Robots txt https: Использование файла robots.txt — Вебмастер. Справка
Использование файла robots.txt — Вебмастер. Справка
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
При очередном обходе сайта робот Яндекса загружает файл robots.txt. Если при последнем обращении к файлу, страница или раздел сайта запрещены, робот не проиндексирует их.
- Требования к файлу robots.txt
- Рекомендации по наполнению файла
- Использование кириллицы
- Как создать robots.txt
- Вопросы и ответы
Роботы Яндекса корректно обрабатывают robots.txt, если:
Размер файла не превышает 500 КБ.
Это TXT-файл с названием robots — robots.txt.
Файл размещен в корневом каталоге сайта.
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK.


Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots.txt правила. |
| Disallow | Запрещает индексирование разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay | Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |
* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы Disallow: /bin/ # запрещает ссылки из "Корзины с товарами".Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска Disallow: /admin/ # запрещает ссылки из панели администратора Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта Clean-param: ref /some_dir/get_book.pl
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно: User-agent: Yandex Disallow: /корзина Sitemap: сайт.рф/sitemap.xml #Верно: User-agent: Yandex Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
В текстовом редакторе создайте файл с именем robots.
 txt и укажите в нем нужные вам директивы.
txt и укажите в нем нужные вам директивы.Проверьте файл в Вебмастере.
Положите файл в корневую директорию вашего сайта.
Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
Сайт или отдельные страницы запрещены в файле robots.txt, но продолжают отображаться в поиске
Как правило, после установки запрета на индексирование каким-либо способом исключение страниц из поиска происходит в течение двух недель. Вы можете ускорить этот процесс.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
Что такое robots.txt и зачем вообще нужен индексный файл
Файл robots.txt вместе с xml-картой несёт, пожалуй, самую важную информацию о ресурсе: он показывает роботам поисковых систем, как именно «читать» сайт, какие страницы важны, а какие следует пропустить. Еще robots.txt — первая страница, на которую стоит смотреть, если на сайт внезапно упал трафик.
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать.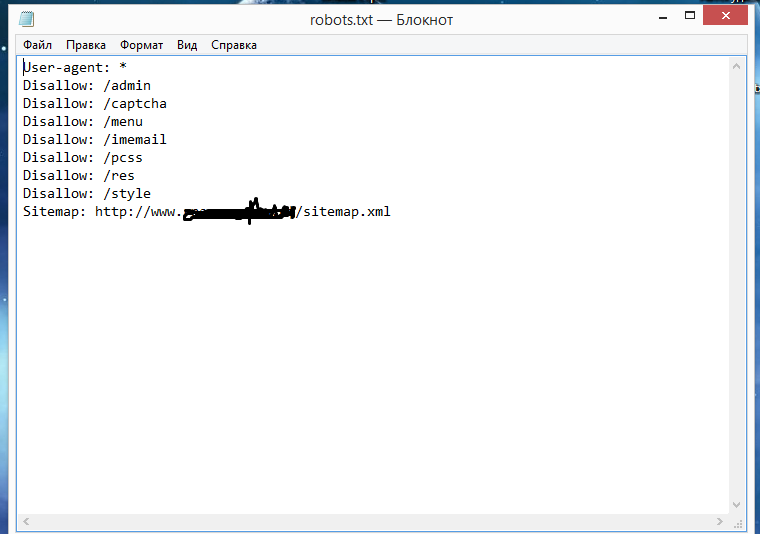 Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt.
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822.
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.
При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается. Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Зачем нужен файл robots.
 txt
txtНапример, иногда роботам не стоит посещать:
- страницы с личной информацией пользователей на сайте;
- страницы с разнообразными формами отправки информации;
- сайты-зеркала;
- страницы с результатами поиска.
Важно: даже если страница находится в файле robots.txt, существует вероятность, что она появится в выдаче, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
Так роботы поисковых систем видят сайт с файлом robots.txt и без него:
Без robots.txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
Так робот поисковых систем видит файл robots.txt:
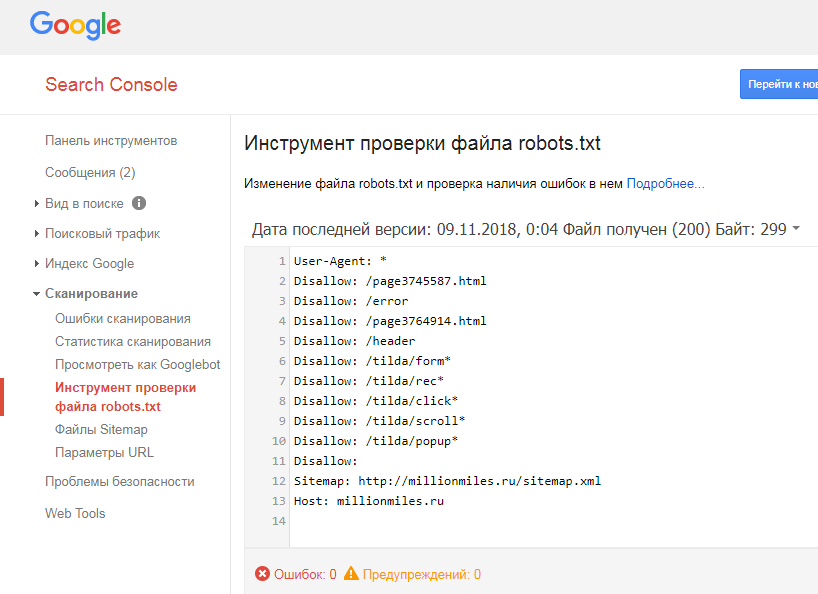
Google обнаружил файл robots.txt на сайте и нашел правила, по которым следует сканировать страницы сайта
Как создать файл robots.txt
С помощью блокнота, Notepad, Sublime, либо любого другого текстового редактора.
