Как взять выписку из егрюл: Получить выписку из ЕГРЮЛ/ЕГРИП удобнее в электронном виде | ФНС России
Как получить выписку из ЕГРЮЛ: подробный гайд
Стать клиентом
Имя: *
Фамилия: *
Отчество:
Телефон *
E-mail*
Я даю согласие на обработку персональных данныхСпасибо за ваше обращение!
Написать нам
Имя: *
Фамилия: *
Отчество:
Телефон *
E-mail*
Я даю согласие на обработку персональных данныхПроверка чекбоксов
Имя: *
Фамилия: *
Отчество:
E-mail*
Линия консультации
Готовый договор
Банк привилегий
Я даю согласие на обработку персональных данныхРоман Сериков
преподаватель-юрист «ЧТО ДЕЛАТЬ КОНСАЛТ»
Корпоративные процедуры | Бухгалтеру | Юристу | Руководителю | Pro K+
Выписка из ЕГРЮЛ – это как паспорт юридического лица. В ней указывают наименование, ИНН, ОГРН, юридический адрес и другую ценную информацию. В статье рассказали, как получить выписку в бумажном и электронном виде и какой вариант выбрать.
В ней указывают наименование, ИНН, ОГРН, юридический адрес и другую ценную информацию. В статье рассказали, как получить выписку в бумажном и электронном виде и какой вариант выбрать.
Сложная правовая ситуация? Получите пошаговый алгоритм действий
подробнее
Какую выписку получать – бумажную или электронную
Выписку предоставляют в двух вариантах – бумажном или электронном. Решите, какой вариант нужен вам. От этого зависит и порядок получения выписки.
Электронная выписка
Электронная выписка подходит для проверки контрагентов, представления в госорганы, суд. На распечатанной электронной выписке электронная подпись будет видна, поэтому в большинстве случаев хватает выписки в таком виде (п. 3 Постановления Пленума ВАС РФ от 17.02.2011 № 12, Письмо ФНС России от 03.12.2015 № ГД-3-14/4585@).
Бумажная выписка
Выписка в бумажном виде платная, и выдают ее не сразу. Для подачи запроса обратитесь в налоговую или МФЦ. Недостатки в виде траты времени и денег компенсируются наличием подписи должностного лица и печатью налоговой.
Недостатки в виде траты времени и денег компенсируются наличием подписи должностного лица и печатью налоговой.
Как получить выписку из ЕГРЮЛ в электронном виде
Выписку в электронном виде предоставят максимально быстро и бесплатно через единый портал госуслуг или сайт ФНС России. Выписку, подписанную усиленной квалифицированной электронной подписью, предоставят в виде PDF-файла. Она равнозначна бумажной выписке (ч. 1 ст. 6 ФЗ от 06.04.2011 № 63-ФЗ, Письмо ФНС России от 03.12.2015 № ГД-3-14/4585@, п. 1 ст. 7 ФЗ от 08.08.2001 № 129-ФЗ, п. 4 Приложения к Приказу Минфина России от 05.08.2019 № 121н).
Как получить выписку из ЕГРЮЛ в бумажном виде
Составьте запрос в налоговую в произвольной форме. Составить запрос без ошибок поможет подробный материал КонсультантПлюс:
Готовое решение: Как составить запрос на получение выписки из ЕГРЮЛ
Образец запроса
Скачать образец запроса на выписку из ЕГРЮЛ
Составленный запрос вы можете подать лично или по почте. В первом варианте запрос подавайте в налоговую, которая выдает сведения из ЕГРЮЛ. Адрес можете узнать на сайте ФНС России в разделе «Контакты инспекций и УФНС России по вашему региону». Регион выбирайте в верхнем углу сайта.
В первом варианте запрос подавайте в налоговую, которая выдает сведения из ЕГРЮЛ. Адрес можете узнать на сайте ФНС России в разделе «Контакты инспекций и УФНС России по вашему региону». Регион выбирайте в верхнем углу сайта.
Другой вариант – подать запрос через МФЦ.
При личной подаче просят предъявить паспорт и доверенность, если запрос составлен от имени организации. Обратите внимание, запрос могут вернуть.
