Роботс тхт: Анализ robots.txt — Вебмастер. Справка
Анализ robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt.
Также инструмент поможет отследить изменения в файле и скачать определенную версию.
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
- Если сайт добавлен в Яндекс Вебмастер и права на его управление подтверждены
Содержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt, нажмите кнопку Проверить.
- Если сайт не добавлен в Яндекс Вебмастер
Перейдите на страницу Анализ robots.
 txt.
txt.В поле Проверяемый сайт укажите адрес вашего сайта. Например, https://example.com.
Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.
 txt.
txt.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
После проверки могут отобразиться:
Предупреждения. Они сообщают об отклонении от правил, которое инструмент может исправить самостоятельно. Также предупреждения указывают на потенциальную проблему, связанную с опечаткой или неточностью в написании правил.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.
Подробное описание см. в разделе Справочник по ошибкам анализа robots.txt.
в разделе Справочник по ошибкам анализа robots.txt.
Когда ваш файл robots.txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
В поле Список URL укажите адрес страницы, которую хотите проверить. Можно указать полный URL или адрес относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите кнопку Проверить.
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.
Чтобы своевременно узнавать об изменениях файла robots.txt, настройте уведомления.
Яндекс Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt.
Список версий отображается, если одновременно выполнены следующие условия:
вы добавили сайт в Яндекс Вебмастер и подтвердили права на управление сайтом;
в Яндекс Вебмастере есть информация об изменениях robots.
 txt.
txt.
Вы можете:
- Просмотреть текущую и предыдущие версии файла
Выберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt, а также результаты анализа.
- Скачать выбранную версию файла
Выберите из списка Версия robots.txt версию файла.
Нажмите кнопку Скачать. Файл сохранится на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например http://example.com вместо http://www.example.com. Формально это два различных URL. Проверяемые URL должны принадлежать сайту, для которого производится анализ robots.txt.
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
Зачем вам нужен файл robots.txt, и как его создать?
Файл robots.txt, он же стандарт исключений для роботов — это текстовый файл, в котором хранятся определенные указания для роботов поисковых систем.
Прежде, чем сайт попадает в поисковую выдачу и занимает там определенное место, его исследуют роботы. Именно они передают информацию поисковым системам, и далее ваш ресурс отображается в поисковой строке.
Robots.txt выполняет важную функцию — он может защитить весь сайт или некоторые его разделы от индексации. Особенно это актуально для интернет-магазинов и других ресурсов, через которые совершаются онлайн-оплаты. Вам же не хочется, чтобы кредитные счета ваших клиентов вдруг стали известны всему интернету? Для этого и существует файл robots.txt.
Про директивы
Поисковые роботы по умолчанию сканируют все ссылки подряд, если только не установить им ограничений.
Главная директива-приветствие, с которой начинается индексация файла — это user-agent
Она может выглядеть так:User-agent: Yandex
Или так:
User-agent: *
Или вот так:
User-agent: GoogleBot
User-agent обращается к конкретному роботу, и дальнейшие руководства к действию будут относиться только к нему.
Так, в первом случае инструкции будут касаться только роботов Яндекс, во втором — роботов всех поисковых систем, в последнем — команды предназначены главному роботу Google.
Резонно спросить: зачем обращаться к роботам по отдельности? Дело в том, что разные поисковые “посланцы” по разному подходят к индексации файла. Так, роботы Google беспрекословно соблюдают директиву sitemap (о ней написано ниже), в то время как роботы Яндекса относятся к ней нейтрально.
Однако, если у вас простой сайт с несложными разделами, рекомендуем не делать исключений и обращаться ко всем роботам сразу, используя символ *.
Вторая по значимости директива — disallow
Она запрещает роботам сканировать определенные страницы. Как правило, с помощью disallow закрывают административные файлы, дубликаты страниц и конфиденциальные данные.На наш взгляд, любая персональная или корпоративная информация должна охраняться более строго, то есть требовать аутентификации. Но, все же, в целях профилактики рекомендуем запретить индексацию таких страниц и в robots.txt.
Директива может выглядеть так:
User-agent: *
Disallow: /wp-admin/
Или так:
User-Agent: Googlebot
Disallow: */index.php
Disallow: */section.php
В первом примере мы закрыли от индексации системную панель сайта, а во втором запретили роботам сканировать страницы index. php и section.php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
php и section.php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
Следующая директива — allow
В противовес предыдущей, это команда разрешает индексировать информацию.
Может показаться странным: зачем что-то разрешать, если поисковой робот по умолчанию готов всё сканировать? Оказывается, это нужно для выборочного доступа. К примеру, вы хотите запретить раздел сайта с названием /korobka/.
Тогда команда будет выглядеть так:
User-agent: *
Disallow: /korobka/
Но в то же время в разделе коробки есть сумка и зонт, который вы не прочь показать другим пользователям.
