Какой процент индексации: Индексация заработной платы: что это, какой процент в 2023 году
Поиск и использование статистики: использование основных статистических методов
Архивное содержимое
Информация, идентифицированная как архивная, предоставляется для справочных, исследовательских или учетных целей. На него не распространяются веб-стандарты правительства Канады, и он не изменялся и не обновлялся с момента архивирования. Пожалуйста, свяжитесь с нами, чтобы запросить формат, отличный от доступных.
- Проценты
- Индексы и индексы
- Средние и медианы
Проценты
Одним из наиболее распространенных способов представления статистики является процентное представление. Процент просто означает «на сотню», а символ, используемый для выражения процента, — %. Один процент (или 1%) составляет одну сотую от общего или целого числа и поэтому рассчитывается путем деления общего или целого числа на 100.
Пример: 1% от 250 = (1 ÷ 100) x 250 = 2,5
вычислить заданный процент от числа, разделить общее число на 100, а затем умножить результат на запрошенный процент:
Пример: 12% от 250 = (250 ÷ 100) x 12 = 30
Чтобы вычислить процентное соотношение одного числа к другому, измените это уравнение и умножьте первое число на 100, а затем разделите результат на второе число:
Пример: 30 как % от 250 = (30 x 100) ÷ 250 = 12%
Чтобы определить процент от суммы по ряду чисел, сложите числа в ряду, чтобы найти итог (т. е. число, равное 100 %), и провести вышеуказанный расчет для каждого числа в ряду:
е. число, равное 100 %), и провести вышеуказанный расчет для каждого числа в ряду:
Пример: Учитывая ряд 30,150,70:
Итого будет 30 + 150 + 70 = 250
30 в процентах от 250 = (30 x 100) ÷ 250 = 12%
150 в % от 250 = (150 x 100) ÷ 250 = 60%
70 как % от 250 = (70 x 100) ÷ 250 = 28%
Если сложить проценты для каждого числа в ряду, они равны проценту для целого: 12% + 60% + 28% = 100 %
Для расчета процентной разницы между двумя числами используются одни и те же базовые вычисления.
Пример: Чтобы найти процентное изменение от 250 до 280,
вычисляется разница между числами:
280 – 250 = 30
и затем выражается в процентах от первого или основного числа:
(30 x 100) ÷ 250 = 12%
Определить целое число ( т. е. значение 100%), если только значение заданного процента:
Пример: если известно, что 280 равно 112%
тогда 1% должен быть 280 ÷ 112 = 2,5
а 100% должно быть (280 x 100) ÷ 112 = 250
Чтобы сравнить ряд различных вещей, их необходимо выразить на основе одной и той же базы:
Пример: если цена на колбасу увеличилась с 2,99 доллара за килограмм до 3,99 доллара, а на такое же количество сосисок — с 1,99 доллара до 2,99 доллара, то эти два увеличения можно выразить в процентах.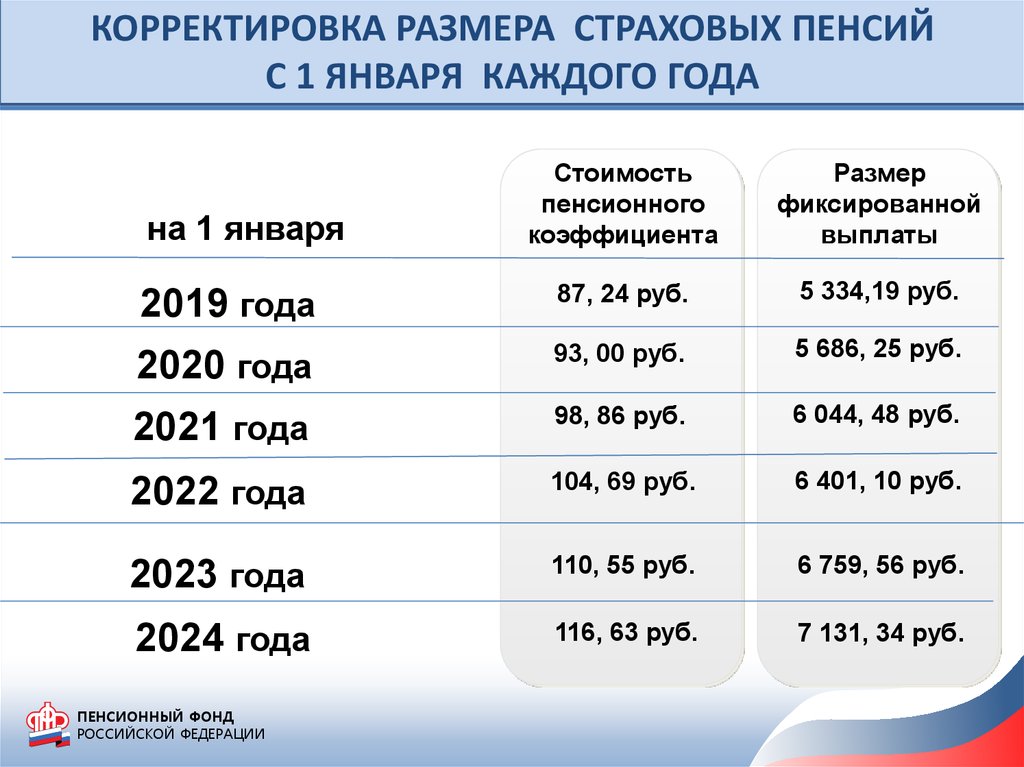
