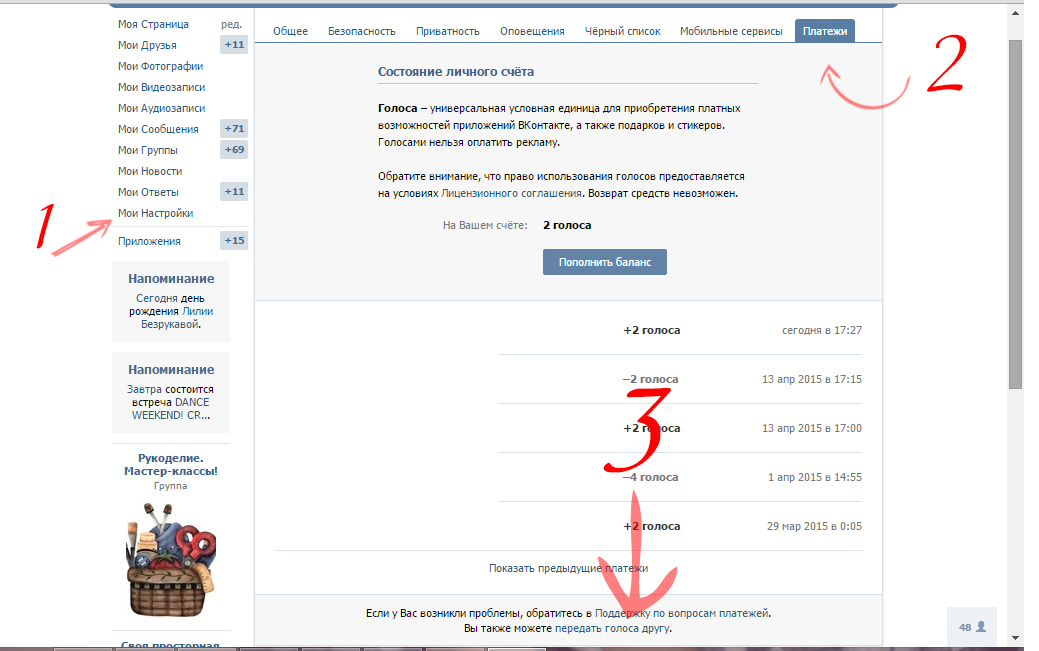
Можно ли перевести голоса вконтакте другому человеку: Ничего не найдено для Kak Perevesti Golosa V Vk%23I
Голосовой DeepFake, или Как работает технология клонирования голоса
Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
- Resemble.AI (предоставляется демоверсия программы).
- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning.
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.
С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется

- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS, создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных
train-other-500(извлеките какLibriSpeech/train-other-500). - VoxCeleb1: наборы данных
Dev A–D,в том числе набор метаданных (извлеките какVoxCeleb1/wavиVoxCeleb1/vox1_meta.csv). - VoxCeleb2: наборы данных
Dev A–H(извлеките какVoxCeleb2/dev).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как
LibriSpeech/train-clean-360 - LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr. org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
pip install audiodatasets
Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
- Librispeech (60 Гб)
- TEDLIUM_release2 (35 Гб)
- VCTK-Corpus (11 Гб)
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
- Корпус речи англоговорящих людей CSTR VCTK
- Набор данных M-AILABS: имеются примеры речи на русском, украинском, немецком, английском, испанском, итальянском, французском и польском языках
- Корпуса звучащей русской речи
- Мультимедийный корпус русского языка: преимущественно фрагменты кинофильмов с распознанным текстом
- Подборка различных речевых датасетов
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине.
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
pip3 install -r requirements.txt
Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
python3 demo_cli.py
Если все тесты пройдены (вы увидите строку All tests passed), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
python3 demo_toolbox.py
Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
python3 demo_toolbox.py -d <путь_к_директории_датасетов>
Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:
Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите
Чтобы услышать как звучит отрывок, просто нажмите Play. Для запуска алгоритма нажмите Synthesize and vocode. С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h.
