Как посчитать среднесписочную численность за квартал: Расчет средней численности работников предприятия
Среднесписочная численность в расчете 4-ФСС (нюансы)
Среднесписочная численность в ФСС-4 — расчет ее предполагает участие в нем довольно большого количества показателей. Рассмотрим процедуру этого расчета поэтапно.
Указание в форме 4-ФСС среднесписочной численности работников в 2019-2020 годах: на что обратить внимание
В форме 4-ФСС (утверждена приказом ФСС от 26.09.2016 № 381) среднесписочная численность работников указывается в отдельном поле титульного листа. Соответствующий показатель отражается в соответствии с приказом ФСС от 07.06.2017 № 275 за период с начала года. В действовавшей ранее редакции приказа № 381 среднесписочная численность заполнялась на отчетную дату.
А вот поля «Численность работающих инвалидов» и «Численность работников, занятых на работах с вредными/опасными производственными факторами» заполняются согласно списочной численности соответствующих категорий сотрудников на отчетную дату.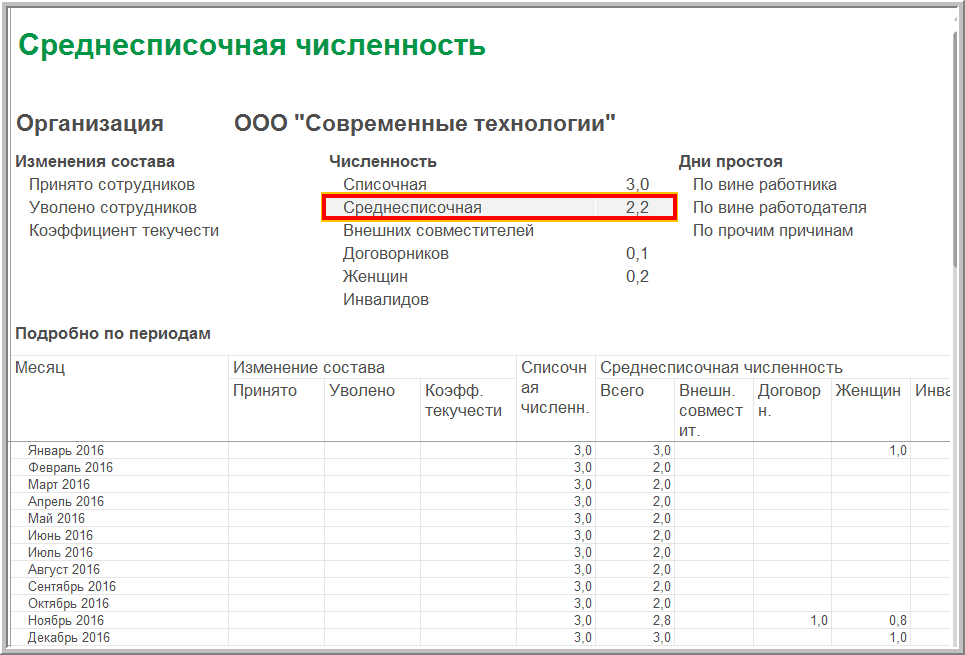
Разъяснения по заполнению расчета 4-ФСС см. здесь.
Как рассчитать для 4-ФСС среднесписочную численность работников: этапы
Расчет рассматриваемого показателя за тот или иной квартал осуществляется в 5 этапов:
1. Исчисление среднесписочной численности всех работников за все дни месяцев с начала года, то есть если отчет сдается за 1 квартал 2020 года, то среднесписочная численность считается за январь-март 2020 года.
2. Исчисление среднесписочной численности по сотрудникам с неполной занятостью за все дни месяцев с начала года.
3. Исчисление среднесписочной численности сотрудников отдельно за каждый месяц.
4. Исчисление среднесписочной численности по работникам с неполной занятостью за каждый месяц.
5. Определение среднесписочной численности специалистов за период с начала года.
Такой алгоритм соответствует порядку определения среднесписочной численности, который Росстат рекомендует применять при
Расчет среднесписочной численности за квартал
Составление ряда отчетов – налоговых и статистических – является основанием для расчета показателя среднесписочной численности работников. Определить его значение можно за любой интересующий промежуток в зависимости от потребностей фирмы. Рассмотрим, как считается среднесписочная численность за квартал и на какие особенности следует обратить внимание при расчете.
Определить его значение можно за любой интересующий промежуток в зависимости от потребностей фирмы. Рассмотрим, как считается среднесписочная численность за квартал и на какие особенности следует обратить внимание при расчете.
В каком случае необходим расчет среднесписочной численности (за квартал, год)
Наличие наемного персонала в соответствии с законодательством становится основанием для предоставления в уполномоченные органы определенных отчетов. Так, расчет показателя требуется при составлении расчета по взносам от несчастных случаев и профессиональных заболеваний 4-ФСС, формировании статистических отчетов П-4 и 1-Т, а также ежегодного предоставления в налоговые органы сведений о среднесписочной численности наемного персонала.
При исчислении величины среднесписочной численности следует руководствоваться положениями, прописанными в следующих нормативных документах:
- Приказ Росстата №357 от 03.08.15г.;
- Приказ Росстата №498 от 26.10.15г.;
- Приказ Росстата №536 от 27.
 08.14г.
08.14г. - Инструкция, определяющая тонкости статистического учета численности рабочих и зарплаты, которая в 1987 году была утверждена Постановлением Госкомстата СССР (далее – Инструкция).
Организации, которые осознают значимость проведения аналитических мероприятий для дальнейшего развития бизнеса, на основании полученного показателя среднесписочной численности имеют возможность определить, насколько высока эффективность привлеченных кадров, динамику среднего уровня оплаты труда и иные существенные показатели.
Среднесписочная численность работников для ФСС
Как рассчитать среднесписочную численность за квартал. Что включить в расчет?
Исчисление показателя средней списочной численности базируется на таком показателе, как численность списочного состава. Немало сомнений возникает при определении категорий персонала, которые подлежат включению в расчет данного показателя.
В соответствии с Инструкцией в численности списочного состава должны быть учтены следующие категории работников:
- Весь персонал организации, с которым подписаны актуальные трудовые контракты, которые ежедневно исполняет, возложенные компанией трудовые функции, включая тех, которые, присутствуя на рабочих местах, не имеют возможности трудиться по причине простоя;
- Сотрудники организации, которые работают по договору на условиях сокращенной продолжительности рабочего времени, а именно неполного рабочего дня или неполной рабочей недели.
 В данную группу не входит персонал, в отношении которого государством предусмотрено введений сокращенной продолжительности;
В данную группу не входит персонал, в отношении которого государством предусмотрено введений сокращенной продолжительности; - Работники, находящиеся в служебных командировках, в том случае, если в соответствии с требованиями законодательства командировка оформлена документально на основании распоряжения руководителя фирмы, а за сотрудником сохранена занимаемая должность и оклад;
- Персонал, отсутствующий на рабочих местах по больничным листам в течение всего периода нетрудоспособности;
- Работники, трудящиеся вне рабочего места на территории организации, то есть удаленно;
- Сотрудники, которые были приняты в компанию на условиях испытательного срока, начиная с первого рабочего дня;
- Персонал, в обязанности которого входит исполнение профессиональных обязанностей на иных территориях, то есть вахтовым методом;
- Работники в декрете, включая период отпуска по беременности и родам и отпуск по уходу за ребенком до полутора лет;
- Сотрудники, направленные в отпуска вне зависимости от того, является ли отпуск основным ежегодным или дополнительным.
 В эту группу также входят те работники, которые по согласованию с руководством получили отпуск за свой счет;
В эту группу также входят те работники, которые по согласованию с руководством получили отпуск за свой счет;
Действующая на сегодняшний день инструкция установила группы работников, которые должны быть исключены из расчета. К ним относят:
- Персонал, который на основании подписанных договоров гражданско-правового характера был привлечен для выполнения в компании работ однократно;
- Внешние совместители организации, для которых основным местом работы будет являться иная организация;
- Сотрудники, которые были временно переведены для работы другую организацию, но за которыми не было была сохранена занимаемая должность и оклад;
- Персонал компании, который находится на этапе увольнения в том случае, если заявление на имя руководителя сотрудником уже было подано, но не рассмотрено, при условии, что работник уже отсутствует на рабочем месте.
- Работники, которые были привлечены в организацию для выполнения разовых работ на основании договоров гражданско-правового характера.
Среднесписочная численность за квартал формула
У хозяйствующих субъектом может возникнуть потребность исчислить значение среднесписочной численности за любой возможный промежуток времени. Как считается среднесписочная численность за квартал? Однако, какой бы период не брался в расчет, первоначально потребуется рассчитать значение за один месяц.
Среднесписочная численность за один месяц рассчитывается как сумма средней списочной численности работников, которые трудятся на условиях полного и неполного рабочего дня. Рассмотрим, какая при этом будет применяться формула:
Численностьсреднесписочная мес. = Численностьсреднесписочная полный день + Численностьсреднесписочная неполный день;
Необходимо рассчитать значение составных показателей, а именно средней списочной численности сотрудников полного и неполного рабочего дня.
