Проверить сайт на уникальность: Анализ контента сайта на уникальность (плагиат)
Проверить сайт на уникальность контента онлайн, проверить страницы сайта на уникальность
Ваши последние проверки
Для доступа к истории проверок нужно войти в систему
Новости сервиса
24.05.2021 20.09.2020 22.09.2019Проверка страниц сайта на уникальность
Для проверки отдельной страницы достаточно ввести адрес в соответствующее поле. Система выделит контент страницы, удалит навигационные элементы, не имеющие отношения к тексту, а затем проверит на уникальность.
Если нужно проверить несколько страниц и у вас есть их список, воспользуйтесь пунктом «Пакетная проверка» и вы сможете ввести весь список сразу.
Мы проверим их по очереди и вы сможете увидеть результаты каждой из проверок.
Автоматическая регулярная проверка сайта
Попробуйте нашу автоматическую регулярную проверку — добавьте страницы сайта на защиту, и мы будем мониторить их уникальность и отправлять вам отчеты на почту!
Лимиты
Нужно проверить весь сайт, а лимитов не хватает? Вы можете купить подписку и проверять значительно больше!
Автоматический подбор разделов сайта
Когда вам нужно проверить страницы определенного раздела сайта или все они имеют похожий адрес, можно воспользоваться новым функционалом сканирования сайта и не искать их вручную.
Проверка идет в два этапа. Сначала укажите адрес сайта, и мы просканируем его и покажем все разделы. Затем вы можете одним кликом проверить любой раздел!
Поиск ссылки на источник
Пользователям с подписками доступна новая функция — автоматический поиск ссылок на проверяемый сайт. Мы будем искать упоминание или активную ссылку на ваш сайт при каждой проверке.
Это позволит вам быстро принять решение о том, является ли копия плагиатом или нет.
Мы будем искать упоминание или активную ссылку на ваш сайт при каждой проверке.
Это позволит вам быстро принять решение о том, является ли копия плагиатом или нет.
Пожалуйста, сообщайте об ошибках, оставляйте отзывы и предложения.
Обратите внимание, на нашем сайте можно также проверить текст на уникальность.
Проверить текст на уникальность онлайн бесплатно
Любая научная работа (дипломная, курсовая, реферат, статья, диссертация и т.д.) перед сдачей должна пройти обязательную проверку на уникальность (подлинность) текста. Согласно требованиям Министерства Образования, студент или научный сотрудник обязан пользоваться только собственными знаниями: если работа скопирована — университет не допускает автора до защиты.
Но самостоятельное написание не является гарантией высокого процента оригинальности текста, потому что любая работа содержит ряд обязательной информации:
- теории;
- юридические законы;
- цитаты;
- распространенные речевые обороты.
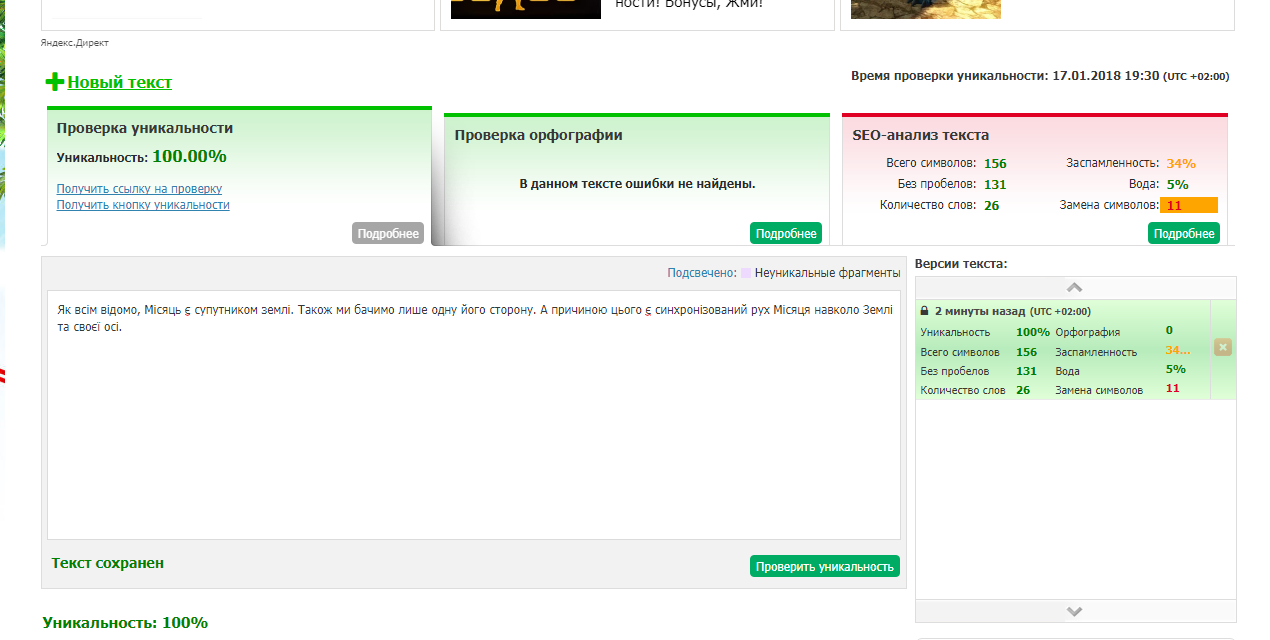
Онлайн проверка текста на уникальность
Поэтому лучше проверять уникальность текста заранее — это позволит устранить все замечания еще до проверки преподавателями. В Интернете можно найти десятки платных и бесплатных антиплагиат-сервисов, но не каждому из них можно доверять. Одни программы используют устаревшие алгоритмы, другие — не предоставляют отчет, третьи — недоступны для студентов.
Поэтому мы создали свою программу для проверки уникальности текста и контента. Она полностью автоматизирована, работает круглосуточно и без регистрации. На проверку одного текста или документа требуется не более 30 секунд.
Как происходит анализ уникальности документа?
За те 30 секунд, пока идет анализ, программа для проверки уникальности статьи, проделывает огромную работу. Она сопоставляет исходный текст с миллионами других документов, которые опубликованы в интернете или хранятся в закрытых базах данных библиотек и университетов.
Для этого текст разбивается на фрагменты определенной величины — шинглы. Вот «постулат теории относительности» — это шингл из 3 слов. Программа по специальным алгоритмам ищет эту фразу в других документах. Если находит, то отмечает фрагмент как заимствованный и снижает процент уникальности. К примеру, показатель оригинальности 80% означает, что в документе содержится 80% авторского материала, а оставшиеся 20% — это плагиат.
Вот «постулат теории относительности» — это шингл из 3 слов. Программа по специальным алгоритмам ищет эту фразу в других документах. Если находит, то отмечает фрагмент как заимствованный и снижает процент уникальности. К примеру, показатель оригинальности 80% означает, что в документе содержится 80% авторского материала, а оставшиеся 20% — это плагиат.
- Загружаете работу, который нужно проверить на уникальность. Поддерживаются все основные форматы: doc, docx, odt, pdf, rtf, txt.
- Выбираете алгоритм, по которому будет осуществляться проверка. Нужно использовать ту систему, которую применяют в вашем учебном заведении. Просто уточните у преподавателя — это не тайна, такая информация является открытой.
- Если нужны дополнительные опции, отметьте их галочками. Можно поискать в файле следы технического кодирования и скрытый текст.
 Это признаки того, что документ подвергался искусственному увеличению оригинальности. Если такие «улики» обнаружены, сервис позволяет их сразу же уничтожить.
Это признаки того, что документ подвергался искусственному увеличению оригинальности. Если такие «улики» обнаружены, сервис позволяет их сразу же уничтожить. - Работа отправляется на проверку. Анализ занимает примерно 30 секунд.
- Вы получаете подробный отчет, где указан процент оригинальности, а заимствованные словосочетания выделены цветом. Здесь же можно посмотреть, откуда, по мнению умного алгоритма, вы стащили фрагменты материала. Скорее всего, практически все цитаты, теории и названия законодательных актов будут отмечены как плагиат.
Antiplagius — лучший сервис определения оригинальности текста
Преимущества нашего сервиса для проверки оригинальности текста:
- В отличие от других сервисов, мы бесплатно проверяем не только большие тексты, но и документы. Работаем с текстами до 200 000 знаков и с документами до 20 Мб.
- Массовая проверка уникальности текста без регистрации. Чтобы пройти тест на уникальность, вам не нужно создавать аккаунт на сайте.

- Нам удалось учесть алгоритмы всех современных онлайн-сервисов для проверки уникальности текста, поэтому мы можем гарантировать объективность и точность полученных результатов.
- Наша программа проверки уникальности позволяет: установить процент оригинальности, увидеть заимствованные фрагменты, получить ссылки на первоисточники.
- Система работает практически мгновенно — всего 30 секунд, и отчет готов. Другие сервисы, через которые ведется массовая проверка документов, не могут похвастаться такой оперативностью. Там ваша работа попадает в длинную очередь и может стоять в ней часами.
- Мы предоставляем возможность сохранить отчет в формате pdf и поделиться результатами с друзьями в социальных сетях или используя ссылку.
А еще, вы сможете получить на нашем сайте и другие услуги:
- профессиональный анализ работы — поиск плагиата и технических ошибок;
- повышение уникальности;
- глубокая проверка в других сервисах (в том числе в закрытой для студентов системе «Антиплагиат.
 ВУЗ»).
ВУЗ»).
К нам обратились уже 1 500 000 студентов, и все они получили хорошую оценку или «зачет» на защите. Мы можем помочь и вам!
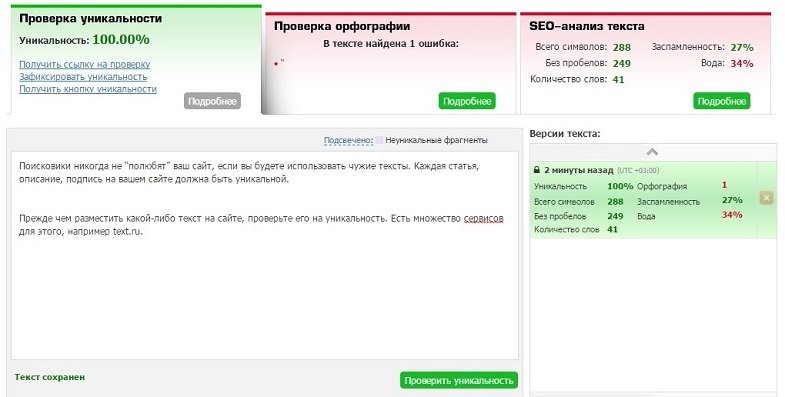
Уникальность контента сайта, орфография, качество
Описание
Сервис позволяет проверить уникальность сайта, орфографию и качество текстов. Для проверки сайта необходимо зарегистрироваться и пополнить баланс на сумму из строки «Максимальная стоимость заказа», которая зависит от выбранных параметров. Реальная стоимость заказа будет зависеть от объема текстов на собранных страницах.
Подробные результаты проверки хранятся 7 дней, далее заказ переходит в архив и остается только общая информация.
Рассмотрим основные этапы проверки сайта.
Оформление заказа
Сервис может получить адреса страниц из списка адресов, карты сайта, файлов RSS или сканируя сайт пауком. Причем сбор адресов может осуществляться сразу из всех источников, пока не будет достигнут указанный лимит максимального количества страниц. Приоритет источников такой же как расположение вкладок в форме: сначала адреса берутся из списка, затем из sitemap, потом из RSS и через сканирование.
Приоритет источников такой же как расположение вкладок в форме: сначала адреса берутся из списка, затем из sitemap, потом из RSS и через сканирование.
Выбранные параметры проверки затем нельзя отредактировать, но можно создать новый заказ.
При сканировании с помощью паука можно закрывать ненужные участки страниц тегом noindex, а ненужные разделы сайта в файле robots.txt.
Отправка собранных адресов на проверку
После получения адресов страниц Вам необходимо проверить и удалить из списка ненужные и отправить заказ на проверку. Вы можете ожидать выполнения заказа во вкладке браузера или зайти позднее, так как исполнение заказа займет некоторое время. После выполнения проверки Вам на email придет уведомление о готовности.
Обработка страниц
Обработка большого количества страниц займет время, Вы можете ожидать во вкладке или дождаться уведомления о готовности на email, при этом вкладку можно закрыть.
Страницы, вернувшие ошибку или не содержащие достаточного объем текста (менее 100 символов) не будут обработаны.
Результат
Результат проверки сайта состоит из общей информации об уникальности, качестве и орфографии сайта и информации по каждой странице. Общая информация хранится даже после перевода заказа в архив. Подробная информация о каждой странице удаляется через 7 дней.Пример общей информации:
Пример информации о странице:
Переходя по ссылкам, можно ознакомиться с подробной информацией об уникальности, качестве, орфографии
Как выглядит проверка с телефона (видео)
5 сервисов для проверки контента сайта
Уникальность – один из самых важных критериев текста при поисковом продвижении. Если использовать контент, скопированный из других источников, то санкции поисковых систем отправят сайт далеко в конец выдачи. Поэтому важно перед всегда проверять текст на плагиат перед размещением. Я создал небольшую подборку из наиболее популярных сервисов проверки уникальности, где постараюсь расписать их главные преимущества и недостатки.
Если использовать контент, скопированный из других источников, то санкции поисковых систем отправят сайт далеко в конец выдачи. Поэтому важно перед всегда проверять текст на плагиат перед размещением. Я создал небольшую подборку из наиболее популярных сервисов проверки уникальности, где постараюсь расписать их главные преимущества и недостатки.
Для наглядности, глубину проверки буду субъективно оценивать по 10-ти бальной шкале. Где 1 – находит только точные копии больших фрагментов текста, 10 – для 100% уникальности приходится изобретать новые слова. Основана она исключительно на личных наблюдениях, если вы с ней не согласны, то мне будет интересно увидеть ваш личный рейтинг в комментариях.
6 баллов. Онлайн-сервис, который позволяет быстро проверить текст до 15 тыс. символов. Лучше сразу пройти регистрацию, после чего вам будет доступно до 10 бесплатных проверок день. Также доступен PRO-аккаунт, который снимает ограничения по количеству текстов и значительно ускоряет работу сервиса.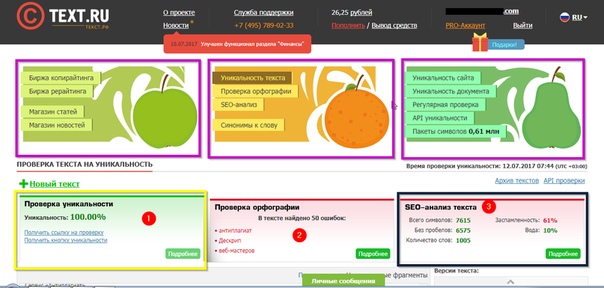
Проверка качественная и занимает не слишком много времени. Поэтому сервис очень популярен среди копирайтеров. Он довольно точно выявляет поверхностный рерайт, особенно если автор пытается схитрить, например используя метод с заменой 1 слова в каждом шингле.
Также Text.ru проводит SEO-анализ текста (водность, заспамленность) и проверку орфографии.
Главный недостаток – ограниченное количество текстов, для больших объемов контента нужен PRO-аккаунт.
8 баллов. Сервис проверяет текст на плагиат сразу по нескольким критериям:
- повторение шинглов;
- совпадение большого количества слов и выражений во фрагментах текста;
- синонимы (заменяет некоторые слова синонимами, что позволяет выявить текст, который прогнали через уникализатор).
Также предоставляет удобные инструменты для семантического анализа (вода, классическая и академическая тошнота), этим заслужил свою популярность среди SEO-оптимизаторов.
Проверить на плагиат можно в онлайн-сервисе, а также в приложении Advego Plagiatus. Лично я считаю одной из наиболее полных и качественных проверок. Доступна настройка критериев.
Лично я считаю одной из наиболее полных и качественных проверок. Доступна настройка критериев.
Однако сервис часто излишне усерден, он находит случайные совпадения с самыми неожиданными источниками. Добиться 100% уникальности здесь вполне возможно, но будьте готовы к неожиданностям. В онлайн-сервисе бесплатный лимит – до 10 тыс символов в день.
Главный недостаток Advego в том, что корректно работает он только в рунете. Скорость проверки через приложение Advego Plagiatus также оставляет желать лучшего, а еще необходимо постоянно вводить капчу.
Комплексный интернет-маркетинг
Мы создаем систему взаимодействия различных инструментов продвижения, синергия которых приводит к отличным результатам. Мы разработаем механизм ведения Вашего бизнеса в интернете.
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Отправить заявку
5 баллов. Один из наиболее быстрых сервисов, в чем его главное преимущество на мой взгляд. Без регистрации вам доступно по 3 бесплатных проверки текста длиной до 10 тыс. символов. Content-Watch использует собственный уникальный алгоритм, поэтому о критериях проверки известно немного.
Без регистрации вам доступно по 3 бесплатных проверки текста длиной до 10 тыс. символов. Content-Watch использует собственный уникальный алгоритм, поэтому о критериях проверки известно немного.
Добиться 100% уникальности здесь несложно. Но не стоит считать, что Content-Watch легко обмануть. Он довольно точно определяет не только откровенный копипаст, но и рерайт низкого качества.
Сервис предоставляет очень полезный платный инструмент: регулярная проверка текстов сайта на плагиат. Таким образом вы сможете обнаружить, если кто-то позаимствует ваш контент.
7-10 баллов. Существует как онлайн-версия, так и отдельная программа, которую можно скачать и установить на ПК. В приложении можно настроить критерии и глубину проверки. Есть возможность сравнить два текста.
Без регистрации длина текста ограничена 3 тысячами символов, после – лимит вырастет до 5 тысяч. За оплату можно сразу отправить на проверку большое количество текстов, что очень удобно, если вы занимаетесь наполнением сайтов.
Читайте также
Качественный копирайтинг
При глубокой проверке на плагиат через приложение получить 100% уникальности очень сложно. Мы даже проверили эксперимент и проверили текст, полученный с помощью генератора контента от Яндекс.
Как видите, даже подобный набор слов получил только 62%.
У сервиса еще несколько серьезных недостатков. Первый – скорость, на одну статью может уйти до 20 минут. Второй – проверка на плагиат и рерайт проводится отдельно, что отбирает еще больше времени.
5 баллов. Полностью бесплатный онлайн-сервис, есть ограничения только по длине текста (10 тыс. символов). Заточен под Яндекс, что очень удобно для продвижения в этой поисковой системе. Определяет степень уникальности, заспамленность, а также процент воды.
Проверка длится недолго, очередь из текстов бывает редко, но требования к контенту здесь ниже, чем у остальных перечисленных сервисов.
Инструменты для проверки сайта
см. также:
также:
Инструменты для оптимизации сайта
Экспресс анализ сайта
SEO анализ веб страницы
Цена SEO аудита сайта
Проверка html (html валидатор)
Проверяет html код, как заданный с помощью ссылки на страницу, так и просто в виде загруженного файла или скопированного текста. Дает список замечаний с рекомендациями по их исправлению.
http://validator.w3.org/
Проверка css (css валидатор)
Проверяет стили документа или таблицу стилей, расположенную в отдельном файле.
http://jigsaw.w3.org/css-validator/
Проверка лент (feed) RSS и Atom
Проверяет правильность работы фидов RSS и Atom.
http://validator.w3.org/feed/
Проверка орфографии на веб странице
Подсвечивает ошибки на заданной URL странице.
http://webmaster.yandex.ru/spellcheck.xml
Показывает ошибки в тексте, скопированном в проверочное окно.
http://api.yandex.ru/speller/
Проверка структуры веб страницы
Показывает структуру веб страницы. Актуален для проверки html5 документов.
Неправильно отображает кириллицу (:.
http://gsnedders.html5.org/outliner/
Проверка контента на уникальность
В бесплатной версии показывает до 10 страниц в инете с частичным совпадением текста с вашей страницей.
http://www.copyscape.com
Проверяет уникальность текста введенного в форму. В бесплатной версии возможно ожидание результатов.
http://www.miratools.ru/Promo.aspx
Проверяет уникальность как введенного текста, так и текста по заданному URL, показывает уровень уникальности в процентах.
Имеет собственный алгоритм проверки.
http://content-watch.ru
Десктопные программы для проверки уникальности контента от бирж копирайтеров. Работают долго, но качественно. Etxt имеет версии для трех операционных систем: Mac, Linux и Windows.
Работают долго, но качественно. Etxt имеет версии для трех операционных систем: Mac, Linux и Windows.
http://advego.ru/plagiatus/
http://www.etxt.ru/antiplagiat/
Поиск похожих сайтов
Показывает сайты с похожим содержанием и схожей внутренней структурой.
http://similarsites.com
Проверка cms сайта
Проверяет наличие признаков наиболее известных cms.
http://2ip.ru/cms/
Проверка доступности с мобильных устройств
Оценивает возможность просмотра страницы с мобильных устройств и выдает список замечаний и ошибок.
http://validator.w3.org/mobile/
Проверка удобства сайта для телефонов от Гугл.
https://www.google.com/webmasters/tools/mobile-friendly/
Показывает скорость загрузки сайта на мобильных устройствах.
https://testmysite.withgoogle.com/intl/ru-ru
Сайт эмулятор выхода с мобильного телефона. Показывает сайт глазами выбранной модели.
Показывает сайт глазами выбранной модели.
http://www.mobilephoneemulator.com/
Проверка доступности для людей с ограниченными возможностями
Сервис проверки страницы для слабовидящих. Доступен on-linе и в виде плагина для Firefox.
http://wave.webaim.org/
Просмотр содержания сайта глазами поискового робота
Показывает текст сайта, приближенный к тому, что видит поисковый индексатор.
http://www.seo-browser.com/
Дистрибутив текстового браузер lynx для win32 систем. Перед использованием нужно отредактировать lynx.bat, указав в нем путь к директории с lynx.
http://www.fdisk.com/doslynx/lynxport.htm
Убирает все разметку и показывает текст страницы, мета теги и теги заголовков, число внешних и внутренних ссылок. Показывает превью страницы в google.
http://www.browseo.net
Проверка битых ссылок
Показывает список исходящих ссылок для URL и проверяет их отклик. Может проверять рекурсирвно, то есть переходить от одного документа к другому самостоятельно.
