Капча онлайн: API rucaptcha.com. Описание методов для пересылки изображений для распознавания и получение результата расшифровки. OCR API. Решение ReCaptcha
Текстовая CAPTCHA в 2022 / Хабр
В этой статье я попробую пройти весь путь в распознавании text-based CAPTCHA, от эвристик до полностью автоматических систем распознавания. Попробую проанализировать, жива ли еще капча(речь про текстовую), или пора ей на покой.
Впервые текстовая капча(text-based CAPTCHA), дальше я ее буду называть просто капча, использовалась в поисковике AltaVista, это был 1997 год, она предотвращала автоматическое добавление URL в поисковую систему. В те годы это была надежная защита от ботов, но прогресс не стоял на месте, и эту защиту начали обходить, используя доступные на то время OCR(например, FineReader).
Капча начала усложняться, в неё добавляли небольшой шум, искажения, чтобы распространенные OCR не могли распознать текст. Тогда начали появляться написанные под конкретные капчи OCR, что требовало дополнительных затрат и знаний у атакующей стороны. И от разработчиков капчей требовалось понимание, в чем сейчас трудности у атакующего, и какие искажения нужно внести, чтобы было сложно автоматизировать распознавание капчи. Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
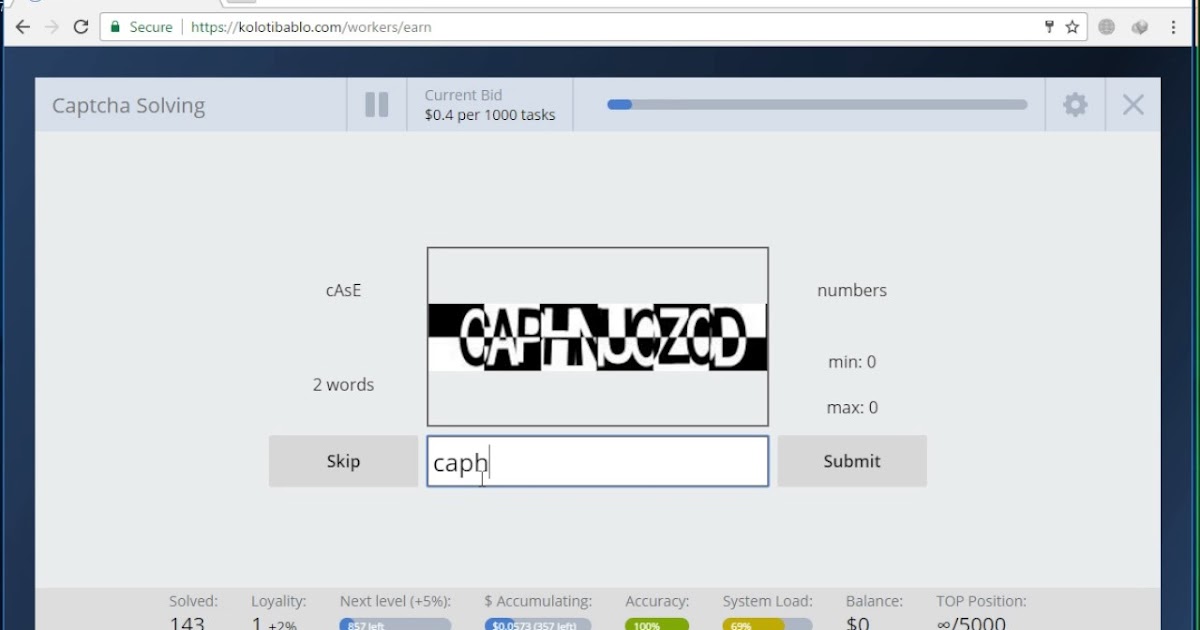
В качестве объекта распознавания возьму капчу Яндекса с сайта Yandex.com. На русскоязычной версии сайта капчи немного сложнее из-за того, что используются как русские, так и английские слова.
Примеры капчНа первый взгляд, достаточно правильно бинаризировать картинку(перевести в черно-белый вариант) и дело в шляпе, можно получить большой процентов правильных распознаваний, так как сегментация на отдельные буквы выглядит довольно простой.
Для снижения эффективности эвристических алгоритмов Яндекс сделал упор на сложность бинаризации: есть капчи, для которых в каждой области изображения будет свой порог бинаризации, и надо подбирать его адаптивно. В среднем капча содержит 14 символов. Даже если мы сделаем классификатор с точностью 99%, и все капчи будем правильно сегментировать, то это нам даст точность в 87% распознавания всей капчи из двух слов. Здесь еще стоит упомянуть, что на сложность модели влияет количество классов(букв, цифр, знаков), используемых во всем наборе капч — чем их больше, тем сложнее достичь высоких процентов распознавания отдельных символов на простых моделях, поэтому капча на яндекс.ру будет сложнее, т.к. в ней используются русские и английские слова.
