Расшифровка текста: Универсальный декодер текста — Хитрые инструменты
Перевод кодировки онлайн

Если вам прислали текстовый документ, информация в котором отображается в виде странных и непонятных символов, можно предположить, что автор использовал кодировку, не распознаваемую вашим компьютером. Для изменения кодировки существуют специальные программы-декодеры, однако куда проще воспользоваться одним из онлайн-сервисов.
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
Перейти на сайт Универсальный декодер
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.

- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».

- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Обратите внимание на то, что если в отправленном вам документе вместо символов отображается «???? ?? ??????», преобразовать его вряд ли получится. Символы появляются из-за ошибок со стороны отправителя, поэтому просто попросите отправить вам текст повторно.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
Перейти на сайт Студия Артемия Лебедева
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.

- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.

- Щелкаем на кнопку «Расшифровать».
- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.

С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
Перейти на сайт Fox Tools
- Вводим исходный текст в верхнее поле.

- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.

- После завершения настроек нажимаем на кнопку «Отправить».

- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.

- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».

Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Читайте также: Выбор и изменение кодировки в Microsoft Word
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
 Мы рады, что смогли помочь Вам в решении проблемы.
Мы рады, что смогли помочь Вам в решении проблемы.Помогла ли вам эта статья?
ДА НЕТПерекодировка текста онлайн
Периодически случается так, что приходят письма, которые невозможно прочитать — они заполнены какими-то непонятными знаками. Происходит такое и с документами. Причина этого кроется в использовании неверной кодировки символов. Что с этим можно сделать, как прочитать что там написано?
Есть два варианта: самому подбирать кодировки или доверить этот процесс специальным программам. Алгоритм нахождения исходной кодировки не очевиден и, скорее всего, сведется к простому перебору. Это долгий и неэффективный метод. Использование онлайн программ позволяет практически мгновенно увидеть читабельный текст.
Способы конвертирования текста онлайн
Любая поисковая система в ответ на запрос «Перекодирование онлайн» выдаст несколько адресов, где можно бесплатно расшифровать текст. Мы рассмотрим наиболее популярные и удобные сервисы, которые без труда переведут нечитаемый текст в изначальный вид.
Способ 1: 2Cyr
Универсальный декодер работает только с кириллическими символами. Сервис пытается изменить кодировку, но если это сделать не удается, предлагаются другие варианты для выбора. На странице можно ознакомиться с пошаговым алгоритмом действий и небольшим количеством теории.
Перейти на сайт 2Cyr
Для перекодировки текста нужно выполнить следующие действия:
- Зайдите на сайт сервиса.
- Вставьте скопированный из источника текст в поле для декодирования.
- В поле «Выбрать кодировку»
- Через небольшой промежуток времени в нижнем поле появится результат.
- В строке «Выберите читаемый вариант перекодировки» нажмите на стрелку справа. В выпадающем окне появится список вариантов. Выберите с помощью мыши любой и нажмите кнопку «ОК», которая находится справа.
- Итог появится в поле для результата.
- Перейдите по ссылке выше.
- Скопированный тестовый фрагмент вставьте в поле.
- Нажмите кнопку «Определить».
- Результат выдается в виде таблицы, где текст приведен не полностью.
- Чтобы увидеть всю расшифрованную запись, необходимо нажать на кнопку с изображением двух стрелок.
- Другие варианты расшифровки можно увидеть, нажав на кнопку «Все найденные».
- Зайдите на сайт по ссылке, указанной выше.
- Текст для перекодировки вставьте в соответствующее поле.
- Выберите режим декодирования кнопками «Просто» или «Сложно». В данном случае выбран простой способ преобразования.
- Нажмите «Расшифровать».
- В режиме «Просто» результат работы Декодера Артемия Лебедева появляется в том же поле, куда ранее был вставлен текст.

Итоговую информацию можно понять, но невозможно использовать в документах. Определены исходная и конечные кодировки символов.
- Для более глубокого преобразования следует нажать поле «Сложно».