Выписку выдадут в течение 5 дней со дня получения запроса. Количество экземпляров и способ передачи выписки будут зависеть от вашего запроса. Если запрос подали через МФЦ, выписку вам выдадут также в МФЦ (подп. 3 п. 16, п. 71 Регламента по предоставлению сведений из ЕГРЮЛ и ЕГРИП).
В КонсультантПлюс найдете образец любого рабочего документа
подробнее
Сколько действует выписка
Срок действия выписки не установлен, но госорганы могут устанавливать определенные требования к предоставляемым выпискам. Например, арбитражный суд требует прикладывать к исковому заявлению выписку, полученную не позднее чем через 30 дней до момента обращения в суд.
Например, арбитражный суд требует прикладывать к исковому заявлению выписку, полученную не позднее чем через 30 дней до момента обращения в суд.
Вместо выписки вам могут выдать справку об отсутствии в ЕГРЮЛ запрашиваемой информации. Это произойдет, если сведения об организации в ЕГРЮЛ отсутствуют или в запросе не были указаны необходимые сведения, поэтому невозможно установить, в отношении какой организации выписка была запрошена (п. 75 указанного Регламента, п. 2 Приложения к Приказу Минфина России от 05.08.2019 № 121).
За что директора привлекут к субсидиарной ответственности
Как уничтожить документы в организации правильно
Как провести годовое собрание участников ООО
Свидетельство о регистрации СМИ: Эл № ФС77-67462 от 18 октября 2016 г. Контакты редакции: +7 (495) 784-73-75, [email protected]
По этой теме
Pro K+ Как заполнить ЕФС при ГПХ (примеры) Pro K+ Как закрыть ИП в 2023 году: пошаговая инструкция, формы документов Pro K+ Приказ о повышении оклада в связи с повышением МРОТ в 2023 году: образец заполнения
Консультант Плюс
Бесплатный доступ на 3 дня
Получить бесплатный доступ
на 3 дня
Спасибо за ваше обращение!
ВЭД (бухучет и налоги)
Иное (интеллектуальное право, земельное право, семейное право, регистрация недвижимости)
Представительство в суде
Налогообложение и отчетность (УСН, спецрежимы)
Бюджетный учет (КОСГУ) и учетная политика (РСБУ)
Зарплата, НДФЛ, страховые взносы
Налоговые проверки и судебные споры с ФНС
Бюджетная и налоговая отчетность
Договорная работа
Иностранные работники
Охрана труда (медосмотры, СОУТ и тд)
ККТ
Оформление приема, увольнения и перевода сотрудников (кадровый документооборот)
Договорная работа (договора поставки, аренды, комиссии, подряда, цессии, новации, займа, НИОКР, коммерческого кредита, лизинга)
Начисление и уплата налогов, отчетность (ОСН)
Учредительные документы. Корпоративные процедуры.
Корпоративные процедуры.
Подготовка документации, планирование закупок, заключение договора по 223-ФЗ
Бухучет. Учетная политика
Корпоративные процедуры
Бюджетная смета казенного учреждения или план ФХД бюджетного (автономного) учреждения
НДФЛ, страховые взносы, зарплата
Взаимодействие с надзорными, контрольными органами, органами государственной и муниципальной власти
Претензионно-исковая работа
Разработка локальных нормативных актов и должностных инструкций
Совместители внутренние и внешние, договора ГПХ
Трудовые споры
Взаимодействие с надзорными, контрольными органами, органами государственной и муниципальной власти (проверки, ответственность)
Подготовка документации, планирование закупок, заключение госконтрактов по 44-ФЗ
Права на объект интеллектуальной собственности, передача исключительных и не исключительных прав по лицензионному договору
14.11.2022 — 24.11.2022
Курс повышения квалификации
Практический курс. Бухгалтерская отчетность бюджетных и автономных учреждений.
Порядок составления, правила проверки, устранение рисков допущения ошибок
Бухгалтерская отчетность бюджетных и автономных учреждений.
