Где взять выписку из егрюл: Получить выписку из ЕГРЮЛ/ЕГРИП удобнее в электронном виде | ФНС России
Как получить выписку из ЕГРЮЛ бесплатно — Контур.Экстерн — СКБ Контур
Рассмотрим, как можно заказать выписку из ЕГРЮЛ онлайн — на портале ФНС или сформировать ее с помощью системы интернет-отчетности Контур.Экстерн.
Прежде чем получать выписку ЕГРЮЛ, важно определить, какая именно выписка нужна: юридически значимая или информационная.
Если необходима юридически значимая выписка, для этого нужно обратиться к специализированному сервису Федеральной налоговой службы на портале nalog.ru.
Благодаря сервису вы можете в режиме онлайн запросить и бесплатно получить информацию из ЕГРЮЛ об интересующем юридическом лице. Информация будет представлена в виде электронной выписки либо справки об отсутствии запрашиваемых сведений, которые в свою очередь будут подписаны УКЭП (усиленной квалифицированной электронной подписью) контролирующего органа — Федеральной налоговой службы.
Чтобы получить выписку, налогоплательщику не потребуется сертификат электронной подписи и регистрация. Выписка формируется в виде PDF-файла с усиленной квалифицированной электронной подписью ФНС и ее визуальным изображением, которое отразится и на распечатанной выписке.
Выписка формируется в виде PDF-файла с усиленной квалифицированной электронной подписью ФНС и ее визуальным изображением, которое отразится и на распечатанной выписке.
Эта электронная выписка обладает юридической значимостью, равной аналогичной выписке на бумаге. Ее можно использовать при аккредитации на крупнейших ЭТП: пяти федеральных площадках госзаказа (Сбербанк-АСТ, ЕЭТП, ОСЭТ ZakazRF, ММВБ «Госзакупки», РТС тендер), а также коммерческих площадках — B2B-Center, «Фабрикант», «Газпромбанк», «ТЭК-Торг» и других.
Как получить выписку из ЕГРЮЛ
- Войти на сайт, регистрироваться не обязательно.
- Сформировать поисковый запрос: указать ИНН, ОГРН/ОГРНИП, наименование организации или ФИО ИП.
- Выбрать регион, чтобы ограничить зону поиска совпадений.
- В результатах поиска появятся все компании и предприниматели, данные которых совпадают с введенными.
- Нажать кнопку «Получить выписку», чтобы скачать PDF-файл с электронной подписью налоговой.
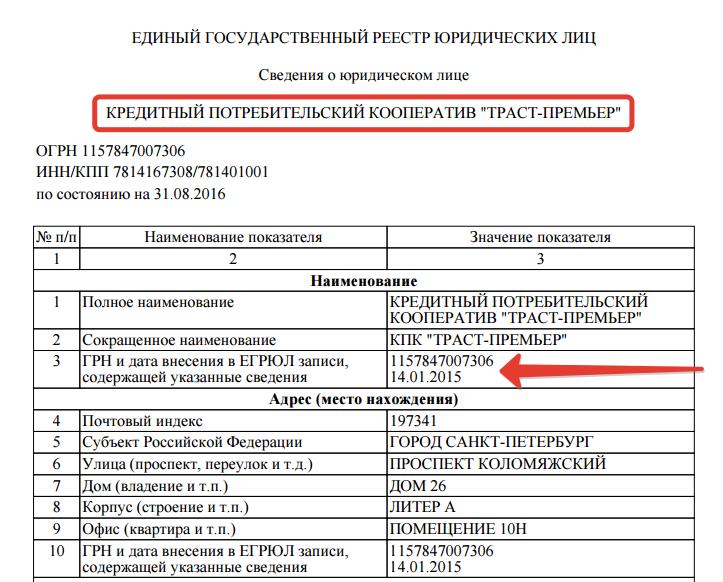
Информационная выписка
Информационную выписку из ЕГРЮЛ можно получить с помощью системы отчетности Контур.Экстерн.
Чтобы получить выписку:
- в Контур.Экстерне нужно выбрать в меню справа «Сервисы для бухгалтеров» пункт «Выписки из ЕГРЮЛ, ЕГРИП и проверка контрагентов»,
- указать ИНН, ОГРН, название или адрес.
После этого появится список, в котором есть совпадения с введенными данными. Нужно войти в необходимую карточку, нажать на «Сформировать выписку по состоянию на …» в разделе «Выписка из ЕГРЮЛ/ЕГРИП». Желаемую дату выписки можно выбрать, так вы сможете получить сведения из ЕГРЮЛ за прошлый период, когда нужно убедиться в отсутствии или наличии изменений. Затем выписку можно распечатать.
Пользуйтесь всеми возможностями Контур.Экстерна
Отправить заявку
Сведения из ЕГРЮЛ
В выписке по юридическому лицу будет представлена следующая информация:
- действующее/не действующее предприятие;
- наименование;
- ИНН/КПП;
- ОГРН;
- ОКПО;
- дата образования;
- юридический адрес;
- ФИО директора;
- виды деятельности;
- ФИО учредителей, размер и доли уставного капитала;
- свидетельства;
- регистрационные номера во внебюджетных фондах и другие сведения.

