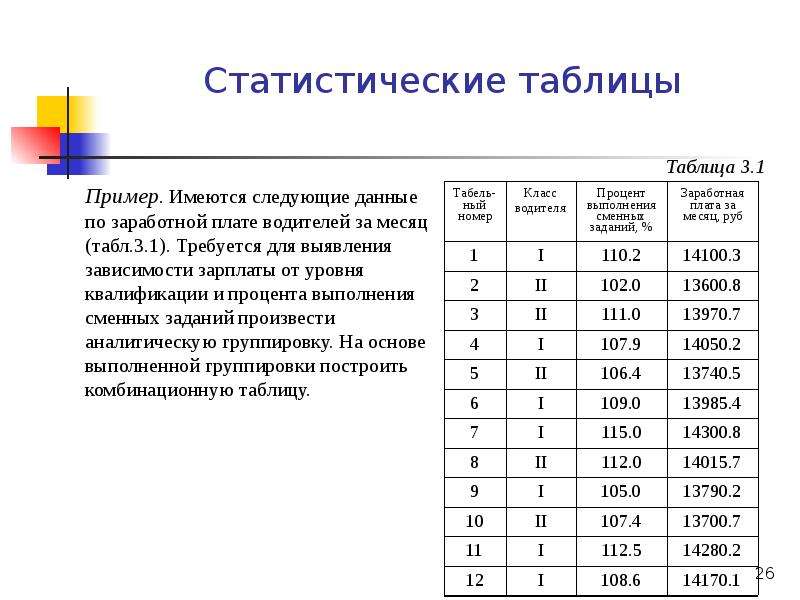
Статистический код: статистический код — это… Что такое статистический код?
ОКОГУ по ИНН | Как узнать ОКОГУ для ООО и ИП по ИНН онлайн? — Контур.Бухгалтерия
Для систематизации и учета информации о хозяйствующих субъектах государство сформировало классификаторы. Они упрощают обработку данных, присваивая коды предприятиям. Один из классификаторов — ОКОГУ. В статье расскажем, что такое ОКОГУ, для чего он нужен, и как его получить.
Что такое ОКОГУ
ОКОГУ — это общероссийский классификатор органов государственной власти и управления. Классификатор включает коды всех органов госвласти. Коды ОКОГУ нужны для идентификации государственных органов, но это не значит, что ИП и юрлица не могут его получить. Они присваиваются организациям, по которым ведется статистическое наблюдение. ОКОГУ присваивается:
- федеральным госорганам;
- муниципальным органам;
- органам самоуправления на местах и избирательным комиссиям;
- субъектам хозяйствования, которые являются объектами статистического наблюдения;
- межгосударственным органам управления.

Зачем нужен ОКОГУ
На государственном уровне органы власти — такие же субъекты, как и организации, и их тоже нужно контролировать. Классификатор ОКОГУ помогает упорядочить и систематизировать информацию об органах управления и упрощает понимание подчиненности и ответственности властных структур.
Как и другие организации, зарегистрированные в налоговой, органы власти включаются в единый госреестр. С помощью ОКОГУ их легко идентифицировать и проще вести статистический учет.
Структура ОКОГУ
Структура классификатора имеет иерархический характер, то есть отражает порядок подчинения органов управления. Подчиненность определяется на основании Конституции, федеральных законов и Указа Президента «О структуре органов исполнительной власти». Код включает 7 знаков, первый из них зависит от объекта кодирования. Выделяют 5 групп объектов:
Органы госвласти:
- Президент, законодательная, исполнительная и судебная власть РФ.
 Другие федеральные органы и Центробанк.
Другие федеральные органы и Центробанк. - Органы госвласти регионов.
- Органы местного самоуправления.
- Предприятия и организации, по которым ведется статистическое наблюдение (банки, академии, фонды, госкорпорации). Группировки хозсубъектов и общественных объединений, необходимые для статистического учета.
- Межгосударственные органы управления.
Для нас интересны коды из 4 группы, а именно группировки хозсубъектов. Большинству организаций присваивается код 4210014, ИП — 4210015. Росстат отвечает за ведение и разработку изменения для ОКОГУ. Все проекты изменений, предварительно вносятся на рассмотрение в Росстандарт.
Как узнать свой ОКОГУ для ООО и ИП
Коды статистики нужны при внесении изменений в учредительные документы, смене руководителя, открытии филиала или по запросу требовательных контрагентов. Также уведомления с кодами из Росстата нужны для получения допусков и разрешений.
Статистические коды должны выдаваться в форме письменного уведомления при регистрации предприятия. Однако ИП на практике почти никогда их не получают. В число кодов статистики входят коды ОКПО, ОГРН, ОКТМО, ОКФС, ОКОПФ, ОКАТО и, конечно, ОКОГУ. Узнать свои коды статистики можно в территориальном отделении налоговой службы или управлении Росстата, оставив официальный запрос. Ответ на запрос дадут в течение 5 дней.
Однако ИП на практике почти никогда их не получают. В число кодов статистики входят коды ОКПО, ОГРН, ОКТМО, ОКФС, ОКОПФ, ОКАТО и, конечно, ОКОГУ. Узнать свои коды статистики можно в территориальном отделении налоговой службы или управлении Росстата, оставив официальный запрос. Ответ на запрос дадут в течение 5 дней.
Для получения кодов нужно представить паспорт, доверенность, копию устава, свидетельство о госрегистрации и выписку из государственного реестра. При первом обращении уведомление выдается бесплатно, обращаясь повторно, придется заплатить. Юридические компании тоже оказывают услуги по предоставлению кодов статистики. Они берут на себя подачу заявления, получение уведомления и передачу его ИП. За услугу берется небольшая плата, она подходит для занятых предпринимателей, так как все выполняется без вашего присутствия.
Как узнать код ОКОГУ по ИНН онлайн
Есть возможность получить коды статистики абсолютно бесплатно и в кратчайшие сроки, воспользовавшись интернетом. Всегда обращайте внимание на надежность информационного ресурса. Рекомендуется пользоваться официальными сайтами госорганов. Все органы власти имеют сайты, которые оснащены базами данных.
Всегда обращайте внимание на надежность информационного ресурса. Рекомендуется пользоваться официальными сайтами госорганов. Все органы власти имеют сайты, которые оснащены базами данных.
Получить код ОКОГУ по ИНН можно на официальном сайте Росстата по следующему адресу http://statreg.gks.ru/. Для получения информации нужно ввести один из известных реквизитов: ИНН, ОГРН или ОКПО — и ввести контрольный код. Регистрация не требуется. В результате будет сформировано уведомление, содержащее коды статистики, такое же выдается при регистрации.
Имейте в виду, что полученные онлайн уведомления не имеют печати и подписи и носят справочный характер.
Автор статьи: Елизавета Кобрина.
Веб-сервис для малого бизнеса Контур.Бухгалтерия поможет отправлять статистические отчеты и безопасно вести бизнес. Первые 14 дней работы в сервисе — бесплатны. Вы можете вести учет, отправлять отчетность, начислять зарплату и получать консультации наших экспертов.
Классификация товаров определение кода ТН ВЭД
Согласно статье 20 Таможенного кодекса ЕАЭС товары подлежат классификации при таможенном декларировании. Из этого следует, что обязанность по определению кода ТН ВЭД на уровне всех десяти знаков возлагается на декларанта (то есть импортера или экспортера).
При этом таможенные органы зачастую не соглашаются с кодом, выбранным декларантом, и принимают свое решение по классификации. Это объясняется сложностью классификационных вопросов, отсутствием четкого, всеобъемлющего справочника, который мог бы предусмотреть все случаи классификации существующих товаров во всем их многообразии.
Кроме того, важно учитывать, что от классификации товаров зависит ставка таможенной пошлины и перечень разрешительных документов, которые необходимо представлять в таможенный орган (сертификаты соответствия, лицензии и т.п.).
Это также является одной из причин частого несогласия таможни с декларируемым кодом.
В случае вышеуказанного несогласия, как правило, происходит доначисление таможенных платежей, а в ряде случаев и возбуждение дела об административном правонарушении по части 2 статьи 16.2 КоАП РФ «недостоверное декларирование» (штраф в размере от одной второй до двукратной суммы неуплаченных таможенных платежей с возможной конфискацией товара).
Чтобы помочь Вам избежать вышеуказанных неблагоприятных последствий, мы готовы оказать Вам услуги по получению предварительного классификационного решения в отношении ввозимого (вывозимого) Вами товара.
Мы можем также предложить Вам практическое содействие в сложных случаях классификации товара и оказать консультационные услуги.
Наконец, если таможенный орган уже классифицировал Ваш товар по неприемлемой для Вас или необоснованной товарной позиции (коду) ТН ВЭД ЕАЭС, мы готовы оказать Вам юридическую помощь по обжалованию данного решения.
Поиск по базе ТН ВЭД ЕАЭС
Вы можете осуществить поиск товара в ТН ВЭД или статистике декларирования за последние годы по описанию или коду товара:
Сама товарная номенклатура с информацией о пошлинах, налогах и разрешительных документах, доступна по следующей ссылке: ТН ВЭД ЕАЭС.
Полезная информация
Предлагаем для Вашего сведения следующую информацию:
Базы данных и справочники
FAO Рыбные промыслы и аквакультура Перечень видов ASFIS для целей статистики рыбного хозяйства, Overview
База данныхЗагрузить перечень
- Загрузить версию за февраль 2020 года ASFIS_sp.zip file (1600 Кб), включающую также версию перечня ASFIS с названиями на арабском, китайском и русском языках
- Выбрать опцию «Сохранить на диск»
- Разархивируйте файлы с помощью WINZIP и сохраните их в отдельную директорию на своём жёстком диске
- Файл ASFIS_sp_2020.txt можно легко импортировать в программу, работающую с электронными таблицами или базами данных
- Файл имеет разграниченный формат: клавиша запятая «,» является разделителем столбцов, ограничителем текста – знак » (UTF-8)
- В первой строке приводятся названия полей, записи отсортированы по классификационному коду
- Поиск данных можно также осуществлять онлайн по базе данных водных видов, созданной терминологами Группы лингвистического обеспечения Службы программирования заседаний и документации (CSCM).

Введение
Каждой видовой позиции присваивается три вида кодов:Код ISSCAAP присваивается в соответствии с Международной стандартной статистической классификацией животного и растительного мира водной среды (ISSCAAP), разделяющей промысловые виды на 50 групп в зависимости от их классификационных, экологических и экономических характеристик. Классификационный код используется ФАО в целях более подробной классификации видовых позиций и для их сортировки в рамках каждой группы ISSCAAP. Трехзначный альфа-код представляет собой уникальный код из трёх букв, широко используемый для обмена данным с национальными корреспондентами и между рыбохозяйственными организациями.По получении впервые статистики производства по видовой позиции Служба статистики и информации до её внесения в статистические базы данных должна была присвоить ей новые коды. Более того, Служба статистики и информации зачастую получает запросы от национальных органов и рыбохозяйственных организаций о предоставлении трёхзначных альфа-кодов для видов, представляющих местный интерес.
 С целью содействия этим процессам классификационные коды и трёхзначные альфа-коды присваивались более широкому спектру видов. С 2000 года перечень ASFIS доступен в интернете для предоставления внешним пользователям стандартизированной системы кодификации, покрывающей большинство видовых позиций, имеющих отношение к рыбному хозяйству.
С целью содействия этим процессам классификационные коды и трёхзначные альфа-коды присваивались более широкому спектру видов. С 2000 года перечень ASFIS доступен в интернете для предоставления внешним пользователям стандартизированной системы кодификации, покрывающей большинство видовых позиций, имеющих отношение к рыбному хозяйству.Перечень видов ASFIS, опубликованный в печатном виде в 2002 году, можно получить бесплатно (см. Контакты). Загрузить вступительную часть и приложения.
Характеристика перечня
Перечень является частью справочных материалов ASFIS, включающих, в том числе Реферативный бюллетень по акватическим наукам и рыболовству (ASFA).В настоящее время перечень видов ASFIS включает 12 871 видовых позиций. Так как существует более 17500 возможных комбинаций 26 букв английского алфавита, сочетающихся в трёхбуквенном альфа-коде, база данных может продолжать расширяться с использованием этой же системы кодификации. Создавать или изменять коды может только администратор перечня, т.
 е. Служба статистики и информации ФАО.
е. Служба статистики и информации ФАО.Для каждой регистрируемой видовой позиции указываются коды ISSCAAP, классификационный код, трехбуквенный альфа-код, научное название, классификационная информация на уровне семейства и на более высоком классификационном уровне. У порядка 75% записей имеется название на английском языке, у 44% на французском языке и 37% на испанском языке. Считается, что официальные названия ФАО имеют только видовые позиции, по которым имеется статистика производства. Имеется также информация о наличии статистики в базах данных ФАО по производству данного вида в рыбном хозяйстве.
С учётом рекомендации 19-й сессии Координационной рабочей группы по статистике рыбного хозяйства (Нумеа, Нов. Каледония, 10-13 июля 2001 года) были пересмотрены названия и состав бывших групп 33, 34 и 37 ISSCAAP. Видовые позиции бывшей группы 33 «Большеголовые окуни, каменные окуни, морские угри» были классифицированы как прибрежные или придонные рыбы и, соответственно, причислены к новым группам 33 «Различные прибрежные рыбы» и 34 «Различные придонные рыбы».
 Виды, ранее входившие в группу 34 «Ставридовые, кефалевые, скумбрещуковые» были перемещены в группу 37, переименованную «Различные пелагические рыбы». Более подробную информацию см. в докладе ФАО по группам ISSCAAP (с. 42-49), представленному 19-й сессии Координационной рабочей группы по статистике рыбного хозяйства, и новую редакцию ISSCAAP, одобренную этой Группой (с.23 доклада Группы).