Сосиски: 3,99 — 2,99 долл. США = 1,00 долл. США
1,00 долл. США в процентах от 2,99 долл. США (1,00 долл. США x 100) ÷ 2,99 долл. США = 33% % от 1,99 доллара США составляет (1,00 доллара США x 100) ÷ $1,99 = 50%
Теперь легко увидеть, что рост цен на сосиски был намного выше, чем на колбасы.
Следует помнить, что сравнение процентов, которые имеют существенно разные основания, может создать ложное впечатление.
Пример: изменение с одного на два составляет 100 %, тогда как изменение с 5 000 000 на 6 000 000 составляет всего 20 %.
К началу страницы
Индексы и индексы
Индексы — это статистический способ выражения разницы между двумя измерениями путем обозначения одного числа в качестве «базы», присвоения ему значения 100 и последующего выражения второго числа как процент от первого.
Пример: если население города увеличилось с 20 000 в 1988 г. до 21 000 в 1991 г., то население в 1991 г. составляло 105% населения в 1988 г. Таким образом, на основе 1988 г. = 100, индекс населения для города составил 105 в 1991 г.
составляло 105% населения в 1988 г. Таким образом, на основе 1988 г. = 100, индекс населения для города составил 105 в 1991 г.
Термин «индекс», как этот термин обычно используется применительно к статистике, представляет собой ряд индексных чисел, выражающий ряд чисел в процентах от одного числа.
Пример: цифры
50 75 90 110
выраженный в виде индекса с первым числом в качестве основания, будет
100 150 180 220
Индексы можно использовать для выражения сравнений между местами, отраслями и т. д., но чаще всего они используются для выражения изменений за определенный период времени, и в этом случае индекс также является временным рядом или «рядом». Один момент времени обозначается как базовый период — это может быть год, месяц или любой другой период — и получает значение 100. Индексы для измерения (цена, количество, стоимость и т. д.) во всех других точках в время указывает процентное изменение по сравнению с базовым периодом.
Если цена, количество или стоимость увеличились на 15% по сравнению с базовым периодом, индекс равен 115; если он упал на 5%, индекс равен 95. Важно отметить, что индексы отражают процентные различия по отношению к базовому году, а не абсолютные уровни. Если индекс цен на один товар равен 110, а на другой — 105, это означает, что цена первого товара увеличилась в два раза больше, чем цена второго. Это не значит, что первый товар дороже второго.
Каждый номер индекса в ряду отражает процентное изменение по сравнению с базовым периодом. Важно не путать изменение индекса в пунктах и процентное изменение между двумя индексами в ряду.
