Robots txt https: Как создать правильный Robots.txt: настройка, индексация
Robots.txt — инструкция для SEO
25466 222
| SEO | – Читать 12 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ROBOTS.TXT
Ильхом Чакканбаев
Автор блога Seopulses.ru
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
Содержание
1. Зачем robots.txt нужен на сайте
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
— Disallow
— Allow
— Sitemap
— Clean-param
— Crawl-delay
7. Как проверить работу файла robots. txt
txt
— В Яндекс.Вебмастер
— В Google Search Console
Заключение
Зачем robots.txt нужен на сайте
Командами robots.txt называются директивы, которые разрешают либо запрещают сканировать отдельные участки веб-ресурса. С помощью файла вы можете разрешать или ограничивать сканирование поисковыми роботами вашего веб-ресурса или его отдельных страниц, чем можете повлиять на позиции сайта. Пример того, как именно директивы будут работать для сайта:
На картинке видно, что доступ к определенным папкам, а иногда и отдельным файлам, не допускает к сканированию поисковыми роботами. Директивы в файле носят рекомендательный характер и могут быть проигнорированы поисковым роботом, но как правило, они учитывают данное указание. Техническая поддержка также предупреждает вебмастеров, что иногда требуются альтернативные методы для запрета индексирования:
Какие страницы нужно закрыть от индексации
| Читать |
Где можно найти файл robots.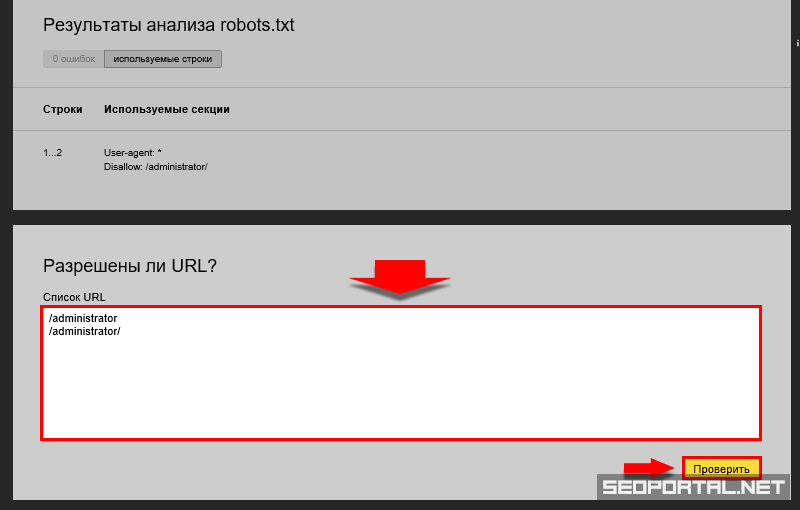 txt и как его создать или редактировать
txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как провести анализ индексации сайта
| Читать |
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
WordPress;
Для Opencart;
Webasyst.
Самые распространенные SEO-ошибки на сайте: инфографика
| Читать |
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
User-agent: Yandex — для обращения к поисковому роботу Яндекса;
User-agent: Googlebot — в случае с краулером Google;
User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Обращения в robots.txt для Яндекса:
Чтобы обозначить обращение для поисковых роботов данной системы применяют такие значения:
Yandex Bot — основной робот, который будет индексировать ваш ресурс;
Yandex Media — робот, который специализируется на сканировании мультимедийной информации;
Yandex Images — индексатор для Яндекс.Картинок;
Yandex Direct — робот, который сканирует страницы веб-площадок, имеющих отношение к рекламе в Яндексе;
Yandex Blogs — робот для поиска в блогах и форумах, который индексирует комментарии в постах;
Yandex News — бот собирающий данные по Яндекс Новостям;
Yandex Pagechecker — робот, который обращается к странице с целью валидировать микроразметку.