Виды, ранее входившие в группу 34 «Ставридовые, кефалевые, скумбрещуковые» были перемещены в группу 37, переименованную «Различные пелагические рыбы». Более подробную информацию см. в докладе ФАО по группам ISSCAAP (с. 42-49), представленному 19-й сессии Координационной рабочей группы по статистике рыбного хозяйства, и новую редакцию ISSCAAP, одобренную этой Группой (с.23 доклада Группы).Принятые критерии
В перечень было включено 12 871 видовых позиций, представляющих интерес или имеющих отношение к рыбному хозяйству и аквакультуре. Для обеспечения использования правильных научных названий и классификации видов производилась сверка с новейшими поправками к классификации. Это позволило выявить ряд устаревших научных названий и классификационных кодов, использовавшихся в базах данных ФАО по статистике рыбного хозяйства. Вместе с тем, данный перечень, очевидно, не является ориентиром в плане классификации, и для ориентировки по спорным вопросам следует сверяться со специализированными источниками.
В данном случае к спорным вопросам, касающимся научных названий и названий, принятых в ФАО, применялся прагматический подход. Изменение научных названий и введение новых видов, предлагаемых систематиками в научной литературе, будет включаться в перечень ASFIS только в случае, когда такие изменения были признаны большинством систематиков и вошли в обиход работников сферы рыбного хозяйства, в особенности в области статистики рыбного хозяйства. В наиболее спорных случаях для проверки того, прижился ли в обиходе новый научный термин, использовался Реферативный бюллетень по водным наукам и рыболовству.
В ряде случаев классификационные коды не изменялись, как это следовало бы сделать, исходя из последних поправок к классификации – когда такие поправки потребовали бы внесения существенных изменений в видовые позиции, по которым ведётся статистика, либо из-за отсутствия свободных знаков классификационного кода. Для некоторых родов, не представляющих существенного интереса для рыбного хозяйства и включающих большое количество видов, для представления рода и включения в список с присвоением классификационного кода выбирался отдельный вид.

Структура базы данных
Основные источники
Виды, имеющие значение для рыбного хозяйства, отбирались главным образом по критериям включения в каталог публикаций ФАО FAO FishFinder – каталоги видов, определители и полевые справочники. База данных FishBase (1998 год) послужила основным источником информации по недавно включенным видам рыб. В отношении рыб так же, как и в FishBase, использовалась классификация высшего уровня Эшмейера (1998 год). В отношении ракообразных использовалась классификация Боумана и Абеля (1982 год), а водорослей – Лунинга, Яриша и Киркмана (1990 год). Для других групп в целях классификации высокого уровня использовался более чем один источник. Краткий перечень ссылок на источники, использованные для составления перечни видов ASFIS, прилагается (библиографические ссылки).| 000000 | Не определён | 0 | 0 |
| 011005 | Пшеница | 2 | г/п |
| 012008 | Рожь | 2 | г/п |
| 013000 | Овес | 2 | 53 |
| 014003 | Ячмень | 2 | г/п |
| 015006 | Зерно кукурузы | 2 | г/п |
| 016009 | Початки кукурузы | 2 | 53 |
| 017001 | Рис | 2 | г/п |
| 017016 | Рис нешелушеный (рис-сырец) | 2 | г/п |
| 017020 | Рис шелушеный (неполированный рис) | 2 | г/п |
| 017035 | Рис прочий | 2 | г/п |
| 018004 | Прочие зерновые | 2 | г/п |
| 018019 | Гречиха | 2 | г/п |
| 018023 | Зерно бобов | 2 | г/п |
| 018038 | Зерно гороха | 2 | г/п |
| 018042 | Зерно фасоли | 2 | г/п |
| 018057 | Зерновые, не поименованные в алфавите | 2 | г/п |
| 018061 | Зерноотходы | 2 | г/п |
| 018076 | Нут | 2 | г/п |
| 018080 | Полба | 2 | г/п |
| 018095 | Просо | 2 | г/п |
| 018108 | Смесь зерновая | 2 | г/п |
| 018112 | Солод в зерне | 2 | г/п |
| 018127 | Сорго (гаолян, джугара и др..jpg) ) ) | 2 | г/п |
| 018131 | Чечевица | 2 | г/п |
| 018146 | Чина | 2 | г/п |
| 018150 | Чумиза | 2 | г/п |
| 021007 | Семена технических культур, кроме семян хлопчатника | 2 | 43 |
| 021011 | Головки маковые с зерном | 2 | 43 |
| 021026 | Зерна пальмовые | 2 | 43 |
| 021030 | Зерно мака | 2 | 43 |
| 021045 | Семена кенафа | 2 | 43 |
| 021054 | Семена конопли | 2 | 43 |
| 021064 | Семена кунжута | 2 | 43 |
| 021079 | Семена льна | 2 | 43 |
| 021083 | Семена масличных культур, не поименованные в алфавите | 2 | 43 |
| 021098 | Семена подсолнечника | 2 | 43 |
| 021100 | Семена сои | 2 | 43 |
| 021115 | Семена фенхеля | 2 | 43 |
| 021120 | Семя кориандровое (кишнец) | 2 | 43 |
| 021134 | Шапки подсолнечника с семенами | 2 | 43 |
| 021149 | Семена клещевины | 2 | 43 |
| 022007 | Семена хлопчатника | 2 | 35 |
| 023002 | Семена свеклы сахарной | 2 | 26 |
| 024005 | Семена прочие | 2 | 29 |
| 024012 | Желуди сушеные и сырые | 2 | 29 |
| 024024 | Семена клевера | 2 | 29 |
| 024039 | Семена кормовых трав, не поименованные в алфавите | 2 | 29 |
| 024043 | Семена лекарственных культур | 2 | 29 |
| 024058 | Семена люпина | 2 | 29 |
| 024062 | Семена люцерны | 2 | 29 |
| 024077 | Семена овощных и бахчевых культур | 2 | 29 |
| 024081 | Семена табака | 2 | 29 |
| 024096 | Семена тимофеевки | 2 | 29 |
| 024109 | Семена тмина | 2 | 29 |
| 024113 | Семена тыквы | 2 | 29 |
| 024128 | Семена цветочных культур | 2 | 29 |
| 024132 | Семена чая | 2 | 29 |
| 024147 | Споры грибов шампиньонов | 2 | 29 |
| 031009 | Хлопок-сырец | 2 | 34 |
| 041000 | Овощи свежие | 2 | 28 |
| 041015 | Артишок свежий | 2 | 28 |
| 041022 | Баклажаны свежие | 2 | 28 |
| 041034 | Бобы овощные свежие | 2 | 28 |
| 041049 | Брюква свежая | 2 | 28 |
| 041053 | Горох овощной свежий | 2 | 28 |
| 041068 | Грибы, в том числе шампиньоны, свежие | 2 | 28 |
| 041072 | Корнеплоды свежие, не поименованные в алфавите | 2 | 28 |
| 041087 | Кабачки свежие | 2 | 28 |
| 041091 | Капуста свежая | 2 | 28 |
| 041104 | Лук зеленый, в том числе порей | 2 | 28 |
| 041119 | Лук репчатый и сеянец | 2 | 28 |
| 041123 | Овощи свежемороженные | 2 | 28 |
| 041138 | Овощи свежие, не поименованные в алфавите | 2 | 28 |
| 041142 | Огурцы свежие | 2 | 28 |
| 041157 | Пастернак свежий | 2 | 28 |
| 041161 | Перец (в стручках) свежий | 2 | 28 |
| 041176 | Петрушка свежая | 2 | 28 |
| 041180 | Морковь свежая | 2 | 28 |
| 041195 | Томаты (помидоры) свежие | 2 | 28 |
| 041208 | Ревень овощной свежий | 2 | 28 |
| 041212 | Редис свежий | 2 | 28 |
| 041227 | Редька свежая | 2 | 28 |
| 041231 | Репа свежая | 2 | 28 |
| 041246 | Салат свежий | 2 | 28 |
| 041250 | Свекла кормовая свежая | 2 | 28 |
| 041265 | Свекла столовая свежая | 2 | 28 |
| 041275 | Сельдерей свежий | 2 | 28 |
| 041284 | Спаржа свежая | 2 | 28 |
| 041299 | Турнепс свежий | 2 | 28 |
| 041301 | Укроп свежий | 2 | 28 |
| 041316 | Фасоль овощная свежая | 2 | 28 |
| 041320 | Хрен свежий | 2 | 28 |
| 041335 | Цикорий свежий | 2 | 28 |
| 041341 | Чеснок свежий | 2 | 28 |
| 041354 | Шпинат свежий | 2 | 28 |
| 041369 | Щавель свежий | 2 | 28 |
| 042003 | Бахчевые культуры | 2 | 25 |
| 042018 | Арбузы свежие | 2 | 25 |
| 042022 | Дыни свежие | 2 | 25 |
| 042037 | Тыква свежая | 2 | 25 |
| 043006 | Картофель свежий | 2 | 51 |
| 043010 | Картофель ранний | 2 | 51 |
| 043025 | Картофель поздний | 2 | 51 |
| 043038 | Картофель семенной | 2 | 51 |
| 044009 | Свекла сахарная | 2 | кр, пв-50, пл-20 |
| 051002 | Фрукты и ягоды свежие, кроме яблок и цитрусовых | 2 | 25 |
| 051017 | Абрикосы свежие | 2 | 25 |
| 051021 | Айва свежая | 2 | 25 |
| 051036 | Алыча свежая | 2 | 25 |
| 051040 | Ананасы свежие | 2 | 25 |
| 051055 | Бананы свежие | 2 | 25 |
| 051061 | Барбарис свежий | 2 | 25 |
| 051074 | Брусника свежая | 2 | 25 |
| 051089 | Брусника свежемороженая | 2 | 25 |
| 051093 | Виноград свежий | 2 | 25 |
| 051106 | Вишни свежие | 2 | 25 |
| 051110 | Гранаты (плоды) | 2 | 25 |
| 051125 | Груши свежие | 2 | 25 |
| 051138 | Земляника свежая | 2 | 25 |
| 051144 | Кизил свежий | 2 | 25 |
| 051159 | Клюква свежая | 2 | 25 |
| 051163 | Клюква свежемороженая | 2 | 25 |
| 051178 | Крыжовник свежий | 2 | 25 |
| 051182 | Малина свежая | 2 | 25 |
| 051197 | Маслины (оливки) свежие | 2 | 25 |
| 051204 | Мушмула свежая | 2 | 25 |
| 051214 | Облепиха свежая | 2 | 25 |
| 051229 | Облепиха свежемороженая | 2 | 25 |
| 051233 | Персики свежие | 2 | 25 |
| 051248 | Рябина (ягоды) свежая | 2 | 25 |
| 051252 | Рябина (ягоды) свежемороженая | 2 | 25 |
| 051267 | Сливы свежие | 2 | 25 |
| 051271 | Смоква (ягоды винные, инжир) свежая | 2 | 25 |
| 051286 | Смородина свежая | 2 | 25 |
| 051290 | Терн (терновник) свежий | 2 | 25 |
| 051303 | Фрукты свежие, не поименованные в алфавите | 2 | 25 |
| 051318 | Фрукты свежемороженые, не поименованные в алфавите | 2 | 25 |
| 051322 | Хурма свежая | 2 | 25 |
| 051337 | Хурма свежемороженая | 2 | 25 |
| 051341 | Черемуха (ягоды) свежая | 2 | 25 |
| 051356 | Черешня свежая | 2 | 25 |
| 051360 | Черника свежая | 2 | 25 |
| 051375 | Ягоды свежие, не поименованные в алфавите | 2 | 25 |
| 051380 | Ягоды свежемороженые, не поименованные в алфавите | 2 | 25 |
| 052005 | Яблоки | 2 | 25 |
| 052014 | Яблоки свежемороженые | 2 | 25 |
| 052024 | Яблоки свежие | 2 | 25 |
| 053008 | Цитрусовые | 2 | 33 |
| 053012 | Апельсины свежие | 2 | 33 |
| 053027 | Грейпфруты свежие | 2 | 33 |
| 053031 | Лимоны свежие | 2 | 33 |
| 053046 | Мандарины свежие | 2 | 33 |
| 053050 | Померанцы свежие | 2 | 33 |
| 053065 | Цитрусовые, не поименованные в алфавите | 2 | 33 |
| 054000 | Орехи | 2 | 35 |
| 054015 | Арахис (земляной орех) | 2 | 35 |
| 054020 | Каштаны | 2 | 35 |
| 054034 | Копра (мякоть кокосового ореха) | 2 | 35 |
| 054049 | Орехи грецкие | 2 | 35 |
| 054053 | Орехи кедровые | 2 | 35 |
| 054068 | Орехи лещинные (фундук) | 2 | 35 |
| 054072 | Орехи миндальные (миндаль) | 2 | 35 |
| 054087 | Орехи, не поименованные в алфавите | 2 | 35 |
| 054091 | Орехи фисташковые (фисташки) | 2 | 35 |
| 054104 | Ядра орехов и фруктовых косточек | 2 | 35 |
| 054119 | Орехи тунговые | 2 | 35 |
| 061004 | Крупный и мелкий рогатый скот | 2 | 10 |
| 061019 | Бараны | 2 | 10 |
| 061023 | Буйволы | 2 | 10 |
| 061038 | Быки | 2 | 10 |
| 061042 | Волы | 2 | 10 |
| 061057 | Козы | 2 | 10 |
| 061061 | Коровы | 2 | 10 |
| 061076 | Овцы | 2 | 10 |
| 061080 | Скот крупный рогатый племенной | 2 | 10 |
| 061095 | Скот крупный рогатый, не поименованный в алфавите | 2 | 10 |
| 061108 | Скот мелкий рогатый племенной | 2 | 10 |
| 061112 | Скот мелкий рогатый, не поименованный в алфавите | 2 | 10 |
| 061127 | Телята | 2 | 10 |
| 061131 | Яки | 2 | 10 |
| 062007 | Свиньи и поросята | 2 | 10 |
| 062011 | Поросята | 2 | 10 |
| 062026 | Свиньи | 2 | 10 |
| 062030 | Свиньи племенные | 2 | 10 |
| 063006 | Животные прочие, птицы живые и пчелы | 2 | 10 |
| 063014 | Верблюды | 2 | 10 |
| 063029 | Грена тутового шелкопряда | 2 | 10 |
| 063033 | Жеребята | 2 | 10 |
| 063048 | Животные дикие (звери), не поименованные в алфавите | 2 | 10 |
| 063052 | Животные домашние, не поименованные в алфавите | 2 | 10 |
| 063067 | Животные морские | 2 | 10 |
| 063071 | Кролики | 2 | 10 |
| 063086 | Лоси | 2 | 10 |
| 063090 | Лошади | 2 | 10 |
| 063103 | Лошаки | 2 | 10 |
| 063118 | Мулы | 2 | 10 |
| 063122 | Олени | 2 | 10 |
| 063137 | Ослы | 2 | 10 |
| 063141 | Пони | 2 | 10 |
| 063156 | Птица живая всякая (домашняя и дикая) | 2 | 10 |
| 063160 | Пчелы в ульях | 2 | 10 |
| 063175 | Собаки | 2 | 10 |
