Парсер групп онлайн: парсер групп ВКонтакте. Эффективная таргетированная реклама.
Парсер групп вконтакте онлайн бесплатно
Среди огромного набора парсеров (специальных инструментов) нашего Сервиса вы можете воспользоваться и таким: “Парсер групп ВКонтакте”, причем сделать это вы можете в режиме онлайн и работать для вас парсеры будут и бесплатно (Классический поиск групп).
Запустите ссылку, расположенную ниже, если вам нужен парсер групп вконтакте онлайн бесплатно.
Выбирайте нужный вам парсер и укажите ваши настройки для поиска групп ВКонтакте, включая ключевое слово, Гео-данные и прочие предложенные разработчиками нюансы настройки.
Запустите парсер в работу, работая на наших серверах в облаке, он соберет группы ВКонтакте по указанным параметрам.
Классический поиск групп будет парсить сообщества ВК бесплатно (до 1000 результатов в отчете).
Чтобы отфильтровать собранные групп ВКонтакте по определенным критериям, воспользуйтесь парсером “Фильтр групп по их данным” https://vk.barkov.net/groupsfilter.aspx
Указывайте параметры для фильтрации, а парсер оставит в финале лишь группы ВКонтакте с вашими настройками.
Подписчиков групп ВК вы соберете парсером “Все подписчики групп” https://vk.barkov.net/members.aspx
Или собирайте подписчиков групп ВКонтакте по пересечениям https://vk.barkov.net/cross.aspx
Запустить скрипт для решения вопроса
Полезный небольшой видеоурок по этой теме
О сервисе поиска аудитории ВКонтакте
vk.barkov.net — это универсальный набор инструментов, который собирает самые разнообразные данные из ВКонтакте в удобном виде.
Каждый инструмент (скрипт) решает свою задачу:
Например, есть скрипт для получения списка всех подписчиков группы.
А вот тут лежит скрипт для сбора списка всех людей, поставивших лайк или сделавших репост к конкретному посту на стене или к любым постам на стене.
Ещё есть скрипт для получения списка аккаунтов в других соцсетях подписчиков группы ВКонтакте.
И таких скриптов уже более 200.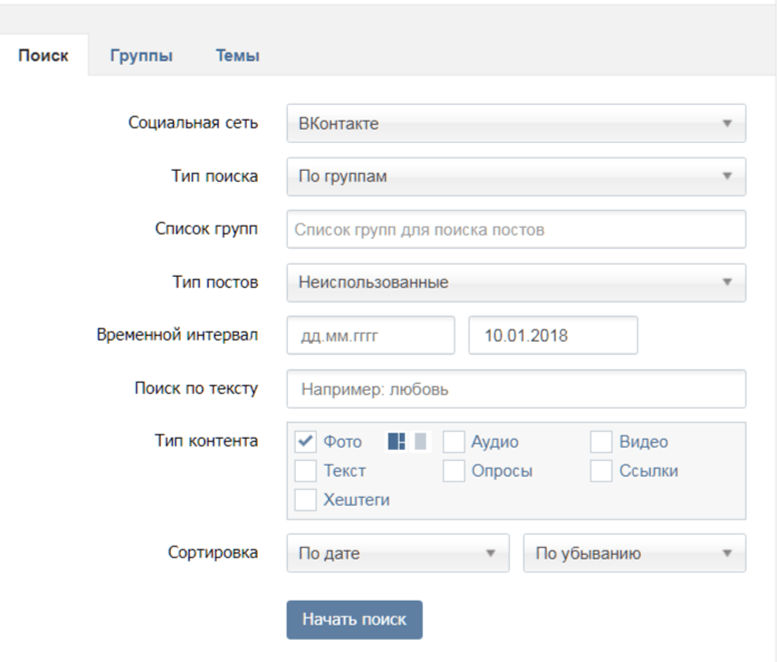 Все они перечислены в меню слева. И мы регулярно добавляем новые скрипты по запросам пользователей.
Все они перечислены в меню слева. И мы регулярно добавляем новые скрипты по запросам пользователей.
Запустить скрипт для решения вопроса
Полезные ответы на вопросы по этому же функционалу для сбора данных из ВКонтакте
Найти группы ВКонтакте по тематике по ключевым словам «фото» и «студия»
Поиск групп ВК по нескольким ключевым словам
Собрать ВКонтакте целевую аудиторию родителей для предложения детского лагеря
Где ВКонтакте найти клиентов для автошколы?
