Файл robots txt пример: примеры для различных CMS, правила, рекомендации
примеры для различных CMS, правила, рекомендации
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года — robots.txt.
Что такое Robots.txt?
Robots.txt — текстовый файл на сайте, содержащий инструкции для роботов какие страницы разрешены для индексации, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировок
- страницы авторизации и регистрации
- сравнения товаров
Как создать и добавить Robots.
 txt на сайт?
txt на сайт?Robots.txt обычный текстовый файл, который можно создать в блокноте, следуя синтаксису стандарта, который будет описан ниже. Для одного сайта нужен только один такой файл.
Файл нужно добавить в корневой каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Но если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной индексирующий робот;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.
 Картинок;
Картинок; - Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.Маркета;
- Googlebot-Mobile —индексатор мобильной версии.
 Картинок;
Картинок;Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow — директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
Примечание: Если данная директива будет указана пустой, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / — это закроет весь сайт от индексации.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site. com/sitemap1.xml
com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указания главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которым он доступен. Указывать Host необходимо в секции для роботов Яндекса:
User-agent: Yandex
Disallow: /site/
Host: site.ru
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param: p1[&p2&p3&p4&. .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (актуально для ресурсов с большим количеством страниц). Чтобы снизить нагрузку на сервер, можно воспользоваться директивой Crawl-delay.
Параметром для Crawl-delay является время в секундах, которое указывает роботам, что страницы следует скачивать с сайта не чаще одного раза в указанный период.
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: /site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- В директивах «Allow», «Disallow» можно указывать только 1 параметр
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.
 txt
txtПри указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*.php # запрещает ‘/store/ex.php’ и ‘/store/test/ex1.php’
Disallow: /*tpl # запрещает не только ‘/tpl’, но и ‘/tpl/user’
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: /site$ # запрещено для индексации ‘/site’, но не запрещено’/ex.css’
User-agent: *
Disallow: /site # запрещено для индексации и ‘/site’, и ‘/site.css’
User-agent: *
Disallow: /site$ # запрещен к индексации только ‘/site’
Disallow: /site*$ # так же, как ‘Disallow: /site’ запрещает и /site.
 css и /site
css и /siteОсобенности настройки robots.txt для Яндекса
Особенностями настройки роботса для Яндекса является только наличие директории Host в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Yandex
