверьте файл robots.txt
Существует множество инструментов, которые могут помочь вам провести проверку своего robots.txt файла, но, когда дело доходит до проверки директив, мы всегда предпочитаем обращаться к первоисточнику. В распоряжении Google имеется инструмент для тестирования файлов robots.txt, который хранится в консоли самой поисковой системы (под «Crawl menu») и мы настоятельно рекомендуем им воспользоваться:

В обязательном порядке тщательно протестируйте внесенные изменения перед тем как начать использовать файл! Вы можете оказаться в числе тех, кто с помощью robots.txt случайно подверг весь свой сайт забвению среди поисковых систем.
Полезно знать: Файл robots.txt wordpress — пример отличного SEO
Источник
Объяснение и иллюстрация файла robots.txt
«Используйте файл robots.txt на своем веб-сервере.
— из руководства Google для веб-мастеров 1
Что такое файл robots.txt?
- Файл robots.txt — это простой текстовый файл, размещаемый на вашем веб-сервере, который сообщает веб-сканерам, таким как робот Googlebot, следует ли им обращаться к файлу или нет.
Базовые примеры robots.txt
Вот несколько распространенных роботов.txt (они будут подробно описаны ниже).
Блокировать одну папку
User-agent: *
Disallow: / folder /
Блок одного файла
User-agent: *
Disallow: /file.html
Зачем вам нужен файл robots.txt?
- Неправильное использование файла robots.txt может снизить ваш рейтинг
- Файл robots.txt управляет тем, как пауки поисковых систем видят ваши веб-страницы и взаимодействуют с ними.
- Этот файл упоминается в нескольких рекомендациях Google.
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальной частью работы поисковых систем.
Совет: чтобы узнать, есть ли ваш robots.txt блокирует любые важные файлы, используемые Google, используйте инструмент рекомендаций Google.
Пауки поисковых систем
Первое, на что паук поисковой системы, такой как робот Googlebot, обращает внимание при посещении страницы, — это файл robots.txt.
Он делает это, потому что хочет знать, есть ли у него разрешение на доступ к этой странице или файлу. Если в файле robots.txt указано, что он может входить, паук поисковой системы переходит к файлам страниц.
Если у вас есть инструкции для робота поисковой системы, вы должны сообщить ему эти инструкции.Вы делаете это с помощью файла robots.txt. 2
Приоритеты вашего сайта
Есть три важных вещи, которые должен сделать любой веб-мастер, когда дело касается файла robots.txt.
- Определите, есть ли у вас файл robots.txt
- Если он у вас есть, убедитесь, что он не вредит вашему рейтингу и не блокирует контент, который вы не хотите блокировать
- Определите, нужен ли вам файл robots.txt
Определение наличия файла robots.txt
Вы можете ввести веб-сайт ниже, нажать «Перейти», и он определит, есть ли на сайте файл robots.txt, и отобразит то, что написано в файле (результаты отображаются здесь, на этой странице) .
Если вы не хотите использовать вышеуказанный инструмент, вы можете проверить его в любом браузере. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
www.yourwebsite.com/robots.txt
Если у вас там есть файл, то это ваш файл robots.txt. Вы либо найдете файл со словами, либо найдете файл без слов, либо вообще не найдете файл.
Определите, блокирует ли ваш robots.txt важные файлы
Вы можете использовать инструмент рекомендаций Google, который предупредит вас, если вы блокируете определенные ресурсы страницы, которые необходимы Google для понимания ваших страниц.
Если у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для тестирования своих роботов.txt файл. Инструкции для этого можно найти здесь (инструмент не общедоступен — требуется логин) .
Чтобы полностью понять, не блокирует ли ваш файл robots.txt что-либо, вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Мы рассмотрим это ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не понадобится иметь файл robots.txt на вашем сайте. На самом деле, зачастую он вам не нужен.