Порядок составления, правила проверки, устранение рисков допущения ошибок
15.11.2022 — 16.11.2022
Вебинар
ОНЛАЙН. Новые ФСБУ и их влияние на показатели отчетности — готовимся к формированию бухгалтерской отчетности за 2022 год
Email:
Поздравляем! Вы успешно подписались на рассылку
Нет
Получите полный доступ к КонсультантПлюс бесплатно!
Попробовать
Да
Вы переходите в систему КонсультантПлюс
Перейти
Как получить выписку из ЕГРЮЛ через Госуслуги?
Через Госуслуги выписка из ЕГРЮЛ в настоящее время получена быть не может. Это связано с тем, что на сайте ФНС России действуют целых два сервиса по предоставлению данной услуги, и создавать третий — не целесообразно. Тем не менее, на портале Госуслуг имеется страница, содержащая сведения о порядке получения выписки из реестра юридических лиц. О том, как получить выписку в электронном виде, с учетом невозможности сделать это на Госуслугах, расскажем в статье.
Это связано с тем, что на сайте ФНС России действуют целых два сервиса по предоставлению данной услуги, и создавать третий — не целесообразно. Тем не менее, на портале Госуслуг имеется страница, содержащая сведения о порядке получения выписки из реестра юридических лиц. О том, как получить выписку в электронном виде, с учетом невозможности сделать это на Госуслугах, расскажем в статье.
СОДЕРЖАНИЕ СТАТЬИ:
- 1 Как заказать выписку из ЕГРЮЛ через Госуслуги, с учетом того, что электронный сервис не доступен?
- 2 Альтернативный способ получения выписки из ЕГРЮЛ в электронном виде через сервис ФНС
Как заказать выписку из ЕГРЮЛ через Госуслуги, с учетом того, что электронный сервис не доступен?
Сайт Госуслуг позволяет получить многие государственные услуги в упрощенном режиме, путем использования содержащихся на нем электронных сервисов. Имеется на сайте и страница (//www.gosuslugi.ru/14397/1/info), на которой содержится информация о порядке получения выписки из ЕГРЮЛ. Выглядит она следующим образом:
Выглядит она следующим образом:
Однако выписка из ЕГРЮЛ через Госуслуги, исходя из информации на указанной странице, получена быть не может. Дается отсылка с указанием, что услуга предоставляется Федеральной налоговой службой.
Кроме того, на приведенной странице описывается порядок получения выписки в бумажном варианте. Для этого приводится возможность подать заявку в ФНС или МФЦ — как лично, путем явки в подразделение ФНС или МФЦ, так и по почте.
Возникает вопрос о том, как получить выписку из ЕГРЮЛ через Госуслуги, если сервис отсутствует? Ответ на него прост — необходимо обратиться на сайт ФНС России, на котором процедура получения документа реализована на высоком уровне. О том, как это сделать, расскажем ниже.
Альтернативный способ получения выписки из ЕГРЮЛ в электронном виде через сервис ФНС
На сайте ФНС представлено целых два сервиса, позволяющих получить выписку из реестра юридических лиц. Первый дает возможность мгновенно скачать не заверенный документ, содержащий сведения о любой организации. Второй позволяет скачать выписку, заверенную электронной цифровой подписью налоговой службы. Такая подпись приравнивает документ по юридической силе к бумажному, с живой подписью и печатью.
Второй позволяет скачать выписку, заверенную электронной цифровой подписью налоговой службы. Такая подпись приравнивает документ по юридической силе к бумажному, с живой подписью и печатью.
Получение не заверенной выписки осуществляется следующим образом:
- Необходимо перейти на сайт //egrul.nalog.ru/.
- Ввести данные об организации. Предусмотрено два способа. Первый позволяет найти организацию по ОГРН и ИНН, а второй по наименованию фирмы и региону ее места нахождения.
- Ввести код с картинки в специальное поле (антиспам).
После этого пользователь попадает на экран, где может скачать выписку в формате PDF, кликнув по ссылке.
Получение заверенной выписки осуществляется следующим образом:
- Необходимо перейти на сайт //service.nalog.ru/vyp/.
- Зарегистрироваться на сайте (кнопка “Регистрация” в правой части экрана).