| 071006 | Сено, солома и корма растительные | 2 | 15 |
| 071010 | Камыш | 2 | 15 |
| 071025 | Корма растительные, не поименованные в алфавите | 2 | 15 |
| 071030 | Крапива | 2 | 15 |
| 071044 | Мох | 2 | 15 |
| 071059 | Мука травяная | 2 | 15 |
| 071063 | Початки кукурузные обрушенные | 2 | 15 |
| 071078 | Сено прессованное | 2 | 15 |
| 071082 | Силос | 2 | 15 |
| 071097 | Солома прессованная в кипах, брикетах, пеллетах (гранулах) | 2 | 15 |
| 071106 | Стебли кукурузы и хлопчатника | 2 | 15 |
| 071114 | Травы кормовые | 2 | 15 |
| 071129 | Тростник | 2 | 15 |
| 071133 | Полова | 2 | 15 |
| 072009 | Сырье табака и махорки | 3 | 21 |
| 072013 | Отходы табачные сырые (крошка и пыль) | 3 | 21 |
| 072028 | Сырье махорки, не поименованное в алфавите | 3 | 21 |
| 072032 | Сырье табака | 3 | 21 |
| 072047 | Табак в листьях и корешках | 3 | 21 |
| 072051 | Табак сырье ферментированное | 3 | 21 |
| 073001 | Культуры прядильные, кроме хлопчатника | 2 | 17 |
| 073016 | Культуры прядильные прочие в стеблях | 2 | 17 |
| 073020 | Солома льна | 2 | 17 |
| 073035 | Стебли джута | 2 | 17 |
| 073045 | Стебли кенафа | 2 | 17 |
| 073054 | Стебли конопли | 2 | 17 |
| 073069 | Треста конопли | 2 | 17 |
| 073073 | Треста льна | 2 | 17 |
| 073088 | Треста прядильных культур, не поименованных в алфавите | 2 | 17 |
| 074004 | Сырье лекарственное растительное | 2 | 17 |
| 074019 | Алоэ (растение лекарственное) | 2 | 17 |
| 074023 | Трава анабазиса (ежовника) безлистного | 2 | 17 |
| 074038 | Бодяга (колонии пресноводных губок) | 2 | 17 |
| 074042 | Водоросли всякие | 2 | 17 |
| 074057 | Трава донника лекарственного | 2 | 17 |
| 074061 | Капуста морская | 2 | 17 |
| 074076 | Кора лекарственных культур (калины, крушины и др. ), не поименованная в алфавите ), не поименованная в алфавите | 2 | 17 |
| 074080 | Кора хинная | 2 | 17 |
| 074095 | Коробочки мака с верхними частями стеблей | 2 | 17 |
| 074108 | Корни лекарственных культур, не поименованные в алфавите | 2 | 17 |
| 074112 | Корни ревеня | 2 | 17 |
| 074127 | Лишайники | 2 | 17 |
| 074131 | Мята перечная | 2 | 17 |
| 074146 | Полынь цитварная | 2 | 17 |
| 074150 | Почки березовые, сосновые, тополиные и др. | 2 | 17 |
| 074165 | Растения лекарственные, не поименованные в алфавите | 2 | 17 |
| 074174 | Ромашка всякая | 2 | 17 |
| 074184 | Споры плауна (ликоподий) | 2 | 17 |
| 074199 | Тимьян | 2 | 17 |
| 074201 | Хмель | 2 | 17 |
| 074216 | Цвет бузиновый, липовый | 2 | 17 |
| 074220 | Шиповник (ягоды) | 2 | 17 |
| 074235 | Ягоды лекарственные, не поименованные в алфавите | 2 | 17 |
| 074240 | Шишкоягоды (плоды) можжевельника обыкновенного | 2 | 17 |
| 074254 | Листья скумпии | 2 | 17 |
| 075007 | Рассада овощная, цветочная, ягодная. Цветы живые и свежесрезанные Цветы живые и свежесрезанные | 2 | 22 |
| 075011 | Луковицы (клубни) цветочные | 2 | 22 |
| 075026 | Мицелий грибов шампиньонов | 2 | 22 |
| 075030 | Прививки (растения) | 2 | 22 |
| 075045 | Рассада овощная, цветочная, ягодная | 2 | 22 |
| 075050 | Рассада, не поименованная в алфавите | 2 | 22 |
| 075064 | Цветы живые и свежесрезанные всякие | 2 | 22 |
| 075079 | Черенки растений | 2 | 22 |
| 076003 | Шерсть, волос, пух, перо | 3 | 22 |
| 076014 | Волос всякий | 3 | 22 |
| 076029 | Гривы и хвосты | 3 | 22 |
| 076033 | Отходы пера, пуха | 3 | 22 |
| 076048 | Перо птичье | 3 | 22 |
| 076052 | Пух птиц всяких | 3 | 22 |
| 076067 | Пух животных | 3 | 22 |
| 076071 | Шерсть линька | 3 | 22 |
| 076086 | Шерсть мытая | 3 | 22 |
| 076090 | Шерсть немытая | 3 | 22 |
| 076103 | Щетина | 3 | 22 |
| 077002 | Кожи, шкуры и пушнина невыделанные | 3 | 40 |
| 077017 | Каракуль невыделанный | 3 | 40 |
| 077021 | Кожи невыделанные всякие | 3 | 40 |
| 077036 | Лоскут кожаный невыделанный | 3 | 40 |
| 077040 | Мерлушки (шкурки овечьи) невыделанные | 3 | 40 |
| 077055 | Овчины (шкуры бараньи и овечьи) невыделанные, не поименованные а алфавите | 3 | 40 |
| 077066 | Пушнина невыделанная, не поименованная в алфавите | 3 | 40 |
| 077074 | Смушки (шкурки овечьи) невыделанные | 3 | 40 |
| 077089 | Сырье кожаное мокросоленое | 3 | 40 |
| 077093 | Сырье кожаное сухосоленое | 3 | 40 |
| 077106 | Хвосты пушнины невыделанные | 3 | 40 |
| 077110 | Шкурки (меха) пушных зверей невыделанные | 3 | 40 |
| 077125 | Шкуры и шкурки домашних животных меховые невыделанные | 3 | 40 |
| 077132 | Шкурки змеиные невыделанные | 3 | 40 |
| 077144 | Шкуры и шкурки невыделанные, не поименованные в алфавите | 3 | 40 |
| 077159 | Шкуры морского зверя невыделанные | 3 | 40 |
| 077163 | Шкуры рыб невыделанные | 3 | 40 |
| 078005 | Удобрения органические | 2 | 47 |
| 078019 | Агримус (лигнин гидролизный для удобрения) | 2 | 47 |
| 078024 | Гуано | 2 | 47 |
| 078039 | Мука костная | 2 | 47 |
| 078043 | Навоз | 2 | 47 |
| 078058 | Туки землеудобрительные органические (компосты) | 2 | 47 |
Статистический подход для внедрения водяных знаков в исполняемый код
Репозиторий БГУИР: Статистический подход для внедрения водяных знаков в исполняемый код Skip navigationPlease use this identifier to cite or link to this item:
https://libeldoc. bsuir.by/handle/123456789/30848
bsuir.by/handle/123456789/30848
| Title: | Статистический подход для внедрения водяных знаков в исполняемый код |
| Other Titles: | Statistical approach to executable code watermarking |
| Authors: | Портянко, С. С. Ярмолик, В. Н. Partsianka, S. S. Yarmolik, V. N. |
| Keywords: | доклады БГУИР интеллектуальные права программное обеспечение водяной знак |
| Issue Date: | 2005 |
| Publisher: | БГУИР |
| Citation: | Портянко, С. С. Статистический подход для внедрения водяных знаков в исполняемый код / С. С. Портянко, В. Н. Ярмолик // Доклады БГУИР. — 2005. — № 1 (9). — С. 98 — 103. |
| Abstract: | В данной статье затронута проблема обеспечения защиты интеллектуальных прав разработчи-
ков программного обеспечения. В частности, рассмотрен вопрос о противодействии несанк-
ционированному повторному использованию программных компонент. В качестве одного из
решений данной проблемы рассмотрены технологии водяных знаков и отпечатков пальцев.
Произведен сравнительный анализ подходов к внедрению статических водяных знаков и вы-
делены преимущества статистического подхода. На основе данного подхода предложен метод
размещения в исполняемом коде программы признака авторства, использующий статистиче-
ские свойства случайных последовательностей. Приведены результаты моделирования пред-
ложенного метода, а также возможное направление дальнейших исследований. В качестве одного из
решений данной проблемы рассмотрены технологии водяных знаков и отпечатков пальцев.
Произведен сравнительный анализ подходов к внедрению статических водяных знаков и вы-
делены преимущества статистического подхода. На основе данного подхода предложен метод
размещения в исполняемом коде программы признака авторства, использующий статистиче-
ские свойства случайных последовательностей. Приведены результаты моделирования пред-
ложенного метода, а также возможное направление дальнейших исследований. |
| URI: | https://libeldoc.bsuir.by/handle/123456789/30848 |
| Appears in Collections: | №1 (9) |
Items in DSpace are protected by copyright, with all rights reserved, unless otherwise indicated.
R — язык для статистической обработки данных. Часть 1/3 | by Anastasia Uvarova | NOP::Nuances of Programming
Я сам изучал R в течение последних нескольких недель.
В своей статье я рассказываю о языке программирования R и его главных концепциях, которые пригодятся каждому исследователю данных.
Сфера науки о данных и развивающихся вычислений требуют от нас всё время адаптироваться и вырабатывать новые навыки. Причина в том, что эта область меняется очень быстро. А ещё в ней в целом высокая планка требований. В профессиональной жизни каждого исследователя данных приходит время, когда нужно бы знать больше, чем один язык программирования. Так я и выбрал R.
В моих материалах вы узнаете обо всех ключевых областях и разберётесь в базовых понятиях. Предполагается, что вы, как читатели, вообще не знакомы с R или совсем немного в нем разбираетесь.
Автор фото Cris DiNoto, источник UnsplashЯ очень советую именно R по многим причинам.
R становился всё известнее и известнее, пока не стал одним из самых популярных языков программирования. Его создали статистики (специалисты по статистике) для статистиков. Он хорошо сочетается с другими языками программирования, например с C++, Java, SQL. Более того, его воспринимают как язык, который отлично подходит для работы со статистикой. А в результате большое количество финансовых организаций и крупных вычислительных компаний применяют R в своих исследованиях и разработках.
Он хорошо сочетается с другими языками программирования, например с C++, Java, SQL. Более того, его воспринимают как язык, который отлично подходит для работы со статистикой. А в результате большое количество финансовых организаций и крупных вычислительных компаний применяют R в своих исследованиях и разработках.
Python — язык для решения задач общего характера, а R — язык программирования для аналитики.
Этот текст объяснит следующие ключевые области языка R:
- Что такое R?
- Как установить R?
- Где писать код на R?
- Что такое R-скрипт и R-пакет?
- Какие типы данных есть в R?
- Как декларировать переменные и их область действия в R?
- Как писать комментарии?
- Что такое векторы?
- Что такое матрица?
- Что собой представляют списки?
- Что такое датафреймы?
- Различные логические операции в R.
- Функции в R.
- Циклы в R.
- Считывание и запись внешних данных в R.

- Как производить статистические вычисления в R.
- Построение графиков и диаграмм в R.
- Объектно-ориентированное программирование в R.
- Знаменитые библиотеки R.
- Как установить внешние библиотеки R.
Приступим же!…
Я буду объяснять язык программирования, начиная с основ, в таком стиле, чтобы вам было легче разобраться. Стоит сказать, что ключ к прогрессу в разработке — это постоянная практика. Чем больше, чем лучше.
Этот материал должен стать целостной базой для вас — читателей.
- R — это бесплатный язык программирования с лицензией GNU. В сущности R — это статистическая среда.
- R в основном используется для статистических вычислений. Он имеет набор алгоритмов, которые углубленно применяются в области машинного обучения. А конкретнее — в анализе временных рядов, классификации, кластеризации, линейном моделировании и т.д.
- Также R — это среда, в которой есть набор программных пакетов, с которыми можно производить вычисления для построения диаграмм и для манипуляций с данными.

- R значительно применяется в проектах статистических исследований.
- R очень похож на другой язык программирования — S.
- R компилируется и запускается на UNIX, Windows, MacOS, FreeBSD и Linux.
- В R есть большое количество структур данных, операторов и параметров. Он включает многое: от массивов до матриц, от циклов до рекурсии вместе с интеграцией с другими ЯП, например с C, C++ и Fortran.
- C можно использовать для обновления объектов в R напрямую.
- R можно дополнять новыми пакетами.
- R — интерпретатор.
- Авторы R вдохновлялись S+, так что, если вы знакомы с S, изучение R будет для вас простым следующим шагом.
Преимущества R:
Вдобавок к плюсам, о которых я написал выше:
- R просто выучить.
- В среде есть очень много бесплатных пакетов с открытым исходным кодом для статистики, аналитики и графики.