Отчитывайтесь во все
контролирующие органы
Как получить выписку на ИП — Пошаговая инструкция по получению выписки ИП
Аудиоверсия этой статьи
Сразу после регистрации юрлица или индивидуального предпринимателя сведения о нем ФНС заносит в государственные реестры – единый государственный реестр юридически лиц (ЕГРЮЛ) или единый государственный реестр индивидуальных предпринимателей (ЕГРИП). Если в деятельности ООО или ИП происходят какие-либо изменения, например, смена директора, ОКВЭД, то в реестрах отражается данная информация. При этом любое заинтересованное лицо может заказать выписку из данных реестров.
Содержание
Основные случаи, когда потребуется выписка из ЕГРИП
Какие данные можно получить
Кто может обратиться за получением выписки
Как получить выписку из ЕГРИП
Деловая среда
Платформа знаний и сервисов для бизнеса
Открыть ИП сейчас
Основные случаи, когда потребуется выписка из ЕГРИП
Необходимость получить подробную информацию о будущем партнере, контрагенте. То есть это один из способов проверки контрагента.
Для обращения в судебные инстанции в случае возникновения спорных, конфликтных ситуаций с контрагентами, которые не удалось урегулировать в досудебном порядке.
При открытии расчетного счета, получения кредита, участия в тендерах.
В любой другой ситуации, когда нужно знать точную информацию о дате, месте регистрации предпринимателя, его анкетных данных и видах его деятельности.

Выписка из ЕГРИП подтверждает, что человек ведет официально предпринимательскую деятельность.
Сервис
Здесь вы можете зарегистрировать бизнес бесплатно и без визита в налоговую
Подать заявку
Какие данные можно получить
Выписка из ЕГРИП содержит следующую информацию:
полное имя индивидуального предпринимателя – в точной формулировке, указанной в его гражданском паспорте;
точная дата проведения государственной регистрации предпринимателя – день, с которого ИП может официально начинать свою деятельность;
гражданская принадлежность предпринимателя;
название органа, который провел регистрацию и ИФНС по месту регистрации;
адрес электронной почты, который указывался при регистрации ИП;
коды видов деятельности по ОКВЭД;
все изменения, которые вносились по любым причинам.

Кто может обратиться за получением выписки
Сведения, которые содержаться в реестрах – это отрытая и общедоступная информация. Получить бумажную или электронную версию может любой заинтересованный в ней человек или организация. Сделать это можно на сайте налоговой службы.
Сервис
Мечтаете о своем бизнесе? Зарегистрируйте ИП удаленно и бесплатно
Подать заявку
Как получить выписку из ЕГРИП
Выписку из ЕГРИП можно получить как в бумажном, так и в электронном виде. Оба варианта абсолютно идентичны и могут применяться с равными возможностями. Сегодня многие сайты предлагают получение выписок, однако доверять можно только одному – сайту ФНС (Федеральная налоговая служба).
Как получить на бумажном носителе
Выписку на бумажном носителе делает ФНС. Регламент этой госуслуги утвержден приказом ФНС России от 19.12.2019 № ММВ-7-14/640@. За бумажную выписку придется заплатить госпошлину:
Регламент этой госуслуги утвержден приказом ФНС России от 19.12.2019 № ММВ-7-14/640@. За бумажную выписку придется заплатить госпошлину:
Такие моменты следует обязательно учитывать и заказывать изготовление информации о любой организации или ИП заблаговременно.
Внимание!
Если предприниматель запрашивает выписку о себе (например, для участия в тендере), то ему пошлину платить не надо.
Для получения бумажных выписок из ЕГРИП следует подать соответствующие заявление с указанием целей их получения, количества необходимых экземпляров, способ получения готовой корреспонденции и срочность получения сведений. Кроме того, нужно указать полное имя и ИНН (или ОГРНИП) предпринимателя, в отношении которого запрашивается выписка. Кроме того, заявителю нужно сообщить данные о себе.
Как получить в электронном виде
Быстро и бесплатно запросить выписки из реестров можно не покидая своего рабочего места. Сведения, которые содержаться в электронном документе из ЕГРИП никак не отличаются от данных из бумажного варианта. Получить выписки из ЕГРИП можно на сайте налоговой службы всего за несколько простых шагов:
Сведения, которые содержаться в электронном документе из ЕГРИП никак не отличаются от данных из бумажного варианта. Получить выписки из ЕГРИП можно на сайте налоговой службы всего за несколько простых шагов:
1. Зайдите на официальный сайт налоговой службы ФНС России, перейдите сверху на вкладку «Сервисы и госуслуги», далее найдите поле «Выписки из реестров» – нажмите на фразу «Предоставление сведений из ЕГРЮЛ/ЕГРИП».
В строке поиска укажите один из перечисленных параметров организации или ИП – фамилия, ИНН или любую другую известную информацию. Также укажите регион деятельности ИП, если вы его знаете (но это не обязательно).