- Получить выписку в формате PDF, заверенную усиленной цифровой подписью ФНС.
Заверенная электронная выписка предоставляется не мгновенно.
На практике срок формирования ссылки на документ составляет от нескольких минут до 1 часа. Предельный срок получения, установленный на нормативном уровне – 1 день.

***
Таким образом, сервис получения выписки на сайте Госуслуг отсутствует, однако на сайте ФНС можно получить документ в электронном виде двумя способами.
Извлечение данных из журналов | New Relic
Опыт научил меня, что регулярные выражения — это швейцарский армейский нож в наборе инструментов разработчика, и почти всегда есть — — лучшее регулярное выражение для текущей работы. Разработка хорошего регулярного выражения имеет тенденцию быть итеративной, а качество и надежность повышаются по мере того, как вы вводите в него новые интересные данные, включая пограничные случаи.
Часто работающее регулярное выражение достаточно хорошо . Если ваши данные очень предсказуемы, то оптимизация регулярного выражения может оказаться ненужной задачей. Однако как только вы начнете использовать регулярное выражение как часть более широкой системы, в масштабе или в ненадежных наборах данных, тем больше вы должны убедиться, что оно надежное, отказоустойчивое и производительное.
Поначалу регулярное выражение может показаться сложным, но система становится логичной и предсказуемой, как только вы ее поймете. Однако обратное проектирование сложного регулярного выражения не очень весело.
В этом сообщении блога вы узнаете, как составить регулярное выражение для важного варианта использования: извлечения пар имя-значение из строки журнала, что часто является важной частью управления вашими журналами. Журналы — хороший пример того, когда вам нужны сильные регулярные выражения, потому что обычно журналы являются частью более широкой системы (в идеале у вас есть журналы для всего стека), их необходимо масштабировать вместе с вашим приложением, и они часто несовместимы. Итак, давайте взглянем на некоторые регулярные выражения — по пути вы, надеюсь, научитесь укреплять другие регулярные выражения, с которыми вы работаете.
Анализ строк журнала с помощью регулярного выражения
Этот вариант использования основан на реальных требованиях, которые изначально использовались для помощи клиенту в анализе своих журналов в New Relic. New Relic имеет мощный механизм анализа данных, который позволяет вам получать необработанные данные журнала и разбивать их на отдельные семантически значимые столбцы.
New Relic имеет мощный механизм анализа данных, который позволяет вам получать необработанные данные журнала и разбивать их на отдельные семантически значимые столбцы.
Вот требования для реального варианта использования:
- Данные журнала содержат несколько пар имя-значение, а также другие данные.
- Пары отображаются в формате:
(атрибут=значение). - Значения могут содержать пробелы.
- Нет необходимости собирать все пары «имя-значение».
- Некоторые пары могут присутствовать во всех строках журнала, а некоторые нет.
- Пары могут появляться в любом порядке.
Вот пример строки журнала:
моя любимая пицца = ветчина и ананас напиток = лайм и лимонад место проведения = Лондон имя = Джеймс Бьюкенен
Для этого примера данных предположим, что вы хотите извлечь из данных поля пицца , напиток и имя . Однако вы не хотите извлекать данные
Однако вы не хотите извлекать данные места проведения или любые другие данные в строке журнала. Чтобы усложнить ситуацию, что, если вы хотите собрать эти данные из многих строк журнала, а данные не всегда представлены последовательно? Какое регулярное выражение будет отображать эти значения для вас?
TL;DR, вот регулярное выражение 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
Для этих правил:
- Не все пары ключ-значение должны присутствовать. Правило по-прежнему работает с парами ключ-значение, которые присутствуют, но не нарушается, если некоторые из пар ключ-значение отсутствуют в строке.
- Порядок пар ключ-значение не имеет значения.
- В значении допускается пробел.
Чтобы узнать больше о том, как работает правило, читайте дальше.
Разбор с помощью Grok
В этом обсуждении основное внимание будет уделено версии правила Grok, поскольку она немного чище. Также правила синтаксического анализа в New Relic написаны на Grok, что позволяет использовать существующие именованные шаблоны Grok. Поскольку Grok основан на регулярных выражениях, любое допустимое регулярное выражение также является допустимым выражением Grok. Если вы не используете Grok, просто используйте стандартную версию регулярного выражения, представленную в предыдущем разделе.