В содержании файла должны быть прописаны инструкция User-agent и правило Disallow, к тому же есть еще несколько второстепенных правил.
User-agent — визитка для роботов
User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в файле robots.txt. На данный момент известно 302 поисковых робота. Чтобы не прописывать всех по отдельности, стоит использовать запись:
Она говорит о том, что мы указываем правила в robots.txt для всех поисковых роботов.
Для Google главным роботом является Googlebot. Если мы хотим учесть только его, запись в файле будет такой:
В этом случае все остальные роботы будут сканировать контент на основании своих директив по обработке пустого файла robots.txt.
Для Yandex главным роботом является… Yandex:
Другие специальные роботы:
- Mediapartners-Google — для сервиса AdSense;
- AdsBot-Google — для проверки качества целевой страницы;
- YandexImages — индексатор Яндекс.Картинок;
- Googlebot-Image — для картинок;
- YandexMetrika — робот Яндекс.Метрики;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YaDirectFetcher — робот Яндекс.
 Директа;
Директа; - Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
- YandexMarket— робот Яндекс.Маркета;
- YandexNews — робот Яндекс.Новостей;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы;
- YandexPagechecker — валидатор микроразметки;
- YandexCalendar — робот Яндекс.Календаря.
Disallow — расставляем «кирпичи»
Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
Такая запись открывает для сканирования весь сайт:
А эта запись говорит о том, что абсолютно весь контент на сайте запрещен для сканирования:
Ее стоит использовать, если сайт находится в процессе доработок, и вы не хотите, чтобы он в нынешнем состоянии засветился в выдаче.
Важно снять это правило, как только сайт будет готов к тому, чтобы его увидели пользователи. К сожалению, об этом забывают многие вебмастера.
Пример. Как прописать правило Disallow, чтобы дать инструкции роботам не просматривать содержимое папки /papka/:
Чтобы роботы не сканировали конкретный URL:
Чтобы роботы не сканировали конкретный файл:
Чтобы роботы не сканировали все файлы определенного разрешения на сайте:
Данная строка запрещает индексировать все файлы с расширением .gif
Allow — направляем роботов
Allow разрешает сканировать какой-либо файл/директиву/страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы с /catalog, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:
Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для страницы подходит несколько правил, робот выбирает последнее правило в отсортированном списке.
Host — выбираем зеркало сайта
Host — одно из обязательных для robots.txt правил, оно сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
Зеркало сайта — точная или почти точная копия сайта, доступная по разным адресам.
Робот не будет путаться при нахождении зеркал сайта и поймет, что главное зеркало указано в файле robots.txt. Адрес сайта указывается без приставки «https://», но если сайт работает на HTTPS, приставку «https://» указать нужно.
Как необходимо прописать это правило:
Пример файла robots.txt, если сайт работает на протоколе HTTPS:
Sitemap — медицинская карта сайта
Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу https://site.ua/sitemap.xml. При каждом обходе робот будет смотреть, какие изменения вносились в этот файл, и быстро освежать информацию о сайте в базах данных поисковой системы.
Инструкция должна быть грамотно вписана в файл:
Crawl-delay — секундомер для слабых серверов
Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта. Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Clean-param — охотник за дублирующимся контентом
Clean-param помогает бороться с get-параметрами для избежания дублирования контента, который может быть доступен по разным динамическим адресам (со знаками вопроса). Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Допустим, страница доступна по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае файл robots.txt будет выглядеть так:
Здесь ref указывает, откуда идет ссылка, поэтому она записывается в самом начале, а уже потом указывается остальная часть адреса.
Но прежде чем перейти к эталонному файлу, необходимо еще узнать о некоторых знаках, которые применяются при написании файла robots. txt.
txt.
Символы в robots.txt
Основные символы файла — «/, *, $, #».
С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами. Например, если стоит один слеш в правиле Disallow, мы запрещаем сканировать весь сайт. С помощью двух знаков слэш можно запретить сканирование какой-либо отдельной директории, например: /catalog/.
Такая запись говорит, что мы запрещаем сканировать все содержимое папки catalog, но если мы напишем /catalog, запретим все ссылки на сайте, которые будут начинаться на /catalog.
Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» ограничивает действия знака звездочки. Если необходимо запретить все содержимое папки catalog, но при этом нельзя запретить урлы, которые содержат /catalog, запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые вебмастер оставляет для себя или других вебмастеров. Робот не будет их учитывать при сканировании сайта.
Робот не будет их учитывать при сканировании сайта.
Например:
Как выглядит идеальный robots.txt
Такой файл robots.txt можно разместить почти на любом сайте:
Файл открывает содержимое сайта для индексирования, прописан хост и указана карта сайта, которая позволит поисковым системам всегда видеть адреса, которые должны быть проиндексированы. Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Но не спешите копировать содержимое файл к себе — для каждого сайта должны быть прописаны уникальные правила, которые зависит от типа сайта и CMS. поэтому тут стоит вспомнить все правила при заполнении файла robots.txt.
