Спрос на авито: Аналитика спроса на Авито — 3 способа
Аналитика спроса на Авито — 3 способа
Без аналитики в продвижении никак. И анализ спроса и конкурентов — первое, с чего нужно начинать. Иначе решения о том, что и где продвигать, будут интуитивны и, вероятно, сольют бюджет. С Авито это правило тоже работает: бизнесу нужно понимать, как работает площадка и какие товары на ней будут покупать. О том, как правильно анализировать спрос на Авито, — разбираем в статье.
В одной поисковой выдаче Авито появляются объявления и частных лиц, и компаний. В марте 2022 года на площадке каждый день размещалось больше 900 000 объявлений. И чтобы выделиться среди них, бизнесу приходится публиковать много объявлений, размещать ключевые слова в тексте и использовать инструменты продвижения от Авито. Подключить аккаунт и оплатить размещения и услуги продвижения можно через eLama — тогда с любыми вопросами о работе с Авито поможет Служба Заботы.
Подключить аккаунт →
Но все эти усилия не будут оправданы, если покупатели не интересуются товаром.
Что популярно на Авито
По подсчетам Авито, самыми продаваемыми товарами в 2021 году стали:
- велосипеды;
- домашние питомцы — кошки, собаки;
- мебель — столы, диваны;
- техника — холодильники, телевизоры;
- мангалы;
- предметы интерьера — зеркала и ковры.
Помимо этого, на Авито часто покупают автозапчасти, товары для досуга и более дорогие продукты — автомобили, дорожную технику и недвижимость. В марте 2022 года выросли продажи товаров для дома (+52%), личного пользования (+47%) и электроника (+41%). А количество сделок во всей категории «Товары» увеличилось на 40–50 % по сравнению с прошлым годом.
На рост продаж в определенных категориях влияет сезонность. Например, к концу года почти в три раза увеличивается спрос на товары для зимних видов спорта и теплую одежду, а весной 2022-го на 48% вырос интерес к рассаде и дачному строительству.
Есть ли спрос на услуги
Авито — почти универсальный канал продаж, который подойдет для бизнеса разных тематик. Сложно продвигаться будет только товарам с узкой аудиторией и сложными B2B-продуктами, продажи в которых предполагают долгий цикл сделки и личное общение с лицом, принимающим решение.
Сложно продвигаться будет только товарам с узкой аудиторией и сложными B2B-продуктами, продажи в которых предполагают долгий цикл сделки и личное общение с лицом, принимающим решение.
В 2020 году пользователей Авито, по данным Data Insight, больше всего интересовало создание сайтов и другие IT-услуги. Следом шли услуги из категорий: «Красота и здоровье» — маникюр, массаж и так далее, «Ремонт и обслуживание техники», «Ремонт, строительство» и «Изготовление изделий на заказ». Весной 2022-го россияне больше всего интересовались ремонтом и обслуживания техники — от смартфонов до холодильников и стиральных машин: спрос на эти услуги вырос на 45%.
Получайте бонусы и вознаграждение за продвижение на Авито
До 20 000 ₽ за продвижение товаров на площадке при запуске до 30 ноября, а также до 8% от оборотов клиентов
Узнать больше
Оценить спрос можно вручную через поиск платформы или с помощью инструментов — Wordstat от Яндекса и «Аналитики спроса» от Авито.
Аналитика спроса от Авито
Это новый инструмент в личном кабинете продавца Авито. Он помогает проанализировать спрос на продукты из разных категорий. Данные собираются автоматически и обновляются каждый день.
Инструмент показывает, сколько продавцов этой тематики есть на площадке, много ли объявлений, часто ли их просматривают пользователи и оставляют ли они контакты, то есть звонят или пишут сообщения.
Инструмент в кабинете продавца Авито«Аналитика спроса» доступна на тарифах «Расширенный», «Максимальный» и при оплате за просмотры, и пока ее можно использовать для всех категорий, кроме работы, услуг и транспорта.
Разберем, как работает инструмент, на примере продвижения садовой техники.
Для сортировки данных есть три фильтра: регион, категория, период времени — за последний месяц или за последний день. Категорию можно найти в поиске или в списке ниже, как показано на изображении.
Садовая техника относится к категории «Для дома и дачи», и уже на этом этапе видно, что конкуренция в тематике высокая — больше миллиона объявлений в месяц.
Затем можно перейти в нужную подкатегорию и оценить количество запросов там:
В «Садовой технике» большой спрос и при этом небольшая конкуренция: на одно объявление приходится примерно четыре контакта. То есть приблизительно четыре пользователя заинтересуются вашим объявлением, но, может, и больше.
Разберем, что означают показатели:
- Продавцы — и частные лица, и компании, которые разместили хотя бы одно объявление в этой категории. Чем больше продавцов, тем выше конкуренция в категории. В тематиках с высокой конкуренцией, понадобится дополнительное платное продвижение, чтобы выделиться среди конкурентов.
- Объявления — количество активных объявлений сейчас на площадке. Чем больше объявлений в категории, тем выше конкуренция за покупателя.
- Контакты — засчитывается каждый раз, когда пользователь пишет чат или нажимает кнопку «Показать телефон».
- Просмотры — общее значение просмотров страницы конкретного объявления в категории.
- Уровень спроса показывает сколько контактов в среднем приходилось на одно объявление. Чем выше уровень спроса, тем большей популярностью пользуется категория или конкретный товар и тем перспективнее тематика.
Чтобы оценить перспективность товара и тематики, в подкатегории можно посмотреть динамику спроса по месяцам, узнать, как менялось количество конкурентов, объявлений и контактов. Есть два графика — за год и месяц. Первый покажет, сезонные изменения спроса, а второй — спрос на выходных и резкие изменения.
На этом графике видно, что количество объявлений остается одинаковым весь год, а интерес пользователей сезонный и растет весной и летом.
«Аналитика спроса» показывает, какие товары будут пользоваться спросом, а какие — нет. Это помогает продавцам оптимизировать свой ассортимент под перспективные ниши.
Что еще посмотреть о продвижении на Авито
- Запускаем продвижение на Авито: пошаговое руководство
- Почему вашему бизнесу нужен профиль на «Авито»: 5 главных причин
- 6 мифов, которые мешают вам продвигать бизнес на Авито
- Вебинар «Авито для агентств: как рекламировать клиентов и увеличивать свой доход»
- Вебинар «Авито для рекламодателей: возможности продвижения и способы повышения продаж»
Работа с поиском Авито
Введите в поиск сервиса название товара и посмотрите, много ли объявлений появляется по этому запросу и есть ли среди них новые. Затем оцените, есть ли в выдаче предложения от конкурентов.