Обращения в robots.txt для Google:
Имена используемые для краулеров от Google:
Googlebot — краулер, индексирующий страницы веб-сайта;
Googlebot Image — сканирует изображения и картинки;
Googlebot Video — сканирует всю видео информацию;
AdsBot Google — анализирует качество размещенной рекламы на страницах для компьютеров;
AdsBot Google Mobile — анализирует качество рекламы мобильных версий сайта;
Googlebot News — оценивает страницы для использования в Google Новости;
AdsBot Google Mobile Apps — расценивает качество рекламы для приложений на андроиде, аналогично AdsBot.
Полный список роботов Яндекс и Google.
Синтаксис в robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
# — отвечает за комментирование;
* — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
По умолчанию указывается при любого правила в файле;
$ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Почему сайт не индексируется или
как проверить индексацию сайта в Google и Яндекс
| Читать |
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category2/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Следует указывать полный URL, когда относительный адрес использовать запрещено;
На нее не распространяются остальные правила в файле robots. txt;
txt;
XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
Sitemap.xml или карта сайта: как создать и настроить для Google и Яндекс
| Читать |
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www. example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь.
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Хотите узнать, как использовать Serpstat для поиска ошибок на сайте?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как проверить работу файла robots. txt
txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
Сам файл;
Кнопку, открывающую его;
Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Заключение
Robots.txt необходим для ограничения сканирования определенных страниц вашего сайта, которые не нужно включать в индекс, так как они носят технический характер. Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google и Яндекс. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.71 из 5 на основе 13 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO
Анатолий Бондаренко
Основные ошибки в оптимизации сайта и как их выявить
SEO
Ilkhom Chakkanbaev
Идеальная оптимизация страницы сайта: наглядное руководство [Инфографика]
SEO
Анастасия Кочеткова
Краулинговый или рендеринговый бюджет: не вместо, а вместе
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.
 д.
д. - Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.д.
Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.

- YandexMedia.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow
и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».

- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *.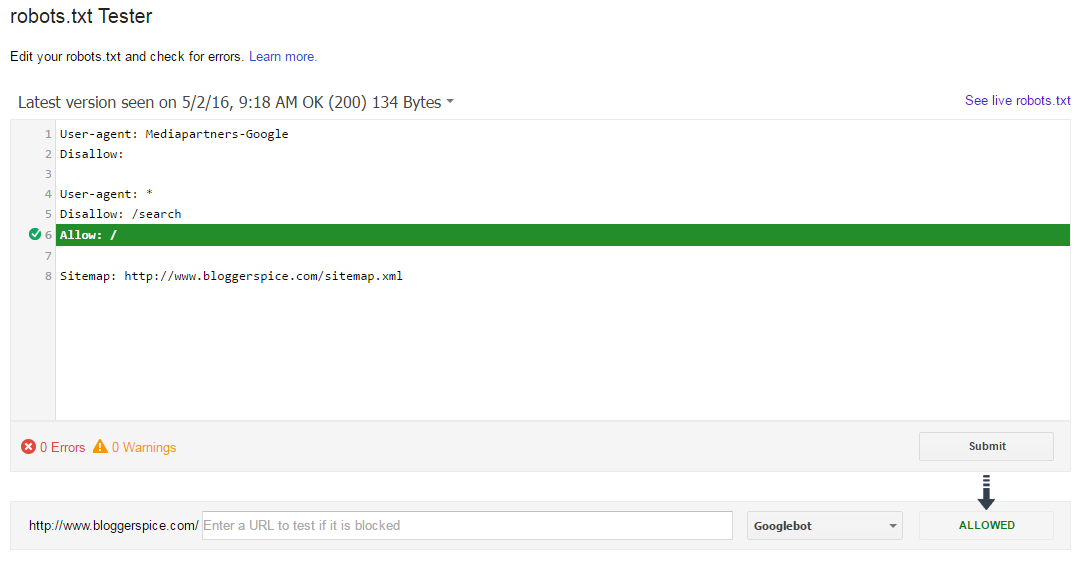 js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.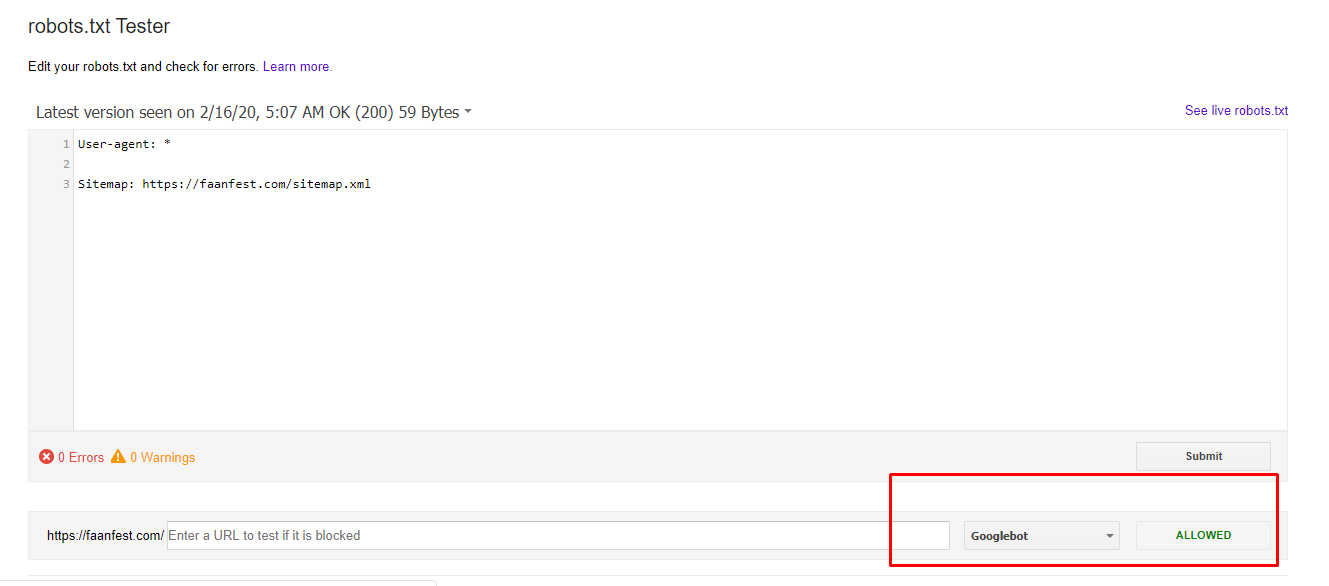
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту.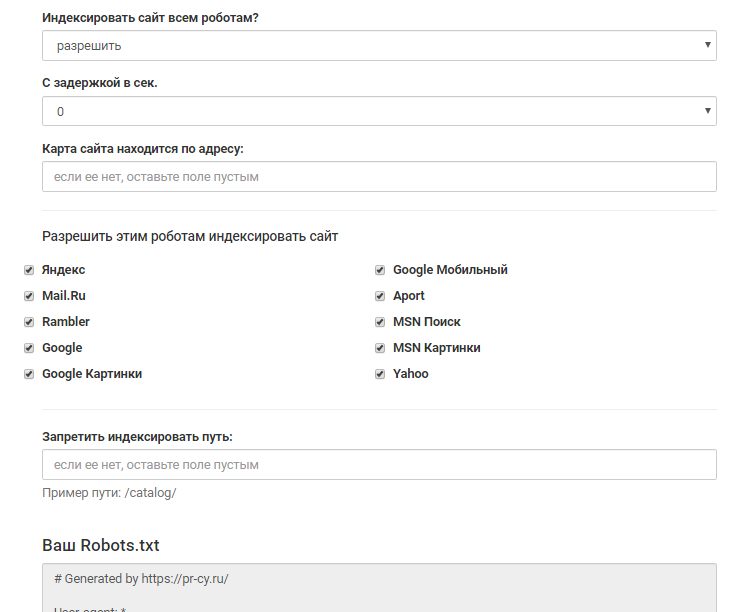 Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Полное руководство по robots.
 txt • Yoast
txt • YoastФайл robots.txt — это один из основных способов указать поисковой системе, где на вашем веб-сайте можно, а где нельзя. Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.txt на вашем веб-сайте.