Также правила синтаксического анализа в New Relic написаны на Grok, что позволяет использовать существующие именованные шаблоны Grok. Поскольку Grok основан на регулярных выражениях, любое допустимое регулярное выражение также является допустимым выражением Grok. Если вы не используете Grok, просто используйте стандартную версию регулярного выражения, представленную в предыдущем разделе.
Запуск с ненадежным правилом синтаксического анализа
Давайте начнем с некоторых данных для проверки регулярного выражения. Я люблю и пиво, и пиццу, и у меня даже есть собственная дровяная печь, так что вот набор данных на тему пиццы:
1: моя любимая пицца = ветчина и ананасовый напиток = лайм и лимонад имя = Джеймс Бьюкенен
2: мой любимый напиток = лайм и лимонад имя = пицца Джеймса Бьюкенена = ветчина и ананас
3: мое любимое имя = пицца Джеймса Бьюкенена = напиток с ветчиной и ананасом = лайм и лимонад
4: моя любимая пицца=ветчина и ананасовый напиток=лайм и лимонад
5: мое любимое имя=Джеймс Бьюкенен пицца=ветчина и ананас фу=барный напиток=лайм и лимонад
6: мой любимый напиток =лайм и лимонад
Вы увидите, что этот набор данных имеет пары ключ-значение в разном порядке, разное количество пробелов и даже разное количество пар ключ-значение.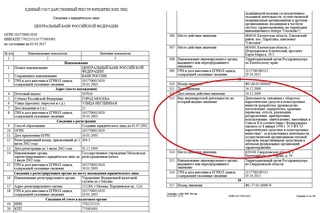
В этом примере данные пары ключ-значение в каждой строке разделены равными = знаки, такие как напиток=кола . Допустим, вы хотите извлечь три значения: pizza , drink и name .
Если данные всегда отображаются в виде первой строки, вы можете написать правило анализа Grok, подобное этому, которое извлекает каждое из значений:
pizza=(?
Это работает, но правило хрупкое. Он требует, чтобы значения всегда были в одном и том же порядке. Если какие-либо значения отсутствуют или есть какие-либо дополнительные данные, все правило не работает. Это плохо. Вы же не хотите, чтобы данные пропали, потому что они не совсем совпадают. И даже если вы уверены, что ваши данные непротиворечивы, можете ли вы быть уверены на 100%?
Если вы хотите попробовать это самостоятельно с помощью встроенного инструмента тестирования синтаксического анализа журналов в New Relic, перейдите к Журналы > Анализ > Создать правило синтаксического анализа . Вы можете вставить пример строки журнала вместе с правилом, чтобы увидеть результат. Кроме того, вы можете попробовать правило Grok, используя этот инструмент Grok.
Вы можете вставить пример строки журнала вместе с правилом, чтобы увидеть результат. Кроме того, вы можете попробовать правило Grok, используя этот инструмент Grok.
Использование правила просмотра вперед
Так как же сделать это правило разбора более надежным? Здесь на помощь приходит использование предпросмотра. Чтобы настроить таргетинг на одну пару ключ-значение, вам нужно знать две вещи: когда начинать сопоставление и когда его заканчивать. Давайте проработаем это шаг за шагом.
Найдите пару значений Возьмем эту пару значений пиццы в качестве примера. Он всегда начинается так: пиццы = . Поскольку шаблон непротиворечив, вы можете заглянуть вперед и записать текст следующим образом:
(?=%{DATA}pizza=(?
Это вернет следующее:
пицца: напиток с ветчиной и ананасом=лайм и лимонад name=james buchanan
ДАННЫЕ эквивалентно выражению . . Вы можете найти полезный список паттернов Grok здесь. Это правило упреждающего поиска находит все после строки  *?
*? pizza= и записывает это в поле с именем pizza . Пока это работает, значения напитка и имени также фиксируются. Таким образом, правило должно быть ограничено захватом символов и пробелов только до следующей пары имя-значение.