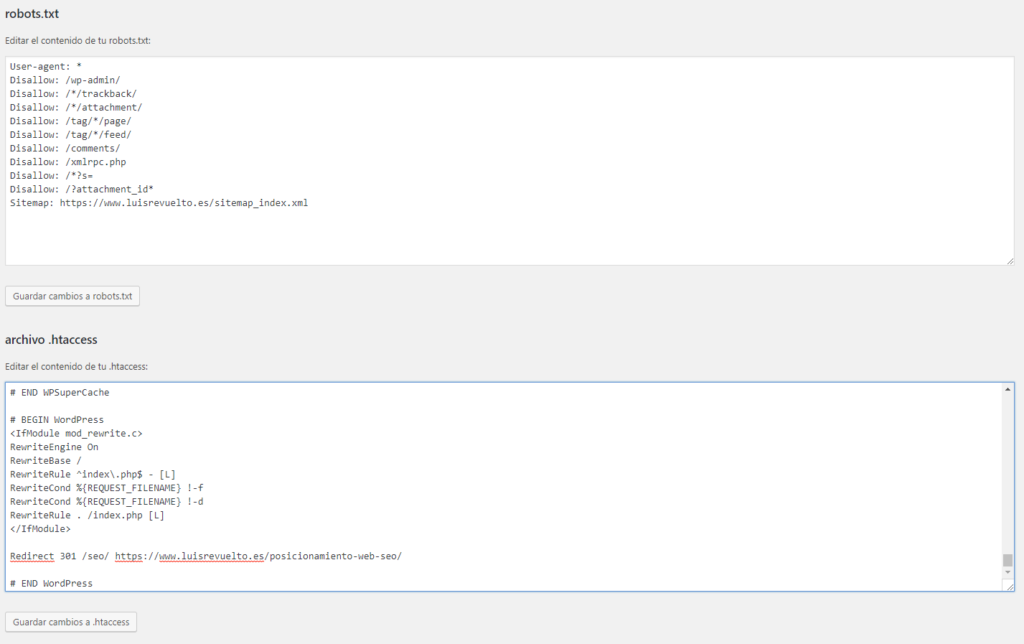
Как проверить файл robots.txt
Если хотите узнать, правильно ли заполнили файл robots.txt, проверьте его в инструментах вебмастеров Google и Яндекс. Просто введите исходный код файла robots.txt в форму по ссылке и укажите проверяемый сайт.
Как не нужно заполнять файл robots.txt
Часто при заполнении индексного файла допускаются досадные ошибки, причем они связаны с обычной невнимательностью или спешкой. Чуть ниже — чарт ошибок, которые я встречала на практике.
Чуть ниже — чарт ошибок, которые я встречала на практике.
1. Перепутанные инструкции:
Правильный вариант:
2. Запись нескольких папок/директорий в одной инструкции Disallow:
Такая запись может запутать поисковых роботов, они могут не понять, что именно им не следует индексировать: то ли первую папку, то ли последнюю, — поэтому нужно писать каждое правило отдельно.
3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то иначе.
4. Нельзя оставлять пустым правило User-agent — нужно сказать, какой робот должен учитывать прописанные в файле правила.
5. Лишние знаки в файле (слэши, звездочки).
6. Добавление в файл страниц, которых не должно быть в индексе.
Нестандартное применение robots.txt
Кроме прямых функций индексный файл может стать площадкой для творчества и способом найти новых сотрудников.
Вот сайт, в котором robots.txt сам является маленьким сайтом с рабочими элементами и даже рекламным блоком.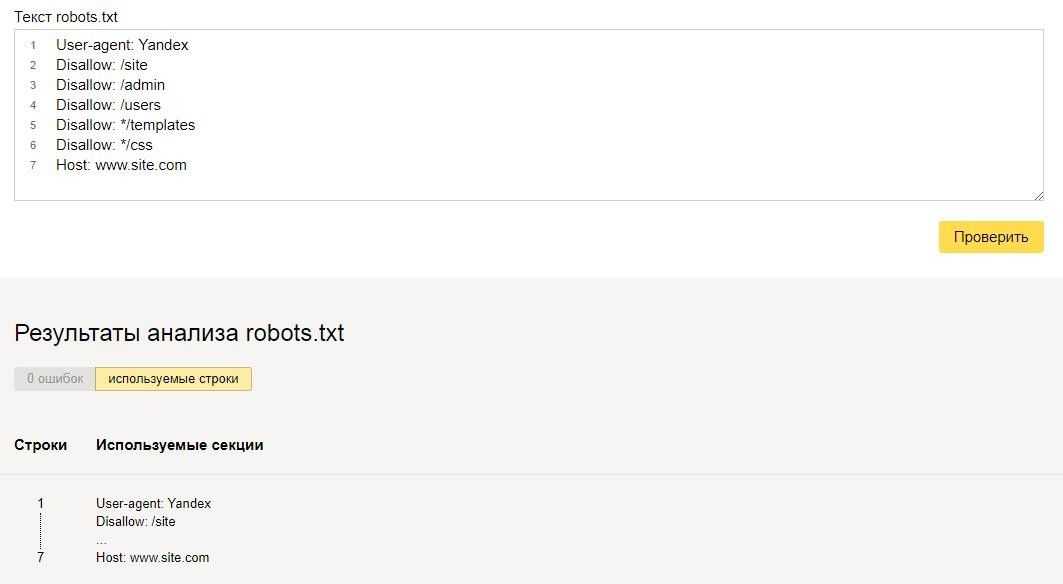
Хотите что-то поинтереснее? Ловите ссылку на robots.txt со встроенной игрой и музыкальным сопровождением.
Многие бренды используют robots.txt, чтобы еще раз заявить о себе:
В качестве площадки для поиска специалистов файл используют в основном SEO-агентства. А кто же еще может узнать о его существовании? 🙂
А у Google есть специальный файл humans.txt, чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.