Внимание!
Любые ошибки, допущенные вами в robots.txt, могут серьезно повредить вашему сайту, поэтому убедитесь, что вы прочитали и поняли всю эту статью, прежде чем погрузиться в нее.
Содержание
- Что такое файл robots.txt?
- Для чего нужен файл robots.txt?
- Куда мне поместить файл robots.txt?
- Плюсы и минусы использования robots.txt
- Синтаксис файла robots.txt
- Не блокировать файлы CSS и JS в robots.txt
- Проверка и исправление в Google Search Console
- Подтвердите файл robots.
 txt
txt - См. код
Что такое файл robots.txt?
Директивы сканирования
Файл robots.txt является одной из нескольких директив сканирования. У нас есть руководства по всем из них, и вы найдете их здесь.
Файл robots.txt — это текстовый файл, читаемый поисковыми системами (и другими системами). Файл robots.txt, также называемый протоколом исключения роботов, является результатом консенсуса среди первых разработчиков поисковых систем. Это не официальный стандарт, установленный какой-либо организацией по стандартизации, хотя его придерживаются все основные поисковые системы.
Базовый файл robots.txt может выглядеть примерно так:
Агент пользователя: * Запретить: Карта сайта: https://www.example.com/sitemap_index.xml
Что делает файл robots.txt?
Кэширование
Поисковые системы обычно кэшируют содержимое файла robots.txt, поэтому им не нужно его постоянно загружать, но обычно они обновляют его несколько раз в день. Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Поисковые системы обнаруживают и индексируют Интернет, просматривая страницы. По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).
Подробнее: Бот-трафик: что это такое и почему вы должны о нем заботиться »
Куда мне поместить файл robots.txt?
Файл robots.txt всегда должен находиться в корне вашего домена. Итак, если ваш домен www.example.com , сканер должен найти его по адресу https://www.example.com/robots.txt .
Также важно, чтобы ваш файл robots.txt назывался robots.txt. Имя чувствительно к регистру, поэтому сделайте это правильно, иначе оно не будет работать.
Плюсы и минусы использования robots.txt
Плюсы: управление краулинговым бюджетом
Общеизвестно, что поисковый паук заходит на веб-сайт с заранее определенным «допуском» на то, сколько страниц он будет сканировать (или сколько ресурс/время, которое он потратит, в зависимости от авторитета/размера/репутации сайта и того, насколько эффективно отвечает сервер). SEO-специалисты называют это краулинговый бюджет .
Если вы считаете, что у вашего веб-сайта проблемы с краулинговым бюджетом, то запрет поисковым системам «тратить» энергию на несущественные части вашего сайта может означать, что вместо этого они сосредоточатся на тех разделах, которые действительно важны. Используйте настройки очистки сканирования в Yoast SEO Premium, чтобы помочь Google сканировать то, что важно.
Иногда может быть полезно запретить поисковым системам сканировать проблемные разделы вашего сайта, особенно на сайтах, где необходимо выполнить большую SEO-очистку. После того, как вы прибрали вещи, вы можете впустить их обратно.
После того, как вы прибрали вещи, вы можете впустить их обратно.