При этом способе доступен выбор таблиц символов. По умолчанию используется автоматическая кодировка.
- Целевая таблица символов выбирается щелчком мыши на поле «Автоматическая кодировка».
- Результат расшифровки можно увидеть во втором поле Декодера. В зависимости от разрешения монитора оно находится либо внизу экрана, либо справа.


Размер исходного текста ограничен 100 КБ.


Универсальный декодер определил тип исходной кодировки, но не справился с некоторыми символами. Тем не менее, текст можно прочитать и приблизительно понять, о чем идет речь. Конвертер кириллицы также предоставляет возможность посмотреть и выбрать альтернативные варианты расшифровки.


Способ 2: Alexpad
В отличие от предыдущего декодера, здесь текст можно не только скопировать в поле, но и загрузить из файла. Документ должен быть в формате TXT и размером не более 500 КБ.
Alexpad работает со всеми известными кодировками символов. На этом сайте также, как и на 2Cyr, есть теоретическая информация о проблеме, и о том как работает перекодировщик. Для ускорения работы декодер обрабатывает по 200 символов. Делает он это достаточно быстро, но если имеется большой текст, придется все время вставлять и копировать его куски.
Перейти на сайт Alexpad
Шаги по расшифровке текста с помощью этого сайта должны быть такими:






Способ 3: Декодер студии Артемия Лебедева
Расшифровщик дизайн студии имеет минималистичное оформление. Кроме поля для исходного текста на странице имеются кнопки для выбора простого или сложного перекодирования.
Перейти на сайт студии Артемия Лебедева
Работа с ним происходит следующим образом:






Качество обработки примерно такое же, как и в простом режиме. Присутствует информация об исходной и конечной кодировках текста.
Тестирование онлайн перекодировщиков подтвердило, что, к сожалению, не всякий текст может быть приведен к нужному виду без ошибок. Когда сервис не может найти соответствие какому-то числу, он подставляет на его место символ, близкий по числовому значению, а не изображению. Обычно используется вопросительный знак «?», но могут применяться и другие варианты. В таких случаях нужно или согласиться с таким представлением и попробовать разобраться в том, что получилось, или обратиться к профессионалам. Тем не менее, онлайн-декодеры имеют право на жизнь. Они часто помогают прочитать то, что, на первый взгляд, прочитать невозможно.
Автоопределение кодировки текста / Хабр
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
Таблица KOI8-r
В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему —
01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Конвертер текста — itTricks
Укажите исходные данные
Обычный текстBase64 — Binary DataHexadecimal — Binary DataJSON/JavaScript/Java — String TextC/C++/PHP — String TextQuoted-Printable — MIME EmailSQL — String TextURL — HTTP GETWWW Form — HTTP POSTXML/HTML — Document Text
Результат
Обычный текстBase64 — Binary DataHexadecimal — Binary DataJSON/JavaScript/Java — String TextC/C++/PHP — String TextQuoted-Printable — MIME EmailSQL — String TextURL — HTTP GETWWW Form — HTTP POSTXML/HTML — Document Text
Быстрое онлайн кодирование, декодирование текста.
Инструмент автоматически определяет формат и кодировку, когда вы вставите данные в поле ввода. Поддерживаемые форматы: base64, hexadecimal, JSON, Java, C++, PHP, quoted-printable, URL, HTTP POST, XML, UTF-8 и другие.
Кодер и декодер запускаются в браузере (через JavaScript) без какой-либо обработки на стороне сервера.
Base64 – кодирование используется для передачи двоичных или текстовых данных в виде (7-bit) ASCII. Он также может быть использован для кодирования URI, кодирования изображений и др.
Вывод использует только 64 символа (A-Za-z0-9+/) для данных,
=
для заполнения пробелами. Поскольку каждые 3 байта данных преобразуются в 4 байта при выводе, формат Base64 приводит к увеличению размера 33% результирующих данных.- JSON, JavaScript, Java, C, C++ & PHP – статья в Википедии о строковых литералах предоставляет сведения о различных символах escape-последовательности, используемых в различных языках программирования.
- Quoted-printable – The quoted-printable encoding is used for converting 8-bit or UTF-8 text into
printable (7-bit) ASCII. It is mostly used in email and
other MIME applications.
Since quoted-printable does not specify the character encoding, it is important to specify this correctly when encoding or decoding. This is sometimes added to message headers or inside a string prefix (in Q-encoding), e.g.=?iso-8859-1?Q?=
. - URL & WWW-form – URL or Percent encoding is used for transferring non-ASCII characters inside
URLs and POST:ed form data (on the web). It is sometimes
also known as WWW-form encoding.
All text is encoded as UTF-8, using a%
followed by two hexadecimal digits for special or reserved characters. Some variations exist for handling spaces (+
or%20
), newlines and special URL characters (=
,&
, etc). - UTF-8 – UTF-8 is a binary text encoding for Unicode. It is reasonably
space efficient for latin languages, but supports the
full Unicode character range (i.e. most known scripts).
Each character is stored into a variable number of bytes. Since JavaScript internally uses only two bytes for each character (UTF-16), this conversion utility only handles code points between U+0000 and U+FFFF. The result is 1 to 3 characters of output per input character.
5 интересных систем шифрования. Разгадайте секретные слова | Конкурсы и тесты
В этот день свой профессиональный праздник отмечает Криптографическая служба России.
«Криптография» с древнегреческого означает «тайнопись».
Как раньше прятали слова?
Своеобразный метод передачи тайного письма существовал во времена правления династии египетских фараонов:
выбирали раба. Брили его голову наголо и наносили на неё текст сообщения водостойкой растительной краской. Когда волосы отрастали, его отправляли к адресату.
Шифр — это какая-либо система преобразования текста с секретом (ключом) для обеспечения секретности передаваемой информации.
АиФ.ru сделал подборку интересных фактов из истории шифрования.
Все тайнописи имеют системы