Начинаем с подготовки данных для обучения кодера:
python3 encoder_preprocess.py <datasets_root>
Для обучения кодер использует окружение visdom.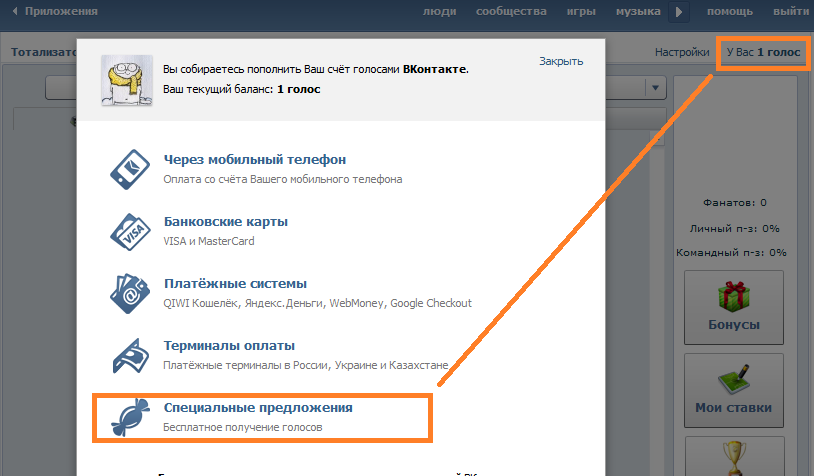 Инструменты окружения выглядят следующим образом:
Инструменты окружения выглядят следующим образом:
При необходимости вы можете отключить окружение с помощью аргумента --no_visdom .
Обучаем кодер:
python3 encoder_train.py my_run <datasets_root>
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py <datasets_root>
Затем вложения:
python3 synthesizer_preprocess_embeds.py <datasets_root>/synthesizer
Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run <datasets_root>/synthesizer
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py <datasets_root>
Наконец, обучаем вокодер:
python3 vocoder_train.py <datasets_root>
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Интересны ли вам проекты, связанные с дипфейками лиц и голоса? Будем рады вашим ответам в комментариях.
Фермы фейков. Схема развода через знакомства с фейковых женских страниц во «ВКонтакте» — Соцсети на vc.ru
Или как «нативно» получать клиентов на консалтинг в сфере инвестирования в IPO через ненавязчивые знакомства в сети.
148 133 просмотров
Возможно, вы получали эти сообщения, в стиле «Привет, давай пообщаемся…» со страницы незнакомой девушки из другого города. Всегда думал, что это какая-то схема развода, и сливал диалог.
Все случаи однотипные: девушка сообщает, что просто от скуки решила с кем-то пообщаться. Часто отправляют голосовые сообщения, чтобы было больше доверия. Обычно девушка с приличными и неброскими фото, никакого интима, что бы не отпугнуть явной фейковостью.
Часто отправляют голосовые сообщения, чтобы было больше доверия. Обычно девушка с приличными и неброскими фото, никакого интима, что бы не отпугнуть явной фейковостью.
На скринах ниже несколько таких переписок фейков со мной.
Я предполагал несколько вариантов развития событий:
- В процессе общения втираются в доверие и далее просят занять небольшую сумму на экстренную ситуацию.
- Доводят переписку до интима и далее шантажируют слить все вашей жене.
- Социальная инженерия, чтобы выяснить «девичью фамилию матери» и прочие данные, для доступа к вашим аккаунтам, если это имеет ценность.
Проходить этот «квест по общению» до конца всегда было лень, но иногда пытался раскрутить фейков на правду, и однажды это удалось 🙂
Ниже удачная переписка с «одной из них» в вк:
Получилось уговорить фэйка на интервью, им оказался парень из Украины.
Далее переходим в телегу, где наш герой раскрывает всю схему:
Кому лень читать скрины, вот краткое содержание:
- Есть целые офисы, в которых трудятся такие «менеджеры фейков», со штатом от 20 человек, как в колл-центре.
- Конкретно этот офис находится на Украине, таких офисов много в каждом городе.
- Часто от имени девушки пишет парень, но есть девушки для отправки голосовых сообщений.