- Богатство различных научных трудов вместе с их применением в R в вашем распоряжении.
- Лучшие мировые университеты учат своих студентов R, следовательно, он стал принятым стандартом, продолжит расти и развиваться.

- Широкие возможности интеграции с другими языками.
- Огромная поддержка в сообществе специалистов.
Ограничения R:
Также есть и некоторые ограничения:
- R не такой быстрый, как C++. К тому же, есть проблемы с его защищённостью и управлением памятью.
- R имеет много пространств имен. Иногда такое впечатление, что их даже слишком много. Тем не менее ситуация улучшается.
- Так как R — это статистический язык, то он не такой интуитивный, как Python, и в нём не так просто работать с ООП, как в Python.
А теперь я представлю вам язык R в формате кратких описательных разделов.
Автор фото Jonas Jacobsson, источник UnsplashМожете установить R на эти платформы:
- Ubunto
- Mac
- Windows
- Fedora
- Debian
- SLES
- OpenSUSE
Первый шаг — загрузите R:
- Откройте интернет-браузер.
- Пройдите по ссылке www.r-project.org.
- Последняя версия R на момент написания оригинала этой статьи была 3.
 6.3 (Holding the Windsock). Выпущена 2020–02–29.
6.3 (Holding the Windsock). Выпущена 2020–02–29.
Вот вам и линки:
Есть разные графические интерфейсы. Очень советую R-Studio.
Скриншот R-StudioЗагрузите десктопную версию RStudio:
Если вы работаете на Windows, в процессе установки R Studio по умолчанию попадет сюда:
C:\Program Files\RStudio
Это два ключевых компонента в языке. В этом разделе поверхностно расскажу о концепциях.
Пакет R
Так как R — это ЯП с открытым кодом, важно понимать, что тут подразумевается под пакетом. Пакет в сущности группирует и упорядочивает код, а также другие функции. Пакет — это библиотека, в которой содержится большое количество файлов.
Специалисты по данным могут писать и делиться своим кодом с другими. Будь это их собственный код с нуля или расширение пакетов других авторов. Пакеты позволяют специалистам по данным переиспользовать код и распространять его среди остальных.
Пакеты созданы, чтобы контейнировать функции и наборы данных.

Специалист по данным может создать пакет, чтобы упорядочить код, документацию, тесты, наборы данных и так далее, и потом этими пакетами можно делиться с другими людьми.
В интернете в открытом доступе есть десятки тысяч пакетов R. Эти пакеты собраны в центральном репозитории. Вообще есть разные репозитории. Это и CRAN, и Bioconductor, и любимый Github.
Одно хранилище заслуживает отдельного упоминания. Это CRAN. Это сеть серверов, которые хранят большое количество версий кода и документации для R.
Пакет содержит файл с описанием, где нужно указать дату, зависимости, автора и версию пакета, а также другие данные. Файл-описание помогает пользователям получить важную информацию о пакете.
Чтобы загрузить пакет, напечатайте:
library(имя пакета)
Чтобы пользоваться функциональностью пакета, напишите в его имени::название функции.
Например, если мы хотим применить функцию “AdBCDOne” из пакета “carat”, можем сделать следующее:
library(carat)
carat::AdBCDOne()
R Script
Скрипт R — это место, где специалист по данным может писать статистический код.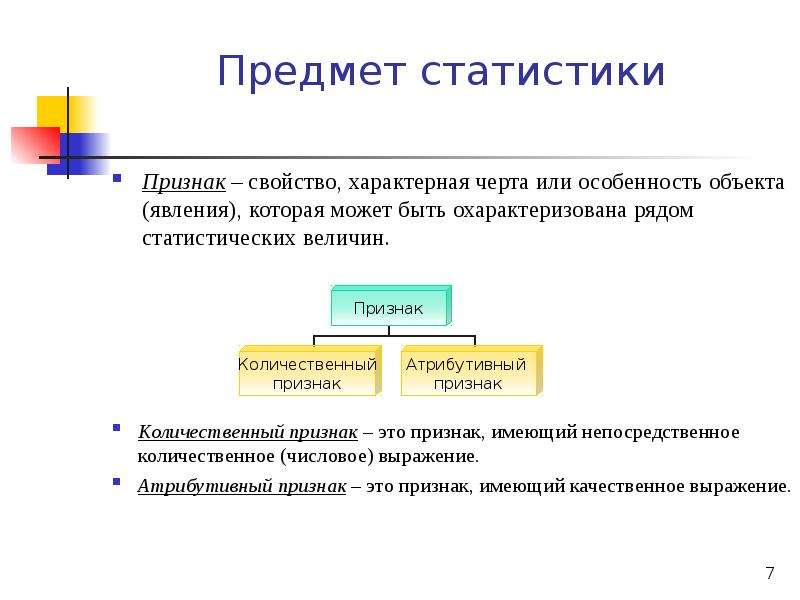 Это текстовый файл с расширением .R, например мы может назвать скрипт tutorial.R.
Это текстовый файл с расширением .R, например мы может назвать скрипт tutorial.R.
Можем создать много скриптов в пакете.
В качестве примера, если вы создали два скрипта R:
- blog.R (для блога)
- publication.R (для публикации)
И если вы хотите вызвать функции publication.R в blog.R, то вам стоит пользоваться командой source(“target R script”). Она импортирует publication.R в blog.R:
source("publication.R")Создаём пакет скрипта
Процесс относительно простой. В сущности вот, что нужно сделать:
- Создайте файл описания.
- Создайте R.scripts и добавьте любые датасеты, документацию, тесты, которые должны быть в этом пакете.
- Напишите свои функции в скриптах R.
- Можем применить devtools и roxygen2, чтобы создать пакеты R с помощью такой команды:
create_package("имя пакета")Очень важно разобраться в разных типах данных и структурах в R. Так вы сможете пользоваться языком эффективно. В этом разделе я опишу концепции.
Так вы сможете пользоваться языком эффективно. В этом разделе я опишу концепции.
Типы данных
Вот базовые типы данных в R:
- символ (character): может быть таким “abc” или таким “a”
- целочисленный (integer): например 5L
- числовой (numeric): например 10.5
- логический (logical): TRUE или FALSE
- комплексный (complex): например 5+4i
Ещё можем пользоваться командой typeof(variable), чтобы определить тип переменной.
Чтобы найти метаданные (атрибуты типа), используйте команду attributes(variable).
Структуры данных
В R достаточно много структур данных. Привожу самые важные:
- Вектор (vector): самая важная структура, которая в сущности является набором элементов.
- Матрица (matrix): похожая на таблицу структура со строками и колонками
- Датафрейм (data frame): табличная структура для статистических операций
- Списки (lists): набор, в котором может быть комбинация типов данных.

- Факторы (factors): для представления категориальных данных.
Я расскажу обо всех этих типах и структурах данных, так что начинаем строить фундамент.
Мы можем создать переменную и присвоить ей значение. Переменная может иметь любой тип данных и структуру данных, которые я привел выше. Есть, конечно, и другие структуры данных. Дополнительно разработчик может создавать и свои собственные пользовательские классы.
Переменная нужна, чтобы сохранять значение, которое может меняться в вашем коде.
Чтобы понять, важно запомнить, что такое окружение в R. В сущности окружение — это место, где хранятся переменные. Это набор пар, где первый элемент — это символ (переменная), а второй — её значение.
Окружение имеет иерархическую структуру (похожую на дерево). Следовательно, окружение может иметь родителя и множество дочерних ответвлений. Корневое окружение — это окружение без родителя.
Надо декларировать переменную и присвоить ей значение при помощи следующего:
x <- "my variable"
print(x)
После этого значение “my variable” будет присвоено переменной x. Функция print() выведет значение x, которое равно “my variable”.
Функция print() выведет значение x, которое равно “my variable”.
Каждый раз, когда мы объявляем переменную и вызываем её, она ищется в текущем окружении, а также рекурсивно ищется в родительских окружениях до тех пор, пока значение не будет найдено.
Чтобы создать набор целых чисел, мы можем сделать следующее:
coll <- 1:5
print(coll)
1 — первое значение, а 5 — последнее значение из набора.
В результате выведутся числа от 1 до 5.
Помните, что IDE R-Studio отслеживает переменные:
Скриншот R StudioФункцию ls() можно писать, чтобы показать переменные и функции в текущем окружении.
Комментарии нужны в коде, чтобы помогать понимать его тем, кто будет с ним разбираться. Читателям, другим специалистам по данным и самому себе. Бывает и такое.
Помните, что нужно всегда убеждаться в том, что комментарии не загрязняют ваши скрипты.
Можем добавить комментарий одной строкой:
#комментарий на одну строку
Можем добавить комментарий в несколько строк при помощи двойных кавычек:
"комментарий на
несколько строк
"
Памятка: в R-Studio выделите код, который вы собираетесь закомментировать и нажмите сочетание клавиш Ctrl+Shift+C.
Так вы автоматически сделаете нужную часть программы комментарием.
Вектор считается одной из самых важных структур данных в R. В сущности вектор представляет собой набор элементов, где у всех элементов должен быть одинаковый тип данных: например, только логический (истинно/ложно — TRUE/FALSE), числовой, знаковый.
Также можем создать пустой вектор:
x <- vector()
По умолчанию тип вектора логический. По команде ниже выведется слово “logical”, так как это и есть тип данных вектора:
typeof(x)
Чтобы создать вектор со своими элементами, пишите функцию конкатенации (объединения строк):
x <- c("Farhad", "Malik", "FinTechExplained")
print(x)Результат выполнения этого кода будет таким:
[1] “Farhad”
[2] “Malik”
[3] “FinTechExplained”
Если мы захотим найти длину вектора, можем воспользоваться функцией length():
length(x)
Результат вывода строки выше будет 3. Потому что в заданном векторе x 3 элемента. Чтобы добавить элементы в вектор, можем комбинировать элемент с вектором.
Чтобы добавить элементы в вектор, можем комбинировать элемент с вектором.
Например, чтобы добавить слово “world” к началу вектора с одним элементом слова “hello”, нужно написать так:
x <- c("hello")
x <- c("world", x)
print(x)В результате напечатается “world” “hello”.
Если мы смешиваем типы элементов, то R в свою очередь будет приспосабливать тип вектора в ответ на это. Тип вектора (режим) будет становиться таким, каким должен быть по своему расчёту, чтобы подходить этому вектору:
another_vec <- c("test", TRUE)
print(typeof(another_vec))И хотя второй элемент имеет логическое значение, тип будет выведен как “character” (символ).
Над векторами можно производить операции.
Для примера, вот вам умножение скаляра на вектор:
x <- c(1,2,3)
y <- x*2
print(y)
В результате напечатается 2,4,6.
Также можем сложить два вектора:
x <- c(1,2,3)
y <- c(4,5,6)
z <- x+y
print(z)
Результат будет: 5 7 9
Если векторы — это знаки и мы хотим сложить их вместе, то:
x <- c("F","A","C")
y <- c("G","E","D")
z <- x+y
print(z)Это выведет:
Error in x + y : non-numeric argument to binary operator (ошибка в выражении x + y: нечисловой аргумент для бинарного оператора).
Продолжение следует…
Читайте также:
Читайте нас в телеграмме, vk и Яндекс.Дзен
Что такое искусственный интеллект (AI)? – Amazon Web Services
Искусственный интеллект (AI) – раздел информатики, который занимается решением когнитивных задач, обычно предназначаемых для человеческого интеллекта, таких как обучение, решение проблем и распознавание шаблонов. Искусственный интеллект (AI) часто ассоциируется с робототехникой и научной фантастикой, но на самом деле он давно вышел за пределы фантастических фильмов. Сегодня искусственный интеллект – это часть продвинутых компьютерных технологий. Одним из выдающихся ученых в этой области является профессор Педро Домингос. Он выделил пять групп ученых, которые вносят вклад в развитие машинного обучения: символисты, сфера которых берет начало в логике и философии; коннекционисты, которые берут знания из нейробиологии; эволюционисты, развивающие методы эволюционной биологии; байесовцы, применяющие математическую статистику и теорию вероятности; и аналогисты, исследования которых базируются на психологии.
В широком смысле эти подходы разделяются на «направляемое» и на «произвольное» обучение. В первом случае используются данные с заданным результатом, а во втором – без него.