Чтобы захватить только значение pizza , вы можете использовать другой просмотр вперед. Следующее правило захватывает любой символ, который не является знаком равенства. Это должно быть не жадным, то есть 9=]+?(?=(?:\s+%{WORD}=))))
Это возвращает следующее для #1: pizza:ветчина и ананас ✅
Однако оно возвращает следующее против # 2: нет совпадений! ❌
Гораздо лучше… но подождите! Вторая линия не соответствует пицце. Вы видите, почему?
Шаблон соответствует данным, за которыми следует другая пара «имя-значение» , , но в этом случае правило просматривает всю строку и дополнительных пар «имя-значение» нет. Захват должен быть расширен до 9=]+?(?=(?:\s+%{WORD}=|%{SPACE}?$))))
Захват должен быть расширен до 9=]+?(?=(?:\s+%{WORD}=|%{SPACE}?$))))
Возврат против #1: pizza:ветчина и ананас ✅
Возврат против #2 : пицца:ветчина и ананас ✅
Это намного лучше и надежнее. Если вы просто хотите захватить одно поле, все готово. Однако при работе с журналами вам часто нужно записывать несколько полей.
Захват нескольких полей в журналахВы можете связать несколько выражений вместе, чтобы захватить другие значения, повторяя одно и то же выражение и изменяя имена значений по мере необходимости: 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))
Это возвращает следующее:
Строка #1: pizza:ветчина и ананас, имя :james buchanan and drink:лайм и лимонад ✅
Строка №2: такая же, как №1 ✅
Строка №3: такая же, как №1 ✅
Строка №4: нет совпадений! ❌
Это работает для строк с первой по третью выборки данных. Теперь правило возвращает совпадения независимо от порядка пар ключ-значение. К сожалению, это не удается для четвертой строки ввода:
К сожалению, это не удается для четвертой строки ввода:
4: моя любимая пицца=ветчина и ананасовый напиток=лайм и лимонад
Вы могли заметить, что в четвертой строке отсутствует ключ имя . Правило регулярного выражения требует присутствия имени , иначе весь шаблон не работает. Это распространенная ошибка, которая часто остается незамеченной при использовании регулярных выражений с наборами данных. Как вы можете себе представить, справиться с такого рода проблемами может быть очень сложно, потому что кажется, что правило работает правильно, но не собирает важную информацию. Вы можете исправить это, сделав каждый шаблон необязательным 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
Это возвращает:
Строка № 1: пицца: ветчина и ананас, имя: Джеймс Бьюкенен и напиток: лайм и лимонад № 1 ✅
Строка № 4: пицца: ветчина и ананас, напиток: лайм и лимонад ✅
Строка № 5: то же, что и № 1 ✅
Строка № 6: напиток: лайм и лимонад ✅
Правило правильно сопоставляет все тестовые входные данные в любом порядке и продолжает работать для отсутствующих полей. 9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
9=]+?(?=(?:\s+%{WORD}=|%{ПРОБЕЛ}?$))))?
Это небольшое изменение гарантирует, что просмотр вперед происходит только в начале строки или при наличии пробела, а не с каждым символом. Это не позволяет правилу использовать просмотры вперед там, где они не нужны.
Заключение
Надеюсь, вы лучше понимаете, как работает это правило, и понимаете, как можно итеративно улучшить правило, чтобы сделать его более надежным. Всегда найдется лучшее регулярное выражение, если хорошенько подумать. Удачи в поиске еще более эффективного варианта использования!
Извлечение подстроки из строки в Python (позиция, регулярное выражение)
В этой статье объясняется, как извлечь подстроку из строки в Python. Вы можете извлечь подстроку, указав позицию и количество символов или используя шаблоны регулярных выражений.
- Извлечь подстроку, указав позицию и количество символов
- Извлечь символ по индексу
- Извлечение подстроки путем нарезки
- Извлечение на основе количества символов
- Извлечь подстроку с помощью регулярных выражений:
re., search()
search() re.findall() - Примеры шаблонов регулярных выражений
- Шаблоны, подобные подстановочным знакам
- Жадные и нежадные
- Извлечь часть шаблона со скобками
- Соответствует любому одиночному символу
- Совпадение с началом/концом строки
- Извлечение по нескольким шаблонам
- Без учета регистра
Если вы хотите выполнить поиск строки, чтобы получить позицию заданной подстроки, или заменить подстроку в строке другой строкой, см. следующие статьи.