Когда у вебмастера появляется достаточно свободного времени, он часто тратит его на модернизацию robots.txt:
Хотите, чтобы все страницы вашего сайта заходили в индекс быстро? Мы выберем для вас оптимальную стратегию SEO-продвижения:
Хочу быстро найти клиентов онлайн
Выводы
С помощью Robots.txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.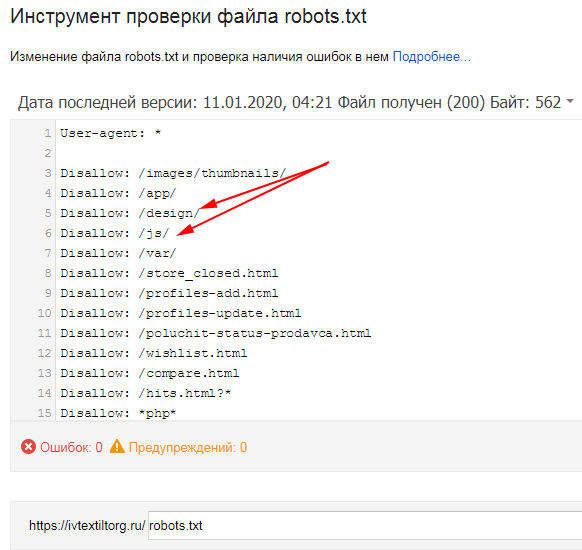
Правила, они же директивы, они же инструкции файла robots.txt:
- User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в robots.txt.
- Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
- Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу https://site.ua/sitemap.xml.
- Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта.
- Host сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
- Allow разрешает сканировать какой-либо файл/директиву/страницу.
- Clean-param помогает бороться с get-параметрами для избежания дублирования контента.
Знаки при составлении robots.txt:
- Знак доллара «$» ограничивает действия знака звездочки.
- С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами.
- Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
- Решетка «#» используется, чтобы обозначить комментарии, которые пишет вебмастер для себя или других вебмастеров.
Используйте индексный файл с умом — и сайт всегда будет в выдаче.
Страницы веб-роботов
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для предоставления инструкций по свой сайт веб-роботам; это называется Исключение роботов Протокол .
Это работает следующим образом: робот хочет просмотреть URL-адрес веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это сделать, он сначала проверяет наличие http://www.example.com/robots.txt и находит:
Агент пользователя: * Запретить: /
«User-agent: *» означает, что этот раздел относится ко всем роботам. «Запретить: /» сообщает роботу, что он не должен посещать страницы на сайте.
При использовании файла /robots. txt необходимо учитывать два важных момента:
txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш файл /robots.txt. Особенно вредоносные роботы, которые сканируют web на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами не обратит внимания.
- файл /robots.txt является общедоступным. Любой может видеть, какие разделы вашего сервера, который вы не хотите использовать роботами.
Так что не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
- Могу ли я заблокировать только плохих роботов?
- Почему этот робот проигнорировал мой /robots.txt?
- Каковы последствия файла /robots.txt для безопасности?
Детали
/robots.txt является стандартом де-факто и никому не принадлежит. орган стандартов. Есть два исторических описания:
- оригинал 1994 г. Стандарт для роботов Документ об исключении.
- Спецификация Internet Draft 1997 г.
 Метод для Интернета
Управление роботами
Метод для Интернета
Управление роботами
Кроме того, есть внешние ресурсы:
- HTML 4.01 Спецификация, Приложение B.4.1
- Википедия — Стандарт исключения роботов
Стандарт /robots.txt активно не разрабатывается. См. Что насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать /robots.txt на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, см. также FAQ.
Как создать файл /robots.txt
Куда поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет файл «/robots.txt» для URL, он удаляет компонент пути из URL (все, начиная с первой косой черты), и помещает «/robots.txt» на свое место.
Например, для «http://www.example.com/shop/index.html будет
удалите «/shop/index.html» и замените его на
«/robots.txt», и в итоге получится
«http://www. example.com/robots.txt».
example.com/robots.txt».
Итак, как владелец веб-сайта, вы должны поместить его в нужное место на своем веб-сайте. веб-сервер, чтобы этот результирующий URL-адрес работал. Обычно это одно и то же место, где вы размещаете приветствие «index.html» вашего веб-сайта страница. Где именно это находится и как туда поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: «robots.txt», а не «Robots.TXT.
Смотрите также:
- Какую программу следует использовать для создания файла /robots.txt?
- Как использовать /robots.txt на виртуальном хосте?
- Как использовать /robots.txt на общем хосте?
Что положить
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись, имеющую вид:
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /~joe/
В этом примере исключены три каталога.
Обратите внимание, что вам нужна отдельная строка «Запретить» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: /cgi-bin/ /tmp/» на одна линия. Кроме того, в записи может не быть пустых строк, так как они используются для разделения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается либо в User-agent, либо в Disallow линии. ‘*’ в поле User-agent — это специальное значение, означающее «любой робот». В частности, у вас не может быть таких строк, как «User-agent: *bot*», «Запретить: /tmp/*» или «Запретить: *.gif».
То, что вы хотите исключить, зависит от вашего сервера. Все, что прямо не запрещено, считается справедливым игра, чтобы получить. Вот несколько примеров:
Исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Чтобы разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots. txt», или вообще не используйте его)
txt», или вообще не используйте его)
Исключить всех роботов из части сервера
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /мусор/
Для исключения одного робота
Агент пользователя: BadBot Запретить: /
Для одного робота
Агент пользователя: Google Запретить: Пользовательский агент: * Запретить: /
Чтобы исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». простой способ — поместить все файлы, которые нужно запретить, в отдельный директории, произнесите «stuff» и оставьте один файл на уровне выше этот каталог:
Пользовательский агент: * Запретить: /~joe/stuff/
В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html
Полное руководство по файлу robots.txt • Yoast
Файл robots.txt — это один из основных способов указать поисковой системе, где на вашем веб-сайте можно, а где нельзя. Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.txt на вашем веб-сайте.