Каждый день компании производят данные для систем машинного и глубокого обучения, и с увеличением объемов данных AI становится «умнее» и развивается все быстрее и быстрее. Данные извлекаются из хранилищ, таких как Amazon Redshift, собираются с помощью платформ для краудсорсинга, таких как Mechanical Turk, или загружаются динамически с помощью Kinesis Streams.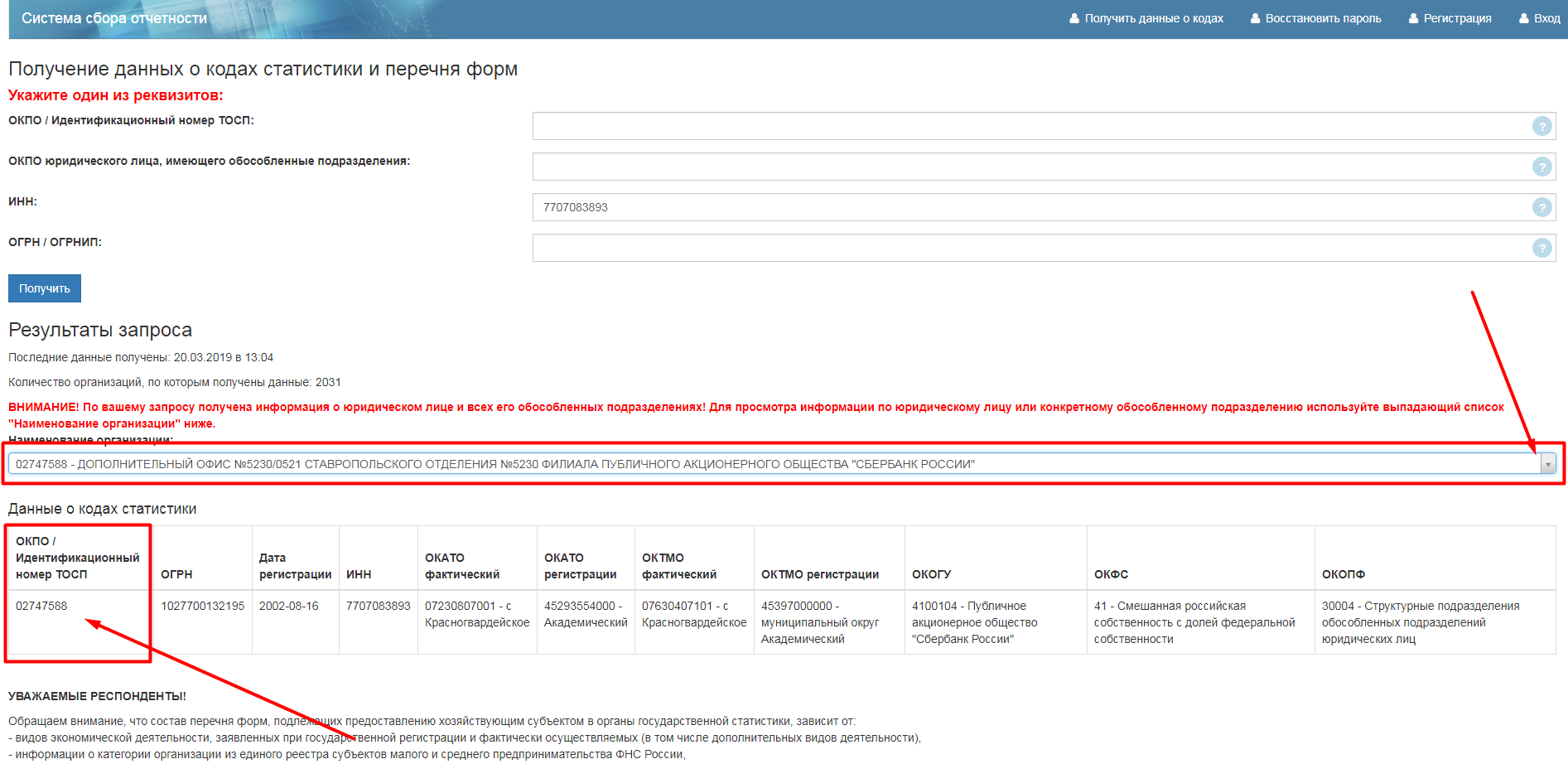 Кроме того, с развитием Интернета вещей и сенсорных технологий данные, которые раньше практически не использовались, теперь стали доступны для анализа, и их объем возрастает в геометрической прогрессии.
Кроме того, с развитием Интернета вещей и сенсорных технологий данные, которые раньше практически не использовались, теперь стали доступны для анализа, и их объем возрастает в геометрической прогрессии.
Машинным обучением обычно называют методы анализа, основанные на байесовской теории, которые используются для распознавания шаблонов и обучения. В основе машинного обучения лежит набор алгоритмов, которые используют предоставленные данные для обучения и прогнозирования, оптимизируют функцию полезности в условиях неопределенности, распознают в данных скрытые структуры и классифицируют данные в кратким описанием. Машинное обучение часто применяется в тех случаях, когда использование точных программных алгоритмов не обеспечивает достаточной гибкости или неэффективно. Обычный компьютерный код обрабатывает входные данные по алгоритму, заложенному разработчиком, и возвращает соответствующий ответ. Система машинного обучения анализирует входные данные для поиска шаблонов и создает статистический код (модель машинного обучения), который возвращает «правильный результат» на основании предыдущих входных данных (а также выходных данных в случае направляемого обучения). Точность модели машинного обучения во многом зависит от качества и количества накопленных со временем данных.
Точность модели машинного обучения во многом зависит от качества и количества накопленных со временем данных.
При использовании качественных данных модель может анализировать многомерные проблемы с миллиардами возможных вариантов и находить оптимальную функцию, которая по входным данным будет прогнозировать корректное значение. Как правило, модели машинного обучения прогнозируют ответ со статистической достоверностью и достаточно надежны. Такие оценочные показатели следует учитывать при принятии решения об использовании моделей машинного обучения или любого отдельного прогнозирования.
Amazon.com активно использует системы машинного обучения для решения практических задач. Технологии машинного обучения помогают расширять сферу деятельности, улучшать работу сервисов, повышать качество логистики и скорость доставки. Amazon.com запустила платформу AWS, чтобы другие компании могли гибко и экономично использовать эти преимущества в своей ИТ-инфраструктуре, и продолжает делать технологии машинного обучения доступными для других.
Сама структура подразделений разработки Amazon.com и приверженность к решению утилитарных коммерческих проблем с помощью машинного обучения помогают создавать простые, но мощные инструменты и сервисы машинного обучения. Сначала эти инструменты тестируются на критически важных процессах в рамках Amazon.com – и только потом становятся доступны для других компаний, так же, как и другие ИТ-сервисы.
Машинное обучение часто используется для прогнозирования результатов на основании данных за прошедший период. Например, компании могут использовать машинное обучение для прогнозирования объемов продаж в будущем финансовом квартале на основе информации о демографической ситуации или оценивать, какие клиенты могут разочароваться в конкретном бренде или, наоборот, стать наиболее лояльными к нему, на основе профиля клиента. Такие прогнозы позволяют принимать более эффективные решения, улучшать качество продуктов и снижать расходы на удержание клиентов. Машинное обучение дополняет системы бизнес-аналитики, которые предоставляют информацию о деятельности компании за прошлые периоды, но фокусируется на прогнозах будущих тенденций.
Машинное обучение дополняет системы бизнес-аналитики, которые предоставляют информацию о деятельности компании за прошлые периоды, но фокусируется на прогнозах будущих тенденций.
Успешная реализация технологий машинного обучения в компании состоит из нескольких шагов. Прежде всего необходимо определить, какую проблему должна решать система, т. е. какие прогнозы могут быть полезны для компании. Затем необходимо собрать данные за прошлые периоды на основании бизнес-показателей (транзакции, показатели продаж, потери клиентов и т. п.). Эти данные будут использоваться для построения модели машинного обучения. После этого модель машинного обучения будет делать прогнозы, которые можно использовать для принятия более обоснованных бизнес-решений.
Глубокое обучение – это частный случай машинного обучения, в котором используются многоуровневые алгоритмы для более глубокого анализа данных.В таких нелинейных алгоритмах создается не просто объяснимый набор связей, как при простом регрессионном анализе,а распределенные представления данных, которые взаимодействуют друг с другом в зависимости от определенного набора факторов. Если предоставить алгоритмам глубокого обучения большой объем входных данных, они смогут определять взаимоотношения между элементами.Например, это могут быть взаимоотношения между формой, цветом, словами и т п.Затем эти отношения используются для прогнозирования.В случае искусственного интеллекта эффективность алгоритмов глубокого обучения заключается в том, что они могут определять гораздо больше взаимоотношений между объектами, чем способен включить в программу человек, а также находить такие взаимоотношения, которые, возможно, люди вообще не в состоянии обнаружить.При достаточно больших объемах входных данных сеть алгоритмов будет делать прогнозы или интерпретировать очень сложные структуры данных.
Если предоставить алгоритмам глубокого обучения большой объем входных данных, они смогут определять взаимоотношения между элементами.Например, это могут быть взаимоотношения между формой, цветом, словами и т п.Затем эти отношения используются для прогнозирования.В случае искусственного интеллекта эффективность алгоритмов глубокого обучения заключается в том, что они могут определять гораздо больше взаимоотношений между объектами, чем способен включить в программу человек, а также находить такие взаимоотношения, которые, возможно, люди вообще не в состоянии обнаружить.При достаточно больших объемах входных данных сеть алгоритмов будет делать прогнозы или интерпретировать очень сложные структуры данных.
Статистический код для статей о клинических исследованиях в специализированном медицинском журнале с высоким уровнем воздействия
Ann Intern Med. Авторская рукопись; доступно в PMC 2019 22 августа.
Опубликован в окончательной редакции как:
PMCID: PMC6705117
NIHMSID: NIHMS1044171
Melissa Assel
1 Департамент эпидемиологии и биостатистики, Нью-Йорк Йорк, Нью-Йорк, США
Эндрю Дж.
 Виккерс
Виккерс1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр Слоуна Кеттеринга, Нью-Йорк, Нью-Йорк, США
1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр им. Слоана Кеттеринга , New York, NY, USA
Вклад авторов
Концепция и дизайн: VickersСбор, анализ или интерпретация данных: Assel, Vickers, Catto, Pierce, Redley, Le
Составление рукописи: Assel, Vickers
Critical пересмотр рукописи на предмет важного интеллектуального содержания: Assel, Vickers
Статистический анализ: Assel, Vickers
Admi государственная, техническая или материальная поддержка: Catto, Pierce, Redley, Le
. Корреспондент Эндрю Дж. Викерс, Мемориальный онкологический центр им. Слоуна Кеттеринга, 485 Lexington Avenue, New York, NY 10017 USA, gro.ccksm@asrekciv, (P): 646-888-8233 Доступна окончательная отредактированная версия этой статьи издателем в Ann Intern Med. См. другие статьи в PMC, в которых цитируется опубликованная статья.
См. другие статьи в PMC, в которых цитируется опубликованная статья.Предпосылки
Принято считать, что статистический анализ должен выполняться путем написания кода хорошего качества в профессиональном статистическом пакете, таком как R, SAS или Stata.Хороший код обеспечивает воспроизводимость, снижает количество ошибок и предоставляет проверяемую документацию анализов, лежащих в основе результатов исследования. В последнее время было предпринято несколько попыток поощрения архивирования кода, соответствующего опубликованным статьям 1–5 , на том основании, что это улучшает прозрачность. Такие усилия были сосредоточены на таких областях, как нейробиология или биоинформатика, которые в значительной степени зависят от ресурсоемкого анализа.
Цель
Изучить, как часто авторы использовали статистический код для статей о клинических исследованиях, опубликованных в влиятельном специализированном журнале, и определить качество этого кода.
Методы и результаты
В середине 2016 года мы добавили в систему онлайн-подачи для European Urology вопрос о том, использовали ли авторы статистический код и, если да, готовы ли они представить, чтобы их статья была принято. В августе 2017 года мы рассмотрели 314 статей, впоследствии принятых в журнал. Авторы 40 статей сообщили, что использовали статистический код. Авторы заархивировали код 18 из этих статей в журнале, а остальные 32 отказались это сделать.
В августе 2017 года мы рассмотрели 314 статей, впоследствии принятых в журнал. Авторы 40 статей сообщили, что использовали статистический код. Авторы заархивировали код 18 из этих статей в журнале, а остальные 32 отказались это сделать.
Мы случайным образом отобрали и просмотрели 50 статей, авторы которых не указали код. Из этих 50 35 не представили статистических данных (например, повествовательный обзор литературы) или только тривиальный анализ (например, единую кривую выживаемости). Остальные 15 включали в себя предметный анализ, такой как большое количество регрессионных моделей, графиков или статистики времени до события. Мы связались с авторами этих 15 статей; 8 сказали нам, что они не использовали код, но 7 ответили, что они действительно использовали код и что их первоначальный ответ был ошибочным.В 6 из этих 7 случаев авторы отказались предоставить свой код в журнал.
Затем мы изучили все полученные наборы кодов, за исключением кода, связанного с 3 статьями, представленными авторами, прошедшими обучение в нашей группе. Большая часть кода практически не содержала аннотаций и часто повторялась. Для половины статей проверенный код не включал форматирование для презентации ().
Большая часть кода практически не содержала аннотаций и часто повторялась. Для половины статей проверенный код не включал форматирование для презентации ().
Таблица 1.
Оценка кода 16 опубликованных статей.
| Домен | Оценка | N |
|---|---|---|
| Хорошо ли аннотированы коды? | Обширные аннотации, позволяющие практически воссоздать код, используя аннотации. | 0 |
| Умеренная аннотация, позволяющая воссоздать по крайней мере некоторый код на основе аннотаций. | 2 | |
Аннотации мало или нет. | 14 | |
| Избегает ли код повторения? | Хорошее использование циклов и макросов, при котором существует мало или только тривиальный повторяющийся код. | 0 |
| Умеренное количество повторяющегося кода (около 10 строк или меньше). | 0 | |
| Отсутствие циклов или макросов и частое повторение кода (10 строк и более). | 15 | |
| Не применимо; нет возможности для повторного кода. | 1 | |
| Включает ли код форматирование для презентации? | Язык разметки или другие методы, используемые для создания форматированного вывода, обеспечивающие все или почти все результаты статьи. | 3 |
| Язык разметки или другие методы, используемые для создания форматированного вывода, требуют нетривиальных поправок или многие результаты не отформатированы. | 5 | |
| Нет форматированного вывода. | 8 |
Обсуждение
Никакой статистический код не использовался для более чем трети статей, опубликованных в влиятельном специализированном медицинском журнале, который включал статистический анализ, не связанный с исследованиями. Ни один набор кода не получил даже среднего балла по трем основным и общепринятым программным критериям. Это не поверхностная проблема. Например, отсутствие кода, форматирующего числовые данные, увеличивает риск ошибок транскрипции; повторяющийся код может привести к непоследовательности анализа.
У нас есть три рекомендации. Во-первых, методы и принципы программного обеспечения должны стать основной частью учебных программ по биостатистике, независимо от степени (бакалавриат или аспирантура) и предмета (биостатистика, общественное здравоохранение или эпидемиология). Учитывая, что студентам придется писать код, когда они придут выполнять анализ в качестве практикующих исследователей, нам трудно понять, почему немногие программы на получение степени в области количественной медицины преподают хорошую практику программирования. Во-вторых, должна проводиться очная экспертная оценка статистического кода.Коллеги должны регулярно делиться кодом друг с другом в целях конструктивной критики, так же как они делятся черновиками научных статей. В-третьих, код, связанный с опубликованными исследованиями, должен быть заархивирован. Это не только улучшит прозрачность и воспроизводимость, но также поможет обеспечить, чтобы исследователи писали более качественный код. Один следователь, с которым мы связались, сказал нам, что он не желает архивировать свой код в журнале, потому что он «не приложил никаких усилий, чтобы сделать его… пригодным для использования другими», в результате чего большая часть кода оказалась «грязной». Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Отказ от использования кода статистического программирования или написание некачественного кода серьезно угрожает достоверности научных результатов. Мы призываем медицинское исследовательское сообщество принять немедленные меры по исправлению положения.