1. Акростих — осмысленный текст (слово, словосочетание или предложение), сложенный из начальных букв каждой строки стихотворения.
Вот, например, стихотворение-загадка с разгадкой в первых буквах:
Довольно именем известна я своим;
Равно клянётся плут и непорочный им,
Утехой в бедствиях всего бываю боле,
Жизнь сладостней при мне и в самой лучшей доле.
Блаженству чистых душ могу служить одна,
А меж злодеями — не быть я создана.
Юрий Нелединский-Мелецкий
Сергей Есенин, Анна Ахматова, Валентин Загорянский часто пользовались акростихами.
2. Литорея — род шифрованного письма, употреблявшегося в древнерусской рукописной литературе. Бывает простая и мудрая. Простую называют тарабарской грамотой, она заключается в следующем: поставив согласные буквы в два ряда в порядке:
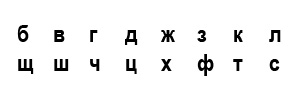
употребляют в письме верхние буквы вместо нижних и наоборот, причём гласные остаются без перемены; так, например, токепот = котёнок и т. п.
Мудрая литорея предполагает более сложные правила подстановки.
3. «ROT1» — шифр для детишек?
Возможно, в детстве вы тоже его использовали. Ключ к шифру очень прост: каждая буква алфавита заменяется на последующую букву.
А заменяется на Б, Б заменяется на В и так далее. «ROT1» буквально означает «вращать на 1 букву вперёд по алфавиту». Фраза «Я люблю борщ» превратится в секретную фразу «А мявмя впсъ». Этот шифр предназначен для развлечения, его легко понять и расшифровать, даже если ключ используется в обратном направлении.
4. От перестановки слагаемых…
Во время Первой мировой войны конфиденциальные сообщения отправляли с помощью так называемых перестановочных шрифтов. В них буквы переставляются с использованием некоторых заданных правил или ключей.
Например, слова могут быть записаны в обратном направлении, так что фраза «мама мыла раму» превращается во фразу «амам алым умар». Другой перестановочный ключ заключается в перестановке каждой пары букв, так что предыдущее сообщение становится «ам ам ым ал ар ум».
Возможно, покажется, что сложные правила перестановки могут сделать эти шифры очень трудными. Однако многие зашифрованные сообщения могут быть расшифрованы с использованием анаграмм или современных компьютерных алгоритмов.
 Диск с шифром Цезаря. Фото: mr.santak/commons.wikimedia.org
Диск с шифром Цезаря. Фото: mr.santak/commons.wikimedia.org5. Сдвижной шифр Цезаря
Он состоит из 33 различных шифров, по одному на каждую букву алфавита (количество шифров меняется в зависимости от алфавита используемого языка). Человек должен был знать, какой шифр Юлия Цезаря использовать для того, чтобы расшифровать сообщение. Например, если используется шифр Ё, то А становится Ё, Б становится Ж, В становится З и так далее по алфавиту. Если используется шифр Ю, то А становится Ю, Б становится Я, В становится А и так далее. Данный алгоритм является основой для многих более сложных шифров, но сам по себе не обеспечивает надёжную защиту тайны сообщений, поскольку проверка 33-х различных ключей шифра займёт относительно небольшое время.
Никто не смог. Попробуйте вы
Зашифрованные публичные послания дразнят нас своей интригой. Некоторые из них до сих пор остаются неразгаданными. Вот они:
 Манускрипт Войнича. «Ботанический» раздел содержит изображения растений. Фото:commons.wikimedia.org
Манускрипт Войнича. «Ботанический» раздел содержит изображения растений. Фото:commons.wikimedia.orgМанускрипт Войнича
Это 240-страничная книга, написанная на абсолютно неизвестном языке с цветными рисунками и странными диаграммами, изображениями невероятных событий и растений, которые не похожи ни на один известный вид.
 Криптос у штаба ЦРУ в Лэнгли, штат Вирджиния. Фото: Jim Sanborn/commons.wikimedia.org
Криптос у штаба ЦРУ в Лэнгли, штат Вирджиния. Фото: Jim Sanborn/commons.wikimedia.orgКриптос. Скульптура, созданная художником Джимом Санборном, которая расположена перед штаб-квартирой Центрального разведывательного управления в Лэнгли, Вирджиния. Скульптура содержит в себе четыре шифровки, вскрыть код четвёртой не удаётся до сих пор. В 2010 году было раскрыто, что символы 64-69 NYPVTT в четвёртой части означают слово БЕРЛИН.
 Криптограмма № 1 — местонахождение тайника. Фото: commons.wikimedia.org
Криптограмма № 1 — местонахождение тайника. Фото: commons.wikimedia.orgШифр Бэйла — это комплект из трёх шифровок, которые, предположительно, раскрывают местонахождение одного из величайших захороненных сокровищ в американской истории: многих тысяч фунтов золота, серебра и драгоценных камней.
Теперь, когда вы прочитали статью, то наверняка сможете разгадать три простых шифра.

