Вконтакте голоса: Как получить голоса в ВК бесплатно или купить: инструкция
«ВКонтакте» разрешила покупать голоса за бонусы от Сбербанка
Продолжение сюжета от
Новости СМИ2
Новости
Новости
Наталья Бархатова
Ex-новостной редактор (РБ.РУ)
Наталья Бархатова
«ВКонтакте» стала партнером программы «Спасибо» от Сбербанка. Теперь на бонусы от банка можно покупать голоса в соцсети. Об этом Rusbase рассказали в компании.
Наталья Бархатова
С 16 июля бонусы можно обменивать на фиксированное количество голосов «ВКонтакте»: 3, 5, 9, 10, 19, 20, 30, 40, 50 или 100.
Теперь при каждой покупке в мобильной и веб-версии «ВКонтакте» пользователям прямо в интерфейсе будет предложено использовать бонусы «Спасибо».
Голоса — внутренняя валюта «ВКонтакте». Их можно тратить на покупку стикеров и подарков, на оплату дополнительных возможностей в играх, но нельзя — на рекламу.
Один голос сейчас равен 7 рублям, уточнили в пресс-службе «ВКонтакте». Их можно купить через банковскую карту, мобильный телефон, платежные системы VK Pay, Qiwi, WebMoney, Pay Pal и другие.
Бонусы Сбербанка начисляются за покупки по карте. Ими впоследствии можно расплачиваться за товары и услуги партнеров программы.
- Сбербанк
- ВКонтакте
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 Как использовать новые правила рекламы VK и увеличить прибыль бизнеса: инструкция
- 2 VK будет платить студентам технических специальностей ежемесячную стипендию
- 3 «Яндекс» будет доставлять посылки, а VK станет монополистом на рынке медиа — прогнозы
- 5 VK запустила мини-приложение для помощи школьникам в IT-профориентации
ВОЗМОЖНОСТИ
28 октября 2022
Национальная технологическая олимпиада
30 октября 2022
Global Shift
30 октября 2022
«Технолидеры Москвы»
Все ВОЗМОЖНОСТИ
Новости
Бесплатную российскую ОС начали продавать в магазинах
Новости
ФАС проверит маркетплейсы и ритейлеров после жалоб о завышенных ценах на армейское снаряжение
Колонки
Должен ли работодатель содействовать военкоматам при вручении повестки работнику?
Колонки
Как переводить деньги в Европу из России в 2022 году?
Колонки
Тренировка памяти: советы и упражнения, которые помогут держать мозг в тонусе
Читать, а не слушать: как работает распознавание речи во «ВКонтакте» | by VK Team
Когда дело доходит до сообщений, читать их быстрее, чем слушать. Также легче просматривать текст, чтобы найти и проверить детали. Однако иногда бывают ситуации, когда гораздо удобнее просто отправить голосовое сообщение, чем набирать все подряд.
Также легче просматривать текст, чтобы найти и проверить детали. Однако иногда бывают ситуации, когда гораздо удобнее просто отправить голосовое сообщение, чем набирать все подряд.
Меня зовут Надя Зуева. В этой статье я расскажу, как мы в ВКонтакте смогли помочь помирить любителей и ненавистников голосовых сообщений с помощью автоматического распознавания речи. Я поделюсь с вами тем, как мы пришли к нашему решению, какие модели мы используем, на каких данных мы их обучали и как мы оптимизировали его для быстрой работы в продакшене.
Мы начали проводить исследования по распознаванию речи в голосовых сообщениях в 2018 году. Тогда мы думали, что это может стать крутой функцией продукта и настоящим вызовом для нашей исследовательской группы. Голосовые сообщения записываются в условиях, далеких от идеальных, люди говорят на сленге и не особо заботятся о правильной дикции. И в то же время распознавание речи должно быть быстрым. Тратить 10 минут на расшифровку 10-секундного голосового сообщения — не вариант.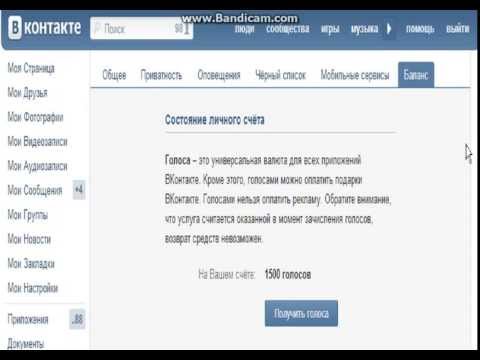
Вначале мы проводили все наши эксперименты с английской речью, так как на английском много хороших наборов данных, и научились их распознавать. Однако большая часть аудитории ВКонтакте говорит по-русски, и в открытом доступе не было российских наборов данных, которые мы могли бы использовать для обучения наших моделей. Сейчас с русскими наборами данных ситуация получше: есть «Голос» от Сбера, Common Voice от Mozilla и ряд других. Но до этого это была отдельная задача, которую нам нужно было решить, создав собственный набор данных.