Затем оцените, есть ли в выдаче предложения от конкурентов.
В Санкт-Петербурге всего 646 активных объявлений по запросу «мотокоса», есть предложения и от компаний, и от частных лиц.
Если объявлений мало или совсем нет, то и спроса на этот товар, вероятнее всего, нет. В этом случае можно посмотреть, есть ли интерес к другим вашим товарам и услугам.
Если объявлений и конкурентов много — изучите их, чтобы выстроить дальнейшую стратегию продвижения. На что обратить внимание:
- Что еще продают конкуренты и какие у них цены.
- Используют ли конкуренты инструменты продвижения — усиление видимости, брендирование страницы и т. д. Если почти у всех есть платное продвижение, то, скорее всего, оно окупается. Подробнее возможности Авито мы разобрали в статье об инструментах продвижения.
- Какие отзывы оставляют конкурентам. В них вы найдете слабые и сильные стороны других компаний: у кого-то платная доставка, а кто-то не вовремя отправляет заказ.

Анализ спроса в Wordstat
Wordstat — сервис от Яндекса, который показывает, насколько популярные те или иные запросы. Обычно Wordstat используют для контекстной рекламы или сбора семантического ядра при SEO-продвижении. Но и для оценки спроса на Авито сервис тоже подойдет: он покажет, ищут ли товары в конкретном регионе.
С помощью Wordstat можно оценить примерный спрос: он показывает только запросы, которые пользователи вводят в поиске Яндекса, показатели в Авито могут от них отличаться. Как работать с сервисом Wordstat, мы разобрали в отдельной статье.
Как посмотреть статистику на Авито | Как пользоваться Аналитикой спроса на Avito
Аудиоверсия этой статьи
Авито — одна из самых популярных площадок для развития бизнеса. Максим Оганов, основатель агентства интернет-маркетинга Oganov Digital и эксперт в бизнес-школе Авито, рассказывает, чем может быть полезен инструмент Аналитика спроса предпринимателю и как им пользоваться
Максим Оганов, основатель агентства интернет-маркетинга Oganov Digital и эксперт в бизнес-школе Авито, рассказывает, чем может быть полезен инструмент Аналитика спроса предпринимателю и как им пользоваться
Деловая среда
Платформа знаний и сервисов для бизнеса
Открыть ИП сейчас
Максим Оганов
– Руководитель агентства комплексного интернет-маркетинга «Oganov Digital»
– Сертифицированный авитолог
– Спикер на мепроприятиях от Деловая среда, Авито, Like Центр, eLama, Синергия и МинЭкономРазвития
– Эксперт и преподаватель в официальной бизнес-школе «Авито»
– Участник акселлераторов ФРИИ и СтартХаб
– Практикующий маркетолог с опытом более 8 лет.
Содержание
Возможности аналитики спроса и как ей пользоваться
Как анализировать статические данные
Как анализировать динамические данные
Чем аналитика спроса полезна бизнесу
🚀 Сервис для быстрого старта бизнеса
Зарегистрируйте бизнес удаленно и бесплатно — через сервис от Деловой среды
Подать заявку онлайн
Аналитика спроса на Авито — это инструмент, позволяющий продавцам:
анализировать активность посетителей сайта, которые ищут нужные товары по запросам;
просматривать количество объявлений в статике и динамике;
выбрать сферу деятельности на площадке и корректировать собственную стратегию продвижения на Авито.

Аналитика спроса помогает определиться с тарифом и понять, какие услуги по продвижению потребуются вашему бизнесу, ведь с высокой конкуренцией нужны услуги большей силы.
Инструмент будет полезен как начинающим предпринимателям, так и опытным продавцам. Любой пользователь Авито с тарифами «Расширенный» и «Максимальный» может посмотреть статистику спроса на товары отдельных категорий.
Возможности аналитики спроса и как ей пользоваться
Рассмотрим работу инструмента на примере категории «Электроника». Чтобы перейти к инструменту, зайдите в свой аккаунт Авито, перейдите в личный кабинет, нажав на иконку профиля.
После перехода в профиль вы увидите меню в левой части экрана. Найдите пункт «Аналитика спроса».
Теперь перед вами страница инструмента.
Все объявления можно сортировать по трем параметрам: регион, категория товара и период публикации (за месяц или за день). Статистика отображается по категориям и подкатегориям. Так, «Электроника» — это категория, объединяющая подкатегории: телефоны, аудио и видео, ноутбуки, товары для компьютера и др. Таким образом, мы можем видеть статистику категории «Электроника» в целом, а также статистику отдельных подкатегорий.
Так, «Электроника» — это категория, объединяющая подкатегории: телефоны, аудио и видео, ноутбуки, товары для компьютера и др. Таким образом, мы можем видеть статистику категории «Электроника» в целом, а также статистику отдельных подкатегорий.
Рассмотрим работу инструмента на реальном примере. У предпринимателя Константина собственный магазин электроники, и он хочет использовать площадку Авито в качестве инструмента продаж:
проанализировать спрос;
выбрать тариф продвижения;
товары, которые стоит продвигать.
Для анализа спроса укажем регион Санкт-Петербург, категорию «Электроника», период — месяц. Получим следующую картину.
Как анализировать статические показатели
На снимке представлены численные показатели по данным: продавцы, объявления, просмотры, контакты и уровень спроса.
Продавцы — это физические и юридические лица, которые разместили хотя бы одно объявление в категории.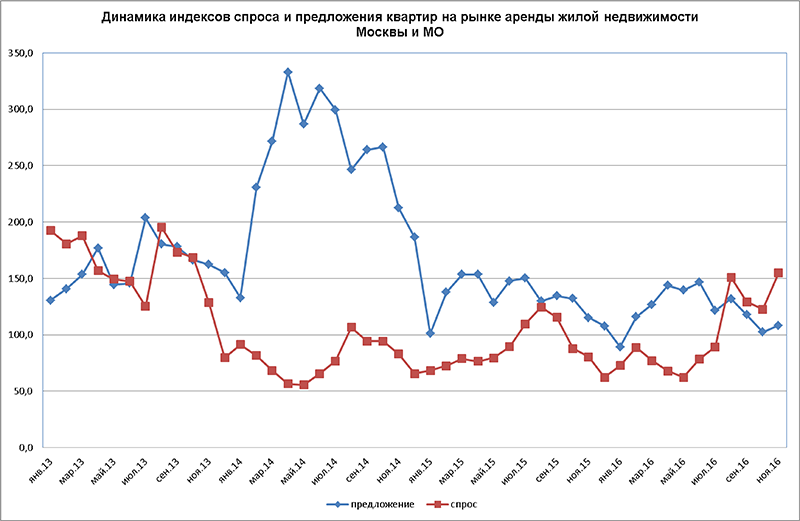 Уровень конкуренции напрямую зависит от количества продавцов. Если конкуренция слишком высокая (ориентировочно — свыше 50 тыс. продавцов), потребуется платное продвижение или услуги авитолога, специалиста по продвижению на Авито.
