Как создать файл robots txt для сайта: Настройка правильного файла robots.txt — SEO на vc.ru
Как создать правильный файл robots.txt, настройка, директивы
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots. txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.
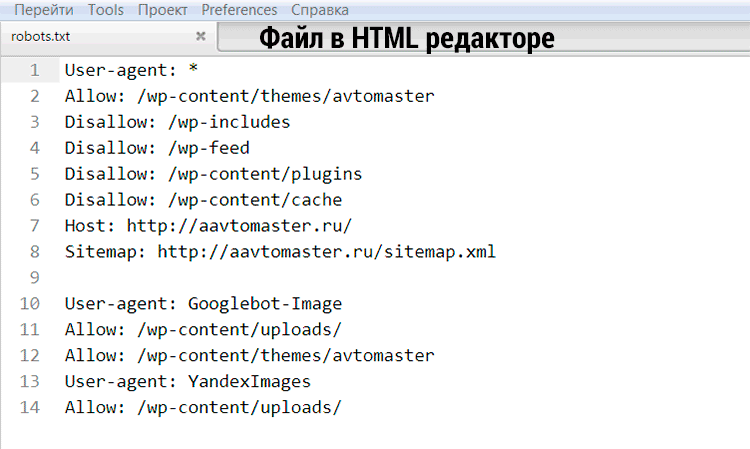 txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]; - Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.
 txt может трактоваться как полностью разрешающий;
txt может трактоваться как полностью разрешающий; - Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
«Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots. txt.
txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива
, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots. txt запретить индексацию сайта кроме некоторых страниц:
txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt
Как настроить robots.txt
Как создать robots. txt
Требования к файлу robots.txt
Как проверить правильность Robots.txt
txt
Требования к файлу robots.txt
Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Кому нужен robots.txtЕсли у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.д.
Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender. com/robots.txt.
com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *.js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG.![]() Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public.html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.
 txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
txt. Нельзя называть его Robots.txt или ROBOTS.TXT. - Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots.txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots. txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
5 шагов по созданию файла robots.
txt для вашего веб-сайтаОсновная задача веб-робота — обход или сканирование веб-сайтов и страниц в поисках информации; они неустанно работают над сбором данных для поисковых систем и других приложений. Для некоторых есть веская причина держать страницы подальше от поисковых систем. Независимо от того, хотите ли вы настроить доступ к своему сайту или хотите работать над сайтом разработки, не отображаясь в результатах Google, файл robots.txt после его внедрения позволяет веб-сканерам и ботам знать, какую информацию они могут собирать.
Что такое файл robots.txt?
robots.txt — это простой текстовый файл веб-сайта в корне вашего сайта, который соответствует стандарту исключения роботов. Например, www.yourdomain.com будет иметь файл robots.txt по адресу www.yourdomain.com/robots.txt. Файл состоит из одного или нескольких правил, которые разрешают или блокируют доступ сканерам, ограничивая их доступ к указанному пути к файлу на веб-сайте. По умолчанию все файлы полностью разрешены для сканирования, если не указано иное.
Файл robots.txt является одним из первых аспектов, проанализированных поисковыми роботами. Важно отметить, что на вашем сайте может быть только один файл robots.txt. Файл размещается на одной или нескольких страницах или на всем сайте, чтобы поисковые системы не отображали информацию о вашем сайте.
В этой статье описаны пять шагов для создания файла robots.txt и синтаксис, необходимый для защиты от ботов.
Как настроить файл Robots.txt
1. Создать файл Robots.txt
У вас должен быть доступ к корню вашего домена. Ваш провайдер веб-хостинга может помочь вам определить, есть ли у вас соответствующий доступ.
Наиболее важной частью файла является его создание и расположение. С помощью любого текстового редактора создайте файл robots.txt. Его можно найти по адресу: 9.0003
- Корень вашего домена: www.yourdomain.com/robots.txt.
- Ваши поддомены: page.yourdomain.com/robots.txt.
- Нестандартные порты: www.yourdomain. com:881/robots.txt.
Примечание:
Файлы robots.txt не помещаются в подкаталог вашего домена (www.yourdomain.com/page/robots.txt).
Наконец, вам нужно убедиться, что ваш файл robots.txt является текстовым файлом в кодировке UTF-8. Google и другие популярные поисковые системы и сканеры могут игнорировать символы вне диапазона UTF-8, что может сделать ваши правила robots.txt недействительными.
2. Установите свой агент пользователя robots.txt
Следующим шагом в создании файлов robots.txt является установка агента пользователя . Пользовательский агент относится к поисковым роботам или поисковым системам, которые вы хотите разрешить или заблокировать. Несколько объектов могут быть пользовательским агентом . Ниже мы перечислили несколько поисковых роботов, а также их ассоциации.
Существует три разных способа установить пользовательский агент в файле robots.txt.
Создание одного агента пользователя
Синтаксис, который вы используете для установки агента пользователя: Агент пользователя: NameOfBot . Ниже DuckDuckBot является единственным установленным пользовательским агентом .