Численностьсреднесписочная полный день = Списочнаячисленность= / Число календарных дней;
В этой формуле одним из составных показателей будет являться списочная численность наемного персонала, рассчитать которую можно с помощью коэффициента списочного состава. Коэффициент списочного состава исчисляется как частное от деления номинального фонда рабочего времени и фактическое количество дней во взятом за основу периоде. Соответственно, списочная численность будет определяться следующим образом:
Коэффициент списочного состава исчисляется как частное от деления номинального фонда рабочего времени и фактическое количество дней во взятом за основу периоде. Соответственно, списочная численность будет определяться следующим образом:
Списочнаячисленность= К-т списочного состава * Явочная численность.
Расчет показателей неполного по существу будет более трудоемким, так как потребуется определить величину показателя человека-дней, отработанных сотрудниками, и на основании этого произвести расчет средней численности. Представить это можно с помощью следующей формулы:
Количество человеко-дней = Фактически отработанные часы / Нормативная продолжительность рабочего дня;
На основании вышеизложенного:
Численностьсреднесписочная неполный день = ∑человеко-дней / Число календарных дней.
Для составления определенных отчетов, в частности расчета по страховым взносам 4-ФСС, а также для проведения аналитических мероприятий потребуется расчет показателя средней списочной численности за один квартал
Для того чтобы определить величину средней списочной численности за один квартал применяется следующая формула:
Численностьсреднесписочная квартал = (Численностьсреднесписочная мес1 + Численностьсреднесписочная мес2 + Численностьсреднесписочная мес3) / 3.
Таким образом, отвечая на вопрос о том, как посчитать среднесписочную численность за квартал, следует обратиться к актуальным положениям действующего законодательства, а именно Приказам органов статистики и Инструкции Постановления Госкомстата от 1987 года, и представленным выше формулам. При этом следует помнить, что расчет средней численности за квартал или календарный год начинается с определения значения данной величины за один месяц.
Среднесписочная численность в ФСС-4 (общие положения на 2020)
Численность работников, указанная на титульном листе 4-ФСС, рассчитывается как среднесписочный показатель. Количество среднесписочного состава работников определяется с начала года по отчетный период путем деления сумм ежемесячной численности на количество месяцев. Рассмотрим актуальные примеры расчета на 2020 год.
В отчетности среднесписочный показатель указывают за квартал, полугодие, 9 месяцев, год с учетом данных с начала налогового периода.
Общие положения подсчета среднесписочной численности
Среднесписочное количество работающих не идентично численности сотрудников, утвержденных штатным расписанием. Порядок определения среднесписочной численности (СЧ) установлен Росстатом в приказе от 26.10.2015 № 428 в редакции, принятой 06.02.2017.
При расчете среднесписочного показателя используются принципы:
- Подсчет лиц за месяц производится в каждый календарный день, включая выходные или праздничные дни.
- Численность сотрудников нерабочего дня определяется по предшествующему выходному рабочему дню. Аналогично учитывается количество лиц при возникновении нескольких нерабочих дней.
- Лицо, имеющее выходной день в соответствии с графиком исполнения обязанностей, включается в расчет по данным предшествующего дня.

- Показатель выводится по результатам месяца. По данным каждого месяца выводится показатель за любой период с начала года.
- Численность устанавливается в целых единицах с округлением в большую или меньшую сторону в зависимости от величины дробного показателя.
Основанием для получения данных о количестве работников служит информация из табелей, кадровых приказов по предприятию. Ответственному работнику необходимо иметь сведения о лицах, которым установлен неполный трудовой день. В основе данных о среднесписочном числе работников лежит списочная численность – количество лиц, числящихся в организации или ИП в конкретный день.
Этапы расчета среднесписочной численности
Для получения показателя максимально возможной точности необходимо соблюсти очередность действий и произвести рутинную работу.
| Действие для получения показателя | Описание |
| Выборка количества лиц за каждый день месяца | Подбор данных производится на основании первичных документов. Выборка производится ежедневно либо, при малой численности, в последний день месяца за каждый день Выборка производится ежедневно либо, при малой численности, в последний день месяца за каждый день |
| Производится расчет показателя | Показатель среднесписочной численности месяца рассчитывают путем деления количества лиц за каждый день на число дней |
| Определяется среднесписочная численность на отчетную дату | При получении показателя на отчетную дату применяется аналогичный порядок с учетом данных с начала года: суммарная численность за каждый месяц с начала года делится на количество месяцев, приходящихся на отчетную дату |
Пример расчета ⇓
Организация ООО «Вызов» ведет учет СЧ для отражения данных в отчете. За январь 2017 года количество лиц составило 125, февраль – 130, март – 110 человек. При подсчете количества за 1 квартал ответственный работник предприятия производит действия:
- Определяет суммарное число лиц за 3 месяца: Ч = 125 + 130 + 110 = 365 человек;
- Рассчитывает среднесписочное количество лиц: Ср = 365 / 3 = 121,67.

Число лиц всегда представляют в целых числах, в отчетности указывается показатель в количестве 122 человек (Читайте также статью ⇒ Расчет страховых взносов по форме 4-ФСС).
Лица, включенные в расчет и исключенные из списка при подсчете численности
В расчет среднесписочной численности включаются лица вне зависимости от факта нахождения на рабочем месте. Сотрудники могут отсутствовать по причине болезни, отпуска, в связи с исполнением государственных обязанностей. При включении их в состав численности учитываются лица с уважительными причинами отсутствия и сохранением средней заработной платы. При выборке количества трудоустроенных лиц предприятия часть работников не подлежит учету в среднесписочной численности.
| Лица, включаемые в расчет | Лица, исключаемые из расчета среднесписочной численности |
| Наемные работники, принятые на постоянную, временную или сезонную работу по трудовому контракту | Лица, трудоустроенные по договорам ГПХ |
| Внутренние совместители | Внешние совместители |
| Работники, отсутствующие по болезни, подтвержденной документом медицинского учреждения | Сотрудницы, находящиеся в отпуске по БиР, по уходу за ребенком |
| Лица на испытательном сроке | Потенциальные сотрудники, с которыми оформлен ученический договор с оплатой на время обучения |
| Работники, находящиеся в очередном отпуске | Лица, получившие отпуск без оплаты в связи с поступлением в учебное заведение |
Особые правила установлены для отражения в показателе численности совместителей. Работник, принятый по договору о внутреннем совместительстве, отражается в количестве 1 штатной единицы. Временные работники других предприятий не учитываются. Кроме совместительства, применяется совмещение либо замещение должностей в связи с внутренней необходимостью. При совместительстве должностей численность не увеличивается.
Работник, принятый по договору о внутреннем совместительстве, отражается в количестве 1 штатной единицы. Временные работники других предприятий не учитываются. Кроме совместительства, применяется совмещение либо замещение должностей в связи с внутренней необходимостью. При совместительстве должностей численность не увеличивается.
Расчет среднесписочного количества сотрудников с частичной занятостью
Учет в численности лиц с неполным трудовым днем или неделей зависит от инициатора уменьшения нормального рабочего дня или недели. При учете численности придерживаются принципам:
- Лица, переведенные на сокращенный трудовой день (смену, неделю) по воле работодателя без их согласия, включаются в расчет как целые единицы.
- В подобном порядке учитывается число сотрудников, в отношении которых законами о труде установлена сокращенная длительность рабочего времени. К данной категории лиц относятся несовершеннолетние, инвалиды, родители детей с инвалидностью, сотрудники, занятые на работах с повышенной вредностью.

- Лица, исполняющие обязанности по схеме неполного графика, установленного по согласованию с сотрудником, включаются в расчет в соответствии с отработанным временем.
- Показатель в день отсутствия работника по уважительной причине равен данным предшествующего дня.
При наличии на предприятии в составе штатных сотрудников лиц с частичной занятостью в расчет включается отработанные человеко-дни. Показатель количества не полностью занятых лиц рассчитывается как частное отработанных человеко-часов к месячной норме времени (Читайте также статью ⇒ Раздельный учет страховых взносов в 2020 году).
Пример включения в расчет лиц с частичной занятостью ⇓
На предприятии с 40 часовой неделей трудятся 3 работника по графику неполного дня. В расчетном месяце количество рабочих дней составляет 20 дней. В учет включаются количество лиц согласно отработанного времени:
- М. трудится по 32 часа в неделю с ежедневым выходом: С1 = 128 / 160 = 0,8 чел.;
- П. работает 4 часа в день: С2 = 80 / 160 = 0,5 чел.;
- Б. – 2 часа в день: С3 = 40 / 160 = 0,25 чел.;
- Общая численность лиц с неполным графиком составила: С = 0,8 + 0,5 + 0,25 = 1,55 человек.
Суммарная численность по лицам с частичной занятостью ежедневно составляет 1,55 человек.
Вопрос № 1. Включаются ли в среднесписочную численность собственники – учредители ООО?
В численности учитываются учредители, оформленные как работники общества, например, на должности директора. Учредители, чьи действия ограничиваются руководящей функцией, не отражаются в расчете.
Расчет среднесписочной численности для отчетности
В октябре 2015 года Росстатом были утверждены новые указания по заполнению формы, которая позволяла выполнять наблюдение за текучестью кадров на предприятии и использовать эти сведения для заполнения отчетности в ФНС в виде расчета среднесписочной численности работников. Рассмотрим все вопросы, связанные с заполнением расчета за квартал, полугодие, девять месяцев и год, а также на способе расчета необходимых показателей за месяц.