User-agent: *
Disallow: /korobka/
Allow: /korobka/sumka/
Allow: /korobka/zont/
Таким образом, вы закрыли общий раздел korobka, но открыли доступ к страницам с сумкой и зонтом.
Sitemap — еще одна важная директива. По названию можно предположить, что эта инструкция как-то связана с картой сайта. И это верно.
И это верно.
Если вы хотите, чтобы при сканировании вашего сайта поисковые роботы в первую очередь заходили в определенные разделы, нужно в корневом каталоге сайта разместить вашу карту — файл sitemap. В отличие от robots.txt, этот файл хранится в формате xml.
Если представить, что поисковой робот — это турист, который попал в ваш город (он же сайт), логично предположить, что ему понадобится карта. С ней он будет лучше ориентироваться на местности и знать, какие места посетить (то есть проиндексировать) в первую очередь. Директива sitemap послужит роботу указателем — мол, карта вон там. А дальше он уже легко разберется в навигации по вашему сайту.
Как создать и проверить robots.txt
Стандарт исключений для роботов обычно создают в простом текстовом редакторе (например, в Блокноте). Файлу дают название robots и сохраняют формате txt.
Далее его надо поместить в корневой каталог сайта. Если вы все сделаете правильно, то он станет доступен по адресу “название вашего сайта”/robots. txt.
txt.
Самостоятельно прописать директивы и во всем разобраться вам помогут справочные сервисы. Воспользуйтесь любыми на выбор: Яндекс или Google. С их помощью за 1 час даже неопытный пользователь сможет разобраться в основах.
Когда файл будет готов, его обязательно стоит проверить на наличие ошибок. Для этого у главных поисковых систем есть специальные веб-мастерские. Сервис для проверки robots.txt от Яндекс:
Сервис для проверки robots.txt от Google:
https://www.google.com/webmasters/tools/home?hl=ru
Когда забываешь про robots.txt
Как вы уже поняли, файл robots совсем не сложно создать. Однако, многие даже крупные компании почему-то забывают добавлять его в корневую структуру сайта. В результате — попадание нежелательной информации в просторы интернета или в руки мошенников плюс огромный общественный резонанс.
Так, в июле 2018 года СМИ говорили об утечке в Сбербанке: в поисковую выдачу Яндекс попала персональная информация клиентов банка — со скриншотами паспортов, личными счетами и номерами билетов.
Не стоит пренебрегать элементарными правилами безопасности сайта и ставить под сомнение репутацию своей компании. Лучше не рисковать и позаботиться о правильной работе robots.txt. Пусть этот маленький файл станет вашим надежным другом в деле поисковой оптимизации сайтов.
Дальше: 20 способов ускорить загрузку сайта в 2018 году
Robots.txt: Руководство для начинающих
Содержание
Robots.txt:
Простой файл, содержащий компоненты, используемые для указания страниц веб-сайта, которые нельзя сканировать (или в некоторых случаях необходимо сканировать). поисковыми ботами. Этот файл необходимо поместить в корневой каталог вашего сайта. Стандарт для этого файла был разработан в 1994 году и известен как стандарт исключения роботов или протокол исключения роботов.
Некоторые распространенные заблуждения о robots.txt:
- Блокирует индексацию контента и его отображение в результатах поиска.

Если вы перечислите определенную страницу или файл в файле robots.txt, но URL-адрес страницы будет найден во внешних ресурсах, роботы поисковых систем все равно могут сканировать и индексировать этот внешний URL-адрес и отображать страницу в результатах поиска. Кроме того, не все роботы следуют инструкциям, данным в файлах robots.txt, поэтому некоторые боты все равно могут сканировать и индексировать страницы, упомянутые в файле robots.txt. Если вам нужен дополнительный блок индексации, метатег robots со значением «noindex» в атрибуте контента будет служить таковым при использовании на этих конкретных веб-страницах, как показано ниже:
Подробнее об этом читайте здесь.
- Защищает частное содержимое.
Если у вас есть частный или конфиденциальный контент на сайте, который вы хотите заблокировать от ботов, пожалуйста, не полагайтесь только на robots.txt. Желательно использовать защиту паролем для таких файлов или вообще не публиковать их в сети.
Желательно использовать защиту паролем для таких файлов или вообще не публиковать их в сети.
- Гарантирует отсутствие дублирования индексации контента.
Поскольку файл robots.txt не гарантирует, что страница не будет проиндексирована, использовать его для блокировки дублирующегося контента на вашем сайте небезопасно. Если вы используете robots.txt для блокировки дублированного контента, убедитесь, что вы также используете другие надежные методы, такие как тег rel=canonical.
- Гарантирует блокировку всех роботов.