Уровень конкуренции напрямую зависит от количества продавцов. Если конкуренция слишком высокая (ориентировочно — свыше 50 тыс. продавцов), потребуется платное продвижение или услуги авитолога, специалиста по продвижению на Авито.
Объявления — общее число объявлений на Авито в настоящий момент.
Контакты — количество заинтересованных пользователей — таких, которые написали или нажали кнопку «Показать номер».
Просмотры — количество посещений карточки.
Уровень спроса — отражает среднее количество покупателей на одно объявление в категории. Уровень спроса 3–5 считается высоким и говорит о популярности категории.
Наибольший интерес для аналитики представляют: количество объявлений, количество контактов и уровень спроса.
Количество объявлений — это общее число объявлений в указанной категории по заданным фильтрам. Этот показатель отражает общий уровень спроса и заполненности рынка теми или иными товарами. В примере видим, что общее число товаров в категории «Телефоны» — 165 392, а в категории «Аудио и видео» — 182 030.
Этот показатель отражает общий уровень спроса и заполненности рынка теми или иными товарами. В примере видим, что общее число товаров в категории «Телефоны» — 165 392, а в категории «Аудио и видео» — 182 030.
📌 Совет
При анализе стоит учесть, что одно объявление может содержать в себе продажу сразу нескольких товаров. К видеокамере может продаваться чехол, штатив и другие аксессуары за дополнительную плату или комплект видеокамер либо аудиотехники. Но бывает и обратное, когда один товар появляется в нескольких объявлениях. Такое можно наблюдать на примере продажи квартир.
Второе интересующее нас поле — контакты. Контакт отражается в статистике, когда потенциальный покупатель нажал кнопку «Показать номер» или начал диалог с продавцом. При этом, даже если пользователь совершил несколько действий, он считается одним контактом. Видим, что в категории «Телефоны» — 579 467 контактов, а в категории «Аудио и видео» — 279 541.
Следующий важный показатель — уровень спроса. Это отношение количества контактов к количеству объявлений в категории. Заметим, что в обеих рассматриваемых категориях он отличается: в среднем на каждое объявление в категории «Телефоны» приходится 3 контакта, а в категории «Аудио и видео» — 1.
Это отношение количества контактов к количеству объявлений в категории. Заметим, что в обеих рассматриваемых категориях он отличается: в среднем на каждое объявление в категории «Телефоны» приходится 3 контакта, а в категории «Аудио и видео» — 1.
Здесь стоит обратить внимание на то, что уровень спроса — это результат простого деления. Поясним: в категории могут быть заброшенные или некачественные объявления с завышенными ценами, а также очень привлекательные предложения, которые закрываются за считанные часы. Поэтому делать однозначные выводы относительно уровня спроса не стоит, но при оценке популярности категории этот показатель очень поможет.
Мы рассмотрели статические показатели данных. Этот вид данных позволяет оценить уровень спроса в категории за конкретный период — месяц или день. Особенно важными пунктами при анализе являются количество контактов, объявлений и уровень спроса.
На основе приведенных данных Константину рациональнее создавать объявления в категории «Телефоны», поскольку спрос здесь более высокий и обеспечит больший поток клиентов. Но чтобы составить полную картину, стоит обратиться и к динамическим показателям.
Но чтобы составить полную картину, стоит обратиться и к динамическим показателям.
Как анализировать динамические показатели
Нажав на название категории «Телефоны», можно посмотреть подробную статистику в цифрах и аналитику спроса на графике, как на изображении ниже.
По графику становится ясно — уровень спроса на телефоны был на среднем уровне на протяжении 2021 года и начал повышаться в феврале 2022-го, достигнув пиковых значений в марте. Сейчас спрос возвращается к своему прежнему состоянию.
Перейдем в категорию «Аудио и видео».
Здесь видим, что уровень спроса в разы ниже, где пиковое значение — 1,93. Однако динамика прослеживается похожая: резкий скачок уровня спроса в марте и затем его стабилизация к прежним значениям.
В этом примере Константину стоит ориентироваться на статические показатели, поскольку динамические не показывают четкой картины. Вероятнее всего, пиковое значение спроса в марте в обеих категориях связано с внешними временными факторами.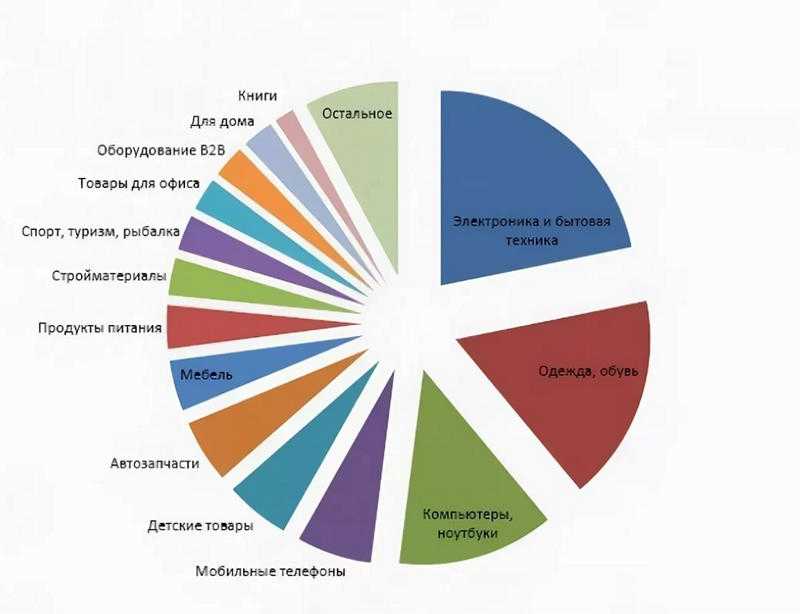
📌 Совет
Уровень спроса в динамике может быть полезен в случае сравнения двух разных направлений, например «Средства гигиены» и «Ноутбуки». Но случается и так, что динамика отличается в категориях одного направления, поэтому анализ в любом случае необходим.
Среди рассмотренных категорий наиболее перспективной для размещения объявлений будет категория «Телефоны». Хотя в категории «Аудио и видео» больше объявлений, количество контактов здесь значительно ниже, что и определяет более низкий уровень спроса. Среднее число контактов в категории «Телефоны» — 3 человека на объявление. Это говорит о том, что посетители заинтересованы в этом виде товаров, то есть чаще ищут их по запросам, следовательно, шансы на успешные продажи повышаются.