Особенности составления списка численности работников
Прежде всего следует отметить, что средняя численность работников определяется помесячно, и каждый сотрудник выступает в роли целой единицы. В списочную численность должны также включаться и наемные работники, с которыми у работодателя заключен трудовой договор.
Не имеет значения, какой тип работы выполняют данные лица: постоянную, временную, сезонную. Даже если человек справился с поставленной задачей за один день и получил заработную плату, то он учитывается как отдельная единица и отражается в отчете:
Существует специальный перечень работников, которые обязательно должны быть учтены при составлении отчетности:
- те, кто фактически осуществляет трудовую деятельность на предприятии или отсутствует по причине простоя;
- находящиеся в командировке;
- отсутствующие по причине временной нетрудоспособности;
- выполняющие государственные или общественные поручения и по этой причине отсутствующие на рабочем месте;
- работающие неполный день или неделю, а также на неполную ставку;
- состоящих на испытательном сроке;
- работающих на дому;
- проходящие дополнительное обучение;
- студенты, проходящие производственную практику или находящиеся в учебном отпуске;
- находящиеся в ежегодном отпуске, по беременности и родам, на выходном или в отгуле;
- принимающие участие в забастовках;
- иностранные граждане, трудоустроенные в организации;
- находящиеся под следствием;
- внутренние совместители учитываются как один человек.
Получите 267 видеоуроков по 1С бесплатно:
Кроме данного перечня, существует список, согласно которому, работники не могут быть включены при расчете средней численности:
- внешние совместители;
- лица, выполняющие работу по договору ГПХ;
- работающие по спец. договорам;
- поступившие на работу в другую фирму по переводу;
- сотрудники, имеющие с работодателем ученический договор на проф. обучение;
- подавшие заявление на увольнение и прекратившие выполнять свои обязанности ранее утвержденного срока;
- собственники компании, не получающие зарплату;
- члены кооператива, не состоящие в трудовых отношениях с компанией;
- адвокаты;
- военнослужащие.
Используя эти два списка, ответственное лицо определяет списочную численность работников помесячно, а затем выполняет для отчетности расчет среднесписочной численности.
Порядок и формула расчета среднесписочной численности
Для расчета среднесписочной численности работников, необходимо, прежде всего, исключить их общего перечня следующие лица:
- женщин, находящихся в отпуске декретном;
- работников в отпусках по причине усыновления новорожденного из род.дома;
- работников, пребывающих в отпуске по уходу за ребенком до 1,5-3 лет;
- сотрудников, находящихся на обучении без сохранения зарплаты.
При выполнении расчета необходимо учесть следующее:
- определить общее число человеко-дней, которые отработал каждый сотрудник, делением общего числа человеко-часов в отчетном периоде на продолжительность рабочего дня. К примеру, по 40-часовой рабочей неделе, где работник трудится всего пять дней, один человеко-час составляет 8 часов;
- вычислить среднюю численность работников, занятых неполный день, делением отработанных человеко-дней на число рабочих дней, при этом дни болезни, отпуска или неявок условно включаются в расчет:
Расчет среднесписочной численности за полугодие, девять месяцев и год, производится путем суммирования всех показателей, полученных за месяцы отчетного периода и делением общей суммы на количество месяцев:
Пример расчета среднесписочной численности за квартал
Приведем пример расчета среднесписочной численности сотрудников предприятия за 1 квартал. Для этого составим небольшую таблицу:
| Месяц | Число дней в месяце | Количество сотрудников | Порядок расчета | Среднесписочный показатель |
| Январь | 31 | 120 | 120 | 3,9 |
| Февраль | 29 | 117 | 117 | 4,03 |
| Март | 31 | 123 | 123 | 3,9 |
| Итоги за квартал | 91 | 360 | 360/91 | 3,9 |
Из таблицы видим, что среднесписочная численность за один день составила 3,9 человека. Теперь, чтобы получить средний показатель за 1 квартал 2017 года, достаточно умножить полученный результат на среднее число дней в месяце 29,4. В результате мы получим показатель в 114,6. Округляем, и получается среднесписочная численность человек в компании за первый квартал, равна 115 единицам.
Как рассчитать среднесписочную численность работников?
Входят ли в среднесписочную численность работники, работающие по совместительству. Учитываются ли они?
Подробная методика расчета среднесписочной численности приводится в двух документах:
1) Указания по заполнению формы федерального статистического наблюдения № 1-Т «Сведения о численности и заработной плате работников»[1];
2) Указания по заполнению форм федерального статистического наблюдения: № П-1 «Сведения о производстве и отгрузке товаров и услуг», № П-2 «Сведения об инвестициях», № П-3 «Сведения о финансовом состоянии организации», № П-4 «Сведения о численности, заработной плате и движении работников», № П-5(м) «Основные сведения о деятельности организации»[2].
Согласно этим документам для определения среднесписочной численности работников за месяц нужно просуммировать списочную численность работников за каждый календарный день месяца, включая праздничные (нерабочие) и выходные дни, и разделить полученную сумму на число календарных дней месяца.
Среднесписочная численность работников за год определяется путем суммирования среднесписочной численности работников за все месяцы отчетного года и деления полученной суммы на 12.
Определение списочной численности работников
Расчет среднесписочной численности работников производится на основании ежедневного учета списочной численности работников. Численность работников списочного состава за каждый день должна соответствовать данным табеля учета рабочего времени работников, на основании которого устанавливается численность работников, явившихся и не явившихся на работу.
Среднесписочная численность работников рассчитывается на основании списочной численности, которая приводится на определенную дату, например на последнее число отчетного периода.
В списочную численность работников включаются наемные работники, работавшие по трудовому договору и выполнявшие постоянную, временную или сезонную работу один день и более, а также работавшие собственники организаций, получавшие заработную плату в данной организации.
В списочной численности работников за каждый календарный день учитываются как фактически работающие, так и отсутствующие на работе по каким-либо причинам, например:
• фактически явившиеся на работу, включая и тех, которые не работали по причине простоя;
• находившиеся в служебных командировках, если за ними сохраняется заработная плата в данной организации, включая работников, находившихся в краткосрочных служебных командировках за границей;
• не явившиеся на работу по болезни;
• не явившиеся на работу в связи с выполнением государственных или общественных обязанностей;
• принятые на работу с испытательным сроком;
• надомники;
• направленные с отрывом от работы в образовательные учреждения для повышения квалификации или приобретения новой профессии (специальности), если за ними сохраняется заработная плата;
• обучающиеся в образовательных учреждениях, аспирантурах, находящиеся в учебном отпуске с сохранением полностью или частично заработной платы;
• находившиеся в ежегодных и дополнительных отпусках, предоставляемых в соответствии с законодательством, коллективным договором и трудовым договором, включая находившихся в отпуске с последующим увольнением;
• получившие день отдыха за работу в выходные или праздничные (нерабочие) дни;
• находившиеся в отпусках по беременности и родам, а также в отпуске по уходу за ребенком;
• принятые для замещения отсутствующих работников;
• совершившие прогулы и некоторые другие.
Работники, принятые на работу по совместительству из других организаций, не включаются в списочную численность, а следовательно, не учитываются при расчете среднесписочной численности. Учет внешних совместителей ведется отдельно.
Работники, получающие в одной организации две, полторы или менее одной ставки или оформленные в одной организации как внутренние совместители, учитываются в списочной численности работников как один человек (целая единица).
Помимо внешних совместителей, в списочную численность не включаются следующие работники:
• выполнявшие работу по договорам гражданско-правового характера;
• направленные организациями на обучение в образовательные учреждения с отрывом от работы, получающие стипендию за счет средств этих организаций; лица, с которыми заключен ученический договор на профессиональное обучение с выплатой в период ученичества стипендии;
• подавшие заявление об увольнении и прекратившие работу до истечения срока предупреждения или прекратившие работу без предупреждения администрации. Они исключаются из списочной численности работников с первого дня невыхода на работу;
• собственники данной организации, не получающие заработную плату, и некоторые другие.
Кроме того, следует иметь в виду, что некоторые работники, учитываемые в списочной численности, не включаются в среднесписочную численность.
К таким работникам относятся:
• женщины, находившиеся в отпусках по беременности и родам, лица, находившиеся в отпусках в связи с усыновлением новорожденного ребенка непосредственно из родильного дома, а также в отпуске по уходу за ребенком;
• работники, обучающиеся в образовательных учреждениях и находившиеся в дополнительном отпуске без сохранения заработной платы, а также поступающие в образовательные учреждения, находившиеся в отпуске без сохранения заработной платы для сдачи вступительных экзаменов в соответствии с законодательством Российской Федерации.
[1] Утверждены приказом Росстата от 13.10.2008 № 258 (в ред. от 23.10.2009).
[2] Утверждены приказом Росстата от 12.11.2008 № 278 (в ред. от 14.03.2011).
М. В. Журавлева,
специалист по кадрам
Как рассчитать и использовать показатель AUC | Надим Кавва
От теории к применению
Фото Юргена Шеффа на UnsplashКривая рабочего режима приемника (ROC) — это графический график, который позволяет нам оценить производительность бинарных классификаторов. При несбалансированных наборах данных оценка площади под кривой (AUC) рассчитывается на основе ROC и является очень полезной метрикой в несбалансированных наборах данных.