Свои варианты оставляйте в комментариях к этой статье. Ответ появится в 13:00 13 мая 2014 года.
Ответ:
1) Блюдечко
2) Слоненку все надоело
3) Хорошая погода
Смотрите также:
Расшифровщик текстов — Удаленная работа в интернете
Доброго здоровья, уважаемый читатель журнала «Web4job.ru”! В этой статье мы поговорим на тему Расшифровщик текстов (транскрибатор), какими навыками необходимо обладать для этой работы.
Расшифровщик текстов
Содержание статьи:
Расшифровка или транскрибация текста подходит для людей, не имеющих постоянного дохода и желающих зарабатывать удаленно.
Транскрибацией могут заниматься студенты, женщины, находящиеся в декретном отпуске, пенсионеры.
Ее преимущество состоит в том, что работать можно дома, не надо ездить на транспорте и не сидеть 8 часов в офисе.
Такая работа пользуется спросом у заказчиков.
Переводы аудио в текст необходимы бизнесменам для расшифровки совещаний, студентам для записей и расшифровки лекций.
Поэтому найти вакансию расшифровщика аудио и видеозаписей в интернете довольно просто.
Оплачиваются такие услуги сдельно, за количество исполненных заказов. Обычно предлагается поминутный расчет или расчет за количество знаков.
Договариваясь с заказчиком об оплате, не надо забывать, что существует риск нарваться на недобросовестного заказчика, поэтому желательно до начала работы заключить договор и договориться о частичной оплате за выполненное задание.
Ни в коем случае не надо соглашаться, если клиент просит оплатить определенную сумму, якобы на почтовые расходы по пересылке аудио или видеоматериала или заплатить за обучение. Это говорит о том, что вы наткнулись на мошенника.
Необходимые качества для работы
Транскрибатор должен:
- Быть грамотным;
- Уметь печатать слепым методом, т.е всеми пальцами. Если скорость печати маленькая, будет сложно переводить аудио или видеотексты, придется постоянно останавливать или перематывать запись;
- Иметь хороший слух и память, т.к. придется работать с большими объемами информации, которые придется запоминать. Часто записи бывают плохого качества, с посторонними шумами, а говорящий может иметь плохую дикцию, что влияет на скорость расшифровки, на такие записи затрачивается времени больше, чем на перевод качественных;
- Быть ответственным и пунктуальным. Задания необходимо выполнять в установленные сроки. Если срок нарушить, это скажется на вашей репутации, вы потеряете клиента, а тот, в свою очередь, охарактеризует вас своим знакомым как неисполнительного человека, которому нельзя доверять заказы;
- Иметь компьютер с подключенным высокоскоростным интернетом, электронную почту и скайп для общения с клиентами;
- Знать основы работы на компьютере и программы, необходимые для работы;
- Иметь электронный кошелек для зачисления заработанных денег;
- Уметь пользоваться поисковыми системами. При расшифровке текстов придется проверять правильность написания многих терминов.
О категориях заказчиков вы узнаете, перейдя по ссылке https://web4job.ru/kategorii-zakazchikov/.
Посмотрим видео на тему Расшифровщик текстов
Перевод аудио и видео в текст
Расшифровка аудио в текст (транскрибация)
Заключение
В этой статье мы рассмотрели тему Расшифровщик текстов (транскрибатор), какие качества необходимы для этой работы.
Надеюсь, статья оказалась полезной. Если возникли вопросы, можете задать их через форму комментариев под этой статьей.
Также буду признательна, если поделитесь статьей со своими друзьями в социальных сетях.
Понравилось? Поделитесь с друзьями!
Получите высокооплачиваемую интернет-профессию!

