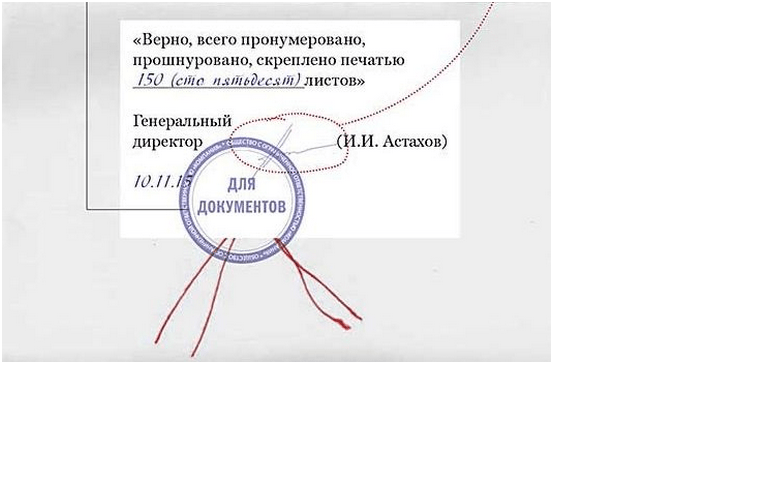
Прошитый документ: в 2, в 3, в 4 и в 5 дырок (проколов)
Сканирование | МобиПринт — типография, копировальный центр, студия графического дизайна
Ниже таблично представлена стоимость сканирования листовой печати А4, А3. Для заказа сканирования через сайт, пожалуйста, воспользуйтесь онлайн-формой, расположенной ранее, либо любым удобным для Вас способом связи. Для получения 10% скидки, пожалуйста, сообщите сотруднику промо-код «Интернет-цена». Обращаем внимание, что скидка применяется только в момент оформления заказа.
«Через автоподатчик» — листовое сканирование стопки документов через автоподатчик, самый быстрый и экономичный способ сканирования документов в стопке. Применяется в случае, если исходная стопка документов не содержит замятий, порванных элементов, жировых следов, скоб, скрепок и пр., т.е. в случае, когда листы беспрепятственно могут проходить через ролики автозахвата сканера.
«Листовое со стекла» — листовое сканирование стопки документов со стекла сканера, простое полистовое сканирование вручную (через сканер ручной подачи документов) раздельных листов в стопке. Это самый распространённый способ сканирования документов.
Это самый распространённый способ сканирования документов.
«Прошитый стандарт (паспорт, журнал)» — прошитые документы в разворотах, сканирование вручную (через сканер ручной подачи) документов, скреплённых на скобу, пружину и пр., например, паспорт, брошюра, книга. В случае, если сканируются паспорта, брошюры или книги, то результат сохраняется в разворотах. В случае, если листы документа удобно переворачиваются (соединены на пружину), то результат сохраняется постранично.
«Прошитый на нить, ветхий документ» — сложное сканирование прошитых вручную документов, скреплённых на нить или скобу, но неудобным для сканирования способом. Чаще всего это толстые нотариально заверенные документы, либо ветхие экземпляры, требующие приладки при сканировании. Результат может быть представлен как в разворотах, так и постранично.
Стоимость сканирования формат А4
| Тираж | Через автоподатчик | Листовое со стекла | Прошитый стандарт (паспорт, журнал) | Прошитый на нить, ветхий документ |
|---|---|---|---|---|
| 1 — 20 | 15 | 30 | 30 | 50 |
| 21 — 50 | 14 | 27 | 30 | 45 |
| 51 — 100 | 13 | 25 | 30 | 40 |
| 101 — 200 | 12 | 23 | 30 | 35 |
| 201 — 300 | 10 | 20 | 30 | 34 |
| 301 — 400 | 9 | 17 | 30 | 33 |
| 401 — 500 | 8 | 15 | 30 | 32 |
| 501 — 1000 | 7 | 13 | 30 | 31 |
| >1000 | 6 | 12 | 30 | 30 |
Стоимость сканирования формат А3
| Тираж | Через автоподатчик | Листовое со стекла | Прошитый стандарт (паспорт, журнал) | Прошитый на нить, ветхий документ |
|---|---|---|---|---|
| 1 — 20 | 20 | 39 | 39 | 65 |
| 21 — 50 | 18 | 35 | 39 | 59 |
| 51 — 100 | 17 | 33 | 39 | 52 |
| 101 — 200 | 16 | 30 | 39 | 46 |
| 201 — 300 | 13 | 26 | 39 | 45 |
| 301 — 400 | 12 | 22 | 39 | 43 |
| 401 — 500 | 11 | 20 | 39 | 42 |
| 501 — 1000 | 9 | 17 | 39 | 41 |
| >1000 | 8 | 16 | 39 | 39 |
Сканирование книг и сшитых документов
Оставить заявку
Копировальный центр и типография Scanmasters – современное предприятие, предлагающее широкий спектр полиграфических услуг, включая сканирование, печать и копирование документации, создание электронных архивов, брошюровка и многие другие.