В этом посте мы рассмотрим теорию и реализуем ее на Python 3.х код. Содержание адаптировано из Data Mining (SENG 474), преподаваемой Марьям Шоаран из Университета Виктории.
В этом примере мы будем использовать набор данных по раку груди в Висконсине, доступный на sklearn. Прежде чем перейти к оценке модели и погрузиться в основную тему этого поста, мы сделаем следующее:
- Разделим данные между обучением и тестированием
- Масштабирование функций
- Подгонка модели логистической регрессии (LR)
Когда мы думаем о классификаторах, таких как Naive Bayes (NB) или LR, они дают вероятность или оценку экземпляра.Этот классификатор скоринга можно использовать с порогом для генерации решения, такого как «Да» или «Нет».
Классификация с пороговым значением, следовательно, монотонна, и мы можем использовать это свойство для создания пространства ROC. Ключевая идея формулируется следующим образом:
Любой экземпляр, который классифицируется как положительный по отношению к данному пороговому значению, будет также классифицирован как положительный для всех нижних пороговых значений .
Следовательно, для LR, если оценка вероятности классификатора выше порогового значения, он будет генерировать положительное предсказание класса, в противном случае — отрицательное предсказание класса.
Более того, многие дискретные классификаторы, такие как деревья решений или наборы правил, могут быть преобразованы в оценочные классификаторы, заглянув внутрь них и хранящейся в них статистике экземпляра. Например, пропорции классов могут служить оценкой, решение класса — это просто самый распространенный класс.
Для нашего примера мы подбираем данные по классификатору LR и суммируем результаты в таблице df_pred ниже:
График ROC создается из линейного сканирования.Используя информацию в таблице выше, мы выполняем следующие шаги:
- Сортировка вероятностей для положительного класса по убыванию
- Перемещение вниз по списку (уменьшение порога), обработка по одному экземпляру за раз
- Вычисление истинного положительного коэффициента (TPR) и частота ложных срабатываний (FPR) по мере продвижения
Напомним, что TPR и FPR определяются следующим образом:
- TPR = истинные положительные результаты / все положительные результаты
- FPR = ложные положительные результаты / все отрицательные результаты
Мы отсортировали фрейм данных из предыдущего раздела и создал из него новый под названием df_roc , который выглядит следующим образом:
После сортировки информации мы запускаем блок кода ниже, который возвращает два массива: один для TPR и один для FPR.
Построив наши результаты, мы получим знакомую кривую ROC:
Оценка AUC — это просто площадь под кривой, которую можно рассчитать с помощью правила Симпсона. Чем больше показатель AUC, тем лучше наш классификатор.
Фото Джона Гиббонса на UnsplashУчитывая два классификатора A и B, мы ожидаем две разные кривые ROC. Рассмотрим график ниже:
Источник: Марьям ШоаранЗаштрихованная область известна как выпуклая оболочка, и мы всегда должны работать в точке, которая лежит на верхней границе выпуклой оболочки.
Например, если мы хотим работать при 40% TPR, мы выбираем классификатор A, который соответствует FPR примерно 5% . В качестве альтернативы, если мы хотим покрыть 80% TPR, мы выбираем классификатор B, который дает лучший FPR, чем A.
представьте, что мы страховая компания и хотим продавать страховые полисы клиентам. Однако из-за бюджетных ограничений мы можем охватить только 800 клиентов из 4000 потенциальных клиентов.Ожидаемая скорость ответа составляет 6%, , что означает, что 240 скажут «да», а 3760 — нет.
Предположим, у нас есть два классификатора A и B, такие, что лучшая точка A — (FPR = 0,1, TPR = 0,2), а лучшая точка B (FPR = 0,25, TPR = 0,6).
Если мы будем основывать наше решение на классификаторе A, мы будем ожидать следующего числа кандидатов: 0,1 * 3760 + 0,2 * (240) = 424 . Для B это: 0,25 * 3760 + 0,6 * (240) = 1084 .
С классификатором A мы обращаемся к слишком немногим, а с классификатором B мы превышаем наш бюджет.Решение этой проблемы показано графически на графике ниже:
Источник: Марьям Шоаран Между A и B находится точка C (0,18, 0,42) на линии ограничения, и это даст желаемую производительность. Мы вычисляем k как пропорциональное расстояние, которое C лежит между A и B. Мы рассчитываем его как k = (0,18–0,1) / (0,25–0,1) =. 53 .
На практике это означает, что для каждой точки, которую мы хотим классифицировать, следуйте этой процедуре, чтобы достичь производительности C:
- Сгенерируйте случайное число от 0 до 1
- Если число больше k, примените классификатор A
- Если число меньше k применить классификатор B
- Повторить для следующей точки
Как и в случае любой другой задачи науки о данных, одной метрики недостаточно, чтобы рассказать всю историю.Помимо AUC, такие показатели, как точность, выпадение осадков и оценка f1, могут рассказать нам больше о том, как работают классификаторы.
Разбивка средней средней точности (mAP) | by Ren Jie Tan
Еще одна метрика для вашего инструментария для анализа данных
Фото Шахина Ешиляпрака на UnsplashЕсли вы сталкивались с проблемой классов визуальных объектов PASCAL (VOC) и общих объектов MS в контексте (COCO) или пробовали работать с проектами, включающими После извлечения информации и повторной идентификации (ReID) вы, возможно, уже хорошо знакомы с метрикой, называемой mAP.
Средняя средняя точность (mAP) или иногда просто AP — популярный показатель, используемый для измерения производительности моделей, выполняющих задачи получения документов / информации и обнаружения объектов.
Средняя средняя точность (mAP) набора запросов определяется Википедией как таковая:
Формула средней средней точности, предоставленная Википедией, где Q — количество запросов в наборе, а AveP (q) — это средняя точность (AP) для данного запроса, q.
Формула по существу говорит нам о том, что для данного запроса q мы вычисляем соответствующую ему AP, а затем среднее значение всех этих оценок AP даст нам одно число, называемое mAP, которое количественно определяет, насколько хорошо наша модель выполняет запрос.
Это определение сбивает с толку людей (вроде меня), которые только начинают работать в этой области. У меня были вопросы, например, что это за набор запросов? А что значит AP? Это просто средняя точность?
В этой статье мы надеемся ответить на эти вопросы и рассчитать MAP как для задач обнаружения объектов, так и для задач поиска информации.В этой статье также будет рассмотрено, почему mAP является подходящей и широко используемой метрикой для задач поиска информации и обнаружения объектов.
- Primer
- AP и mAP для поиска информации
- AP и mAP для обнаружения объектов
Точность и отзыв являются двумя обычно используемыми показателями для оценки эффективности данной модели классификации. Чтобы понять MAP, нам нужно сначала проверить точность и отзыв.
Наиболее «знаменитая» точность и отзыв
В области статистики и науки о данных, точность определенного класса в классификации, a.k.a. положительное предсказанное значение дается как отношение истинно положительного (TP) к общему количеству предсказанных положительных результатов. Формула представлена как таковая:
Формула точности для данного класса в классификацииАналогичным образом, отзыв , также известный как истинная положительная скорость или чувствительность, данного класса в классификации, определяется как отношение TP и общей достоверности положительные. Формула представлена как таковая:
Вызов формулы данного класса в классификацииПросто взглянув на формулы, мы могли подозревать, что для данной модели классификации существует компромисс между ее точностью и эффективностью отзыва.Если мы используем нейронную сеть, этот компромисс может быть скорректирован с помощью порогового значения softmax последнего слоя модели.
Чтобы наша точность была высокой, нам нужно уменьшить количество FP, тем самым уменьшится наш отзыв. Точно так же уменьшение количества FN повысит наш отзыв и снизит точность. Очень часто в случаях поиска информации и обнаружения объектов мы хотели бы, чтобы наша точность была высокой (наши предсказанные положительные результаты должны быть TP).
(источник)Точность и отзыв обычно используются вместе с другими показателями, такими как точность, F1-оценка, специфичность, a.k.a. истинная отрицательная скорость (TNR), рабочие характеристики приемника (ROC), подъемная сила и усиление.
Менее «известная» точность и отзыв
Однако, когда дело доходит до поиска информации, определение отличается от .
В соответствии с определением Wiki, точность определяется как отношение полученных документов, которые имеют отношение к запросу пользователя, к полученным документам .
Формула точности для поиска информации, данная WikiСохраняя номенклатуру, подобную формуле, определенной выше, соответствующий документ может рассматриваться как TP.
По умолчанию точность учитывает все извлеченные документы, но, тем не менее, она также может быть оценена по заданному количеству извлеченных документов, обычно известному как пороговый рейтинг, когда модель оценивается только с учетом только ее верхнего уровня. большинство запросов. Эта мера называется точностью при k или P @ K.
Давайте использовать пример, чтобы лучше понять формулу.
Определение типичной задачи поиска информации
Типичная задача при поиске информации заключается в том, что пользователь предоставляет запрос к базе данных и извлекает информацию, очень похожую на запрос.Давайте теперь выполним вычисление точности на примере с , тремя положительными точными показаниями (GTP).
Дополнительная номенклатура: Положительные результаты — это данные, помеченные как положительные. Другими словами, соответствующие документы.