Внимание!
Любые ошибки, допущенные вами в файле robots.txt, могут серьезно повредить вашему сайту, поэтому убедитесь, что вы прочитали и поняли всю эту статью, прежде чем погрузиться в нее.
Содержание
- Что такое файл robots.txt?
- Что делает файл robots.txt?
- Куда мне поместить файл robots.txt?
- Плюсы и минусы использования robots.txt
- Синтаксис файла robots.txt
- Не блокировать файлы CSS и JS в robots.txt
- Проверка и исправление в Google Search Console
- Подтвердите файл robots.
 txt
txt - См. код
Что такое файл robots.txt?
Директивы сканирования
Файл robots.txt является одной из нескольких директив сканирования. У нас есть руководства по всем из них, и вы найдете их здесь.
Файл robots.txt — это текстовый файл, читаемый поисковыми системами (и другими системами). Файл robots.txt, также называемый протоколом исключения роботов, является результатом консенсуса среди первых разработчиков поисковых систем. Это не официальный стандарт, установленный какой-либо организацией по стандартизации, хотя его придерживаются все основные поисковые системы.
Базовый файл robots.txt может выглядеть примерно так:
Агент пользователя: * Запретить: Карта сайта: https://www.example.com/sitemap_index.xml
Что делает файл robots.txt?
Кэширование
Поисковые системы обычно кэшируют содержимое файла robots.txt, поэтому им не нужно его постоянно загружать, но обычно они обновляют его несколько раз в день. Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Поисковые системы обнаруживают и индексируют Интернет, просматривая страницы. По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).
Подробнее: Бот-трафик: что это такое и почему вы должны о нем заботиться »
Куда мне поместить файл robots.txt?
Файл robots.txt всегда должен находиться в корне вашего домена. Итак, если ваш домен www.example.com , сканер должен найти его по адресу https://www.example.com/robots.txt .
Также важно, чтобы ваш файл robots.txt назывался robots.txt. Имя чувствительно к регистру, поэтому сделайте это правильно, иначе оно не будет работать.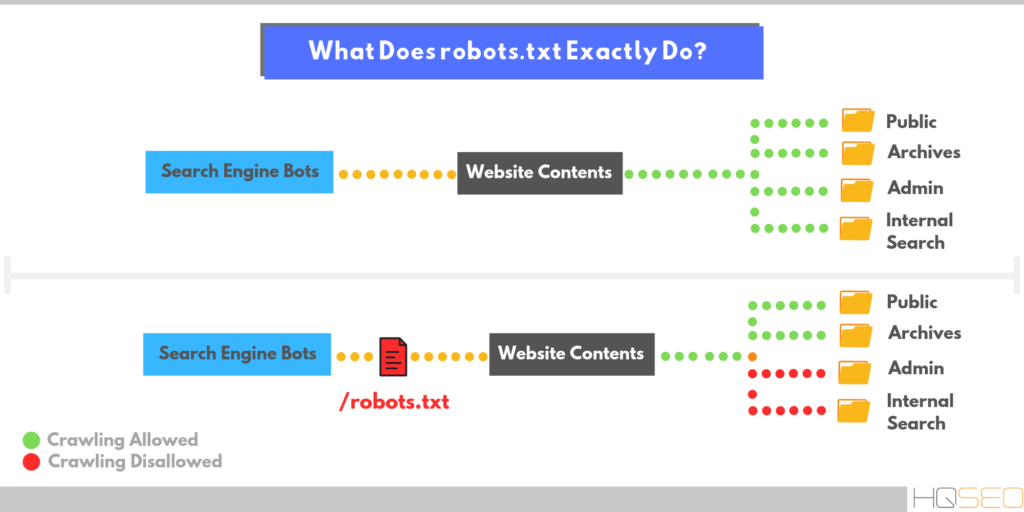
«За» и «против» использования robots.txt
«За»: управление бюджетом сканирования ресурс/время, которое он потратит, в зависимости от авторитета/размера/репутации сайта и того, насколько эффективно отвечает сервер). SEO-специалисты называют это
краулинговый бюджет .Если вы считаете, что у вашего веб-сайта проблемы с краулинговым бюджетом, то запрет поисковым системам «тратить» энергию на несущественные части вашего сайта может означать, что вместо этого они сосредоточатся на тех разделах, которые действительно важны. Используйте настройки очистки сканирования в Yoast SEO Premium, чтобы помочь Google сканировать то, что важно.
Иногда может быть полезно запретить поисковым системам сканировать проблемные разделы вашего сайта, особенно на сайтах, где необходимо выполнить большую SEO-очистку. После того, как вы прибрали вещи, вы можете впустить их обратно.
Примечание о блокировке параметров запроса
Одной из ситуаций, когда краулинговый бюджет имеет решающее значение, является ситуация, когда ваш сайт использует множество параметров строки запроса для фильтрации или сортировки списков. Допустим, у вас есть десять различных параметров запроса, каждый из которых имеет разные значения, которые можно использовать в любой комбинации (например, футболки разных цветов и размеров). Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Допустим, у вас есть десять различных параметров запроса, каждый из которых имеет разные значения, которые можно использовать в любой комбинации (например, футболки разных цветов и размеров). Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Против: не удалять страницу из результатов поиска
Несмотря на то, что вы можете использовать файл robots.txt, чтобы сообщить сканеру, куда он не может попасть на вашем сайте, вы не можете использовать его, чтобы сказать поиску движок, URL-адреса которого не показывать в результатах поиска – другими словами, его блокировка не остановит его индексацию. Если поисковая система найдет достаточное количество ссылок на этот URL, она включит его; он просто не будет знать, что находится на этой странице. Таким образом, ваш результат будет выглядеть так:
Таким образом, ваш результат будет выглядеть так:
Если вы хотите надежно заблокировать страницу от появления в результатах поиска, вам нужно использовать мета-роботы тег noindex . Это означает, что для того, чтобы найти тег noindex , поисковая система должна иметь доступ к этой странице, поэтому не блокируйте ее с помощью robots.txt.