Пример: если индекс цен на сливочное масло составлял 130 в один год и 143 в следующем году, то изменение индекса в пунктах
будет:
143 – 130 = 13
но процентное изменение индекса будет:
(143 – 130) x 100) ÷ 130 = 10%
Начало страницы
Средние значения и медианы
Оба эти способа представляют ряд чисел одним числом.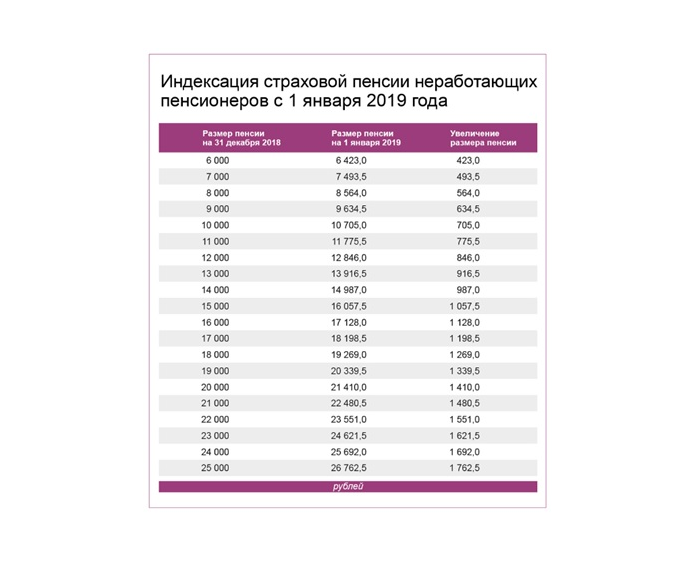 Среднее значение, которое чаще всего упоминается в публикациях Статистического управления Канады, является средним арифметическим. Это то, что большинство людей называют «средним», и оно рассчитывается путем сложения чисел в ряду и деления суммы на любое число чисел.
Среднее значение, которое чаще всего упоминается в публикациях Статистического управления Канады, является средним арифметическим. Это то, что большинство людей называют «средним», и оно рассчитывается путем сложения чисел в ряду и деления суммы на любое число чисел.
Пример: Если пять детей в возрасте соответственно 3, 4, 5, 8 и 10 лет, их средний возраст:
3 + 4 + 5 + 8 + 10 = 6
5
Медиана — это значение среднего числа ряда, ранжированного по размеру.
Пример: Учитывая возраст пяти детей 5, 4, 8, 3 и 10 лет, чтобы найти медианный возраст, сначала нужно переставить ряд в порядке возрастания, т. е. 3, 4, 5, 8, 10 и значение среднего числа, то есть 5, будет средним возрастом.
Индексация данных к общей отправной точке
DataBasics
Как индексировать любые ряды экономических данных к общей отправной точке для облегчения сравнения числовых данных.
Индексирование похоже на скачки
То, что скаковая лошадь может бегать, относительно неинтересно. Больше интриги для букмекеров и игроков заключается в том, что данная скаковая лошадь может бежать относительно быстрее, чем другая. Немногие пришли бы посмотреть, как случайно расставленные лошади скачут по дорожке, каждая стартует и останавливается по своему желанию, и у каждой есть своя финишная черта. Именно сравнение соревнующихся лошадей и последующее ранжирование делают гонку захватывающей.
Больше интриги для букмекеров и игроков заключается в том, что данная скаковая лошадь может бежать относительно быстрее, чем другая. Немногие пришли бы посмотреть, как случайно расставленные лошади скачут по дорожке, каждая стартует и останавливается по своему желанию, и у каждой есть своя финишная черта. Именно сравнение соревнующихся лошадей и последующее ранжирование делают гонку захватывающей.
Чтобы провести справедливое сравнение, официальные лица ипподрома нормализуют начальную точку с помощью стартовых ворот, отпускают всех лошадей одновременно и используют точные измерительные приборы для определения победителя. Очевидно, что некоторые скаковые лошади быстрее и сильнее других. Но без общей отправной точки любое определение физического превосходства было бы сомнительным.