В среднем капча содержит 14 символов. Даже если мы сделаем классификатор с точностью 99%, и все капчи будем правильно сегментировать, то это нам даст точность в 87% распознавания всей капчи из двух слов. Здесь еще стоит упомянуть, что на сложность модели влияет количество классов(букв, цифр, знаков), используемых во всем наборе капч — чем их больше, тем сложнее достичь высоких процентов распознавания отдельных символов на простых моделях, поэтому капча на яндекс.ру будет сложнее, т.к. в ней используются русские и английские слова.
Из слабых мест этой капчи можно отметить, что буквы легко сегментируются при правильной бинаризации, и можно использовать проверку по словарю.
Далее будет описан эвристический алгоритм распознавания, а также я оставлю здесь ссылку на обучающую и тренировочную выборки.
Подготовительный этап
Для начала скачаем капчи и разделим их на тренировочную выборку и тестовую. Скачивание изображений капчи происходило через ВПН(с сайта yandex.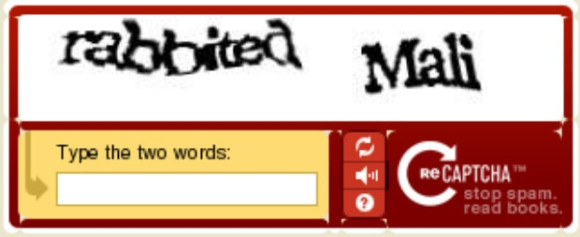 com). При попытке сделать аккаунт вручную через браузер система меня распознавала ботом(думаю, из-за ВПН). Поэтому, предполагаю, я получил капчи с повышенной сложностью — «Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение. » https://habr.com/ru/company/yandex/blog/549996/ Тип браузера, похоже, на результат не влиял (Opera, Chrome, Edge).
com). При попытке сделать аккаунт вручную через браузер система меня распознавала ботом(думаю, из-за ВПН). Поэтому, предполагаю, я получил капчи с повышенной сложностью — «Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение. » https://habr.com/ru/company/yandex/blog/549996/ Тип браузера, похоже, на результат не влиял (Opera, Chrome, Edge).
Итого набралось 4847 капч в тренировочную выбрку, и 354 — в тестовую. На распознавание обеих выборок было потрачено несколько долларов на сервисе decaptcher.com.
Эвристический алгоритм распознавания
Алгоритм будет состоять из нескольких шагов, это бинаризация, очистка от шума, извлечение двух слов, при необходимости — нормализация наклона для каждого слова, потом сегментация и распознавание.
1. Бинаризируем картинку — перевод цветного изображения, или изображения в градациях серого в черно-белое изображения. Цель — получение фона(0) и объекта(1), и уменьшение шума после бинаризации. Алгоритмы бинаризации будут описаны ближе к концу. Далее для каждого этапа сформируем параметры, которые будем потом оптимизировать. С этого момента работаем только с бинарным изображением.
Бинаризируем картинку — перевод цветного изображения, или изображения в градациях серого в черно-белое изображения. Цель — получение фона(0) и объекта(1), и уменьшение шума после бинаризации. Алгоритмы бинаризации будут описаны ближе к концу. Далее для каждого этапа сформируем параметры, которые будем потом оптимизировать. С этого момента работаем только с бинарным изображением.
2. Бинарное изображение очищаем от шума. Извлекаем связанные области из изображения — это наши объекты. Далее по количеству пикселей, которые входят в объект, разделяем их на шум и полезный объект. Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
3. Извлекаем из изображения 2 слова. Пробел между словами находится примерно по центру изображения. Величину «примерно» будем искать в окне ширины X, это будет еще одним параметром для оптимизации. Далее получаем горизонтальную гистограмму яркости в этом окне, вводим еще одно значение — порог, который будет нам показывать в этом столбце пробел, или объект, наибольшее кол-во пробелов подряд будут нам говорить о том, что это место разделения двух слов. В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
4. Нормализация наклона текста(для тех капч, где она нужна). Чтобы получить точность распознавания отдельных букв выше, нужно в некоторых капчах нормализовать наклон. Для этого мы проводим морфологическую операцию закрытие, и у нас получается единый объект. Далее находим ориентацию этого объекта, это угол между осью Х и главной осью элипса, в который вписывается наш объект.
5. Сегментация. На этом этапе у нас есть изображения 2-х слов, теперь нужно разбить их на отдельные буквы, для дальнейшего распознавания. Так как в нашем случае буквы не соприкасаются вместе, то можем извлечь связные области из изображения, это и будут наши символы, пригодные для дальнейшего распознавания.
Примеры символов извлеченные из двух изображений6. Распознавание символов. Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами. Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Теперь, в зависимости от метода бинаризации, я представлю результаты распознаваний. Сначала я использовал один порог бинаризации для всех капч, порог подобрал на тренировочной выборке, и получил 15% правильно распознанных капч на тренировочной и 15% на тестовой.