Директивы Noindex
Раньше можно было добавить директивы noindex в файл robots.txt, чтобы удалить URL-адреса из результатов поиска Google и избежать появления этих «фрагментов». Это больше не поддерживается (и технически никогда не было).
Con: не распространяется значение ссылки
Если поисковая система не может просканировать страницу, она не может распределить значение ссылки по ссылкам на этой странице. Это тупик, когда вы заблокировали страницу в robots.txt. Любое значение ссылки, которое могло пройти на эту страницу (и через нее), теряется.
Синтаксис robots.txt
WordPress robots.
 txt
txtУ нас есть целая статья о том, как лучше настроить файл robots.txt для WordPress. Не забывайте, что вы можете редактировать файл robots.txt вашего сайта в разделе Инструменты Yoast SEO → Редактор файлов.
Файл robots.txt состоит из одного или нескольких блоков директив, каждый из которых начинается со строки пользовательского агента. «User-agent» — это имя конкретного паука, к которому он обращается. У вас может быть либо один блок для всех поисковых систем, используя подстановочный знак для пользовательского агента, либо отдельные блоки для определенных поисковых систем. Поисковый паук всегда выберет блок, который лучше всего соответствует его названию.
Эти блоки выглядят так (не пугайтесь, мы объясним ниже):
User-agent: *
Disallow: /User-agent: Googlebot
Disallow:User-agent: bingbot
Disallow: /not-for-bing/
Такие директивы, как Allow и Disallow , не должны учитывать регистр, поэтому вам решать писать их строчными буквами или заглавными буквами.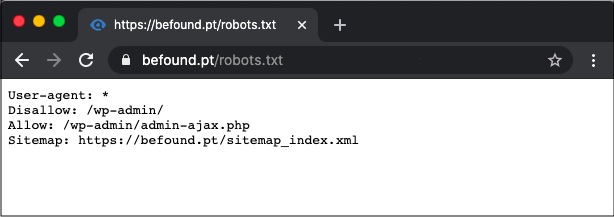 Значения – с учетом регистра, поэтому
Значения – с учетом регистра, поэтому /photo/ не совпадает с /Photo/ . Нам нравится писать директивы с большой буквы, потому что это облегчает чтение файла (для людей).
Директива агента пользователя
Первый бит каждого блока директив — это агент пользователя, который идентифицирует конкретного паука. Поле user-agent соответствует пользовательскому агенту этого конкретного паука (обычно более длинному), поэтому, например, наиболее распространенный паук от Google имеет следующий пользовательский агент:
Mozilla/5.0 (совместимый; Googlebot/2.1; +http ://www.google.com/bot.html)
Если вы хотите указать этому сканеру, что делать, относительно простой User-agent: Googlebot 9Строка 0196 поможет.
Большинство поисковых систем имеют несколько пауков. Они будут использовать определенный паук для своего обычного индекса, рекламных программ, изображений, видео и т. д.
Поисковые системы всегда выбирают наиболее конкретный блок директив, который они могут найти. Допустим, у вас есть три набора директив: один для
Допустим, у вас есть три набора директив: один для * , один для Googlebot и один для Googlebot-News . Если приходит бот, чей пользовательский агент Googlebot-Video , он будет следовать Ограничения Googlebot . Бот с пользовательским агентом Googlebot-News будет использовать более конкретные директивы Googlebot-News .
Наиболее распространенные пользовательские агенты для поисковых роботов
Вот список пользовательских агентов, которые вы можете использовать в файле robots.txt для соответствия наиболее часто используемым поисковым системам:
| Поисковая система | Поле | Агент пользователя |
|---|---|---|
| Baidu | Общие | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Видео | baiduspider-video |
| Bing | Общий | |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| Общие | Googlebot | |
| Изображения | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | Общие | SLURP |
| YANDEX | Общий | Yandex |
Директива
9099999099900
9099900
.
 У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук. Пустая строка
У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук. Пустая строка Disallow означает, что вы ничего не запрещаете, чтобы паук мог получить доступ ко всем разделам вашего сайта.В приведенном ниже примере блокируются все поисковые системы, которые «прослушивают» файл robots.txt, и не могут сканировать ваш сайт.
User-agent: *
Disallow: /
В приведенном ниже примере все поисковые системы могут сканировать весь ваш сайт, пропуская один символ.
User-agent: *
Disallow:
В приведенном ниже примере Google не сможет сканировать каталог Photo на вашем сайте и все, что в нем содержится.
Агент пользователя: googlebot
Запретить: /Фото
Это означает, что все подкаталоги каталога /Photo также не будут сканироваться. Это , а не , заблокирует Google от сканирования каталога /photo , так как эти строки чувствительны к регистру.
Это и заблокирует доступ Google к URL-адресам, содержащим /Photo , например /Photography/ .
Как использовать подстановочные знаки/регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или подстановочные знаки; однако все основные поисковые системы это понимают. Это означает, что вы можете использовать такие строки для блокировки групп файлов:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
В приведенном выше примере * расширяется до любого имени файла, которому оно соответствует. Обратите внимание, что остальная часть строки по-прежнему чувствительна к регистру, поэтому вторая строка выше не блокирует сканирование файла с именем /copyrighted-images/example.JPG .