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Disallow: */css
Host: www.site.com
В данном случаем директива Host указывает роботам Яндекса, что главным зеркалом сайта является www.site.com (но данная директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность лишь состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *. js
js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
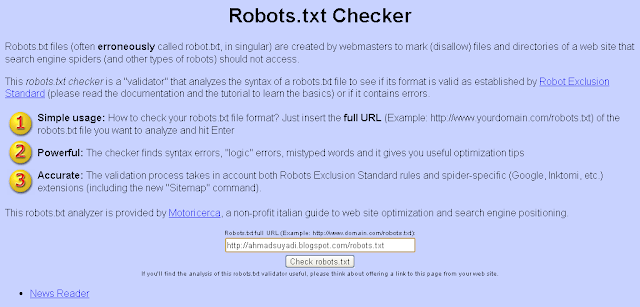
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:
Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексацией сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те страницы, которые могут повредить хорошему ранжированию ресурса в выдаче.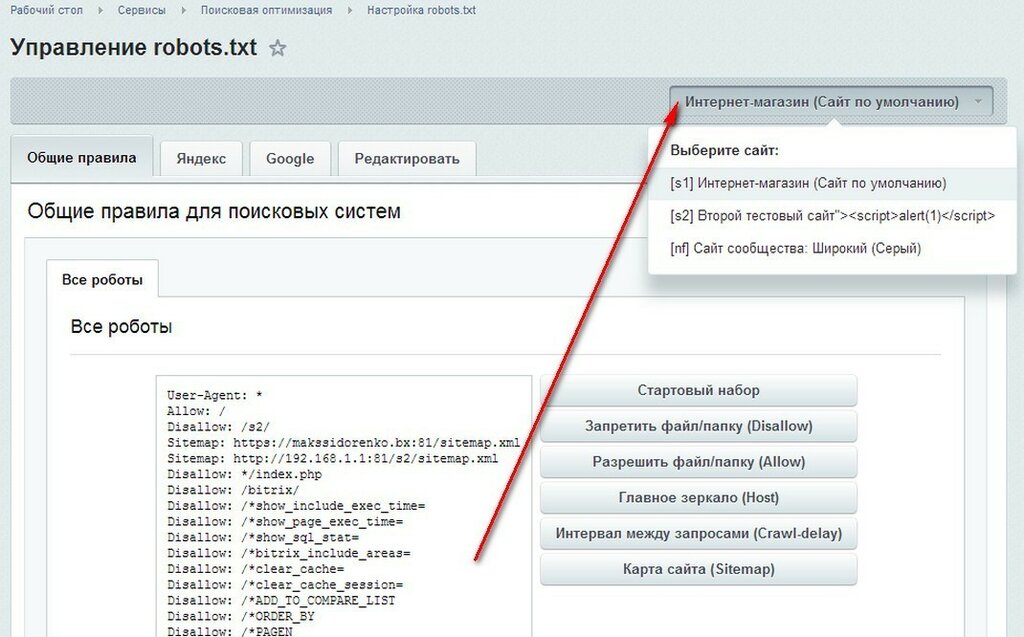
Пример настройки роботс для WordPress
Правильный robots.txt для WordPress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots. txt для CMS 1C-Bitrix:
txt для CMS 1C-Bitrix:
User-Agent: Yandex
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo. png
png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site. ru
ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index. php
php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out. php
php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots. txt для Джумлы должен быть составлен таким образом:
txt для Джумлы должен быть составлен таким образом:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ru/sitemap.xml
site.ru/sitemap.xml
Файл robots txt для сайта
Robots.txt – это служебный файл, инструкция для поисковых роботов для индексации сайта. В файле указываются каталоги, которые не требуется индексировать. Обычно это администраторская панель, кеш, служебные файлы. Размещается в корневой папке веб-ресурса. Его использование необходимо для лучшей индексации страниц, защиты приватной информации и повышения безопасности сайта.
Часто используется веб-мастерами вместе с другим служебным файлом, предусмотренным протоколом sitemap ( написанном на языке XML), который действует наоборот, предоставляя карту сайта с разрешенными к чтению роботами страницами.
Robots.txt и его влияние на индексацию сайта
На индексацию сайта также влияют скорость и надежность хостинга. Быстрый и надежный хостинг со скидкой до 30%!
После создания сайта его корневая папка на хосте становится доступной для поисковых систем. Роботы читают все, что найдут, без разбора.
В каталогах динамических сайтов, находящихся под управлением CMS, они не найдут никакой информации, ведь она хранится в базах данных MYSQL.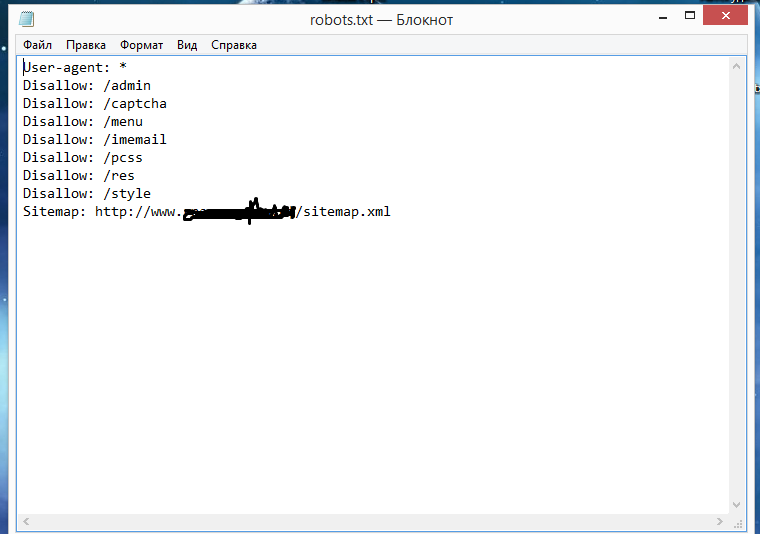 Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Для хакеров и прочих компьютерных злоумышленников доступные к чтению служебные файлы – это еще не дверь, но замочная скважина, в которую они обязательно залезут с электронной отмычкой для получения контроля над всем сайтом. Если в файле robots.txt указать, что читать надо только индексные файлы, то знакомство поисковой системы с динамическим сайтом произойдет быстрее, а его безопасность повысится.