Использование алгоритма Оцу дало 13.6% на тренировочной и 12.25% на тестовой.
Метод бинаризации Sauvola, после подбора параметров он дал 26.01% на тренировочной и 25.8% на тестовой.
Подметив, что капчи можно разделить по фону на группы, сделаем кластеризацию. Признаки извлечем с помощью метода Zoning. Суть метода такова — изображение делится на непересекающиеся области заданного размера, после чего извлекаем из каждой области среднее значение яркости. Чем меньше у нас размер окна, тем точнее описывается изображение. Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Примеры кластеров:
Кластер 1Кластер 2Кластер 3Кластер 4Кластер 5Теперь у нас есть капчи, которые мы правильно бинаризировали, можно попробовать что-нибудь потяжелее, например U-Net для бинаризации, сеть с 13.5+ млн. параметров. Получили на тренировочных данных 39,2% правильных ответов, на тесте — 38.7%.
Для каждого нового типа капч, нам приходилось бы придумывать какие то новые схемы бинаризации, сегментации, что делает задачу трудоемкой в зависимости от капчи, но не невозможной. И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
А что на счет полностью автоматизированного процесса создания модели для распознавания, где не надо ничего придумывать, никакой эвристики? На вход — капчи с ответами, на выходе — готовая модель. Относительно недавно на сайте библиотеки Keras появились исходники, которые, при небольшой модификации, можно использовать для распознавания любых текстовых капч https://keras.io/examples/vision/captcha_ocr/
На Яндекс капче у меня получились такие цифры: на тренировочных данных сеть показала точность 55%, на тестовых — 39%. Из-за слишком маленькой тренировочной выборки для такой большой сети происходило быстро переобучение, но при правильно подобранных параметрах регуляризации сеть могла обучаться. Если увеличить тренировочную выборку, добавив туда отраженные картинки, то получим на тренировочных 58% точности, а на тесте — 43%. Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Сеть чаще всего ошибается на капчах такого вида:
Типы капч на которых система чаще всего ошибаетсяЭто коррелирует с тезисом авторов Яндекс капчи, в своей статье они писали -«Наиболее сложные датасеты с распознаванием слов на сегодняшний день представляют собой сильно искривлённые тексты (irregular text recognition).» Но в данном случае это скорее ограничение архитектуры используемой сети. Полученные фичи после слоев CNN мы распознаем lstm слоем последовательно слева направо, и в некоторых срезах возможного символа у нас находится сразу несколько символов. Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Рис. 1Но если сделать капчи, написав текст в одну строчку и добавив в текст искажения, усложняя ее (рис. 2), то получим 97% правильных ответов и 3% ошибочных.
Рис.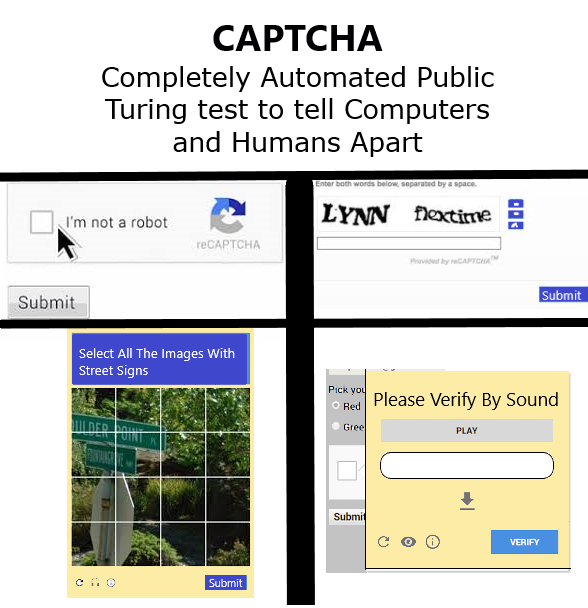 2
2Для увеличения процента успешных распознаваний яндекс капч можно использовать детектор текста, после чего нормализовать наклон и далее распознать нейронной сетью. Примеры сложных яндекс капч и детектора текста(рис. 3)
Рис. 3Если использовать детектор текста, то мы получим на тренировочных 60% точности, а на тесте — 51%. Я использовал уже предобученный на синтетике детектор текса — CRAFT: Character-Region Awareness For Text detection, а распознаванием отдельных слов занималась уже обученная модель на самой Яндекс капче.
Разработчики из Яндекса при проектировании капчи решали сразу две проблемы — уменьшение потенциальной эффективности ОЦР при «дружелюбности» для человека. Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Рис. 4Но это не так, нейронные сети без труда «ломают» такие капчи и могут показать уровень расознавания выше человеческого. При этом не нужно придумывать какие-то эвристические алгоритмы, достаточно скачать готовую сетку и обучить, 99% текстовых капч она решит.