Может проверять рекурсирвно, то есть переходить от одного документа к другому самостоятельно.
http://validator.w3.org/checklink
Freeware инструмент для проверки битых ссылок. Для работы нужно установить его на свой компьютер. Рекурсивно сканирует сайт, делает отчеты, может быть полезен для составления карты сайта.
http://home.snafu.de/tilman/xenulink.html
Проверка перелинковки и заголовков страниц
Проверяет и показывает внутренние ссылки, заголовки страниц, наличие дублированного контента на сайте. Бесплатно позволяет сканировать сайт 1 раз в 30 дней.
http://www.siteliner.com/
Сканирует до 500 страниц сайта в бесплатной версии. Проверяет число внешних и внутренних ссылок. Выводит информацию о просканированных страницах: вложенность, коды ответа, названия, мета информацию и заголовки.
http://www.screamingfrog.co.uk/seo-spider/
Проверка ссылочной структуры и веса внутренних страниц
Программа сканирует сайт, строит матрицу внутренних ссылок,
добавляет внешние (входящие) ссылки с заданных URL и, на основании этих данных, рассчитывает
внутренние веса страниц сайта. Программа может быть использована для нахождения внешних (исходящих) ссылок для списка URL страниц сайта.
Программа может быть использована для нахождения внешних (исходящих) ссылок для списка URL страниц сайта.
http://www.design-sites.ru/utility/link-analyzer.php
Проверка HTTP заголовков и ответа сервера, видимости страниц для роботов
Проверяет коды ответа сервера, прогнозирует скорость загрузки страницы в зависимости от объема в байтах ее данных,
показывает содержимое html тега head, внутренние и внешние ссылки для страницы, содержимое страницы глазами поискового робота.
http://urivalet.com/
Проверяет коды ответа сервера. Дает возможность проверить редиректы (коды ответа 301, 302), заголовок Last-Modified и др.
http://www.rexswain.com/httpview.html
Показывает объемы и содержимое данных, передаваемых при загрузки страницы.
http://www.websiteoptimization.com/services/analyze/
Проверяет редиректы, использование атрибута canonical, мета теги, некоторые аспекты безопасности сайта. Дает рекомендации по улучшению загрузки страниц.
Дает рекомендации по улучшению загрузки страниц.
http://www.seositecheckup.com
Проверка информации о домене и об IP адресе
WHOIS-сервис центра регистрации доменов RU center. Дает информацию по IP адресам и доменам по всему миру. Иногда зависает.
https://www.nic.ru/whois/?wi=1
Служба Whois от РосНИИРОС (RIPN). Дает информацию для доменов в зоне RU и IP адресам из базы RIPE (Европа).
http://www.ripn.net:8080/nic/whois/
Определяет, где у домена хостинг и также показывает IP адрес сайта.
http://www.whoishostingthis.com
Проверка не включен ли IP адрес в черный список для рассылки email.
http://whatismyipaddress.com/blacklist-check
http://ru.smart-ip.net/spam-check/
Проверка MX записей для домена. Проверка SMTP сервера для домена. Проверка IP в черных списках для рассылки.
https://mxtoolbox. com/
com/
Поиск по базе зарегистрированных торговых марок в США.
http://tmsearch.uspto.gov/
Проверка файлов robots.txt
Проверяет доступность для индексации страниц сайта роботом Yandex.
http://webmaster.yandex.ru/robots.xml
Проверяет корректность файла robots.txt.
https://www.websiteplanet.com/webtools/robots-txt
Техосмотр сайта
Мониторинг доступности сайта. Дает возможость подключить один сайт бесплатно с минимальными опциями проверки.
http://www.siteuptime.com
Проверка скорости загрузки сайта. Посылает отчет на email. Имеет платные сервисы мониторинга доступности сайта.
http://webo.in
Проверка скорости загрузки страниц сайта.
http://www.iwebtool.com/speed_test
Видимость сайта в поисковиках
Сервис, показывающий ключевые слова для сайта, по которым он находится в ТОП 20 (первой двадцатке) выдачи Google во времени. Данные о поисковом и рекламном трафике.
Данные о поисковом и рекламном трафике.
http://www.semrush.com/
Положение в ТОП50 yandex и Google. Тиц сайта и PR главной страницы, наличие в важных каталогах, видимость в топе по ВЧ запросам.
http://pr-cy.ru/
Проверка банов и уровня доверия к сайту
Проверка трастовости сайта. Сервис, утверждающий, что он измеряет траст для Яндекса (проверить все равно никто не может :).
http://xtool.ru/
Проверка наложения фильтров Панда и Пингвин от Гугл. Сервис позволяет визуально определить падал ли сайт в даты апдейтов Панда и Пингвин.
http://feinternational.com/website-penalty-indicator/
Проверка Page Rank страниц сайта (при копировании URL в инструмент нужно стереть последнюю букву а потом написать заново).
http://www.prchecker.net/
Проверка истории развития сайта
Показывает историю развития сайта и дает возможность посмотреть скриншоты старых страниц.
http://www.archive.org/web/web.php
История позиций сайта в ТОП Google (ключевые фразы, страницы, заголовки), показателей PR, ТИЦ, Alexa Rank, числа обратных ссылок для популярных сайтов.
http://SavedHistory.com
SEO плагины для проверки сайтов
SEO Doctor — дополнение к Firefox. Показывает ссылки на странице и дает удобный интерфейс к различным SEO сервисам.
http://www.prelovac.com/vladimir/browser-addons/seo-doctor/
SeoQuake — дополнение к Firefox. Показывает важнейшие характериситки сайта: ТИЦ, PR, обратные ссылки, Alexa Rank.
Работает как с выдачей Google, так и с выдачей Yandex. Дает возможность быстрого анализа конкурентов.
http://www.seoquake.com/
IEContextHTML — дополнение к Internet Explorer. Проверяет индексацию ссылок в Yandex и Google, показывает список внешних и внутренних ссылок, позволяет импортировать данные c веб страниц.
http://www.design-sites.ru/utility/ie-context-html.php
Видимость сайта в посковиках в зависимосит от места расположения
Обновляемый список бесплатных прокси серверов, в том числе и Российских.
http://www.checker.freeproxy.ru/checker/last_checked_proxies.php
http://spys.ru/proxys/ru/
Анонимный бесплатный прокси с возможностью представиться из трех стран. Работает с поиском Google.
https://hide.me/en/proxy
Эммуляторы поиска Google в разных странах, путем задания параметров поиска.
http://searchlatte.com/
http://isearchfrom.com/
Проверка позиций в Yandex и Google
Сервис дает возможность глубокой проверки (до 500) позиции сайта по регионам в Yandex.
http://www.design-sites.ru/utility/search-xml.php
Анализ обратных ссылок
Осуществляет анализ ссылочной массы сайта, формирует срезы по различным критериям: тип ссылки, анкоры, страницы. Показывает вес обратных ссылок.
Сервис доступен только для зарегистрированных пользователей.
Показывает вес обратных ссылок.
Сервис доступен только для зарегистрированных пользователей.
http://ahrefs.com
Проверка наличая обратных ссылок на сайт
Проверяет наличие бэклинков на сайт в предложенном списке URL (до 100 страниц).
http://webmasters.ru/tools/tracker
см. также:
Инструменты для социально-направленного поиска
PlusOneChecker
Показывает число лайков (plusone) в Google+. Можно вводить сразу список проверяемых URl.
http://www.plusonechecker.net/
Facebook Graph API Explorer
При вводе в поле GET URL адреса страницы сайта (например: http://www.design-sites.ru/utility/express-analys.php) показывает число «Поделиться» и комментариев для этой страницы.
Для работы нужно быть «залогининым» в Facebook.
https://developers.facebook.com/tools/explorer
Показывает популярность в Твиттере, Google+, Facebook, LinkedIn, Pinterest, Delicious, StumbleUpon, Diggs.
http://sharedcount.com
Cool Social
Показывает популярность первой страницы сайта в Твиттере, Google+, Facebook, Delicious, StumbleUpon.
Для российских сайтов данные иногда неверные.
http://www.coolsocial.net
Social-Popularity
Показывает метрику «Поделиться» (Shares) для российских сетей: «В Контакте», «Одноклассники», «Mail.ru», «Ya.ru».
http://www.design-sites.ru/utility/social-popularity.php
Social Crawlytics
Сканирует сайт и формирует отчеты «Shares» основных зарубежных социальных сетей для этих страниц. Регистрирует пользователей через акаунт в твиттере. Отчеты можно видеть уже на следующий день.
https://socialcrawlytics.com
Проверка сайта на вирусы
Dr.Web
Проверяет заданный URL на подозрительный код, показывает подгружаемые скрипты и результаты их проверки.
http://vms.drweb.com/online/
Virus Total
Проверяет URL на вирусы 30 сканерами.
https://www.virustotal.com/#url
Alarmer
Система защиты сайта от вирусов. Ежедневно сканирует файлы сайта и присылает отчет об их изменениях по email.
http://www.design-sites.ru/alarmer.php
Проверка текста на уникальность: 7 онлайн сервисов
Контент и его уникальность в сегодняшнем SEO
Еще в далеком 1996 году Билл Гейтс предвидел, что именно уникальный контент станет залогом для успешного развития любой компании в сети Интернет. Конечно, он имел в виду не только текстовый, но и мультимедийный контент — фотографии, видеофайлы и аудиозаписи. О том, как проверять их на уникальность и уникализировать медиа-контент мы расскажем в следующих статьях, а сегодняшняя целиком и полностью посвящена обзору онлайн сервисов для проверки текстового контента на уникальность.
Зачем это нужно?
Уникальность и актуальность контента стали не просто факторами ранжирования. Алгоритмы семантического анализа от основных поисковых систем шагнули далеко вперед. Важно понимать, что простой уникальности теперь недостаточно для того, чтобы поисковик полюбил ваш текст. Основываясь на моделях LSI, Google и Яндекс постоянно совершенствуют методики оценки релевантности текста тому или иному запросу. Если говорить очень грубо, то ваш текст должен иметь собственный стиль, речь должна быть живой — изобиловать синонимами и нестандартными словосочетаниями, а тема должна быть максимально раскрыта по сравнению с конкурентами. Эпоха массового прямолинейного рерайта подходит к своему концу — добавляя что-то новое и полезное в текстовый контент, вы увеличиваете шансы на лучшее ранжирование.
Что такое неуникальный текст (плагиат)?
С точки зрения поисковой системы плагиат — это размещение уже знакомого ей текста на другом ресурсе. Вроде бы все довольно просто, но здесь важно обратить внимание на несколько факторов:
Вроде бы все довольно просто, но здесь важно обратить внимание на несколько факторов:
1. Первоисточником (автором) считается тот сайт, где робот ПС впервые обнаружил контент. Зачастую сайт, который скопировал текст с вашего ресурса, может быть проиндексирован быстрее и именно он будет считаться первоисточником. Это довольно распространенная проблема для интернет магазинов с выгрузкой товаров партнерам в реальном времени — многие ваши страницы будут проиндексированы позже, чем на партнерских ресурсах и плагиатором для ПС будет как раз ваш сайт.
2. Ничего страшного в том, что текст с вашего сайта скопировали нет, если поисковая система считает ваш ресурс первоисточником.
3. Поисковики умеют распознавать некачественный рерайт, а сервисы для проверки уникальности далеко не идеальны.
Сервисы для проверки уникальности текста онлайн
1. Content watch — очень простой и удобный сервис. В бесплатной версии позволяет проверять текст длиной до 10 тысяч символов, до 7 проверок в день. В платной версии есть возможность автоматизированных проверок с помощью API, также разработчики выпустили плагины для популярных CMS, что довольно удобно. Удобная реализация проверки текста по имени сайта с подбором страниц, однако, эта функция доступна только для зарегистрированных пользователей.
Content watch — очень простой и удобный сервис. В бесплатной версии позволяет проверять текст длиной до 10 тысяч символов, до 7 проверок в день. В платной версии есть возможность автоматизированных проверок с помощью API, также разработчики выпустили плагины для популярных CMS, что довольно удобно. Удобная реализация проверки текста по имени сайта с подбором страниц, однако, эта функция доступна только для зарегистрированных пользователей.
2. Text.ru — дизайн сайта придется по душе пользователям, которые помнят времена доступа в интернет по dial-up модему. Но при всей своей архаичности, функционал сайта идет в ногу со временем. Кроме проверки на уникальность также доступна масса полезных сервисов для анализа контента — проверка орфографии, подбор синонимов, анализ водности и заспамленности. Для проверки сайта по url или использования API придется зарегистрироваться. Сайт показывает сколько проверок в очереди перед вами, из-за чего временами на получение результата может уйти довольно внушительное время.
3. Copyscape — отличный сервис для проверки как русскоязычного, так и англоязычного контента. Работает очень шустро, очередей не замечено. Однако, просто проверить только что написанный текст у вас не получится — нужно ввести ссылку на страницу в сети, где он размещен. Данная особенность порой сводит на нет все преимущества работы сервиса. Также имеет ограничение по количеству проверок в бесплатной версии.
4. Pr-cy — без регистрации не дает поверить текст длиной более 1000 символов, временами даже на правильный ввод капчи реагирует сообщением об ошибке. Огромный минус в том, что сервис показывает только доменное имя источника заимствования, а не конкретную страницу. То есть вам еще нужно будет приложить усилия для нахождения непосредственно страницы с совпадающим контентом на том домене, что показывает pr-cy. В общем юзабилити на уровне.
5. Антиплагиат — после регистрации доступна загрузка файла с текстом, а также классическая проверка текста. Скорость проверки оставляет желать лучшего. Очень подозрительно дает 100% уникальности и не находит заимствований для тех текстов, уникальность которых была не так однозначна для остальных вышеперечисленных сервисов.
Скорость проверки оставляет желать лучшего. Очень подозрительно дает 100% уникальности и не находит заимствований для тех текстов, уникальность которых была не так однозначна для остальных вышеперечисленных сервисов.
6. Plagiarisma — до регистрации функционал крайне беден: проверка происходит только по индексу Yahoo, на каких сайтах найдены совпадения вы не увидите. После регистрации возможна проверка по индексу Google, проверка по url и загрузка файла с текстом. Даже после регистрации сохраняется ограничение по длине анализируемого текста — всего 2000 символов. По утверждению создателей, сервис поддерживает 190 языков.
7. Advego — некогда лучший и любимый многими сервис по проверке контента. Онлайн версия от advego просит раскошелиться — необходимо купить определенное количество символов, при каждой проверке с вашего баланса будет вычитаться количество символов анализируемого текста. Споры по поводу актуальности алгоритмов Advego не утихают по сей день. Тем не менее для комплексного анализа текстового контента этот сервис вполне достоин занять свое место в вашем наборе инструментов.
Тем не менее для комплексного анализа текстового контента этот сервис вполне достоин занять свое место в вашем наборе инструментов.
Резюме:
Идеальных онлайн сервисов для проверки на плагиат не существует. У опытных оптимизаторов и копирайтеров есть большие вопросы к алгоритмам работы каждого из описанных в данной статье инструментов. Мы советуем попробовать каждый и сделать ваши тексты интересными и уникальными. Желаем удачи!
Комментарии
Комментарии
Проверенные сайты антиплагиата — 5 лучших сервисов
Антиплагиат ру, без сомнения, уникальный ресурс, первый появившийся в стране онлайн сервис, который охватил все ВУЗы России. Бесспорный лидер в своей области.
На сайте антиплагиат ру, можно быстро и бесплатно проверить текст на антиплагиат, причем любого объема. Есть небольшие ограничения при работа с бесплатной версией
1) Загружать бесплатно в антиплагиат ру можно только в пдф или тхт формате
2) После каждой проверки, нельзя сразу проверить вторую работу, нужно подождать 6 минут
Подходит ли сайт антиплагиат ру студентам?
Сайт антиплагиат ру, без сомнения, это лучший сайт антиплагиата для студентов, и причин тому множество.
На начало 2021 года, 95% вузов России используют при проверке именно сайт антиплагиат ру(точнее они используют расширенную, полную версию сайта антиплагиат ру, которая называется Антиплагиат ВУЗ, но мы их будем назваться под одним названием)
Поэтому на вопрос, какой проверенный антиплагиат использовать для проверки текста на уникальность студенту – отвечаем однозначно, сайт Антиплагиат ру.
Это бесплатный сайт, без сомнения проверенный временем, и самое главное именно им пользуются преподаватели.
Основной акцент при анализе документов на уникальность, антиплагиат ру делает именно на курсовые и дипломные работы, которые выложены в открытом доступе в интернете. Это еще одни причина того, почему он показывает правильный процент.
Еще одним плюсом того, почему стоит использовать антиплагит ру студенту, это тот факт, что антиплагиат ру, показывает более высокую оригинальность, по сравнению с другими системами проверки,о которых мы расскажем дальше. Т.е проходную планку процентов, вам набрать будет проще.
Мы подготовили для вас полную инструкцию пользования сайтом Антиплагиат ру.
Подходит ли сайт Антиплагиат ру веб-мастерам и программистам?
Вот тут уже картина совершенно иная. Сайт антиплагиат ру совершенно не пригоден для работы веб-мастеров и программистов.
Все дело в том, что при проверке уникальности текста для учебных заведений, важна проверка именно по базам курсовых и дипломных работ, а веб-мастерам, эти базы интересны в последнюю очередь.
Веб-мастерам важнее проанализировать весь интернет, все текста рунета, и сделать статью для сайта уникальной во всей сети. Только так, ее можно продвинуть в поисковиках Яндекс и ГУГЛ.
А антиплагиат ру, акцент делает именно на базы курсовых и дипломных работ, и зачастую контент со страниц обычных сайтов в антиплагиат ру проскакивает, и показывает высокую оригинальность.
Одним словом, веб мастера и программисты не должны использовать при проверке своего контента, пусть даже и проверенный сайт антиплагиат ру, иначе они могут пойти по неверному пути. Дело не в репутации сайта, а в системе его анализа.
Проверить работу в Антиплагиат ВУЗ
Антиплагиат вуз, как мы уже ранее говорили, это копия сайта Антиплагиат ру. Ей пользуются преподаватели вузов, при проверке работ на уникальность.
массовая проверка уникальности списка URL-адресов (страниц сайта) между собой
BatchUniqueChecker предназначен для массовой проверки уникальности содержимого на страницах из списка URL-адресов или файла Sitemap.
Показать различия между выбранными URL-адресами
Проверка уникальности двух текстов
Настройки
Условия использования: Freeware
Основные характеристики
- Проверить уникальность содержимого в URL из списка любого размера
- Импортировать список URL-адресов из файла Sitemap.xml или добавить вручную
- Инструмент может использоваться для анализа только «значимого» текста (внутри абзацев HTML) с веб-страниц.

- Определите различия между любыми двумя выбранными URL-адресами
- Установка длины черепицы (от 1 до 10 слов на черепицу)
- Экспорт отчетов в Excel (формат CSV)
Отличия от аналогов
- Многопоточность и быстрая проверка URL
- Portable format (работает без установки с любого внутреннего или внешнего накопителя)
- Бесплатное программное обеспечение
История версий
Версия 1.3 (сборка 21), 25.02.2021:
- Исправлена некорректная работа программы с потоками
- количество ошибок проверки URL должно быть значительно меньше
Версия 1.3 (сборка 20), 07.12.2020:
- Исправлена проблема с некорректным использованием пауз между запросами к веб-страницам
- доработан и улучшен перевод
- обновленный сплиттер (визуальный делитель)
Версия 1. 2 (сборка 19), 27.10.2020:
2 (сборка 19), 27.10.2020:
- улучшенный алгоритм определения «содержательных» текстов
- мы добавили возможность перепроверки URL-адресов завершенных с ошибками
- мы добавили возможность отображать URL-адреса, наиболее близкие по уникальности к выбранному
- добавлено сравнение уникальности двух произвольных текстов (вкладка Настройки)
Версия 1.1 (сборка 16), 25.10.2020:
- мы добавили два способа получения контента для проверки уникальности: полнотекстовый поиск (PlainText) и «осмысленный» (содержательные предложения и разделы текста) Контент веб-страницы
- легче загружать благодаря поддержке User-Agent
- теперь можно отключить стоп-слова
Версия 1.0 (сборка 5), 14.10.2020:
- многопоточная проверка страниц в списке URL (до 10 потоков одновременно)
- импортировать URL-адреса из Sitemap.xml или txt-файла или вставить их вручную из буфера обмена
- сравнить любые два URL-адреса и отобразить их различия
- уникальность URL визуализируется разными цветами в таблице результатов и на графике
- экспорт результатов в Excel (CSV)
Минимальные системные требования
— 1 ГБ ОЗУ (рекомендуется 8 ГБ и больше)
— Microsoft Windows 10/8/7 / Vista / XP
— Интернет
Твиттер
<< Назад
Как проверить дублированный контент: инструменты и советы
Вы, наверное, знаете, что ваш сайт всегда должен содержать оригинальный контент. Если ваш сайт содержит дублированный контент, это огромная ошибка, которая может навредить вашему рейтингу и репутации. Плагиат или выдача чужой работы за свою без разрешения недопустимы как в Интернете, так и в автономном режиме. Дублированный контент может привести к тому, что Google оштрафует вас, понизив рейтинг вашей страницы или полностью исключив вашу веб-страницу из результатов поиска.Это вообще противоречит цели публикации контента.
Еще одна возможность, которую вы должны учитывать, заключается в том, что другие могут дублировать контент на вашем сайте и пытаться использовать его без вашего разрешения. Эти недобросовестные маркетологи могут откровенно использовать контент, который вы создали на их веб-сайтах, даже не спрашивая вас и не сообщая вам об этом, и в конечном итоге они могут превзойти вас в рейтинге поисковых систем.
Как определяется повторяющееся содержимое?
Дублированный контент — это контент, который появляется более чем в одном месте в Интернете, то есть на разных веб-сайтах.Если вы публикуете свой собственный контент более чем в одном месте, у вас будет дублированный контент. Если вы копируете чужой контент на свой сайт или они публикуют ваш на своем сайте, это дублированный контент.