- Выбирают «жертву» с предполагаемой финансовой достаточностью. Есть своя Ц/А, всем подряд не пишут.
- Каждый ведет по 30-40 диалогов в день.
- История у каждого фейка одна для всех, чтобы не путаться в «показаниях».
- Большинство людей удается развести.
- Предпочитают работать на западную аудиторию, там конверсия намного выше, но и РФ не забывают.

- Нейросети пока не используют, ведут диалог сами, без скриптов, но на обучении показывают удачные примеры.
- На каждую «жертву» дается до 5 дней, за это время нужно втереться в доверие.
- Кульминация: необходимо ненавязчиво сообщить о своем родственнике, который занимается инвестированием в сфере ipo, вызвать ваш интерес к хорошему и быстрому заработку и предложить вам связаться с ним для работы.
То есть основная задача — лидогенерация на услуги по инвестиционному консалтингу.
- Далее «лид» передается в компанию заказчика, а менеджер получает вознаграждение.
По сути таким образом можно привлекать лидов на практически любую сферу, странно, что работают в основном по инвестированию, скорее всего, хорошо платят за лида.
Даже скинул фото своего рабочего места:
«Есть плейстейшн, офис открыт круглосуточно, панорамный вид»
Собеседник уверял, что конкретно их компания не занимается мошенничеством и привлекает клиентов только на «белые» услуги, никакого кидалова.
Возможно так и есть, но нельзя исключать, что такой «менеджер» может сам не знать всей правды. И конечно же уверен, есть ряд таких же контор, которые занимаются именно разводом и кидаловом. Чего уж говорить о политических ботах, думаю там технологии куда серьезнее.
Преобразователь голоса | Speechify
Программное обеспечение для изменения голоса позволяет нам изменить то, как мы звучим. Он добавляет желаемые уровни искажений, играет с высотой тона и даже меняет тон нашего голоса. В наш век постоянного онлайн-взаимодействия такие приложения нужны так же, как и любые другие.
Изменить собственный голос при общении через смартфон или компьютер проще простого. Все, что вам нужно, это правильный плагин, и вы сможете изменить свою личность, возраст или, как ни странно, подражать кому-то, кого вы знаете.
Но зачем кому-то играть с голосовыми эффектами? Это просто для развлечения, или есть другие серьезные причины для нового голоса? Короче — и то, и другое.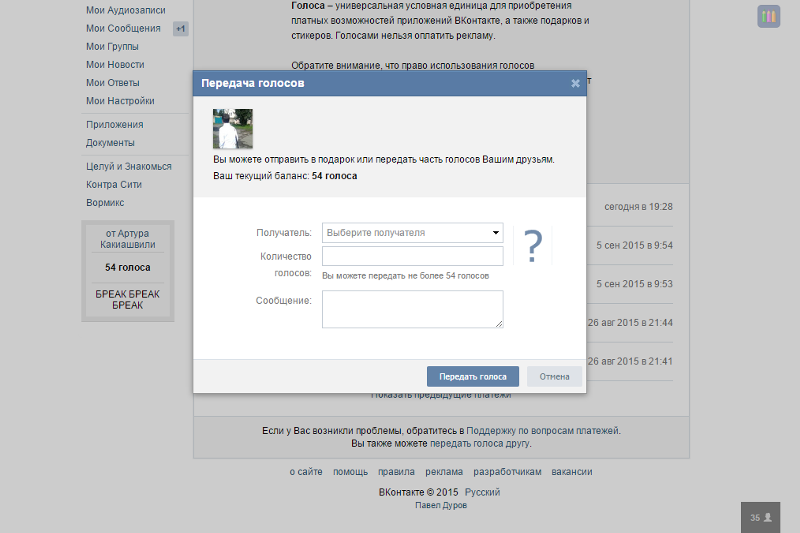 Однако не будем здесь забегать вперед. Позвольте нам объяснить все, что нужно знать о программах смены голоса, шаг за шагом.
Однако не будем здесь забегать вперед. Позвольте нам объяснить все, что нужно знать о программах смены голоса, шаг за шагом.