2. В открывшемся окне появятся результаты поиска. Далее нужно выбрать нужного ИП нажать кнопку «получить выписку». После этого документ, формата PDF будет загружен на компьютер.
Выписки из ЕГРИП станут отличными помощниками для построения успешного и процветающего бизнеса. Запросить такой документ можно непосредственно у контрагента или получить его самостоятельно любым из указанных ранее способов.
Сервис
Доверьте онлайн-регистрацию ИП профессионалам. Услуга бесплатна
Подать заявку
Как извлечь часть строковой переменной с помощью регулярных выражений?
Обработка строк в Stata довольно проста из-за множества встроенных строковых функции. Среди этих строковых функций есть три функции, связанные с регулярные выражения, regexm для сопоставления, regexr для замены и регулярных выражения для подвыражений. Мы покажем несколько примеров использования регулярное выражение для извлечения и/или замены части строковой переменной используя эти три функции. Внизу страницы пояснение все операторы регулярных выражений, а также функции, которые работают с обычные выражения.
Примеры
Пример 1. Исследователь имеет адреса в виде строковой переменной и хочет создать новую переменную который содержит только почтовые индексы.
Пример 2: У нас есть переменная, которая содержит полные имена в порядке первых
имя, а затем фамилию. Мы хотим создать новую переменную с полным именем в
порядок фамилии, а затем имени через запятую.
Мы хотим создать новую переменную с полным именем в
порядок фамилии, а затем имени через запятую.
Пример 2: Даты вводились как строковая переменная, в некоторых случаях год вводился в виде четырехзначного числа значение (это то, что Stata обычно ожидает увидеть), но в других случаях оно вводилось как двузначное ценить. Мы хотим создать переменную даты в числовом формате на основе этой строки. переменная. С этой задачей можно легко справиться с помощью обычных команд Stata, см. нашу страницу часто задаваемых вопросов. «Моя переменная даты — это строка, как я могу превратить ее в переменную даты, которую Stata может распознавать?» для получения информации о том, как это сделать. Мы включили этот пример здесь для демонстрационных целей, а не потому, что регулярные выражения обязательно лучший способ справиться с этой ситуацией.
В этих ситуациях можно использовать регулярные выражения для определения случаев, в которых
строка содержит набор значений (например, определенное слово, число, за которым следует слово
и т. д.) и извлечь этот набор значений из всей строки для использования в другом месте.
д.) и извлечь этот набор значений из всей строки для использования в другом месте.
Пример 1. Извлечение почтовых индексов из адресов
Начнем с некоторых поддельных адресов.
адрес ввода str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» "673 Жасмин Стрит, Лос-Анджелес, Калифорния " "2376 Первая улица, Сан-Диего, Калифорния " "Уэст Сентрал Стрит, 6, Темпе, AZ 80068" «1234 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» конец
Чтобы найти почтовый индекс, мы будем искать пятизначное число в адресе.
Команда gen (сокращение от «генерировать») ниже указывает Stata создать новую переменную с именем zip .
Остальная часть команды немного сложна, сначала оценивается «if», if(regexm(address, «[0-9][0-9][0-9][0-9][0-9]»)) ищет в переменной адрес пятизначное число и, если может
найти пятизначное число в переменной адрес , = regexs(0) указывает, что Stata должна установить значение zip равным этому
пятизначное число. Мы указываем
что мы хотим пятизначное число, указав «[0-9]»
в пять раз. Если иное не указано с помощью *, + или ? знак, один и только один из
символы, содержащиеся в скобках, будут совпадать. Это означает, что нанизывание пяти из этих
выражения вместе позволят нам найти строку ровно из пяти цифр.
Обратите внимание, что 0-9указывает, что выражение должно соответствовать любому символу 0
до 9 (т. е. 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9 совпадают).
Мы указываем
что мы хотим пятизначное число, указав «[0-9]»
в пять раз. Если иное не указано с помощью *, + или ? знак, один и только один из
символы, содержащиеся в скобках, будут совпадать. Это означает, что нанизывание пяти из этих
выражения вместе позволят нам найти строку ровно из пяти цифр.
Обратите внимание, что 0-9указывает, что выражение должно соответствовать любому символу 0
до 9 (т. е. 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9 совпадают).
gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]"))
список
+------------------------------------------------- -------------+
| почтовый индекс |
|------------------------------------------------- -------------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
|
3. | 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 6 West Central St, Tempe AZ 80068 80068 |
5. | 1234 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 |
+------------------------------------------------- -------------+ Пример 1, вариантный номер 1
В приведенном выше упрощенном примере ни один из адресов не содержит пятизначных номеров улиц. числа. Что делать, если есть адреса с пятизначными номерами улиц? Давайте посмотрим
в другом наборе данных поддельных адресов и посмотреть, что происходит, когда мы пытаемся использовать
тот же код выше.