Для статических веб-ресурсов этот файл станет небольшой гарантией, что хранящиеся конфиденциальные данные (телефоны, адреса электронной почты и другие) не окажутся в открытом доступе.
Веб-мастер, создавая файл robots.txt, может запретить роботам поисковых систем посещение всего сайта или дать доступ к его индексации только одной из категорий или страниц сайта.
Какие страницы стоит запретить и закрыть в robots.txt?
Если на хосте, где размещен сайт, есть панель управления, то этот файл можно создать, открыв корневую папку и нажав кнопку «новый файл» (бывают варианты в названиях). Но лучше создать файл на домашнем компьютере, а для загрузки воспользоваться каналом FTP.
Самой удобной программой для создания файла robots.txt является Notepad++. Но не возбраняется использовать обычный блокнот из набора Windows или текстовый редактор Word. Сохранять файл надо с расширением .txt.
Даже если он написан неправильно, это не приведет к потере работоспособности сайта, как это происходит с неправильным файлом .htaccess.
— Если не хочется ни изучать синтаксис файла, ни создавать его самостоятельно, то можно обратиться, например на http://pr-cy.ru/robots/, где его сгенерируют автоматически.
Директивы файла — user agent, host и т.д.
Директивы (команды) файла пишутся на латинице, после каждой из них ставится двоеточие и указывается объект управления.![]()
Директивы бывают стандартные:
- User-agent – имя поискового робота;
- Allow – разрешить;
- Disallow – запретить;
- Sitemap – адрес, где находится sitemap.xml;
- * – для всех.
И расширенные:
- Craw-delay– промежуток времени между чтением директорий;
- Request-rate – количество страниц, просмотренных за одну секунду;
- Visit-time – желаемое время посещения сайта роботом.
Расширенные директивы снижают нагрузку на сервер и защищают сайт от слишком назойливых парсеров.
Google, Яндекс и настройка роботс
Поисковые системы Гугл и Яндекс одинаково хорошо читают этот файл, но рассчитывать, что его наличие послужит установлению каких-либо особенных отношений поисковых систем с сайтом – это ненужный романтизм, лишенный оснований. Есть некоторые отличия в том как можно обратиться к поисковому роботу, ведь у каждой системы их целый набор:
- YandexBot и Googlebot – это обращение к основным поисковым роботам;
- YandexNews и Googlebot-news – роботы, специализирующиеся на новостном контенте;
- YandexImages и Googlebot-image – индексаторы картинок.

У Яндекса поисковых роботов девять, а у Google восемь. Если требуется общая индексация, то после директивы User-agent пишется Yandex или Googlebot.
У Яндекса есть еще одна особенность: его роботы читают директиву Host, указывающую на «зеркало» сайта. Гугл ее не понимает.
Нужен красивый домен для Вашего проекта? Проверить и купить домен дешево болеее чем в 300 зонах!
Как составить robots.txt для Joomla
Вот как может выглядеть этот файл для новостного сайта на CMS Joomla.
User-agent: YandexNews
Disallow: /administrator
Disallow: /components
Disallow: /libraries
Allow: /index1.php
Allow: /index2.php
Request-rate: 1/20
Visit-time: 0200-0600
В нем для индексации «приглашен» новостной бот Яндекса, которому запрещено читать директории administrator, components и libraries (папка, где собственно и содержится «движок»). Индексировать можно 1 страницу за 20 секунд, а посещать сайт с двух ночи до шести утра по Гринвичу.
Проверить правильность написания файла robots.txt можно обратившись в Яндексе к сервису «Вебмастеру». Такой же Центр Веб-мастеров есть и у Google.
Не нужно использовать этот файл как основу – в нем просто показано использование директив.