Выражение признательности
Финансирование
Эта работа была поддержана грантом MSKCC (номер гранта P30-CA008748) Национальным институтом здравоохранения / Национальным институтом рака.
Сноски
Нет конфликта интересов
Ссылки
1. Эглен С.Дж., Марвик Б., Хальченко Ю.О. и др. К стандартным практикам совместного использования компьютерного кода и программ в неврологии. Nat Neurosci 2017; 20 (6): 770–773. [Бесплатная статья PMC] [PubMed] [Google Scholar] 2. О’Нил К., Бринкман Р.Р. Публикация кода имеет важное значение для воспроизводимой биоинформатики проточной цитометрии. Цитометрия Часть A
2016; 89 (1): 10–11. [PubMed] [Google Scholar] 3. Герберт Р., Элкинс М. Код публикации: инициатива по повышению прозрачности анализа данных, представленных в журнале физиотерапии.Журнал физиотерапии
2017; 63 (3): 129–130. [PubMed] [Google Scholar]
Цитометрия Часть A
2016; 89 (1): 10–11. [PubMed] [Google Scholar] 3. Герберт Р., Элкинс М. Код публикации: инициатива по повышению прозрачности анализа данных, представленных в журнале физиотерапии.Журнал физиотерапии
2017; 63 (3): 129–130. [PubMed] [Google Scholar]Статистический код для статей о клинических исследованиях в высокоэффективном специализированном медицинском журнале
Ann Intern Med. Авторская рукопись; доступно в PMC 2019 22 августа.
Опубликован в окончательной редакции как:
PMCID: PMC6705117
NIHMSID: NIHMS1044171
Melissa Assel
1 Департамент эпидемиологии и биостатистики, Нью-Йорк Йорк, Нью-Йорк, США
Эндрю Дж.Викерс
1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр им. Слоана Кеттеринга, Нью-Йорк, штат Нью-Йорк, США
1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр им. Слоана Кеттеринга, Нью-Йорк, Нью-Йорк, США
Автор Вклад
Концепция и дизайн: VickersСбор, анализ или интерпретация данных: Assel, Vickers, Catto, Pierce, Redley, Le
Составление рукописи: Assel, Vickers
Критический пересмотр рукописи для важного интеллектуального содержания: Assel , Vickers
Статистический анализ: Assel, Vickers
Административная, техническая или материальная поддержка: Catto, Pierce, Redley, Le
. Корреспондент Эндрю Дж. Викерс, Мемориальный онкологический центр им. Слоуна Кеттеринга, 485 Lexington Avenue, New York, NY 10017 USA, gro.ccksm@asrekciv, (P): 646-888-8233 Доступна окончательная отредактированная версия этой статьи издателем в Ann Intern Med. См. другие статьи в PMC, в которых цитируется опубликованная статья.
Корреспондент Эндрю Дж. Викерс, Мемориальный онкологический центр им. Слоуна Кеттеринга, 485 Lexington Avenue, New York, NY 10017 USA, gro.ccksm@asrekciv, (P): 646-888-8233 Доступна окончательная отредактированная версия этой статьи издателем в Ann Intern Med. См. другие статьи в PMC, в которых цитируется опубликованная статья.Предпосылки
Принято считать, что статистический анализ должен выполняться путем написания кода хорошего качества в профессиональном статистическом пакете, таком как R, SAS или Stata.Хороший код обеспечивает воспроизводимость, снижает количество ошибок и предоставляет проверяемую документацию анализов, лежащих в основе результатов исследования. В последнее время было предпринято несколько попыток поощрения архивирования кода, соответствующего опубликованным статьям 1–5 , на том основании, что это улучшает прозрачность. Такие усилия были сосредоточены на таких областях, как нейробиология или биоинформатика, которые в значительной степени зависят от ресурсоемкого анализа.
Цель
Изучить, как часто авторы использовали статистический код для статей о клинических исследованиях, опубликованных в влиятельном специализированном журнале, и определить качество этого кода.
Методы и результаты
В середине 2016 года мы добавили в систему онлайн-подачи для European Urology вопрос о том, использовали ли авторы статистический код и, если да, готовы ли они представить, чтобы их статья была принято. В августе 2017 года мы рассмотрели 314 статей, впоследствии принятых в журнал. Авторы 40 статей сообщили, что использовали статистический код. Авторы заархивировали код 18 из этих статей в журнале, а остальные 32 отказались это сделать.
Мы случайным образом отобрали и просмотрели 50 статей, авторы которых не указали код. Из этих 50 35 не представили статистических данных (например, повествовательный обзор литературы) или только тривиальный анализ (например, единую кривую выживаемости). Остальные 15 включали в себя предметный анализ, такой как большое количество регрессионных моделей, графиков или статистики времени до события. Мы связались с авторами этих 15 статей; 8 сказали нам, что они не использовали код, но 7 ответили, что они действительно использовали код и что их первоначальный ответ был ошибочным.В 6 из этих 7 случаев авторы отказались предоставить свой код в журнал.
Мы связались с авторами этих 15 статей; 8 сказали нам, что они не использовали код, но 7 ответили, что они действительно использовали код и что их первоначальный ответ был ошибочным.В 6 из этих 7 случаев авторы отказались предоставить свой код в журнал.
Затем мы изучили все полученные наборы кодов, за исключением кода, связанного с 3 статьями, представленными авторами, прошедшими обучение в нашей группе. Большая часть кода практически не содержала аннотаций и часто повторялась. Для половины статей проверенный код не включал форматирование для презентации ().
Таблица 1.
Оценка кода 16 опубликованных статей.
| Домен | Оценка | N |
|---|---|---|
| Хорошо ли аннотированы коды? | Обширные аннотации, позволяющие практически воссоздать код, используя аннотации. | 0 |
| Умеренная аннотация, позволяющая воссоздать по крайней мере некоторый код на основе аннотаций. | 2 | |
| Аннотации мало или нет. | 14 | |
| Избегает ли код повторения? | Хорошее использование циклов и макросов, при котором существует мало или только тривиальный повторяющийся код. | 0 |
| Умеренное количество повторяющегося кода (около 10 строк или меньше). | 0 | |
Отсутствие циклов или макросов и частое повторение кода (10 строк и более). | 15 | |
| Не применимо; нет возможности для повторного кода. | 1 | |
| Включает ли код форматирование для презентации? | Язык разметки или другие методы, используемые для создания форматированного вывода, обеспечивающие все или почти все результаты статьи. | 3 |
| Язык разметки или другие методы, используемые для создания форматированного вывода, требуют нетривиальных поправок или многие результаты не отформатированы. | 5 | |
Нет форматированного вывода. | 8 |
Обсуждение
Никакой статистический код не использовался для более чем трети статей, опубликованных в влиятельном специализированном медицинском журнале, который включал статистический анализ, не связанный с исследованиями. Ни один набор кода не получил даже среднего балла по трем основным и общепринятым программным критериям. Это не поверхностная проблема. Например, отсутствие кода, форматирующего числовые данные, увеличивает риск ошибок транскрипции; повторяющийся код может привести к непоследовательности анализа.
У нас есть три рекомендации. Во-первых, методы и принципы программного обеспечения должны стать основной частью учебных программ по биостатистике, независимо от степени (бакалавриат или аспирантура) и предмета (биостатистика, общественное здравоохранение или эпидемиология). Учитывая, что студентам придется писать код, когда они придут выполнять анализ в качестве практикующих исследователей, нам трудно понять, почему немногие программы на получение степени в области количественной медицины преподают хорошую практику программирования. Во-вторых, должна проводиться очная экспертная оценка статистического кода.Коллеги должны регулярно делиться кодом друг с другом в целях конструктивной критики, так же как они делятся черновиками научных статей. В-третьих, код, связанный с опубликованными исследованиями, должен быть заархивирован. Это не только улучшит прозрачность и воспроизводимость, но также поможет обеспечить, чтобы исследователи писали более качественный код. Один следователь, с которым мы связались, сказал нам, что он не желает архивировать свой код в журнале, потому что он «не приложил никаких усилий, чтобы сделать его… пригодным для использования другими», в результате чего большая часть кода оказалась «грязной».Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Во-вторых, должна проводиться очная экспертная оценка статистического кода.Коллеги должны регулярно делиться кодом друг с другом в целях конструктивной критики, так же как они делятся черновиками научных статей. В-третьих, код, связанный с опубликованными исследованиями, должен быть заархивирован. Это не только улучшит прозрачность и воспроизводимость, но также поможет обеспечить, чтобы исследователи писали более качественный код. Один следователь, с которым мы связались, сказал нам, что он не желает архивировать свой код в журнале, потому что он «не приложил никаких усилий, чтобы сделать его… пригодным для использования другими», в результате чего большая часть кода оказалась «грязной».Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Отказ от использования кода статистического программирования или написание некачественного кода серьезно угрожает достоверности научных результатов. Мы призываем медицинское исследовательское сообщество принять немедленные меры по исправлению положения.
Выражение признательности
Финансирование
Эта работа была поддержана грантом MSKCC (номер гранта P30-CA008748) Национальным институтом здравоохранения / Национальным институтом рака.
Сноски
Нет конфликта интересов
Ссылки
1. Эглен С.Дж., Марвик Б., Хальченко Ю.О. и др. К стандартным практикам совместного использования компьютерного кода и программ в неврологии. Nat Neurosci 2017; 20 (6): 770–773. [Бесплатная статья PMC] [PubMed] [Google Scholar] 2. О’Нил К., Бринкман Р.Р. Публикация кода имеет важное значение для воспроизводимой биоинформатики проточной цитометрии. Цитометрия Часть A 2016; 89 (1): 10–11. [PubMed] [Google Scholar] 3. Герберт Р., Элкинс М. Код публикации: инициатива по повышению прозрачности анализа данных, представленных в журнале физиотерапии.Журнал физиотерапии 2017; 63 (3): 129–130. [PubMed] [Google Scholar]Статистический код для статей о клинических исследованиях в высокоэффективном специализированном медицинском журнале
Ann Intern Med. Авторская рукопись; доступно в PMC 2019 22 августа.
Авторская рукопись; доступно в PMC 2019 22 августа.
Опубликован в окончательной редакции как:
PMCID: PMC6705117
NIHMSID: NIHMS1044171
Melissa Assel
1 Департамент эпидемиологии и биостатистики, Нью-Йорк Йорк, Нью-Йорк, США
Эндрю Дж.Викерс
1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр им. Слоана Кеттеринга, Нью-Йорк, штат Нью-Йорк, США
1 Департамент эпидемиологии и биостатистики, Мемориальный онкологический центр им. Слоана Кеттеринга, Нью-Йорк, Нью-Йорк, США
Автор Вклад
Концепция и дизайн: VickersСбор, анализ или интерпретация данных: Assel, Vickers, Catto, Pierce, Redley, Le
Составление рукописи: Assel, Vickers
Критический пересмотр рукописи для важного интеллектуального содержания: Assel , Vickers
Статистический анализ: Assel, Vickers
Административная, техническая или материальная поддержка: Catto, Pierce, Redley, Le
. Корреспондент Эндрю Дж. Викерс, Мемориальный онкологический центр им. Слоуна Кеттеринга, 485 Lexington Avenue, New York, NY 10017 USA, gro.ccksm@asrekciv, (P): 646-888-8233 Доступна окончательная отредактированная версия этой статьи издателем в Ann Intern Med. См. другие статьи в PMC, в которых цитируется опубликованная статья.
Корреспондент Эндрю Дж. Викерс, Мемориальный онкологический центр им. Слоуна Кеттеринга, 485 Lexington Avenue, New York, NY 10017 USA, gro.ccksm@asrekciv, (P): 646-888-8233 Доступна окончательная отредактированная версия этой статьи издателем в Ann Intern Med. См. другие статьи в PMC, в которых цитируется опубликованная статья.Предпосылки
Принято считать, что статистический анализ должен выполняться путем написания кода хорошего качества в профессиональном статистическом пакете, таком как R, SAS или Stata.Хороший код обеспечивает воспроизводимость, снижает количество ошибок и предоставляет проверяемую документацию анализов, лежащих в основе результатов исследования. В последнее время было предпринято несколько попыток поощрения архивирования кода, соответствующего опубликованным статьям 1–5 , на том основании, что это улучшает прозрачность. Такие усилия были сосредоточены на таких областях, как нейробиология или биоинформатика, которые в значительной степени зависят от ресурсоемкого анализа.
Цель
Изучить, как часто авторы использовали статистический код для статей о клинических исследованиях, опубликованных в влиятельном специализированном журнале, и определить качество этого кода.
Методы и результаты
В середине 2016 года мы добавили в систему онлайн-подачи для European Urology вопрос о том, использовали ли авторы статистический код и, если да, готовы ли они представить, чтобы их статья была принято. В августе 2017 года мы рассмотрели 314 статей, впоследствии принятых в журнал. Авторы 40 статей сообщили, что использовали статистический код. Авторы заархивировали код 18 из этих статей в журнале, а остальные 32 отказались это сделать.
Мы случайным образом отобрали и просмотрели 50 статей, авторы которых не указали код. Из этих 50 35 не представили статистических данных (например, повествовательный обзор литературы) или только тривиальный анализ (например, единую кривую выживаемости). Остальные 15 включали в себя предметный анализ, такой как большое количество регрессионных моделей, графиков или статистики времени до события. Мы связались с авторами этих 15 статей; 8 сказали нам, что они не использовали код, но 7 ответили, что они действительно использовали код и что их первоначальный ответ был ошибочным.В 6 из этих 7 случаев авторы отказались предоставить свой код в журнал.