🚀 Сервис для быстрого старта бизнеса
Зарегистрируйте ИП или ООО без визита в налоговую и пошлины — через сервис от Деловой среды
Подать заявку онлайн
Чем аналитика спроса полезна бизнесу
Аналитика спроса — это удобный, а главное, полезный инструмент при работе с площадкой Авито.
С помощью аналитики спроса можно увидеть:
какие товары сезонные,
на какие растет спрос,
какие постепенно уходят с рынка.
Сезонные товары отслеживаются по динамическим данным — кривая спроса будет повышаться в определенный сезон. Рост спроса сопровождается повышением кривой ближе к настоящей дате, а спад — снижением кривой.
Аналитика позволит выбрать нужную категорию товара, если вы только планируете начать свой бизнес на Авито, а также оценить уровень конкуренции в своей категории и составить грамотную стратегию продвижения на Авито — определить количество объявлений и их структуру, выбрать услуги по продвижению.
Статьи
10 советов предпринимателям, как успешно продавать на маркетплейсах
Выбор ниши
Статьи
Как привлекать клиентов через маркетплейсы услуг
Соцсети
Статьи
5 ошибок предпринимателей на сервисах объявлений.
 Гид по эффективным продажам
Гид по эффективным продажамПродвижение в Интернете
Задача прогнозирования спроса Avito — Kaggle — Сквозная реализация. | by Zishaan Khan
В электронной коммерции сочетание крошечных нюансов продукта может привести к существенному увеличению интереса пользователя к покупке. Следующие детали, упомянутые ниже, могут иметь большое значение для развития интереса, если пользователь взглянул на продукт.
Итак, приведенные выше несколько примеров показывают, как один продавец может оптимизировать листинг продукта на веб-сайте электронной коммерции. Но что происходит, даже если продавец имеет полностью оптимизированный список своего продукта и не получает никакого количества продаж. Это приводит к проблеме анализа спроса на продукт, который продавец хочет продать. Это так важно, потому что если продавец вкладывает деньги в рекламу, а люди не посещают его товар или даже после посещения не заинтересованы в покупке товара, это явно объясняет какую-то проблему в товаре продавца.
Такие компании, как Amazon или Flipkart, тратят миллионы на рекламу, и если спрос на продукты не существует, это приводит к огромным потерям для компании или даже продавца, который перерасходует свои собственные деньги на рекламу своего продукта, если спрос на его продукт не существует. просто разочарование продавца может привести к большим проблемам в бизнесе.
В апреле 2018 года Avito запустил в Kaggle конкурс, основанный на предсказании спроса на тот или иной товар. Avito — российский сайт объявлений с разделами, посвященными продаже товаров общего назначения, работе, недвижимости, знакомствам, продаже автомобилей и услугам. Avito — самый популярный сайт объявлений в России и второй по величине сайт объявлений в мире после Craigslist. [Источник: Википедия].
Набор данных был создан командой Avito, в котором набор данных имеет различные категориальные характеристики, такие как идентификатор рекламы, заголовок рекламы, описание рекламы, изображение рекламы, item_id, user_id и т. д., а также Deal_Probablity в качестве целевой переменной. Здесь вероятность сделки представляет собой непрерывную переменную, которая находится в диапазоне от 0 до 1. Нули указывают наименьшие вероятности того, что предмет будет куплен, а 1 указывает на самые высокие вероятности того, что предмет будет куплен. Итак, эта проблема — проблема регрессии в машинном обучении.
д., а также Deal_Probablity в качестве целевой переменной. Здесь вероятность сделки представляет собой непрерывную переменную, которая находится в диапазоне от 0 до 1. Нули указывают наименьшие вероятности того, что предмет будет куплен, а 1 указывает на самые высокие вероятности того, что предмет будет куплен. Итак, эта проблема — проблема регрессии в машинном обучении.
1. Что такое прогнозирование спроса.
2. Почему важно прогнозирование спроса.
3. Набор данных Kaggle и показатели его производительности
4. Простой исследовательский анализ данных
5. Предварительная обработка данных
6. Разработка функций
7. Изучение наших моделей машинного обучения
9002 9.0 Лучшая модель оценки Развертывание на виртуальной машине — (в процессе)10. Итоги и будущие работы
11. Ссылки
Что такое прогнозирование спроса? Прогнозирование спроса — это процесс оценки будущего потребительского спроса за определенный период с использованием исторических данных и другой информации.
Надлежащее прогнозирование спроса дает компаниям ценную информацию об их потенциале на текущем рынке и других рынках, чтобы менеджеры могли принимать обоснованные решения о ценообразовании, стратегиях роста бизнеса и рыночном потенциале.
Без прогнозирования спроса предприятия рискуют принять неверные решения в отношении своей продукции и целевых рынков, а неосведомленные решения могут иметь далеко идущие негативные последствия для затрат на хранение запасов, удовлетворенности клиентов, управления цепочками поставок и прибыльности.
Почему важно прогнозирование спроса?
Существует ряд причин, по которым прогнозирование спроса является важным процессом для бизнеса:
- Прогнозирование продаж помогает в бизнес-планировании, составлении бюджета и постановке целей. Когда у вас будет хорошее представление о том, как могут выглядеть ваши будущие продажи, вы можете приступить к разработке обоснованной стратегии закупок, чтобы убедиться, что ваши поставки соответствуют спросу клиентов.
- Это позволяет предприятиям более эффективно оптимизировать запасы, увеличить оборачиваемость запасов и снизить затраты на хранение.
- Это дает представление о предстоящем движении денежных средств, что означает, что предприятия могут более точно планировать расходы на оплату поставщиков и другие операционные расходы, а также инвестировать в развитие бизнеса.
- С помощью прогнозирования продаж вы также можете заблаговременно выявлять и устранять любые перегибы в конвейере продаж, чтобы обеспечить стабильную эффективность вашего бизнеса в течение всего периода. Когда дело доходит до управления запасами, большинство владельцев бизнеса электронной коммерции слишком хорошо знают, что слишком мало или слишком много запасов может нанести ущерб операциям.
- Предвидеть спрос означает знать, когда увеличить персонал и другие ресурсы, чтобы обеспечить бесперебойную работу в периоды пиковой нагрузки.
3. Понимание набора данных Kaggle и показателей его производительности.