Мы определим следующие переменные:
- Q — запрос пользователя;
- G — набор помеченных данных в базе данных;
- d (i, j) — функция оценки, показывающая, как похожий объект i соответствует j
- G ‘, который упорядоченный набор G в соответствии с функцией оценки d (,)
- k должен быть индексом G’
После вычисления d (,) для каждый из документов с Q, мы можем отсортировать G и получить G ‘.
Скажем, модель возвращает следующий G ‘
Модель вернула отсортированные результаты запроса G’Используя приведенную выше формулу точности, мы получаем следующее:
P @ 1 = 1/1 = 1
P @ 2 = 1/2 = 0,5
P @ 3 = 1/3 = 0,33
P @ 4 = 2/4 = 0,5
P @ 5 = 3/5 = 0,6
P @ n = 3 / n
Найти диапазон & Расчет среднего числа в наборе
Расчет среднего и диапазона
Математическое определение
- Среднее
- Среднее значение всех данных в наборе.
- Медиана
- Значение в наборе, наиболее близкое к середине диапазона.
- Режим
- Значение, которое чаще всего встречается в наборе данных.
- Диапазон
- Разница между самыми большими и самыми маленькими данными в наборе данных.
Пример расчета
Вычислить среднее значение, медианное значение, моду и диапазон для 3, 19, 9, 7, 27, 4, 8, 15, 3, 11.
Как найти среднее (или среднее значение)
Чтобы вычислить среднее значение, сложите числа 3 + 3 + 4 + 7 + 8 + 9 + 11 + 15 + 19 + 27 = 106, затем разделите его на количество точек данных 106/10 = 10.6.
Как найти медиану
В порядке возрастания числа: 3, 3, 4, 7, 8, 9, 11, 15, 19, 27. Всего 10 чисел, поэтому 5-е и 6-е числа используются для вычисления медианы. (8 + 9) / 2 = 8,5
Если бы в серии было 9 чисел, а не 10, вы бы взяли 5-е число и не нужно было бы усреднять 2 средних числа. 2 средних числа нужно усреднить только в том случае, если в наборе данных есть четное количество точек данных.
Как найти режим
Единственное число, которое появляется несколько раз, — 3, так что это режим.
Как найти диапазон
Чтобы вычислить диапазон, вычтите наименьшее число из наибольшего числа 27-3 = 24.
Среднее значение, медиана и мода: тенденции данных, обнаружение аномалий и использование в спорте
— Руководство Автор: Корин Б. Аренас , опубликовано 17 октября 2019 г.
В школе мы спрашиваем средний балл по тесту, чтобы узнать, иметь хорошую оценку. Когда дело доходит до покупки дорогих товаров, мы часто спрашиваем средняя цена для поиска лучших предложений.
Это всего лишь несколько примеров того, как средние значения используются в реальная жизнь.
В этом разделе вы узнаете о различных типах средних значений, а также о том, как они рассчитываются и применяются в различных областях, особенно в спорте.
Что означает термин «средний»?
Когда люди описывают «среднее» группы чисел, они часто ссылаются на среднее арифметическое. Это один из 3-х различных типов среднего, в том числе медиана и мода.
| Типы среднего | Описание |
|---|---|
| Среднее | Среднее число чисел в группе. |
| Медиана | Среднее число в наборе чисел. |
| Режим | Число, которое чаще всего встречается в наборе чисел. |
В разговорной речи большинство людей просто говорят «средний», когда они действительно имеют в виду подлость.Среднее арифметическое и среднее слова-синонимы, которые используются как синонимы, согласно Dictionary.com.
Он рассчитывается путем сложения чисел в наборе и деления их на общее число в наборе — что и делает большинство людей, когда находят среднее значение. См. Пример ниже.
Среднее
Установить: 8, 12, 9, 7, 13, 10
Среднее = (8 + 12 + 9 + 7 + 13 + 10) / 6
= 59/6
= 9,83
Среднее или среднее арифметическое в этом примере 9.83 .
Медиана
Медиана , с другой стороны, является другим типом среднее, представляющее среднее число в упорядоченной последовательности чисел. Этот работает, упорядочивая последовательность чисел (в порядке возрастания), а затем определяя число, которое встречается в середине набора. См. Пример ниже.
Средняя медиана
Набор: 22, 26, 29, 33, 39 , 40, 42, 47, 53
В этом примере 39 — это медианное или среднее значение в наборе.
Режим
Режим — в основном наиболее частое значение, которое повторяется в наборе значений. Например, если в вашем наборе 21, 9, 14, 3, 11, 33, 5, 9, 16, 21, 5, 9, какой режим?
Ответ 9, потому что это значение повторяется 3 раза.
В статистике термины «среднее», «медиана» и «мода» используются для измерить центральную тенденцию в выборочных данных. Это иллюстрируется нормальным график распределения ниже.
График нормального распределения используется для визуализации стандартного отклонения при анализе данных.Распределение статистических данных показывает, насколько часто встречаются значения в наборе данных.
На графике выше проценты представляют количество значений, попадающих в каждый раздел. Выделенные проценты в основном показывают, сколько данных приходится на середину графика.
Какая связь между средним, медианой и модой?
На первый взгляд может показаться, что связи нет между средним, медианным и модой. Но есть эмпирический взаимосвязь, существующая при измерении центра набора данных.
Математики заметили, что обычно разница между медианой и модой, и это в 3 раза больше между средним и медианным значением.
Эмпирическая взаимосвязь выражается в следующей формуле:
Среднее — Режим = 3 (Среднее — Медиана)
Рассмотрим пример данных о населении по 50 штатам. Например, среднее значение для населения составляет 7 миллионов, а медиана — 4,8. миллиона и режим 1,5 миллиона.
- Среднее значение = 7 миллионов
- Среднее значение = 4.8 миллионов
- Режим = 1,5 миллиона
Среднее — Режим = 3 (Среднее — Медиана)
7 миллионов — 1,5 миллиона = 3 (7 миллионов — 4,8 миллиона)
5,5 миллиона = 3 (2,2)
5,5 миллиона = 6,6 миллиона
Примите к сведению: Профессор математики Кортни Тейлор, доктор философии. заявил, что это не точные отношения. Когда вы делаете расчеты, цифры не всегда точны. Но соответствующие цифры будут относительно близкими.
Асимметричные или искаженные данные
Согласно микроэкономическим примечаниям.com, когда значения среднего, медианы и моды не равно, распределение асимметрично или искажено. Степень перекоса представляет степень, в которой набор данных отличается от нормального распределения.
Когда среднее значение больше, чем медиана, а медиана больше, чем мода (Среднее> Медиана> Режим), она — это распределение с положительным перекосом . Он описывается как «перекос право », потому что длинный конец кривой направлен вправо.
На приведенном ниже примере графика медиана и мода расположены слева от среднего.
С другой стороны, в отрицательном асимметричное распределение, среднее значение меньше медианы, а медиана меньше чем режим (Среднее <Среднее <Режим). Конец длиннохвостого расположен в сторону левая часть графика.
На приведенном ниже графике показаны медиана и мода, расположенные справа от среднего.
Отличие среднего от медианы: устойчивые числовые сводки
В наборе данных, когда среднее значение высокое, читатель может предположить медиана также будет высокой.Однако так происходит не всегда.
Разница между средним и медианным значением становится очевидной, когда набор данных имеет совершенно несопоставимое значение. Эта ситуация привлекает внимание концепция устойчивого числовые аннотации. Статистика устойчивости — это числовая сводка, в которой экстремальные цифры не оказывают существенного влияния на его стоимость.
Давайте покажем это, продемонстрировав, как присутствие Билла Гейтса влияет на среднее и среднее богатство, когда он входит в комнату.
Например, 10 человек обедают в ресторане.Назовем это набором A. В таблице ниже показаны их доходы в порядке убывания.
| название | Годовой доход |
|---|---|
| Раффи | 33 000 долл. США |
| Джесси | 38 000 долл. США |
| Корин | 39 000 долл. США |
| Павел | 42 000 долл. США |
| Кэт | 46 000 долл. США |
| Луиджи | 49 000 долл. США |
| Карл | 52 000 долл. США |
| Сьюзен | 60 000 долл. США |
| Мигель | 68 000 долл. США |
| Джон | 79 000 долл. США |
Общий доход людей в ресторане составляет 506000 долларов, со средним доходом 50 600 долларов.
Поскольку в наборе 10 человек, для получения медианы необходимо добавить 5 значений th и 6 th (Kat и Luigi’s годовой доход) и разделите его на 2.
Медиана = (46 000 + 49 000) / 2 = 95 000/2
= 47 500
Средний доход группы составляет 47 500 долларов.
Диапазон — это разница между наименьшим доходом (Раффи) и самый высокий доход (Джон), который составляет 46000 долларов.
Установить годовой доход
| Суммарный доход | 506 000 долл. США |
| Подлый | 506 000 долл. США |
| Медиана | 47 500 долл. США |
| Спектр | 46 000 долл. США |
Теперь, если Джон выйдет из ресторана и войдет Билл Гейтс, как это повлияет на статистику годового дохода группы? Давайте назовем эту следующую группу набор Б.