Поисковым системам может быть сложно определить, какой контент более релевантен запросу в поисковой системе, когда контент слишком похож. Цель поисковых систем — предоставить пользователям наилучшие возможные результаты при поиске определенного термина. Google и другие поисковые системы могут исключить дублирующийся контент из своих поисковых запросов.
Некоторые причины дублирования содержимого
Во многих случаях использование дублированного контента не является преднамеренным или преднамеренным. Google относится к дублированному контенту как к идентичным или «в значительной степени похожим» блокам текста внутри или между доменами. Примеры не вредоносного дублированного контента включают описания товаров в магазине и версии веб-страниц только для печати.
Примеры не вредоносного дублированного контента включают описания товаров в магазине и версии веб-страниц только для печати.
Умышленное дублирование контента — другое дело. Когда один и тот же контент используется в нескольких доменах в попытке увеличить трафик или манипулировать рейтингом в поисковых системах, это может расстраивать людей, которые пытаются искать информацию и в конечном итоге получают один и тот же контент в нескольких местах.Вот почему поисковые системы делают все возможное, чтобы воспрепятствовать этой практике.
Использование Google для проверки дублированного содержания
Один из быстрых способов проверить, может ли страница считаться дублирующейся, — это скопировать около десяти слов из начала предложения и затем вставить их с кавычками в Google. На самом деле это рекомендованный Google способ проверки.
Если вы протестируете это для страницы на своем веб-сайте, вы ожидаете, что будет отображаться только ваша веб-страница и, в идеале, без других результатов.
Если другие веб-сайты отображаются не хуже вашего, Google намекает, что считает, что исходный источник — это результат, который он показывает первым. Если это не ваш веб-сайт, возможно, у вас проблема с дублированием контента.
Повторите этот процесс, протестировав несколько случайных коротких предложений текста с вашей веб-страницы в Google.
Бесплатные инструменты для проверки дублированного содержимого
Когда вы пишете свой контент, вы можете непреднамеренно сделать его слишком похожим на уже опубликованный контент.Всегда полезно дважды проверять все, что вы пишете, с помощью средств проверки на плагиат, чтобы убедиться, что ваш контент рассматривается как уникальный. Некоторые из этих инструментов доступны бесплатно.
Вот несколько хороших бесплатных инструментов, которые можно использовать для проверки дублированного контента:
Copyscape — этот инструмент может быстро сравнить написанное вами содержимое с уже опубликованным за считанные секунды. Инструмент сравнения выделит контент, который отображается как повторяющийся, и сообщит вам, какой процент вашего контента соответствует уже опубликованному контенту.
Plagspotter — этот инструмент может определять повторяющиеся страницы контента в Интернете. Это отличный инструмент для поиска плагиатов, укравших ваш контент. Это также позволяет вам еженедельно автоматически отслеживать ваши URL-адреса для выявления дублирующегося контента.
Duplichecker — этот инструмент быстро проверяет оригинальность контента, который вы планируете разместить на своем сайте. Зарегистрированные пользователи могут выполнять до 50 поисков в день.
Siteliner — это отличный инструмент, который может проверять весь ваш сайт один раз в месяц на наличие дублированного контента.Он также может проверять неработающие ссылки и определять страницы, которые наиболее заметны для поисковых систем.
Smallseotools — доступны различные инструменты SEO, в том числе средство проверки на плагиат, которое идентифицирует фрагменты идентичного контента.
И если вы хотите копнуть глубже, эти ссылки также предлагают больше инструментов по доступной цене.
Премиум-инструменты для проверки на плагиат
Премиум-программы для проверки на плагиат имеют возможность проверять дублированный контент с помощью передовых алгоритмов.Они дают вам уверенность в том, что ваша работа не будет приписана тому, кто ее не писал.
Премиум-инструменты для борьбы с плагиатом обычно предлагают отчеты, которые могут подтвердить подлинность. Будущие выводы о том, что ваша работа не является оригинальной, могут противоречить этим отчетам, которые можно сохранить в формате PDF.
Примеры дополнительных инструментов для проверки дублированного контента:
Grammarly — их премиальный инструмент предлагает как средство проверки на плагиат, так и проверку грамматики, выбора слов и структуры предложения.
Plagium — Предлагает бесплатный быстрый поиск или глубокий поиск премиум-класса.
Plagiarismcheck.org — обнаруживает точные совпадения и перефразированный текст.
Ваш контент был очищен?
Содержимое вашего веб-сайта должно быть полностью оригинальным, и указанные выше инструменты могут помочь вам убедиться, что вы случайно не сделали свой контент слишком похожим на контент, который появляется на чужом веб-сайте.
Другая причина постоянно проверять дублирующийся контент — это веб-сайты, которые намеренно крадут контент из чужого блога, чтобы использовать его самостоятельно.Обычно это делается с помощью автоматизированного программного обеспечения. Если у вас есть привычка проверять контент на своем собственном сайте, вы можете обнаружить, что часть его была очищена. Как можно ловить парсеры контента? Что делать, если вы обнаружите, что ваш контент дословно опубликован на чужом сайте?
Способы отлова скребков
Регулярное использование премиальных инструментов для борьбы с плагиатом может помочь вам найти контент, который вы написали на чужом сайте.Есть еще несколько способов отловить скопированный контент.
Обратные ссылки в WordPress могут отображаться в спаме, если вы используете Askimet. Когда ваш контент всегда включает ссылки на некоторые из ваших других сообщений, вы можете найти таким образом парсеры контента.
Воспользуйтесь инструментами для веб-мастеров и проверьте ссылки на свой сайт. Когда у вас есть большое количество ссылок с определенного сайта, вы можете обнаружить, что часть вашего контента была скопирована на их. Единственный способ быть уверенным — это посетить их сайт и проверить, какие страницы ссылаются на ваш сайт.Вы можете найти свой собственный контент на их сайте.
Используйте Google Alerts, чтобы получать уведомления, если какие-либо заголовки ваших сообщений появляются в Интернете после того, как ваш контент уже был опубликован.
Чем больше вы утвердитесь в качестве авторитета в своей нише, тем больше вы можете обнаружить, что те, кто еще не утвердил свой собственный голос или авторитет, хотят позаимствовать ваш. Это позволяет им предоставлять авторитетную информацию в своем блоге, не прилагая усилий для создания качественного контента.
Что делать с парсерами контента
Очистка содержимого неэтична. Как только вы обнаружите, что ваш контент был очищен, у вас есть несколько вариантов того, что вам следует делать.
Свяжитесь с владельцем веб-сайта, на котором опубликовано ваше содержание, и сообщите ему, что вы нашли его на его сайте. Владелец сайта может не знать, что на его сайт был добавлен украденный контент, поэтому дайте ему возможность сомневаться. Вы можете связаться с ними через их контактную форму или через любую из социальных сетей, в которых они участвуют.
Если это качественный сайт, дайте им возможность поддерживать контент в актуальном состоянии, указав вас как автора и ссылку на ваш сайт. Другой вариант — предложить написать исправленную статью в обмен на ссылку. Если это некачественный сайт, сообщите им, что вы хотите, чтобы ваш контент был немедленно удален.
Если нет очевидного способа связаться с владельцем веб-сайта, выполните поиск в Whois. Это, вероятно, позволит вам узнать, кто они, если только он не зарегистрирован в частном порядке. Если вы все еще не можете узнать, кто является владельцем сайта, вы сможете узнать, кто его размещает, с помощью бесплатного инструмента Whoishostingthis.com. Свяжитесь с хостинговой компанией и сообщите им, что владелец веб-сайта публикует контент, защищенный авторским правом. Компании, предоставляющие веб-хостинг, серьезно относятся к подобным жалобам и своевременно предлагают помощь.
Защита содержимого с помощью DMCA
Вы обладаете авторскими правами на любой исходный контент, который вы публикуете на своем сайте. Один из способов защитить себя — разместить на своем сайте значок DMCA. DMCA гласит, что они бесплатно удалят ваш контент, если ваш контент будет украден, пока он защищен одним из их значков.
DMCA помогает сдерживать воров и предлагает инструменты, которые помогут вам найти неавторизованные копии вашего контента на чужом сайте. Они быстро удалят плагиат, включая изображения и видео.
Последние мысли о повторяющемся содержании
Люди, которые выходят в Интернет за информацией, ожидают найти оригинальный и полезный контент, и именно это они должны быть в состоянии найти. По возможности следует избегать дублирования контента. Контент должен быть хорошо написан и уникален, чтобы читатели могли получить максимум удовольствия от работы в сети.
Связанные
Уникальный контент: что вы должны знать
Краткое объяснение:
Уникальный контент — это термин, относящийся к поисковой оптимизации (SEO). Это означает, что контент является оригинальным и больше нигде не дублируется. Уникальный контент играет ключевую роль в поисковом рейтинге, потому что алгоритмы поиска высоко оценивают уникальный контент и могут наказывать веб-сайты за публикацию дублированного контента.
Подробное объяснение:
Противоположность уникальному контенту — это дублированный контент.Дублированный контент — это идентичный контент, который публикуется более чем на одном веб-сайте. В то время как уникальный контент может улучшить позицию веб-сайта на страницах рейтинга поисковых систем, дублированный контент может уменьшить его. Фактически, Google может даже удалять сайты с повторяющимся содержанием из своего поискового индекса.
Люди ищут информацию в Интернете, и поисковые системы, такие как Google, хотят предоставить своим пользователям наилучшее соответствие их содержанию. Они разработали сложные алгоритмы для определения сайтов с наивысшим качеством контента, чтобы обеспечить наилучший пользовательский интерфейс для своих клиентов.Когда веб-сайты пытаются обмануть алгоритмы, дублируя контент, чтобы они могли занять более высокое место в результатах поиска, Google наказывает их.
Чтобы занять высокое место в поисковых системах, веб-сайты должны оптимизировать свой контент для SEO, используя ключевые слова и обращая внимание на качество и релевантность своего контента. Хотя у них может возникнуть соблазн попытаться обмануть алгоритм, Google и другие поисковые системы вкладывают много времени и ресурсов, чтобы убедиться, что они сопоставляют правильный контент поисковому запросу.Создавая уникальный контент, который актуален и интересен читателю, сайты имеют больше шансов подняться на вершину рейтинга.
Уникальный контент от Textbroker
Textbroker специализируется на создании уникального контента, оптимизированного для SEO, и помогает компаниям подняться на вершину рейтинга поисковых систем. На рынке авторов есть эксперты по созданию контента практически по любой теме, который компании публикуют на своих собственных веб-сайтах или в каналах социальных сетей. Предоставляя оригинальную и интересную для читателей информацию, компании могут увеличить посещаемость своих веб-сайтов и увеличить продажи.Уникальный контент имеет абсолютный приоритет в Textbroker. Компания использует Copyscape, чтобы гарантировать, что нигде больше не существует контента и что все авторы создают оригинальные статьи.
Советы по созданию уникального контента
Написать уникальный контент несложно. Следуйте этим советам, чтобы контент был оригинальным и уникальным:
- Никогда не копируйте текст откуда-нибудь. Избегайте плагиата, цитируя исследования и используя свои слова для описания концепции.
- Всегда используйте несколько источников при исследовании.
- Придайте тексту уникальную структуру.
- Используйте свой неповторимый стиль.
- Используйте свои собственные рассуждения. Объясняйте вещи так, как вы их понимаете.
Заключение
Хотя дублированный контент может снизить рейтинг поиска, уникальный контент может его улучшить. Фактически, это необходимо для высокого ранжирования в органических результатах поиска. Такие компании, как Textbroker, предоставляют уникальные услуги по написанию контента, чтобы помочь компаниям создавать высококачественный контент, оптимизированный для поиска.
Избегайте дублирования содержимого | Центр поиска Google | Разработчики Google
Дублированный контент обычно относится к основным блокам контента внутри или между доменами. которые либо полностью соответствуют другому контенту, либо в значительной степени похожи. В основном это не обманчивое происхождение. Примеры не вредоносного дублированного контента могут включать:
- Дискуссионные форумы, которые могут создавать как обычные, так и урезанные страницы, ориентированные на мобильные устройства
- Товары в интернет-магазине, которые отображаются или связаны по нескольким отдельным URL-адресам
- Версии веб-страниц только для печати
Если ваш сайт содержит несколько страниц с практически идентичным содержанием, существует ряд способы указать предпочтительный URL для Google.(Это называется «канонизацией».) Больше информации о канонизация.
Однако в некоторых случаях контент намеренно дублируется между доменами в попытке манипулировать рейтингом в поисковых системах или получать больше трафика. Подобные обманчивые практики могут приводит к ухудшению пользовательского опыта, когда посетитель видит практически тот же контент повторяется в наборе результатов поиска.
Google изо всех сил пытается индексировать и показывать страницы с четкой информацией.Эта фильтрация означает,
например, если на вашем сайте есть «обычная» и «печатная» версии каждой статьи, и
ни один из них не заблокирован с помощью noindex тег, мы выберем один из них для включения в список. В тех редких случаях, когда Google считает, что
дублированный контент может быть показан с намерением манипулировать нашим рейтингом и обманывать наших пользователей,
мы также внесем соответствующие корректировки в индексирование и ранжирование задействованных сайтов. В виде
в результате может пострадать рейтинг сайта или он может быть полностью удален из
Индекс Google, и в этом случае он больше не будет отображаться в результатах поиска.
Есть несколько шагов, которые вы можете предпринять для упреждающего решения проблем с дублирующимся контентом и обеспечения чтобы посетители видели то, что вы им хотите.
- Используйте 301s : Если вы реструктурировали свой сайт, используйте 301 редирект («RedirectPermanent») в вашем файле .htaccess, чтобы правильно перенаправлять пользователей, робота Google и других пауков. (В Apache, вы можете сделать это с помощью файла .htaccess; в IIS это можно сделать через административную приставка.)
- Будьте последовательны : Старайтесь, чтобы ваши внутренние ссылки были последовательными. Например,
не ссылайтесь на
http://www.example.com/page/иhttp://www.example.com/pageиhttp://www.example.com/page/index.htm. - Используйте домены верхнего уровня : чтобы помочь нам обслуживать наиболее подходящую версию
document, по возможности используйте домены верхнего уровня для обработки контента для конкретной страны. Были
с большей вероятностью будет знать, что
http: // www.example.deсодержит контент, ориентированный на Германию, например, чемhttp://www.example.com/deилиhttp://de.example.com. - Тщательно распространяйте информацию : если вы распространяете свой контент на других сайтах, Google
всегда будет показывать версию, которая, по нашему мнению, наиболее подходит для пользователей в каждом заданном поиске,
который может быть или не быть той версией, которую вы предпочитаете. Однако полезно убедиться, что каждый
сайт, на котором синдицируется ваш контент, содержит обратную ссылку на вашу исходную статью.Ты
также можете попросить тех, кто использует ваш синдицированный материал, использовать
noindexтег, чтобы поисковые системы не индексировали свою версию содержания. - Минимизировать повторение шаблонов : Например, вместо включения длинный текст об авторских правах внизу каждой страницы, включая очень краткое изложение, а затем ссылка на страницу с более подробной информацией. Кроме того, вы можете использовать Параметр Инструмент обработки, чтобы указать, как вы хотите, чтобы Google обрабатывал параметры URL.
- Избегайте публикации заглушек : пользователям не нравится видеть «пустые» страницы, поэтому избегайте
заполнители там, где это возможно. Например, не публикуйте страницы, для которых у вас еще нет
реальный контент. Если вы действительно создаете страницы-заполнители, используйте
noindexтег, чтобы заблокировать индексирование этих страниц. - Изучите свою систему управления контентом : Убедитесь, что вы знакомы с как контент отображается на вашем веб-сайте.Блоги, форумы и связанные с ними системы часто показывают один и тот же контент в нескольких форматах. Например, запись в блоге может появиться на домашней странице блог, на странице архива и на странице других записей с таким же ярлыком.
- Свернуть похожее содержимое : Если у вас много похожих страниц, рассмотрите возможность расширения каждой страницы или объединения страниц в одну. Например, если у вас есть сайт о путешествиях с отдельными страницами для двух городов, но с одинаковой информацией на обеих страницах, вы можете либо объединить страницы об обоих городах в одну, либо развернуть каждый страница, содержащая уникальный контент о каждом городе.
Google не рекомендует блокировать доступ сканеров к дублированному контенту на вашем веб-сайте,
будь то файл robots.txt или другие методы. Если поисковые системы не могут сканировать страницы с
дублированный контент, они не могут автоматически определить, что эти URL-адреса указывают на один и тот же контент
и поэтому им придется рассматривать их как отдельные уникальные страницы. Лучшее решение
позволяет поисковым системам сканировать эти URL-адреса, но помечать их как дубликаты с помощью rel = "canonical" элемент ссылки, инструмент обработки параметров URL или 301 редирект.В случаях, когда дублирующийся контент приводит к тому, что мы сканируем слишком большую часть вашего веб-сайта, вы также можете
настроить сканирование
настройку скорости в Search Console.
Дублированный контент на сайте не является основанием для действий на этом сайте, если только не выяснится, что Цель дублированного контента — вводить в заблуждение и манипулировать результатами поиска. Если ваш сайт страдает от проблем с дублированием контента, и вы не следуете перечисленным советам выше, мы хорошо поработали над выбором версии контента, который будет отображаться в наших результатах поиска.
Однако, если наш обзор показал, что вы использовали обман, и ваш сайт был удален из результатов поиска, внимательно просмотрите свой сайт. Если ваш сайт был удален из результатов поиска, просмотрите наш веб-мастер Рекомендации для получения дополнительной информации. После внесения изменений и уверенности в том, что ваш сайт больше не нарушает наши правила, отправьте ваш сайт на пересмотр.
В редких случаях наш алгоритм может выбрать URL-адрес внешнего сайта, на котором размещается ваш контент без вашего разрешения.Если вы считаете, что другой сайт копирует ваш контент в нарушение закона об авторском праве вы можете обратиться к хозяину сайта с просьбой об удалении. В Кроме того, вы можете попросить Google удалить страницу, нарушающую авторские права, из результатов поиска, подача запроса в соответствии с Законом о защите авторских прав в цифровую эпоху.
Как бороться с дублирующимся контентом (включая проблемы, созданные вашей CMS)
Вы когда-нибудь беспокоились о дублировании контента?
Это может быть что угодно: какой-нибудь шаблонный текст на вашем веб-сайте.Или описание продукта на своей веб-странице электронной коммерции, которое вы позаимствовали у первоначального продавца. Или, может быть, цитата, которую вы скопировали из любимого сообщения в блоге или авторитетного источника в вашей нише.
Как бы вы ни старались предложить 100% уникальный контент, у вас ничего не получится.
Дублированный контент входит в пятерку основных проблем SEO, с которыми сталкиваются сайты, особенно сейчас, когда Google применил свое Panda Update.
Это правда: вы НЕ МОЖЕТЕ удалить все экземпляры дублированного контента на своих веб-страницах, даже если вы используете параметр rel canonical tag url.
Мэтт Каттс из Google заявил, что дублированный контент постоянно встречается в сети, от сообщений в блогах до веб-страниц и социальных сетей. Каттс заявил,
25-30% Интернета — это дублированный контент .
И Google это понимает.
Таким образом, не существует наказания GOOGLE ДУБЛИКАЦИОННОГО КОНТЕНТА.
Да, вы правильно прочитали.
Google не наказывает веб-сайты, использующие дублированный контент.То, что Google преследует сайты с X% дублированного контента, — это еще один миф SEO.
Теперь вы, вероятно, задаетесь вопросом: если Google не наказывает веб-сайты с дублированным содержанием, в чем вся суета вокруг ? Зачем нужны относительные канонические теги и управление контентом, чтобы у вас не было дубликатов?
Хотя Google не наказывает сайты за дублированный контент, он не поощряет его. Давайте посмотрим, почему Google не одобряет дублирование контента и их Panda Update, а затем рассмотрим различные способы решения проблем с дублированием контента на вашем сайте.От параметров URL до канонических тегов и идентификаторов сеансов — есть много способов уменьшить проблемы с дублированием контента.
Прежде чем мы начнем, давайте посмотрим, как Google определяет повторяющийся контент.
Что такое дублированный контентВот определение дублированного содержания в Google:
Дублированный контент обычно относится к основным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту, либо в значительной степени похожи.
Как вы можете понять из определения Google, Google выделяет два типа дублированного контента: первый тип встречается в одном домене, а другой — в нескольких доменах.
Вот несколько примеров, которые помогут понять дублированный контент и разные типы.
Экземпляры дублированного контента в одном доменеКак вы понимаете, дублированный контент такого типа встречается на вашем сайте электронной коммерции, в сообщениях в блогах или на веб-сайте.
Думайте о таком повторяющемся содержимом как об одном и том же содержимом, которое появляется на разных веб-страницах вашего сайта.
Может быть:
- Этот контент присутствует на вашем сайте в разных местах (URL).
- Или, возможно, он доступен разными способами (что приводит к другим параметрам URL). Например, это могут быть те же сообщения, которые отображаются при поиске по различным категориям и тегам на вашем сайте.
Давайте рассмотрим несколько примеров повторяющегося содержания различных типов на одном и том же сайте.
Содержание базовой плиты:Проще говоря, шаблонный контент доступен в разных разделах или веб-страницах вашего сайта.
Энн Смарти классифицирует содержимое Boilerplate как:
- (по всему сайту) глобальная навигация (главная, о нас и т. Д.)
- Определенные специальные области, особенно если они содержат ссылки (блогролл, навигационная панель)
- Разметка (javascript, идентификатор CC / имена классов, такие как верхний и нижний колонтитулы)
Если вы посмотрите на стандартный сайт, у него обычно есть верхний колонтитул, нижний колонтитул и боковая панель.В дополнение к этим элементам большинство CMS позволяют вам показывать ваши самые последние сообщения или самые популярные сообщения на вашей домашней странице.
Когда поисковые роботы просканируют ваш сайт, они поймут, что этот контент присутствует на вашем сайте несколько раз, и поэтому это действительно дублированный контент.