- Поиск строки в Python (проверка наличия подстроки и получение ее позиции)
- Заменить строки в Python (replace, translate, re.sub, re.subn)
Вы можете получить символ в нужной позиции, указав индекс в [] . Индексы начинаются с 0 (индексация с нуля).
с = 'abcde' печать (с [0]) # а печать (ы [4]) # е
источник: str_index_slice.py
Можно указать обратную позицию с отрицательными значениями.
-1 представляет последний символ.
печать(с[-1]) # е печать (с [-5]) # а
источник: str_index_slice.py
Возникает ошибка, если указан несуществующий индекс.
# print(s[5]) # IndexError: индекс строки вне допустимого диапазона # печать(с[-6]) # IndexError: индекс строки вне допустимого диапазона
источник: str_index_slice.py
Вы можете извлечь подстроку в диапазоне start <= x < stop с помощью [start:stop] . Если начать опущен, диапазон начинается с начала строки, а если стоп опущен, диапазон распространяется до конца строки.
с = 'abcde' печать (с [1: 3]) # До нашей эры печать (с [: 3]) # азбука печать (с [1:]) # BCDE
источник: str_index_slice.py
Вы также можете использовать отрицательные значения.
печать (с[-4:-2]) # До нашей эры печать (с [: - 2]) # азбука печать (с [-4:]) # BCDE
источник: str_index_slice. py
py
Если start > end , ошибка не возникает, а пустая строка '' извлекается.
печать(с[3:1]) # печать (с [3: 1] == '') # Истинный
источник: str_index_slice.py
Значения вне диапазона игнорируются.
печать (с[-100:100]) # абвде
источник: str_index_slice.py
В дополнение к начальной позиции start и конечной позиции stop , вы можете указать приращение step например [start:stop:step] . Если шаг отрицателен, подстрока извлекается в обратном порядке.
печать (с[1:4:2]) # БД печать (с [:: 2]) # туз печать (с [:: 3]) # объявление печать (с[::-1]) # edcba печать(с[::-2]) # эка
источник: str_index_slice.py
Дополнительные сведения о нарезке см. в следующей статье.
- Как разрезать список, строку, кортеж в Python
Встроенная функция len() возвращает количество символов. Например, вы можете использовать это, чтобы получить центральный символ или извлечь первую или вторую половину строки с нарезкой.
Например, вы можете использовать это, чтобы получить центральный символ или извлечь первую или вторую половину строки с нарезкой.
Обратите внимание, что вы можете указать только целочисленные значения int для индекса [] и среза [:] . Деление на / вызывает ошибку, поскольку результатом является число с плавающей запятой float .
В следующем примере используется целочисленное деление // . Десятичная точка усекается.
с = 'abcdefghi' печать (длина (ы)) № 9 # print(s[len(s) / 2]) # TypeError: строковые индексы должны быть целыми числами print(s[len(s) // 2]) # е print(s[:len(s) // 2]) # абвд print(s[len(s) // 2:]) # эфги
источник: str_index_slice.py
Регулярные выражения можно использовать с модулем re стандартной библиотеки.
- Регулярные выражения с модулем re в Python
Используйте re.search() для извлечения подстроки, соответствующей шаблону регулярного выражения. Укажите шаблон регулярного выражения в качестве первого параметра и целевую строку в качестве второго параметра.
Укажите шаблон регулярного выражения в качестве первого параметра и целевую строку в качестве второго параметра.
импорт с = '012-3456-7890' печать (поиск (r'\d+', s)) # <объект re.Match; диапазон = (0, 3), совпадение = '012'>
источник: str_extract_re.py
\d соответствует цифре, а + соответствует одному или нескольким повторениям предыдущего шаблона. Таким образом, \d+ соответствует одной или нескольким последовательным цифрам.