# Пример установки user-agent Пользовательский агент: DuckDuckBot
Создание более одного пользовательского агента
Если нам нужно добавить более одного, выполните тот же процесс, что и для пользовательского агента DuckDuckBot , в следующей строке, введя имя дополнительные пользовательский агент . В этом примере мы использовали Facebot.
#Пример установки более одного пользовательского агента Агент пользователя: DuckDuckBot Агент пользователя: Facebot
Установка всех сканеров в качестве агента пользователя
Чтобы заблокировать всех ботов или сканеров, замените имя бота звездочкой (*).
#Пример того, как установить все поисковые роботы в качестве агента пользователя User-agent: *
Примечание:
Знак решетки (#) обозначает начало комментария.
3. Установите правила для файла robots.
txtФайл robots.txt читается группами. Группа будет указывать, кем является пользовательский агент , и иметь одно правило или директиву, чтобы указать, к каким файлам или каталогам пользовательский агент может или не может получить доступ.
Вот используемые директивы:
- Запретить : Директива, относящаяся к странице или каталогу, относящемуся к вашему корневому домену, который вы не хотите сканировать названным агентом пользователя . Он начинается с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько запретить настройки для каждого правила.
- Разрешить : Директива относится к странице или каталогу, относящемуся к вашему корневому домену, который вы хотите, чтобы названный пользовательский агент сканировал. Например, вы можете использовать директиву allow для переопределения правила disallow . Он также будет начинаться с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько разрешить настройки для каждого правила.
- Карта сайта : Директива карты сайта является необязательной и указывает местоположение карты сайта для веб-сайта. Единственным условием является то, что это должен быть полный URL-адрес. Вы можете использовать ноль или больше, в зависимости от того, что необходимо.
Поисковые роботы обрабатывают группы сверху вниз. Как упоминалось ранее, они получают доступ к любой странице или каталогу, для которых явно не установлено значение , запрещающее . Поэтому добавьте Disallow: / под user-agent информация в каждой группе, чтобы запретить этим конкретным пользовательским агентам сканировать ваш сайт.
# Пример как заблокировать DuckDuckBot Агент пользователя: DuckDuckBot Запретить: / #Пример того, как заблокировать более одного пользовательского агента Агент пользователя: DuckDuckBot Агент пользователя: Facebot Запретить: / #Пример того, как заблокировать все поисковые роботы Пользовательский агент: * Disallow: /
Чтобы заблокировать определенный поддомен от всех поисковых роботов, добавьте косую черту и полный URL-адрес поддомена в правило запрета.
# Пример Пользовательский агент: * Disallow: /https://page.yourdomain.com/robots.txt
Если вы хотите заблокировать каталог, выполните тот же процесс, добавив косую черту и имя вашего каталога, но затем закончите еще одной косой чертой.
# Пример Пользовательский агент: * Disallow: /images/
Наконец, если вы хотите, чтобы все поисковые системы собирали информацию на всех страницах вашего сайта, вы можете создать правило allow или disallow , но не забудьте добавить косую черту при использовании разрешить правило . Примеры обоих правил показаны ниже.
# Разрешить пример, чтобы разрешить все поисковые роботы Пользовательский агент: * Позволять: / # Пример запрета, чтобы разрешить все поисковые роботы Пользовательский агент: * Disallow:
4. Загрузите файл robots.txt
Веб-сайты не содержат файл robots.txt автоматически, поскольку он не требуется. Как только вы решите создать его, загрузите файл в корневой каталог вашего сайта. Загрузка зависит от файловой структуры вашего сайта и среды веб-хостинга. Обратитесь к своему хостинг-провайдеру, чтобы узнать, как загрузить файл robots.txt.
5. Проверьте правильность работы файла robots.txt
Существует несколько способов проверить правильность работы файла robots.txt. С любым из них вы можете увидеть любые ошибки в вашем синтаксисе или логике. Вот некоторые из них:
- Тестер Google robots.txt в их Search Console.
- Средство проверки и тестирования robots.txt от Merkle, Inc.
- Средство тестирования robots.txt компании Ryte.
Бонус: использование robots.txt в WordPress
Если вы используете WordPress плагин Yoast SEO, вы увидите раздел в окне администратора для создания файла robots.txt.
Войдите в серверную часть своего веб-сайта WordPress и откройте Инструменты в разделе SEO , а затем нажмите Редактор файлов .
Yoast Следуйте той же последовательности, что и раньше, чтобы установить пользовательские агенты и правила. Ниже мы заблокировали поисковые роботы из каталогов WordPress wp-admin и wp-includes, но по-прежнему разрешаем пользователям и ботам видеть другие страницы сайта. Когда закончите, нажмите Сохраните изменения в robots.txt , чтобы активировать файл robots.txt.