Собрать ВК Группы — Подписчики групп
Тематический поиск групп по ВКонтакте
Спарсить только активные паблики, где можно оставлять комментарии
Собрать целевую аудиторию для продвижения товара ВКонтакте
Поиск групп по тематикам ВК
Поиск групп VK по городам конкретной страны
Парсер групп вк онлайн
Парсинг групп на открытую стену ВКонтакте
Как собрать все группы ВКонтакте с конкретным названием?
Найти список сообществ ВКонтакте по ключевому слову и по другим критериям по определенным городам
Спарсить ВКонтакте группы с открытой стеной
Как собирая группы ВКонтакте, скрывать закрытые группы?
ВК группы поиск
Поиск группы вк
Как набрать целевую аудиторию в группу вконтакте
Парсинг групп ВК по городу
парсинг, минусация, группировка — Сервисы на vc.
 ru
ruДобрый день, в данной статье расскажу как можно быстро и комфортно работать с семантическим ядром онлайн.
816 просмотров
Сперва давайте перечислим необходимый функционал для сбора ядра:
- Семантическая карта
- Парсер Wordstat(РФ) или Keyword Planner(бурж)
- Расширение ядра
- Минусация. Сбор списка минус-слов
- Группировка семантики
Вот эти все моменты и обсудим в этой статье. Приятного чтения 🙂
Сбор семантической карты
Зачем она вообще нужна?
В целом, для того чтобы ничего не упустить и найти ряд «неочевидных» запросов при помощи работы с синонимами/ассоциациями. Т. е. прежде чем собирать запросы для парсинга — собирают так называемую семантическую карту. Которая представляет собой наборы групп слов, которые в дальнейшем перемножают друг с другом получая «фразы для парсинга».
Функционал сервиса позволяет:
1. Создавать группы слов с многоступенчатой вложенностью друг в друга
2. По клику на слово отправлять его в нужную группу слов
3. Перемножать группы слов друг на друга с получением фраз и добавлением их в сегмент
4. Сохранять за сегментом нужный набор групп слов и автоматически создавать из них фраз при новом добавлении в них слов
Т.е. самое главное это максимально полно собрать всю возможную семантику, а для этого нужно проработать все-все возможные ключевые слова. Так как чем менее очевиден запрос, тем с более высокой вероятностью для него будет дешевая ставка, так как будет меньше конкуренции.
Сбор основных «верхних масок» для парсинга
Если мы работаем через семантическую карту, то при сборе запросов для парсинга (масок) сперва их разбиваем на слова и записываем слова в столбики, формируя таким образом семантическую карту.
Обычно ее собирают в Xmind, но мы внедрили этот функционал и теперь не нужно пользоваться 100500 сервисами при проработке ядра.
Справа получается есть встроенные однословные парсеры из которых можно получать нужные нам ключевые слова:
1. По ключевым словам: Вордстат, Keyword Planner, Букварикс, СЕО, Подстказки
2. По домену: Мастер Кампаний(Я.Директ), Keyword Planner, Букварикс, СЕО
При помощи данных парсеров можно на одной странице удобно прорабатывать семантическую карту:
1. Добавлять слова в группы слов сем. карты
2. Добавлять запросы в сегменты
3. Добавлять слова в список минус-слов
К тому же, очень крутым решением стало внедрение еще парсеров Синонимов и Ассоциаций
Синонимы хороши для проработки похожих слов, как еще ЦА будет искать наш товар/услугу.Ассоциации хороши для проработки и поиска новых ЦА, идей болей и воронок.
После того как семантическая карта проработана нужно перемножить слова с получением фраз.
Парсер Wordstat(РФ) или Keyword Planner(бурж)
Постарался сделать все очень просто и одновременно функционально:
- не нужны акки, прокси, капча — все предоставляется сервисом
- от вас нужны только ключевые слова — все, остальное берет на себя система
По скорости парсинга 1 потока (а их можно покупать несколько):
- Yandex Wordstat:
1. сбора фраз — около 500 запросов/час;2. снятия частоты — около 15к запросов/час
сбора фраз — около 500 запросов/час;2. снятия частоты — около 15к запросов/час
- Keyword Planner
1. сбора фраз — около 2к запросов/час;2. снятия частоты — около 2к запросов/час
Парсинг фраз
Можно парсить сразу в несколько сегментов:
1. сперва нажмите в шапке на раздел “Прасеры”
2. добавьте запросы для парсинга в один или несколько сегментов
3. выберите ГЕО и запустите парсинг
Из приятных фич — парсинг для Вордстата поддерживает режим «маска +1 слово».