числа. Что делать, если есть адреса с пятизначными номерами улиц? Давайте посмотрим
в другом наборе данных поддельных адресов и посмотреть, что происходит, когда мы пытаемся использовать
тот же код выше.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас 77845» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния,». "2376 Первая улица, Сан-Диего, Калифорния
" "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238» конец gen zip = regexs(0) if(regexm(адрес, "[0-9][0-9][0-9][0-9][0-9]")) список +------------------------------------------------- ---------+ | почтовый индекс | |------------------------------------------------- ---------| 1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 77845 | 2. | 673 Jasmine Street, Лос-Анджелес, Калифорния| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 66666 | 5.| 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 12345 | +------------------------------------------------- ---------+
Судя по всему, это работает некорректно, так как последние две строки переменная zip подобрали номера улиц для этих адресов вместо почтовых индексов. В этот набор данных, почтовый индекс появляется в конце адресной строки. Если мы предположим, что это относится ко всем адресам в данных, исправление будет очень просто. Мы можем указать «[0-9][0-9][0-9][0-9][0-9]$» который проинструктирует Stata найти пятизначное число в конце строки.
gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]$"))
список
+------------------------------------------------- ---------+
| почтовый индекс |
|------------------------------------------------- ---------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
|
3. | 2376 Первая улица, Сан-Диего, Калифорния
| 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 66666 West Central St, Tempe AZ 80068 80068 |
5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 01238 |
+------------------------------------------------- ---------+ Пример 1, номер варианта 2
Иногда почтовый индекс также включает четырехзначный добавочный номер и страну имя может также появляться в конце адреса, например, в некоторых адреса, указанные ниже.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния,». "2376 Первая улица, Сан-Диего, Калифорния " "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» "12345 Мэйн-Сент-Соммервиль, Массачусетс, Массачусетс 01239.-2345" "12345 Мейн-Стрит Уотертвон, Массачусетс, Массачусетс, 01239, США" конец
В этом типе более реалистичной ситуации код в предыдущем
примеры не будут работать правильно, так как после zip есть лишние символы
код, который необходимо извлечь. Вот как мы можем это сделать, используя более сложный регулярный
выражение.
Вот как мы можем это сделать, используя более сложный регулярный
выражение.
gen zip = regexs(1) if regexm(address, "([0-9][0-9][0-9][0-9][0-9])[-]*[0-9 ]*[ a-zA-Z]*$")список+------------------------------------------------ --------------+ | почтовый индекс | |------------------------------------------------- -------------| 1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 | 2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 80068 | 5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 | |------------------------------------------------- -------------| 6. | 12345 Мейн-Стрит Соммервиль MA 01239-2345 01239 | 7. | 12345 Main St Watertwon MA 01239 США 01239 | +------------------------------------------------- -------------+
Мы добавили в регулярное выражение следующее: «[-]*[0-9]*[ a-zA-Z]*» . В этом регулярном выражении есть три компонента.
В этом регулярном выражении есть три компонента.
- [-]* – совпадение нуля или более дефисов «-»
- [0-9]* – совпадение нуля или более чисел
- [a-zA-Z]* — совпадение нуля или более пробелов или букв
Эти дополнения позволяют нам сопоставлять случаи, когда есть замыкающие символов после почтового индекса и для правильного извлечения почтового индекса. Заметить, что мы также использовали «регулярные выражения (1)» вместо «регулярных выражений (0)», как мы делали ранее, потому что мы теперь используют подвыражения, указанные парой скобок в « ([0-9][0-9][0-9][0-9][0-9]) «. Другая стратегия, которая может работать лучше в некоторых случаях, — это регулярное выражение
.gen zip2 = regexs(1) if(regexm(address, ".*([0-9][0-9][0-9][0-9][0-9])"))
В этом примере точка (т. е. «.») соответствует любому символу, а одна звездочка («*») соответствует любому
персонажи. Вместе, два
указать, что искомое число не должно встречаться в самом
начало строки, но может появиться в любом месте после.
Пример 2: Извлечение имени и фамилии и переключение их порядка
У нас есть переменная, которая содержит полное имя человека в порядке имени и затем фамилия. Мы хотим создать новую переменную для полного имени в порядке фамилия, а затем имя через запятую. Для начала давайте сделаем образец данных набор.
прозрачный введите str40 полное имя "Джон Адамс" "Адам Смитс" "Мэри Смитс" "Чарли Уэйд" конец
Теперь нам нужно захватить первое слово и второе слово и поменять их местами. Здесь регулярное выражение для этой цели: (([a-zA-Z]+)[ ]*([a-zA-Z]+)).
Это регулярное выражение состоит из трех частей:
- ([a-zA-Z]+) — подвыражение , захватывающее строку, состоящую из буквы, как строчные, так и прописные. Это будет первое имя.
- [ ]* – совпадение с пробелами. Это расстояние между первым имя и фамилия.
- ([a-zA-Z]+) – подвыражение, захватывающее строку, состоящую из
буквы.
 Это будет фамилия.