Если подвести итог, то проектирование текстовой капчи в текущих реалиях требует понимания методов и подходов, которыми будет пользоваться злоумышленник для ее распознавания и исходя из этого проектировать капчу, которая эффективно сможет противостоять роботам, и при этом будет простой для восприятия человеком.
Прошу вас поделиться своими мыслями в комментариях, как может выглядеть текстовая капча, которая будет сложной для распознавания машиной.
Captcha и recaptcha — презентация онлайн
Похожие презентации:
Пиксельная картинка
Информационная безопасность. Методы защиты информации
Электронная цифровая подпись (ЭЦП)
Этапы доказательной медицины в работе с Pico. Первый этап
История развития компьютерной техники
От печатной книги до интернет-книги
Краткая инструкция по CIS – 10 шагов
Информационные технологии в медицине
Информационные войны
Моя будущая профессия. Программист
МИНОБРНАУКИ РОССИИ
ФГБОУ ВО «ХГУ им. Н.Ф. КАТАНОВА»
Н.Ф. КАТАНОВА»
Инженерно-технологический институт
Кафедра информационных технологий и систем
CAPTCHA и RECAPTCHA
Обучающийся
Корочкин М.В.
Направление: 09.03.03 «Прикладная информатика»,
профиль «Прикладная информатика в экономике»
Курс 3
Гр. 28
Абакан 2020
CAPTCHA
Ка́пча (CAPTCHA — англ. Completely Automated Public Turing test to tell Computers
для различения компьютеров и людей) — компьютерный тест, используемый для
того, чтобы определить, кем является пользователь системы: человеком или
компьютером. Термин появился в 2000 году. Основная идея теста: предложить
пользователю такую задачу, которая с лёгкостью решается человеком, но крайне
сложна и трудоёмка для компьютера.
Варианты реализации
В наиболее распространённом варианте капчи пользователь вводит символы,
изображённые на рисунке (зачастую с добавлением помех или полупрозрачности),
но так, чтобы было очень затруднительно машинное распознавание текста.
Уязвимости
Использование уязвимостей
Угадывание
Использование баз данных
Автоматическое распознавание
Распознавание чужими руками
Полезность
Капча сама по себе не может остановить спамеров. С другой стороны, этот
метод защиты может создавать большие неудобства людям.
К тому же капчей злоупотребляют, например, файловые хостинги, что
несёт в массы сервисы по распознаванию капчи и делает её ещё более
неэффективной.
ReCAPTCHA
ReCAPTCHA — система, разработанная в университете Карнеги — Меллон для
защиты веб-сайтов от интернет-ботов и одновременной помощи в оцифровке
текстов книг. Является продолжением проекта CAPTCHA. В сентябре 2009 года
reCAPTCHA была приобретена компанией Google.
ReCAPTCHA
● Текстовые реализации
● Графические
реализации
Прочие разновидности
● Логическая капча
● Поведенческая капча
● Звуковая каптча
Логическая капча
Поведенческая капча
Звуковая капча
Альтернатива капчи
Как подсчитала компания Cloudflare , на решение каптчи у
пользователя уходит, в среднем, 32 секунды.

млрд пользователей Интернета, и каждый сталкивается с такими задачами
примерно раз за 10 дней. Таким образом, на решение каптчи ежедневно
уходит примерно 500 лет.
Альтернатива капчи
Каждое устройство имеет встроенный защищенный модуль,
содержащий уникальный секрет, запечатанный производителем.
Cloudflare запрашивает у устройства доказательства подлинности, не
раскрывая информацию о модуле.
Альтернатива капчи
Криптография с открытым ключом позволяет создавать
неподдающиеся подделке цифровые подписи, а пользователь генерирует
их ключ, которым может подписывать сообщения, и ключ проверки,
который может использовать кто угодно для проверки их подлинности.
Альтернатива капчи
Криптография с открытым ключом позволяет создавать
неподдающиеся подделке цифровые подписи, а пользователь генерирует
их ключ, которым может подписывать сообщения, и ключ проверки,
который может использовать кто угодно для проверки их подлинности.
English Русский Правила
Должны ли вы использовать Captcha в своих веб-формах? Давайте посмотрим на данные
Что такое Captcha?Любой, кто регулярно пользуется интернетом, знаком с капчей. Это те надоедливые письма, которые просят нас доказать нашу человечность и показать, что мы не роботы?
Британский комик Майкл Макинтайр весело описал боль, которую они причиняют, в своем стендапе.
К сожалению, они не шутка, когда негативно влияют на коэффициент конверсии вашей формы.
Old School Captcha Captcha расшифровывается как «Полностью автоматизированный публичный тест Тьюринга, позволяющий отличить компьютеры от людей». Он был разработан для защиты наших веб-сайтов и форм на них от спама.