В отличие от ботов Google, не все боты являются законными и поэтому могут не следовать инструкциям файла robots.txt, чтобы заблокировать определенный файл от индексации. Единственный способ заблокировать этих нежелательных или вредоносных ботов — заблокировать их доступ к вашему веб-серверу с помощью конфигурации сервера или сетевого брандмауэра, при условии, что бот работает с одного IP-адреса.
Использование robots.txt:
В некоторых случаях использование robots.txt может показаться неэффективным, как указано в предыдущем разделе. Однако у этого файла есть причина, и это его важность для SEO на странице.
Ниже приведены некоторые практические способы использования файла robots.txt:
- Для предотвращения посещения краулерами личных папок.
- Чтобы роботы не сканировали менее примечательный контент на веб-сайте. Это дает им больше времени для сканирования важного контента, который должен отображаться в результатах поиска.
- Чтобы разрешить сканирование вашего сайта только определенным ботам. Это экономит пропускную способность. Поисковые боты по умолчанию запрашивают файлы robots.txt. Если они не найдут его, они сообщат об ошибке 404, которую вы найдете в файлах журнала. Чтобы избежать этого, вы должны как минимум использовать файл robots.txt по умолчанию, то есть пустой файл robots.txt.
- Для предоставления ботам местоположения вашего файла Sitemap.
 Для этого введите в файле robots.txt директиву, в которой указано местоположение вашего файла Sitemap:
Для этого введите в файле robots.txt директиву, в которой указано местоположение вашего файла Sitemap: - Карта сайта: http://yoursite.com/sitemap-location.xml
Вы можете добавить это в любом месте файла robots.txt, потому что директива не зависит от строки пользовательского агента. Все, что вам нужно сделать, это указать местоположение вашего файла Sitemap в части sitemap-location.xml URL-адреса. Если у вас несколько файлов Sitemap, вы также можете указать расположение файла индекса Sitemap. Узнайте больше о файлах Sitemap в нашем блоге XML Sitemaps.
Ознакомьтесь с нашим Руководством по поисковой оптимизации Robots.txt, чтобы узнать, как работают файлы robots.txt и как их можно использовать для SEO.
Примеры файлов robots.txt:
В файле robots.txt есть два основных элемента: User-agent и Disallow.
Агент пользователя: Агент пользователя чаще всего представлен подстановочным знаком (*), который представляет собой знак звездочки, означающий, что инструкции по блокировке предназначены для всех ботов.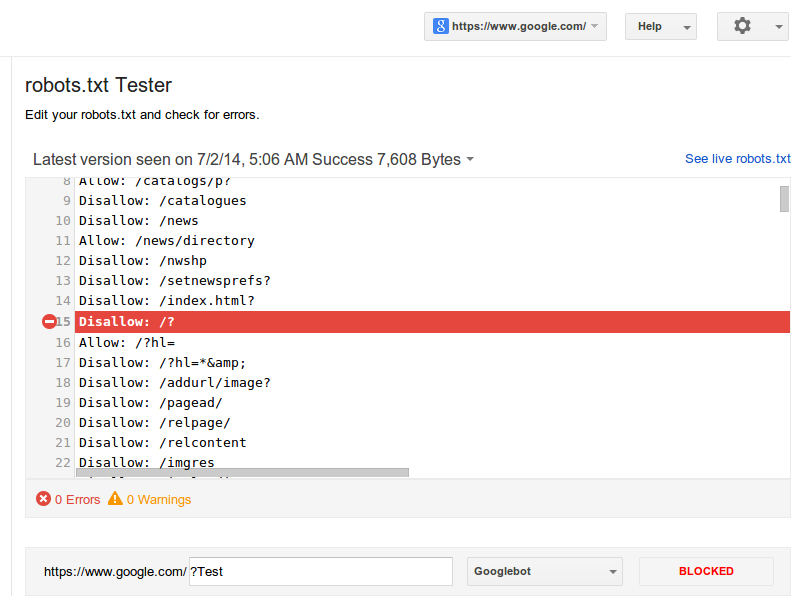 Если вы хотите, чтобы определенные боты были заблокированы или разрешены на определенных страницах, вы можете указать имя бота в директиве пользовательского агента.
Если вы хотите, чтобы определенные боты были заблокированы или разрешены на определенных страницах, вы можете указать имя бота в директиве пользовательского агента.
Disallow: если ничего не указано в disallow, это означает, что боты могут сканировать все страницы на сайте. Чтобы заблокировать определенную страницу, вы должны использовать только один префикс URL для каждого запрета. Вы не можете включать несколько папок или префиксов URL-адресов в элемент disallow в файле robots.txt.
Ниже приведены некоторые распространенные варианты использования файлов robots.txt.