Это будет фамилия.
gen n = regexs(2)+", "+regexs(1) if regexm(fullname, "([a-zA-Z]+)[ ]*([a-zA-Z]+)")
список
+-------------------------------+
| полное имя п |
|-------------------------------|
1. | Джон Адамс Адамс, Джон |
2. | Адам Смитс Смитс, Адам |
3. | Мэри Смитс Смитс, Мэри |
4. | Чарли Уэйд Уэйд, Чарли |
+---------------------------------------------+ Это действительно работает. Давайте посмотрим, как регулярных выражений работают в этом случае. регулярное выражение фактически идентифицирует ряд разделов на основе всего выражения, а также подвыражения. Следующий код использует регулярных выражения для размещения каждого из этих компоненты (подвыражения) в свою собственную переменную а затем отображает их.
gen n0 = regexs(0) if regexm(fullname, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n1 = regexs(2) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n2 = regexs(3) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
список полных имен n0 n1 n2
+------------------------------------------------+
| полное имя n0 n1 n2 |
|------------------------------------------------|
1. | Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+
| Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+ Пример 3: Двух- и четырехзначные значения года.
В этом примере у нас есть даты, введенные как строковая переменная. Стата может справиться
это с помощью стандартных команд (см. «Моя переменная даты является строкой, как я могу
превратить его в переменную даты, которую Stata может распознать?»), мы используем это как пример того, что
вы могли бы сделать с регулярными выражениями. Целью этого процесса является создание строки
переменная с соответствующим четырехзначным годом для каждого случая, который Stata может
затем легко преобразовать в дату. Для этого начнем с разделения
вывести каждый элемент даты (день, месяц и год из двух или четырех цифр) в
отдельная переменная, то мы будем присваивать случаям правильный четырехзначный год
где в настоящее время только две цифры, наконец, мы объединяем переменные, чтобы создать одну
строковая переменная, которая содержит месяц, день и год из четырех цифр.
Сначала введите даты:
ввод даты str18 20 января 2007 г. 16 июня 2006 г. 06 сентября 1985 г. 21 июня 2004 г. 4июля90 9 января 1999 г. 6 августа 99 г. 19 августа 2003 г. конец
Далее мы хотим определить день месяца и поместить его в переменную позвонил день . Для этого мы проинструктируем Stata найти день, глядя на начало строки (т.е. дата), для одного или нескольких значений от 0 до 9. (Другими словами, ищите номер в начале строки, так как мы знаем, что первая серия чисел день.) Создать новую переменную 9[0-9]+»)
Строка синтаксиса ниже находит месяц, ища одну или несколько букв вместе в строке. Затем генерирует переменную month и устанавливает ее равной месяцу, указанному в строке.
gen month = regexs(0) if regexm(date, "[a-zA-Z]+")
В этом году все становится сложнее. Обратите внимание, что значения для присвоения
столетия основаны на моем знании моих «данных». Прежде всего, мы извлекаем все
цифры для года. Мы используем оператор «$», чтобы указать, что поиск ведется из
конец строки. Затем мы превращаем строковую переменную в числовую переменную
используя функцию Stata «real». Следующее действие включает в себя работу с двузначными годами
начиная с «0». Это соответствует последним годам двадцать первого века.
Чтобы превратить их в четырехзначные годы, мы объединяем (используя +) строку
идентифицируется (год из двух цифр) строкой «20». Далее мы найдем
двузначные годы 10-9[1-9][0-9]$») gen date2 = день+месяц+год список +————————————————- —+
| дата день месяц год date2 |
|————————————————- —|
1. | 20 января 2007 г. 20 января 2007 г. 20 января 2007 г. |
2. | 16 июня 2006 г. 16 июня 2006 г. 16 июня 2006 г. |
3. | 06 сентября 1985 г. 06 сентября 1985 г. 06 сентября 1985 г. |
4. | 21 июня 2004 г. 21 июня 2004 г. 21 июня 2004 г. |
5. | 4июля90 4 июля 1990 г.
Прежде всего, мы извлекаем все
цифры для года. Мы используем оператор «$», чтобы указать, что поиск ведется из
конец строки. Затем мы превращаем строковую переменную в числовую переменную
используя функцию Stata «real». Следующее действие включает в себя работу с двузначными годами
начиная с «0». Это соответствует последним годам двадцать первого века.
Чтобы превратить их в четырехзначные годы, мы объединяем (используя +) строку
идентифицируется (год из двух цифр) строкой «20». Далее мы найдем
двузначные годы 10-9[1-9][0-9]$») gen date2 = день+месяц+год список +————————————————- —+
| дата день месяц год date2 |
|————————————————- —|
1. | 20 января 2007 г. 20 января 2007 г. 20 января 2007 г. |
2. | 16 июня 2006 г. 16 июня 2006 г. 16 июня 2006 г. |
3. | 06 сентября 1985 г. 06 сентября 1985 г. 06 сентября 1985 г. |
4. | 21 июня 2004 г. 21 июня 2004 г. 21 июня 2004 г. |
5. | 4июля90 4 июля 1990 г. 4 июля 1990 г. |
|————————————————- —|
6. | 9 января 1999 г. 9 января 1999 г. 9 января 1999 г. |
7. | 6 августа 1999 г. 6 августа 1999 г. 6 августа 1999 г. |
8. | 19 августа 2003 г. 19 августа 2003 г. 19 августа 2003 г. |
+————————————————- —+
4 июля 1990 г. |
|————————————————- —|
6. | 9 января 1999 г. 9 января 1999 г. 9 января 1999 г. |
7. | 6 августа 1999 г. 6 августа 1999 г. 6 августа 1999 г. |
8. | 19 августа 2003 г. 19 августа 2003 г. 19 августа 2003 г. |
+————————————————- —+
Регулярные выражения
Регулярные выражения, как правило, являются способом поиска и в некоторых случаях замены появление шаблона в строке на основе набора правил. Эти правила определяется набором операторов. Следующее Таблица показывает все операторы, которые принимает Stata, и поясняет каждый из них. Обратите внимание, что в Стате, регулярные выражения всегда заключаются в кавычки.