Поскольку обратная косая черта \ используется в специальных последовательностях регулярных выражений, таких как \d , удобно использовать необработанную строку, добавляя r перед '' или "" .
- Необработанные строки в Python
Когда строка соответствует шаблону, re.search() возвращает объект соответствия. Вы можете получить совпадающую часть в виде строки str с помощью метода group() объекта сопоставления.
m = поиск(r'\d+', s) печать (м.группа()) # 012 печать (тип (м. группа ())) # <класс 'ул'>
источник: str_extract_re.py
Дополнительные сведения об объектах сопоставления регулярных выражений см. в следующей статье.
- Как использовать объекты сопоставления регулярных выражений в Python
Как и в приведенном выше примере, re.search() возвращает только объект соответствия первой части, даже если имеется несколько совпадающих частей.
re.findall() возвращает список всех совпадающих подстрок.
print(re.findall(r'\d+', s)) # ['012', '3456', '7890']
источник: str_extract_re.py
В этом разделе приведены примеры шаблонов регулярных выражений с использованием метасимволов и специальных последовательностей.
Подстановочные шаблоны
. соответствует любому одиночному символу, кроме новой строки, а * соответствует нулю или более повторениям предыдущего шаблона.
Например, a.*b соответствует строке, начинающейся с a и заканчивающейся b . Поскольку * соответствует нулю повторений, оно также соответствует ab .
print(re.findall('a.*b', 'axyzb'))
# ['аксизб']
print(re.findall('a.*b', 'a---b'))
# ['а---б']
print(re.findall('a.*b', 'aあいうえおb'))
# ['аあいうえおб']
print(re.findall('a.*b', 'ab'))
# ['аб']
источник: str_extract_re.py
+ соответствует одному или нескольким повторениям предыдущего шаблона. a.+b не соответствует ab .
print(re.findall('a.+b', 'ab'))
# []
print(re.findall('a.+b', 'axb'))
# ['ахб']
print(re.findall('a.+b', 'axxxxxxb'))
# ['аххххххб']
источник: str_extract_re.py
? соответствует нулю или одному предыдущему шаблону. В случае a.?b он соответствует ab и строке, содержащей только один символ между а и б .
print(re.findall('a.?b', 'ab'))
# ['аб']
print(re.findall('a.?b', 'axb'))
# ['ахб']
print(re.findall('a.?b', 'axxb'))
# []
источник: str_extract_re.py
Жадные и нежадные
* , + и ? — все жадные совпадения, соответствующие как можно большему количеству текста. *? , +? и ?? — это нежадные, минимальные совпадения, соответствующие как можно меньшему количеству символов.
с = 'ахб-аххххххб'
print(re.findall('a.*b', s))
# ['ахб-аххххххб']
print(re.findall('a.*?b', s))
# ['ахб', 'аксхххххб']
источник: str_extract_re.py
Если вы заключите часть шаблона регулярного выражения в круглые скобки () , вы сможете извлечь из этой части подстроку.
print(re.findall('a(.*)b', 'axyzb'))
# ['xyz']
источник: str_extract_re.py
Если вы хотите сопоставить скобки () как символы, экранируйте их обратной косой чертой \ .
print(re.findall(r'\(.+\)', 'abc(def)ghi')) # ['(определение)'] print(re.findall(r'\((.+)\)', 'abc(def)ghi')) # ['защита']
источник: str_extract_re.py
Соответствует любому одиночному символу
Использование квадратных скобок [] в шаблоне соответствует любому одиночному символу из заключенной строки.
Если вы соедините последовательные кодовые точки Unicode с - , например [a-z] , будут покрыты все символы между ними. Например, 9[а-я]+', с))
# ['абв']
print(re.findall('[az]+$', s))
# ['ги']
источник: str_extract_re.py
Использовать | для соответствия подстроке, соответствующей любому из указанных шаблонов. Например, чтобы сопоставить подстроки, соответствующие шаблону A или шаблону B , используйте A|B .
с = 'ахххб-012'
print(re.findall('a.*b', s))
# ['ахххб']
print(re.findall(r'\d+', s))
# ['012']
print(re.

Об авторе