Шифровать текст онлайн
Обзор наших программных решений для Windows
 Автоматический процессор электронной почты
Автоматический процессор электронной почты
Automatic Email Processor — мощное дополнение к Outlook для автоматического хранения и печати входящих писем и их вложений. Для этого, различные фильтры, гибкие параметры конфигурации, такие как индивидуально определяемые папки хранения и возможность последующей обработки доступны.
Еще …  Мастер автотекста
Мастер автотекста
AutoText Master позволяет использовать текстовые модули практически во всех приложениях. Программа помогает набирать часто используемые отрывки текста, сложные терминологические или текстовые блоки, в которых только одно значение, такое как дата или имя, должно быть введено через маску ввода и представляет изощренная альтернатива довольно элементарному Word Autotext.
Еще …  Пакетный заменитель текста
Пакетный заменитель текста
С Batch Text Replacer у вас под рукой есть мощный инструмент для одновременного редактирования нескольких текстовых файлов. Программа содержит множество мощных функций для настройки содержимого текстовых файлов по мере необходимости.
Еще …  Folder2List
Folder2List
С помощью Folder2List вы можете быстро и легко создавать списки папок и файлов.Выберите данные для отображения из множества свойств и отформатируйте данные с помощью различных параметров настройки.
Еще …  Средство извлечения вложений Outlook
Средство извлечения вложений Outlook
Outlook Attachment Extractor — полезный инструмент для Outlook, позволяющий автоматически сохранять вложения из входящих писем. Помимо прочего, доступны мощные фильтры, индивидуально определяемые папки хранения и возможность последующей обработки
Еще …  Эксперт по переименованию
Эксперт по переименованию
С помощью Rename Expert вы можете быстро и легко переименовывать файлы и папки. Программа предлагает множество инновационных функций для создания последовательных и, прежде всего, значимых имен.
Еще …  Заменитель текста Word
Заменитель текста Word
Word Text Replacer позволяет удобно выполнять замену текста в нескольких файлах Word одновременно.Например, адрес, номер телефона и т.п. можно заменить в уже обширном портфеле документов Word.
Еще ….Шифрование
AES — Простое шифрование или дешифрование строк или файлов
Symmetric Ciphers Online позволяет зашифровать или расшифровать произвольное сообщение используя несколько хорошо известных симметричные алгоритмы шифрования например AES, 3DES или BLOWFISH.
Симметричные шифры используют одинаковые (или очень похожие с алгоритмической точки зрения view) ключи как для шифрования, так и для дешифрования сообщения. Они предназначены для быть легко вычисляемым и способным обрабатывать даже большие сообщения в реальном времени.Таким образом, симметричные шифры удобны для использования одним объектом, который знает секретный ключ, используемый для шифрования и необходимый для расшифровки его частные данные — например, алгоритмы шифрования файловой системы основаны на симметричные шифры. Если симметричные шифры должны использоваться для безопасной связи между двумя или более сторонами проблемы, связанные с управлением симметричными ключами возникают. Такие проблемы можно решить с помощью гибридный подход это включает использование асимметричные шифры. Симметричные шифры являются базовыми блоками многих систем криптографии и являются часто используется с другими механизмами криптографии, которые компенсируют их недостатки.
Симметричные шифры могут работать либо в блочный режим или в потоковый режим. Некоторые алгоритмы поддерживают оба режима, другие поддерживают только один режим. В блочном режиме криптографический алгоритм разбивает входное сообщение на массив небольших блоков фиксированного размера, а затем шифрует или дешифрует блоки по одному. В потоковом режиме каждая цифра (обычно один бит) ввода сообщение шифруется отдельно.