[ ] Квадратные скобки означают, что один из символов внутри скобки должны совпадать. Например, если я хочу найти одна буква между f и m, я бы набрал «[f-m]» а-я Диапазон указывает, что допустимо любое значение в этом диапазоне. Это чувствительно к регистру, поэтому az не совпадает с AZ, если любой регистр может считаться совпадением, включая оба a-zA-Z. Числовые значения также приемлемо в виде диапазонов (например, 0-9).
. Точка соответствует любому символу. Позволяет сопоставлять символы, которые обычно являются регулярными выражениями операторы. Например, если вы хотите сопоставить «[«, введите [ вместо всего один [. * Совпадает с нулем или более символов в предыдущем выражении. Например если бы я хотел сопоставить число, состоящее из одной или нескольких цифр, если есть число, но все же хотите указать совпадение, если остальная часть выражения подходит, я мог бы указать [0-9″ указывает что следующее выражение должно появиться в начале строки. $ Если в конце выражения появляется символ «$», это означает, что предыдущее выражение должно стоять в конце строки. Например, если бы я хотел сопоставить число, которое появилось последним в конце строки я бы указал «[0-9]+$»
| Логический оператор или, указывающий, что либо выражение предшествующий это или следующее за ним квалифицируется как совпадение. ( ) Создает подвыражение внутри большего выражения. Полезно с оператор «или» (т.е. | ), и при извлечении и замене значений. Например, если я хочу извлечь числовое значение, которое, как я знаю, следует сразу после слова или набора букв, я мог бы использовать регулярное выражение «[a-zA-Z]+([0-9]+)» соответствует всему выражение, но позволяет выбрать часть в скобках (называется подстрокой). Обработка подстрок обсуждается в более подробно ниже. Эти выражения можно комбинировать для поиска самых разных строк.
Как упоминалось выше, есть три типа функций, которые могут быть предварительно сформированы. с регулярными выражениями в Stata (если вы творческий человек, вы можете сделать любое количество другие вещи, использующие эти функции, но основными инструментами являются встроенные функции Stata).
Стата имеет отдельные команды для каждого из трех типов действий регулярных выражений могут выполнить:
- регулярное выражение — используется для поиска совпадающих строк, оценивается как единица, если есть совпадение, и ноль иначе
- регулярных выражений — используется для возврата n -й подстроки в выражении соответствует регулярному выражению (следовательно, регулярное выражение всегда должно запускаться перед регулярными выражениями, обратите внимание что «если» оценивается первым, даже если оно появляется позже в строке синтаксис).
- regexr — используется для замены совпадающего выражения чем-то другим.
Каждый из них имеет немного отличающийся синтаксис. Строка ниже показывает синтаксис для regexm , то есть функция, соответствующая вашему регулярному выражению, где строка может быть строкой, которую вы вводите сами, строкой из макроса или обычно имя переменной. Регулярное выражение является регулярным выражение для строки, которую вы хотите найти, обратите внимание, что оно должно появиться в кавычки.
регулярное выражение ( строка , " регулярное выражение ")Для регулярных выражений, то есть для вызова всей строки или ее части, используется следующий синтаксис:
регулярных выражений ( н )Где n — это номер, присвоенный подстроке, которую вы хотите извлечь. Подстроки фактически разделяются при запуске регулярного выражения. Вся подстрока возвращается нулем, и каждая подстрока последовательно нумеруется от 1 до n. Для например, регулярное выражение(«907-789-3939», «([0-9]*)-([0-9]*)-([0-9]*)») возвращает следующее:
Подвыражение # Возвращенная строка 0 907-789-3939 1 907 2 789 3 3939 Обратите внимание, что в подвыражениях 1, 2 и 3 пропущены тире, так как они не заключаются в круглые скобки, которые отмечают подвыражения.
Вы можете еще раз взглянуть на то, как это работает, используя следующий синтаксис, который использует команду display для запуска функции.
отображать регулярное выражение("907-789-3939", "([0-9]*)-([0-9]*)-([0-9]*)") отображать регулярные выражения (0) отображать регулярные выражения (1) отображать регулярные выражения (2) отображать регулярные выражения (3)Поскольку это функции, команды регулярных выражений работают внутри других команд (например, генерировать), но не могут быть использованы сами по себе (т.е. вы не можете запустить команду в Stata с регулярное выражение(…)).