По данным Forbes, Билл Гейтс с 2017 по 2018 год составила 90 миллиардов долларов.
| название | Годовой доход |
|---|---|
| Раффи | 33 000 долл. США |
| Джесси | 38 000 долл. США |
| Корин | 39 000 долл. США |
| Павел | 42 000 долл. США |
| Кэт | 46 000 долл. США |
| Луиджи | 49 000 долл. США |
| Карл | 52 000 долл. США |
| Сьюзен | 60 000 долл. США |
| Мигель | 68 000 долл. США |
| Билл Гейтс | $ 90 000 000 000 |
Годовой доход группы Б
| Суммарный доход | 90 000 427 000 долларов США |
| Подлый | 9 000 042 700 долл. США |
| Медиана | 47 500 долл. США |
| Спектр | 89 999 967 000 долларов США |
С Биллом Гейтсом общий доход теперь составляет 90 миллиардов долларов плюс меньший доход людей в ресторане.Средний доход и диапазон группы сейчас слишком высоко.
Однако медиана остается на том же уровне около 47 500 долларов.
Среднее значение показывает, что это лучший показатель фактического финансовый статус. Точно так же мы можем сказать, что Билл Гейтс — исключение с ежегодным доход достигает миллиардов.
В этом примере показано, что
Расчет средневзвешенного (среднего из средних)
Распространенная проблема с отчетами в Excel — объединение наборов данных, например объединение ежемесячных чисел для получения итоговых данных за квартал или год.Добавление простых показателей очевидно, но что вы делаете с такими вещами, как средняя позиция или коэффициент конверсии? [ Совет: не следует усреднять или суммировать то, что уже является средним или соотношением ]
207 001 показ при средней позиции 35,7 + 735 462 показа при средней позиции 55,1 = 942 463 показа при средней позиции ???
CTR — CTR; Позиция средняя Позиция
Наша цель — вычислить среднее положение для каждого из 3 типов устройств за минимально возможное количество шагов.Сложность заключается в том, что 2 набора данных могут быть в разном порядке (настольный компьютер / мобильный телефон / планшет против мобильного устройства / настольного компьютера / планшета), и некоторые значения могут отсутствовать в каждом наборе данных (мобильный / настольный компьютер).
Приманка взвешенного среднего
Ставки и средние значения — это рассчитываемые показатели, и все они основаны на выборке или «совокупности» данных. В приведенном выше примере средняя позиция 35,7 (выделена желтым) основана на конкретной группе из 207 001 показа. Фактическая математика, лежащая в основе этой средней позиции, включает сложение всех индивидуальных значений позиций и деление на общее количество показов, что дает нам «среднее»:
средняя позиция = (сумма позиций) / (сумма показов)
При объединении подобных рассчитываемых показателей важен размер каждой группы — объединение небольшой выборки в большую выборку не должно сильно влиять на общее среднее значение (оно должно быть ближе к 55.1, чем 35,7 в примере выше). Мы хотим получить «взвешенное» среднее значение, в котором размер выборки учитывается при объединении чисел. Поиск типичной формулы для средневзвешенного значения дает что-то вроде этого: вы умножаете каждое среднее значение на весовой коэффициент, который рассчитывается из доли представленных ими показов, а затем складываете их:
средневзвешенное значение = средняя позиция1 * показы1 / (показы1 + показы2) + средняя позиция2 * показы2 / (показы1 + показы2)
Простое описание звучит сложно, и эту формулу сложно реализовать , особенно с большими наборами данных.Это потребует поиска совпадающих строк, затем вычисления доли или «веса», затем применения этого к среднему номеру позиции и, наконец, сложения их вместе. Это много поисков и вычислений, и это может быть очень медленным.
Упрощение проблемы и решение
В подобных ситуациях нам нужно переформулировать проблему таким образом, чтобы ее было легче (быстрее) решить. Возвращаясь к простой формуле для среднего, мы можем предположить, что если средняя позиция — это сумма позиций, деленная на количество показов, то средняя позиция для объединенных данных должна быть суммой всех позиций , деленное на количество всех показов :
средняя позиция = (сумма позиций1 + сумма позиций2) / (показы1 + показы2)
Это звучит намного проще, чем приведенная выше формула, и если вы хорошо разбираетесь в подстановках математических формул, вы действительно можете показать, что это приведет к точно так же, как .Разница в том, что здесь используется число, которого нет в наших данных: «сумма позиций». Но это достаточно легко вычислить; так как средняя позиция (сумма позиций) / показы, то мы знаем:
сумма позиций = средняя позиция * количество показов
Хотите верьте, хотите нет, но теперь у нас есть действительно простой способ объединить наше среднее значение с помощью нескольких простых шагов в электронной таблице:
- добавить один набор данных к другому
- добавить подсчет столбца (средняя позиция * количество показов) под названием «сумма позиций».
- объединить повторяющиеся строки, суммируя числа в совпадающих строках (Сортировка и промежуточный итог в Excel)
- рассчитать новую среднюю позицию = (сумма позиций) / (сумма показов)
Общий подход
Если вы примените то же мышление к рейтингу кликов (ctr) в стандартном отчете поиска Google, вы поймете, что у вас уже есть клики и показы (они являются метриками по умолчанию), которые необходимы для расчета ctr (ctr = кликов / показов).Все, что вам нужно сделать, это добавить данные, объединить повторяющиеся строки, а затем рассчитать новый столбец ctr на основе кликов / показов.
«Дополнительный» шаг для средней позиции в первом примере существует потому, что мы не начали с одной из «базовых» метрик за рассчитанной метрикой — (сумма позиций). Возвращаясь к пошаговому списку, мы можем сделать его более общим:
- добавить один набор данных к другому
- , если вам нужно объединить рассчитанные метрики (среднее, ставка, процент), сначала разбейте их на их базовые метрики *
- объединить повторяющиеся строки, суммируя числа в каждом столбце
- пересчитать рассчитанные показатели из (суммированных) базовых показателей
* Примечание. По возможности включите в запрос базовые метрики, чтобы избежать второго шага.например включите в запрос отказы и сеансы вместо показателя отказов.
НадстройкаAnalytics Edge для Excel: автоматизация без программирования
В то время как вы можете сделать все это вручную в Excel, эта пошаговая математика предназначена для надстройки Analytics Edge Core, и весь процесс можно автоматизировать за пару минут, как показано в этом видео. . Бесплатно 30 дней — скачайте сейчас!
Базовые показатели для общих ставок и средних
Ваша первая задача — выяснить, каковы базовые метрики для любой ставки или средней метрики, которую вы используете.Затем вы можете включить эти показатели в свой запрос или рассчитать их на основе имеющихся у вас данных. Вот некоторые из наиболее распространенных для Google Search и Google Analytics:
CTR = клики / показы
показатель отказов = отказы / сеансы
% новые сеансы = новые пользователи / сеансы
средняя продолжительность сеанса = продолжительность сеанса / сеансы
целевой коэффициент конверсии = достигнутые цели / сеансы
средняя стоимость заказа = доход / сеансы
коэффициент конверсии электронной торговли = транзакций / сеансов
Сводка
Если вам нужно объединить два или более наборов чисел, и они включают вычисляемые метрики, такие как средние, ставки или проценты, убедитесь, что вы правильно их объединяете.Не пугайтесь сложных формул для взвешенных средних — проблема и решение на самом деле довольно просты.
Начните с (или вычислите) базовых показателей, объедините (суммируйте) повторяющиеся строки и пересчитайте вычисленные показатели. Простые операции для точной отчетности.
что это такое и как рассчитать?
Коэффициенты рентабельности: что это такое?
Коэффициенты рентабельности измеряют способность компании генерировать прибыль относительно продаж, активов и капитала.Эти коэффициенты оценивают способность компании генерировать прибыль, прибыль и денежные потоки по отношению к некоторой метрике, часто к сумме вложенных денег. Они подчеркивают, насколько эффективно управляется прибыльность компании.
Общие примеры коэффициентов рентабельности включают рентабельность продаж, рентабельность инвестиций, рентабельность собственного капитала, рентабельность задействованного капитала (ROCE), рентабельность денежных средств на инвестированный капитал (CROCI), маржу валовой прибыли и маржу чистой прибыли. Все эти коэффициенты показывают, насколько хорошо компания генерирует прибыль или выручку по сравнению с определенным показателем.
Различные коэффициенты рентабельности позволяют получить различную полезную информацию о финансовом здоровье и результатах деятельности компании. Например, соотношение валовой прибыли и чистой прибыли показывает, насколько хорошо компания управляет своими расходами. Рентабельность вложенного капитала (ROCE) показывает, насколько хорошо компания использует вложенный капитал для получения прибыли. Рентабельность инвестиций показывает, приносит ли компания достаточно прибыли своим акционерам.
Для большинства этих соотношений желательно более высокое значение.Более высокое значение означает, что компания преуспевает и хорошо генерирует прибыль, выручку и денежные потоки. Показатели прибыльности в отдельности не имеют большого значения. Они предоставляют значимую информацию только тогда, когда их анализируют в сравнении с конкурентами или с коэффициентами в предыдущие периоды. Следовательно, анализ тенденций и отраслевой анализ необходимы для того, чтобы сделать значимые выводы о прибыльности компании.