Отключить сканирование корзины
Поисковые системы, сканирующие ссылки добавления в корзину и нежелательные страницы, могут повредить вашему поисковому рейтингу. Ссылки «Добавить в корзину» могут вызывать более специфические проблемы, поскольку эти страницы не кэшируются, что увеличивает нагрузку на ЦП и память вашего сервера, поскольку страницы повторяются.
К счастью, адаптировать файл robot.txt вашего сайта несложно, чтобы поисковые системы сканировали только те страницы, которые вам нужны. Используйте эти строки кода в файле robots.txt сайта, чтобы адресовать ссылки для добавления в корзину и указать поисковым системам не индексировать их.
Агент пользователя: * Disallow: /*add-to-cart=*
Также рекомендуется изменить файл robots. txt, чтобы запретить индексирование страниц корзины, оформления заказа и моей учетной записи, что можно сделать, добавив строки ниже.
Запретить: /корзина/ Запретить: /checkout/ Disallow: /my-account/
Заключение
Мы рассмотрели, как создать файл robots.txt. Эти шаги просты в выполнении и могут сэкономить ваше время и нервы, связанные с сканированием содержимого вашего сайта без вашего разрешения. Создайте файл robots.txt, чтобы заблокировать ненужное сканирование поисковыми системами и ботами.
Если вы размещаете с помощью Liquid Web и у вас есть вопросы по созданию файла robots.txt для вашего веб-сайта, обратитесь за помощью в нашу службу поддержки.
Страницы веб-роботов
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для предоставления инструкций по свой сайт веб-роботам; это называется Исключение роботов Протокол .
Это работает следующим образом: робот хочет просмотреть URL-адрес веб-сайта, скажем,
http://www. example.com/welcome.html. Прежде чем это сделать, он сначала
проверяет наличие http://www.example.com/robots.txt и находит:
Агент пользователя: * Запретить: /
«User-agent: *» означает, что этот раздел относится ко всем роботам. «Запретить: /» сообщает роботу, что он не должен посещать страницы на сайте.
При использовании файла /robots.txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш файл /robots.txt. Особенно вредоносные роботы, которые сканируют web на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами не обратит внимания.
- файл /robots.txt является общедоступным. Любой может видеть, какие разделы вашего сервера, который вы не хотите использовать роботами.
Так что не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
- Могу ли я заблокировать только плохих роботов?
- Почему этот робот проигнорировал мой /robots. txt?
- Каковы последствия файла /robots.txt для безопасности?
Детали
/robots.txt является стандартом де-факто и никому не принадлежит. орган стандартов. Есть два исторических описания:
- оригинал 1994 г. Стандарт для роботов Документ об исключении.
- Спецификация Internet Draft 1997 г. Метод для Интернета Управление роботами
Кроме того, есть внешние ресурсы:
- HTML 4.01 Спецификация, Приложение B.4.1
- Википедия — Стандарт исключения роботов
Стандарт /robots.txt активно не разрабатывается. См. Что насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать /robots.txt на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, см. также FAQ.
Как создать файл /robots.txt
Куда его поместить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет файл «/robots.txt» для URL, он удаляет компонент пути из URL (все, начиная с первой косой черты), и помещает «/robots.txt» на свое место.
Например, для «http://www.example.com/shop/index.html будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге получится «http://www.example.com/robots.txt».
Итак, как владелец веб-сайта, вы должны поместить его в нужное место на своем веб-сайте. веб-сервер, чтобы этот результирующий URL-адрес работал. Обычно это одно и то же место, где вы размещаете приветствие «index.html» вашего веб-сайта страница. Где именно это находится и как туда поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: «robots.txt», а не «Robots.TXT.
Смотрите также:
- Какую программу следует использовать для создания файла /robots.txt?
- Как использовать /robots.txt на виртуальном хосте?
- Как использовать файл /robots. txt на общем хосте?
Что положить
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись, имеющую вид:
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /~joe/
В этом примере исключены три каталога.
Обратите внимание, что вам нужна отдельная строка «Запретить» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: /cgi-bin/ /tmp/» на одна линия. Кроме того, в записи может не быть пустых строк, так как они используются для разделения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается либо в User-agent, либо в Disallow линии. ‘*’ в поле User-agent — это специальное значение, означающее «любой робот». В частности, у вас не может быть таких строк, как «User-agent: *bot*», «Запретить: /tmp/*» или «Запретить: *.gif».
То, что вы хотите исключить, зависит от вашего сервера. Все, что прямо не запрещено, считается справедливым
игра, чтобы получить. Вот несколько примеров:
Исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Чтобы разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или вообще не используйте его)
Исключить всех роботов из части сервера
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /мусор/
Для исключения одного робота
Агент пользователя: BadBot Запретить: /
Для одного робота
Агент пользователя: Google Запретить: Пользовательский агент: * Запретить: /
Исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». простой способ — поместить все файлы, которые нужно запретить, в отдельный директории, произнесите «stuff» и оставьте один файл на уровне выше этот каталог:
Пользовательский агент: * Запретить: /~joe/stuff/
В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.

Об авторе