Телефон: +7 (499) 397-72-55, +7 (925) 789-37-87, +7 (925) 451-22-69
Почта: [email protected]
Автор
Scanmasters
Время на чтение
5 мин.
Просмотров
134
Опубликовано
27.04.2022
Содержание
Прокрутите вниз
Сегодня копировальными центрами и типографиями предоставляется множество различных услуг, среди которых сканирование всевозможных документов, чертежей, фотоизображений, книг и др. Такой вид печатных материалов как сброшюрованные документы в виде книг, журналов, карточных сшивок, сшитых и нотариально заверенных документов, сшитых томов уголовных дел и тому подобного являются одним из наиболее сложных объектов для сканирования. На то, что такой документ невозможно расшить указывает ценность самой брошюровки, например, в случае исторических документов или редких книг либо его юридическая значимость (в случае нотариальных или уголовных документов). В таком случае необходимо использовать специальную технику с которой в состоянии справится только высококвалифицированные специалисты. В зависимости от того, какое оборудование используется и какое выходное качество документа необходимо, скорость при которой будет сканироваться один разворот сшитого документа может исчисляться в секундах, а иногда и в десятках секунд. При необходимости сканирования большого количества или других документов, для которых не предусмотрена расшивка, а также в зависимости от их формата, как правило, используются книжные сканеры. Книжные сканеры обеспечивают возможность держать книгу раскрытой кверху и при этом с возможностью перелистывания страниц в процессе сканирования.
В таком случае необходимо использовать специальную технику с которой в состоянии справится только высококвалифицированные специалисты. В зависимости от того, какое оборудование используется и какое выходное качество документа необходимо, скорость при которой будет сканироваться один разворот сшитого документа может исчисляться в секундах, а иногда и в десятках секунд. При необходимости сканирования большого количества или других документов, для которых не предусмотрена расшивка, а также в зависимости от их формата, как правило, используются книжные сканеры. Книжные сканеры обеспечивают возможность держать книгу раскрытой кверху и при этом с возможностью перелистывания страниц в процессе сканирования.
Сегодня на рынке существует целый ряд специализированных сканирующих устройств, предназначенных для сканирования книг и сброшюрованных документов (сканирование документов) от различных производителей. Книжные сканеры по типу и механизму сканирования можно разделить на три вида: Классические сканеры (с горизонтальным предметным столом, с книжной колыбелью или без нее, с камерой, имеющей отличную оптику и высокое разрешение). Варианты сканеров, которые основаны на традиционных цифровых фотоаппаратах (имеющие специализированные штативы с V-образным или плоским предметным столом, а также с прижимным стеклом или без него). Другие устройства в виде ручных сканеров типа C-pen Docupen, специализированных планшетных сканеров типа Plustek OpticBook, планшетных приставок сканеров для документов. Возможность сканирования книг в зависимости от модели и настроек сканера составляет в среднем 4-15 с на разворот. Также, как правило, используются дополнительные источники света, чаще холодного. Архивная обработка при сканировании документов такого типа не требуется, а распознавание обычно нужно.
Варианты сканеров, которые основаны на традиционных цифровых фотоаппаратах (имеющие специализированные штативы с V-образным или плоским предметным столом, а также с прижимным стеклом или без него). Другие устройства в виде ручных сканеров типа C-pen Docupen, специализированных планшетных сканеров типа Plustek OpticBook, планшетных приставок сканеров для документов. Возможность сканирования книг в зависимости от модели и настроек сканера составляет в среднем 4-15 с на разворот. Также, как правило, используются дополнительные источники света, чаще холодного. Архивная обработка при сканировании документов такого типа не требуется, а распознавание обычно нужно.
Основные понятия и обзор системы
Добро пожаловать в Stitch!