С точки зрения Интернета, СПАМ — это дьявольская работа. Это блокирует входящие сообщения вашей команды электронной коммерции; отвлекая их от решения реальных вопросов о продажах или других обязанностей, связанных с получением дохода. В худшем случае СПАМ может привести к тому, что боты переполнят ваши системы, что вызовет серьезные проблемы в работе вашего веб-сайта и серверной части, а также повысит риск мошенничества и других преступных действий.
В худшем случае СПАМ может привести к тому, что боты переполнят ваши системы, что вызовет серьезные проблемы в работе вашего веб-сайта и серверной части, а также повысит риск мошенничества и других преступных действий.
Таким образом, несмотря на то, что CAPTCHA является источником раздражения для веб-пользователей, на самом деле она здесь, чтобы спасти нас от жизни, потраченной на удаление сотен спам-писем, и защитить наши личные данные от тех, кто пытается манипулировать ими в своих двуличных целях.
В этом смысле CAPTCHA представляет собой дихотомию как для веб-дизайнеров, так и для владельцев веб-бизнеса: .
Но, с другой стороны, Captcha — отличный способ защитить конфиденциальность и обеспечить работу в Интернете без проблем с удобством использования, которые создает СПАМ.
Так как же нам добиться правильного баланса?
К счастью для нас, по мере развития технологий появляются лучшие итерации и альтернативы Captcha.
Если вы прочитаете эту статью, вы поймете, что должно работать лучше всего для оптимизации вашей веб-формы, ваших клиентов и вашего бизнеса в целом.
Самое главное, эта информация должна позволить вам достичь правильного баланса между безопасностью вашего веб-ресурса и данных клиентов, одновременно повышая удобство работы пользователей и защищая коэффициент конверсии.
Поскольку пользовательский опыт является ключевым компонентом вашего бренда, это работа, которую вы хотите сделать правильно.
Каковы плюсы и минусы использования Captcha?
Капча весьма эффективна в качестве средства защиты от спама. Оно бесплатное, простое в установке и предоставляет веб-сайтам дополнительный уровень безопасности в трех областях:
- Защита регистрации на веб-сайте от получения бесполезной информации и учетных записей ботов
- Предотвращение спама в комментариях в виде рекламы и нежелательных сообщений
- Демонстрация клиентам того, что вы серьезно относитесь к мерам безопасности, когда речь идет о конфиденциальной информации
Без защиты на месте, человек, который активно использует электронную почту (получение 10 электронных писем в неделю считается активным), может получать до 160 спам-писем КАЖДУЮ ОДНУ НЕДЕЛЮ!
Утилизация всех этих «электронных отходов» может занять 5-6 часов в месяц.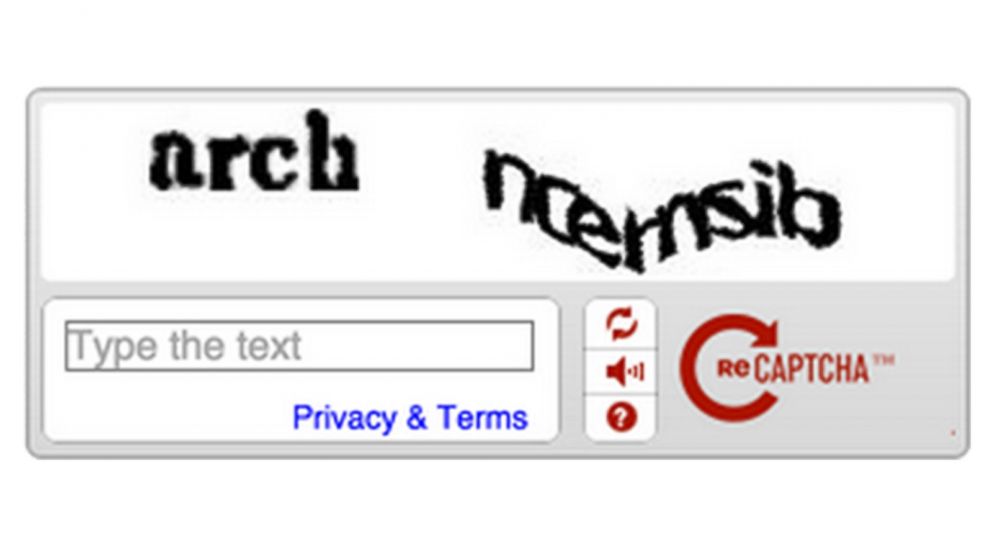 Кроме того, поскольку СПАМ может быть воротами для мошенничества и фишинга, по оценкам, на его долю приходится глобальный ущерб в десятки миллиардов долларов.
Кроме того, поскольку СПАМ может быть воротами для мошенничества и фишинга, по оценкам, на его долю приходится глобальный ущерб в десятки миллиардов долларов.
Однако, как и у большинства вещей в жизни, у Captcha есть свои недостатки.