Причины, по которым вы можете захотеть иметь robots.txt файл:
- У вас есть контент, который вы хотите заблокировать для поисковых систем
- Вы используете платные ссылки или рекламу, требующую специальных инструкций для роботов
- Вы хотите настроить доступ к своему сайту для надежных роботов
- Вы разрабатываете действующий сайт, но не хотите, чтобы поисковые системы еще индексировали его
- Они помогают следовать некоторым рекомендациям Google в определенных ситуациях.
- Вам нужно частично или полностью вышеперечисленное, но у вас нет полного доступа к вашему веб-серверу и его настройке
Каждой из вышеперечисленных ситуаций можно управлять другими методами, но с помощью robots.txt — хорошее центральное место для заботы о них, и у большинства веб-мастеров есть возможность и доступ, необходимые для создания и использования файла robots.txt.
Причины, по которым вы можете не иметь файл robots.txt:
- Просто и без ошибок
- У вас нет файлов, которые вы хотите заблокировать для поисковых систем.
- Вы не попадете ни в одну из перечисленных выше причин, по которым у вас есть файл robots.txt.
Не иметь роботов — это нормально.txt файл.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как робот Google, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Как сделать файл robots.txt
Если вы умеете печатать или копировать и вставлять, вы также можете создать файл robots.txt.
Файл представляет собой просто текстовый файл, что означает, что вы можете использовать блокнот или любой другой текстовый редактор для его создания. Вы также можете сделать их в редакторе кода. Вы даже можете «скопировать и вставить» их.
Вместо того, чтобы думать: «Я создаю файл robots.txt», просто подумайте: «Я пишу заметку», это практически один и тот же процесс.
Что должен сказать robots.txt?
Это зависит от того, что вы хотите.
Все инструкции robots.txt приводят к одному из следующих трех результатов
- Полное разрешение: все содержимое может сканироваться.
- Полное запрещение: сканирование контента невозможно.
- Условное разрешение: директивы в файле robots.txt определяют возможность сканирования определенного контента.
Давайте объясним каждый.
Полное разрешение — все содержимое можно сканировать
Большинство людей хотят, чтобы роботы посещали все на их веб-сайтах. Если это так и вы хотите, чтобы робот индексировал во всех частях вашего сайта есть три варианта, чтобы роботы знали, что им рады.
1) Нет файла robots.txt
Если на вашем сайте нет файла robots.txt, вот что происходит …
В гости приходит робот вроде Googlebot. Ищет файл robots.txt. Он не находит его, потому что его там нет. Затем робот чувствует бесплатно посещать все ваши веб-страницы и контент, потому что это то, на что он запрограммирован в данной ситуации.
2) Создайте пустой файл и назовите его robots.txt
Если на вашем веб-сайте есть файл robots.txt, в котором ничего нет, то происходит следующее …
В гости приходит робот вроде Googlebot.Ищет файл robots.txt. Он находит файл и читает его. Читать нечего, поэтому После этого робот может свободно посещать все ваши веб-страницы и контент, потому что именно на это он запрограммирован в данной ситуации.
3) Создайте файл с именем robots.txt и напишите в нем следующие две строки …
Если на вашем веб-сайте есть файл robots.txt с этими инструкциями, происходит следующее …
В гости приходит робот вроде Googlebot. Он ищет роботов.txt файл. Он находит файл и читает его. Читает первую строку. Затем это читает вторую строку. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что вы ему сказали (я объясню это ниже).
Полное запрещение — сканирование содержимого невозможно
Предупреждение. Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Чтобы заблокировать доступ всех известных «пауков» поисковых систем к вашему сайту, в вашем файле robots.txt:
Не рекомендуется делать это, поскольку это не приведет к индексации ни одной из ваших веб-страниц.
Инструкции robot.txt и их значение
Вот объяснение того, что означают разные слова в файле robots.txt
Пользовательский агент
Часть «User-agent» предназначена для указания направления к конкретному роботу, если это необходимо. Есть два способа использовать это в ваш файл.