То же самое верно и для экономических данных. Экономисты любят сравнивать данные. Они делают это, чтобы получить перспективу и поместить вещи в контекст. Например, полезно знать, что занятость в штате со временем растет.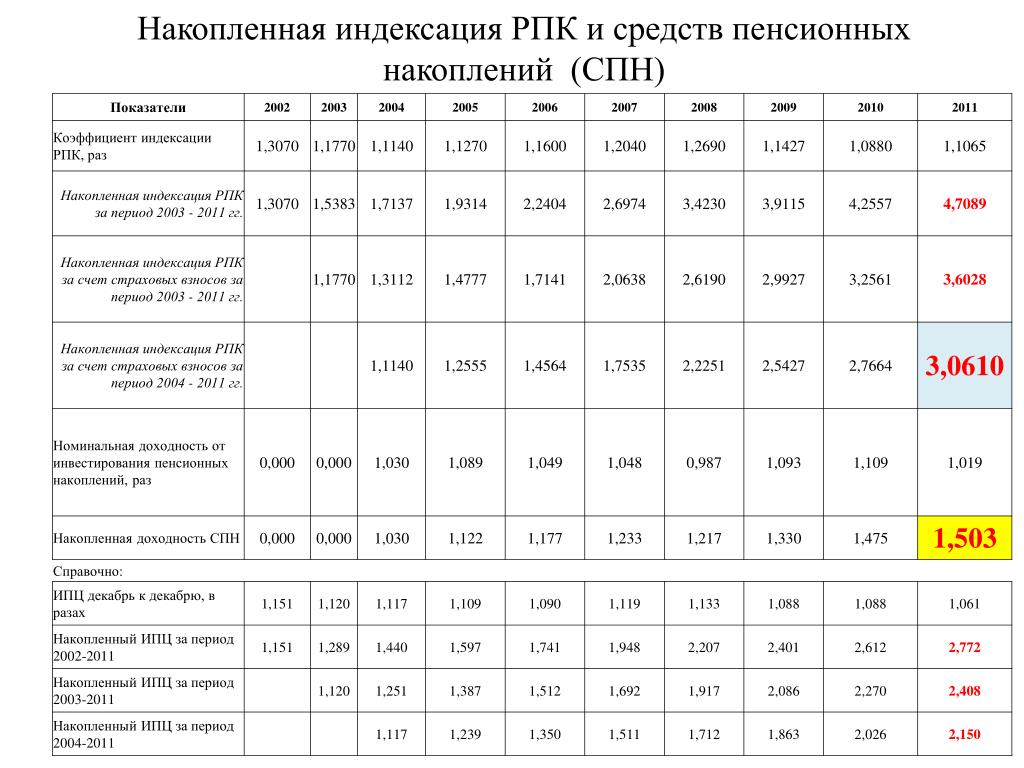 Но более красноречивым является знание темпов его роста по сравнению с другими штатами. Например, уровень изменения занятости в штате, хотя и положительный, может быть самым слабым из 50 штатов в выборке.
Но более красноречивым является знание темпов его роста по сравнению с другими штатами. Например, уровень изменения занятости в штате, хотя и положительный, может быть самым слабым из 50 штатов в выборке.
Начальные данные в одной и той же точке
Относительно простой способ проведения таких сравнений — индексация данных к общей начальной точке. По сути, рассматриваемые переменные должны быть установлены равными друг другу, а затем со временем проверяться на наличие различий. Индексированные данные удобны тем, что позволяют наблюдателю быстро определить темпы роста, взглянув на вертикальную ось диаграммы. Они также позволяют сравнивать переменные с разными величинами.
Индексация позволяет сравнивать данные любой величины
Например, предположим, что аналитик хочет использовать график для сравнения валового внутреннего продукта (ВВП) трех разных стран. Начертить такую диаграмму с абсолютными значениями было бы сложно из-за различий в размерах между странами. ВВП одной страны может измеряться триллионами, другой – сотнями миллиардов, а третьей – десятками миллиардов. Все эти суммы не уместились бы на графике.
ВВП одной страны может измеряться триллионами, другой – сотнями миллиардов, а третьей – десятками миллиардов. Все эти суммы не уместились бы на графике.