Снятие частоты
Что бы запустить парсер снятия частоты, нужно добавить фразы в сегмент в котором хотите снять частоту, и далее:
1. сперва нажмите в шапке на раздел “Прасеры”
2. выберите раздел “снятие частоты”
3. выберите один или несколько сегментов
4. выберите ГЕО и запустите парсинг
Ну все! Самый сложный этап завершен — вы молодцы, стоит наградить себя чашечкой чая и немного разгрузить голову пока будет идти парсинг.
Расширение семантики
После того как парсинг завершен, но нам все мало запросов, можно попробовать расширить семантику при помощи баз ключевых слов.
Я обычно использую для этого Букварикс. База на 20 июня 2022 г. насчитывает около 2 млрд. 126 млн. ключевых словЭто огромный источник данных. Используется для расширения уже собранного семантического ядра, а так же поиска пропущенных запросов, новых масок, нестандартных идей, не охваченных ЦА.
Отмечу — база довольно грязная! И с ней нужно уметь правильно работать.Из-за того, что вам могут возвращаться 100-ни тысяч запросов следите за лимитами ядра, чтобы все фразы влезли.
Минусация. Сбор списка минус-слов
Ну и мы уже на финишной прямой. Осталось только отминусовать и разгруппировать собранные запросы.
Для этого открываем группиратор и начинаем собирать списки минус-фраз параллельно удаляя все запросы где содержатся эти слова.
Данный процесс при больших объемах не быстрый и довольно монотонный, нужно запостись терпением.
Группировка семантики
Как вся семантика почищена — приступаем к ее сегментации.
Находим ключевые точки разделения фраз, обычно это запросы для которых мы будем использовать разные офферы в объявлениях. И по этому нехитрому признаку быстренько делим наши запросы по сегментам.
Готово!
Вот и вся магия 🙂
Чем более полно вы проработаете семантику, чем лучше вы ее очистите и логичнее разгруппируете — тем лучше будут показатели вашей рекламной кампании.
На этом все! Ссылка на сервис — shinta.ru
Успехов
Платформа Parse
Помощь и связь
Наши предпочтительные каналы связи для помощи, проблем и обсуждений.
Тег parse-platform переполнения стека Используйте для любых вопросов на уровне кода, связанных с платформой Parse. При необходимости используйте и другие теги, такие как parse-server, parse-dashboard, parse-cloud-code, parse-javascript-sdk, parse-ios-sdk, parse-android-sdk, parse-dotnet-sdk, parse- rest-api и parse-live-query. |
Форум сообществаИспользуйте для вопросов и обсуждений на высоком уровне о платформе Parse. |
Проблемы с GithubИспользуйте для сообщения об ошибках и создания запросов на включение для определенных репозиториев. |
Сервер синтаксического анализа и панель мониторинга
Сервер REST и панель инструментов для управления вашими данными.
Документация
Узнайте больше о развертывании собственного сервера Parse или ознакомьтесь с нашими подробными руководствами по SDK для клиентов.
SDK и библиотеки
Версии наших SDK с открытым исходным кодом с соответствующими ссылками, чтобы узнать больше.
Объектив-C
Справочник API
Последняя версия
Андроид
Направляющая
Справочник API
Последняя версия
JavaScript
Направляющая
Справочник API
Последняя версия
Руководство
Справочник API
Последняя версия
Флаттер
Направляющая
Справочник API
Последняя версия
Направляющая
Справочник API
Направляющая
Справочник API
Последняя версия
.
 NET + Xamarin
NET + XamarinНаправляющая
Справочник API
Последняя версия
Направляющая
Справочник по API
Последняя версия
Ардуино
Направляющая
Справочник API
Последняя версия
Встроенный C
Направляющая
Справочник по API
Последняя версияСерверные адаптеры синтаксического анализа
Официальные адаптеры для Parse Server.
Другие полезные репозитории
Список полезных инструментов, библиотек и прочих полезных вещей, которые вам помогут.

Docparser — Программное обеспечение для анализа документов
Извлечение важных данных из файлов Word, PDF и изображений. Отправляйте в Excel, Google Таблицы и сотни других форматов и интеграций.