Но этот тип дублированного контента не вредит вашему SEO . Боты поисковых систем достаточно сложны, чтобы понимать, что намерение, стоящее за этим дублированием контента, не является злонамеренным.Итак, вы в безопасности.
Несовместимые структуры URL:Посмотрите на следующие URL-адреса —
www.yoursite.com/
yoursite.com
http://yoursite.com
http://yoursite.com/
https://www.yoursite.com
https://yoursite.com
Вам они кажутся одинаковыми?
Да, вы правы, целевой URL такой же. Итак, для вас они означают одно и то же. К сожалению, боты поисковых систем воспринимают их как разные URL-адреса.
Но когда боты поисковых систем сталкиваются с одним и тем же контентом на двух разных URL-адресах : http://yoursite.com и https://yoursite.com , они рассматривают это как дублированный контент.
Эта проблема относится и к параметрам URL, сгенерированным также для целей отслеживания:
http://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays
Параметры URLс отслеживанием также могут вызывать проблемы с дублированием контента.
Локализованные домены:Предположим, вы обслуживаете разные страны и создали локализованные домены для каждой обслуживаемой страны.
Например, у вас может быть версия вашего сайта .de для Германии и версия .au для Австралии.
Естественно, что содержание обоих сайтов будет частично совпадать. Если вы не переведете свой контент для домена .de, поисковые системы обнаружат, что ваш контент дублируется на обоих сайтах.
В таких случаях, когда поисковик ищет вашу компанию, Google покажет любой из этих двух URL.
Google часто видит статус поисковика. Предположим, что поисковик находился в Германии. По умолчанию Google показывает только ваш домен .de. Однако Google может ошибаться.
Экземпляры дублированного контента на разных доменах Скопировано:Копирование содержания с сайта (без разрешения) является неправильным, и Google так считает. Если вы не предлагаете ничего, кроме дублированного контента, ваш сайт будет в опасности, особенно сейчас, когда идет обновление Panda Update.Google может вообще не показывать его в результатах поиска или сбрасывать ваш веб-сайт с первых нескольких страниц результатов.
Курирование контента:Курирование контента — это процесс поиска историй и создания сообщений в блогах, релевантных вашим читателям. Эти истории могут быть откуда угодно в Интернете — от веб-страниц до социальных сетей.
Поскольку сообщение о курировании контента составляет список фрагментов контента со всего Интернета, естественно, что сообщение содержит дублированный контент (даже если это просто дублированные заголовки).В большинстве сообщений в блогах также используются выдержки и цитаты.
Опять же, Google не считает это СПАМом.
Пока вы предоставляете некоторую информацию, свежий взгляд или объясняете вещи в своем собственном стиле, Google не будет рассматривать это дублирование контента как злонамеренное, освобождая вас от беспокойства о необходимости добавлять относительные канонические теги, идентификаторы сеанса и т. Д. .
Синдикация контента:Синдикация контента становится все более популярной тактикой управления контентом.Курата обнаружил, что идеальный комплекс контент-маркетинга включает в себя 10% синдицированного контента.
По словам Search Engine Land, « синдикация контента — это процесс продвижения вашего блога, сайта или видеоконтента на сторонние сайты в виде полной статьи, фрагмента, ссылки или эскиза. ”
Сайты, которые объединяют контент, предлагают его контент для публикации на нескольких сайтах. Это означает, что существует несколько копий любого синдицированного сообщения.Это также верно и в отношении социальных сетей.
Если вы знакомы с публикацией Хаффингтона, то знаете, что она допускает распространение контента. Каждый день он публикует истории со всего Интернета и переиздает их с разрешения.
Buffer также объединяет контент. Их содержание переиздается на таких сайтах, как Huffington Post, Fast Company, Inc. и других.
На следующем снимке экрана показан трафик, который такой синдицированный контент приносит на их сайт.
Хотя эти случаи считаются дублированным контентом, Google не наказывает их.
Лучший способ синдицировать контент — это попросить переиздающие сайты объявить вас оригинальным создателем контента, а также дать обратную ссылку на ваш сайт с соответствующим текстом привязки, т. Е. На исходный фрагмент контента.
Очистка содержимого:Очистка контента всегда является серой зоной, когда вы обсуждаете проблемы с дублированным контентом.
Википедия определяет парсинг веб-страниц (или парсинг контента) как:
Веб-скрапинг (сбор веб-данных или извлечение веб-данных) — это программный компьютерный метод извлечения информации с сайтов.
Интересно, что даже Google собирает данные, чтобы сразу предложить их в первой поисковой выдаче.
Итак, неудивительно, что твит Мэтта Катта,
Если вы видите, что URL-адрес парсера превосходит исходный источник контента в Google, сообщите нам об этом…
создавал довольно много шума.
Дэн Баркер ответил этим твитом:
@mattcutts Мне кажется, я заметил одного, Мэтт. Обратите внимание на сходство в тексте содержания:
Как видите.Google извлекает контент из лучших результатов и показывает его прямо в поисковой выдаче. Это, без сомнения, списание контента.
Таким образом, не во всех случаях отказываться от скрапинга как злоупотребления служебным положением.
Однако, если вы пойдете немного глубже, вы увидите, что Google не приемлет сайты-парсеры контента, как указано в их Panda Update.
Теперь, когда у вас есть разумное представление о том, что считается дублированным содержанием, давайте рассмотрим случаи, которые не являются случаями дублирования содержания, но веб-мастера часто беспокоятся о них.
Что не считается повторяющимся содержанием Переведено содержание:Переведенное содержимое НЕ ЯВЛЯЕТСЯ ДУБЛИРОВАННЫМ содержимым. Если у вас есть сайт, вы локализовали его для разных стран и перевели основной контент на местные языки, вы не столкнетесь с проблемами дублирования контента.
Но этот пример не так прост. Если вы используете для перевода какое-либо программное обеспечение, инструменты для веб-мастеров или даже переводчик Google, качество перевода не будет идеальным.
И, когда перевод не имеет естественного смысла и не требует индивидуальной проверки, Google может рассматривать контент как спам или дублированный контент.
Такой контент может быть легко идентифицирован как созданный с помощью программного обеспечения и может поднимать флажки для Google.
Лучший способ избежать этой проблемы — привлечь к работе переводчика-человека. Или сделайте достойную работу с хорошим программным обеспечением, а затем передайте его на рассмотрение профессиональному переводчику.
Просматривая переведенный контент, вы убедитесь, что качество контента на высшем уровне, и Google не сочтет его дублирующимся.
Но, если по какой-то причине вы не можете сделать ни одно из двух, вам следует заблокировать программно переведенный контент от просмотра ботами с помощью robots.txt. (Я покажу вам, как это сделать в следующих разделах.)
Мобильный контент сайта:Если у вас нет адаптивного сайта, возможно, вы разработали отдельную мобильную версию для своего основного сайта.
Итак, у вас будут разные URL, обслуживающие одно и то же содержание, например:
http: ваш сайт.com — Веб-версия
http.m.yoursite.com — Мобильная версия
Наличие одного и того же контента в версиях веб-сайта и мобильной версии сайта не считается дублированным контентом. Кроме того, вы должны знать, что у Google есть разные поисковые боты, которые сканируют мобильные сайты, поэтому вам не нужно беспокоиться об этом случае.
Google может выявлять экземпляры дублированного контента, созданного со злым умыслом. Вы никогда не подвергаетесь риску, если не пытаетесь обмануть систему. Но вам все равно следует избегать случаев дублирования контента, поскольку они влияют на ваш SEO.
Вот как дублированный контент может повлиять на SEO:
Проблемы, вызванные дублированием содержимого Проблема № 1 — Снижение популярности ссылкиКогда вы не устанавливаете единообразную структуру URL-адресов для своего сайта, вы в конечном итоге создаете и распространяете различные версии ссылок на свой сайт, когда начинаете построение ссылок.
Чтобы лучше понять это, представьте, что вы создали эпический ресурс, который произвел тонну входящих ссылок и трафика из множества идентификаторов сеансов.
Тем не менее, вы не видите, что авторитет страницы этого первоисточника повысился так, как вы ожидали.
Почему авторитет страницы не вырос, несмотря на все ссылки и тягу?
Возможно, это не так, потому что разные сайты с обратными ссылками ссылались на ресурс, используя разные версии URL ресурса.
Нравится:
http://www.yoursite.com/resource
http://yoursite.com/resource
http://yoursite.com/resource
и так далее…
Вы видите, как непонимание управления дублированным контентом разрушило ваши шансы на создание страницы с более высоким авторитетом?
Все потому, что поисковые системы не могли интерпретировать, что все URL-адреса указывают на одно и то же целевое местоположение.
Проблема № 2 — Отображение недружественных URL-адресовКогда Google встречает два идентичных или существенно похожих ресурса в сети, он предпочитает показать один из них поисковику. В большинстве случаев Google выберет наиболее подходящую версию вашего контента. Но не каждый раз это получается правильно.
Может случиться так, что для определенного поискового запроса Google может показать не очень красивую версию URL вашего сайта.
Например, если пользователь искал вашу компанию в Интернете, какой из следующих параметров URL-адреса вы хотели бы показать посетителю:
http: // ваш сайт.com
или http://yoursite.com/overview.html
Думаю, вам будет интересно показать первый вариант.
Но Google может просто показать второй.
Если бы вы в первую очередь избегали дублирования контента, не было бы этой путаницы, и пользователь увидел бы только лучшую и наиболее брендированную версию вашего URL.
Проблема № 3 — Отключение ресурсов сканера поисковой системыЕсли вы понимаете, как работают сканеры, вы знаете, что Google отправляет своих поисковых мета-роботов для сканирования вашего сайта в зависимости от частоты публикации свежего контента.
Теперь представьте, что сканеры Google посещают ваш сайт и просматривают пять URL-адресов только для того, чтобы обнаружить, что все они предлагают одинаковый контент.
Когда поисковые роботы обнаруживают и индексируют один и тот же контент в разных местах вашего сайта, вы теряете циклы сканирования. Понимая дублированный контент, поисковые роботы не будут сканировать ваш новый контент.
В противном случае эти циклы обходчика могли бы использоваться для обхода и индексации любого недавно опубликованного контента, который вы могли добавить на свой сайт.Это не только приведет к потере ресурсов сканера, но и нанесет ущерб вашему SEO.
Как Google обрабатывает дублированный контентКогда Google находит идентичные экземпляры контента, он решает показать один из них. Выбор ресурса для отображения в результатах поиска будет зависеть от поискового запроса.
Если на вашем сайте такое же содержание и вы также предлагаете его печатную версию, Google рассмотрит, заинтересован ли поисковик в печатной версии. Если это так, будет получена и представлена только печатная версия контента.
Вы могли заметить сообщения в поисковой выдаче о том, что другие похожие результаты не были показаны. Это происходит, когда Google выбирает одну из нескольких копий аналогичного контента на разных веб-страницах.
Дублированный контент не всегда рассматривается как СПАМ. Это становится проблемой только тогда, когда целью является злоупотребление, обман и манипулирование рейтингом в поисковых системах.
Google серьезно относится к дублированному контенту и может даже заблокировать ваш сайт, если вы попытаетесь обмануть поисковую систему, используя дублированный контент.
Политика Google в отношении дублированного содержания гласит:
В тех редких случаях, когда Google считает, что дублированный контент может быть показан с намерением манипулировать нашим рейтингом и обмануть наших пользователей, мы также внесем соответствующие корректировки в индексирование и ранжирование задействованных сайтов. В результате может пострадать рейтинг сайта или сайт может быть полностью удален из индекса Google, и в этом случае он больше не будет отображаться в результатах поиска.
Как вы видели выше, большинство случаев дублирования контента происходит непреднамеренно.Даже вы можете использовать шаблонный текст на своем сайте. Кроме того, возможно, что различные сайты, социальные сети или сообщения в блогах копируют и повторно публикуют ваш контент без вашего разрешения.
Есть разные способы проверить свой сайт на наличие проблем с дублирующимся контентом. Давайте рассмотрим несколько вариантов.
Как определить проблемы с дублированным контентом Метод № 1. Выполните простой поиск в GoogleСамый простой способ обнаружить проблемы с дублированным контентом на вашем сайте — это выполнить простой поиск в Google.
Просто найдите ключевое слово, по которому вы ранжируете, и наблюдайте за результатами поисковой системы. Если вы обнаружите, что Google показывает неудобный для пользователя URL-адрес вашего содержания, значит, на вашем сайте дублированный контент.
Метод № 2: Ищите предупреждения в Google WebmastersИнструмент для веб-мастеров Google Search Console также заранее предупреждает вас о случаях дублирования контента на вашем сайте.
Чтобы найти предупреждения Google о дублированном содержании, войдите в свою учетную запись Google для веб-мастеров.Если вы уже вошли в систему, вы можете просто нажать на эту ссылку.
Метод 3. Проверьте показатели Crawler на панели инструментов веб-мастеровПоказатели поискового робота показывают количество страниц, просканированных поисковыми роботами Google на вашем сайте.
Если вы видите, что роботы сканируют и индексируют сотни страниц на вашем сайте, а у вас их всего несколько, возможно, вы используете несогласованные URL-адреса или текст привязки или не используете относительные канонические теги.И, следовательно, сканеры поисковых систем просматривают один и тот же контент несколько раз по разным URL-адресам.
Чтобы просмотреть показатели сканера , войдите в свою учетную запись Google Webmasters, нажмите на параметр Сканировать на левой панели. В развернутом меню выберите параметр Crawl Stats .
Если при использовании этого инструмента для веб-мастеров вы видите необычно высокую активность поисковых роботов, вам следует проверить структуру URL-адресов и посмотреть, не используются ли на вашем сайте несовместимые URL-адреса.
Метод 4: Кричащая лягушкаScreaming Frog — это инструмент для веб-мастеров по SEO-аудиту, который сканирует ваш сайт так же, как поисковые роботы. С его помощью можно выявить несколько типов повторяющегося контента и проблемы с параметрами URL.
шагов по использованию Screaming Frog для поиска повторяющихся проблем с контентом:
1. Посетите официальный сайт Screaming Frog и загрузите копию, совместимую с вашей системой.
Обратите внимание, что бесплатную версию Screaming Frog можно использовать для сканирования до 500 веб-страниц.Этого достаточно для большинства сайтов.
2. После установки программы откройте ее и введите URL-адрес своего сайта. Щелкните start.
3. После того, как Screaming Frog просканирует ваш сайт, вы можете щелкнуть по полю, которое вы хотите проверить на дублированный контент, такой как URL-адреса, заголовки страниц, якорный текст, метаописания и так далее.
После выбора поля выберите повторяющийся фильтр. Используя этот метод, вы можете обнаружить все случаи дублирования контента на вашем сайте.
Метод 5. Поиск блоков содержимогоЭтот метод несколько грубоват, но если вы подозреваете, что ваш контент копируется на разных сайтах или в сообщениях в блогах, или присутствует в разных местах вашего сайта, вы также можете попробовать его.
Скопируйте случайный текстовый блок из своего контента и выполните простой поиск в Google. Не забывайте не использовать длинные абзацы, так как они вернут ошибку.
Выберите абзац из 2–3 предложений и поищите его в Google.
Если результаты поиска показывают, что ваш контент публикуется на разных сайтах, вероятно, вы стали жертвой плагиата.
Используя вышеуказанные методы, вы можете легко определить проблемы с дублирующимся контентом на своем сайте. Теперь давайте взглянем на некоторые решения для решения проблем с дублированием контента.
4 решения проблемы дублирования контента 1. СогласованностьКак вы видели в предыдущем разделе, большинство случаев дублирования контента происходит, когда структура URL-адреса несовместима.
Лучшее решение здесь — стандартизация предпочитаемой структуры ссылок, а также правильное использование канонических тегов. Это может быть версия с www или без www. Или, может быть, версия HTTP или HTTP — что бы это ни было, она должна быть согласованной.
Вы можете сообщить Google предпочитаемую версию URL-адреса, установив свои предпочтения в своей учетной записи Google Webmasters.
После входа в систему нажмите на значок настроек в правом верхнем углу. Затем выберите Параметры сайта .
Здесь вы можете увидеть возможность установить предпочтительный домен:
Преимущества настройки предпочтительного домена:
- Сортировка проблем с дублирующимся контентом в версиях с www и без www
Теперь вы знаете, что боты Google рассматривают yoursite.com и www.yoursite.com как две разные страницы и считают один и тот же контент на них дублированным.
Просто установив предпочтительный домен, вы можете попросить Google просто просканировать и проиндексировать один из них, а также исключить весь риск дублирования контента.
Установка предпочтительного домена помогает вашему сайту сохранять ссылочный вес даже тогда, когда сайт с обратными ссылками ссылается на нежелательную версию вашего сайта.
Выдержка из ресурса Google:
Например, если вы укажете предпочтительный домен как http://www.example.com и мы найдем ссылку на ваш сайт в формате http://example.com, мы перейдем по этой ссылке как http: // www.example.com вместо этого.
Кроме того, мы учтем ваши предпочтения при отображении URL-адресов.Если вы не укажете предпочтительный домен, мы можем рассматривать версии домена с префиксом www и без него как отдельные ссылки на отдельные страницы.
Выбор предпочтительного домена Google в значительной степени устраняет несоответствия между версиями вашего сайта с префиксом www и без него.
После установки предпочтительного домена в Инструментах Google для веб-мастеров следующим шагом должно стать настройка 301 редиректа со всех ссылок на нежелательные домены на вашем сайте на предпочтительные. Это поможет поисковым системам и посетителям узнать о предпочитаемой вами версии.
Однако могут быть и другие несоответствия, о которых я упоминал выше. Чтобы разобраться в них, вам следует не просто выбрать предпочтительную версию URL-адреса, но также выбрать точный синтаксис и параметры URL-адреса, которые ваша команда должна использовать при ссылке на любой контент на вашем сайте.
У вас также может быть руководство по стилю, которое можно распространять внутри компании, чтобы показать стандартный способ совместного использования URL-адресов. По сути, всякий раз, когда вы делитесь ссылкой на любую страницу или публикацию на своем сайте, вы должны убедиться, что каждый раз используется один и тот же формат ссылки и текст привязки.
Помните, что поисковые системы могут обрабатывать эти веб-страницы по-разному: http://www.yoursite.com/page/ и http://www.yoursite.com/page и http://www.yoursite.com/page/index .htm. Так что выберите одно и придерживайтесь его.
2. Канонизация
Большинство CMS позволяют организовать контент с помощью тегов и категорий. Часто, когда пользователи выполняют поиск по тегам или категориям, появляются те же результаты. В результате роботы поисковых систем могут подумать, что оба URL-адреса предлагают одинаковый контент.
http://www.yoursite.com/some-category
и
http://www.yoursite.com/some-tag
Эта проблема более серьезна на сайтах электронной коммерции, где один продукт можно найти с помощью нескольких фильтров (что приводит к нескольким возможным параметрам URL).
Это правда, что категории, теги, фильтры и окна поиска помогают организовать контент и упростить посетителям сайта поиск того, что им нужно.
Но, как вы можете видеть на скриншоте выше, такой поиск по сайту электронной коммерции приводит к множеству параметров URL и, таким образом, вызывает проблемы с дублированным контентом.
Когда люди ищут контент в Google, эти многочисленные ссылки могут сбить с толку ботов Google Panda Update, и Google может в конечном итоге показать недружелюбную версию вашего ресурса, например http://www.yoursite.com/?q=search term в результатах поиска.
Чтобы избежать этой проблемы, Google рекомендует добавить канонический тег к предпочтительному URL-адресу вашего содержания.
Когда бот поисковой системы переходит на страницу и видит канонический тег, он получает ссылку на исходный ресурс.Кроме того, все ссылки на любую повторяющуюся страницу считаются ссылками на исходную страницу-источник. Таким образом, вы не потеряете SEO-ценность этих ссылок.
Канонические теги могут быть реализованы несколькими способами:
Метод 1. Установите предпочтительную версию: www и без wwwУстановка предпочтительной версии вашего домена, как мы обсуждали в предыдущем разделе, также является формой канонизации.
Но, как вы понимаете, он касается только очень широкой проблемы.Он не решает проблемы с дублированным контентом, создаваемые системой управления контентом.
Метод 2. Вручную укажите каноническую ссылку для всех страницВ этом методе вы должны начать с определения исходного ресурса. Исходный ресурс — это веб-страница, которую вы хотите предоставлять своим читателям каждый раз, когда они ищут.
Исходный ресурс — это также страница, которую вы хотите установить в качестве предпочтительной страницы, чтобы сигнализировать ботам поисковых систем. Этого можно добиться с помощью канонических тегов.
Используйте методы, перечисленные в приведенном выше разделе, для выявления экземпляров дублированного контента на вашем сайте. Затем определите страницы, которые предлагают похожий контент, и выберите исходный ресурс для каждой.
После двух описанных выше шагов вы будете готовы использовать канонический тег.
Для этого вам нужно будет получить доступ к исходному коду ресурса и в его теге
добавить следующую строку:Здесь «https: // yoursite.com.com/category/resource » — это страница, которую вы хотите назвать исходным ресурсом.
Вы будете следовать тому же процессу добавления относительных канонических тегов на каждую похожую страницу.
Мой блог на CrazyEgg поддерживает категории. Таким образом, сообщения доступны через список блогов на главной странице, а также через различные категории.
Я использую тег rel = canonical, чтобы отмечать предпочтительный URL для каждой страницы и сообщения.
Посмотрите на следующий снимок экрана с тегом:
Использование канонического тега — это простой способ сообщить Google о ссылке, которую вы хотите, чтобы Google показывал пользователям при поиске.
Как вы, наверное, догадались, мой сайт построен на WordPress, и я использую плагин Yoast SEO. Этот плагин позволяет вам установить предпочитаемую версию каждой страницы и публикации. Таким образом, вам не нужно беспокоиться о том, что ваше сообщение будет доступно или появится по разным URL-адресам.
Если ваш сайт построен на WordPress, я рекомендую вам установить этот плагин. Вы можете найти опцию канонического тега URL в расширенных настройках плагина.