Примечание о блокировке параметров запроса
Одной из ситуаций, когда краулинговый бюджет имеет решающее значение, является ситуация, когда ваш сайт использует множество параметров строки запроса для фильтрации или сортировки списков. Допустим, у вас есть десять различных параметров запроса, каждый из которых имеет разные значения, которые можно использовать в любой комбинации (например, футболки разных цветов и размеров). Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Против: не удалять страницу из результатов поиска
Несмотря на то, что вы можете использовать файл robots.txt, чтобы сообщить сканеру, куда он не может попасть на вашем сайте, вы не можете использовать его, чтобы сказать поиску движок, URL-адреса которого не показывать в результатах поиска – другими словами, его блокировка не остановит его индексацию. Если поисковая система найдет достаточное количество ссылок на этот URL, она включит его; он просто не будет знать, что находится на этой странице. Таким образом, ваш результат будет выглядеть так:
Если поисковая система найдет достаточное количество ссылок на этот URL, она включит его; он просто не будет знать, что находится на этой странице. Таким образом, ваш результат будет выглядеть так:
Если вы хотите надежно заблокировать страницу от появления в результатах поиска, вам нужно использовать мета-роботы тег noindex . Это означает, что для того, чтобы найти тег noindex , поисковая система должна иметь доступ к этой странице, поэтому не блокируйте ее с помощью robots.txt.
Директивы Noindex
Раньше можно было добавить директивы noindex в файл robots.txt, чтобы удалить URL-адреса из результатов поиска Google и избежать появления этих «фрагментов». Это больше не поддерживается (и технически никогда не было).
Con: не распространяется значение ссылки
Если поисковая система не может просканировать страницу, она не может распределить значение ссылки по ссылкам на этой странице. Это тупик, когда вы заблокировали страницу в robots. txt. Любое значение ссылки, которое могло пройти на эту страницу (и через нее), теряется.
txt. Любое значение ссылки, которое могло пройти на эту страницу (и через нее), теряется.
Синтаксис robots.txt
WordPress robots.txt
У нас есть целая статья о том, как лучше настроить файл robots.txt для WordPress. Не забывайте, что вы можете редактировать файл robots.txt вашего сайта в разделе Инструменты Yoast SEO → Редактор файлов.
Файл robots.txt состоит из одного или нескольких блоков директив, каждая из которых начинается со строки пользовательского агента. «User-agent» — это имя конкретного паука, к которому он обращается. У вас может быть либо один блок для всех поисковых систем, используя подстановочный знак для пользовательского агента, либо отдельные блоки для определенных поисковых систем. Поисковый паук всегда выберет блок, который лучше всего соответствует его названию.
Эти блоки выглядят так (не пугайтесь, ниже мы объясним):
User-agent: *
Disallow: /User-agent: Googlebot
Disallow:User-agent: bingbot
Disallow: /not-for-bing/
Такие директивы, как Allow и Disallow , не должны учитывать регистр, поэтому вам решать писать их строчными буквами или заглавными буквами. Значения чувствительны к регистру, поэтому
Значения чувствительны к регистру, поэтому /photo/ не совпадает с /Photo/ . Нам нравится писать директивы с большой буквы, потому что это облегчает чтение файла (для людей).
Директива агента пользователя
Первый бит каждого блока директив — это агент пользователя, который идентифицирует конкретного паука. Поле user-agent соответствует пользовательскому агенту этого конкретного паука (обычно более длинному), поэтому, например, наиболее распространенный паук от Google имеет следующий пользовательский агент:
Mozilla/5.0 (совместимый; Googlebot/2.1; +http ://www.google.com/bot.html)
Если вы хотите указать этому сканеру, что делать, относительно простой User-agent: Googlebot 9Строка 0066 сделает свое дело.
Большинство поисковых систем имеют несколько пауков. Они будут использовать определенный паук для своего обычного индекса, рекламных программ, изображений, видео и т. д.
Поисковые системы всегда выбирают наиболее конкретный блок директив, который они могут найти. Допустим, у вас есть три набора директив: один для
Допустим, у вас есть три набора директив: один для * , один для Googlebot и один для Googlebot-News . Если приходит бот, чей пользовательский агент Googlebot-Video , он будет следовать ограничениям Googlebot 9.0066 . Бот с пользовательским агентом Googlebot-News будет использовать более конкретные директивы Googlebot-News .