Набор данных был большим, я сталкивался с различными проблемами при обработке больших данных, так как у меня меньше вычислительного устройства. Ядра Kaggle недостаточно для тех, кто планирует выполнять все операции на ядре Kaggle. Набор данных, предоставленный командой Avito, содержит все, изображения, текст, категориальные и непрерывные переменные. Давайте посмотрим на CSV-файл поезда.
-
item_id— Идентификатор конкретного объявления. -
user_id— Идентификатор пользователя -
регион— Объявления относятся к региону. -
город— Объявление принадлежит городу. -
parent_category_name— Категория объявлений верхнего уровня согласно рекламной модели Авито. -
category_name— Мелкозернистая категория объявлений по рекламной модели Авито. -
param_1— Необязательный параметр из рекламной модели Авито. -
param_2— Необязательный параметр из рекламной модели Авито.
-
param_3— Необязательный параметр из рекламной модели Авито. -
заголовок— Заголовок объявления. -
описание— Описание объявления. -
цена— Цена объявления. -
item_seq_number— Порядковый номер объявления для пользователя. -
activation_date— Дата размещения объявления. -
user_type— Тип пользователя. -
изображение— Идентификационный код изображения. Привязывается к jpg-файлу в train_jpg. Не каждое объявление имеет изображение. -
image_top_1— Классификационный код изображения на Авито. -
Deal_Probability— Целевая переменная. Это вероятность того, что реклама действительно что-то продала. Невозможно точно проверить каждую транзакцию, поэтому значение этого столбца может быть любым числом с плавающей запятой от нуля до единицы.
4.
 Простой исследовательский анализ данных.
Простой исследовательский анализ данных.Давайте изучим данные, проанализировав их.
4.1. Изучение отсутствующих значений данных.
Давайте проверим процент отсутствующих точек данных, присутствующих в нашем наборе данных для обучения и тестирования.
Наблюдения :
Существует много NA для необязательных параметров — пользователи обычно игнорируют ввод необязательных параметров. Изображение — NA означает отсутствие изображения для объявления, как описано в разделе данных, который — «Не в каждом объявлении есть изображение». Цена — какой-то пользователь не ввел цену.
4.2 Анализ вероятности сделки
Диаграмма рассеяния для распределения вероятности сделки Около 65% (1000000/1503424 = 0,66) объявлений имеют нулевую вероятность сделки. Ясно, что около 100 тыс. объявлений ничего не продали. Немногие объявления имеют вероятность 1, а остальные находятся в диапазоне от 0 до 1. Объявления
Объявления
В раздачах по регионам с рекламой видно, что в одних регионах рекламы больше, чем в других, возможно, эти города популярны в России.
Блочная диаграмма вероятности сделки относительно регионыПриведенная выше диаграмма показывает, что некоторые регионы имеют незначительные преимущества по показателю вероятности.
4.4 Распределение рекламы по городам:
Топ 25 городов по распространению рекламы, лучшие города – хорошие города России.
Топ-25 городов Распространение рекламы4,5 Распределение рекламы по названию родительской категории
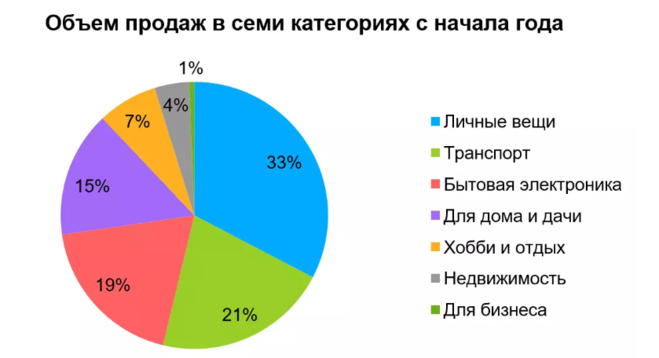
Распределение рекламы по названию родительской категорииРодительская категория «Личные вещи» преобладает в наборе данных.
Блок-диаграмма вероятности сделки относительно названия родительской категорииУ родительской категории «Услуги» вероятность сделки выше, чем у других.
4.6. Название категории Разумное распределение рекламы
Распределение рекламы по названию категории Распределение рекламы ясно показывает преобладание двух категорий над другой категорией.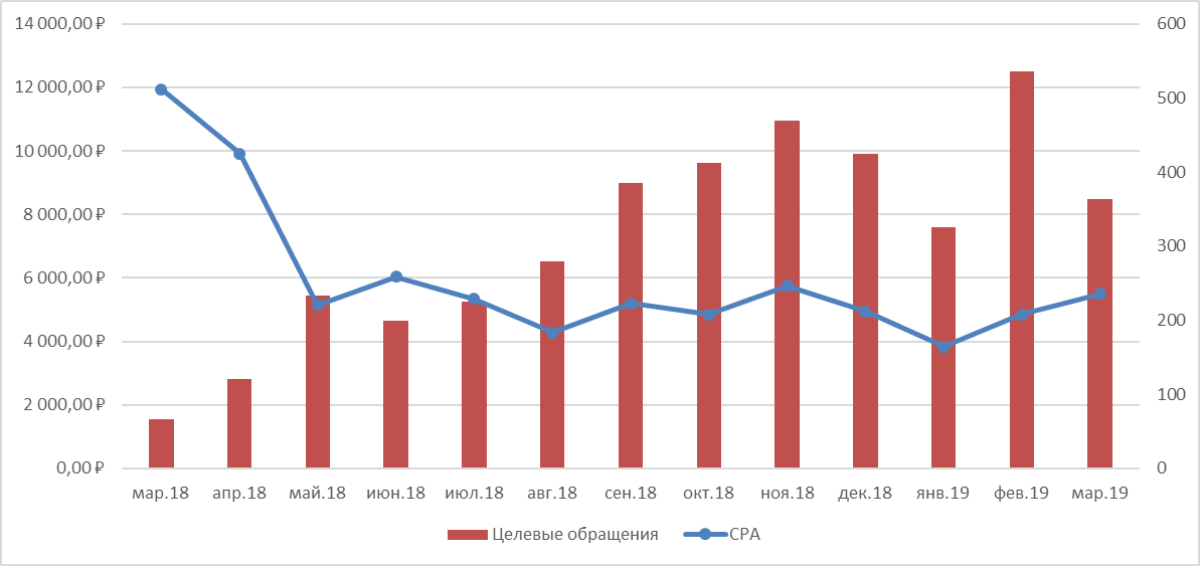 Эти категории: одежда, обувь, аксессуары, детская одежда и обувь.
Эти категории: одежда, обувь, аксессуары, детская одежда и обувь.
Блочная диаграмма показывает, что некоторые категории имеют большую вероятность сделки, чем другие.