Мы связались с авторами этих 15 статей; 8 сказали нам, что они не использовали код, но 7 ответили, что они действительно использовали код и что их первоначальный ответ был ошибочным.В 6 из этих 7 случаев авторы отказались предоставить свой код в журнал.
Затем мы изучили все полученные наборы кодов, за исключением кода, связанного с 3 статьями, представленными авторами, прошедшими обучение в нашей группе. Большая часть кода практически не содержала аннотаций и часто повторялась. Для половины статей проверенный код не включал форматирование для презентации ().
Таблица 1.
Оценка кода 16 опубликованных статей.
| Домен | Оценка | N |
|---|---|---|
| Хорошо ли аннотированы коды? | Обширные аннотации, позволяющие практически воссоздать код, используя аннотации. | 0 |
| Умеренная аннотация, позволяющая воссоздать по крайней мере некоторый код на основе аннотаций. | 2 | |
| Аннотации мало или нет. | 14 | |
| Избегает ли код повторения? | Хорошее использование циклов и макросов, при котором существует мало или только тривиальный повторяющийся код. | 0 |
| Умеренное количество повторяющегося кода (около 10 строк или меньше). | 0 | |
Отсутствие циклов или макросов и частое повторение кода (10 строк и более). | 15 | |
| Не применимо; нет возможности для повторного кода. | 1 | |
| Включает ли код форматирование для презентации? | Язык разметки или другие методы, используемые для создания форматированного вывода, обеспечивающие все или почти все результаты статьи. | 3 |
| Язык разметки или другие методы, используемые для создания форматированного вывода, требуют нетривиальных поправок или многие результаты не отформатированы. | 5 | |
Нет форматированного вывода. | 8 |
Обсуждение
Никакой статистический код не использовался для более чем трети статей, опубликованных в влиятельном специализированном медицинском журнале, который включал статистический анализ, не связанный с исследованиями. Ни один набор кода не получил даже среднего балла по трем основным и общепринятым программным критериям. Это не поверхностная проблема. Например, отсутствие кода, форматирующего числовые данные, увеличивает риск ошибок транскрипции; повторяющийся код может привести к непоследовательности анализа.
У нас есть три рекомендации. Во-первых, методы и принципы программного обеспечения должны стать основной частью учебных программ по биостатистике, независимо от степени (бакалавриат или аспирантура) и предмета (биостатистика, общественное здравоохранение или эпидемиология). Учитывая, что студентам придется писать код, когда они придут выполнять анализ в качестве практикующих исследователей, нам трудно понять, почему немногие программы на получение степени в области количественной медицины преподают хорошую практику программирования. Во-вторых, должна проводиться очная экспертная оценка статистического кода.Коллеги должны регулярно делиться кодом друг с другом в целях конструктивной критики, так же как они делятся черновиками научных статей. В-третьих, код, связанный с опубликованными исследованиями, должен быть заархивирован. Это не только улучшит прозрачность и воспроизводимость, но также поможет обеспечить, чтобы исследователи писали более качественный код. Один следователь, с которым мы связались, сказал нам, что он не желает архивировать свой код в журнале, потому что он «не приложил никаких усилий, чтобы сделать его… пригодным для использования другими», в результате чего большая часть кода оказалась «грязной».Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Во-вторых, должна проводиться очная экспертная оценка статистического кода.Коллеги должны регулярно делиться кодом друг с другом в целях конструктивной критики, так же как они делятся черновиками научных статей. В-третьих, код, связанный с опубликованными исследованиями, должен быть заархивирован. Это не только улучшит прозрачность и воспроизводимость, но также поможет обеспечить, чтобы исследователи писали более качественный код. Один следователь, с которым мы связались, сказал нам, что он не желает архивировать свой код в журнале, потому что он «не приложил никаких усилий, чтобы сделать его… пригодным для использования другими», в результате чего большая часть кода оказалась «грязной».Мы считаем, что ценность хорошо написанного кода выходит далеко за рамки косметики, и что «грязный» код вполне может привести к научным ошибкам.
Отказ от использования кода статистического программирования или написание некачественного кода серьезно угрожает достоверности научных результатов. Мы призываем медицинское исследовательское сообщество принять немедленные меры по исправлению положения.
Выражение признательности
Финансирование
Эта работа была поддержана грантом MSKCC (номер гранта P30-CA008748) Национальным институтом здравоохранения / Национальным институтом рака.
Сноски
Нет конфликта интересов
Ссылки
1. Эглен С.Дж., Марвик Б., Хальченко Ю.О. и др. К стандартным практикам совместного использования компьютерного кода и программ в неврологии. Nat Neurosci 2017; 20 (6): 770–773. [Бесплатная статья PMC] [PubMed] [Google Scholar] 2. О’Нил К., Бринкман Р.Р. Публикация кода имеет важное значение для воспроизводимой биоинформатики проточной цитометрии. Цитометрия Часть A 2016; 89 (1): 10–11. [PubMed] [Google Scholar] 3. Герберт Р., Элкинс М. Код публикации: инициатива по повышению прозрачности анализа данных, представленных в журнале физиотерапии.Журнал физиотерапии 2017; 63 (3): 129–130. [PubMed] [Google Scholar]Постоянное улучшение качества статистического кода: предотвращение ошибок и повышение прозрачности
Введение
Четкое изложение статистических подходов может обеспечить хорошее понимание исследований в области здравоохранения, уменьшить количество серьезных ошибок и способствовать развитию науки. Тем не менее, в отличие от растущей сложности данных и анализов, опубликованных разделов о методах иногда недостаточно для описания необходимых деталей.Таким образом, обеспечение качества, прозрачности и воспроизводимости статистических подходов к исследованиям в области здравоохранения имеет важное значение.1 2
Тем не менее, в отличие от растущей сложности данных и анализов, опубликованных разделов о методах иногда недостаточно для описания необходимых деталей.Таким образом, обеспечение качества, прозрачности и воспроизводимости статистических подходов к исследованиям в области здравоохранения имеет важное значение.1 2
Подобные опасения носят не только теоретический характер, но и имеют прямое значение для исследований в области качества и безопасности. Например, Программа сокращения реадмиссии в больницы была учреждена в 2012 году Центрами медицинских услуг и услуг Medicaid (CMS) США и наложила финансовые штрафы на больницы с высоким процентом реадмиссии. Последующие исследования были направлены на определение степени, в которой эта программа была успешной в сокращении повторной госпитализации, не вызывая непредвиденных последствий, таких как повышение смертности.Четкое определение успеха или неудачи этой программы имеет важное значение, но в 2018 году в двух известных статьях, использующих один и тот же набор данных CMS, были представлены противоположные результаты.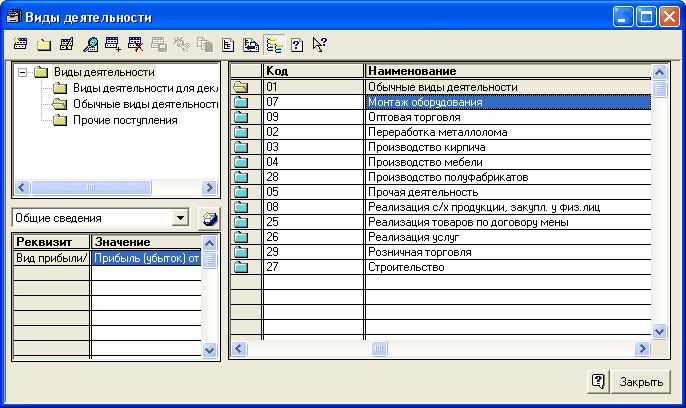 3 4 Эти конфликты, несомненно, связаны с различиями в аналитических решениях, но конкретные различия сложно согласовать с данными статистическими данными. код был недоступен для читателей. В другом недавнем примере основная статья была отозвана из-за обнаружения ошибки статистического кодирования, которая изменила категоризацию групп лечения и контроля.5 В этом клиническом испытании изучалась программа поддержки госпитализированных пациентов с хронической обструктивной болезнью легких, первоначально сообщалось о более низком риске госпитализации и посещения отделения неотложной помощи, но на самом деле было продемонстрировано, что программа поддержки была связана с причинением вреда. Оба случая демонстрируют, как передовые методы обмена статистическим кодированием на момент публикации могут улучшить качество исследования.
3 4 Эти конфликты, несомненно, связаны с различиями в аналитических решениях, но конкретные различия сложно согласовать с данными статистическими данными. код был недоступен для читателей. В другом недавнем примере основная статья была отозвана из-за обнаружения ошибки статистического кодирования, которая изменила категоризацию групп лечения и контроля.5 В этом клиническом испытании изучалась программа поддержки госпитализированных пациентов с хронической обструктивной болезнью легких, первоначально сообщалось о более низком риске госпитализации и посещения отделения неотложной помощи, но на самом деле было продемонстрировано, что программа поддержки была связана с причинением вреда. Оба случая демонстрируют, как передовые методы обмена статистическим кодированием на момент публикации могут улучшить качество исследования.
Хотя полезность статистического совместного использования кода может показаться самоочевидной, это происходит гораздо реже, чем можно было бы ожидать.2 Мы считаем, что основным препятствием для совместного использования статистического кода является…
Доступность статистического кода по результатам исследований с использованием данных Medicare в общих медицинских журналах | Медицинские журналы и публикации | JAMA Internal Medicine
Ограниченный доступ к статистическому коду (т. Е. Инструкциям по компьютерному программированию, используемым для выполнения анализа на основе данных исследований) после публикации статьи может быть препятствием для открытой науки, методологической строгости и воспроизводимости исследования. 1 , 2 В отличие от данных клинических исследований, которые могут вызвать проблемы с конфиденциальностью, обмен статистическим кодом должен быть простым. 3 Мы оценили доступность статистического кода по исследовательским статьям, опубликованным в ведущих медицинских журналах общего профиля, уделяя особое внимание исследованиям с использованием данных Medicare. 4
Е. Инструкциям по компьютерному программированию, используемым для выполнения анализа на основе данных исследований) после публикации статьи может быть препятствием для открытой науки, методологической строгости и воспроизводимости исследования. 1 , 2 В отличие от данных клинических исследований, которые могут вызвать проблемы с конфиденциальностью, обмен статистическим кодом должен быть простым. 3 Мы оценили доступность статистического кода по исследовательским статьям, опубликованным в ведущих медицинских журналах общего профиля, уделяя особое внимание исследованиям с использованием данных Medicare. 4
Мы провели поиск всех исследований, в которых упоминалось использование национальных наборов данных Medicare (часть A и / или B), опубликованных в 6 общих медицинских журналах в период с января 2017 года по декабрь 2018 года (eAppendix 1 в Приложении).Мы отправили электронное письмо с описанием нашего проекта соответствующим авторам определенных статей (eAppendix 2 в Приложении) до 3 раз в течение 6 недель с двухнедельными интервалами.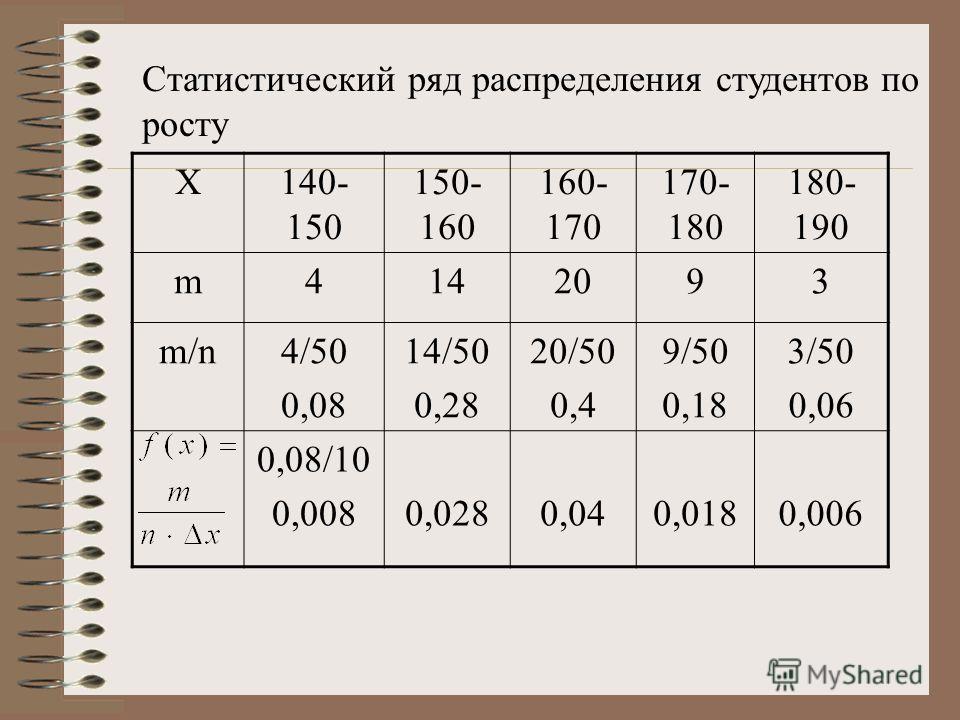 Мы запросили статистический код; когда код был доступен, один из нас (J.L.) оценивал, является ли он полным или частичным, консультируясь при необходимости со вторым автором (B.K.N.). Мы определили код как законченный, если он может полностью воспроизвести исследование от построения когорты до окончательных результатов. Мы также попросили соответствующих авторов заполнить анонимный опрос (eAppendix 3 в Приложении).Совет по институциональному обзору Мичиганского университета исключил это исследование из рассмотрения на людях и отказался от согласия.
Мы запросили статистический код; когда код был доступен, один из нас (J.L.) оценивал, является ли он полным или частичным, консультируясь при необходимости со вторым автором (B.K.N.). Мы определили код как законченный, если он может полностью воспроизвести исследование от построения когорты до окончательных результатов. Мы также попросили соответствующих авторов заполнить анонимный опрос (eAppendix 3 в Приложении).Совет по институциональному обзору Мичиганского университета исключил это исследование из рассмотрения на людях и отказался от согласия.