Наиболее распространенные пользовательские агенты для поисковых роботов
Вот список пользовательских агентов, которые вы можете использовать в файле robots.txt для соответствия наиболее часто используемым поисковым системам:
| Поисковая система | Поле | Агент пользователя |
|---|---|---|
| Baidu | Общие | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Видео | baiduspider-video |
| Bing | Общие | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| Общие | Googlebot | |
| Изображения | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | Общие | SLURP |
| Yandex | Общий | Яндекс |
DISLALIN У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук.
 Пустая строка
Пустая строка Disallow означает, что вы ничего не запрещаете, чтобы паук мог получить доступ ко всем разделам вашего сайта.В приведенном ниже примере блокируются все поисковые системы, которые «прослушивают» файл robots.txt, и не могут сканировать ваш сайт.
User-agent: *
Disallow: /
В приведенном ниже примере все поисковые системы могут сканировать весь ваш сайт, пропуская один символ.
User-agent: *
Disallow:
В приведенном ниже примере Google не сможет сканировать каталог Photo на вашем сайте и все, что в нем содержится.
Агент пользователя: googlebot
Запретить: /Фото
Это означает, что все подкаталоги каталога /Photo также не будут сканироваться. Это , а не , заблокирует Google от сканирования каталога /photo , так как эти строки чувствительны к регистру.
Это и заблокирует доступ Google к URL-адресам, содержащим /Photo , например /Photography/ .
Как использовать подстановочные знаки/регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или подстановочные знаки; однако все основные поисковые системы это понимают. Это означает, что вы можете использовать такие строки для блокировки групп файлов:
Запретить: /*.php
Запретить: /copyrighted-images/*.jpg
В приведенном выше примере * расширяется до любого имени файла, которому оно соответствует. Обратите внимание, что остальная часть строки по-прежнему чувствительна к регистру, поэтому вторая строка выше не блокирует сканирование файла с именем /copyrighted-images/example.JPG .
Некоторые поисковые системы, такие как Google, позволяют использовать более сложные регулярные выражения, но имейте в виду, что другие поисковые системы могут не понимать эту логику. Самая полезная функция, которую это добавляет, - это $ , что указывает на конец URL-адреса. В следующем примере вы можете увидеть, что это делает:
Disallow: /*.php$
Это означает, что /index.php нельзя индексировать, но /index.php?p=1 можно. быть. Конечно, это полезно только в очень специфических обстоятельствах и довольно опасно: легко разблокировать то, чего вы не хотели.
Нестандартные директивы сканирования robots.txt
А также Disallow и Директивы User-agent , есть пара других директив сканирования, которые вы можете использовать. Все сканеры поисковых систем не поддерживают эти директивы, поэтому убедитесь, что вы знаете их ограничения.
Директива allow
Хотя в исходной «спецификации» ее не было, в самом начале речь шла о директиве allow. Похоже, что большинство поисковых систем его понимают, и он позволяет использовать простые и очень читаемые директивы, такие как:
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Единственным другим способом достижения того же результата без директивы allow было бы конкретно запретить каждый файл в папке wp-admin .
Директива Crawl-delay
Crawl-delay является неофициальным дополнением к стандарту, и не многие поисковые системы придерживаются его. По крайней мере, Google и Яндекс им не пользуются, а с Bing непонятно. Теоретически, поскольку поисковые роботы могут быть довольно прожорливыми, вы можете попробовать .0065 crawl-delay направление, чтобы замедлить их.