4.7 Тип пользователя Разумное распространение рекламы:
Распределение рекламы по типу пользователяСуществует только три типа и набор данных с более частным пользователем, за которым следует компания и магазин.
Box График вероятности сделки по типу пользователяВероятность сделки с частным пользователем лучше всех.
4.8 Распределение цен на рекламу.
График распределения цен на бревнаЖурнал цен показывает не полностью гауссовское распределение. Когда мы делаем логарифм цен, мы можем проанализировать, что его максимальное значение лежит в диапазоне от 5 до 15.
4.9. Длина слова в заголовке объявления:
Длина слова распределение заголовка Максимальное количество слов в заголовке от 1 до 6.
4.10. Анализ дат активации:
Даты различаются для обучающих и тестовых наборов. В данном наборе данных есть данные для обучения с 15 по 28 марта и для тестирования с 12 по 18 апреля 2017 года. Между данными для обучения и тестирования имеется разрыв в две недели.
5. Предварительная обработка данных
Предварительная обработка данных для любого набора данных — довольно сложная задача, потому что вы хотите обработать отсутствующее значение и очистить данные для подачи в модель машинного обучения. Если мы вводим значения NaN, мы должны позаботиться о связи между отсутствующими значениями и нашей целевой переменной, которая здесь является вероятностью сделки.
5.1 Обработка отсутствующих значений
Цена: Для цены отсутствует 85632 значения, что составляет примерно 5,6 % в сравнении. Я использовал здравый смысл и подход, чтобы заменить это значение этими отсутствующими значениями со средним значением его категории.
Изображение: Для изображений, отсутствующих в наборе данных, изначально я думал просто ничего не вменять, но я руководствуюсь здравым смыслом и вменяю изображение в отношении режима этого конкретного изображения родительской категории.
Для остальных функций , поскольку пропущенных значений много, я заменяю значения NaN строкой «отсутствует», чтобы это было действием в качестве новой категории.
5.2. Очистка текста:
Очистка текста и описания путем понижения текста и знаков препинания.
5.3. Изображения в массив:
Я преобразовал изображения в массив с помощью cv2, а затем изменил его размер до 128 x 128, поскольку у меня не так много памяти, чтобы справиться с этой проблемой, я сохраняю размерность низкой.
6. Разработка функций:
Создание новых функций может оказаться сложной задачей. Лучший способ получить фору в этом — погрузиться в предметную область и поискать исследовательские работы, блоги, статьи и т. д. Ядра Kaggle в связанных доменах также являются хорошим способом найти информацию об интересных функциях.
д. Ядра Kaggle в связанных доменах также являются хорошим способом найти информацию об интересных функциях.
Мы реализовали несколько простых и проверили работоспособность модели.
Вот краткий обзор функций:
6.1. По регионам Минимальные, максимальные, средние и медианные цены:
Агрегация цен по регионам.
6.2. По городу Минимальные, максимальные, средние и медианные цены:
Агрегация цен по городу
6.3. Название родительской категории Мин., макс., среднее и медианное цены: Агрегация цен, группирующих родительскую категорию.
6.4. Название категории Мин., Макс., Среднее и Медиана Цены:
Агрегация групп цен Название категории.
6.5. Регион и город Минимальные, максимальные, средние и медианные цены:
Агрегация цен по регионам и городам.
6.6. Тип пользователя и родительская категория с учетом минимальных, максимальных, средних и медианных цен: Агрегация цен, группирующих тип пользователя и имя родительской категории.
6.7. Тип пользователя и название категории с учетом Мин., Макс., Среднее и Медиана Цены: Агрегация цен по типу пользователя и названию категории.
6.8. Длина слов в заголовке и описании.
6.9. В заголовке и описании учитываются специальные символы, такие как ↓, ✔, ❀, ஜ, ! и т.д.
6.9. Предварительно обученные векторы слов FastText встраиваются в заголовок.
6.10. Встраивание предварительно обученных векторов слов FastText для описания.
6.11. Категориальная характеристика :
Я решил использовать слой встраивания в глубокой нейронной сети. Поэтому я создаю пользовательскую функцию с токенизатором Keras для кодирования всех категориальных функций. Категориальные функции включают user_type, город, регион, parent_category_name, category_name, param_1, param_2, param_3, image_top_1.
- Примечание:
В части развертывания я собираюсь отказаться от функции агрегирования, причина в том, что мои тестовые данные также имеют распределение, благодаря которому мы можем агрегировать функции и наши значения. Но для развертывания я собираюсь вставить одну точку данных в свою модель, чтобы агрегация невозможна. Даже здесь, если мы возьмем реальный сценарий, если мы предопределили наши значения агрегации здесь, мы можем иметь или не иметь новое категориальное значение. Вот почему я подумал зайти сюда.
Но для развертывания я собираюсь вставить одну точку данных в свою модель, чтобы агрегация невозможна. Даже здесь, если мы возьмем реальный сценарий, если мы предопределили наши значения агрегации здесь, мы можем иметь или не иметь новое категориальное значение. Вот почему я подумал зайти сюда.
7. Изучение наших моделей машинного обучения:
Для построения моей первой базовой модели я использовал различные подходы высшего ранга, и общим в их подходах является то, что большинство из них использует методы Boosting Ensemble. Они собрали различные ансамбли, некоторые из них рассчитаны даже на 30 базовых моделей. А вот обладатель первого ранга делится своими подходами к глубокому обучению, что весьма интересно и вдохновляюще. Поэтому я решил двигаться вперед с подходом глубокого обучения, поскольку моя основная цель не в том, чтобы победить тройку лучших в Kaggle, я подхожу к этой проблеме как к реальному бизнес-решению.
7.1. Первая базовая модель:
Итак, в моей первой базовой модели я использовал LSTM для обеих своих текстовых функций: заголовка и описания. Здесь используется слой встраивания и инициализируется предварительно обученными весами из русского языка FastText. Категориальная и другая инженерная функция отправляется на какой-то плотный слой, затем все объединяется и переходит на несколько плотных слоев.
Здесь используется слой встраивания и инициализируется предварительно обученными весами из русского языка FastText. Категориальная и другая инженерная функция отправляется на какой-то плотный слой, затем все объединяется и переходит на несколько плотных слоев.
Все функции активации здесь «RELU», а веса инициализируются с помощью He_Normal(). Используемый здесь LSTM также имеет recurrent_dropout, который равен 0,3. Здесь наша модель кажется немного подогнанной, я не сильно регулировал только один пакетную нормализацию и один слой отсева. Поскольку это наш первый подход к сокращению, наша модель выполняет достойную роль с частной оценкой 0,24619.и публичный балл 0,24175.