Преимущества использования устройства для изменения голоса
По сути, все, что мы используем в серьезных целях, имеет и более забавную сторону. То же самое касается программного обеспечения голосового редактора. Многие люди используют голосовые фильтры, чтобы шутить над Discord, играя в многопользовательские игры. Тем не менее, другие используют его для создания голоса за кадром для определенных ситуаций.
Тем не менее, нет неправильного способа использования голосовых модуляторов и звуковых эффектов. Все, что работает для вас, нормально, если за этим не стоит преступный умысел. Итак, давайте обсудим, как люди используют его для развлечения, а также для других целей.
Преобразователи голоса для развлечения и развлечения
Если вы геймер, вы, вероятно, уже зарегистрированы в Discord. Это отличная платформа для общения и сотрудничества во время игры в такие игры, как Fortnite. Тем не менее, почему только держать это в том, что? Почему бы не добавить немного веселья? Вот тут-то и появляются приложения для изменения голоса. С помощью такого программного обеспечения вы можете шутить со своими онлайн-приятелями, воспроизводя разные голоса.
Тем не менее, почему только держать это в том, что? Почему бы не добавить немного веселья? Вот тут-то и появляются приложения для изменения голоса. С помощью такого программного обеспечения вы можете шутить со своими онлайн-приятелями, воспроизводя разные голоса.
Скайп или использование Zoom с друзьями и родственниками — еще один пример, когда может быть полезно использование приложения для изменения голоса. Помимо веселья друг с другом, вы можете подшутить над ними. Изменение вашего голоса во время маскировки может превратить вас в настоящего хамелеона. Разумеется, это может быть неуместным способом шутить в зависимости от ситуации, поэтому вы всегда должны держать его на безопасном уровне.
С другой стороны, большинство программ для изменения голоса также могут работать с предварительно записанными аудиофайлами WAV. Вот почему он широко используется в индустрии развлечений. Будь то видео или музыка, вы можете создавать уникальные звучащие голоса и звуковые эффекты в соответствии с вашими потребностями. Это включает в себя изменение высоты тона, чтобы изменить звучание с мужского на женское и наоборот.
Это включает в себя изменение высоты тона, чтобы изменить звучание с мужского на женское и наоборот.
Изменители голоса для особых целей
Изменители голоса предназначены не только для развлечения и игр. Они могут играть более серьезную роль, если вы хотите создавать определенный контент. Например, многие люди, которые создают видео на YouTube или делают подкасты, используют такое программное обеспечение. На это может быть множество причин, но главная идея — оставаться анонимным в мире, который становится все более и более прозрачным.
Преобразователь голоса рекомендуется использовать при попытке избавиться от надоедливых абонентов, таких как продавцы. Большинство из них будут продолжать продвигать свой продукт, если поймут, что обращаются к пожилым людям или молодежи. Тем не менее, есть и злоумышленники. Помимо того, что вы сначала обратитесь в полицию, вы можете отбиться от них, записав глубокий голос.
Еще одна конкретная цель использования устройства смены голоса — это когда вы хотите задать определенные вопросы. Управляя своим голосом, вы можете узнать о конкурирующем бизнесе, заказать сомнительный продукт или даже расследовать мошенничество партнера. Таким образом, частные детективы обычно используют устройства для смены голоса при поиске информации.
Управляя своим голосом, вы можете узнать о конкурирующем бизнесе, заказать сомнительный продукт или даже расследовать мошенничество партнера. Таким образом, частные детективы обычно используют устройства для смены голоса при поиске информации.
Альтернативы программам для изменения голоса
Если вы хотите изменить свой голос без использования дорогостоящего программного обеспечения, вы всегда можете сделать это по-старому. Под этим мы подразумеваем речь через казу или подобный инструмент. К сожалению, это не лучший способ, так как может быть сложно говорить достаточно ясно, чтобы другие могли понять. Вместо этого это может стать комичным и раздражающим.