Stitch — это облачная платформа с открытым исходным кодом для быстрого перемещения данных. Простой и мощный ETL-сервис Stitch подключается ко всем вашим источникам данных — от баз данных, таких как MySQL и MongoDB, до приложений SaaS, таких как Salesforce и Zendesk, — и реплицирует эти данные в место назначения по вашему выбору.
В этом руководстве мы рассмотрим основные концепции и архитектуру Stitch, в том числе:
Что делает Stitch, как его настроить и как рассчитывается использование
Обзор репликации данных в Stitch
Преобразования данных, которые выполняет Stitch
Пошаговый обзор системы Stitch, от извлечения данных до их загрузки
Некоторые следующие шаги
Основы
Что делает Стич?
Настройка Stitch
Какие интеграции и назначения
Как рассчитывается использование Stitch
Что такое Стич?
Создание облачного конвейера данных ETL. ETL — это сокращение от «извлечение, преобразование, загрузка», которые представляют собой этапы процесса, перемещающего данные из источника в пункт назначения.
При этом имейте в виду, что Стич не такой:
- Служба анализа данных . Однако у нас есть много партнеров по аналитике, которые могут помочь в этом.
- Средство визуализации данных или создания запросов. Stitch только перемещает данные. Для его анализа вам понадобится дополнительный инструмент. Обратитесь к нашему списку инструментов анализа для некоторых предложений.
- Пункт назначения . Назначение обычно является хранилищем данных и требуется для использования Stitch. Хотя мы не можем создать его для вас, вы можете воспользоваться нашим руководством по выбору пункта назначения, если вам нужна помощь в выборе подходящего пункта назначения для ваших нужд.
Настроить
Всего за несколько минут вы можете настроить собственный конвейер данных:
- Зарегистрируйте учетную запись Stitch . У вас еще нет аккаунта? Зарегистрируйтесь здесь для бесплатной пробной версии.

- Подключить пункт назначения . Место назначения, обычно база данных или хранилище данных, куда Stitch будет загружать реплицированные данные. Сюда входят такие продукты, как Amazon Redshift, Amazon S3 или Google BigQuery.
- Подключить интеграцию . Интеграции — это источники данных, или откуда Stitch реплицирует данные. Сюда входят приложения SaaS, такие как Google Analytics, базы данных, такие как MySQL, и многое другое.
Пошаговые инструкции по настройке Stitch см. в руководстве по настройке конвейера данных Stitch.
Интеграции и места назначения
Чтобы использовать Stitch, вам необходимо место назначения и хотя бы одна интеграция или источник данных.
Места назначения
Stitch поддерживает некоторые из самых популярных озер данных, хранилищ и платформ хранения в качестве мест назначения, таких как Amazon Redshift, Google BigQuery и Microsoft Azure Synapse Analytics.
Выбранное место назначения определяет способ загрузки и структурирования реплицированных данных. Более подробно это обсуждается в разделе Преобразования.
Более подробно это обсуждается в разделе Преобразования.
См. документацию по целевому назначению для получения дополнительной информации о каждом из предложений Stitch по целевому назначению. Если вы новичок в хранении данных или хотите посмотреть, как предложения Stitch по сравнению друг с другом, ознакомьтесь с нашим руководством по выбору места назначения. Это руководство поможет вам выбрать наилучшее место назначения Stitch для ваших потребностей в хранении данных, от обеспечения совместимости ваших источников данных до соблюдения вашего бюджета.
Интеграции
Интеграция — это источник данных. Это может быть база данных, API, файл или другое приложение данных, из которого Stitch реплицирует данные, например MySQL, Google Analytics или Amazon S3.
Во время бесплатной пробной версии доступны все интеграции Stitch. После окончания пробного периода некоторые интеграции, такие как Oracle или Google Analytics 360, будут доступны только в том случае, если вы войдете в план Advanced или Premium.
Обратитесь к документации по интеграции для получения дополнительной информации о каждой из интеграций Stitch, например, какие данные доступны или какие функции поддерживаются.
Использование строк и стежков
Использование стежков зависит от объема. Как и часть данных тарифного плана сотового телефона, каждый тарифный план Stitch включает определенное количество реплицируемых строк в месяц. На общее использование строк может влиять множество факторов, в том числе выбранное вами место назначения и количество имеющихся у вас интеграций.
Подробные сведения о том, как рассчитывается использование, о факторах, влияющих на него, и о том, как можно сократить использование, см. в руководстве «Понимание и сокращение использования».