Если сообщение или страница, которую вы создаете, сами по себе являются предпочтительной версией, оставьте тег Canonical URL пустым.Если это не так, добавьте ссылку на предпочтительный ресурс в поле Canonical URL .
Метод 3. Настройка 301 редиректаЧасто реструктуризация сайтов приводит к дублированию контента. Реструктуризация формата ссылок также может создать несколько копий одного и того же контента.
Чтобы уменьшить влияние таких проблем с дублированием содержимого, настройте переадресацию 301. 301 редирект с нежелательных URL-адресов ресурса на их предпочтительные URL-адреса — отличный способ предупредить поисковые системы о ваших предпочтениях.
Когда бот поисковой системы переходит на страницу и видит редирект 301, он достигает исходного ресурса через страницу с дублированным контентом. В таких случаях все ссылки на дублирующую страницу обрабатываются как ссылки на исходную страницу (значение SEO не теряется).
В зависимости от вашего сайта вы можете использовать эти разные способы для настройки 301 редиректа. Если у вас есть какие-либо вопросы о настройке переадресации, ваш веб-хостинг сможет вам помочь.
Если вы используете WordPress, вы можете использовать плагин, например Redirection, для создания 301 редиректа.
Какой бы метод вы ни выбрали, я бы посоветовал провести тест на неработающие ссылки, поскольку настройка переадресации может пойти не так.
3. Метатег NoindexМета-теги — это способ для веб-мастеров предоставить поисковым системам важную информацию о своих сайтах.
Мета-тег noindex сообщает ботам поисковых систем не индексировать определенный ресурс.
Люди часто путают метатег noindex с метатегом nofollow. Разница между ними в том, что когда вы используете теги noindex и nofollow, вы просите поисковые системы не индексировать страницу и не подписываться на нее.
Принимая во внимание, что когда вы используете теги noindex и follow, вы запрашиваете поисковые системы не индексировать страницу, но не игнорировать любые ссылки на / с страницы.
Вы можете использовать метатег noindex, чтобы поисковые системы не индексировали ваши страницы с дублированным содержанием.
Чтобы использовать метатег для обработки экземпляров дублированного контента, вы должны добавить следующую строку кода в тег заголовка вашей страницы с дублированным контентом.
Использование тега Follow вместе с тегом noindex гарантирует, что поисковые системы не игнорируют ссылки на повторяющихся страницах.
4. Используйте тег hreflang для обработки локализованных сайтовКогда вы используете переведенный контент, вы должны использовать тег hreflang, чтобы помочь поисковым системам выбрать правильную версию вашего контента.
Если у вас есть сайт на английском языке и вы перевели его на испанский для обслуживания местной аудитории, вам следует добавить тег «” к испанской версии вашего сайта.
Вы должны следовать одному и тому же процессу для всех различных локализованных версий вашего сайта.Это устранит риск того, что поисковые системы будут рассматривать его как дублированный контент, а также улучшит взаимодействие с пользователем, когда пользователи захотят взаимодействовать с вашим сайтом на своем родном языке, определяемом их идентификатором сеанса.
5. Используйте хэштег вместо оператора вопросительного знака при использовании параметров UTMОбычно используются параметры URL отслеживания, такие как источник, кампания и канал, для измерения эффективности различных каналов.
Однако, как мы обсуждали ранее, когда вы создаете ссылку типа http: // yoursite.com /? utm_source = newsletter4 & utm_medium = email & utm_campaign = holiday , поисковые системы сканируют его и сообщают о дублированном содержании.
Простой обходной путь — использовать оператор # вместо вопросительного знака. Когда боты поисковых систем сталкиваются со знаком # в URL-адресе, они игнорируют все, что следует за знаком, тем самым избегая проблем с дублированием контента.
6. Будьте осторожны с распространением контентаЕсли вы разрешаете разным сайтам повторно публиковать ваш контент, всегда просите их ссылаться на ваш сайт с точным якорным текстом.Запрос на повторно публикуемые сайты использовать тег rel или noindex также может помочь вам предотвратить проблемы с дублированием контента, вызванные повторной публикацией.
Как не обрабатывать дублированный контентКак я уже говорил, дублированный контент происходит постоянно. Если вы тоже обнаружили, что на вашем сайте есть экземпляры дублированного контента, вы должны их исправить. Я уже показал вам разные способы сделать это.
Однако теперь я хотел бы показать вам некоторые способы, которые не являются правильными и не должны использоваться для устранения проблем с дублированием контента.
1. Не блокируйте URL с помощью robots.txtВо-первых, что такое robots.txt? Robots.txt — это текстовый файл, содержащий сообщения, которые вы хотите передать сканерам поисковых систем. Эти сообщения могут быть направлены на то, чтобы поисковые роботы не индексировали указанные URL-адреса.
Некоторые веб-мастера указывают URL-адреса, содержащие повторяющееся содержимое в файлах Robot.txt, и таким образом пытаются заблокировать сканирование поисковыми системами.
Google Panda Update не одобряет методы, которые каким-либо образом блокируют поисковые роботы.Когда сканирование страниц заблокировано, роботы Google считают их уникальными, при этом они должны знать, что это не уникальные страницы, а просто страницы с повторяющимся содержанием.
Вторая проблема с этим типом блокировки заключается в том, что другие сайты могут по-прежнему иметь возможность ссылаться на заблокированную страницу. Если качественный сайт ссылается на заблокированную страницу и роботы поисковых систем не сканируют и не индексируют эту страницу, вы не получите преимущества этой обратной ссылки для SEO.
Кроме того, вы всегда можете пометить повторяющиеся страницы как повторяющиеся с помощью тега «canonical».
2. Не пересказывайте (и не перефразируйте) контент, чтобы сделать его «уникальным»Боты Google могут определить, создан ли ваш контент или создан ботами. Так что вращение контента или просто перефразирование его, чтобы оно выглядело уникальным, не поможет.
Публикация вращающегося контента будет указывать поисковым системам на то, что вы применяете теневые методы для манипулирования рейтингом в результатах поиска. Это может привести к тому, что Google примет меры против вашего сайта.
3. Не используйте опцию «удалить URL» в Google WebmastersЕсли вы заметили, инструменты Google для веб-мастеров дают вам возможность удалять URL-адреса с вашего сайта.
Итак, довольно много веб-мастеров выбирают недружественную версию своего ресурса, которая отображается в результатах поиска, и удаляют ее, используя вышеуказанный вариант.
Проблема с этим решением заключается в том, что URL-адреса удаляются только временно. И ваш сайт по-прежнему будет сталкиваться со всеми проблемами, о которых я упоминал выше. Это вообще не решение.
Эта функция полезна, когда вы хотите удалить что-то со своего сайта и хотите быстро исправить это, пока вы не поработаете над сайтом, чтобы решить эту проблему.Это не помогает решить проблемы с дублированием контента.
ЗаключениеБольшинство проблем с дублирующимся контентом можно избежать или исправить. Понимание дублированного контента повлияет на ваш рейтинг в поисковых системах.
Проверяли ли вы свой сайт на предмет дублирования контента? Если есть, какие методы вы собираетесь использовать для их сортировки?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO — разблокируйте огромное количество SEO-трафика.Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media — эффективные платные стратегии с четкой окупаемостью.
Заказать звонок
Веб-инструмент для поиска общих и уникальных РНК-целей CRISPR с одним руководством в наборе похожих последовательностей
Abstract
Геномная инженерия произвела революцию в результате открытия сгруппированных регулярно расположенных палиндромных повторов (CRISPR) и системных генов, связанных с CRISPR (Cas), у бактерий.Система CRISPR / Cas9 типа IIB Streptococcus pyogenes функционирует у многих видов, и дополнительные типы систем CRISPR / Cas находятся в стадии разработки. В системе типа II экспрессия единственной направляющей РНК CRISPR (sgRNA) нацелена на определенную последовательность, а Cas9 генерирует специфичную для последовательности нуклеазу, индуцирующую небольшие делеции или вставки. Более того, было показано, что большие вставки ДНК проникают в сайты, на которые нацелены sgRNA и Cas9. Доступно несколько инструментов для создания sgRNA, которые нацелены на уникальные участки генома.Однако возможность найти мишени sgRNA, общие для нескольких подобных последовательностей или, напротив, уникальные для каждой из этих последовательностей, также была бы полезной. Чтобы предоставить такой инструмент для нескольких типов систем CRISPR / Cas и многих видов, мы разработали программное обеспечение CRISPR MultiTargeter. Рассматриваемые сходные последовательности ДНК представляют собой дублированные гены и наборы экзонов различных транскриптов гена. Таким образом, мы реализовали базовый поиск мишеней sgRNA входных последовательностей для нацеливания на одну sgRNA и две sgRNA / Cas9 никазы, а также общие и уникальные поиски мишеней sgRNA в 1) наборе входных последовательностей; 2) набор похожих генов или транскриптов; или 3) транскрипция одного гена.Мы демонстрируем потенциальные возможности использования программы, идентифицируя уникальные изоформ-специфические сайты sgRNA в 71% альтернативных транскриптов рыбок данио и общие сайты-мишени sgRNA примерно в 40% пар генов с дупликациями у рыбок данио. Дизайн уникальных мишеней в альтернативных экзонах полезен, потому что он облегчит функциональные геномные исследования изоформ транскриптов. Точно так же его применение к дублированным генам может упростить эксперименты по нацеливанию на мультигенные мутации. В целом эта программа предоставляет уникальный интерфейс, который расширяет возможности использования технологии CRISPR / Cas.
Образец цитирования: Прихожий С.В., Раджан В., Гастон Д., Берман Дж. Н. (2015) CRISPR MultiTargeter: веб-инструмент для поиска общих и уникальных РНК-мишеней CRISPR с одним проводником в наборе похожих последовательностей. PLoS ONE 10 (3): e0119372. https://doi.org/10.1371/journal.pone.0119372
Академический редактор: Ходака Фудзи, Университет Осаки, ЯПОНИЯ
Поступила: 17 ноября 2014 г .; Одобрена: 30 января 2015 г .; Опубликован: 5 марта 2015 г.
Авторские права: © 2015 Прихожий и др.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника
Доступность данных: Все соответствующие данные находятся в пределах документ и вспомогательные информационные файлы к нему.
Финансирование: Хотя этот проект специально не финансировался каким-либо грантом, авторы с благодарностью признают грантовую поддержку проекта IGNITE (Орфанные болезни: идентификация генов и новые методы лечения для улучшения лечения) от Genome Atlantic и Канадских институтов здравоохранения. Грант на исследовательскую деятельность 287512.
Конкурирующие интересы: Авторы заявляют, что у них нет конкурирующих интересов.
Введение
За последние два десятилетия было признано, что виды бактерий и архей обладают адаптивным иммунитетом против молекулярных патогенов, таких как вирусы [1]. Этот иммунитет основан на сгруппированных регулярно расположенных палиндромных повторах (CRISPR) и спейсерах, гомологичных патогенам-мишеням, а также на белках Cas (последовательность, ассоциированная с CRISPR). Последовательности спейсеров происходят из областей протоспейсеров, которые также характеризуются специфическими мотивами, примыкающими к протоспейсерам (PAM), необходимыми для их расщепления и встраивания во фрагмент CRISPR [2,3].CRISPR и соответствующие спейсеры транскрибируются и процессируются в некодирующие crRNA, которые в комплексе со специфическими белками Cas могут расщеплять ДНК, распознаваемую областью спейсерной РНК. Системы CRISPR / Cas разнообразны и подразделяются на три типа в зависимости от последовательности, расположения PAM и конкретных генов Cas [4]. Из всех известных систем CRISPR / Cas система типа IIB была принята для использования в исследованиях, когда было показано, что единая направляющая РНК (sgRNA), генерируемая соединением crRNA и tracrRNA из Streptococcus pyogenes , может успешно программировать Cas9 для расщепления различных Последовательности ДНК, содержащие последовательность NGG PAM после спейсерной последовательности в той же цепи [5].Такие искусственные sgRNAs вместе с Cas9 сначала были применены к клеткам человека [6,7], а затем к растущему числу других видов (обзор в [8]). Кроме того, были разработаны варианты систем CRISPR / Cas9 ( e . g . Neisseria meningitides Cas9 (NmCas9), разрезанная в NNNNGATT PAM [9] или Streptococcus thermophilus Cas9 (StCas9), разрезанная в NNAGAAW PAM [10]). для экспериментального использования и может найти новые применения [11].
Базовые вычислительные исследования систем CRISPR / Cas были сосредоточены на идентификации сайтов CRISPR в геномах бактерий и архей, что привело к разработке таких инструментов, как CRISPR finder и CRISPRdb [12].Принятие CRISPR / Cas для экспериментальной работы также стимулировало разработку программ для генерации sgRNA и поиска их целевых сайтов (Таблица 1). ZiFiT (http://zifit.partners.org/ZiFiT/) [13] — одна из самых ранних доступных программ для быстрого поиска потенциальных сайтов-мишеней Cas9 sgRNA в последовательностях ДНК. Недавний прогресс в разработке программного обеспечения sgRNA включает в себя реализацию функции поиска по сторонним сайтам, чтобы минимизировать потенциальные проблемы, создаваемые нецелевыми активностями комплексов sgRNA / Cas, дизайн sgRNA для новых типов систем CRISPR / Cas и новые приложения существующие ферменты.Оптимизированный дизайн CRISPR (http://crispr.mit.edu/), разработанный Zhang Lab, позволил провести обширный анализ нецелевых сайтов, но в настоящее время он ограничен исключительно PAM «NGG» и длиной последовательности 250 нуклеотидов при каждом запуске. занимает несколько минут. Точно так же поиск сайтов-мишеней sgRNA с помощью инструмента CRISPR Direct (http://crispr.dbcls.jp/) из Центра баз данных для наук о жизни приводит к выводу таблицы сайтов-кандидатов с их последовательностями, характеристиками основных последовательностей этих сайтов. сайтов, а также количество уникальных совпадений в геноме и номера совпадений «12-мер + PAM» [14].Cas9 Online Designer (http://cas9.wicp.net/), разработанный Dayong Guo, и автономный программный пакет sgRNAcas9 [15] — это две дополнительные программы, которые могут проверять нецелевые сайты непосредственно во время поиска по целевому сайту. Из всего доступного в настоящее время программного обеспечения для дизайна sgRNA веб-сайт CHOPCHOP (https://chopchop.rc.fas.harvard.edu/) выделяется своей скоростью, универсальностью, удобством использования, динамическим графическим интерфейсом и нецелевым предсказание, но охват видов несколько ограничен [16].Нацеливание CRISPR / Cas9 для различных экспериментов по маркировке белков поддерживается веб-сайтом E-CRISP (http://www.e-crisp.org/E-CRISP/) [17], который также обеспечивает аналогичные функции с другими программами. Интересно, что пока эта рукопись находилась в стадии подготовки, был обнаружен пакет CRISPRSeek Bioconductor, реализующий анализ мишеней sgRNA в двух последовательностях, что несколько похоже на рабочие процессы в текущем программном обеспечении [18], но не так полно разработано, как в нашем программном обеспечении, и также требует Навыки R и Bioconductor для использования.Потенциал эффективности таргетинга sgRNA — еще одна очень важная тема, которую начинают решать инструменты проектирования sgRNA, первым из которых является sgRNA Designer от Broad Institute (http://www.broadinstitute.org/rnai/public/analysis-tools/ sgrna-design) [19]. Эти авторы подготовили большие объединенные библиотеки векторов sgRNA для ряда генов, количественно оценили их эффективность таргетинга и разработали статистическую модель для прогнозирования оценки эффективности таргетинга sgRNAs на основе ее последовательности.Сосредоточение внимания на многих видах из определенной филогенетической группы является еще одним направлением программного обеспечения для разработки sgRNA CRISPR / Cas9, примером которого является flyCRISPR Optimal Target Finder (http://tools.flycrispr.molbio.wisc.edu/targetFinder/) [20]. Прогнозирование отклонения от цели также было реализовано для уже разработанных sgRNA группами, опубликовавшими CasOT [21], Cas-OFFinder (http://www.rgenome.net/cas-offinder/) [22] и GT-Scan (http: //gt-scan.braembl.org.au/gt-scan/) [23]. CasOT и Cas-OFFinder ориентированы исключительно на сайты-мишени CRISPR / Cas и имеют несколько ограничительные параметры, в то время как GT-Scan может приспособиться к очень широкому определению цели, является быстрым и удобным для пользователя.Таким образом, GT-Scan является предпочтительным программным обеспечением для проверки целевых сайтов, идентифицированных с помощью нашего программного обеспечения.
Несмотря на этот быстро растущий список онлайн-ресурсов, текущая разработка программного обеспечения для систем CRISPR / Cas в значительной степени сосредоточена на программах, предсказывающих сайты-мишени, уникальные для всего генома. Однако мы пришли к выводу, что при наличии двух или более связанных последовательностей в геноме или соответствующем транскриптоме было бы полезно предсказать общие сайты-мишени sgRNA, присутствующие во ВСЕХ из этих последовательностей, а также уникальные сайты-мишени, присутствующие только в ОДНОЙ последовательностей.Имея это в виду, мы разработали CRISPR MultiTargeter, который специально разработан для работы с дублированными генами и конститутивными, а также альтернативными экзонами, присутствующими в определенных транскриптах (по сравнению с существующими программами в таблице 1). Такие предсказанные целевые сайты могут быть дополнительно протестированы с использованием программного обеспечения для прогнозирования смещенных от цели сайтов, описанного выше. CRISPR MultiTargeter может применяться к геномам нескольких видов, произвольным последовательностям ДНК и поддерживает различные специфичности целевого сайта sgRNA с соответствующими параметрами.Мы также внедрили новую систему оценки для sgRNA типа II, разработанную Doench и коллегами [19]. Поскольку наша основная модельная система — это рыба данио ( Danio rerio ), популярная модельная система для понимания онтогенетических, клеточных и биохимических процессов и механизмов, а также для моделирования заболеваний, мы провели полногеномный анализ приложений CRISPR MultiTargeter на изоформах транскриптов и дублированные гены как доказательство концепции. Мы предполагаем, что это программное обеспечение упростит нацеливание на множественные гены и мутационный анализ различных изоформ транскриптов.
Методы
Создание базы данных и поиск последовательности
Когда пользователь вводит идентификаторы последовательностей, программа извлекает последовательности, соответствующие этим идентификаторам, вместе с дополнительной информацией о последовательностях, как предписано алгоритмом. Нуклеотидные последовательности Refseq извлекаются из системы Entrez Национального центра биотехнологической информации, и поэтому процесс поиска не накладывает никаких ограничений на их виды происхождения. Хранение и доступ к другой информации о последовательностях были реализованы с использованием системы управления базами данных SQLite3, которой можно легко управлять с помощью операторов SQL внутри сценариев Python.Мы использовали базу данных Ensembl BioMart в качестве источника информации о последовательностях генов, транскриптов и экзонов, используемых в этом программном обеспечении. Данные Biomart были взяты из версии базы данных Ensembl Genes 76 и самых последних геномных сборок для каждого вида ( Homo sapiens —GRCh48; Mus musculus —GRCm38.p2; Rattus norvegicus —Rnor_5.0; Gallus gallus gallus gallus Galgal4; Xenopus tropicalis —JGI4.2; Danio rerio —Zv9; Oryzias latipes —HdrR; Drosophila melanogaster —BDGP5; TA CaenorhabditisBelena_Safeerae ; —ИРГСП-1.0; Zea mays —AGPv3). В нашей базе данных есть следующие таблицы и поля: гены (генеид, символ, последовательность, виды), экзоны (exonID, geneid, последовательность, цепь, chrstart, chrend, genestart, geneend) и транскрипты (transcriptID, geneid, последовательность). Большая часть данных о последовательностях, содержащихся в таблицах, была вставлена без изменений из исходных источников. Последовательности генов были созданы путем последовательного слияния всех экзонов каждого гена в соответствии с их координатами. Эта особенность последовательностей генов позволяет проводить исчерпывающее сравнение родственных генов, что невозможно при сравнении последовательностей транскриптов, которые не включают некоторые экзоны.Чтобы избежать ошибочной идентификации мишени, сайты-кандидаты-мишени проверяются по отдельным последовательностям экзонов.
Веб-интерфейс
Веб-интерфейс CRISPR MultiTargeter содержит главную страницу с объяснением общего использования программы, графическими пояснениями и ссылками на страницы ввода для конкретных типов анализов, которые будут описаны позже. Независимо от типа анализа входные веб-страницы требуют, чтобы пользователи вводили два типа информации: детали определения целевого сайта sgRNA и входные последовательности, которые будут использоваться для поиска целевых сайтов.Чтобы определить, как будут осуществляться поиск сайтов-мишеней sgRNA, пользователю необходимо указать 5 ‘динуклеотид, выбрав один из трех вариантов («NN», «GN», «GG»), длину цели и с какой стороны. последовательность PAM расположена для этой конкретной системы CRISPR / Cas. Пользователь может либо выбрать последовательность PAM «NGG» по умолчанию, либо указать ее, используя стандартные символы алфавита нуклеиновых кислот. Пользователь также может допустить несоответствие между sgRNA и ее геномной последовательностью-мишенью в первых 8 нуклеотидах.Недавнее исследование показало, что такое несоответствие не влияет на связывание sgRNA [24] и имеет отношение к этому программному обеспечению, поскольку нацеливание на несколько последовательностей с одной и той же sgRNA более осуществимо, если такое несовпадение допустимо. Ввод последовательности в это программное обеспечение может быть выполнен просто путем вставки последовательностей или содержимого файлов FASTA в текстовую область веб-сайта или загрузки в программу. В качестве альтернативы пользователь может предоставить идентификаторы последовательностей, соответствующие им виды и тип идентификаторов среди символов генов, идентификаторов генов / транскриптов Ensembl или идентификаторов RefSeq.
Обработка нескольких последовательностей
Выравнивание последовательностей было выполнено с использованием программного обеспечения ClustalW2 [25] после того, как файлы входных последовательностей были автоматически подготовлены скриптами Python. Выходные файлы после выравнивания последовательностей затем обрабатывались с помощью Biopython [26] для создания объектов выравнивания, подходящих для поиска общих сайтов направляющей РНК в нескольких последовательностях.