Чтобы разрешить всем ботам доступ ко всему сайту (по умолчанию robots.txt) используется следующее:
User-agent:* Disallow:
Чтобы заблокировать весь сервер от ботов, используется этот robots.txt:
User-agent:* Disallow: /
Разрешить одного робота и запретить другим роботам:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Чтобы заблокировать сайт от одного робота:
Агент пользователя: XYZbot Запретить: /
Чтобы заблокировать некоторые части сайта:
Агент пользователя: * Запретить: /tmp/ Запретить: /junk/
Используйте этот файл robots. txt для блокировки всего содержимого определенный тип файла. В этом примере мы исключаем все файлы, которые являются файлами Powerpoint. (ПРИМЕЧАНИЕ: знак доллара ($) указывает на конец строки):
txt для блокировки всего содержимого определенный тип файла. В этом примере мы исключаем все файлы, которые являются файлами Powerpoint. (ПРИМЕЧАНИЕ: знак доллара ($) указывает на конец строки):
User-agent: * Disallow: *.ppt$
Блокировать ботов из определенного файла:
User-agent: * Disallow: / каталог/файл.html
Для сканирования определенных HTML-документов в каталоге, который заблокирован от ботов, вы можете использовать директиву Allow. Некоторые основные поисковые роботы поддерживают директиву Allow в файле robots.txt. Пример показан ниже:
User-agent: * Disallow: /folder/ Allow: /folder1/myfile.html
Чтобы заблокировать URL-адреса, содержащие определенные строки запроса, которые могут привести к дублированию содержимого, используется приведенный ниже файл robots.txt. В этом случае любой URL, содержащий вопросительный знак (?), блокируется:
User-agent: * Disallow: /*?
Иногда страница будет проиндексирована, даже если вы включите ее в файл robots. txt по таким причинам, как внешняя ссылка. Чтобы полностью заблокировать отображение этой страницы в результатах поиска, вы можете добавить метатеги robots noindex на эти страницы по отдельности. Вы также можете включить тег nofollow и указать ботам не переходить по исходящим ссылкам, вставив следующие коды:
txt по таким причинам, как внешняя ссылка. Чтобы полностью заблокировать отображение этой страницы в результатах поиска, вы можете добавить метатеги robots noindex на эти страницы по отдельности. Вы также можете включить тег nofollow и указать ботам не переходить по исходящим ссылкам, вставив следующие коды:
Чтобы страница не индексировалась:
Для того, чтобы страница не индексировалась и по ссылкам не переходили:
ПРИМЕЧАНИЕ: Если вы добавите эти страницы в файл robots. txt, а также добавить указанный выше метатег на страницу, она не будет сканироваться, но страницы могут отображаться в списках результатов поиска только по URL-адресам, поскольку ботам было специально заблокировано чтение метатегов на странице.
Еще один важный момент: вы не должны включать URL-адреса, заблокированные в файле robots.txt, в карту сайта XML. Это может произойти, особенно если вы используете отдельные инструменты для создания файла robots. txt и XML-карты сайта. В таких случаях вам, возможно, придется вручную проверить, включены ли эти заблокированные URL-адреса в карту сайта. Вы можете проверить это в своей учетной записи Google Webmaster Tools, если ваш сайт отправлен и проверен в инструменте, а также отправлена ваша карта сайта.
txt и XML-карты сайта. В таких случаях вам, возможно, придется вручную проверить, включены ли эти заблокированные URL-адреса в карту сайта. Вы можете проверить это в своей учетной записи Google Webmaster Tools, если ваш сайт отправлен и проверен в инструменте, а также отправлена ваша карта сайта.
Перейдите на страницу Инструменты для веб-мастеров > Оптимизация > Карты сайта , и если инструмент покажет какую-либо ошибку сканирования в отправленных картах сайта, вы можете дважды проверить, включена ли эта страница в robots.txt.
Кроме того, в GWT есть инструмент тестирования robots.txt. Он находится в разделе Инструменты для веб-мастеров > Здоровье > Заблокированные URL-адреса .
Этот инструмент — отличный способ научиться пользоваться файлом robots.txt. Вы можете увидеть, как роботы Google будут обрабатывать URL-адреса после того, как вы введете URL-адрес, который хотите протестировать.