Пример правильного файла robots.txt для WordPress — как запретить все лишнее
А это – рабочий файл robots.txt для CMS WordPress.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
Host: http://вашсайт.ру
Sitemap: http://вашсайт.ру/sitemap. xml
xml
В первом блоке написаны директивы для всех поисковых роботов, они же дублируются для Яндекса, только с уточнением основной версии сайта. Как видно, из индекса исключена пагинация, служебные файлы и каталоги.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
- Виртуальные серверы с NVMe SSD дисками от 299 руб/мес
- Безлимитный хостинг на SSD дисках от 142 руб/мес
- Выделенные серверы в наличии и под заказ
- Регистрацию доменов в более 350 зонах
Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду .
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает все боты
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц .
Что, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса

При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту.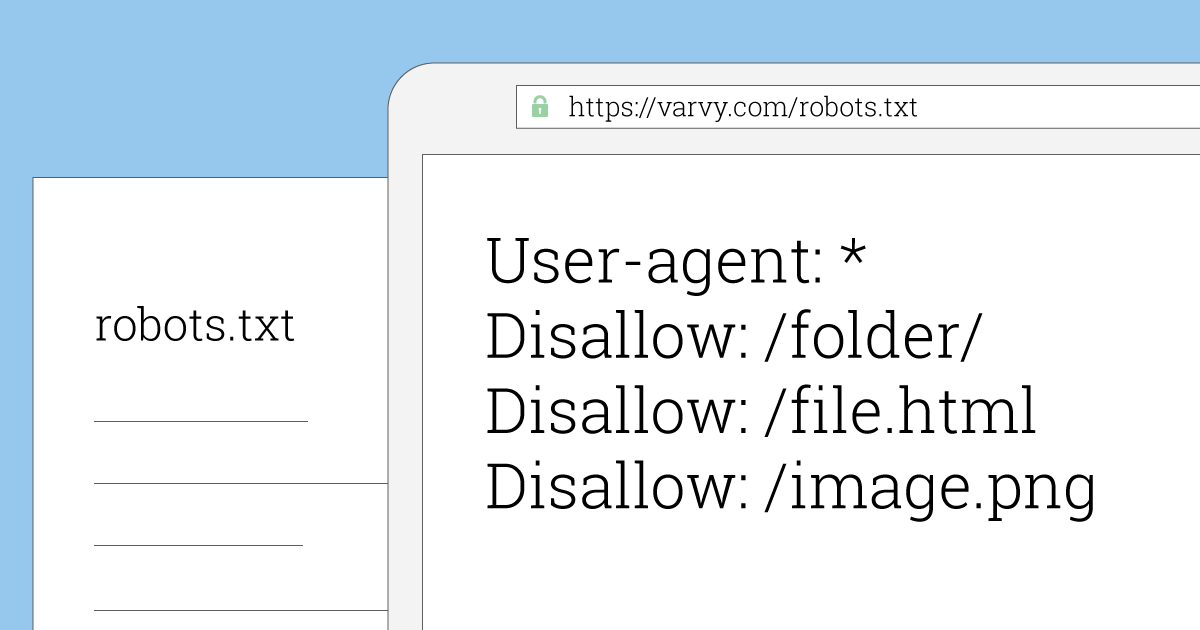 Вы можете сделать это с помощью
Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter

Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила. Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Руководство по использованию robots.txt + примеры
Файл robots.txt часто упускают из виду, а иногда забывают о нем на веб-сайте и в поисковой оптимизации.
Тем не менее, файл robots.txt является важной частью любого набора инструментов SEO, независимо от того, начинаете ли вы работать в этой отрасли или нет, или вы опытный ветеран SEO.
Что такое файл robots.txt?
Файл robots.txt можно использовать для самых разных целей: от информирования поисковых систем, куда идти, чтобы найти карту сайта вашего сайта, до указания им, какие страницы сканировать, а какие нет, а также в качестве отличного инструмента для управления вашими сайтами. краулинговый бюджет сайтов.
Возможно, вы спрашиваете себя: « подождите минутку, что такое краулинговый бюджет? ”Сканирующий бюджет — это то, что Google использует для эффективного сканирования и индексации страниц вашего сайта. Каким бы большим ни был Google, у них по-прежнему есть только ограниченное количество ресурсов, доступных для сканирования и индексации контента ваших сайтов.