Репликация
Процесс репликации Stitch состоит из трех отдельных этапов:
- Извлечение : Stitch извлекает данные из ваших источников данных и сохраняет их в конвейере данных Stitch через Import API.

- Подготовка : Данные слегка преобразованы для обеспечения совместимости с местом назначения.
- Загрузить : Stitch загружает данные в пункт назначения.
Однократное появление этих трех фаз называется задание репликации . Вы можете следить за ходом выполнения задания репликации на любой странице интеграции Summary .
Настройки извлечения
Когда вы настраиваете интеграцию в Stitch, вам также необходимо определить ее настройки репликации. Эти параметры управляют фазой извлечения процесса репликации, включая частоту извлечения, какие данные следует извлекать и как данные извлекаются.
Время загрузки данных
Поскольку наш процесс выполняется поэтапно, важно отметить, что репликация Stitch не выполняется в режиме реального времени. Это означает, что между извлечением данных и загрузкой данных будет некоторое время, о котором вы можете узнать больше в разделе «Архитектура системы» этого руководства.
Кроме того, скорость извлечения и загрузки в значительной степени зависит от ресурсов, доступных в ваших источниках данных и месте назначения.
Удаленные записи
Stitch никогда не удалит данные из места назначения, даже если записи были удалены из источника. Дополнительные сведения и примеры см. в руководстве по работе с удаленными записями.
Преобразования
Цель Stitch — доставить данные из ваших источников данных к месту назначения в удобном необработанном формате:
Полезный означает с типами и структурами, которые упрощают работу с данными, а необработанный означает сохранение как можно ближе к исходному представлению.
Это не означает, что Stitch не выполняет преобразования в процессе репликации. Stitch просто не выполняет 90 163 произвольных 90 164 преобразований. Stitch выполнит только те преобразования, которые необходимы для обеспечения того, чтобы загруженные данные были полезными и совместимыми с вашим местом назначения.
Ввод данных
структуры JSON
Имена объектов
Часовые пояса
Философия Stitch заключается в том, что то, что вы делаете со своими данными, зависит от ваших потребностей, и, сохраняя данные в их исходной форме, Stitch позволяет вам управлять ими и преобразовывать их по своему усмотрению. Хотя мы не поддерживаем определяемые пользователем преобразования внутри Stitch, вы можете воспользоваться преимуществами решений Talend для преобразования и качества данных, чтобы разрабатывать и интегрировать свои собственные преобразования.
Тип данных
Процесс типизации данных Stitch состоит из трех шагов, которые происходят во время репликации:
- Извлечение : Определение типа данных в источнике
- Подготовка : сопоставление типа данных с типом данных Stitch
- Загрузка : преобразование типа данных Stitch в совместимый с местом назначения тип данных
Stitch преобразует типы данных только там, где это необходимо, чтобы убедиться, что данные принимаются пунктом назначения.
За некоторыми исключениями, когда изменяется тип данных или поле имеет несколько типов данных в источнике, Stitch создаст дополнительный столбец в месте назначения для размещения нового типа данных. Это будет выглядеть так, как будто столбец был «разделен». Например:
| идентификатор | has_magic__bo | has_magic__st |
| 1 | истинный | |
| 2 | да | |
| 3 | нет |
Stitch обрабатывает измененные типы данных таким образом, чтобы ранее загруженные данные сохранялись в исходном формате. Некоторые клиенты Stitch используют представления для принуждения типов данных, когда это происходит.
Дополнительные сведения и примеры см. в руководстве по столбцам со смешанными типами данных.
Структуры JSON
Назначение, которое вы используете, определяет, как Stitch обрабатывает сложные структуры JSON, такие как массивы и объекты.
Если ваш пункт назначения изначально поддерживает хранение вложенных данных, Stitch будет хранить данные как тип, подходящий для хранения частично структурированных данных. Затем вы можете использовать функции JSON, поддерживаемые местом назначения, для разбора и анализа данных.
Если ваш пункт назначения изначально не поддерживает хранение вложенных данных, Stitch «удалит» или нормализует данные в отношения. Для объектов JSON атрибуты будут объединены в таблицу, а массивы будут распакованы в подтаблицы. Дополнительные сведения и примеры см. в руководстве по вложенным структурам JSON.
Имена объектов
Когда вы изначально настраиваете интеграцию, вы определяете имя схемы в месте назначения, куда Stitch будет загружать данные этой интеграции.