Уважаемый UX-дизайнер и специалист по цифровым технологиям Гарри Бригнулл (Harry Brignull) сказал:
«Использование CAPTCHA — это способ сообщить миру о том, что у вас есть проблема со спамом, что вы не знаете, как с этим бороться, и что вы решили переложить разочарование по поводу проблемы на вашу пользовательскую базу. Что касается заявлений, то это довольно неубедительно».
Если ваши клиенты недовольны тем, что им приходится выполнять тест Captcha, вероятность того, что они вставят палочки перед совершением покупки, возрастет.
Исследование, проведенное Animoto, показало, что веб-формы без проверки подлинности обеспечивают 64-процентную конверсию, в то время как форма с капчей имеет коэффициент конверсии 48%. Таким образом, добавив CAPTCHA, компания может потерять почти треть конверсий со своих веб-форм или касс.
Таким образом, добавив CAPTCHA, компания может потерять почти треть конверсий со своих веб-форм или касс.
Несмотря на то, что мы понимаем финансовую сторону здесь — т. е. вы упускаете часть продаж — мы знаем, что приоритетом должно быть создание всемирной сети, которая будет настолько безопасной и свободной от коррупции, насколько это возможно. Мы, веб-эксперты, должны внедрить правильные системы для защиты наших клиентов и нашего бизнеса от коррупции.
Таким образом, вопрос, на который нужно ответить, заключается в том, какая система защиты от спама поможет вам достичь правильного баланса: уделение приоритетного внимания конфиденциальности и безопасности вашего пользователя + создание удобного пользовательского интерфейса + сводит к минимуму любые компромиссы с коэффициентами конверсии ?
Возможно, использование двух или более систем, описанных ниже, является правильным путем, чтобы ваши веб-пользователи были довольны, а ваши финансовые директора были довольны вашими финансовыми показателями.
Давайте рассмотрим все варианты, которые есть в вашем распоряжении.
Варианты защиты от спама для ваших форм:Re-Captcha
Служба Google ReCAPTCHA началась как исследовательский проект Университета Карнеги-Меллона в 2007 году.
Google приобрел проект в 2007 году. предоставление компаниям ReCAPTCHA бесплатно в обмен на разрешение использовать данные сервиса для обучения его систем визуальной идентификации.
Зуко в настоящее время использует ReCaptcha на нашем собственном веб-сайте, так что вы знаете, что нам это нравится.
В отличие от старой неразборчивой капчи, пользователям проще ее увидеть.
Он просит вас щелкнуть поле, чтобы подтвердить, что вы не робот, а затем сканирует отправителя для подтверждения. Если есть какие-либо сомнения, он показывает вам изображение (как показано ниже), чтобы убедиться, что вы действительно человек.
Спорим, вы все выполнили одно из них! Компания Google недавно запустила версию 3 своего предложения Captcha, получившего название «невидимая reCaptcha».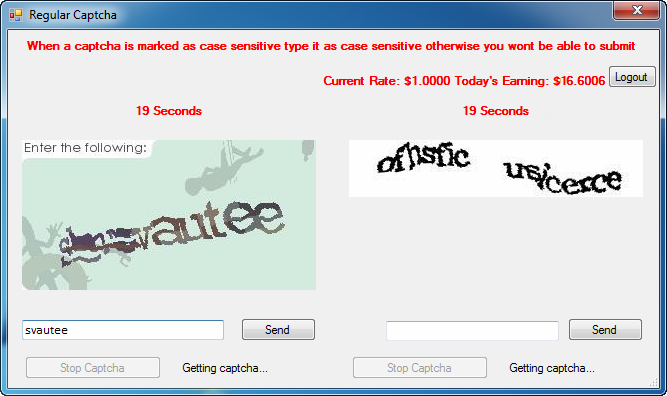 Они используют точки данных для оценки того, как пользователь взаимодействует со страницей, чтобы определить, является ли пользователь ботом или человеком. Никаких флажков со стороны пользователей не нужно: все незаметно. Глядя на ваши поведенческие черты, такие как то, как быстро вы заполнили форму, были ли какие-либо орфографические ошибки или неправильный выбор в различных точках, все это демонстрирует, что вы человек. Мы все делаем ошибки, роботы меньше.
Они используют точки данных для оценки того, как пользователь взаимодействует со страницей, чтобы определить, является ли пользователь ботом или человеком. Никаких флажков со стороны пользователей не нужно: все незаметно. Глядя на ваши поведенческие черты, такие как то, как быстро вы заполнили форму, были ли какие-либо орфографические ошибки или неправильный выбор в различных точках, все это демонстрирует, что вы человек. Мы все делаем ошибки, роботы меньше.
Но прежде чем вы перестанете читать эту статью и начнете кричать «давайте перейдем к невидимой reCAPTCHA — работа сделана», вам нужно знать следующее: , многие веб-сайты (включая Zuko) откладывают установку этой версии до тех пор, пока не будут полностью удовлетворены тем, что система отслеживания поведения Google не ставит под угрозу защиту конфиденциальности. Что касается технологии, которую они используют для отслеживания вашего поведения, включая наличие у вас учетной записи Google, есть опасения по поводу того, что делается с этими данными. Наблюдайте за этим пространством.