Внешние наборы данных
Набор данных онологов рыбок данио для эталонного генома рыбок данио Zv9 был получен от авторов последней сборки генома рыбок данио (Консорциум генома рыбок данио Сэнгера) [27] по запросу.В этом исследовании онологи были определены как «серии генов у недуплицированных видов, которые обнаружены на двух разных хромосомах у видов, подвергшихся дупликации всего генома». Общее количество генов составляет 8083, а количество «пар» — 3440 (таблица S1). Некоторые из этих «пар» представляют собой пары между группами онологов. Когда эти групповые пары были разделены на все возможные уникальные пары отдельных генов, общее количество уникальных пар онологов составило 6305 (таблица S2).
Анализ данных, визуализация и графика
Результаты анализа генома или транскриптома сначала обрабатывались с использованием написанных на заказ скриптов Python, а затем импортировались в языковую среду R (R Studio) для построения графиков.Входные данные, все промежуточные файлы, скрипты python и R доступны в репозитории GitHub https://github.com/SergeyPry/CRISPR_MultiTargeter/. Некоторые файлы были слишком большими для включения, но их создание объяснялось в том же репозитории. Все рисунки были созданы с использованием программ GIMP и Inkscape.
Типы дизайна sgRNA в CRISPR MultiTargeter и их приложения
Основной мотивацией для разработки инструмента CRISPR Multiargeter было предоставление эффективного вычислительного метода для определения общих и уникальных целей для sgRNAs системы CRISPR / Cas в нескольких схожих последовательностях.Наличие такого набора сайтов-мишеней уменьшило бы количество sgRNA в экспериментах, направленных на одновременное разрушение нескольких похожих генов. В качестве альтернативы, набор уникальных сайтов для каждой из подобных последовательностей позволит более точно настроить подход к нацеливанию.
Для простоты использования мы создали четыре различных рабочих процесса, сосредоточенных на конкретных видах целевого дизайна sgRNA. Простая страница поиска по sgRNA CRISPR позволяет пользователю находить целевые сайты в одной или нескольких входных последовательностях в соответствии с определенной специфичностью целевого сайта sgRNA (рис.1А). Реализация целевой специфичности регулярного выражения гарантирует, что все возможные цели могут быть найдены, даже если они перекрываются. Более того, программа поддерживает дизайн sgRNAs для нормальной одинарной двухцепочечной эндонуклеазной активности и близлежащих пар sgRNAs для приложений Cas9-никазы [28]. Пользователь также может предоставить входные последовательности несколькими способами: можно ввести последовательность ДНК без какого-либо идентификатора или в виде текста в формате FASTA, загрузить те же последовательности в файл или предоставить идентификаторы последовательностей (использование см. В следующем разделе), который будет использоваться для извлечения соответствующих последовательностей из базы данных веб-сайта.Кроме того, мы хотели предоставить новым пользователям простой опыт проектирования и предоставить им возможность рассмотреть другие типы дизайна sgRNA, доступные на веб-сайте. Хотя другие инструменты разработки sgRNA CRISPR предоставляют аналогичные функции, CRISPR MultiTargeter не ограничивается наиболее часто используемой в настоящее время системой CRISPR / Cas9 типа II, но отличается тем, что может приспособиться к новым системным особенностям CRISPR / Cas, таким как NmCas9 [9] и StCas9 [10] ] (Таблица 1).
Рис. 1. Рабочие процессы поиска цели направляющей РНК в CRISPR MultiTargeter.
А . Простой поиск РНК руководства CRISPR. Пользователь вводит ряд последовательностей или идентификаторов последовательностей и спецификаций для целевого поиска. Затем программа запускает эти данные, выполняет сопоставление регулярного выражения, сохраняет полученные координаты и генерирует визуальные и табличные представления целей в каждой последовательности. В . Общий поиск цели РНК-руководства в нескольких последовательностях. Входные последовательности используются для генерации множественного выравнивания последовательностей. Как и в случае (A) , регулярное выражение с целевыми спецификациями запускается при согласованном выравнивании как в прямой, так и в обратной ориентации.Успешное совпадение определяется как наличие не более одного несоответствия в согласованной последовательности, если пользователь допускает несовпадения. Эти совпадения затем выделяются при множественном выравнивании последовательностей. Кроме того, для входных последовательностей выполняется другой алгоритм, чтобы найти уникальные целевые сайты в каждой последовательности (не показаны). С . Общая и уникальная направляющая РНК нацелена на поиск в похожих генах или транскриптах . В этом рабочем процессе последовательности генов или транскриптов извлекаются из базы данных.Общие цели обнаруживаются на основе множественного выравнивания последовательностей, а уникальные целевые сайты обнаруживаются с использованием алгоритма исчерпывающего сравнения строк (не показан). Все сайты-мишени также проверяются на принадлежность к одному экзону, чтобы гарантировать успешное нацеливание геномной последовательности. На иллюстрации местоположения различных целевых сайтов в генах A и B показаны вместе с ожидаемым результатом выполнения программы. Д . Общая и уникальная направляющая РНК-мишень для поиска в транскриптах единственного гена .Поиск целевых сайтов выполняется, как описано в (C) . На иллюстрации входные последовательности представляют собой изоформы транскрипта A1, A2 и A3 гена A. Показаны различные типы целевых сайтов, а также ожидаемый результат программы. В моделях (C), и (D) общие цели обозначены розовым цветом, а уникальные цели — оранжевым.
https://doi.org/10.1371/journal.pone.0119372.g001
Следующие три рабочих процесса CRISPR MultiTargeter работают только с несколькими последовательностями и разделяют основные функции алгоритма, который генерирует множественное выравнивание последовательностей из этих последовательностей для находит общие цели и выполняет исчерпывающее сравнение строк для определения уникальных целевых сайтов в каждой последовательности.Они различаются механизмом ввода последовательности и их способностью проверять, находится ли каждый идентифицированный целевой сайт в определенном экзоне. Первый из этих рабочих процессов фокусируется на нескольких последовательностях, представленных в формате FASTA, без учета происхождения этих последовательностей или их экзонной структуры в геноме из-за отсутствия такой информации (рис. 1B). Основное обоснование разработки этого рабочего процесса состояло в том, чтобы дать пользователям возможность выполнять тщательно настроенные целевые поиски с помощью нашего инструмента в тех случаях, когда эти последовательности не были добавлены в основные базы данных модельной системы или когда они получены из геномов видов, еще не поддерживаемых программой.CRISPR MultiTargeter также предлагает тот же тип анализа, который применяется к аналогичным генам или транскриптам, извлеченным из базы данных по их идентификаторам последовательностей (рис. 1C), или для ДНК-представлений различных изоформ транскриптов одного гена (рис. 1D). В обоих последних двух рабочих процессах известен вид происхождения последовательностей, а также их экзонная структура. Последовательности генов, используемые в этих рабочих процессах, были созданы путем слияния всех экзонов каждого гена, как описано в разделе «Создание базы данных».
Вход, алгоритм и выход CRISPR MultiTargeter
CRISPR MultiTargeter требует нескольких параметров мишеней CRISPR sgRNA и входных последовательностей, а также связанных с ними параметров (рис. 2). Из-за механизма действия системы CRISPR / Cas основными характеристиками sgRNA являются длина целевого сайта и последовательность PAM, подходящая для конкретного типа системы CRISPR / Cas. Недавние эксперименты изучали длину целевого сайта и устойчивость к несоответствию системы CRISPR / Cas типа II [24,29,30].Типичная длина сайта-мишени в этой системе составляет 17–20 нуклеотидов, что приводит к определению сайта-мишени NGG N 17-20 для системы CRISPR / Cas9. Другой реализуемый параметр — является ли 5’-самый динуклеотид полностью неограниченным (NN) или должен соответствовать другому паттерну, генерируемому синтезом sgRNA полимеразой T7 (GG) или промотором U6 (GN). В целом, текущая реализация поиска по целевым сайтам основана на предположении, что единственными ограничениями последовательности целевых сайтов CRISPR / Cas являются 5’-крайний динуклеотид и последовательность PAM.Одним из основных предлагаемых вариантов использования CRISPR MultiTargeter является нацеливание на несколько последовательностей, что может быть более легко достигнуто, допуская несовпадения в первых 8 нуклеотидах, которые, как известно, существенно не влияют на связывание sgRNA [24]. Этот параметр может плохо распространяться на другие системы, поэтому пользователь может решить не допускать каких-либо несоответствий. Параметр несоответствия может быть расширен в последующих версиях программы, если такие данные о несоответствии станут доступными для других систем. Как обсуждалось ранее, этой реализации достаточно для доступных системных инструментов CRISPR / Cas, и можно ожидать, что она хорошо адаптируется к новым системам, поскольку они разделяют определение целевого сайта с помощью sgRNA.Входные последовательности обрабатываются алгоритмом в зависимости от того, выполняется ли простой поиск цели sgRNA или основанный на выравнивании.
Рис. 2. Алгоритм поиска сайтов-мишеней sgRNA в индивидуальных и множественных аналогичных последовательностях.
Входные данные для этого алгоритма состоят из спецификации сайта-мишени sgRNA и данных последовательности. Пунктирные линии рядом с полями последовательностей представляют две возможные ветви алгоритма: простой поиск CRISPR sgRNA и поиск общих и уникальных целевых сайтов во множестве похожих последовательностей.Спецификация целевого сайта является общей для обеих ветвей алгоритма и состоит из длины целевого сайта, последовательности PAM и ее местоположения, а также последовательности 5’-динуклеотида и области, где допускается единственное несоответствие. Простой поиск sgRNA достигается путем выполнения регулярного выражения (шаблона поиска) для спецификации целевого сайта для всех входных последовательностей в обеих ориентациях. Программа может предоставлять выходные данные для последовательности и местоположения идентифицированных целевых сайтов в визуальном и табличном форматах.Во второй ветви алгоритма несколько похожих последовательностей сначала выравниваются с помощью программы ClustalW2. Полученное в результате множественное выравнивание последовательностей считывается программой и вычисляется консенсусная последовательность. Выполнение выражения спецификации целевого сайта на этой консенсусной последовательности приводит к идентификации общих целевых сайтов-кандидатов. Если последовательности экзонов доступны для конкретной последовательности (обозначены «?» И пунктирными линиями), каждый сайт-кандидат-мишень как в общем, так и в уникальном наборе проверяется, чтобы убедиться, что этот сайт полностью лежит в последовательности экзона.Затем окончательно идентифицированные общие целевые сайты отображаются в визуальном и табличном форматах. Поиск уникальных целевых сайтов осуществляется путем вычисления всех возможных целевых сайтов в обеих ориентациях во всех последовательностях. Затем каждый целевой сайт сравнивается со всеми идентифицированными целевыми сайтами в этих последовательностях. Скорость сравнения зависит от переменной счетчика несоответствий (счетчик MM), которая гарантирует, что сравнение будет остановлено («Конец»), как только будет обнаружено более двух несоответствий (идентичности обозначены знаком «*»).Целевые сайты, которые проходят этот сравнительный тест и последующий тест на локализацию в последовательностях экзонов, являются подтвержденными уникальными целевыми сайтами. Затем эти уникальные целевые сайты можно будет вывести, как и раньше.
https://doi.org/10.1371/journal.pone.0119372.g002
В простом алгоритме поиска одна или несколько последовательностей ДНК берутся в качестве входных данных, и поиск выполняется независимо друг от друга (рис. 2). После того, как все целевые сайты во всех последовательностях найдены, программа предоставляет визуальные и табличные представления целевых сайтов в расширяемых и сворачиваемых (реализованных в JavaScript) ссылках для выравнивания с помеченными целевыми сайтами и таблицами с данными последовательностей целевых сайтов (рис.3). Таблицы представлены в формате HTML и в виде текста для вставки в электронные таблицы или текстовые редакторы.
Рис. 3. Примеры страниц ввода и вывода CRISPR MultiTargeter.
А . Форма ввода для ввода нескольких генов или транскриптов состоит из параметров для спецификации целевого сайта sgRNA и области ввода идентификаторов. В . Страница вывода состоит из общего заголовка, указывающего тип выполненного дизайна, за которым следует список входных идентификаторов, которые пользователь предоставил со ссылками на страницы генов Ensembl, если они доступны.Этот пример взят из рабочего процесса множественных генов / транскриптов, выполненного для генов sox9a и sox9b рыбок данио. Основная часть вывода сосредоточена на общих сайтах-мишенях sgRNA и организована в виде визуальных представлений и таблиц. Пользователь может просмотреть подробную информацию об этих представлениях, щелкнув ссылку «развернуть или скрыть». Визуальный просмотр состоит из ссылок для выравнивания с выделенными целевыми сайтами и маркеров для начальных сайтов целевых сайтов. Представление таблицы содержит таблицы HTML с соответствующей информацией о сайтах-мишенях sgRNA, такой как их идентификационные номера, последовательности, начало, конец, а также вычисленные характеристики последовательностей, такие как GC% и прогнозируемая температура отжига (Tm) sgRNA: взаимодействие ДНК, номера экзонов и прогнозируемые баллы.На странице также есть раздел «Уникальные мишени sgRNA», который организован аналогичным образом.
https://doi.org/10.1371/journal.pone.0119372.g003
Напротив, основной алгоритм программы, ориентированный на поиск общих и уникальных целевых сайтов, обрабатывает входные последовательности на основе предположения, что они похожи. Сначала файл FASTA, подходящий для ClustalW2, временно записывается в новую папку. Затем CRISPR MultiTargeter запускает ClustalW2, который вычисляет выравнивание входных последовательностей и записывает полученные выходные файлы в ту же папку.Затем выходное выравнивание считывается с помощью Biopython и вычисляется согласованная последовательность для всего выравнивания. Представление пробелов («-») и несовпадений («X») позволяет программе легко выполнять поиск регулярного выражения в согласованной последовательности в соответствии с критериями, определенными выше. Затем этот поиск выполняется с использованием стандартного кода Python как для согласованной последовательности, так и для ее обратного дополнения. Чтобы гарантировать правильный результат, алгоритм отслеживает координаты целевого сайта в согласованной последовательности и в каждой отдельной последовательности в обеих ориентациях.Затем уникальные сайты-мишени sgRNA вычисляются с помощью совершенно другого алгоритма (рис. 2). Сначала вычисляются все возможные целевые сайты для каждой последовательности в обеих ориентациях. Поскольку сайты-мишени без последовательности PAM в основном нефункциональны для расщепления белками Cas, можно ограничить тестирование уникальностью сайтов-мишеней только для нормальных PAM-содержащих сайтов. Затем каждый из идентифицированных сайтов-мишеней сравнивается со всеми другими сайтами-мишенями во всех последовательностях. Сравнение выполняется с 5’-конца, и если количество различий между ними больше двух, сравнение останавливается и программа переходит к следующему целевому сайту (рис.2). Как общие, так и уникальные сайты-мишени sgRNA в последовательностях с известными структурами экзонов также фильтруются путем проверки того, что они полностью расположены внутри одного экзона, чтобы гарантировать, что их последовательности не являются результатом сплайсинга РНК двух разных экзонов и, следовательно, не будут встречаться в геном (рис. 2).
Расчет характеристик sgRNA
Каждый идентифицированный сайт-мишень sgRNA характеризуется своим GC-процентом, который влияет на температуру плавления (Tm) полученного дуплекса РНК: ДНК, который может влиять на активность sgRNA, но не является прямо пропорциональным.Хотя трудно предсказать точную Tm этого дуплекса внутри белковых комплексов CRISPR / Cas, можно предсказать ее, основываясь на биофизических экспериментах in vitro, и вычислительных моделях, полученных на их основе. Мы реализовали термодинамическое предсказание Tm ближайшего соседа, первоначально предоставленное Сугимото и др., 1995 [31] и основанное на предыдущей реализации в MELTING [32]. Код python был получен из пакета Bio.SeqUtils.MeltingTemp Biopython, и результаты были проверены по результатам MELTING 4.2 (http://mobyle.pasteur.fr/cgi-bin/portal.py?#forms::melting). Другой параметр, реализованный в CRISPR MultiTargeter, — это оценка от 0 до 1, указывающая на прогнозируемую активность sgRNAs и полученная из модели логистической регрессии, описанной Doench и коллегами [19]. Вкратце, оценочная функция целевая последовательность sgRNA, 4 нуклеотида (нуклеотидов) к 5 ’, последовательность PAM и 3 нуклеотида к 3’, PAM. Текущее требование для функции оценки, чтобы sgRNA были типа II и имели длину 20 нуклеотидов.
Нецелевое тестирование предсказанных sgRNA
Поскольку задача нецелевого анализа включает сложные вычисления, включающие большие объемы геномных данных, и этот анализ не является основным предметом статьи, мы решили добавить пояснения и ссылки к выходным данным инструмента, что позволит пользователю анализировать с помощью других инструментов определили целевые сайты для потенциальных нецелевых целей. Мы выбрали Cas-OFFinder (http://www.rgenome.net/cas-offinder/) [22] и GT-Scan (http: // gt-scan.braembl.org.au/gt-scan/) [23] в качестве инструментов для последующего нецелевого анализа. В обоих случаях пользователь должен скопировать выходные данные области ввода текста, содержащие последовательности целевых сайтов sgRNA и их характеристики, в программу электронных таблиц, а затем выбрать последовательности целевых сайтов sgRNA для анализа. Есть четыре параметра для выбора для анализа вне мишени: тип последовательности PAM, длина последовательности, целевой геном и максимальное количество несовпадений потенциальных сайтов вне мишени. Cas-OFFinder допускает 4 различных типа PAM, и соответствующие длины последовательностей фиксируются в этой программе, тогда как GT-Scan очень гибок в этом отношении и позволяет пользователю указать любой тип последовательности PAM и выбрать длину последовательности.Cas-OFFinder и GT-Scan также имеют хороший охват целевых геномов с 23 и 28 доступными геномами, соответственно, и большинство модельных видов присутствует среди этих геномов. Наконец, обе программы позволяют пользователю указать максимальное количество несовпадений между целевым сайтом sgRNA и потенциальными нецелевыми сайтами в геноме.
Результаты и обсуждение
Уникальная идентификация сайта-мишени sgRNA в изоформах транскриптов рыбок данио с использованием CRISPR MultiTargeter
Чтобы продемонстрировать применимость CRISPR MultiTargeter для определения уникальных сайтов-мишеней sgRNA, специфичных для изоформ транскрипта, мы решили сосредоточиться на наборе генов рыбок данио с множеством альтернативных транскриптов.Уникальные сайты-мишени sgRNA очень важны для мутационного анализа конкретных изоформ транскриптов. Действительно, нацеливание на конкретные изоформы транскриптов у мышей с использованием технологии CRISPR / Cas было предложено в недавнем обзоре тонких целевых мутаций, которые становятся все более важными для понимания функции генов [33]. До недавнего времени такие эксперименты по нацеливанию были очень сложными для мышей и почти невозможными для видов, не поддающихся геномной инженерии путем гомологичной рекомбинации, таких как рыбки данио.Применение CRISPR MultiTargeter для разработки sgRNA, специфичных для изоформ транскриптов, значительно упростит дизайн таких экспериментов. Уникальность этих изоформ-специфичных sgRNA для всего генома может быть исследована с помощью веб-инструмента Cas-OFFinder [22] или GT-Scan [23], как описано в разделе «Методы». Если необходимо ввести определенные мутации, могут быть выполнены совместные инъекции sgRNA и Cas9 с соответствующими двух- или одноцепочечными молекулами ДНК. В этом полногеномном анализе у рыбок данио мы использовали автономный скрипт Python рабочего процесса транскрипции CRISPR MultiTargeter с настройками по умолчанию (5′-динуклеотид — NN; длина — 20; последовательность PAM — NGG) для поиска специфичных для транскриптов изоформ ( unique) сайты-мишени sgRNA во всех генах рыбок данио с двумя или более изоформ согласно базе данных Ensembl.Изоформы транскриптов присутствуют примерно в 40% всех генов рыбок данио на основании нашего анализа и общего числа генов в эталонном геноме Zv9 рыбок данио [27]. Мы проанализировали эти 12 383 гена, используя наш рабочий процесс для транскриптов одного гена для идентификации и количественной оценки уникальных сайтов-мишеней sgRNA, специфичных для изоформ транскриптов (рис. 4). Почти все эти гены (97,5%) имели по крайней мере один транскрипт с уникальными сайтами-мишенями sgRNA, что можно ожидать, поскольку для идентификации уникальных сайтов потребуется только альтернативная экзонная последовательность достаточной длины в альтернативных транскриптах (рис.4А). Точно так же 71% всех альтернативных транскриптов, проанализированных в этой программе, содержали уникальные изоформ-специфичные сайты sgRNA (рис. 4A). Этот процент можно объяснить тем фактом, что многие альтернативные экзоны присутствуют во множестве известных изоформ транскриптов и, таким образом, не могут претендовать на уникальность в наборе транскриптов одного гена. Сайты sgRNA, обнаруженные в этом анализе, почти одинаково распределены среди смысловой и антисмысловой ориентации (51% и 49% соответственно) (рис. 4A). Распределение количества sgRNA, специфичных для изоформ транскрипта, в индивидуальных транскриптах довольно широкое, но смещено в сторону более низких частот со средним значением 48.7 (рис. 4Б). Такое широкое распределение целевых чисел отражает вариабельность длины участков последовательности, специфичных для изоформ транскрипта. В целом, этот анализ изоформ транскриптов рыбок данио показывает, что сайты-мишени sgRNA могут быть идентифицированы в отдельных изоформах транскриптов с помощью CRISPR MultiTargeter и, таким образом, облегчают эксперименты по нацеливанию на изоформы. Полученный в результате более продвинутый мутационный анализ, вероятно, улучшит наше понимание роли продуктов альтернативных транскриптов в клетке.
Рис. 4. Уникальные сайты-мишени sgRNA, специфичные для изоформ транскрипта, для sgRNA типа II CRISPR в генах рыбок данио.