Каким бы большим ни был Google, у них по-прежнему есть только ограниченное количество ресурсов, доступных для сканирования и индексации контента ваших сайтов.
Если на вашем сайте всего несколько сотен URL-адресов, Google сможет легко сканировать и индексировать страницы вашего сайта.
Однако, если ваш сайт большой, например, сайт электронной коммерции, и у вас есть тысячи страниц с большим количеством автоматически сгенерированных URL-адресов, Google может не просканировать все эти страницы, и вы потеряете много потенциального трафика и видимость.
Здесь важно расставить приоритеты, что, когда и сколько сканировать.
Google заявил, что « наличие большого количества URL-адресов с низкой добавленной стоимостью может негативно повлиять на сканирование и индексирование сайта. » Здесь файл robots.txt может помочь с факторами, влияющими на бюджет сканирования вашего сайта.
Вы можете использовать этот файл для управления бюджетом сканирования вашего сайта, убедившись, что поисковые системы тратят свое время на ваш сайт максимально эффективно (особенно если у вас большой сайт) и сканируют только важные страницы и не тратят впустую время на таких страницах, как вход, регистрация или страницы благодарности.
Прежде чем робот, такой как Googlebot, Bingbot и т. д., просканирует веб-страницу, он сначала проверит, существует ли на самом деле файл robots.txt, и, если он существует, они обычно будут следовать и соблюдать указания, указанные в нем. этот файл.
Файл robots.txt может быть мощным инструментом в арсенале любого SEO-специалиста, поскольку это отличный способ контролировать, как сканеры/боты поисковых систем получают доступ к определенным областям вашего сайта. Имейте в виду, что вы должны быть уверены, что понимаете, как работает файл robots.txt, иначе вы случайно запретите Googlebot или любому другому боту сканировать весь ваш сайт, и он не будет найден в результатах поиска!
Ресурсы
Но если все сделано правильно, вы можете контролировать такие вещи, как:
- Блокировка доступа к целым разделам вашего сайта (среда разработки и промежуточной среды и т. д.)
- Предотвращение сканирования, индексации или отображения страниц результатов внутреннего поиска вашего сайта в результатах поиска.
- Указание местоположения вашей карты сайта или карт сайта
- Оптимизация краулингового бюджета путем блокировки доступа к страницам с низкой ценностью (вход в систему, спасибо, корзины покупок и т. д.)
- Предотвращение индексации определенных файлов на вашем веб-сайте (изображений, PDF-файлов и т. д.)

Ниже приведены несколько примеров того, как вы можете использовать файл robots.txt на своем сайте.
Предоставление всем поисковым роботам/роботам доступа ко всему содержимому ваших сайтов:
Агент пользователя: * Disallow:
Блокировка всех поисковых роботов/роботов на всех ваших сайтах:
User-agent: * Disallow: /
Вы можете видеть, как легко сделать ошибку при создании ваших сайтов robots.txt, поскольку отличие от блокировки всего вашего сайта от просмотра заключается в простой косой черте в директиве запрета (Disallow: /).
Блокировка определенных веб-сканеров/ботов из определенной папки:
Агент пользователя: Googlebot Disallow: /
Блокировка поисковых роботов/роботов на определенной странице вашего сайта:
User-agent: Disallow: /thankyou.
 html
html Исключить всех роботов из части сервера:
User-agent: * Запретить: /cgi-bin/ Запретить: /tmp/ Disallow: /junk/
Вот пример того, как выглядит файл robots.txt на сайте theverge.com:
Файл примера можно посмотреть здесь: www.theverge.com/robots.txt
Вы можете увидеть, как The Verge использует свой файл robots.txt, чтобы специально вызвать новостного бота Google «Googlebot-News», чтобы убедиться, что он не сканирует эти каталоги на сайте.
Важно помнить, что если вы хотите убедиться, что бот не сканирует определенные страницы или каталоги на вашем сайте, вы должны указать эти страницы и / или каталоги в объявлениях «Запретить» в файле robots.txt. , как в приведенных выше примерах.