В качестве другого примера на диаграмме 1 показано, как неодинаковые величины квартальных уровней занятости в Техасе и США затрудняют графическую интерпретацию. Эта диаграмма показывает, что уровень занятости в США значительно выше, чем уровень занятости в Техасе, но из-за этого большого неравенства в величине по этой диаграмме невозможно сказать, росла ли занятость в Техасе (или снижалась) быстрее или медленнее, чем занятость в Техасе. США с 2003 по 2012 год.
Индексация числовых данных полезна в различных контекстах. Он постоянно проявляется в экономическом, финансовом и бизнес-анализе. Торговцы акциями индексируют цены на акции и фондовые индексы, чтобы сравнивать результаты с течением времени. Экономисты индексируют данные по выдающимся событиям, скажем, экономическим пикам (или спадам), чтобы увидеть, как данные снижаются (или растут) по отношению друг к другу. Во всех случаях это позволяет быстро сравнивать и ранжировать.
Во всех случаях это позволяет быстро сравнивать и ранжировать.
Техническое решение
Механизм индексации
Для индексации числовых данных значения должны быть скорректированы таким образом, чтобы они были равны друг другу в заданный начальный период времени. По соглашению это значение обычно равно 100. С этого момента каждое значение нормализуется до начального значения, сохраняя те же процентные изменения, что и в неиндексированных рядах. Последующие значения рассчитываются таким образом, чтобы процентные изменения в индексированном ряду были такими же, как и в неиндексированном.
Рассмотрим данные в Таблице 1. Переменные X и Y представляют ряд гипотетических данных. В среднем переменная 9 t — новое индексированное значение переменной.
| Таблица 1 Индексирование двух рядов данных | ||||
| Год | Х | Д | Индексированное значение X | Индексированное значение Д |
| 2000 | 250 | 2000 | 100 | 100 |
| 2001 | 500 | 3000 | 200 | 150 |
| 2002 | 810 | 6000 | 324 | 300 |
| 2003 | 925 | 6500 | 370 | 325 |
| 2004 | 1010 | 6500 | 404 | 325 |
| 2005 | 1052 | 7100 | 421 | 355 |
| 2006 | 1030 | 7300 | 412 | 365 |
| 2007 | 1240 | 7600 | 496 | 380 |
| 2008 | 1470 | 7800 | 588 | 390 |
| 2009 | 1500 | 8300 | 600 | 415 |
| 2010 | 1525 | 9200 | 610 | 460 |
| 2011 | 1580 | 9900 | 632 | 495 |
| 2012 | 1740 | 10 200 | 696 | 510 |
| 2013 | 1890 | 9800 | 756 | 490 |
В период с 2000 по 2001 год переменная X увеличилась с 250 до 500, или на 100 процентов. Следовательно, индексированное значение X также должно увеличиться на 100 процентов, со 100 до 200. Точно так же Y увеличилось на 50 процентов между 2000 и 2001 годами. Таким образом, индексированное значение Y увеличилось на 50 процентов, со 100 до 150, за тот же период времени.
Следовательно, индексированное значение X также должно увеличиться на 100 процентов, со 100 до 200. Точно так же Y увеличилось на 50 процентов между 2000 и 2001 годами. Таким образом, индексированное значение Y увеличилось на 50 процентов, со 100 до 150, за тот же период времени.
Индексация позволяет быстро оценить процентные изменения между начальным периодом времени и любым последующим периодом времени. Например, в период с 2000 по 2013 год переменные X и Y увеличились на 656 и 390 процентов соответственно.
Пример из реальной жизни
Применение метода к занятости в Техасе и США
Индексация улучшает способность анализировать изменения данных за определенный период времени. На примере уровней занятости в США и Техасе было трудно увидеть, как рост рабочих мест в Техасе сравнивается с ростом рабочих мест на национальном уровне. Однако такое сравнение возможно с индексированными данными.
Расчеты
В таблице 2 каждое значение в столбце США делится на 130 093 и умножается на 100, чтобы получить индексированное значение. Аналогичным образом каждое значение в столбце Техас делится на 9 394 и умножается на 100.