Некоторые поисковые системы, такие как Google, позволяют использовать более сложные регулярные выражения, но имейте в виду, что другие поисковые системы могут не понимать эту логику. Самая полезная функция, которую это добавляет, - это
Самая полезная функция, которую это добавляет, - это $ , что указывает на конец URL-адреса. В следующем примере вы можете увидеть, что это делает:
Disallow: /*.php$
Это означает, что /index.php нельзя индексировать, но /index.php?p=1 можно. быть. Конечно, это полезно только в очень специфических обстоятельствах и довольно опасно: легко разблокировать то, чего вы не хотели.
Нестандартные директивы сканирования robots.txt
А также Disallow и Директивы User-agent , есть пара других директив сканирования, которые вы можете использовать. Все сканеры поисковых систем не поддерживают эти директивы, поэтому убедитесь, что вы знаете их ограничения.
Директива allow
Хотя в исходной «спецификации» ее не было, в самом начале речь шла о директиве allow. Похоже, что большинство поисковых систем понимают его, и он позволяет использовать простые и очень читаемые директивы, такие как:
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Единственным другим способом достижения того же результата без директивы allow было бы конкретно запретить каждый отдельный файл в папке wp-admin .
Директива Crawl-delay
Crawl-delay является неофициальным дополнением к стандарту, и не многие поисковые системы его придерживаются. По крайней мере, Google и Яндекс им не пользуются, а с Bing непонятно. Теоретически, поскольку поисковые роботы могут быть довольно прожорливыми, вы можете попробовать .0195 crawl-delay направление, чтобы замедлить их.
Строка, подобная приведенной ниже, указывает этим поисковым системам изменить частоту запросов страниц на вашем сайте.
crawl-delay: 10
Будьте осторожны при использовании директивы crawl-delay . Установив задержку сканирования в десять секунд, вы разрешаете этим поисковым системам доступ только к 8640 страницам в день. Это может показаться достаточным для небольшого сайта, но не очень для больших сайтов.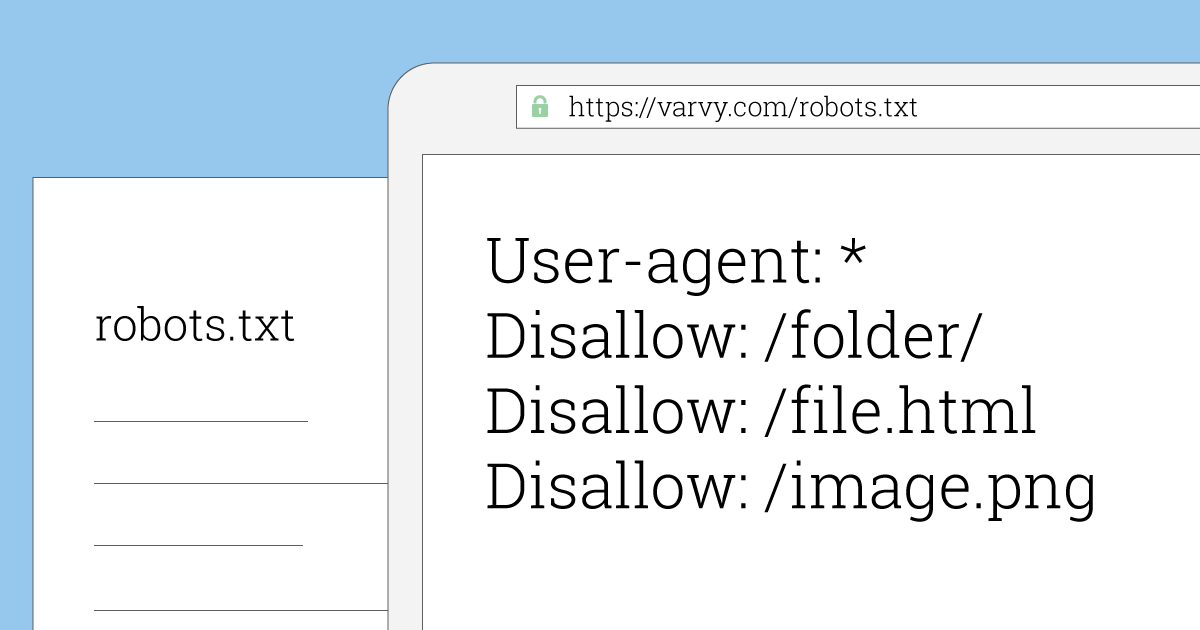 С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
Директива карты сайта для XML-карт сайта
С помощью директивы карты сайта вы можете указать поисковым системам — Bing, Yandex и Google — где найти вашу карту сайта XML. Конечно, вы можете отправить свои XML-карты сайта в каждую поисковую систему, используя их инструменты для веб-мастеров. Мы настоятельно рекомендуем вам это сделать, потому что инструменты для веб-мастеров предоставят вам массу информации о вашем сайте. Если вы не хотите этого делать, добавление строки карты сайта в файл robots.txt является хорошей быстрой альтернативой. Yoast SEO автоматически добавит ссылку на вашу карту сайта, если вы позволите ему сгенерировать файл robots.txt. В существующий файл robots.txt вы можете добавить правило вручную через редактор файлов в разделе «Инструменты».
Карта сайта: https://www.example.com/my-sitemap.xml
Не блокировать файлы CSS и JS в robots.txt
С 2015 года Google Search Console предупреждает владельцев сайтов не блокировать CSS и JS файлы. Мы давно говорим вам одно и то же: не блокируйте файлы CSS и JS в файле robots.txt. Объясним, почему не следует блокировать эти файлы от робота Googlebot.