Наконец, есть несколько важных моментов, о которых следует помнить, когда дело доходит до robots.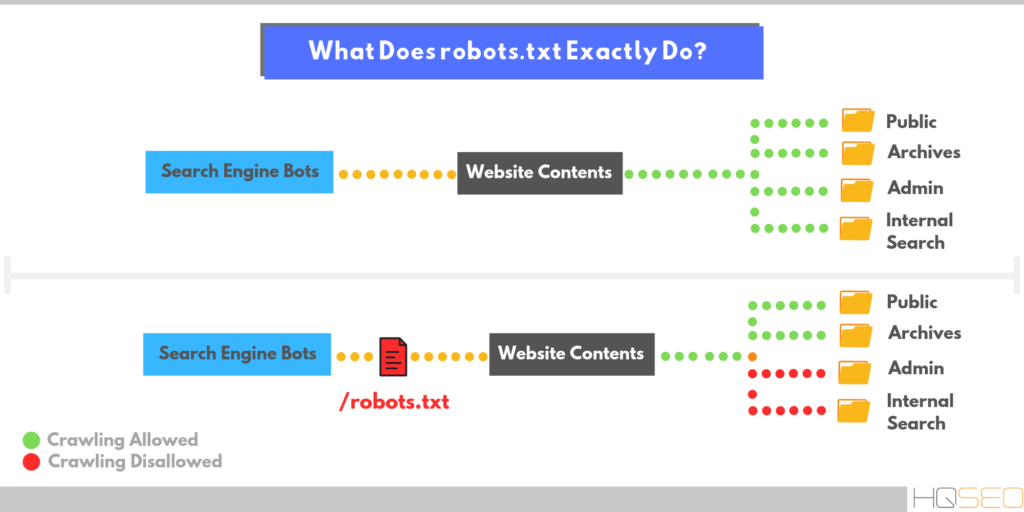 txt:
txt:
- Если вы используете косую черту после каталога или папки, это означает, что robots.txt заблокирует каталог или папку и все, что в ней , как показано ниже:
- Запретить: /junk-directory/
- Убедитесь, что файлы CSS и коды JavaScript, отображающие расширенное содержимое, не заблокированы в файле robots.txt, так как это будет препятствовать предварительному просмотру фрагментов.
- Проверьте свой синтаксис с помощью Google Webmaster Tool или поручите это кому-то, кто хорошо разбирается в robots.txt, иначе вы рискуете заблокировать важный контент на своем сайте.
- Если у вас есть два раздела пользовательского агента, один для всех ботов и один для определенного бота, скажем, Googlebots, вы должны иметь в виду, что поисковый робот Googlebot будет следовать только инструкциям в пользовательском агенте для Googlebot и не для общего с подстановочным знаком (*). В этом случае вам, возможно, придется повторить операторы запрета, включенные в общий раздел пользовательского агента, в раздел, относящийся к роботам Google.
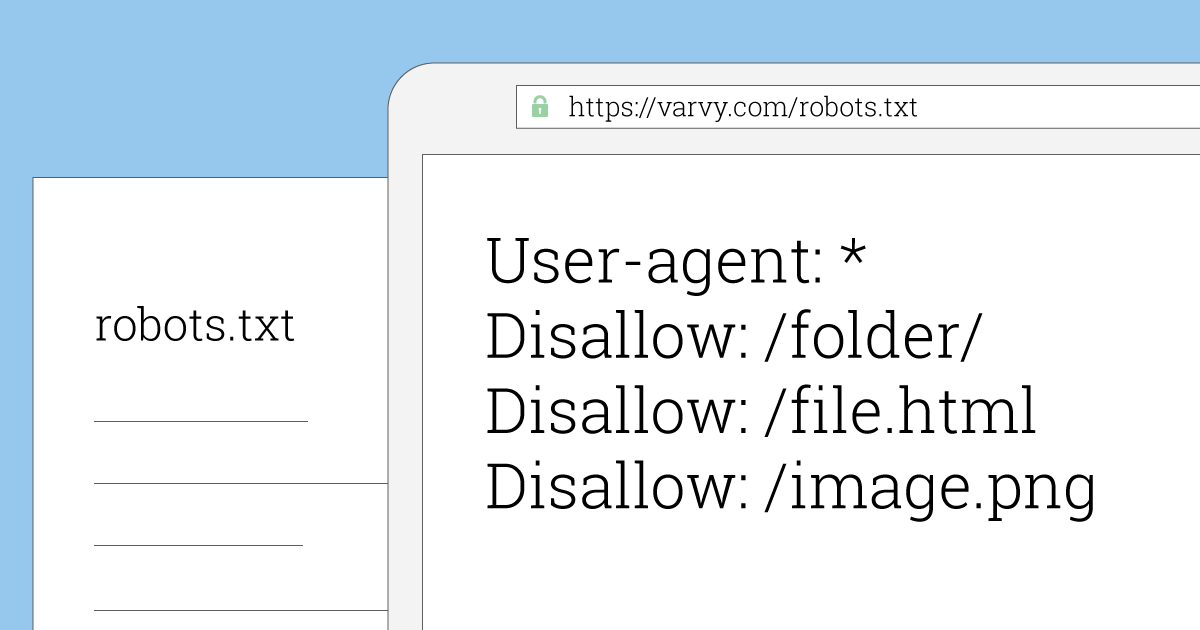 Взгляните на текст ниже:
Взгляните на текст ниже: - User-agent: * Disallow: /folder1/ Disallow: /folder2/ Disallow: /folder3/ User-agent: googlebot Задержка сканирования: 2 Disallow: /folder1/ Disallow: /folder2/ Запретить: /folder3/ Запретить: /folder4/ Запретить: /folder5/
Опубликовано
Категория
Подпишитесь на регулярные обновления
Спасибо! Мы отправили вам электронное письмо для подтверждения подписки.