Если вы хотите сообщить всем роботам одно и то же, поставьте «*» после «User-agent». Это будет выглядеть так…
Вышеупомянутая строка говорит: «Эти указания применимы ко всем роботам».
Если вы хотите что-то сказать конкретному роботу (в этом примере роботу Google), это будет выглядеть так …
В строке выше говорится, что «эти указания относятся только к роботу Googlebot».
Запрещено:
Часть «Запретить» предназначена для указания роботам, в какие папки им не следует смотреть. Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали фотографии на вашем сайте, вы можете поместить эти фотографии в одну папку и исключить ее.
Допустим, вы поместили все эти фотографии в папку под названием «фотографии». Теперь вы хотите запретить поисковым системам индексировать эту папку.
Вот как должен выглядеть ваш файл robots.txt в этом сценарии:
User-agent: *
Disallow: / photos
Две вышеуказанные строки текста в файле robots.txt не позволят роботам посетить папку с фотографиями. «Пользовательский агент *» часть говорит, что «это относится ко всем роботам». В части «Запретить: / фотографии» указано «не посещать и не индексировать папку с моими фотографиями».
Инструкции для робота Googlebot
Робот, который Google использует для индексации своей поисковой системы, называется Googlebot. Он понимает еще несколько инструкций, чем другие роботы.
Помимо «Имя пользователя» и «Запретить» робот Googlebot также использует инструкцию Разрешить.
Разрешить
Инструкции «Разрешить:» позволяют сообщить роботу, что можно видеть файл в папке, которая была «Запрещена». по другим инструкциям. Чтобы проиллюстрировать это, давайте возьмем приведенный выше пример, когда робот не посещает и не индексирует ваши фотографии.Мы поместили все фотографии в одну папку под названием «фотографии» и создали файл robots.txt, который выглядел так …
User-agent: *
Disallow: / photos
Теперь предположим, что в этой папке есть фотография с именем mycar.jpg, которую вы хотите проиндексировать роботом Googlebot. С Разрешить: инструкции, мы можем сказать Googlebot сделать это, это будет выглядеть так …
User-agent: *
Disallow: / photos
Allow: /photos/mycar.jpg
Это сообщит роботу Googlebot, что он может посещать mycar.jpg «в папке с фотографиями, хотя в противном случае папка» фото » Исключенный.
Тестирование файла robots.txt
Чтобы узнать, заблокирована ли отдельная страница файлом robots.txt, вы можете использовать этот технический инструмент SEO, который сообщит вам, блокируются ли файлы, важные для Google, а также отобразит содержимое файла robots.txt.
Ключевые концепции
- Если вы используете файл robots.txt, убедитесь, что он используется правильно
- Неправильный robots.txt может заблокировать индексирование вашей страницы роботом Googlebot
- Убедитесь, что вы не блокируете страницы, необходимые Google для ранжирования ваших страниц.
Патрик Секстон
.
Страницы веб-роботов
О /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для инструкций по их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет перейти по URL-адресу веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это произойдет, он первым проверяет http://www.example.com/robots.txt и находит:
Пользовательский агент: * Запретить: /
«User-agent: *» означает, что этот раздел применим ко всем роботам.»Disallow: /» сообщает роботу, что он не должен посещать никакие страницы на сайте.
При использовании /robots.txt следует учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, сканирующие Интернет на наличие уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами не обращаю внимания.
- файл /robots.txt является общедоступным. Все могут видеть, какие разделы вашего сервера вы не хотите, чтобы роботы использовали.
Так что не пытайтесь использовать /robots.txt для сокрытия информации.
Смотрите также:
Реквизиты
Файл /robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Вдобавок есть внешние ресурсы:
Стандарт /robots.txt активно не развивается. См. Как насчет дальнейшего развития /robots.txt? для более подробного обсуждения.