Однако имена таблиц и столбцов, которые вы задали для репликации, автоматически генерируются на основе двух факторов:
- Имя объекта в источнике
- Правила именования объектов, применяемые пунктом назначения
Во время загрузки Stitch попытается сохранить имена объектов как можно ближе к источнику.
Примечание : Имена таблиц и столбцов нельзя изменить в Stitch.
Часовые пояса
Некоторые направления, предлагаемые Stitch, изначально не поддерживают часовые пояса. Чтобы обеспечить точность и согласованность, Stitch обрабатывает данные с часовыми поясами следующим образом:
- Извлечение данных из источника
- Преобразование исходных данных в формат UTC
- Загрузить данные в формате UTC в пункт назначения
В зависимости от места назначения, которое вы используете, данные могут храниться или не храниться вместе с информацией о часовом поясе. Это зависит от того, поддерживает ли пункт назначения часовые пояса.
Для получения дополнительной информации см. справку по загрузке для вашего пункта назначения.
Архитектура системы

Процесс репликации Stitch состоит из трех фаз:
Экстракт
Подготовить
Загрузить
Примечание . Этот процесс одинаков независимо от региона конвейера данных вашей учетной записи.
Первая фаза процесса репликации называется Извлечение . На этом этапе данные извлекаются из интеграции с использованием заданных вами параметров репликации.
Фаза извлечения включает:
Шаг 1: механизм репликации на основе Singer
Шаг 2: API импорта
Шаг 1: Механизм репликации на основе Singer
Для приложений и баз данных SaaS данные извлекаются по расписанию с помощью механизма репликации на основе Singer, который Stitch запускает для таких источников данных, как API, базы данных и плоские файлы.
На этом шаге происходят две вещи:
Синхронизация структуры .
 В начале каждого извлечения Stitch запускает так называемую синхронизацию структуры. Синхронизация структуры обнаруживает таблицы и столбцы, доступные в источнике, а также любые изменения в структуре этих таблиц и столбцов.
В начале каждого извлечения Stitch запускает так называемую синхронизацию структуры. Синхронизация структуры обнаруживает таблицы и столбцы, доступные в источнике, а также любые изменения в структуре этих таблиц и столбцов.Примечание : Новые таблицы и столбцы, обнаруженные во время синхронизации структуры, будут доступны в Stitch после завершения текущего задания репликации. Для большинства интеграций новые таблицы и столбцы не будут автоматически настроены на репликацию.
Данные извлекаются в формате JSON. На основе схем, таблиц и столбцов, настроенных для репликации, Stitch извлекает данные в формате JSON и отправляет их в API импорта.
Шаг 2: API импорта
Следующим шагом в процессе репликации является API импорта.
Для данных, отправленных непосредственно в Stitch через веб-перехватчик или интеграцию Import API, это первый шаг в процессе репликации. ( Примечание : Вот почему интеграции веб-перехватчика и API импорта не имеют журналов извлечения. )
)
API импорта проверяет и аутентифицирует каждый запрос, а затем сохраняет данные во внутреннем конвейере данных Stitch.
Если данные не проходят проверку или возникает другая критическая ошибка, извлечение завершится неудачно и вызовет уведомление в приложении и по электронной почте. Ошибку также можно просмотреть на вкладке «Журналы извлечения» интеграции.
Подготовка
Второй этап процесса репликации называется Подготовка . На этом этапе извлеченные данные буферизуются в надежном, высокодоступном внутреннем конвейере данных Stitch и готовятся к загрузке.
Этап подготовки включает:
Шаг 3: Конвейер
Шаг 4: Стримеры
Шаг 3: Конвейер
Stitch использует системы Apache Kafka и Amazon S3, охватывающие несколько центров обработки данных, для надежной буферизации данных, получаемых API импорта, и обеспечения достижения нашей самой важной цели уровня обслуживания: не потерять данные. Данные всегда шифруются в состоянии покоя и автоматически удаляются из буфера не позднее, чем через семь дней.
Данные всегда шифруются в состоянии покоя и автоматически удаляются из буфера не позднее, чем через семь дней.
Шаг 4: Streamery
Затем данные считываются из конвейера и разделяются, группируются и подготавливаются к загрузке внутренней службой Stitch, которая называется Streamery.