Артикул
Извлечение данных из журналов | New Relic
Опыт научил меня, что регулярные выражения — это швейцарский армейский нож в наборе инструментов разработчика, и их почти всегда лучшее регулярное выражение для текущей работы. Разработка хорошего регулярного выражения имеет тенденцию быть итеративной, а качество и надежность повышаются по мере того, как вы вводите в него новые интересные данные, включая пограничные случаи.
Работающее регулярное выражение часто бывает достаточно хорошим . Если ваши данные очень предсказуемы, то оптимизация регулярного выражения может оказаться ненужной задачей. Однако как только вы начнете использовать регулярное выражение как часть более широкой системы, в масштабе или в ненадежных наборах данных, тем больше вы должны убедиться, что оно надежное, отказоустойчивое и производительное.
Поначалу регулярное выражение может показаться сложным, но система становится логичной и предсказуемой, как только вы ее поймете. Однако обратное проектирование сложного регулярного выражения не очень весело.
В этом сообщении блога вы узнаете, как составить регулярное выражение для важного варианта использования: извлечения пар имя-значение из строки журнала, что часто является важной частью управления вашими журналами. Журналы — хороший пример того, когда вам нужны сильные регулярные выражения, потому что обычно журналы являются частью более широкой системы (в идеале у вас есть журналы для всего стека), их необходимо масштабировать вместе с вашим приложением, и они часто несовместимы. Итак, давайте взглянем на некоторые регулярные выражения — по пути вы, надеюсь, научитесь укреплять другие регулярные выражения, с которыми вы работаете.
Итак, давайте взглянем на некоторые регулярные выражения — по пути вы, надеюсь, научитесь укреплять другие регулярные выражения, с которыми вы работаете.
Синтаксический анализ строк журнала с помощью регулярного выражения
Этот вариант использования основан на реальных требованиях, которые изначально использовались для помощи клиенту в анализе своих журналов в New Relic. New Relic имеет мощный механизм анализа данных, который позволяет вам получать необработанные данные журнала и разбивать их на отдельные семантически значимые столбцы.
Вот требования для реального варианта использования:
- Данные журнала содержат несколько пар имя-значение, а также другие данные.
- Пары отображаются в формате:
(атрибут=значение). - Значения могут содержать пробелы.
- Нет необходимости собирать все пары «имя-значение».
- Некоторые пары могут присутствовать во всех строках журнала, а некоторые — нет.
- Пары могут появляться в любом порядке.

Вот пример строки журнала:
моя любимая пицца = ветчина и ананас напиток = лайм и лимонад место проведения = Лондон имя = Джеймс Бьюкенен
Для этого примера данных предположим, что вы хотите извлечь из данных поля пицца , напиток и имя . Однако вы не хотите извлекать данные места проведения или любые другие данные в строке журнала. Чтобы усложнить ситуацию, что, если вы хотите собрать эти данные из многих строк журнала, а данные не всегда представлены последовательно? Какое регулярное выражение будет отображать эти значения для вас?
TL;DR, вот регулярное выражение 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
Для этих правил:
- Не все пары ключ-значение должны присутствовать. Правило по-прежнему работает с парами ключ-значение, которые присутствуют, но не нарушается, если некоторые из пар ключ-значение отсутствуют в строке.

- Порядок пар ключ-значение не имеет значения.
- В значении допускается пробел.
Чтобы узнать больше о том, как работает правило, читайте дальше.
Синтаксический анализ с помощью Grok
Это обсуждение сосредоточится на версии правила Grok, потому что она немного чище. Также правила синтаксического анализа в New Relic написаны на Grok, что позволяет использовать существующие именованные шаблоны Grok. Поскольку Grok основан на регулярных выражениях, любое допустимое регулярное выражение также является допустимым выражением Grok. Если вы не используете Grok, просто используйте стандартную версию регулярного выражения, представленную в предыдущем разделе.
Запуск с ненадежным правилом синтаксического анализа
Давайте начнем с некоторых данных для проверки регулярного выражения. Я люблю и пиво, и пиццу, и у меня даже есть собственная дровяная печь, так что вот набор данных на тему пиццы:
1: моя любимая пицца = ветчина и ананасовый напиток = лайм и лимонад имя = Джеймс Бьюкенен
2: мой любимый напиток = лайм и лимонад имя = пицца Джеймса Бьюкенена = ветчина и ананас
3: мое любимое имя = пицца Джеймса Бьюкенена = напиток с ветчиной и ананасом = лайм и лимонад
4: моя любимая пицца=ветчина и ананасовый напиток=лайм и лимонад
5: мое любимое имя=Джеймс Бьюкенен пицца=ветчина и ананас фу=барный напиток=лайм и лимонад
6: мой любимый напиток =лайм и лимонад
Вы увидите, что этот набор данных имеет пары ключ-значение в разном порядке, разное количество пробелов и даже разное количество пар ключ-значение.
В этом примере данные пары ключ-значение в каждой строке разделены равными = знаки, такие как напиток=кола . Допустим, вы хотите извлечь три значения: пицца , напиток и имя .