Первая базовая модель Поток7.2 Добавление GRU и встраивание в базовую модель:
Как мы видели, мы получили приличный результат для начала, я начал с LSTM для текстовых данных. Одна вещь, которую я заметил, это то, что потери не уменьшаются при 0,23, поскольку они могут найти свои глобальные минимумы. Поэтому я попытался сначала изменить LSTM на GRU и повторно запустить обучение, это помогает нашей модели уменьшить потери с 0,23 до 0,227. Итак, я продолжал импровизировать модель, добавляя слой внедрения к каждому из категориальных данных, поскольку категориальные данные здесь очень важны.
Поэтому я попытался сначала изменить LSTM на GRU и повторно запустить обучение, это помогает нашей модели уменьшить потери с 0,23 до 0,227. Итак, я продолжал импровизировать модель, добавляя слой внедрения к каждому из категориальных данных, поскольку категориальные данные здесь очень важны.
Эта модель вдохновлена танцем первого победителя с ансамблями. Ключевое отличие от моей предыдущей модели заключается в том, что я никогда не добавлял изображения в свою модель, в этой модели я экспериментировал с VGG16, Inception и InceptionResNetV2 для трансферного обучения, в котором InceptionResnetV2 работает лучше, чем VGG16 и Inception. После вывода базового уровня из InceptionResNetV2 я экспериментировал со слоем свертки, затем с максимальным пулом, а затем с плотным слоем, что повышает производительность модели трансферного обучения.
Я использовал однослойный GRU для текстовой функции и пытался сделать мою модель слабой, так как иногда модель получает переобучение. За всеми плотными слоями последовали пакетная нормализация и выпадение, чтобы упорядочить мою модель.
За всеми плотными слоями последовали пакетная нормализация и выпадение, чтобы упорядочить мою модель.
Эта модель лучше, чем две предыдущие модели. Вот одна вещь, которой я хочу поделиться со всеми вами, это то, что, поскольку этот набор данных большой, у меня нет таких ресурсов, чтобы работать со всеми наборами данных вместе с изображениями. Итак, здесь я экспериментировал только с 50 тысячами точек данных, исходный набор данных содержит 1,5 миллиона точек данных. Недостаток использования меньшего количества точек данных приводит к переобучению модели, я пробовал несколько способов упорядочить модель, но ничего не работает. Вышеупомянутые две модели, которые были обучены с полным набором данных, идеально подходят для моего набора данных перекрестной проверки. Модель не может изучить все распределение.
Очки за отправку Kaggle:
9. Развертывание на виртуальной машине:
Я использовал потоковый API с открытым исходным кодом для развертывания моей модели на моей локальной машине, вы должны написать все коды на python Без HTML, CSS или JavaScript , это весело па! Вы можете проверить видео ниже.
10. Резюме и будущие аспекты:
Этот проект довольно интересный, все типы данных для решения проблемы. Подводя итог этому проекту, мы построили хорошую модель с самого начала. Первая модель способна дать правильное направление для движения вперед. Дальнейшее использование слоя GRU и Embedding увеличивает производительность модели. После этого изображение дает более важную информацию о нашей модели, которая помогает достичь хорошего результата. Я обучил модель до 75000 точек данных вместе с изображениями, в будущем я попытаюсь обучить свою модель целыми точками данных.
Все коды доступны в моем профиле Github. Вы можете получить к ним доступ, нажав здесь.
Если вам нравится этот блог, не стесняйтесь спрашивать или предлагать мне что-либо через LinkedIn. Пожалуйста, подключите меня на Linkedin!
Спасибо, что читаете мой блог!! Желаю отличного дня. 🙂
Референции:
- Решение 1-го места: «Танец с ансамблем»
- Блог Кун-Сян — решение 18-го ранга.

- 3. Блог Сешин Ли:
- 13-е место — Webber
- 3-е место — Team SuperAnova .
- Решение 4-го места — Team Wave на дистанции вверху.
- Особая благодарность Applied Roots и их наставникам.
Категории | Мостафа Эль-Араби
Проекты
Avito Прогноз спроса Kaggle конкурс
Соревнования, Проекты ·Проверьте код github
Avito запустила конкурс на Kaggle, предлагая пользователям предсказать Avito, чтобы предсказать спрос на онлайн-рекламу на основе ее полного описания (заголовок, описание, изображения и т. д.), ее контекста (географическое место размещения, уже размещенные похожие объявления) и исторический спрос на подобную рекламу в.
 ..
..Многоязычная платформа Bot Framework V4
Проекты ·Проверьте код github
Во время моей работы в Microsoft Research Lab в Каире мне посчастливилось работать над проектом фреймворка бота для поддержки нескольких языков.
Обучение распознаванию речи с помощью речевых команд Tf
Соревнования, Проекты ·Проверьте код github
В конце 2017 года Google запустила конкурс на Kaggle, используя свою команду Speech для набора данных. В этом соревновании перед нами стояла задача предсказать простые команды по вводимой пользователем голосовой команде.
 Каждое высказывание длится около 2 секунд.
Каждое высказывание длится около 2 секунд.Этот конкурс привлек меня, чтобы получить больше опыта…
Библиотека создания моделей
Проекты ·Проверьте код github
Во время моей работы в Valeo из-за важного запроса на проект я смог получить больше опыта как в MATLAB (ранее использовавшемся в предыдущем проекте компьютерного зрения), так и в моделях Simulink.
Классификация действий по неподвижным изображениям
Проекты ·В качестве заключительного проекта курса компьютерного зрения в моем колледже с профессором Марваном Торки мы использовали классификацию действий Pascal Voc 2010.
 Этот проект побудил меня узнать больше о машинном обучении и компьютерном зрении в частности. С тех пор как этот проект машинное обучение стало для меня хобби, а платформа Kaggle облегчила мне жизнь в изучении новых техник…
Этот проект побудил меня узнать больше о машинном обучении и компьютерном зрении в частности. С тех пор как этот проект машинное обучение стало для меня хобби, а платформа Kaggle облегчила мне жизнь в изучении новых техник…Разработка Windows Phone
Проекты ·На втором курсе Александрийского университета меня привлекла область разработки мобильных приложений. В то время я обнаружил, что Microsoft Windows Phone 7.1 SDK подходит для начала мобильной разработки на C# на новой многообещающей мобильной платформе.
Веб-сайт Allemny Initiative
Проекты ·Allemny — это арабское слово, которое означает «научи меня». Эта инициатива в основном направлена на поощрение самообучения и обновление методов обучения с использованием новых тактик обучения, чтобы справиться с современными технологиями. Мы создаем короткие видеоролики, которые простым способом объясняют инженерные темы и программное обеспечение, чтобы каждый мог понять наши данные.