Кредитная карта не требуется
Docparser идентифицирует и извлекает данные из документов Word, PDF и документов на основе изображений, используя технологию зонального оптического распознавания символов, расширенное распознавание образов и помощь ключевых слов-привязок. Чтобы настроить анализатор документов , нужно выполнить 3 этапа.
Загрузка/импорт документа
Загрузите документ напрямую, подключитесь к облачному хранилищу (Dropbox, Box, Google Drive, OneDrive), отправьте файлы по электронной почте в виде вложений или используйте REST API.
Определить правила
Обучить Docparser извлекать нужные данные без кодирования. Выберите предустановленные правила, характерные для вашего документа PDF или изображения, используя параметры, соответствующие типу вашего документа.
Загрузка/экспорт данных
Загружайте данные напрямую в форматы Excel, CSV, JSON или XML или подключайте Docparser к тысячам облачных приложений, таких как Zapier, Workato, MS Power Automate и другим.
Выберите один из шаблонов правил Docparser или создайте свои собственные правила для документов.
Счета-фактуры
Извлеките важные данные счетов, затем интегрируйте их с вашей системой учета или загрузите в виде электронной таблицы. Извлеките данные, такие как ссылочный номер, даты, итоги или позиции.
Заказы на покупку
Извлеките данные заказа на покупку и переместите их непосредственно в вашу систему управления заказами, систему учета или любую конечную точку по вашему выбору.
Банковские выписки
Преобразование кредитных карт и банковских выписок в электронные таблицы, такие как Excel, или другой формат для вашей системы учета.
Контракты и соглашения
Извлечение повторяющихся данных из всех типов юридических соглашений, таких как договоры аренды и лизинга, гарантийные и страховые соглашения или договоры на основе формы.
HR Forms & Applications
Легко извлекайте данные HR-форм, таких как регистрационные формы, формы заявлений, отчеты, формы обратной связи, платежные ведомости или любые другие документы, связанные с HR, и преобразовывайте их в удобный формат по вашему выбору.
Заказы на отгрузку и накладные о доставке
Для обычных магазинов, предприятий прямой поставки или чего-либо еще автоматизируйте обработку ваших накладных и накладных, включая штрих-коды и QR-коды.
Список продуктов и прайс-листов
Извлекайте таблицы из списков продуктов в формате PDF и вводите их в кассу, на сайт электронной коммерции или даже в Excel. Даже синтаксический анализ отсканированных документов упрощается благодаря встроенной функции OCR PDF Scanner.
Зональный ОКР
Перетащите прямоугольник, чтобы выделить область данных, которую вы хотите выделить.
Извлечение данных таблицы
Определение строк/столбцов путем перетаскивания разделителей столбцов на место.
Предварительная обработка отсканированного изображения
Выравнивание изображений, удаление артефактов сканирования и других дефектов изображения.
Флажки и радиокнопки
Ответы данных формы распознаются и извлекаются ответы.
Выбор штрих-кода и QR-кода
Обработка штрих-кода и QR-кода с помощью встроенного сканера.
Финансы и бухгалтерский учет
Деловые документы
Создайте свой собственный
Финансы и бухгалтерский учет
Деловые документы
Создайте свой собственный
Кредитная карта не требуется
Что говорят наши довольные клиенты
Отличное решение для копирования и вставки PDF ☺ Это работает очень просто и удобно. Действительно хорошее решение для копирования файлов из PDF в файл Excel.
☹Вы не можете загрузить более 30 страниц. Таким образом, вам нужно разрезать PDF-файл на части, а затем загрузить вырезанный PDF-файл отдельно.
Отлично и экономит время Мы вдвое сократили время ввода информации, извлекая только необходимую информацию, поэтому нам не нужно открывать и читать PDF-файл. ☺Возможность поиска маркера для извлечения данных после него ☹ Функция уточнения поиска поначалу немного сбивала с толку, но немного поэкспериментировав с ней, я освоился.
Работает только в особых случаях Иногда это немного сложно использовать, но это экономит время, когда дело доходит до ввода больших документов. Также вам необходимо подумать, стоит ли вводить некоторую информацию с помощью программного обеспечения, потому что иногда загрузка может занять больше времени, чем ввод вручную. ☺ Это действительно помогает, когда нужно ввести большое количество информации для документа. ☹В некоторых документах это работает не очень хорошо, а иногда создание нового шаблона немного раздражает. но как только у вас есть это действительно полезно
Он делает то, что мне нужно ☺
Продукт работает и стабилен. Как только вы начнете использовать его, легко настроить новые документы. Мы сканируем ряд документов, и с помощью программы у нас есть возможность масштабировать процессы, которые в противном случае выполнялись бы вручную.