В блочном режиме обработки, если блоки были зашифрованы полностью независимо от того, зашифрованное сообщение может быть уязвимо для некоторых тривиальных атак.Очевидно, если бы было два одинаковых блока, зашифрованных без дополнительных контекст и используя ту же функцию и ключ, соответствующие зашифрованные блоки тоже будет идентичным. Вот почему блочные шифры обычно используются в различных режимы работы. Режимы работы вводят дополнительную переменную в функцию, которая содержит состояние расчета. Состояние изменяется во время шифрования / дешифрования процесс и объединены с содержанием каждого блока. Такой подход смягчает проблемы с идентичными блоками, а также могут служить для других целей.В значение инициализации дополнительной переменной называется вектор инициализации. В различия между режимами работы блочных шифров заключаются в том, как они сочетаются вектор состояния (инициализации) с входным блоком и путь вектора значение изменяется во время расчета. Потоковые шифры сохраняются и меняются их внутреннее состояние по дизайну и обычно не поддерживает явный входной вектор значения на их входе.
Примечание по безопасности: данные передаются по сети в незашифрованном виде ! Пожалуйста, не вводите конфиденциальную информацию в форму выше поскольку мы не можем гарантировать вам, что ваши данные не будут скомпрометированы.
Используя выбор Тип входа , выберите тип входа — текстовая строка или файл. В случае ввода текстовой строки введите свой ввод в Входной текст textarea 1,2 . В противном случае используйте кнопку «Обзор», чтобы выбрать входной файл для загрузки. Затем выберите криптографическую функцию, которую вы хотите использовать в поле Функция . В зависимости от выбранной функции поле Вектор инициализации (IV) имеет вид показано или скрыто.Вектор инициализации — это всегда последовательность байтов, каждый байт должен быть представлен в шестнадцатеричной форме.
Выберите режим работы в поле Mode и введите ключ в поле Key . Допустимая длина ключей для определенных криптографических функций перечислены ниже. Если вы не укажете ключ с допустимой длиной, ключ будет продлен на правильное количество нулевых байтов в конце. При смене ключа префикс функции sha1 (key) будет автоматически заполняется поле IV.Вы все еще можете изменить IV. Функция предназначена только для вашего удобства. С помощью переключателей под Ключ поле ввода, вы можете указать, вводится ли значение ключа следует интерпретировать как обычный текст или шестнадцатеричное значение.
Наконец, нажмите «Зашифровать!» или кнопку «Расшифровать!» кнопка в зависимости от того, хотите ли вы, чтобы входное сообщение было зашифровано или расшифровано.
Выходное сообщение отображается в шестнадцатеричном виде и может быть загружено как двоичный файл.Формат выходного файла — это просто дамп двоичных данных. Вектор инициализации добавлен к имени файла для удобства.
| Криптографическая функция | Длина ключа | Длина вектора инициализации (все режимы) | ||
|---|---|---|---|---|
| В байтах | В битах | В байтах | В битах | |
| AES | 16, 24 или 32 | 128, 192 или 256 | 16 | 128 |
| DES | 1-8 байтов | 8-64 | 16 | 128 |
| ТРОЙНИКИ | От 1 до 24 | от 8 до 192 | 16 | 128 |
| BLOWFISH | 1 до 56 | 8 до 448 | 16 | 128 |
| BLOWFISH-compat | от 1 до 56 | от 8 до 448 | 16 | 128 |
| RIJNDAEL-256 | от 1 до 32 | от 8 до 256 | 64 | 512 |
| R4 | 1 до 256 | 8 до 2048 | — | — |
| SERPENT | от 1 до 32 | от 8 до 256 | 32 | 256 |
| ДВА РЫБКИ | от 1 до 32 | от 8 до 256 | 32 | 256 |
1 Вы можете использовать только шестнадцатеричные символы, символы новой строки, табуляторы и символы новой строки, если вы расшифровываете строку.
2 В вашем распоряжении есть функция автоопределения вводимого текста. Автоопределение определяет, находится ли содержимое поля Входной текст в форма обычного текста или шестнадцатеричной строки. Вы можете отключить эту функцию, нажав на «ВЫКЛ» или изменив текущий тип ввода под Текст ввода поле.
Максимальный размер вводимой текстовой строки — 131 072 символа. Максимальный размер входного файла — 2 097 152 байта.
.Vigenere Cipher — онлайн-декодер, кодировщик, решатель, транслятор