Streamery записывает данные в Amazon S3, которые зашифрованы, разделены по арендатору (учетной записи Stitch) и набору данных и готовы к загрузке. Большая часть данных загружается в течение нескольких минут, но если пункт назначения недоступен, он может оставаться в S3 до 30 дней, прежде чем будет автоматически удален.
Загрузка
Последняя фаза процесса репликации называется Загрузка . На этом этапе подготовленные данные преобразуются для совместимости с местом назначения, а затем загружаются.
Фаза загрузки включает:
Шаг 5: Погрузчики
Шаг 6: Пункт назначения
Шаг 5: Загрузчики
Загрузчик считывает данные из Streamery (Amazon S3) и выполняет необходимые преобразования, например, преобразование данных в соответствующие типы данных или структуру, прежде чем загружать их в пункт назначения. Диск используется как временный буфер, данные шифруются при записи и удаляются сразу после загрузки.
Диск используется как временный буфер, данные шифруются при записи и удаляются сразу после загрузки.
Stitch по умолчанию использует соединения с шифрованием SSL/TLS к месту назначения, когда это возможно. Туннели с шифрованием SSH также доступны для настройки для большинства типов назначения.
При возникновении критической ошибки загрузка завершится ошибкой и вызовет уведомление в приложении и по электронной почте. Ошибку также можно просмотреть на вкладке Загрузка отчетов интеграции.
Шаг 6: Пункт назначения
Наконец-то данные загружены в пункт назначения! Для каждой интеграции Stitch создаст схему (или набор данных, или папку, или базу данных, в зависимости от вашего назначения) и загрузит в нее данные этой интеграции. Обратитесь к руководству Понимание структур схем интеграции для получения информации о том, как будут структурированы схемы.
На этом этапе вы можете использовать инструмент анализа для взаимодействия с вашими данными.
Следующие шаги
Теперь, когда вы освоили основы, переходите к:
Настройка конвейера данных Stitch : Настройте конвейер данных Stitch и запустите его.

Понимание и сокращение использования строк : Изучите основы выставления счетов Stitch, как просмотреть и понять использование и уменьшить количество строк.
Подключение других источников данных к Stitch : Не видите нужную интеграцию в Stitch? Узнайте о вариантах получения данных из неподдерживаемых в настоящее время источников данных в Stitch.
Вопросы? Обратная связь?
Помогла ли эта статья? Если у вас есть вопросы или отзывы, отправьте запрос на внесение изменений со своими предложениями, откройте вопрос на GitHub или свяжитесь с нами.
Печать внакидку: Ослепительная печать
О печати внакидку
Печать внакидку — это один из четырех предлагаемых нами вариантов переплета. Переплет внакидку часто используется для буклетов, журналов, программ и каталогов. При печати внакидку большие листы бумаги сгибаются пополам, собираются вместе и сшиваются в корешке документа.
Узнать цену
Преимущества и недостатки печати внакидку
Преимущества печати внакидку
- Переплет внакидку — самый дешевый из предлагаемых нами вариантов переплета.
- Это хороший вариант для многостраничных документов до 80 страниц.
- Брошюры внакидку можно печатать на одной и той же бумаге или с более плотной обложкой.
- Вы можете размещать изображения на разворотах, не теряя ни одного изображения на краю скрепления.
Недостатки переплета внакидку включают
- Более толстые брошюры с переплетом внакидку могут стать громоздкими, особенно на стороне брошюры с корешком.
- Брошюры внакидку не ложатся ровно, потому что они закруглены по краю переплета.
- Из-за способа печати буклетов внакидку их необходимо заказывать с шагом в четыре страницы. Если в вашем буклете 14 страниц, вам нужно будет придумать еще две страницы или удалить две страницы.
Как сшиваются документы внакидку?
При сшивании внакидку большие листы бумаги печатаются по две страницы на каждой стороне листа (по четыре страницы на лист бумаги). Бумага складывается пополам, все листы собираются вместе, а затем две скобы (называемые сшитыми) помещаются в корешок книги. Поскольку каждый лист состоит из четырех страниц, печать внакидку должна выполняться с шагом в четыре страницы.
Бумага складывается пополам, все листы собираются вместе, а затем две скобы (называемые сшитыми) помещаются в корешок книги. Поскольку каждый лист состоит из четырех страниц, печать внакидку должна выполняться с шагом в четыре страницы.
В Dazzle Printing наши цифровые печатные машины выполняют брошюровку во время печати документа. Сначала печатаются внутренние страницы, а затем обложка. Листы бумаги собираются в зоне ожидания до тех пор, пока все листы не будут напечатаны. Затем листы складываются пополам и два сшиваются в корешок.