Если данные всегда отображаются в виде первой строки, вы можете написать правило анализа Grok, подобное этому, которое извлекает каждое из значений:
pizza=(?
Это работает, но правило хрупкое. Он требует, чтобы значения всегда были в одном и том же порядке. Если какие-либо значения отсутствуют или есть какие-либо дополнительные данные, все правило не выполняется. Это плохо. Вы же не хотите, чтобы данные пропали, потому что они не совсем совпадают. И даже если вы уверены, что ваши данные непротиворечивы, можете ли вы быть уверены на 100%?
Если вы хотите попробовать это самостоятельно с помощью встроенного инструмента тестирования синтаксического анализа журналов в New Relic, перейдите к Журналы > Анализ > Создать правило синтаксического анализа . Вы можете вставить пример строки журнала вместе с правилом, чтобы увидеть результат. Кроме того, вы можете попробовать правило Grok, используя этот инструмент Grok.
Вы можете вставить пример строки журнала вместе с правилом, чтобы увидеть результат. Кроме того, вы можете попробовать правило Grok, используя этот инструмент Grok.
Использование правила просмотра вперед
Так как же сделать это правило анализа более надежным? Здесь на помощь приходит использование предпросмотра. Чтобы настроить таргетинг на одну пару ключ-значение, вам нужно знать две вещи: когда начинать сопоставление и когда его заканчивать. Давайте проработаем это шаг за шагом.
Найдите пару значений Возьмем эту пару значений пиццы в качестве примера. Он всегда начинается так: пицца= . Поскольку шаблон непротиворечив, можно просмотреть и записать текст следующим образом:
(?=%{DATA}pizza=(?
Это вернет следующее:
пицца: напиток с ветчиной и ананасом=лайм и лимонад name=james buchanan
ДАННЫЕ эквивалентно выражению . . Вы можете найти полезный список паттернов Grok здесь. Это правило упреждающего поиска находит все после строки  *?
*? pizza= и записывает это в поле с именем pizza . Пока это работает, значения напитка и имени также фиксируются. Таким образом, правило должно быть ограничено захватом символов и пробелов только до следующей пары имя-значение.
Чтобы захватить только значение пиццы , вы можете использовать другой просмотр вперед. Следующее правило захватывает любой символ, который не является знаком равенства. Это должно быть не жадным, то есть 9=]+?(?=(?:\s+%{WORD}=))))
Это возвращает следующее для #1: pizza:ветчина и ананас ✅
Однако оно возвращает следующее против # 2: нет совпадений! ❌
Гораздо лучше… но подождите! Вторая линия не соответствует пицце. Вы видите, почему?
Шаблон соответствует данным, за которыми следует другая пара «имя-значение» , , но в этом случае правило просматривает всю строку и дополнительных пар «имя-значение» нет. Захват должен быть расширен до 9=]+?(?=(?:\s+%{WORD}=|%{SPACE}?$))))
Захват должен быть расширен до 9=]+?(?=(?:\s+%{WORD}=|%{SPACE}?$))))
Возврат против #1: pizza:ветчина и ананас ✅
Возврат против #2 : пицца:ветчина и ананас ✅
Это намного лучше и надежнее. Если вы просто хотите захватить одно поле, все готово. Однако при работе с журналами вам часто нужно записывать несколько полей.
Захват нескольких полей в журналахВы можете связать несколько выражений вместе, чтобы захватить другие значения, повторяя одно и то же выражение и изменяя имена значений по мере необходимости: 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))
Это возвращает следующее:
Строка #1: pizza:ветчина и ананас, имя :james buchanan and drink:лайм и лимонад ✅
Строка №2: аналогична №1 ✅
Строка №3: аналогична №1 ✅
Строка №4: нет совпадений! ❌
Это работает для строк с первой по третью образца данных. Теперь правило возвращает совпадения независимо от порядка пар ключ-значение. К сожалению, это не удается для четвертой строки ввода:
К сожалению, это не удается для четвертой строки ввода:
4: моя любимая пицца=ветчина и ананасовый напиток=лайм и лимонад
Вы могли заметить, что в четвертой строке отсутствует ключ имя . Правило регулярного выражения требует наличия имени , иначе весь шаблон не работает. Это распространенная ошибка, которая часто остается незамеченной при использовании регулярных выражений с наборами данных. Как вы можете себе представить, справиться с такого рода проблемами может быть очень сложно, потому что кажется, что правило работает правильно, но не собирает важную информацию. Вы можете исправить это, сделав каждый шаблон необязательным 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
Это возвращает:
Строка №1: пицца: ветчина и ананас, имя: Джеймс Бьюкенен и напиток: лайм и лимонад № 1 ✅
Строка № 4: пицца: ветчина и ананас, напиток: лайм и лимонад ✅
Строка № 5: то же, что и № 1 ✅
Строка № 6: напиток: лайм и лимонад ✅
9
Правило правильно сопоставляет все тестовые входные данные в любом порядке и продолжает работать для отсутствующих полей.

Об авторе