Строка, подобная приведенной ниже, указывает этим поисковым системам изменить частоту запросов страниц на вашем сайте.
crawl-delay: 10
Будьте осторожны при использовании директивы crawl-delay . Установив задержку сканирования в десять секунд, вы разрешаете этим поисковым системам доступ только к 8640 страницам в день. Это может показаться достаточным для небольшого сайта, но не очень для больших сайтов. С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
Директива карты сайта для XML-карт сайта
С помощью директивы карты сайта вы можете указать поисковым системам — Bing, Yandex и Google — где найти вашу карту сайта XML. Конечно, вы можете отправить свои XML-карты сайта в каждую поисковую систему, используя их инструменты для веб-мастеров. Мы настоятельно рекомендуем вам это сделать, потому что инструменты для веб-мастеров предоставят вам массу информации о вашем сайте. Если вы не хотите этого делать, добавление строки
Конечно, вы можете отправить свои XML-карты сайта в каждую поисковую систему, используя их инструменты для веб-мастеров. Мы настоятельно рекомендуем вам это сделать, потому что инструменты для веб-мастеров предоставят вам массу информации о вашем сайте. Если вы не хотите этого делать, добавление строки карты сайта в файл robots.txt является хорошей быстрой альтернативой. Yoast SEO автоматически добавит ссылку на вашу карту сайта, если вы позволите ему сгенерировать файл robots.txt. В существующий файл robots.txt вы можете добавить правило вручную через редактор файлов в разделе «Инструменты».
Карта сайта: https://www.example.com/my-sitemap.xml
Не блокировать файлы CSS и JS в robots.txt
С 2015 года Google Search Console предупреждает владельцев сайтов не блокировать CSS и JS файлы. Мы давно говорим вам одно и то же: не блокируйте файлы CSS и JS в файле robots.txt. Объясним, почему не следует блокировать эти файлы от робота Googlebot.
Блокируя файлы CSS и JavaScript, вы запрещаете Google проверять правильность работы вашего веб-сайта. Если вы заблокируете файлы CSS и JavaScript в своем robots.txt , Google не может отобразить ваш веб-сайт должным образом. Теперь Google не может понять ваш сайт, что может привести к снижению рейтинга. Более того, даже такие инструменты, как Ahrefs, отображают веб-страницы и выполняют JavaScript. Поэтому не блокируйте JavaScript, если хотите, чтобы ваши любимые инструменты SEO работали.
Это идеально согласуется с общим предположением, что Google стал более «человечным». Google хочет видеть ваш сайт таким, каким его видит посетитель-человек, чтобы он мог отличить основные элементы от дополнительных. Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Проверка и исправление в Google Search Console
Google поможет вам найти и исправить проблемы с файлом robots.txt, например, в разделе «Индексирование страниц» в Google Search Console. Просто выберите параметр «Заблокировано robots.txt»:
Проверьте в Search Console, какие URL-адреса заблокированы вашим robots. txt Чтобы разблокировать заблокированные ресурсы, нужно изменить файл robots.txt . Вам нужно настроить этот файл так, чтобы он больше не запрещал Google доступ к файлам CSS и JavaScript вашего сайта. Если вы работаете на WordPress и используете Yoast SEO, вы можете сделать это напрямую с нашим плагином Yoast SEO.
Проверьте файл robots.txt
Различные инструменты могут помочь вам проверить файл robots.txt, но когда дело доходит до проверки директив сканирования, мы всегда предпочитаем обращаться к источнику. Google имеет инструмент тестирования robots.txt в своей консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
Проверка файла robots.txt в консоли поиска GoogleОбязательно проверьте свои изменения. тщательно, прежде чем поставить их жить! Вы не будете первым, кто случайно использует robots.txt, чтобы заблокировать весь ваш сайт и попасть в забвение поисковой системы!
За кулисами синтаксического анализатора robots.
txtВ июле 2019 года Google объявил, что делает свой синтаксический анализатор robots.txt открытым исходным кодом. Если вы хотите разобраться в гайках и болтах, вы можете увидеть, как работает их код (и даже использовать его самостоятельно или предложить его модификации).
Йоост де Валк
Йоост де Валк — основатель Yoast. После продажи Yoast он перестал быть активным на постоянной основе и теперь выступает в качестве советника компании. Он интернет-предприниматель, который вместе со своей женой Марике активно инвестирует и консультирует несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Robots.txt и SEO: полное руководство
Что такое Robots.txt?