Затем документ перемещается в устройство обрезки, которое обрезает документ с трех сторон (скрепленный край не обрезается) до конечного размера брошюры. Таким образом, буклет печатается на листах большего размера, на которых можно напечатать обрезы, а затем обрезать до конечного размера. Таким образом, печать может доходить до края страницы.
Статья о брошюровщике
Более подробное описание идеального переплета.
Прочитать статью
Часто задаваемые вопросы о печати внакидку
Брошюры с брошюровкой внакидку какого размера можно печатать?
У нас есть четыре стандартных размера буклетов для сшивания внакидку
5,5 x 8,5, 6 x 9, 8,5 x 11 и 9 x 12
Мы также можем печатать буклеты нестандартного размера. Однако, из-за положения стежков, край должен быть не менее 6 дюймов в длину. Если вы хотите заказать нестандартный размер, используйте следующий больший размер в нашем калькуляторе. Чтобы заказать буклет размером 7,5 x 10 дюймов, вы должны использовать калькулятор для 8,5 x 11,
Однако, из-за положения стежков, край должен быть не менее 6 дюймов в длину. Если вы хотите заказать нестандартный размер, используйте следующий больший размер в нашем калькуляторе. Чтобы заказать буклет размером 7,5 x 10 дюймов, вы должны использовать калькулятор для 8,5 x 11,
Можно ли печатать буклеты внакидку в альбомной ориентации?
Мы можем печатать буклеты размером 6 x 9 дюймов только в альбомной ориентации внакидку. За пейзажные книги взимается дополнительная плата. Если вам нужна альбомная книга другого размера, предлагаем заказать идеальный переплет.
Какое минимальное и максимальное количество страниц можно сшить внакидку?
Минимальное количество страниц, которые можно сшить внакидку, составляет 8 страниц, а максимальное количество страниц — 80 страниц. Поскольку брошюры с брошюровкой внакидку могут стать громоздкими по мере увеличения количества страниц, мы рекомендуем использовать более легкую бумагу по мере увеличения количества страниц. Мы рекомендуем использовать 100# обложку и 100# текст или светлее для буклетов объемом до 24 страниц (более легкая бумага подойдет), 80# обложка и 80# текст для буклетов до 60 страниц (легкая бумага подойдет), и 80 # обложка и 70 # текст для буклетов до 80 страниц.
Мы рекомендуем использовать 100# обложку и 100# текст или светлее для буклетов объемом до 24 страниц (более легкая бумага подойдет), 80# обложка и 80# текст для буклетов до 60 страниц (легкая бумага подойдет), и 80 # обложка и 70 # текст для буклетов до 80 страниц.
Можно ли печатать буклет внакидку с самообложкой?
Самостоятельная обложка означает, что внутренние страницы и страницы обложки печатаются на бумаге одинаковой плотности. Мы можем печатать брошюры с самообложкой внакидку, но обычно это лучше, если вы печатаете брошюру, которая будет использована один раз и выброшена. Обычно лучше иметь более тяжелую обложку для обложки, так как это защитит книгу, сделает ее более прочной и долговечной.
Можно ли печатать на внутренней стороне обложки?
Да, можем. Большинство буклетов для брошюровки, которые мы печатаем, имеют печать на внутренней стороне обложки. Когда вы отправляете файл PDF, мы предполагаем, что вы хотите печатать на внутренней стороне обложки, если после передней обложки и перед задней обложкой нет пустых страниц.
Когда вы отправляете файл PDF, мы предполагаем, что вы хотите печатать на внутренней стороне обложки, если после передней обложки и перед задней обложкой нет пустых страниц.
Предлагаете ли вы ламинирование обложек?
Хотя мы предлагаем глянцевое, мягкое на ощупь, кожаное и льняное ламинирование, мы не можем ламинировать обложки внакидку. Если вы определенно хотите ламинирование, подумайте о переходе на идеальный переплет.
Предлагаете ли вы скругление углов для книг для брошюр?
Да, мы предлагаем 2-х и 4-х угловое скругление на брошюрах. Скругление двух углов является наиболее типичным выбранным вариантом. Скругление углов отлично подходит для детских книг, журналов и планировщиков.
Как следует подавать файлы брошюровки?
Все файлы должны быть в формате PDF высокого разрешения с обрезами.

Об авторе