А . Доли генов с идентифицированными сайтами sgRNA, специфичными для изоформ транскрипта, транскрипты с сайтами sgRNA, специфичными для изоформ, и пропорции этих сайтов в смысловой и антисмысловой ориентации. Сайты sgRNA имеют длину 20 п.н. с 5’-динуклеотидом NN и последовательностью NGG PAM. В . Распределение общего количества целевых сайтов для изоформ транскрипта.Среднее количество сайтов-мишеней sgRNA (48,7) указано пунктирной линией над гистограммой. Оси графика масштабируются с использованием функции извлечения квадратного корня. Полосы гистограммы окрашены в соответствии с шкалой частот, как показано.
https://doi.org/10.1371/journal.pone.0119372.g004
Применение CRISPR MultiTargeter к дублированным генам у рыбок данио для идентификации и количественного определения общих сайтов-мишеней sgRNA
Чтобы протестировать CRISPR MultiTargeter на определение общих целей в схожих генах, мы выбрали набор онологов рыбок данио, т.е.е. паралогичные гены, происходящие из дупликаций генома и названные в честь Сусуму Оно [34]. Понимание онологов и ортологических взаимоотношений генов у разных видов важно для правильной номенклатуры генов, основанной на ортологии, эволюционных исследований и для более легкого анализа функций генов. В геноме рыбок данио часто возникает ситуация, когда создание моделей потери функции для определенных генов осложняется наличием очень похожих дублированных генов, что требует от исследователей нацеливать по крайней мере два гена для достижения значимого фенотипа.Данные полногеномного секвенирования, такие как порядок генов и синтения регионов между видами, предполагают, что линия, ведущая к происхождению рыбок данио, претерпела два раунда дупликации генома во время происхождения позвоночных и дополнительный раунд во время эволюции костистых животных (см. [35,36]). После дупликаций генома многие из дублирующих генов по-разному теряются в расходящихся клонах, что приводит к появлению явно новых генов, в то время как другие гены приобретают новые функции и / или паттерны экспрессии, которые могут способствовать эволюционным инновациям [37].Таким образом, дупликации генов и последующие потери генов могут способствовать дивергенции клонов и большей генетической и морфологической сложности. Помимо эволюционных соображений, практическая работа по нацеливанию на два или более онологов требует определения наиболее полного набора пар или групп онологов. В настоящее время наиболее надежные методы основаны на идентификации крупномасштабных областей консервативной синтении между видами [38,39]. Для проверки применимости CRISPR MultiTargeter для разработки sgRNAs, нацеленных на аналогичные гены, был выбран набор онологов, идентифицированных в последней статье о эталонном геноме рыбок данио [27].Эти авторы использовали метод сравнения дважды консервативных синтений рыбок данио с человеком, чтобы идентифицировать 3440 пар онологов и в общей сложности 8083 онологов, которые представляют 26% всех генов рыбок данио. Некоторые из этих пар онологов являются парами между группами онологов. Чтобы упростить наше приложение для тестирования, парные группы были разбиты на все возможные пары, в результате чего получилось 6305 пар генов. Упрощенная версия CRISPR MultiTargeter с параметрами по умолчанию использовалась для определения общих целей для каждой пары генов.Общие сайты-мишени были идентифицированы для 2412 пар онологов (38,2%, рис. 5А), что указывает на значительную применимость CRISPR MultiTargeter для таких генов. Недавние открытия, что сайты-мишени 17-нуклеотидной sgRNA более специфичны и не менее эффективны [30], могут еще больше повысить процент целевых онологов. Доля сайтов-мишеней с единичными ошибочными совпадениями (43,9%, рис. 5A) была меньше, чем доля полностью консервативных сайтов-мишеней (56,1%, рис. 5A), что позволяет предположить, что общие сайты-мишени sgRNA могут с большей вероятностью обнаруживаться в регионах, высококонсервативных среди подобные последовательности.Интересно, что общие сайты-мишени sgRNA также были более распространены в смысловой ориентации множественных выравниваний последовательностей (57,1%, фиг. 5A), чем в антисмысловой ориентации (42,9%, фиг. 5A), что можно объяснить смещенным распределением. последовательности «GG» в различных цепях ДНК консервативных областей выравнивания. Распределение количества общих сайтов-мишеней для разных пар онологов сильно смещено в сторону небольшого количества сайтов-мишеней, при этом некоторые гены показывают большее количество общих сайтов-мишеней (рис.5Б). Результаты этого вычислительного анализа указывают на широкую применимость CRISPR MultiTargeter для нацеливания на оба дублированных гена одновременно с одной sgRNA. Такое приложение может быть полезно для упрощения нацеливания на одну или несколько пар дублированных генов. Поскольку первоначально продемонстрированное мультиплексное редактирование генома с помощью системы CRISPR / Cas9 [40] теперь применяется к разным видам и целям [41,42], то часто случается, что некоторые из генов имеют дубликаты, на которые пользователь может захотеть нацелить .В качестве альтернативы, если ген имеет известные онологи, CRISPR MultiTargeter может идентифицировать целевые сайты для этого гена, отсутствующие в других геномах, без выполнения полногеномного поиска. Наконец, для решения проблем, связанных с нецелевой активностью, пользователь может применить одно из доступных программ для прогнозирования отклонений от цели [21,22].
Рис. 5. Общие сайты-мишени для CRISPR sgRNA типа II в онологах рыбок данио.
А . Доли пар генов с идентифицированными общими сайтами-мишенями sgRNA, сайтами-мишенями с единичными несовпадениями и без несовпадений, а также в смысловой и антисмысловой цепях.Сайты sgRNA имеют длину 20 п.н. с 5’-динуклеотидом NN и последовательностью NGG PAM. В . Распределение общего числа общих целевых сайтов для разных пар генов. Среднее количество целевых сайтов (6,48) указано пунктирной линией на гистограмме. Оси графика масштабируются с использованием функции извлечения квадратного корня. Полосы гистограммы окрашены в соответствии с шкалой частот, как показано.
https://doi.org/10.1371/journal.pone.0119372.g005
Сравнение CRISPR MultiTargeter с другими инструментами проектирования sgRNA
Чтобы подчеркнуть, почему текущее программное обеспечение может быть полезно для успешного проектирования sgRNA, и предоставить сравнительный анализ многих других программных инструментов, мы собрали несколько важных функций инструментов дизайна sgRNA (Таблица 1).Возможно, что некоторые инструменты не включены, но этот обзор является репрезентативным, а не исчерпывающим. Большинство современных программных средств поддерживают либо доминирующую в настоящее время систему CRISPR Cas9 типа II из Streptococcus pyogenes , либо несколько систем типа II из других видов бактерий. Напротив, CRISPR MultiTargeter поддерживает все эти и другие системы CRISPR / Cas, если пользователь может указать положение (5 ’или 3’) относительно целевого сайта и последовательности PAM, используя стандартный алфавит нуклеиновых кислот.Хотя эта функция не имеет непосредственного значения, другие системы CRISPR / Cas, вероятно, будут приняты для экспериментального использования и, следовательно, потребуют новых функций программного обеспечения, аналогичных реализованным нами. Как и другие программные инструменты, CRISPR MultiTargeter работает как веб-инструмент, принимает как вводимые последовательности, так и несколько различных типов идентификаторов, поддерживает конструктивные типы никазы дикого типа и Cas9, содержит базу данных последовательностей из нескольких модельных систем и важных для сельского хозяйства видов. и, как и 4 других инструмента (Optimized CRISPR Design, sgRNAcas9, sgRNA Designer, CRISPRseek), поддерживает анализ в пакетном режиме.В отличие от других инструментов, мы не проводили нецелевой анализ отдельных sgRNA, разработанных с использованием наших инструментов, потому что это не было основной задачей программного обеспечения, а скорее предоставляли пользователю подробные инструкции как на страницах ввода, так и на страницах вывода о том, как искать для удаленных целей с использованием недавно разработанных специализированных веб-инструментов Cas-OFFinder [22] и GT-Scan [23], двух программ, которые хорошо интегрируются с CRISPR Multitargeter. Интересно, что авторы инструмента sgRNA Designer [19] также не реализовали анализ вне мишени из-за потенциальной нерелевантности расщепления вне мишени для поставленной экспериментальной цели и связанных с этим вычислительных затрат.Однако основная цель sgRNA Designer заключалась в реализации модели оценки sgRNA, основанной на высокопроизводительных экспериментах на клеточных линиях, в которых анализировалось влияние 1841 20-нуклеотидных sgRNA типа II на 9 генов. Эта модель представляет логистическую регрессию предпочтений нуклеотидов в различных положениях, а также некоторые глобальные особенности, такие как содержание GC. Мы реализовали эту модель в неизмененном виде в CRISPR MultiTargeter, надеясь, что она поможет пользователям выбрать более эффективные sgRNA. Однако мы обнаружили, что количество эффективных sgRNA находится в диапазоне от 0.1 и 0,2 (неопубликованные наблюдения). Поэтому на веб-сайте представлены некоторые инструкции, чтобы пользователь мог интерпретировать эти оценки. Системы оценки для sgRNA все еще находятся в зачаточном состоянии, и необходимы дополнительные исследования в нескольких модельных системах для проверки прогнозов эффективности sgRNA, сделанных с помощью этой модели, с необходимостью разработки дополнительных моделей.
Хотя описанные выше особенности важны, основным аргументом в пользу CRISPR MultiTargeter было изучение нескольких похожих последовательностей и идентификация сайтов-мишеней sgRNA, общих для этих последовательностей или уникальных для одной из них.Среди доступных в настоящее время инструментов единственным, обеспечивающим несколько схожую функциональность, является CRISPRseek [18], разработанный как пакет Bioconductor и способный идентифицировать целевые сайты sgRNA, имеющие разную эффективность расщепления между двумя очень похожими последовательностями, такими как аллели гена. Такое приложение не было реализовано в CRISPR MultiTargeter, поскольку оно предназначено для анализа набора более разнородных последовательностей. Таким образом, эти два инструмента могут иметь взаимодополняющее использование, и подход, аналогичный подходу в CRISPRseek, также может быть реализован в CRISPR MultiTargeter в качестве дополнительного рабочего процесса.Независимо от сходства и различий между этими двумя инструментами, мы считаем, что наличие таких инструментов, как CRISPR MultiTargeter и CRISPRseek, будет способствовать разработке таргетинга CRISPR / Cas, фокусируясь не только на изолированном гене или сайте, но и на более широком контексте различных аллелей. , похожие гены и изоформы транскриптов.
Выводы
Мы разработали веб-инструмент CRISPR MultiTargeter для поддержки мутационного таргетинга и геномной инженерии с использованием недавно разработанной системы CRISPR / Cas.Это программное обеспечение имеет две отличительные особенности в своем применении: во-первых, простое определение новой спецификации целевого сайта sgRNA и, во-вторых, с учетом набора схожих последовательностей, возможность идентифицировать целевые сайты, общие для всех этих последовательностей, а также те, которые уникальны для каждой конкретной последовательности. последовательность в комплекте. Подобно другому программному обеспечению для разработки sgRNA, мы также обеспечиваем дизайн sgRNA для нацеливания на мутации мутантами Cas9 дикого типа и никазы Cas9, а также несколько вариантов для определения сайта-мишени, ввода последовательности и удобного формата вывода.Мы также реализовали недавно разработанный алгоритм оценки качества [19]. CRISPR MultiTargeter в настоящее время может применяться к геномам девяти животных, трех видов растений, а также к нуклеотидным последовательностям Refseq любых видов, и можно легко добавить дополнительные базы данных по видам. Существует три различных алгоритма поиска целевых сайтов sgRNA. Пользователь может искать сайты sgRNA, сопоставляя отдельные последовательности с определением сайта-мишени sgRNA. Для обычных мишеней sgRNA легко выполнить множественное выравнивание последовательностей с последующим сопоставлением целевого сайта консенсусной последовательности.Напротив, идентификация уникальных сайтов-мишеней в каждой последовательности требует использования алгоритма сравнения строк между всеми возможными сайтами-мишенями в различных последовательностях. Программа была протестирована с помощью вычислений, найдя sgRNA, специфичные для изоформ транскрипта, во всех альтернативных транскриптах у рыбок данио, что выявило широкую применимость инструмента для этой задачи и значительный потенциал для анализа мутаций, специфичных для изоформ транскриптов, у многих видов. Второе испытание программы было сосредоточено на дублированных генах у рыбок данио и привело к идентификации общих целевых сайтов почти 40% пар генов.Такие общие сайты-мишени можно использовать для одновременной инактивации пар генов в экспериментах по инактивации нескольких генов. У рыбок данио распространенность дублированных генов составляет около 26%, что делает такое применение весьма актуальным. Таким образом, мы предполагаем, что CRISPR MultiTargeter дополнит существующие инструменты для создания sgRNA CRISPR и упростит новые типы генетического анализа.
Благодарности
Хотя этот проект специально не финансировался каким-либо грантом, мы с благодарностью отмечаем грантную поддержку проекта IGNITE (Орфанные болезни: идентификация генов и новая терапия для улучшения лечения), предоставленного Genome Atlantic и рабочий грант 287512 Канадского института исследований в области здравоохранения.
Вклад авторов
Задумал и спроектировал эксперименты: старший вице-президент. Проведены эксперименты: SVP VR. Анализировал данные: SVP VR. Предоставленные реагенты / материалы / инструменты анализа: DG. Написал статью: SVP VR DG JNB. Провел проверку скриптов перед хостингом, вывел сайт в онлайн: DG SVP.
Ссылки
- 1. Bhaya D, Davison M, Barrangou R (2011) Системы CRISPR-Cas у бактерий и архей: универсальные малые РНК для адаптивной защиты и регулирования.Анну Преподобный Женет 45: 273–297. pmid: 22060043
- 2. Shah SA, Erdmann S, Mojica FJM, Garrett RA (2013) Мотивы распознавания Protospacer. РНК Биол 10: 891–899. pmid: 23403393
- 3. Mojica FJM, Díez-Villaseñor C, García-Martínez J, Almendros C (2009) Последовательности коротких мотивов определяют цели системы защиты прокариот CRISPR. Микробиология 155: 733–740. pmid: 19246744
- 4. Сорек Р., Лоуренс С.М., Виденхефт Б. (2013) CRISPR-опосредованные адаптивные иммунные системы у бактерий и архей.Анну Рев Биохим 82: 237–266. pmid: 23495939
- 5. Jinek M, Chylinski K, Fonfara I, Hauer M, Doudna JA, Charpentier E. (2012) Программируемая эндонуклеаза ДНК, управляемая двойной РНК, в адаптивном бактериальном иммунитете. Наука 337: 816–821. pmid: 22745249
- 6. Конг Л., Ран Ф.А., Кокс Д., Лин С., Барретто Р., Хабиб Н. и др. (2013) Мультиплексная геномная инженерия с использованием систем CRISPR / Cas. Наука 339: 819–823. pmid: 23287718
- 7. Мали П., Ян Л., Эсвелт К. М., Аач Дж., Гуэль М., ДиКарло Дж. Э. и др.(2013) РНК-управляемая инженерия генома человека с помощью Cas9. Наука 339: 823–826. pmid: 23287722
- 8. Кэрролл Д. (2014) Геномная инженерия с целевыми нуклеазами. Анну Рев Биохим 83: 409–439. pmid: 24606144
- 9. Hou Z, Zhang Y (2013) Эффективная инженерия генома в плюрипотентных стволовых клетках человека с использованием Cas9 из Neisseria meningitidis. Proc Natl Acad Sci U S A 110: 15644–15649. pmid: 23940360
- 10. Сюй К., Жэнь Ц., Лю З., Чжан Т., Чжан Т., Ли Д. и др.(2014) Эффективная инженерия генома у эукариот с использованием Cas9 из Streptococcus thermophilus. Cell Mol Life Sci.
- 11. Walsh RM, Hochedlinger K (2013) Вариант системы CRISPR-Cas9 добавляет гибкости в геномную инженерию. Proc Natl Acad Sci U S A 110: 15514–15515. pmid: 24014593
- 12. Грисса И., Вергно Дж., Пурсель С. (2007) База данных CRISPRdb и инструменты для отображения CRISPR и создания словарей спейсеров и повторов. BMC Bioinformatics 8: 172.pmid: 17521438
- 13. Hwang WY, Fu Y, Reyon D, Maeder ML, Tsai SQ, Sander JD и др. (2013) Эффективное редактирование генома рыбок данио с использованием системы CRISPR-Cas. Nat Biotechnol 31: 227–229. pmid: 23360964
- 14. Naito Y, Hino K, Bono H, Ui-Tei K (2014) CRISPRdirect: программное обеспечение для разработки направляющей РНК CRISPR / Cas с уменьшенным количеством сайтов вне цели. Биоинформатика: 1–4. pmid: 25189783
- 15. Xie S, Shen B, Zhang C, Huang X, Zhang Y (2014) sgRNAcas9: программный пакет для разработки CRISPR sgRNA и оценки потенциальных сайтов расщепления вне цели.PLoS One 9: e100448. pmid: 24956386
- 16. Montague TG, Cruz JM, Gagnon JA, Church GM, Valen E (2014) CHOPCHOP: веб-инструмент CRISPR / Cas9 и TALEN для редактирования генома. Нуклеиновые кислоты Res 42: W401 – W407. pmid: 24861617
- 17. Heigwer F, Kerr G, Boutros M (2014) E-CRISP: быстрая идентификация целевого сайта CRISPR. Нат Методы 11: 122–123. pmid: 24481216
- 18. Чжу Л.Дж., Холмс Б.Р., Аронин Н., Бродский М.Х. (2014) CRISPRseek: пакет биокондукторов для идентификации целевых направляющих РНК для систем редактирования генома CRISPR-Cas9.PLoS One 9: e108424. pmid: 25247697
- 19. Doench JG, Hartenian E, Graham DB, Tothova Z, Hegde M, Smith I, et al. (2014) Рациональный дизайн высокоактивных sgRNA для инактивации гена, опосредованной CRISPR-Cas9. Nat Biotechnol.
- 20. Gratz SJ, Ukken FP, Rubinstein CD, Thiede G, Donohue LK, Cummings AM и др. (2014) Высокоспецифичная и эффективная гомологически-направленная репарация, катализируемая CRISPR / Cas9, у дрозофилы. Генетика 196: 961–971. pmid: 24478335
- 21.Xiao A, Cheng Z, Kong L, Zhu Z, Lin S, Gao G и др. (2014) CasOT: инструмент для поиска вне мишени Cas9 / gRNA по всему геному. Биоинформатика 30: 1180–1182.
- 22. Bae S, Park J, Kim J- S (2014) Cas-OFFinder: быстрый и универсальный алгоритм, который ищет потенциальные нецелевые сайты эндонуклеаз, управляемых РНК Cas9. Биоинформатика 30: 1473–1475. pmid: 24463181
- 23. О’Брайен А., Бейли Т.Л. (2014) GT-Scan: определение уникальных геномных мишеней. Биоинформатика: 1–3.pmid: 25189783
- 24. Hsu PD, Scott DA, Weinstein JA, Ran FA, Konermann S, Agarwala V, et al. (2013) ДНК-специфичность нацеливания на РНК-управляемые нуклеазы Cas9. Nat Biotechnol 31: 827–832. pmid: 23873081
- 25. Ларкин М.А., Блэкшилдс Г., Браун Н.П., Ченна Р., МакГеттиган П.А., МакВильям Х. и др. (2007) Clustal W и Clustal X версии 2.0. Биоинформатика 23: 2947–2948. pmid: 17846036
- 26. Cock PJA, Antao T, Chang JT, Chapman BA, Cox CJ, Dalke A и др.(2009) Biopython: свободно доступные инструменты Python для вычислительной молекулярной биологии и биоинформатики. Биоинформатика 25: 1422–1423. pmid: 19304878
- 27. Хоу К., Кларк М.Д., Торроха К.Ф., Торранс Дж., Бертло С., Маффато М. и др. (2013) Эталонная последовательность генома рыбок данио и ее связь с геномом человека. Природа 496: 498–503. pmid: 23594743
- 28. Ран Ф.А., Сюй П.Д., Лин Си-И, Гутенберг Дж. С., Конерманн С., Тревино А. Э. и др. (2013) Двойное проникновение с помощью РНК-управляемой CRISPR Cas9 для повышения специфичности редактирования генома.Cell 154: 1380–1389. pmid: 23992846
- 29. Fu Y, Foden JA, Khayter C, Maeder ML, Reyon D, Joung JK и др. (2013) Высокочастотный мутагенез вне мишени, индуцированный нуклеазами CRISPR-Cas в клетках человека. Nat Biotechnol 31: 822–826. pmid: 23792628
- 30. Fu Y, Sander JD, Reyon D, Cascio VM, Joung JK (2014) Повышение специфичности нуклеазы CRISPR-Cas с использованием усеченных направляющих РНК. Nat Biotechnol 32: 279–284. pmid: 24463574
- 31. Сугимото Н., Накано С., Катох М., Мацумура А., Накамута Н., Омичи Т. и др.(1995) Термодинамические параметры для прогнозирования стабильности гибридных дуплексов РНК. Биохимия 34: 11211–11216. pmid: 7545436
- 32. Dumousseau M, Rodriguez N, Juty N, Le Novere N (2012) MELTING, гибкая платформа для прогнозирования температур плавления нуклеиновых кислот. BMC Bioinformatics 13: 101. pmid: 225
- 33. Menke DB (2013) Разработка тонких целевых мутаций в геноме мыши. Бытие 51: 605–618. pmid: 23 6
- 34. Вулф К. (2000) Надежность — это не то, о чем вы думаете.Нат Генет 25: 3–4. pmid: 10802639
- 35. Panopoulou G, Poustka AJ (2005) Время и механизм дупликаций генома древних позвоночных — приключение гипотезы. Тенденции Genet 21: 559–567. pmid: 16099069
- 36. Kasahara M (2007) Гипотеза 2R: обновление. Curr Opin Immunol 19: 547–552. pmid: 17707623
- 37. Postlethwait JH (2007) Геном рыбок данио в контексте: исчезнувшие технологии. J Exp Zool 577: 563–577.