Robots.txt — это файл, указывающий поисковым роботам не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) распознают и выполняют запросы Robots. txt.
Почему файл robots.txt важен?
Большинству веб-сайтов не нужен файл robots.txt.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они НЕ будут автоматически индексировать страницы, которые не важны, или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотели бы использовать файл robots.txt.
Блокировать непубличные страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать. Например, у вас может быть промежуточная версия страницы. Или страница входа. Эти страницы должны существовать. Но вы же не хотите, чтобы на них попадали случайные люди. Это тот случай, когда вы должны использовать robots.txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.
Максимальный краулинговый бюджет. Если вам трудно проиндексировать все ваши страницы, у вас может быть проблема с краулинговым бюджетом. Блокируя неважные страницы с помощью файла robots. txt, робот Googlebot может тратить больше вашего краулингового бюджета на страницы, которые действительно важны.
Предотвращение индексации ресурсов: Использование метадиректив может работать так же хорошо, как Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают с мультимедийными ресурсами, такими как PDF-файлы и изображения. Вот где в игру вступает robots.txt.
Суть? Robots.txt указывает поисковым роботам не сканировать определенные страницы вашего сайта.
Вы можете проверить, сколько страниц вы проиндексировали в Google Search Console.
Если число соответствует количеству страниц, которые вы хотите проиндексировать, вам не нужно возиться с файлом Robots.txt.
Но если это число больше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не должны быть проиндексированы), то пришло время создать файл robots.txt для вашего веб-сайта.
Передовой опыт
Создание файла robots.txt
Первым делом необходимо создать файл robots. txt.
Будучи текстовым файлом, вы можете создать его с помощью блокнота Windows.
И независимо от того, как вы в конечном итоге сделаете свой файл robots.txt, формат будет точно таким же:
User-agent: X
Disallow: Y
User-agent — это конкретный бот, которым вы Разговариваю с.
И все, что идет после «запретить», — это страницы или разделы, которые вы хотите заблокировать.
Вот пример:
User-agent: googlebot
Disallow: /images
Это правило предписывает роботу Googlebot не индексировать папку изображений вашего веб-сайта.
Вы также можете использовать звездочку (*), чтобы обратиться ко всем без исключения ботам, которые заходят на ваш сайт.
Вот пример:
User-agent: *
Disallow: /images
Знак «*» указывает всем и каждому паукам НЕ сканировать вашу папку с изображениями.
Это лишь один из многих способов использования файла robots. txt. В этом полезном руководстве от Google содержится дополнительная информация о различных правилах, которые вы можете использовать, чтобы заблокировать или разрешить ботам сканировать разные страницы вашего сайта.
Сделайте так, чтобы ваш файл robots.txt было легко найти
Когда у вас есть файл robots.txt, пришло время запустить его.
Технически вы можете поместить файл robots.txt в любой основной каталог вашего сайта.
Но чтобы увеличить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https://example.com/robots.txt
(Обратите внимание, что ваш файл robots.txt чувствителен к регистру , Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка на наличие ошибок и ошибок
ОЧЕНЬ важно, чтобы ваш файл robots.txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.
К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Он показывает вам ваш файл robots.txt… и любые ошибки и предупреждения, которые он находит:
Как видите, мы блокируем пауков от сканирования нашей страницы администратора WP.
Мы также используем robots.txt, чтобы заблокировать сканирование автоматически сгенерированных страниц тегов WordPress (чтобы ограничить дублированный контент).
Robots.txt и мета-директивы
Зачем использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега «noindex»?
Как я упоминал ранее, тег noindex сложно применить к мультимедийным ресурсам, таким как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots.txt, чем вручную добавлять тег noindex к каждой отдельной странице.
Существуют также крайние случаи, когда вы не хотите тратить краулинговый бюджет на переход Google на страницы с тегом noindex.

Об авторе