Блокируя файлы CSS и JavaScript, вы запрещаете Google проверять правильность работы вашего веб-сайта. Если вы заблокируете файлы CSS и JavaScript в своем robots.txt , Google не может отобразить ваш веб-сайт должным образом. Теперь Google не может понять ваш сайт, что может привести к снижению рейтинга. Более того, даже такие инструменты, как Ahrefs, отображают веб-страницы и выполняют JavaScript. Поэтому не блокируйте JavaScript, если хотите, чтобы ваши любимые SEO-инструменты работали.
Это идеально согласуется с общим предположением, что Google стал более «человечным». Google хочет видеть ваш сайт таким, каким его видит посетитель, поэтому он может отличить основные элементы от дополнительных. Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Проверка и исправление в Google Search Console
Google поможет вам найти и исправить проблемы с файлом robots.txt, например, в разделе «Индексирование страниц» в Google Search Console. Просто выберите параметр «Заблокировано robots.txt»:
Проверьте консоль поиска, чтобы узнать, какие URL-адреса заблокированы вашим файлом robots.txt Чтобы разблокировать заблокированные ресурсы, нужно изменить файл robots.txt . Вам нужно настроить этот файл так, чтобы он больше не запрещал Google доступ к файлам CSS и JavaScript вашего сайта. Если вы работаете на WordPress и используете Yoast SEO, вы можете сделать это напрямую с нашим плагином Yoast SEO.
Проверьте файл robots.txt
Различные инструменты могут помочь вам проверить файл robots.txt, но когда дело доходит до проверки директив сканирования, мы всегда предпочитаем обращаться к источнику. У Google есть инструмент тестирования robots.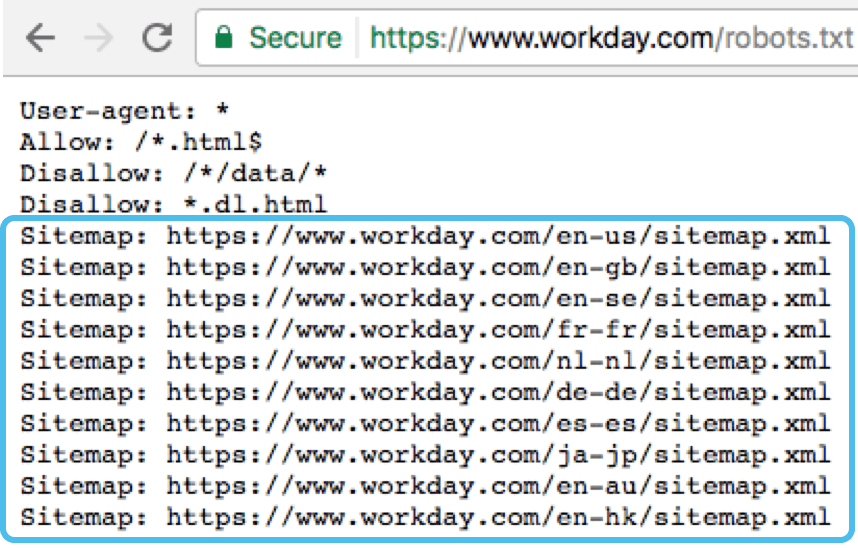 txt в консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
txt в консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
Обязательно проверьте свои изменения. тщательно, прежде чем поставить их жить! Вы не будете первым, кто случайно использует robots.txt, чтобы заблокировать весь ваш сайт и попасть в забвение поисковой системы!
За кулисами синтаксического анализатора robots.txt
В июле 2019 года Google объявил, что делает свой синтаксический анализатор robots.txt открытым исходным кодом. Если вы хотите разобраться в гайках и болтах, вы можете увидеть, как работает их код (и даже использовать его самостоятельно или предложить его модификации).
Йост де Валк
Йост де Валк является основателем Yoast. После продажи Yoast он перестал быть активным на постоянной основе и теперь выступает в качестве советника компании. Он интернет-предприниматель, который вместе со своей женой Марике активно инвестирует и консультирует несколько стартапов.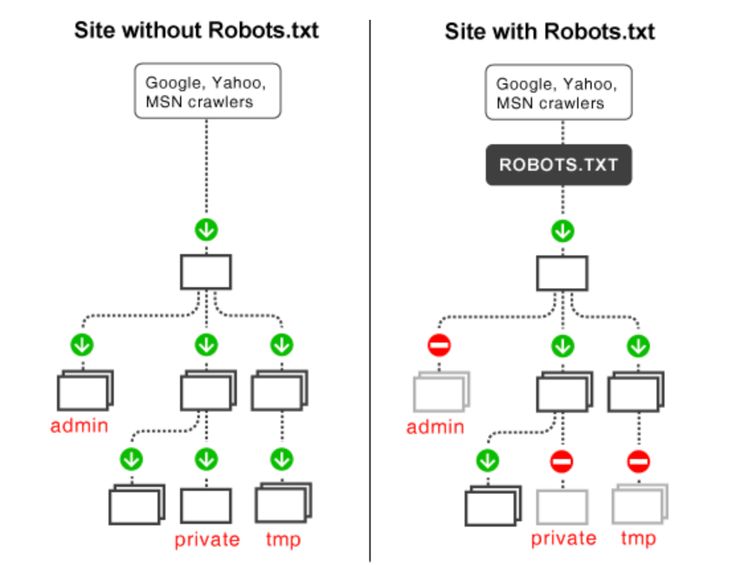

Об авторе