Другой альтернативой является использование удаленного устройства для изменения голоса. А именно, вы просто помещаете его между ртом и микрофоном, и он будет управлять вашим голосом в режиме реального времени. Тем не менее, эти устройства довольно примитивны с точки зрения возможностей, которые они предоставляют своим пользователям. Большинство из них могут только добавить искажения, поэтому вы будете звучать довольно зловеще, даже если это не входит в ваши намерения.
Большинство из них могут только добавить искажения, поэтому вы будете звучать довольно зловеще, даже если это не входит в ваши намерения.
К счастью, существуют альтернативные программы для изменения голоса. Наиболее распространенными являются приложения для преобразования текста в речь (TTS), такие как Speechify. Хотя их первоначальная цель не состоит в том, чтобы изменить голос, они все же могут делать это с большим эффектом. Это особенно верно, если вы ищете полностью уникальный звук, который никоим образом не будет похож на ваш голос.
Идея программного обеспечения TTS заключается в том, чтобы напечатать то, что вы хотите сказать, и приложение распознает это и использует искусственный интеллект (ИИ), чтобы превратить это в речь. Впрочем, это только его основная цель. Большинство этих приложений имеют различные пресеты, которые напоминают разные типы голосов. От мужских и женских до глубоких и высоких, до молодых и старых, существует большое разнообразие. Можно использовать даже голоса знаменитостей!
Speechify — преобразование текста в речь
Не секрет, что существует множество инструментов TTS.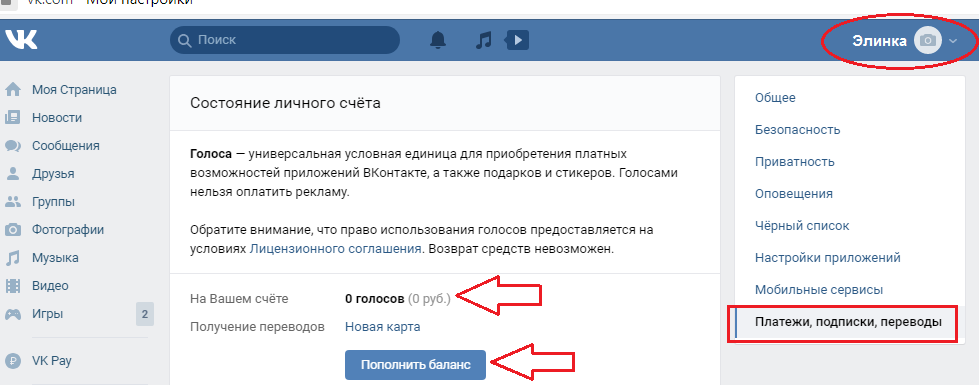 Однако не многие из них предлагают такие же результаты и множество опций, как Speechify. Это программное обеспечение на основе OCR, которое использует как искусственный интеллект, так и машинное обучение для преобразования того, что вы пишете или печатаете, в речь.
Однако не многие из них предлагают такие же результаты и множество опций, как Speechify. Это программное обеспечение на основе OCR, которое использует как искусственный интеллект, так и машинное обучение для преобразования того, что вы пишете или печатаете, в речь.
Что отличает его от других инструментов TTS, так это то, что вы можете использовать его разными способами. Speechify доступен на смартфонах (как iOS, так и Android), а также на компьютерах Mac и Windows. В любом случае Speechify распознает символы и прочитает их вам.
Когда дело доходит до использования Speechify для голосовых эффектов, это может быть даже проще, чем использование реального программного обеспечения для управления голосом. Все, что вам нужно сделать, это ввести то, что вы хотите сказать, и инструмент превратит это в речь, используя искусственный голос.
Вы можете поиграть с тоном, выбрать различные пресеты и отрегулировать скорость речи, что даже может заставить текст звучать так, как будто его читает бурундук. Но это не все! Speechify также позволяет делать фотографии текста, а OCR также превращает написанные слова в речь. Это может быть отличным вариантом, если вы хотите процитировать отсылки к фильмам или играм, подходящие для случая.
Но это не все! Speechify также позволяет делать фотографии текста, а OCR также превращает написанные слова в речь. Это может быть отличным вариантом, если вы хотите процитировать отсылки к фильмам или играм, подходящие для случая.