При анализе коэффициентов прибыльности необходимы некоторые базовые знания о характере бизнеса компании.Например, продажи некоторых предприятий носят сезонный характер, и они подвержены сезонности в своей деятельности. Индустрия розничной торговли является примером такого бизнеса. Доходы розничной торговли обычно очень высоки в четвертом квартале из-за Рождества. Поэтому сравнивать показатели рентабельности в этом квартале с показателями рентабельности предыдущих кварталов нецелесообразно. Для осмысленных выводов следует сравнить показатели рентабельности этого квартала с показателями рентабельности аналогичных кварталов в предыдущие годы.
Возврат денежных средств на инвестированный капитал (CROCI)
Денежная отдача на вложенный капитал ( CROCI ) — это показатель, который сравнивает денежные средства, полученные компанией, с ее собственным капиталом. Это также иногда называют «денежным возвратом на вложенные деньги». Он сравнивает заработанные деньги с вложенными деньгами.
DuPont Formula
DuPont формула (также известная как анализ DuPont , модель DuPont, уравнение DuPont или метод DuPont ) — это метод оценки рентабельности капитала компании (ROE), разбивающий его на три части. части.
Прибыль до уплаты процентов после уплаты налогов (EBIAT)
Прибыль до уплаты процентов и после уплаты налогов используется для измерения способности фирмы получать доход посредством различных операций в течение определенного периода времени.
Коэффициент удержания прибыли
Коэффициент удержания заработка также называется коэффициентом вспашки. Согласно определению, коэффициент удержания прибыли или коэффициент обратной выплаты — это коэффициент, который измеряет сумму нераспределенной прибыли после выплаты дивидендов акционерам.
EBIT (прибыль до уплаты процентов и налогов)
EBIT (прибыль до уплаты процентов и налогов) — это показатель прибыльности предприятия, не включающий процентные расходы и расходы по налогу на прибыль.
EBITDA
EBITDA (прибыль до уплаты процентов, налогов, износа и амортизации) является показателем финансовых результатов компании. Он измеряет финансовые показатели компании, вычисляя прибыль от основных бизнес-операций, без учета влияния структуры капитала, налоговых ставок и политики амортизации.
EBITDARM
Сокращение от Прибыль до вычета процентов, налогов, износа, амортизации, аренды и комиссий за управление, EBITDARM относится к показателю финансовых результатов, который используется по сравнению с более распространенными показателями, такими как EBITDA, в ситуациях, когда арендная плата и плата за управление компании представляют больший, чем обычно, процент эксплуатационных расходов.
EBT (прибыль до налогообложения)
Прибыль до налогообложения (EBT) можно определить как деньги, удерживаемые компанией до вычета суммы, подлежащей уплате в качестве налогов.
Эффективная норма прибыли
Эффективная норма прибыли — это ставка процента по инвестициям ежегодно, когда начисление сложных процентов происходит более одного раза.
Маржа валовой прибыли
Валовая прибыль маржа (валовая прибыль) — это отношение валовой прибыли (валовая прибыль за вычетом себестоимости продаж) к выручке от продаж. Это процент, на который валовая прибыль превышает производственные затраты.Валовая прибыль показывает, сколько компания зарабатывает с учетом затрат, которые она несет на производство своей продукции или услуг.
Чистая процентная маржа
Чистая процентная маржа может быть выражена как показатель эффективности, который исследует успешность инвестиционных решений фирмы по сравнению с ее долговыми ситуациями. Отрицательная чистая процентная маржа указывает на то, что фирма не смогла принять оптимальное решение, поскольку процентные расходы были выше, чем сумма прибыли, полученной от инвестиций.Таким образом, при расчете чистой процентной маржи финансовая стабильность вызывает постоянную озабоченность.
Маржа чистой прибыли
Маржа чистой прибыли (или маржа прибыли , чистая маржа ) — это коэффициент прибыльности, рассчитанный как отношение чистой прибыли (чистой прибыли) после налогообложения к выручке (выручке). Маржа чистой прибыли отображается в процентах. Он показывает сумму каждого доллара продаж, оставшегося после оплаты всех расходов.
NOPLAT (Чистая операционная прибыль за вычетом скорректированных налогов)
NOPLAT равно Чистая операционная прибыль за вычетом скорректированных налогов .Это измерение прибыли, которая включает затраты и налоговые льготы по долговому финансированию. Другими словами, можно сказать, что NOPLAT — это прибыль до вычета процентов и налогов после внесения поправок на налоги. Это общая операционная прибыль фирмы с поправкой на налоги. Он показывает прибыль, полученную от основной деятельности компании после вычета налогов на прибыль, связанных с основной деятельностью компании. Для создания моделей DCF или моделей дисконтированных денежных потоков часто используется NOPLAT.
OIBDA
OIBDA ( операционная прибыль до вычета износа и амортизации ) — это не общепринятый принцип бухгалтерского учета, связанный с оценкой финансовых результатов, используемый организациями для отображения прибыльности в продолжающейся деятельности, связанной с бизнесом, без учета влияния налоговой структуры и заглавные буквы.
Коэффициент операционных расходов
Коэффициент операционных расходов можно объяснить как способ количественной оценки стоимости эксплуатации объекта недвижимости по сравнению с доходом, приносимым этой недвижимостью.
Операционная маржа
Операционная маржа ( маржа операционной прибыли , рентабельность продаж) — отношение операционной прибыли к чистым продажам (выручке).
Коэффициент накладных расходов
Коэффициент накладных расходов — это сравнение операционных расходов и общих доходов, не связанных с производством товаров и услуг. Операционные расходы компании — это расходы, которые компания несет ежедневно.Операционные расходы включают в себя обслуживание оборудования, расходы на рекламу, амортизацию оборудования, мебели и различные другие расходы. Эти расходы, когда они контролируются, могут обеспечить компанию, поддерживая качество бизнеса. Все компании хотят свести к минимуму накладные расходы, чтобы это помогло им понять и управлять доходами компании.
Анализ прибыли
В управленческой экономике Анализ прибыли — это форма учета затрат, используемая для элементарных инструкций и краткосрочных решений.Анализ прибыли расширяет использование информации, предоставляемой анализом безубыточности. Важная часть анализа прибыли — это точка, в которой общие доходы и общие расходы равны. В этой точке безубыточности компания не испытывает ни прибыли, ни убытков.
Относительная доходность
Относительная доходность относится к доходности актива за определенный период времени по сравнению с эталонным показателем. Относительная доходность рассчитывается как разница между абсолютной доходностью, достигнутой активом, и доходностью, достигнутой эталоном.
Рентабельность активов (ROA)
Рентабельность активов (ROA) — это финансовый коэффициент, который показывает процент прибыли, которую получает компания, по отношению к ее общим ресурсам (общим активам). Рентабельность активов является ключевым показателем рентабельности, который измеряет размер прибыли производится компанией на доллар ее активов. Он показывает способность компании получать прибыль до использования кредитного плеча.
Рентабельность активов (ROAA)
Рентабельность активов ( ROAA ) можно определить как показатель, используемый для оценки прибыльности активов фирмы.Проще говоря, эта доходность средних активов показывает, что компания может делать с тем, чем она владеет. Как правило, он используется компаниями, банками и другими финансовыми учреждениями в качестве оценки для определения их эффективности.
Рентабельность среднего задействованного капитала (ROACE)
Рентабельность среднего задействованного капитала ( ROACE ) — это коэффициент, который показывает прибыльность по сравнению с инвестициями, сделанными в компанию. ROACE отличается от рентабельности использованного капитала, поскольку он рассчитывает среднее значение капитала на начало и конец периода за конкретный период, в отличие от только показателя капитала на конец периода.
Рентабельность среднего капитала (ROAE)
Рентабельность капитала в среднем (ROAE) относится к результатам деятельности компании за финансовый год. Этот коэффициент представляет собой скорректированную версию доходности капитала, которая измеряет прибыльность компании. Таким образом, рентабельность среднего капитала включает в себя знаменатель, вычисляемый как сумму стоимости капитала на начало и конец года, деленную на два.
Рентабельность вложенного капитала (ROCE)
Рентабельность вложенного капитала (ROCE) — это мера прибыли, которую предприятие получает от вложенного капитала, обычно выражается в процентах.Используемый капитал равен капиталу компании плюс долгосрочные обязательства (или совокупные активы — текущие обязательства), другими словами, все долгосрочные средства, используемые компанией. ROCE указывает на эффективность и прибыльность капитальных вложений компании.
Доходность долга (ROD)
Рентабельность долга ( ROD ) может быть выражена как количественная оценка результатов деятельности или чистой прибыли компании, связанной с суммой долга, выпущенного компанией.Иными словами, доходность долга относится к сумме прибыли, полученной на каждый доллар, удерживаемый компанией в долгах.
Рентабельность капитала (ROE)
Рентабельность собственного капитала ( ROE ) — это сумма чистой прибыли, возвращенная как процент от собственного капитала. Он показывает, сколько прибыли получила компания по сравнению с общей суммой акционерного капитала, указанной в балансе.
Рентабельность инвестированного капитала (ROIC)
ROIC — это капитал, который представляет собой рентабельность инвестиций в бизнес. Это высокотехнологичный способ оценки рентабельности инвестиций на акции с поправкой на некоторые особенности рентабельности активов и рентабельности собственного капитала.
Рентабельность инвестиций (ROI)
Рентабельность инвестиций ( ROI ) — это показатель эффективности, используемый для оценки эффективности инвестиций. Он сравнивает величину и время получения прибыли от инвестиций непосредственно с величиной и сроками инвестиционных затрат. Это один из наиболее часто используемых подходов для оценки финансовых последствий бизнес-инвестиций, решений или действий.