Аналогичным образом каждое значение в столбце Техас делится на 9 394 и умножается на 100.
| Таблица 2 Индексирование данных о занятости в Техасе и США | ||||
| Период | США | Техас | Индекс США | Техас проиндексирован |
| 2003 — Q1 | 130 093 | 9 394 | 100,0 | 100,0 |
| 2003 — Q2 | 129 843 | 9 368 | 99,8 | 99,7 |
| 2003 — Q3 | 129 871 | 9 345 | 99,8 | 99,5 |
| 2003 — 4 квартал | 130 175 | 9 375 | 100,1 | 99,8 |
| 2004 — Q1 | 130 563 | 9 419 | 100,4 | 100,3 |
| 2004 — Q2 | 131 285 | 9 460 | 100,9 | 100,7 |
| 2004 — Q3 | 131 623 | 9 501 | 101,2 | 101. 1 1 |
| 2004 — Q4 | 132 206 | 9 564 | 101,6 | 101,8 |
| 2005 — Q1 | 132 660 | 9 605 | 102,0 | 102,2 |
| 2005 — Q2 | 133 388 | 9 679 | 102,5 | 103,0 |
| 2005 — Q3 | 134 132 | 9 764 | 103.1 | 103,9 |
| 2005 — 4 квартал | 134 596 | 9 823 | 103,5 | 104,6 |
| 2006 — Q1 | 135 402 | 9 924 | 104.1 | 105,6 |
| 2006 — Q2 | 135 912 | 9 998 | 104,5 | 106,4 |
| 2006 — Q3 | 136 350 | 10 058 | 104,8 | 107,1 |
| 2006 — 4 квартал | 136 700 | 10 151 | 105,1 | 108,1 |
| 2007 — Q1 | 137 243 | 10 232 | 105,5 | 108,9 |
| 2007 — Q2 | 137 591 | 10 335 | 105,8 | 110,0 |
| 2007 — Q3 | 137 659 | 10 415 | 105,8 | 110,9 |
| 2007 — четвертый квартал | 137 885 | 10 483 | 106,0 | 111,6 |
| 2008 — Q1 | 137 935 | 10 562 | 106,0 | 112,4 |
| 2008 — Q2 | 137 443 | 10 607 | 105,6 | 112,9 |
| 2008 — Q3 | 136 711 | 10 635 | 105,1 | 113,2 |
| 2008 — 4 квартал | 135 087 | 10 618 | 103,8 | 113,0 |
| 2009 — 1 квартал | 132 812 | 10 516 | 102. 1 1 | 111,9 |
| 2009 — Q2 | 130 945 | 10 330 | 100,7 | 110,0 |
| 2009 — 3 квартал | 129 944 | 10 248 | 99,9 | 109,1 |
| 2009 — четвертый квартал | 129 447 | 10 213 | 99,5 | 108,7 |
| 2010 — Q1 | 129 319 | 10 229 | 99,4 | 108,9 |
| 2010 — Q2 | 129 960 | 10 290 | 99,9 | 109,5 |
| 2010 — 3 квартал | 129 920 | 10 346 | 99,9 | 110.1 |
| 2010 — 4 квартал | 130 226 | 10 408 | 100,1 | 110,8 |
| 2011 — Q1 | 130 685 | 10 452 | 100,5 | 111,3 |
| 2011 — Q2 | 131 237 | 10 530 | 100,9 | 112,1 |
| 2011 — 3 квартал | 131 531 | 10 582 | 101. 1 1 | 112,6 |
| 2011 — 4 квартал | 131 985 | 10 606 | 101,5 | 112,9 |
| 2012 — Q1 | 132 681 | 10 711 | 102,0 | 114,0 |
| 2012 — Q2 | 133 004 | 10 757 | 102,2 | 114,5 |
| 2012 — 3 квартал | 133 416 | 10 808 | 102,6 | 115,0 |
| 2012 — 4 квартал | 133 864 | 10 875 | 102,9 | 115,8 |
Техас рос быстрее, чем США в течение периода исследования
На диаграмме 2 показано влияние индексации двух рядов данных. С 2003 по 2008 год занятость в Техасе росла гораздо быстрее, чем занятость в стране. Кроме того, после последней рецессии рост занятости в Техасе продолжает опережать рост в остальной части США.

Об авторе