Вы можете просмотреть, как Google обрабатывает файл robots.txt в своем руководстве по спецификациям robots.txt, у Google есть текущий предел максимального размера файла robots.txt, максимальный размер для Google установлен на уровне 500 КБ, поэтому важно помните о размере файла robots. txt вашего сайта.
txt вашего сайта.
Создание файла robots.txt для вашего сайта — довольно простой процесс, но в нем легко ошибиться. Не позволяйте этому отговорить вас от создания или изменения файла robots для вашего сайта. Эта статья от Google проведет вас через процесс создания файла robots.txt и должна помочь вам научиться создавать собственный файл robots.txt.
Когда вы освоитесь с созданием или изменением файла robots вашего сайта, у Google есть еще одна замечательная статья, в которой объясняется, как проверить файл robots.txt вашего сайта, чтобы убедиться, что он настроен правильно.
Проверка наличия файла robots.txt Если вы не знакомы с файлом robots.txt или не уверены, есть ли он на вашем сайте, вы можете быстро проверить его. Все, что вам нужно сделать, чтобы проверить, это перейти в корневой домен вашего сайта, а затем добавить /robots.txt в конец URL-адреса. Пример: www.yoursite.com/robots. txt
txt
Если ничего не отображается, значит у вас нет файла robots.txt для вашего сайта. Сейчас самое подходящее время, чтобы приступить к работе и попробовать создать его для своего сайта.
Передовой опыт:- Убедитесь, что все важные страницы доступны для сканирования, а контент, который не представляет реальной ценности в случае обнаружения в поиске, заблокирован.
- Не блокируйте файлы JavaScript и CSS на своих сайтах
- Всегда выполняйте быструю проверку файла, чтобы убедиться, что ничего не изменилось случайно
- Правильное использование заглавных букв в именах каталогов, подкаталогов и файлов
- Поместите файл robots.txt в корневой каталог вашего веб-сайта, чтобы его можно было найти
- Файл robots.txt чувствителен к регистру, файл должен называться «robots.txt» (без других вариантов)
- Не используйте файл robots.txt, чтобы скрыть личную информацию о пользователе, так как она все равно будет видна
- Добавьте местоположение карты сайта в файл robots. txt.
- Убедитесь, что вы не блокируете какой-либо контент или разделы вашего веб-сайта, которые вы хотите просканировать.
 txt.
txt.Если на вашем сайте есть субдомен или несколько субдоменов , вам потребуется файл robots.txt для каждого субдомена, а также для основного корня. домен. Это будет выглядеть примерно так: store.yoursite.com/robots.txt, и yoursite.com/robots.txt.
Как упоминалось выше в разделе « передовой практики », важно помнить, что нельзя использовать файл robots.txt для предотвращения сканирования конфиденциальных данных, таких как личная информация пользователя, и их появления в результатах поиска.
Причина этого в том, что возможно, что другие страницы могут ссылаться на эту информацию, и если есть прямая обратная ссылка, она будет обходить правила robots.txt, и этот контент все равно может быть проиндексирован. Если вам нужно заблокировать действительное индексирование ваших страниц в результатах поиска, используйте другой метод, например, добавление защиты паролем или добавление метатега noindex к этим страницам. Google не может войти на защищенный паролем сайт/страницу, поэтому они не смогут сканировать или индексировать эти страницы.
Если вам нужно заблокировать действительное индексирование ваших страниц в результатах поиска, используйте другой метод, например, добавление защиты паролем или добавление метатега noindex к этим страницам. Google не может войти на защищенный паролем сайт/страницу, поэтому они не смогут сканировать или индексировать эти страницы.
Хотя вы можете немного нервничать, если вы никогда раньше не работали с файлом robots.txt, будьте уверены, что он довольно прост в использовании и настройке. Как только вы освоитесь со всеми тонкостями файла robots, вы сможете улучшить SEO своего сайта, а также помочь посетителям вашего сайта и ботам поисковых систем.
Правильно настроив файл robots.txt, вы поможете ботам поисковых систем разумно расходовать краулинговые бюджеты и поможете им не тратить свое время и ресурсы на сканирование ненужных страниц. Это поможет им наилучшим образом организовать и отобразить контент вашего сайта в поисковой выдаче, что, в свою очередь, означает, что вы будете более заметны.
Об авторе