К сожалению, что-то пошло не так. Пожалуйста, попробуйте еще раз
Обманчиво важный файл, необходимый всем веб-сайтам
Файл robots.txt помогает основным поисковым системам понять, какие места на вашем веб-сайте им разрешено посещать.
Но, несмотря на то, что основные поисковые системы поддерживают файл robots.txt, не все они одинаково придерживаются правил.
Ниже рассмотрим, что такое файл robots.txt и как его можно использовать.
Что такое файл robots.txt?
Каждый день ваш сайт посещают боты, также известные как роботы или пауки. Поисковые системы, такие как Google, Yahoo и Bing, отправляют этих ботов на ваш сайт, чтобы ваш контент можно было просканировать, проиндексировать и отобразить в результатах поиска.
Поисковые системы, такие как Google, Yahoo и Bing, отправляют этих ботов на ваш сайт, чтобы ваш контент можно было просканировать, проиндексировать и отобразить в результатах поиска.
Боты — это хорошо, но в некоторых случаях вы не хотите, чтобы бот бегал по вашему сайту, сканировал и индексировал все. Вот где на помощь приходит файл robots.txt.
Добавляя определенные директивы в файл robots.txt, вы указываете ботам сканировать только нужные вам страницы.
Однако важно понимать, что не каждый бот будет соблюдать правила, указанные в файле robots.txt. Google, например, не будет слушать никаких указаний, которые вы поместите в файл о частоте сканирования.
Вам нужен файл robots.txt?
Нет, для веб-сайта файл robots.txt не требуется.
Если бот заходит на ваш сайт, а у него его нет, он просто просканирует ваш сайт и проиндексирует страницы, как обычно.
Файл robot.txt нужен только в том случае, если вы хотите лучше контролировать то, что сканируется.
Некоторые преимущества его наличия включают:
- Помощь в управлении перегрузками сервера
- Предотвратить бесполезное сканирование ботами, которые посещают нежелательные для вас страницы
- Сохранять конфиденциальность определенных папок или субдоменов
Может ли файл robots.txt препятствовать индексации контента?
Нет, вы не можете запретить индексацию содержимого и его отображение в результатах поиска с помощью файла robots.txt.
Не все роботы будут следовать инструкциям одинаково, поэтому некоторые из них могут индексировать содержимое, которое вы запретили сканировать или индексировать.
Кроме того, если контент, который вы пытаетесь запретить показывать в результатах поиска, имеет внешние ссылки на него, это также приведет к его индексации поисковыми системами.
Единственный способ гарантировать, что ваш контент не проиндексирован, — это добавить на страницу метатег noindex. Эта строка кода выглядит так и будет отображаться в html вашей страницы.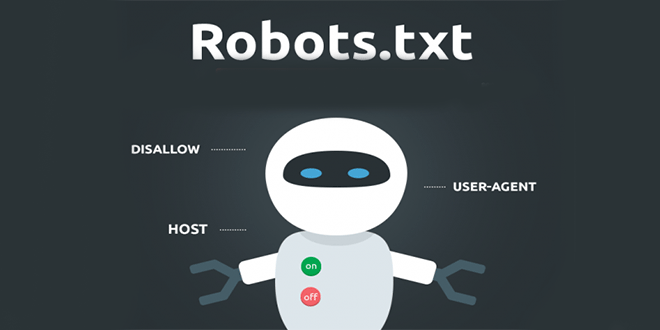
Важно отметить, что если вы хотите, чтобы поисковые системы не индексировали страницу, вам необходимо разрешить ее сканирование в файле robots.txt.
Где находится файл robots.txt?
Файл robots.txt всегда будет находиться в корневом домене веб-сайта. Например, наш собственный файл можно найти по адресу https://www.hubspot.com/robots.txt.
На большинстве веб-сайтов вы должны иметь доступ к реальному файлу, чтобы вы могли редактировать его через FTP или через файловый менеджер в CPanel вашего хоста.
В некоторых платформах CMS вы можете найти файл прямо в вашей административной области. HubSpot, например, упрощает настройку файла robots.txt из вашей учетной записи.
Если вы используете WordPress, доступ к файлу robots.txt можно получить в папке public_html вашего веб-сайта.
WordPress включает файл robots.txt по умолчанию с новой установкой, которая будет включать следующее:
User-agent: *
Disallow: /wp-admin/
Запретить: /wp-includes/
Вышеприведенное указывает всем ботам сканировать все части веб-сайта, кроме всего, что находится в каталогах /wp-admin/ или /wp-includes/.
Но вы можете создать более надежный файл. Давайте покажем вам, как, ниже.