Расшифровка Vigenere требует ключа (и алфавита). Что касается шифрования, то здесь возможны два способа.
Расшифровка Vigenere путем вычитания букв
Пример: Для расшифровки NGMNI используется ключ KEY и алфавит ABCDEFGHIJKLMNOPQRSTUVWXYZ.
Для расшифровки возьмите первую букву зашифрованного текста и первую букву ключа и вычтите их значение (буквы имеют значение, равное их положению в алфавите, начиная с 0).Если результат отрицательный, прибавьте 26 (26 = количество букв в алфавите), результат дает ранг простой буквы.
Пример: Возьмите первые буквы зашифрованного текста N (значение = 13) и ключ K (значение = 10) и вычтите их (13-10 = 3), буква значения 3 будет D.
Продолжить со следующими буквами сообщения и следующими буквами ключа, когда дойдете до конца ключа, вернитесь к первому ключу ключа.
Пример: NGMNI
KEYKE
Пример: DCODE — это простой текст.
Расшифровка Vigenere с помощью таблицы
Чтобы расшифровать Vigenere с помощью квадратной таблицы с двойной записью, используйте следующую сетку (регистр букв — ABCDEFGHIJKLMNOPQRSTUVWXYZ):
005 
Ключ КЛЮЧ.
Находит первую букву ключа в левом столбце и находит в строке первую букву зашифрованного сообщения. Затем поднимитесь по столбцу, чтобы прочитать первую букву, это соответствующая простая буква.
Пример: Найдите букву K в первом столбце и в ее строке найдите ячейку с буквой N, имя ее столбца — D, это первая буква простого сообщения.
Продолжайте со следующими буквами сообщения и следующими буквами ключа, когда дойдете до конца ключа, вернитесь к первому ключу ключа.
Пример: Исходный простой текст — DCODE.
. Программа для шифрования и дешифрования в C (текстовые файлы)
#include
#include
int encrypt (void);
int decrypt (void);
int encrypt_view (недействительный);
int decrypt_view (void);
ФАЙЛ * fp1, * fp2;
символов;
int main ()
{
int выбор;
, а (1)
{
printf («Выберите одно из следующего: \ n»);
printf («\ n1.Зашифровать \ n «);
printf (» 2. Расшифровать \ n «);
printf (» 3. Просмотреть зашифрованный файл \ n «);
printf (» 4. Просмотреть зашифрованный файл \ n «) ;
printf («5. Выход \ n»);
printf («\ nВведите свой выбор: \ t»);
scanf («% d», & choice);
переключатель (выбор)
{
case 1: encrypt ();
break;
case 2: decrypt ();
break;
case 3: encrypt_view ();
break;
case 4: decrypt_view ();
break;
case 5: exit (1);
}
}
printf («\ n»);
return 0;
}
int encrypt ()
{
printf («\ n»);
fp1 = fopen («/ home / tusharso ni / Desktop / Source «,» r «);
if (fp1 == NULL)
{
printf («Исходный файл не может быть найден \ n»);
}
fp2 = fopen («/ home / tusharsoni / Desktop / Target», «w»);
if (fp2 == NULL)
{
printf («Целевой файл не может быть найден \ n»);
}
, а (1)
{
ch = fgetc (fp1);
if (ch == EOF)
{
printf («\ nКонец файла \ n»);
перерыв;
}
else
{
ch = ch — (8 * 5 — 3);
fputc (ch, fp2);
}
}
fclose (fp1);
fclose (fp2);
printf («\ n»);
возврат 0;
}
int decrypt ()
{
printf («\ n»);
fp1 = fopen («/ home / tusharsoni / Desktop / Target», «r»);
if (fp1 == NULL)
{
printf («Исходный файл не может быть найден \ n»);
}
fp2 = fopen («/ home / tusharsoni / Desktop / Source», «w»);
if (fp2 == NULL)
{
printf («Целевой файл не может быть найден \ n»);
}
, а (1)
{
ch = fgetc (fp1);
if (ch == EOF)
{
printf («\ nКонец файла \ n»);
перерыв;
}
else
{
ch = ch + (8 * 5 — 3);
fputc (ch, fp2);
}
}
fclose (fp1);
fclose (fp2);
printf («\ n»);
возврат 0;
}
int encrypt_view ()
{
printf («\ n»);
fp1 = fopen («/ home / tusharsoni / Desktop / Target», «r»);
if (fp1 == NULL)
{
printf («Файл не найден \ n»);
выход (1);
}
else
{
, а (1)
{
ch = fgetc (fp1);
если (ch == EOF)
{
перерыв;
}
else
{
printf («% c», ch);
}
}
printf («\ n»);
fclose (fp1);
}
printf («\ n»);
возврат 0;
}
int decrypt_view ()
{
printf («\ n»);
fp1 = fopen («/ home / tusharsoni / Desktop / Source», «r»);
if (fp1 == NULL)
{
printf («Файл не найден \ n»);
выход (1);
}
else
{
, а (1)
{
ch = fgetc (fp1);
если (ch == EOF)
{
перерыв;
}
else
{
printf («% c», ch);
}
}
printf («\ n»);
fclose (fp1);
}
возврат 0;
printf («\ n»);
}
.
Ключ КЛЮЧ.
Об авторе