- 38.Catchen JM, Conery JS, Postlethwait JH (2009) Автоматическая идентификация консервативной синтении после дупликации всего генома. Genome Res 19: 1497–1505. pmid: 19465509
- 39. Кураку С., Мейер А. (2012) Выявление и филогенетическая оценка консервативной синтении, полученной при дублировании всего генома. Методы Мол Биол 855: 385–395. pmid: 22407717
- 40. Jao L-E, Wente SR, Chen W (2013) Эффективное мультиплексное двуаллельное редактирование генома рыбок данио с использованием системы нуклеаз CRISPR.Proc Natl Acad Sci U S A 110: 13904–13909. pmid: 23918387
- 41. Сакума Т., Нисикава А., Куме С., Чаяма К., Ямамото Т. (2014) Мультиплексная геномная инженерия в человеческих клетках с использованием комплексной векторной системы CRISPR / Cas9. Sci Rep 4: 5400. pmid: 24954249
- 42. Ма И, Шен Б., Чжан Икс, Лу И, Чен В., Ма Дж и др. (2014) Наследственная мультиплексная генная инженерия у крыс с использованием CRISPR / Cas9. PLoS One 9: e89413. pmid: 24598943
21 уникальная тенденция веб-дизайна на 2021 год
Добро пожаловать в наш ежегодный обзор тенденций веб-дизайна.От ретро-типографики до постоянно растущего движения без кода — в 2021 году есть на что рассчитывать.
2020 год был непростым. С его галлонами дезинфицирующего средства для рук, неудобными встречами Zoom и надвигающейся тревогой неопределенности, мы все чувствуем себя немного измотанными. Несмотря на обстоятельства, мы все сделали все возможное, чтобы пройти через все это. Многие из нас потратили время на изучение новых дизайнерских навыков. А некоторые из нас только что испекли хлеб на закваске. У всех нас есть свои навыки выживания.
Когда дело дошло до дизайна, мы следили за нескончаемыми тенденциями в Интернете.Поговорив с командой Brand Studio в Webflow и несколькими другими дизайнерами, мы составили исчерпывающий список некоторых тенденций веб-дизайна, которые мы ожидаем увидеть в 2021 году. Мы надеемся, что этот список не только вдохновит вас, но и вдохновит. подходить к Интернету более инклюзивно и доступно.
21 современная тенденция веб-дизайна на 2021 год
Вот 21 тенденция веб-дизайна, которая также поможет сделать 2021 год немного ярче.
1. Ретро-шрифты
Мы видели, как многие старые вещи снова становились крутыми, а затем, в свою очередь, становились еще менее крутыми.Подумайте об усах на руле и джинсах для мамы. Ирония недолговечна.
Ретро-шрифты испытали те же приливы и отливы своей популярности, и многие дизайны с винтажной типографикой не устарели.
Однако типографика с возвратом пережила некоторое возрождение. Мы не видим таких же утомленных шрифтов. Скорее, стилизация и немного артистизма переосмысливают, какими могут быть ретро-шрифты.
Мы видим это слияние старого и нового на странице продвижения Spotify Carnival.Вместо того, чтобы казаться устаревшими и клише, они вдохнули новую жизнь в традиционные жирные шрифты, немного поэкспериментировав. Это хороший пример использования традиционных шрифтов и придания им классного и современного стиля, сохраняя при этом разборчивость.
На этом веб-сайте компании по организации мероприятий Goliath Entertainment чувствуется ретрофутуризм. Смелая типографика отсылает к прошлому, но при этом очень актуальна.
В 2021 году мы с нетерпением ждем более творческого переосмысления типографики.
2. Анимация прокрутки параллакса
Эффекты прокрутки параллакса были тенденцией в дизайне веб-сайтов в течение многих лет, и в 2021 году мы надеемся увидеть более тонкие и творческие исследования того, чего можно достичь с помощью параллакса.
Помните, что слишком большое количество движений в эффектах параллакса может быть вредным для людей с вестибулярными расстройствами, потому что иллюзия глубины и движения может вызвать дезориентацию и головокружение. Вот несколько рекомендаций, которые, как мы видим, все больше дизайнеров принимают во внимание, чтобы гарантировать, что они включают параллакс минимально и не причиняют вреда:
- Не позволяйте эффектам параллакса отвлекать важную информацию
- Не усложняйте для пользователя выполнение важная задача
- Свести количество эффектов параллакса к минимуму
- Свести к минимуму количество перемещений параллакса в каждом экземпляре
- Ограничить эффекты параллакса в пределах небольшой области экрана
- Включить возможность для пользователей отключить эффекты параллакса
Сайт портфолио Алисы Ли использует эффекты параллакса, которые реагируют на положение мыши, чтобы оживить ее иллюстрацию.Количество движений невелико и ограничено рамками героя. Это отличный пример использования параллакса с ограничениями и намерениями.
Не всякая параллакс-анимация должна отображать большие жесты по экрану. Мы также видели более тонкие приложения. В этом веб-дизайне для Green Meadow этот эффект можно было почти полностью упустить. Но это мягкое раскрытие текста создает достаточное сопоставление, чтобы привлечь внимание к каждому блоку текста по мере его появления.
В следующем году мы будем рады видеть, как прокрутка с параллаксом используется тонко, не для яркого эффекта, а как инструмент для выделения или выделения важных фрагментов контента.
3. Горизонтальная прокрутка
Горизонтальная прокрутка, которая раньше считалась ошибкой веб-дизайна, возвращается.
Все больше веб-дизайнеров продолжают экспериментировать с горизонтальной прокруткой. Те, кто это делает, лучше всего ломают шаблон не ради того, чтобы отличаться, а как практический способ постепенно раскрывать вторичную информацию, как в галерее изображений.
Дизайнеры, успешно использующие горизонтальную прокрутку в 2021 году, будут иметь в виду следующие соображения:
- Не заставляйте пользователей перемещаться по горизонтальному содержимому: разрешите альтернативные способы навигации, такие как кнопки со стрелками с четкими метками
- Используйте четкие визуальные подсказки для указать, где контент использует горизонтальную прокрутку, и не скрывать эти подсказки за наведениями.
- Подумайте о том, какой контент выиграет от отображения в горизонтальной прокрутке — фотогалерея — хороший соперник, поскольку горизонтальная прокрутка показала бы пользователям небольшой предварительный просмотр и предоставить им возможность просматривать больше или продолжать движение вниз по странице.
- Избегайте необходимости горизонтальной прокрутки для текста, который необходимо прочитать.
На нашей собственной странице функций Designer мы использовали небольшую горизонтальную прокрутку для увеличения на большом изображении и покажите более релевантные фрагменты изображения в большем размере, чтобы сопровождать релевантный контент.
На главной странице Momento Design Studio есть четкая подсказка рядом с основной кнопкой, которая также действует как ссылка, медленно перемещая вас к избранным работам при нажатии. Движение прокрутки идет в быстром темпе и не слишком длинное, что позволяет отображать избранные изображения.
McBride Design использует горизонтальную прокрутку для демонстрации больших фотографий своих работ, не занимая слишком много места на странице. Они также включают в себя четкий индикатор в правом нижнем углу, который устанавливает ожидание, что страница будет прокручиваться по горизонтали.
4. 3D-визуализация повсюду
С появлением экранов с более высоким разрешением 3D-дизайн прошел долгий путь от блочных и скошенных краев Geocities. Мы наблюдаем, как высококачественные 3D-изображения органично вплетаются в веб-дизайн. Вместо того, чтобы отвлекать внимание, они улучшают общее впечатление пользователя.
Креативное агентство Sennep добавляет глубины с помощью трехмерных элементов на своем веб-сайте. Здесь присутствует приятное чувство гармонии между всеми элементами дизайна.Это прекрасный пример того, как в более минималистичных макетах 3D может произвести еще большее впечатление.
Yaya поместила свою любовь к 3D во главу угла своей домашней страницы с помощью этой причудливой и крутой анимации героя.
В приведенном ниже примере от компании Pitch, производящей программное обеспечение для презентаций, они имеют красочную компоновку, полную трехмерных форм, теней, градиентов и многослойных элементов. Эти элементы трехмерного дизайна воплощают этот дизайн в жизнь.
Трехмерные элементы добавляют уникальности и объемности любой веб-странице.
5. Мультимедийные возможности
Поскольку большинство людей имеют доступ к более высокоскоростному Интернету, мультимедийные возможности Интернета появляются повсюду. Объединение визуальных элементов, текста, видео и аудио делает пользовательский интерфейс более удобным.
Успешные проекты в 2021 году будут использовать ограничения с мультимедийными возможностями:
- Сделайте ставку на простоту, например, при сочетании движения и звука. Слишком много происходящего может отвлекать или подавлять людей с когнитивными расстройствами.
- Обдуманно используйте различные форматы мультимедиа, чтобы сделать контент максимально доступным.
- Включите скрытые субтитры и стенограммы для всех предварительно записанных мультимедиа.
- Включайте замещающий текст для изображений и сопровождайте сложные изображения более длинным описательным текстом.
- Убедитесь, что весь текст написан с использованием HTML, а не отображается внутри изображений.
- Избегайте автоматического воспроизведения видео или движущегося содержимого: вместо этого предоставьте четкую кнопку «воспроизведение», которая дает пользователю возможность воспроизвести и приостановить воспроизведение содержимого.
Эффективное и доступное использование мультимедиа требует учета множества факторов. Вот дополнительные ресурсы о доступности видео.
На сайте Николаса Эрреры есть элементы управления воспроизведением красивого фонового видео: оно воспроизводится при нажатии, а также может быть приостановлено. Он также включает в себя тонкую анимацию, которая показывает, насколько далеко вы находитесь в видео.
Мультимедийные возможности работают во многих различных областях. В приведенном ниже примере мы видим снимок экрана из Black Yearbook.Это краудфандинговая книга, составленная Адрейнтом Берэлом и его друзьями, чтобы показать, каково быть афроамериканским учеником, посещающим преимущественно белые школы. Полные элементы управления воспроизведением четко видны на всех видео. Красиво снятый кинематографический фильм переходит от одной сцены к другой в начале дизайна с гипнотическим саундтреком, играющим на заднем плане, что очень похоже на трейлер к фильму. За этим введением стоит страсть, и вы захотите углубиться в изучение книги и движений, стоящих за ней.
И для чего-то необычного, мы собираемся завершить этот список мультимедийных примеров с MSCHF, печально известной компанией, стоящей за множеством вирусных веб-дропов. Внешний вид MSCHF пересекает линию брутализма с почти абсурдистским дизайном, который сочетает в себе строгую типографику, текстовые SMS-сообщения и другие элементы.
6. Опыт дополненной реальности (AR)
А с мультимедийными возможностями, давайте не будем забывать все удивительные впечатления от погружения с использованием дополненной реальности (AR).AR теперь означает больше, чем просто охота на покемонов на вашем мобильном устройстве Apple или Android. Новые технологии, такие как API WebXR и программное обеспечение от Wayfair Technologies, открыли эту сферу почти для всех.
Jeep использует дополненную реальность для страницы «Сборка и цена джипа». Для тех, кто ненавидит заходить в автосалоны, это будет легким и беззаботным опытом. Все больше веб-сайтов розничной торговли и электронной коммерции используют возможности дополненной реальности, чтобы продавать свои продукты и расширять возможности потенциальных клиентов в процессе покупки.
7. Акцент на зернистость
Жесткие сетки и плоские однотонные блоки действительно могут лишить веб-дизайн индивидуальности. Зернистая текстура придаст им более естественный вид.
Мы видим красоту зернистости на этом веб-сайте Studio Gusto. Он использует элементы дизайна lo-fi для более грубого взаимодействия с пользователем, которое кажется более естественным, чем гладкое совершенство, которое является обычным явлением во многих веб-дизайнах.
8. Акцент на приглушенные цвета
Так же, как зерно может придать дизайну более естественное ощущение, приглушенные цвета могут сделать это.
Magic Theater Studio использует светлую цветовую палитру вместе с темными блоками зеленого цвета, что создает четкий контраст между разделами этого веб-дизайна. Эти приглушенные цвета являются идеальным фоном для нарисованного от руки текста и иллюстраций. На заднем плане есть слегка жужжащая зернистость, которая почти неразличима, и легкое искажение светлого и темного фона, что делает дизайн очень живым.
Это маркетинговое портфолио для Бобби Роу, представленное ниже, представляет собой праздник цвета и содержит информативные и забавные записи о работе, которую он выполняет.Может быть трудно создать веб-дизайн, который был бы хорошо продуман, но Бобби Роу справился с этим веб-дизайном. Есть хорошее разнообразие приглушенных цветов и более смелых.
9. Дизайн на основе предпочтений
Веб-разработка сделала большие успехи в предоставлении более персонализированного опыта. Это может быть что угодно: от переключения между темным / светлым режимом и другими способами изменения внешнего вида сайта и навигации до предложения контента, адаптированного к вашему вкусу, например, пользовательских списков воспроизведения, созданных Spotify.
Новые методы проектирования и алгоритмы делают Интернет менее пассивным и ориентированным на пользователя. В будущем еще больше внимания будет уделяться удовлетворению потребностей, желаний и вкусов тех, кто просматривает веб-сайты.
10. Размытие по Гауссу
Размытие по Гауссу очень хорошо работает для обеспечения плавного фокуса изображений и градиентов. Этот эффект существует уже некоторое время, но дизайнеры использовали его в более заметных областях веб-дизайна.
Moment House начинает свою домашнюю страницу не с изображения героя, а с приятного гауссовского размытия цветов. Это придает атмосферность и напрямую перекликается с фотографией городского пейзажа Лос-Анджелеса, которая следует за ней. Он идеально передает линзу золотого света и дымки, через которую просматривается Лос-Анджелес.
Мы видим размытие по Гауссу на заднем плане Monograph Communications. Это пушистое смешение красного, пурпурного и синего цветов создает приятный контраст между прямыми линиями и жирной типографикой, которая их накладывает.
Портфолио UX Я Тамара использует тот же подход, добавляя немного размытия по Гауссу на задний план.
Goodbooks объединяет похожий на пар пузырь размытия по Гауссу. Снимок экрана ниже не передает этого должного, но похоже на то, что скрыто за белым экраном. Мы видим изменение и вращение формы, но никогда не видим полностью, что это такое. Это создает такой замечательный визуальный якорь и привлекает внимание к призыву к действию под ним, чтобы проверить их 12 лучших рекомендуемых книг.
Нам нравится видеть, как вещи, которые существовали вечно, например размытие по Гауссу, становятся все более популярными в руках дизайнеров, которые используют их по-новому и интересно.
11. Прокрутка
Мы заметили растущую тенденцию в том, что дизайнеры рассказывают истории через веб-интерфейс. Здесь на помощь приходит скролл-повествование — визуальное повествование, которое подчеркивает сюжет и вовлекает вас в его повествование.
Лучшие применения ограничения практики скроллинга:
- Сохраняйте движение в пределах небольшой области.
- Обеспечьте взаимодействие на условиях пользователя: предоставьте очевидные элементы управления воспроизведением для воспроизведения / приостановки / остановки взаимодействий и движений.
- Убедитесь, что любые элементы прокрутки помогают выделить историю, а не отвлекают от важного текста.
На нашем собственном сайте истории искусства веб-дизайна используются небольшие, тонкие анимации и красивые иллюстрации, которые подтверждают рассказ о том, как история искусства влияет на веб-дизайн.
12. Темный режим
Акцентируйте внимание на показе AC DC «Снова в черном», потому что темный режим появится на экранах в 2021 году.Все больше дизайнеров принимают эстетику темного режима, где черный цвет обеспечивает идеальный темный фон, чтобы элементы дизайна выделялись на экране.
В приведенном ниже примере агентство Obys разработало прекрасную дань уважения модельеру Питеру Линдбергу, соединив тонко текстурированный черный фон с красивым шрифтом с засечками.
Не бойтесь уйти из жизни в 2021 году с собственными дизайнерскими работами.
13. Мультяшные иллюстрации
Не так давно были времена, когда веб-сайты были просто текстом и несколькими изображениями или графикой.Веб-дизайн эволюционировал, и теперь дизайнеры создают работу, которая связывает людей с людьми на более личном уровне. Мультяшные иллюстрации приобрели популярность как способ трансформации веб-сайтов со здоровой человечностью.
Существует так много источников и художников, создающих фантастические мультяшные иллюстрации. Blush — отличная платформа для поиска пользовательских иллюстраций персонажей, таких как этот отличный набор от Виджая Верма.
Карикатуры предлагают очень многое с точки зрения творчества и делают бренд более представительным.Мы с нетерпением ждем появления в следующем году новых персонажей веб-дизайна.
14. Геометрические сетки
Сетки просты, но обладают большой гибкостью в том, как их можно интегрировать в проект. Геометрические сетки набирают популярность как способ структурировать макет, придавая ему четкий и смелый вид.
Этот дизайн от Хадсона Гэвина и Мартина использует блоки как для элементов навигации, так и для контента. По этим большим цветным квадратам интересно перемещаться, и они так хорошо работают, удерживая ваше внимание.
Геометрические сетки не обязательно должны располагаться одинаково. Flowmingo использует более асимметричную геометрическую сетку, но в основе их макета лежат квадраты и линии. Более толстые линии подчеркивают квадратные формы во всем.
И для более легкого прикосновения мы получили красивое расположение квадратов и четких линий в этой геометрической сетке для косметической компании Skin Labs.
Геометрические сетки должны быть в наборе инструментов любого веб-дизайнера, чтобы обеспечить прочную структуру и простое представление.
15. Пользовательские курсоры
Курсоры, вероятно, являются одним из наиболее недооцененных аспектов веб-дизайна, и большинство из нас довольствуется простой старой стрелкой. Когда дизайнер может взять эту незначительную часть сайта и превратить ее во что-то крутое, это настоящее достижение.
Мы только что говорили о HGM Legal и об их использовании геометрических сеток, но у них также есть необычный жирный черный курсор.
Инструмент «Перо» продвигает круговой курсор на один шаг дальше, объединяя анимацию и текст, создавая почти психоделический эффект.
Или посмотрите на этот трансформирующийся круговой курсор от Büro, который меняет свой внешний вид в зависимости от того, над каким элементом дизайна он наведен.
В 2021 году мы надеемся увидеть больше оригинальных вариантов того, чем может быть курсор.
16. Карточки с прокруткой
Мы были рады видеть, что карточки с прокруткой стали неотъемлемой частью дизайна. Независимо от того, прокручиваются ли они по горизонтали или по вертикали, они добавляют на сайт мгновенное действие и являются отличным способом представления информации.
На этом веб-сайте Ofcina используются привлекательные цвета для прокручиваемых карточек.
Макеты карт существуют довольно давно, и нам нравится видеть, как они используются в новых направлениях прокрутки.
17. Бесцветный дизайн
Редкий белый цвет создает чистый дизайн, а любые цветные элементы привлекают еще больше внимания.
В этом дизайне для латинских дизайнеров много белого пространства с эффектом наведения, который преобразует черно-белое изображение каждого дизайнера в полноцветное.
Даже что-то вроде минималистичного простого дизайна может быть интересным благодаря микровзаимодействию, анимации и другим динамическим эффектам.
User Experience Database также использует бесцветный подход к дизайну, что делает его минимальным и легким для чтения.
18. Аудио
Использование звука в качестве неотъемлемой части дизайна устраняет барьеры доступности для людей с нарушениями зрения, а также приносит пользу тем, кто предпочитает слушать большой кусок текста на веб-сайте,
The New York Times отлично справляется с предоставлением звукового сопровождения к некоторым из представленных ими статей.
Мы надеемся, что в будущем на веб-сайтах появится больше возможностей для звука, что даст людям возможность выбирать, как они хотят воспринимать контент.
19. Интернет, вдохновленный печатью
С цифровой техникой, которая заменила так много, что когда-то были физическими объектами, произошло возрождение старых медиа. Популярность виниловых альбомов является доказательством того, что люди хотят испытать что-то, кроме кучи нулей и единиц.
Макеты, вдохновленные печатью, удовлетворяют желание людей найти что-то в реальном мире. Макеты в стиле журналов и другие элементы традиционного графического дизайна обеспечивают связь с тактильными ощущениями от печати на бумаге.
Приведенный выше пример из Home Run Studio и приведенный ниже для Foundamour черпают вдохновение из печати, давая им знакомство и связь с публикацией.
20. Системы проектирования для единообразия
Системы проектирования мощные. Используя CMS для создания повторяемых макетов и связанных коллекций, легко обновлять или редактировать, а также быстро создавать дублирующиеся веб-сайты. Независимо от того, используются ли они в малых или больших масштабах, они полезны для любой организации при создании и управлении своими проектами.
Руководство по стилю от SaaslyМы также видели действительно полезные приложения, разработанные, чтобы еще больше упростить рабочие процессы дизайн-системы. Zeroheight действует как централизованное пространство для управления задачами и совместной работы. Figma предлагает шаблоны, а также другие инструменты для систем дизайна. А коллекция CMS от Webflow может поддерживать дизайн-систему любого размера.
21. Отсутствие кода
Отсутствие кода не означает полное исключение кода. Программисты и разработчики всегда будут важны.Никакой кодекс не означает открытия этих областей знаний для тех, кто в противном случае был бы освобожден. Это позволяет творить любому, у кого есть идея или видение.
Без кода дизайнеры становятся фронтенд-разработчиками. Писатели становятся веб-дизайнерами. А владельцы малого бизнеса могут окунуться в мир электронной коммерции. Кем бы вы ни были, никакой код не дает вам возможности стать чем-то большим. Он убирает границу между не дизайнерами, теми, кто занимается только дизайном, и теми, кто занимается разработкой. Он объединяет людей в сотрудничестве.
Было захватывающе наблюдать за развитием новых платформ без кода, а также за разработкой курсов дизайна, которые включают в свои учебные программы учения об этом. Нам не терпится увидеть, что произойдет с отказом от кода в 2021 году.
Мы с нетерпением ждем 2021 года
Всегда интересно наблюдать, как веб-дизайн продолжает меняться и продолжает расти движение без кода.
Нам тоже не терпится увидеть, что вы собираетесь создать в новом году. Разместите свои последние работы в нашей витрине и не забудьте присоединиться к поддерживающему и растущему сообществу на нашем форуме сообщений.

Об авторе