Мы идентифицировали 51 статью с 41 уникальным корреспондентом (рисунок). В одной статье сообщалось об отсутствии использования статистического кода. Из оставшихся 50 статей мы смогли получить код из 10; для 3 статистический код был общедоступен в Интернете, а для 7 его предоставили соответствующие авторы (таблица). Для 8 статей, в которых указывалось, что код доступен по запросу, код был предоставлен только для 3. Из 41 автора-корреспондента, с которым связались, 22 не ответили; из 19 ответивших заполнили анкету 16. Основные проблемы заключались в том, что код был недостаточно чистым, чтобы поделиться им (n = 2), неуверенность в том, как будет использоваться код (n = 3), а также время и усилия, затраченные на совместное использование кода (n = 3). Когда их спросили, поддержат ли они общедоступный онлайн-репозиторий кода, 12 из 16 авторов, заполнивших опрос, выразили поддержку.
Из 41 автора-корреспондента, с которым связались, 22 не ответили; из 19 ответивших заполнили анкету 16. Основные проблемы заключались в том, что код был недостаточно чистым, чтобы поделиться им (n = 2), неуверенность в том, как будет использоваться код (n = 3), а также время и усилия, затраченные на совместное использование кода (n = 3). Когда их спросили, поддержат ли они общедоступный онлайн-репозиторий кода, 12 из 16 авторов, заполнивших опрос, выразили поддержку.
Наше исследование обнаружило ограниченную доступность статистического кода для исследовательских статей с использованием данных Medicare в общих медицинских журналах.Возможны несколько объяснений. Наш запрос мог быть воспринят как расплывчатый или несерьезный, из-за чего некоторые авторы-корреспонденты были сдержаны из-за усилий, необходимых для подготовки статистического кода для распространения. Другие, возможно, не решались поделиться кодом из-за опасений по поводу цели нашего исследования или защиты интеллектуальной собственности. В другом случае (в котором участвовало несколько статей) автор-корреспондент сообщил о возможных препятствиях, связанных с требованиями разрешения спонсора.Наконец, некоторые учетные записи электронной почты могли стать неактивными или заблокированными, что привело к неполучению ответов. Поскольку нашей целью было оценить эффективность простого подхода к доступу к статистическому коду, мы не связывались с соавторами, когда мы не получали ответа от соответствующего автора, и не использовали неофициальные каналы связи.
В другом случае (в котором участвовало несколько статей) автор-корреспондент сообщил о возможных препятствиях, связанных с требованиями разрешения спонсора.Наконец, некоторые учетные записи электронной почты могли стать неактивными или заблокированными, что привело к неполучению ответов. Поскольку нашей целью было оценить эффективность простого подхода к доступу к статистическому коду, мы не связывались с соавторами, когда мы не получали ответа от соответствующего автора, и не использовали неофициальные каналы связи.
Несмотря на ограничения нашего исследования, эти результаты показывают, что ограниченная доступность статистического кода после публикации исследовательских статей с использованием данных Medicare может быть препятствием для воспроизводимости исследования.Наши результаты также предполагают, что традиционный обычай связываться с авторами после публикации может быть недостаточным для получения статистического кода. Одним из решений может быть то, что медицинские журналы поощряют или требуют представления статистического кода перед публикацией статьи. Этот подход будет аналогичен подходу в других областях, таких как фундаментальные науки 5 или экономика (например, где статистический код для исследований Medicare размещен на веб-сайте Американской экономической ассоциации 6 ).Журналы также могут основываться на политике обмена данными для клинических испытаний, одобренных Международным комитетом редакторов медицинских журналов, в соответствии с которой авторы должны указывать в статье, будут ли передаваться индивидуальные данные, что будет делиться и по каким критериям доступа, включая механизм.
Этот подход будет аналогичен подходу в других областях, таких как фундаментальные науки 5 или экономика (например, где статистический код для исследований Medicare размещен на веб-сайте Американской экономической ассоциации 6 ).Журналы также могут основываться на политике обмена данными для клинических испытаний, одобренных Международным комитетом редакторов медицинских журналов, в соответствии с которой авторы должны указывать в статье, будут ли передаваться индивидуальные данные, что будет делиться и по каким критериям доступа, включая механизм.
Принято к публикации: 14 февраля 2020 г.
Автор для корреспонденции: Брахмаджи К. Налламоту, доктор медицины, магистр здравоохранения, Мичиганский интегрированный центр аналитики здоровья и медицинского прогнозирования, Департамент внутренней медицины Медицинской школы Мичиганского университета, 2800 Plymouth Rd, Building 16, Room 132W, Ann Arbor, MI 48109-2800 (bnallamo @ med.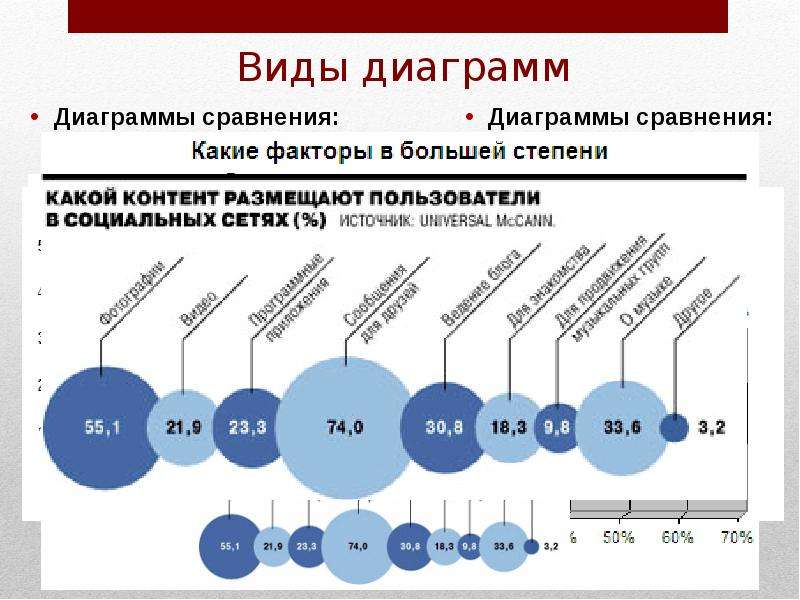 umich.edu).
umich.edu).
Опубликован онлайн: 13 апреля 2020 г. doi: 10.1001 / jamainternmed.2020.0671
Вклад авторов: Г-жа ДеБланк и доктор Налламоту имели полный доступ ко всем данным в исследовании и несут ответственность за целостность данные и точность анализа данных.
Концепция и дизайн исследования : ДеБлан, Кей, Лерич, Налламоту.
Сбор, анализ или интерпретация данных : Все авторы.
Составление рукописи : ДеБлан, Кей, Лерич.
Критический пересмотр рукописи на предмет важного интеллектуального содержания : Все авторы.
Статистический анализ : Lehrich, Kamdar.
Административная, техническая или материальная поддержка : DeBlanc, Kay, Lehrich, Nallamothu.
Научное руководство : ДеБлан, Кей, Налламоту.
Раскрытие информации о конфликте интересов: Д-р Камдар получил личные гонорары за консультации от Стэнфордского университета и Lucent Surgical, а также нефинансовую поддержку от Западного университета медицинских наук.Доктор Вэлли получил гранты от Национальных институтов здоровья. Д-р Аянян получал личные гонорары от сети JAMA за работу в качестве редактора JAMA Health Forum и от New England Journal of Medicine за работу в качестве члена Консультативного совета по перспективам. Доктор Налламоту получил личные гонорары от Американской кардиологической ассоциации за работу в качестве редактора журнала AHA Journals и за работу в качестве главного редактора журнала Circulation: Cardiovascular Quality & Outcomes ; владеет акциями AngioInsight Inc; является главным исследователем или соисследователем по грантам на исследования от Национальных институтов здравоохранения, Службы исследований и развития служб здравоохранения Министерства здравоохранения США по делам ветеранов, Американской кардиологической ассоциации, Apple и Toyota; и является соавтором патента на полезную продукцию США №US 15/356 012 (US 20170148158A1), который принадлежит Мичиганскому университету и лицензирован AngioInsight Inc. О других раскрытиях информации не сообщалось.
Дополнительные материалы: Мы ценим помощь Брэдли Трампауэра, магистр медицины (факультет внутренней медицины, Медицинская школа Мичиганского университета, Анн-Арбор), с форматированием и развертыванием опроса. Он не получил компенсации за свою работу.
4. муки KE, Liede А, Лю J, и другие.Использование базы данных Medicare в эпидемиологических исследованиях и исследованиях служб здравоохранения: ценный источник реальных данных о пожилых людях и инвалидах в США. Clin Epidemiol . 2017; 9: 267-277. DOI: 10.2147 / CLEP.S105613PubMedGoogle ScholarCrossrefСписки кодов — Статистика торговли Японии: Статистика торговли Министерства финансов Японии
- Статистический код (9 цифр)
В Японии 9-значные статистические коды используются для классификации товаров в таможенных декларациях.Следовательно, «Товар» означает товар, классифицированный на основе этого 9-значного статистического кода.
9-значный статистический код состоит из 6-значного кода HS и 3-значного внутреннего кода. Шестизначный код ГС согласован на международном уровне в соответствии с Конвенцией ГС (Международная конвенция о гармонизированной системе описания и кодирования товаров) и используется как для экспорта, так и для импорта. Таким образом, на основе 6-значного кода HS торговую статистику Японии можно сравнить со статистикой зарубежных стран. Трехзначные внутренние коды для экспорта и импорта не всегда одинаковы.Поэтому списки 9-значных статистических кодов для экспорта и импорта различаются.
Списки статистических кодов из 9 цифр
- Код основного товара
(Относительно «Основного товара» см. Глоссарий.)
Списки основных товарных кодов ниже включают описания и соответствующие статистические коды.
- 01.04.2021 (Экспорт , Импорт (HTML)) Новый
- 01.01.2021 (Экспорт, Импорт (HTML))
- 01.04.2020 (Экспорт, Импорт (HTML))
- 01.01.2020 (Экспорт, Импорт (HTML))
- 01.04.2019 (Экспорт, Импорт (HTML))
- 01.01.2019 (Экспорт, Импорт (HTML))
- 01.04.2018 (Экспорт, Импорт (HTML))
- 01.01.2018 (Экспорт, Импорт (HTML))
- 01.04.2017 (Экспорт, Импорт (HTML))
- 01.01. / 2017 (Экспорт, Импорт (HTML))
- 01.01.2016 (Экспорт, Импорт (HTML))
- 01.01.2015 (Экспорт, Импорт (HTML))
- 01.01.2014 (Экспорт, Импорт (HTML))
- 01.01.2013 (Экспорт, Импорт (HTML))
- 01.01.2012 (Экспорт, Импорт (HTML))
- 01.01.2011 (Экспорт, Импорт (HTML))
- 01.01.2010 (Экспорт, Импорт (HTML))
- 01.01.2009 (Экспорт, Импорт (HTML))
- 01.01.2008 (157 КБ, PDF)
- 01.01.2007 ( 158кб, PDF)
- 01.01.2006 (159kb, PDF)
- 01.01.2005 (160kb, PDF)
- 01.01.2004 (153kb, PDF)
- 01.01.2003 (132kb, PDF)
- 01 / 01/2002 (132 КБ, PDF)
- 01.01.2001 (129 КБ, PDF)
мод-инвентарь-хранилище / статистический-код-тип.raml на главном сервере · folio-org / mod-inventory-storage · GitHub
: mod-inventory-storage / statistics-code-type.raml на главном сервере · folio-org / mod-inventory-storage · GitHub Постоянная ссылка В настоящее время невозможно получить участников| #% RAML 1.0 | |
| название: Статистический код типа справочника API | |
| версия: v1.0 | |
| протоколов: [HTTP, HTTPS] | |
| baseUri: http: // localhost | |
| документация: | |
| — заголовок: Статистический справочник типов кода API | |
| Содержимое | : документирует вызовы API, которые могут быть выполнены для запроса и управления типами статистического кода системы |
| типов: | |
| statisticsCodeType:! Включает статистический код.json | |
| statisticsCodeTypes:! Include statisticscodetypes.json | |
| ошибок:! Include raml-util / schemas / errors.schema | |
| черт: | |
| pageable:! Include raml-util / traits / pageable.raml | |
| с возможностью поиска:! Include raml-util / traits / с возможностью поиска.raml | |
| язык:! Включают raml-util / traits / language.raml | |
| проверить:! Include raml-util / traits / validation.raml | |
| Типы ресурсов: | |
| Коллекция | :! Включают raml-util / rtypes / collection.raml |
| элемент коллекции:! Включают raml-util / rtypes / item-collection.raml | |
| / статистические-код-типы: | |
| тип: | |
| коллекция: | |
| exampleCollection:! Include examples / statisticscodetypes.json | .|
| exampleItem:! Include examples / statisticscodetype.json | |
| schemaCollection: statisticsCodeTypes | |
| schemaItem: statisticsCodeType | |
| получить: | |
| — это: [ | |
| с возможностью поиска: {описание: «с допустимыми доступными для поиска полями», пример: «name = aaa»}, | |
| страница | |
| ] | |
| Описание | : возвращает список типов статистических кодов |
| пост: | |
| Описание | : Создайте новый тип статистического кода |
| : [проверить] | |
| удалить: | |
| описание: «Удалить все типы статистических кодов» | |
| : [язык] | |
| ответов: | |
| 204: | |
| описание: «Все типы статистических кодов удалены» | |
| 500: | |
| Описание | : «Внутренняя ошибка сервера, e.грамм. из-за неправильной конфигурации « |
| кузов: | |
| текст / простой: | |
| пример: «Внутренняя ошибка сервера, обратитесь к администратору» | |
| / {statisticsCodeTypeId}: | |
| Описание | : передать статистический код типа ID |
| тип: | |
| экспоната: | |
| exampleItem:! Include examples / statisticscodetype.json | |
| Схема | : statisticsCodeType |

Об авторе