На оставшейся части этой страницы дается обзор того, как использовать / robots.txt на ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Где поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет URL-адрес в файле «/robots.txt», он удаляет компонент пути из URL-адреса (все, начиная с первой косой черты), и помещает на его место «/robots.txt».
Например, для http: // www.example.com/shop/index.html, он будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге будет «http://www.example.com/robots.txt».
Итак, как владельцу веб-сайта вам необходимо поместить его в нужное место на своем веб-сервер для работы полученного URL. Обычно это то же самое место, куда вы помещаете главный «index.html» вашего веб-сайта страница. Где именно это и как поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать строчные буквы для имени файла: «роботы.txt », а не« Robots.TXT.
Смотрите также:
Что туда класть
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись следующего вида:Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Запретить: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что для каждого префикса URL-адреса вам нужна отдельная строка «Запретить». хотите исключить — нельзя сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, в записи может не быть пустых строк, поскольку они используются для разграничения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается ни в User-agent, ни в Disallow линий. ‘*’ В поле User-agent — это специальное значение, означающее «любой робот «. В частности, у вас не может быть таких строк, как» User-agent: * bot * «, «Запрещать: / tmp / *» или «Запрещать: * .gif».
Что вы хотите исключить, зависит от вашего сервера. Все, что не запрещено явно, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Disallow: / junk /
Для исключения одного робота
Пользовательский агент: BadBot Запретить: /
Чтобы позволить одному роботу
Пользовательский агент: Google Запретить: Пользовательский агент: * Запретить: /
Для исключения всех файлов, кроме одного
В настоящее время это немного неудобно, поскольку нет поля «Разрешить».В простой способ — поместить все файлы, которые нельзя разрешить, в отдельный директорию, скажите «вещи» и оставьте один файл на уровне выше этот каталог:Пользовательский агент: * Запретить: / ~ joe / stuff /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html.
Файл Robots.txt — что это? Как это использовать? // WEBRIS
Короче говоря, файл Robots.txt управляет доступом поисковых систем к вашему сайту.
Этот текстовый файл содержит «директивы», которые диктуют поисковым системам, какие страницы должны «разрешать» и «запрещать» доступ поисковой системе.
 Скриншот нашего файла Robots.txt
Скриншот нашего файла Robots.txt
Добавление неправильных директив может негативно повлиять на ваш рейтинг, поскольку это может помешать поисковым системам сканировать страницы (или весь ваш) веб-сайт.
Украдите наш план SEO
Получите БЕСПЛАТНУЮ копию нашего бестселлера The SEO Blueprint. Напишите письмо, мы сразу же его отправим.

Что такое «роботы» (в отношении SEO)?
Роботы — это приложения, которые «просматривают» веб-сайты, документируя (то есть «индексируя») информацию, которую они охватывают.
В отношении файла Robots.txt эти роботы называются пользовательскими агентами.
Вы также можете услышать их зовут:
- Пауки
- Боты
- Веб-сканеры
Это , а не официальных имен User-agent сканеров поисковых систем. Другими словами, вы не стали бы «Запрещать» «Crawler», вам нужно будет получить официальное название поисковой системы (сканер Google называется «Googlebot»).
Вы можете найти полный список веб-роботов здесь.

Изображение предоставлено
На этих ботов влияют разные способы, включая контент, который вы создаете, и ссылки, ведущие на ваш сайт.
Ваш файл Robots.txt позволяет напрямую общаться с ботами поисковых систем , давая им четкие указания о том, какие части вашего сайта вы хотите сканировать (или не сканировать).
Как использовать файл Robots.txt?
Вы должны понимать «синтаксис», в котором создается файл Robots.txt.
1. Определите User-agent
Укажите имя робота, о котором вы говорите (например, Google, Yahoo и т. Д.). Опять же, вы захотите обратиться за помощью к полному списку пользовательских агентов.
2. Запретить
Если вы хотите заблокировать доступ к страницам или разделу своего веб-сайта, укажите здесь URL-путь.