Использование файла robots.txt
Может быть много причин, по которым вы хотите настроить файл robots.txt — от контроля бюджета сканирования до блокировки разделов веб-сайта от сканирования и индексирования. Давайте сейчас рассмотрим несколько причин использования файла robots.txt.
1. Блокировать все поисковые роботы
Блокировать доступ всех поисковых роботов к вашему сайту — это не то, что вы хотели бы делать на активном веб-сайте, но это отличный вариант для разрабатываемого веб-сайта. Если вы заблокируете сканеры, это поможет предотвратить показ ваших страниц в поисковых системах, что хорошо, если ваши страницы еще не готовы для просмотра.
2. Запретить сканирование определенных страниц
Один из наиболее распространенных и полезных способов использования файла robots.txt — ограничить доступ роботов поисковых систем к частям вашего веб-сайта. Это может помочь максимизировать краулинговый бюджет и предотвратить попадание нежелательных страниц в результаты поиска.
Важно отметить, что если вы сказали боту не сканировать страницу, это не означает, что она не будет проиндексирована. Если вы не хотите, чтобы страница отображалась в результатах поиска, вам нужно добавить на страницу метатег noindex.
Образец директив файла robots.txt
Файл robots.txt состоит из блоков строк директив. Каждая директива будет начинаться с пользовательского агента, а затем правила для этого пользовательского агента будут размещены под ней.
Когда конкретная поисковая система попадает на ваш веб-сайт, она ищет пользовательский агент, который относится к ним, и читает блок, который ссылается на них.
В файле можно использовать несколько директив. Давайте сломаем их, сейчас.
1. User-Agent
Команда user-agent позволяет направлять определенных ботов или пауков. Например, если вы хотите настроить таргетинг только на Bing или Google, вам следует использовать эту директиву.
Хотя существуют сотни пользовательских агентов, ниже приведены примеры некоторых из наиболее распространенных вариантов пользовательских агентов.
User-agent: Googlebot
User-agent: Googlebot-Image
User-agent: Googlebot-Mobile
User-agent: Googlebot-News
User-agent: Bingbot
Агент пользователя: Baiduspider
Агент пользователя: msnbot
Агент пользователя: slurp (Yahoo)
‘sвведите их правильно.
Пользовательский агент с подстановочным знаком
Пользовательский агент с подстановочным знаком отмечен звездочкой (*) и позволяет легко применить директиву ко всем существующим пользовательским агентам. Поэтому, если вы хотите, чтобы к каждому боту применялось определенное правило, вы можете использовать этот пользовательский агент.
Агент пользователя: *
Агенты пользователя будут следовать только тем правилам, которые наиболее точно к ним применимы.
2. Disallow
Директива disallow запрещает поисковым системам сканировать или получать доступ к определенным страницам или каталогам на веб-сайте.
Ниже приведены несколько примеров использования директивы disallow.
Блокировать доступ к определенной папкеВ этом примере мы говорим всем ботам не сканировать что-либо в каталоге /portfolio на нашем веб-сайте.
User-agent: *
Disallow: /portfolio
Если мы хотим, чтобы Bing не сканировал только этот каталог, мы должны добавить его следующим образом:
User-agent: Bingbot 0005
Запретить: /portfolio
Блокировать PDF или другие типы файлов Если вы не хотите, чтобы ваш PDF или другие типы файлов сканировались, вам поможет приведенная ниже директива. Мы сообщаем всем ботам, что не хотим, чтобы какие-либо PDF-файлы сканировались. $ в конце сообщает поисковой системе, что это конец URL-адреса.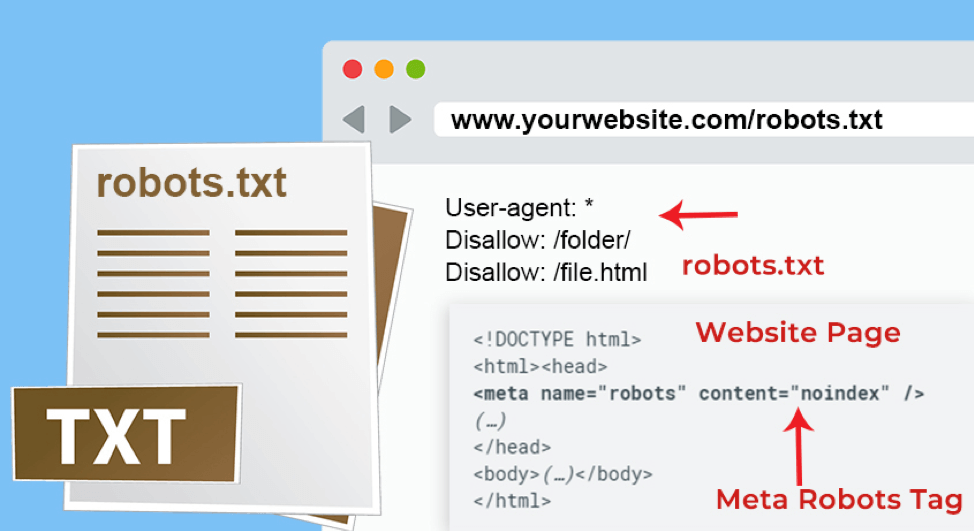
Итак, если у меня есть pdf-файл по адресу mywebsite.com/site/myimportantinfo.pdf , , поисковые системы не получат к нему доступ.