Наблюдайте за этим пространством.
hCaptcha — надежная альтернатива услугам интернет-гиганта. Эти ребята — «самая широко используемая в мире независимая служба CAPTCHA» с долей рынка около 15%.
В их решении есть ряд положительных моментов, главным из которых является их способность обеспечить конфиденциальность всех важных пользователей. Им не нужно собирать тонны данных для выявления трафика или поведения ботов, как это делают другие варианты.
hCaptcha поддерживает Privacy Pass и в первую очередь направлен на снижение частоты требуемых CAPTCHA. Они утверждают:
- Собрать минимально необходимый объем персональных данных
- Обеспечить прозрачность в отношении того, какие данные они собирают, как и почему они должны их использовать
- Иметь надежное решение для слабовидящих и других пользователей с проблемами доступности
В то время как эти являются очень важным аргументом против «невидимой Recaptcha» Google, это платная услуга, поэтому она требует реальных затрат.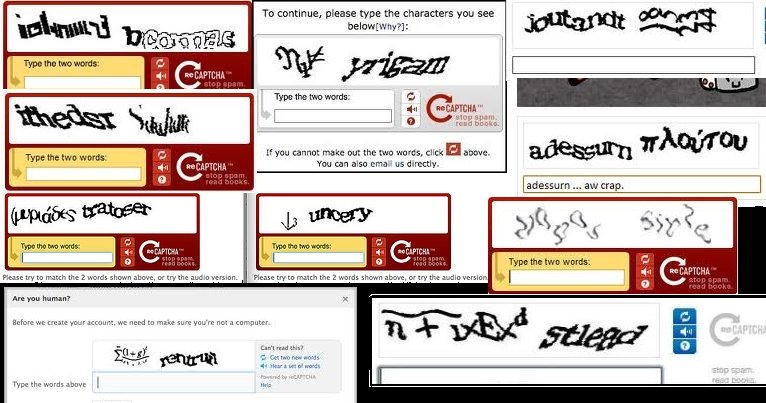
У них также есть дополнительный бонус: их тесты более увлекательны, а их изображения более удобны для пользователя:
Если вы любите рассматривать как долгосрочные, так и краткосрочные и среднесрочные перспективы, то стоит помнить, что придет день, когда вам понадобятся альтернативные средства защиты от спама, отличные от Captcha. Последние 20 лет мы участвовали в гонке с ботами и искусственным интеллектом, поскольку машины пытаются догнать человеческие возможности.
Джейсон Полакис, профессор компьютерных наук Иллинойского университета в Чикаго, говорит, что теперь они почти выигрывают гонку:
«Сейчас машинное обучение почти так же хорошо справляется с базовыми задачами распознавания текста, изображений и голоса, как и люди. На самом деле алгоритмы, вероятно, справляются с этим лучше; Мы находимся на этапе, когда усложнение программного обеспечения в конечном итоге делает его слишком сложным для многих людей. Нам нужна какая-то альтернатива, но конкретного плана пока нет».
Если вы предпочитаете отказаться от классических методов тестирования «Captcha» сейчас, вы можете вместо этого рассмотреть один из этих методов:
Двойной выбор По сути, подтверждение по электронной почте.
Регистрация пользователя в веб-форме / оформлении заказа подтверждается только тогда, когда он нажимает на ссылку, которую ваш веб-сайт отправляет ему на его личную электронную почту.
Основным преимуществом этого варианта является то, что он почти полностью устраняет СПАМ и предоставляет вам действительно заинтересованную аудиторию (как вы знаете, рассматриваемый пользователь более «заинтересован», так как он предоставил вам свои данные и потратил время выполнить задание).
Однако есть несколько недостатков:
- Вам необходимо создать механизм в системе вашего веб-сайта, чтобы автоматически отправлять пользователю электронное письмо для подтверждения. Это будет означать значительные инвестиции в программное обеспечение для автоматизации маркетинга.

- Исследования показали, что количество регистраций может сократиться на 20 % по сравнению с однократной подпиской. Это связано с тем, что некоторым людям не нравится указывать свой личный адрес электронной почты, ИЛИ просто они просто забывают искать вашу ссылку, и она исчезает в их СПАМе, что немного иронично.
Поскольку вы рискуете потерять пятую часть своих пользователей из-за двойной подписки, мы предлагаем вам рассмотреть этот вариант только в том случае, если у вас есть фундаментальная потребность, такая как:
- Вы обрабатываете чрезвычайно конфиденциальные данные
- Вы сталкивались с проблемами доставки вашей базы данных в прошлом (т. е. были зарегистрированы как спам)
- Вы знаете, что являетесь потенциальной мишенью для злонамеренных действий — это отличный способ держать в страхе профессиональных спамеров и мошенников.