☹ Ничего.
Как только вы начнете использовать его, легко настроить новые документы. Мы сканируем ряд документов, и с помощью программы у нас есть возможность масштабировать процессы, которые в противном случае выполнялись бы вручную.
☹ Ничего.
Лучший инструмент для структурирования данных из входящих документов ☺ Очень прост в настройке и использовании. Сверхточный поиск данных в разных форматах документов, даже если они не всегда находятся в одном и том же месте каждый раз. Лучше всего иметь возможность получить информацию в удобном для использования формате, чтобы затем обработать ее так, как вам нравится. ☹Было бы здорово увидеть, что OCR может обрабатывать письменные ответы и некоторые дополнительные интеграции с продуктами Office
Этот продукт избавляет от необходимости выполнять черную работу Мне это нравится, потому что он делает то, чего не может Mailparser.
☺Автоматизация, потому что она экономит нам массу времени.
☹Иногда вебхуки не всегда работают с моей целевой программой.
Обзор Докпарсера ☺Простота использования и интеграции с существующим программным обеспечением ☹Немного дороже, но стоит своих денег, если вы используете его для экономии времени
Docparser экономит моей команде сотни часов и помогает выявить новые возможности для бизнеса Каждый месяц моя команда получала более 700 страниц отчета в формате PDF с обновлениями статуса проекта. Каждая страница была отдельным проектом. Некоторые из них были старыми проектами и не представляли интереса. Некоторые из них были проектами, над которыми мы уже работали, и их нужно было отслеживать. Некоторые из них были новыми проектами, с которыми нам нужно было работать. Поиск и разделение этого документа вручную было неэффективным, и мы упускали важные проекты. Я начал искать решения, от скриптов Python до PowerQuery и программных пакетов/сервисов. Посмотрел несколько компаний, в том числе и Docparser. Я посещал вебинары и имел демонстрации. Опробовав бесплатный уровень нашего Docparser с некоторыми образцами документов, я понял, что он может делать именно то, что мне нужно. Мне немного помогла служба поддержки пользователей, и теперь я усовершенствовал свои правила синтаксического анализа. Поэтому каждый месяц, когда выходит более 700 страниц PDF, я могу извлечь информацию, которая нужна моей команде, и экспортировать ее в Excel. Мы экономим сотни часов разочарования и не пропускаем ничего важного.
☺Очень легко настроить благодаря полезным руководствам. Я смог «протестировать» программное обеспечение, используя уровень бесплатного пользования, чтобы убедиться, что оно может производить ТОЧНО то, что я хотел. Это было огромной помощью для оценки по сравнению с другими продуктами и принятия решения. Теперь, когда у меня настроены правила синтаксического анализа, очень легко запускать мой большой отчет раз в месяц и распространять его среди моей команды.
☹ Немного обучения, чтобы правильно настроить правила синтаксического анализа. Мне нужно было посетить их справочный вебинар, чтобы понять, что я делаю неправильно (но потом мне очень помогли).
Мне немного помогла служба поддержки пользователей, и теперь я усовершенствовал свои правила синтаксического анализа. Поэтому каждый месяц, когда выходит более 700 страниц PDF, я могу извлечь информацию, которая нужна моей команде, и экспортировать ее в Excel. Мы экономим сотни часов разочарования и не пропускаем ничего важного.
☺Очень легко настроить благодаря полезным руководствам. Я смог «протестировать» программное обеспечение, используя уровень бесплатного пользования, чтобы убедиться, что оно может производить ТОЧНО то, что я хотел. Это было огромной помощью для оценки по сравнению с другими продуктами и принятия решения. Теперь, когда у меня настроены правила синтаксического анализа, очень легко запускать мой большой отчет раз в месяц и распространять его среди моей команды.
☹ Немного обучения, чтобы правильно настроить правила синтаксического анализа. Мне нужно было посетить их справочный вебинар, чтобы понять, что я делаю неправильно (но потом мне очень помогли).
Docparser помогает Docparser сделал возможным автоматизировать ряд повторяющихся действий человека ☺Простота в использовании и внедрении в собственное программное обеспечение ☹Удобство использования и простой режим масштабирования
Отличная платформа ☺Нам больше не нужно вводить каждый счет в нашу бизнес-систему.

Об авторе