3. Разрешить
Если вы хотите напрямую разблокировать путь URL-адреса в заблокированном родительском элементе, введите здесь путь к подкаталогу этого URL-адреса.

Файл Robots.txt из Википедии.
Короче говоря, вы можете использовать robots.txt, чтобы сообщить этим сканерам: «Индексируйте эти страницы, но не индексируйте другие».
Почему Роботы.txt так важен
Может показаться нелогичным «блокировать» страницы от поисковых систем. Для этого есть ряд причин и случаев:
1. Блокировка конфиденциальной информации
Справочники — хороший пример.
Вероятно, вы захотите скрыть те, которые могут содержать конфиденциальные данные, например:
- / тележка /
- / cgi-bin /
- / скрипты /
- / wp-admin /
2. Блокировка некачественных страниц
Google неоднократно заявлял, что очень важно «очищать» свой веб-сайт от страниц низкого качества.Наличие большого количества мусора на вашем сайте может снизить производительность.
Для получения более подробной информации ознакомьтесь с нашим аудитом контента.
3. Блокировка повторяющегося контента
Вы можете исключить любые страницы, содержащие повторяющийся контент. Например, если вы предлагаете «печатные версии» некоторых страниц, вы не хотите, чтобы Google индексировал повторяющиеся версии, поскольку дублированный контент может повредить вашему рейтингу.
Однако имейте в виду, что люди по-прежнему могут посещать эти страницы и ссылаться на них, поэтому, если информация относится к тому типу, который вы не хотите, чтобы другие видели, вам нужно будет использовать защиту паролем, чтобы сохранить ее конфиденциальность.
Это потому, что, вероятно, есть страницы, содержащие конфиденциальную информацию, которую вы не хотите показывать в поисковой выдаче.
Форматы Robots.txt для разрешения и запрета
Robots.txt на самом деле довольно прост в использовании.
Вы буквально указываете роботам, какие страницы нужно «разрешить» (что означает, что они будут их индексировать), а какие — «запретить» (которые они будут игнорировать).
Вы используете последний только один раз, чтобы перечислить страницы, которые не должны сканировать пауки.Команда «Разрешить» используется только в том случае, если вы хотите, чтобы страница сканировалась, но для ее родительской страницы установлено значение «Запрещено».
Вот как выглядит robot.txt для моего сайта:

Начальная команда user-agent сообщает всем веб-роботам (т. Е. *) — а не только роботам для определенных поисковых систем — что эти инструкции применимы к ним.
Как настроить Robots.txt для вашего веб-сайта
Во-первых, вам нужно будет записать ваши директивы в текстовый файл.
Затем загрузите текстовый файл в каталог верхнего уровня вашего сайта — его нужно добавить через Cpanel.

Изображение предоставлено
Ваш живой файл всегда будет идти сразу после «.com /» в вашем URL. Наш, например, находится по адресу https://webris.org/robot.txt.
Если бы он был расположен по адресу www.webris.com/blog/robot.txt, сканеры даже не стали бы его искать, и ни одна из его команд не была бы выполнена.
Если у вас есть поддомены, убедитесь, что у них есть собственные robots.txt файлы. Например, в нашем поддомене training.webris.org есть собственный набор директив — это невероятно важно проверять при проведении аудита SEO.
Тестирование файла Robots.txt
Google предлагает бесплатный тестер robots.txt, который можно использовать для проверки.

Он расположен в Google Search Console под Crawl> Robots.txt Tester.
Роботы-укладчики.txt для улучшения SEO
Теперь, когда вы понимаете этот важный элемент SEO, проверьте свой сайт, чтобы убедиться, что поисковые системы индексируют те страницы, которые вам нужны, и игнорируют те, которые вы хотите исключить из результатов поиска.
В дальнейшем вы можете продолжать использовать robot.txt для информирования поисковых систем о том, как они должны сканировать ваш сайт.
.
Об авторе