Метод Honeypot описывает способ кодирования полей веб-форм, которые невидимы для человеческого глаза, но которые боты обнаруживают и сразу же заполняют. Любые материалы, которые содержат эти поля как заполненные, перемещаются прямо в корзину.
Любые материалы, которые содержат эти поля как заполненные, перемещаются прямо в корзину.
Хотя это звучит как блестящее решение, у него есть ограничения.
Первый связан с автозаполнением браузеров. Если пользователь нажмет на автозаполнение, браузер все равно заполнит «невидимые» поля. Таким образом, некоторые материалы, отправленные людьми, будут перемещены прямо в корзину, и вы получите один — теперь очень недоволен — клиент.
Второе ограничение заключается в том, что, как и в случае с тестами Captcha, боты совершенствуют свои методы, чтобы они могли идентифицировать и игнорировать ловушки-приманки. Эффективность этого метода со временем будет снижаться, поскольку боты учатся замечать выбоины.
Тем не менее, метод по-прежнему обеспечивает некоторую степень защиты. Если вы против использования любой формы Captcha, это лучше, чем ничего.
Социальная регистрация Надежный способ перехитрить ботов — предложить регистрацию в социальных сетях. У ботов нет собственных учетных записей в социальных сетях или электронной почте!
У ботов нет собственных учетных записей в социальных сетях или электронной почте!
Интегрируясь со сторонними компаниями, в основном с такими компаниями, как Facebook, Instagram, Linked In, Twitter или Google и Microsoft, вы можете проверять человечность пользователей без необходимости повторного ввода ими своих личных данных.
В
есть огромное количество вариантов социального знака.0015
- Многие люди скрывают свои личные данные. Blue Research сообщает, что 86% людей обеспокоены необходимостью создавать новые учетные записи на веб-сайтах, а 54% могут покинуть сайт и перейти на другой вместо того, чтобы заполнять еще одну регистрационную форму
- еще один пароль для еще одного веб-сайта, а это означает, что они с большей вероятностью вернутся к вам снова, если ваш процесс будет способствовать простоте.
- Интеграция с социальными сетями упрощает «распространение», что может быть важно для компаний, которые ценят молву.
- Данные, которые пользователь уже предоставил этим каналам, проверены. Предполагая, что все правильные разрешения были установлены, вы должны получить блестящее качество данных для сбора в CRM при выборе этого метода.
Хотя мы являемся поклонниками социальных регистраций в правильном контексте, вам нужно помнить о нескольких вещах.
- Разница в возрастных группах . Данные социальной платформы LoginRadius показали, что только 11% пользователей в возрасте 50+ выбирают регистрацию в социальных сетях по сравнению с 38% пользователей в возрасте 18-25 лет. Если ваши продукты или услуги предназначены для пожилых людей, интеграция с социальными сетями может оказаться для вас неподходящим методом.
- B2B против B2C . Speero, эксперты CRO, отмечают, что уровень внедрения для предприятий B2B значительно ниже, чем для предприятий на рынке B2C, из-за того, что бизнес-пользователи неохотно делятся своими личными данными в этом контексте.
 Внимание к GDPR означает, что сотрудники более осторожно, чем когда-либо, предоставляют компаниям свои адреса электронной почты, поскольку они хотят свести к минимуму бесконечные сообщения о продажах. С другой стороны, предприятия B2C, похоже, получают выгоду от регистрации в социальных сетях, хотя мы рекомендуем также использовать регистрацию по электронной почте, чтобы максимизировать возможную аудиторию.
Внимание к GDPR означает, что сотрудники более осторожно, чем когда-либо, предоставляют компаниям свои адреса электронной почты, поскольку они хотят свести к минимуму бесконечные сообщения о продажах. С другой стороны, предприятия B2C, похоже, получают выгоду от регистрации в социальных сетях, хотя мы рекомендуем также использовать регистрацию по электронной почте, чтобы максимизировать возможную аудиторию.
Как видите, вопрос о том, следует ли вам использовать CAPTCHA в своих веб-формах, не так прост. Вам нужно установить, что будет лучше всего работать для обслуживания пользователей, посещающих вашу форму, сохраняя при этом коэффициент конверсии. Если вы видите, что подлинные регистрации форм падают с обрыва в момент введения CAPTCHA, вам нужно искать альтернативы. Передовая практика должна включать в себя опробование различных методов, а затем A/B-тестирование влияния на ваши коэффициенты конверсии с течением времени и с некоторыми изменениями здесь и там.
Если вам нужен совет о том, что вам делать дальше, свяжитесь с нами, мы будем рады помочь.
Для получения дополнительных рекомендаций по часто задаваемым вопросам о формах и важных советов ознакомьтесь со вторым разделом «Большого руководства Зуко по оптимизации форм и аналитике».



Об авторе