В этом проекте…
Соревнования
Avito Прогноз спроса Kaggle конкурс
Соревнования, Проекты ·Проверьте код github
Avito запустила конкурс на Kaggle, предлагая пользователям предсказать Avito, чтобы предсказать спрос на онлайн-рекламу на основе ее полного описания (заголовок, описание, изображения и т.
AI Challenger англо-китайский машинный перевод
Соревнования ·Ai Challenger, новая китайская платформа для задач ИИ, их первый конкурс был связан с системой машинного перевода, и я хотел попробовать свои методы в системах NMT в системе, в которой я понятия не имею о целевом китайском языке.
В этом конкурсе я участвовал как Марб и получил 25,50 блю баллов за их тест Тестовый набор…
Обучение распознаванию речи с помощью речевых команд Tf
Соревнования, Проекты ·Проверьте код github
В конце 2017 года Google запустила конкурс на Kaggle, используя свою команду Speech для набора данных. В этом соревновании перед нами стояла задача предсказать простые команды по вводимой пользователем голосовой команде. Каждое высказывание длится около 2 секунд.
Этот конкурс привлек меня, чтобы получить больше опыта…
Система бронирования зданий
Соревнования ·Летом 2013 года инженерный факультет Александрийского университета объявил конкурс на создание системы онлайн-бронирования номеров с автоматическим заполнением номеров на основе имеющихся курсов, а также их вместимости и необходимого оборудования в помещении, я выиграл первый приз этого конкурса и мой система развернута по адресу http://eng.
 staff.alexu.edu.eg/~m.elaraby/
staff.alexu.edu.eg/~m.elaraby/Участие в ACM Sigmod 2013 EGN Team
Соревнования ·ACM Sigmod Programming Contest — это соревнование по программированию, запущенное в 2013 году, в основном направленное на реализацию программы, используемой для сопоставления больших документов, проиндексированных инструментом во время выполнения.
Это был мой первый всемирный онлайн-соревнование, и это был захватывающий опыт для меня и моих коллег из команды EGN.
Опыт
Работа в Раисе
Опыт ·Мне удалось получить предложение от Raisa Egypt, стартапа, специализирующегося на прогнозировании нефти и газа по геологическим особенностям суши.

Работа в Microsoft Research Lab
Опыт ·Я всегда хотел работать в области машинного обучения, и во время работы в Valeo я участвовал в kaggle в учебных целях. Переход в Microsoft Lab помог мне получить больше промышленного и исследовательского опыта в этой области.
Работа в Valeo
Опыт ·После окончания инженерного факультета Александрийского университета мне посчастливилось получить рекомендацию в компании Valeo Automotive, за 2 года и 3 месяца в Valeo я приобрел обширные знания в области разработки программного обеспечения.

Стажировка в Бкаме в качестве инженера-программиста
Опыт ·Bkam был быстрорастущим стартапом, специализирующимся на онлайн-сравнении цен на товары, доступные в Интернете и на месте, в нескольких магазинах и предоставлении вам ссылки на магазин с лучшей ценой для определенного товара.
На втором курсе мне посчастливилось получить рекомендацию от моего ассистента Ахмеда ЭльШаркаси присоединиться к ним.
Публикации
Идентификация критических нейронов в архитектурах ANN с использованием смешанного целочисленного программирования
Публикации ·Скачать статью
Проверить код
В этом исследовании мы пытаемся понять архитектуру нейронной модели, вычисляя показатель важности для нейронов. Вычисленный показатель важности можно использовать для сокращения модели или для понимания того, какие функции более значимы для обученной ИНС (искусственной нейронной сети). Рейтинг важности…
Перевод разговорного языка с учетом гендерных аспектов с арабского на английский
Публикации ·Скачать статью
Во время моей работы в Microsoft Research Lab в Каире мы проводили мозговой штурм для исследовательских проектов, связанных с нашей работой Skype Translator для предстоящей летней стажировки. Мне пришла в голову идея создать систему машинного перевода, которая сохраняет потерянную гендерную информацию при переводе с арабского Английский.

Синтетические разговорные данные для нейронного машинного перевода
Публикации ·Скачать статью
Во время моей работы в Microsoft Research Lab в Каире моей первой задачей было преобразовать диалект левантийского арабского языка в английскую систему NMT, но параллельных данных, доступных для диалектического левантийского языка, было недостаточно для обучения приличной модели для переводчика Skype.
Учебники
Введение в смешанное целочисленное программирование
Учебники ·Смешанно-целочисленное программирование используется для решения задач оптимизации с дискретными переменными решения.
 Следовательно, его допустимая область представляет собой набор несвязанных целочисленных точек, и алгоритмы, основанные на градиенте, не могут быть применены напрямую.
Следовательно, его допустимая область представляет собой набор несвязанных целочисленных точек, и алгоритмы, основанные на градиенте, не могут быть применены напрямую.Обучение модели Attentional LSTM
Учебники ·
Обзор бумаги
Прогнозирование точности нейронной сети по весам
Обзор статьи ·Проверьте код github
В этой статье Unterthiner et al. (2020) эмпирически показали, что мы можем предсказать разрыв в обобщении нейронной сети, только взглянув на ее веса.
 В этой работе они выпустили набор данных из 120 тысяч сверточных нейронных сетей, обученных на разных наборах данных.
В этой работе они выпустили набор данных из 120 тысяч сверточных нейронных сетей, обученных на разных наборах данных.…
Прогнозирование разрыва обобщения в глубоких сетях с распределением маржи
Обзор статьи ·Проверьте код github
В этой статье (Jiang et al. (2018)) они обсуждают метод, который может предсказать разрыв в обобщении на основе обученных глубоких нейронных сетей. Авторы использовали информацию о предельном распределении из входного обучающего набора в качестве вектора признаков, используемого оценщиком для получения…
Объяснение добавления нескольких задач PackNet в единую сеть путем итеративного сокращения
Обзор статьи ·Проверьте код github
В этой статье (Mallya & Lazebnik, 2018) они обсуждают метод добавления и поддержки нескольких задач в одной архитектуре, не беспокоясь о катастрофическом забывании. В этой статье они показывают, что три задачи мелкозернистой классификации могут быть добавлены к одной…
Стабилизация обучения GAN со случайными проекциями
Обзор статьи ·Проверьте код github
В этой статье (Neyshabur et al. (2017)) они представили структуру для стабилизации обучения GAN с использованием нескольких проекций с фиксированными фильтрами каждого входного изображения на другой дискриминатор. Обучение моделей GAN нестабильно в многомерном пространстве и некоторые проблемы, которые могут.


Об авторе