Рентабельность чистых активов (RONA)
Рентабельность чистых активов (RONA) представляет собой сравнение чистой прибыли с чистыми активами.Это показатель финансовых показателей компании, который учитывает прибыль компании в отношении основных средств и чистого оборотного капитала.
Рентабельность исследовательского капитала (RORC)
Рентабельность капитала на исследования в размере (RORC) — это расчет, используемый для оценки дохода, полученного компанией как результат затрат на исследования и разработки. Возврат на исследовательский капитал является элементом производительности и роста, поскольку исследования и разработки являются одним из методов, используемых компаниями для разработки новых продуктов и услуг для продажи.Этот показатель обычно используется в отраслях, которые в значительной степени зависят от НИОКР, таких как фармацевтическая промышленность.
Рентабельность нераспределенной прибыли (RORE)
Рентабельность нераспределенной прибыли в размере (RORE) — это расчет, позволяющий выявить степень реинвестирования прибыли предыдущего года. Рентабельность нераспределенной прибыли выражается в процентном соотношении. Более высокая рентабельность нераспределенной прибыли указывает на то, что компании было бы лучше реинвестировать бизнес.Напротив, более низкая рентабельность нераспределенной прибыли указывает на то, что выплата дивидендов может оказаться в наилучших интересах компании.
Рентабельность выручки (ROR)
Рентабельность выручки ( ROR ) — это показатель прибыльности, который сравнивает чистую прибыль компании с ее выручкой. Это финансовый инструмент, используемый для измерения показателей прибыльности компании. Также называется маржа чистой прибыли .
Рентабельность продаж (ROS)
Рентабельность продаж (ROS) — это коэффициент, широко используемый для оценки операционных результатов компании.Он также известен как « маржа операционной прибыли » или « маржа операционной прибыли ». ROS показывает, какую прибыль получает предприятие после оплаты переменных производственных затрат, таких как заработная плата, сырье и т. Д. (Но до вычета процентов и налогов). Это доход от стандартных операций, который не включает уникальные или разовые транзакции. ROS обычно выражается в процентах от продаж (выручки).
Доход на сотрудника
Доход на сотрудника измеряет объем продаж, произведенных одним сотрудником.Это показатель эффективности человеческих ресурсов компании. Это показатель продуктивности персонала компании. Это также показывает, насколько эффективно компания использует свои человеческие ресурсы.
Доходность, скорректированная с учетом риска
Это концепция, которая измеряет стоимость риска, связанного с доходностью инвестиций. Это имеет большое значение, поскольку позволяет инвесторам сравнивать доходность инвестиций с высоким и высоким риском с менее рискованными и более низкими доходами от инвестиций. Доходность с поправкой на риск может применяться к инвестиционным фондам, портфелям и отдельным ценным бумагам.
Программа Python Расчет суммы и среднего первых n натуральных чисел
Как найти сумму и среднее значение первых n натуральных чисел в Python? В этой статье мы собираемся написать код Python для вычисления суммы и среднего положительных чисел, начиная с 1 и заканчивая заданным числом (n), используя цикл for.
Цели данной статьи :
- Вычислить сумму и среднее первых n натуральных чисел , используя функцию цикла и диапазона .
- Вычислите сумму и среднее первых n натуральных чисел, используя математическую формулу в программе.
- Вычислить сумму и среднее значение любых введенных пользователем чисел .
- Вычислить сумму и среднее значение для данного списка в Python
- Вычислить сумму с помощью встроенной функции суммы в Python
Теперь давайте посмотрим каждую по отдельности.
Алгоритм вычисления суммы и среднего первых n натуральных чисел
- Позволяет пользователю ввести число (n), которое он хочет вычислить для суммы и среднего значения.Программа принимает вводимые пользователем данные с помощью функции ввода.
- Затем выполните цикл до введенного числа, используя цикл for и функцию range ().
- Затем вычислите сумму по формуле
сумма = сумма + текущее число. - Наконец, после завершения цикла, вычислите среднее значение, используя
average = sum / n.n— номер, введенный пользователем.
Программа Python для вычисления суммы
п = 10
сумма = 0
для числа в диапазоне (0, n + 1, 1):
сумма = сумма + число
print («СУММА первых», n, «числа:», сумма) Выход :
Сумма первых 10 чисел: 55
Примечание. Приведенная выше программа выполняет цикл от 1 до числа, введенного пользователем, и добавляет все числа к сумме переменных .
Программа Python для вычисления среднего значения
print («вычислить среднее первых n натуральных чисел»)
п = 10
средний = 0
сумма = 0
для числа в диапазоне (0, n + 1,1):
сумма = сумма + число;
среднее = сумма / п
print («Среднее от первого», n, «натуральное число:», среднее) Выход :
вычислить среднее значение первых n натуральных чисел Среднее значение первых 10 натуральных чисел: 5,5
Вычислить сумму и среднее значение первых n натуральных чисел по формуле
.В приведенной выше программе мы вычислили сумму и среднее значение с помощью функции цикла и диапазона.Давайте посмотрим, как вычислить сумму и среднее значение напрямую с помощью математической формулы .
Сумма первых n натуральных чисел = n * (n + 1) / 2 , для n натуральное число.
среднее значение первого n натурального числа = (n * (n + 1) / 2) / n
Давайте теперь посмотрим на пример.
п = 10
сумма = п * (п + 1) / 2
среднее = (n * (n + 1) / 2) / n
print («Сумма первых», n, «натуральные числа с использованием формулы:», сумма)
print ("Среднее от первого", n, "натуральные числа по формуле:", среднее)
Выход :
Сумма первых 10 натуральных чисел по формуле: 55.0 Среднее значение первых 10 натуральных чисел по формуле: 5,5
Расчет суммы и среднего числа нескольких введенных пользователем чисел
Например, вы хотите вычислить сумму и среднее значение любых пяти чисел, введенных пользователем . то есть, если вы хотите вычислить сумму и среднее значение или процент от нескольких введенных пользователем чисел, обратитесь к следующей программе.
чисел = ввод («Введите числа, разделенные пробелом»)
numberList = числа.Трещина()
печать ("\ п")
print ("Все введенные числа", numberList)
# Вычисление суммы всех введенных пользователем чисел
сумма1 = 0
для числа в numberList:
sum1 + = int (число)
print ("Сумма всех введенных чисел =", сумма1)
# Вычисление среднего числа всех введенных пользователем чисел
среднее = сумма1 / лен (числоСписок)
print ("Среднее из всех введенных чисел =", среднее)
Выход :
Введите числа через пробел 5 10 15 20 25 Все введенные числа ['5', '10', '15', '20', '25'] Сумма всех введенных чисел = 75 Среднее значение всех введенных чисел = 15.0
Подробнее о том, как принять список в качестве ввода от пользователя.
Вычислить сумму и среднее значение данного списка в Python
Допустим, у вас есть список чисел, и вы хотите вычислить сумму чисел, присутствующих в списке.
- Все, что вам нужно сделать, это перебрать список с помощью цикла for и добавить каждое число к переменной суммы.
- Чтобы вычислить среднее, разделите сумму на длину данного списка (общее количество в списке)
Давайте посмотрим на это на примере.
Программа 1:
сумма = 0
список = [11,22,33,44,55,66,77]
для числа в списке:
сумма = сумма + число
среднее = сумма / лен (список)
print ("сумма элементов списка:", сумма)
print ("Среднее значение элемента списка", среднее) Выход :
сумма элементов списка: 308 Среднее значение элемента списка составляет 44,0
Вычислить сумму с помощью встроенной функции суммы в Python
Давайте посмотрим, как использовать функцию sum () для вычисления суммы.
print («Сумма диапазона чисел:», sum (range (1, 5))) Выход :
Сумма диапазона чисел: 10
Python цикл while для вычисления суммы и среднего
Вы также можете использовать цикл while для вычисления суммы и среднего n чисел. Здесь n может быть 2, 5 или любым числом. Выполните следующие шаги:
- Примите значение n = 20
- Выполнить цикл while, пока n не станет больше нуля
- Добавить текущее значение n к суммируемой переменной.Кроме того, уменьшите n на 1 в теле цикла .
- вычисляет среднее значение путем деления суммы на общее количество.
Давайте посмотрим на демонстрацию, чтобы вычислить сумму и среднее значение с помощью цикла while.
п = 20
total_numbers = n
сумма = 0
в то время как (n> = 0):
сумма + = п
n- = 1
print ("сумма с использованием цикла while", сумма)
среднее = сумма / всего_числа
print («Среднее с использованием цикла while», среднее) Выход :
Суммас использованием цикла 210 Среднее с использованием цикла while 10.5
Практическая задача: добавить две матрицы в Python
matrixOne = [[6,9,11],
[2, 3,8]]
matrixTwo = [[15,18,11],
[26,16,19]]
результат = [[0,0,0],
[0,0,0]]
# Первая итерация строк
для i в диапазоне (len (matrixOne)):
# Вторая итерация столбцов
для j в диапазоне (len (matrixOne [0])):
результат [i] [j] = matrixOne [i] [j] + matrixTwo [i] [j]
print («Сложение двух матриц в Python»)
для res в результате:
печать (разрешение) .
Об авторе