В общем, Speechify, вероятно, лучший инструмент для преобразования текста в речь на данный момент. Несмотря на множество альтернатив, его универсальность выделяет его из толпы. Благодаря многочисленным голосовым опциям он может подойти любому, кто хочет быстро изменить свой голос — и все это независимо от того, идет ли речь о развлечениях и развлечениях или о чем-то более серьезном.
Часто задаваемые вопросы
Какие программы для изменения голоса самые лучшие?
В Интернете есть множество высококачественных программ с функцией изменения голоса. Первое, что приходит на ум, это определенно Мерф. Благодаря функции аудиоредактора Murf может помочь вам устранить фоновые эффекты и шумы, сделав ваш голос профессиональным.
Отдельно стоит упомянуть Adobe Audition. Как и другие их продукты, Adobe Audition — это высококачественный голосовой редактор. Он может изменить практически любую характеристику вашего голоса, что делает его подходящим как для игр, записи подкастов, так и для имитации популярных персонажей.
Как и другие их продукты, Adobe Audition — это высококачественный голосовой редактор. Он может изменить практически любую характеристику вашего голоса, что делает его подходящим как для игр, записи подкастов, так и для имитации популярных персонажей.
Конечно, вы всегда можете использовать лучшее приложение для преобразования текста в речь, Speechify, как простой способ преобразовать любой текст, который вы хотите напечатать или написать, в реалистичную речь за считанные секунды.
Как я могу получить бесплатный преобразователь голоса?
Если у вас нет средств на покупку профессионального приложения для изменения голоса, вы всегда можете использовать бесплатное программное обеспечение для создания собственного голоса. Конечно, они не предложат каких-то расширенных опций, но они могут выполнить работу для большинства людей.
Лучший бесплатный преобразователь голоса в реальном времени, безусловно, Voicemod. Это приложение популярно среди любителей онлайн-игр, поскольку оно совместимо с Twitch и Discord. Кроме того, Voicemod имеет простую в использовании звуковую панель, которая позволяет добавлять многочисленные звуковые эффекты без необходимости предварительно просматривать часовое руководство.
Кроме того, Voicemod имеет простую в использовании звуковую панель, которая позволяет добавлять многочисленные звуковые эффекты без необходимости предварительно просматривать часовое руководство.
Voicemod также является фаворитом из-за низкой загрузки ЦП. Это главная проблема для геймеров, поскольку игра в требовательную игру с помощью такой программы запуска, как Steam, может привести к падению частоты кадров, что повлияет на производительность.
Лучший бесплатный вариант преобразования текста в речь для ваших потребностей в изменении голоса — это Speechify! Также доступна премиум-версия с еще более невероятными функциями.
Какой самый реалистичный преобразователь голоса?
Вот лучшие устройства для изменения голоса в реальном времени, которые вы можете использовать, чтобы троллить своих друзей, как босс.
- Голосмод
- Устройство смены голоса NCH Voxal
- МорфВокс Младший
- Программное обеспечение для изменения голоса AV Diamond
- Устройство для изменения голоса рыбы-клоуна
Конечно, мы не можем не упомянуть очень естественно звучащие голоса Speechify как приложения для преобразования текста в речь.
ВКонтакте запустили голосовые и видеозвонки со сквозным шифрованием
Дата: 30.04.18
Чтобы активировать функцию, вам должен позвонить один из ваших друзей.
В приложениях «ВКонтакте» для iOS и Android появилась функция голосовых и видеозвонков. Как уточнили в соцсети, звонки защищены сквозным шифрованием, при котором ключи известны только общающимся пользователям.
При сквозном шифровании невозможна передача «никаких ключей» и доступ к информации третьих лиц «технически невозможен», заверили «ВКонтакте».
Первый раз активация функции будет передана звонком от того, кто уже был активирован.
Эта функция доступна только для пользователей последних версий приложений. Остальные будут уведомлены при попытке входящего вызова.
Чтобы позвонить, нужно нажать кнопку вызова в правом верхнем углу диалога. На видео можно переключаться во время разговора.

Об авторе