Пользовательский агент: *
DISLAING: * .PDF $
Для файлов PowerPoint вы можете использовать:
Пользовательский агент: *
Diswalk Лучшим вариантом может быть создание папки для вашего PDF или других файлов, а затем запретить сканерам сканировать ее и не индексировать весь каталог с помощью метатега.
Блокировать доступ ко всему веб-сайтуЭта директива особенно полезна, если у вас есть веб-сайт для разработки или тестовые папки. Эта директива говорит всем ботам вообще не сканировать ваш сайт. Важно не забыть удалить это, когда вы запускаете свой сайт, иначе у вас возникнут проблемы с индексацией.
User-agent: *
Знак * (звездочка), который вы видите выше, — это то, что мы называем «подстановочным знаком». Когда мы используем звездочку, мы подразумеваем, что приведенные ниже правила должны применяться ко всем пользовательским агентам.
Когда мы используем звездочку, мы подразумеваем, что приведенные ниже правила должны применяться ко всем пользовательским агентам.
3. Разрешить
Директива allow может помочь вам указать определенные страницы или каталоги, которые вы делаете вы хотите, чтобы боты имели доступ и сканировали. Это может быть правилом переопределения параметра запрета, показанного выше.
В приведенном ниже примере мы сообщаем роботу Googlebot, что не хотим, чтобы сканировался каталог портфолио, но мы хотим, чтобы был получен доступ и сканировался один конкретный элемент портфолио:
Агент пользователя: Googlebot
Запретить: /portfolio
Разрешить: /portfolio/crawlableportfolio
поисковые роботы для сканирования вашей карты сайта.
Если вы отправляете свои карты сайта непосредственно в инструменты каждой поисковой системы для веб-мастеров, то нет необходимости добавлять их в файл robots. txt.
txt.
Карта сайта: https://yourwebsite.com/sitemap.xml
5. Задержка сканирования
Задержка сканирования может заставить бота замедлить сканирование вашего веб-сайта, чтобы ваш сервер не перегружался.
Это директива, с которой вы должны быть осторожны. На очень большом веб-сайте это может значительно минимизировать количество URL-адресов, сканируемых каждый день, что было бы контрпродуктивно. Однако это может быть полезно на небольших веб-сайтах, где боты посещают слишком много.
Примечание. Задержка сканирования равна не поддерживается Google или Baidu . Если вы хотите попросить их сканеры замедлить сканирование вашего веб-сайта, вам нужно будет сделать это с помощью их инструментов .
Что такое регулярные выражения и подстановочные знаки?
Сопоставление с образцом — это более продвинутый способ управления тем, как бот сканирует ваш веб-сайт с использованием символов.
Есть два общих выражения, которые используются как Bing, так и Google. Эти директивы могут быть особенно полезны на веб-сайтах электронной коммерции.
Звездочка: * рассматривается как подстановочный знак и может представлять любую последовательность символов
Знак доллара: $ используется для обозначения конца URL-адреса
Хороший пример использования подстановочного знака * приведен в сценарии где вы хотите запретить поисковым системам сканировать страницы, на которых может быть вопросительный знак. Приведенный ниже код говорит всем ботам игнорировать сканирование любых URL-адресов, в которых есть вопросительный знак.
Агент пользователя: *
Запретить: /*?
Как создать или отредактировать файл robots.txt
Если на вашем сервере нет файла robots.txt, вы можете легко добавить его, выполнив следующие действия.
- Откройте предпочитаемый вами текстовый редактор, чтобы создать новый документ.

- Добавьте директивы, которые вы хотите включить в документ.
- Сохраните файл с именем «robots.txt»
- Проверьте свой файл, как показано в следующем разделе
- Загрузите файл .txt на свой сервер с помощью FTP или в CPanel. Способ загрузки зависит от типа вашего веб-сайта.
В WordPress вы можете использовать такие плагины, как Yoast, All In One SEO, Rank Math, для создания и редактирования файла.
Вы также можете использовать инструмент-генератор robots.txt , который поможет вам подготовить файл, который поможет свести к минимуму количество ошибок.
Как протестировать файл robots.txt
Прежде чем вы начнете использовать созданный вами код файла robots.txt, вам нужно будет запустить его через тестер, чтобы убедиться, что он действителен. Это поможет предотвратить проблемы с неправильными директивами, которые могли быть добавлены.

Об авторе