Первая версия нашей модели была основана на wav2letter++ от Facebook AI Research и была готова к экспериментам в продакшене в 2019 году. Мы запустили ее в тихом режиме как функцию поиска голосовых сообщений. Благодаря этому мы смогли убедиться, что распознавание речи может быть полезно для преобразования голосовых сообщений в текст, и начали вкладывать больше ресурсов в создание этой технологии.
В начале 2020 года нашей задачей было нечто большее, чем просто создание точной модели. Нам нужно было увеличить производительность для нашей многомиллионной аудитории. Дополнительным вызовом для нас стал сленг. У нас не было другого выбора, кроме как выяснить, как его разобрать.
Нам нужно было увеличить производительность для нашей многомиллионной аудитории. Дополнительным вызовом для нас стал сленг. У нас не было другого выбора, кроме как выяснить, как его разобрать.
Теперь конвейер распознавания речи состоит из трех моделей. Первая — акустическая модель, отвечающая за распознавание звуков. Вторая — это языковая модель, которая формирует слова из звуков. И третья — это модель Punctuation, которая добавляет в текст знаки препинания. Мы рассмотрим каждую из этих моделей, но сначала давайте подготовим входные данные.
Для задач ASR первое, что вам нужно сделать, это преобразовать звук в формат, с которым может работать нейросеть. Сам по себе звук сохраняется в памяти компьютера в виде массива значений, показывающих колебания амплитуды во времени. Обычно частота дискретизации исчисляется десятками тысяч точек в секунду (или кГц), а получившийся трек получается очень длинным и сложным для работы. Поэтому перед прогоном через нейросеть звуки предварительно обрабатываются.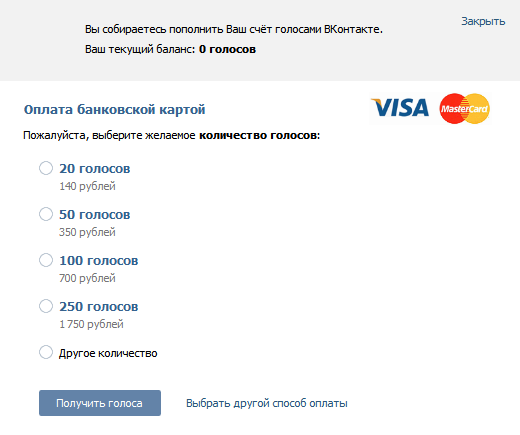 Они преобразуются в спектрограмму, которая показывает интенсивность звуковых колебаний на различных частотах с течением времени.
Они преобразуются в спектрограмму, которая показывает интенсивность звуковых колебаний на различных частотах с течением времени.
Подход с использованием спектрограммы считается консервативным. Есть и другие варианты, такие как wav2vec (который похож на word2vec в НЛП, но для звука). Несмотря на то, что современные модели ASR в настоящее время используют wav2vec, этот подход не обеспечил улучшения качества для нашей архитектуры.
После преобразования необработанного сигнала в удобный формат для использования с нейронными сетями мы готовы распознавать речь, получая вероятностное распределение фонем во времени по звуку.
Большинство подходов сначала создают фонетические транскрипции (по сути, «что слышно, то и написано»), а затем отдельная языковая модель «прочесывает» результат, исправляя грамматические и орфографические ошибки и удаляя лишние буквы.
Марковские модели использовались в качестве простых акустических моделей для распознавания речи (например, в элайнерах). Теперь нейронные сети заменили эти модели для полного распознавания речи, но марковские модели по-прежнему используются, например, для разбиения длинных аудиосигналов на более мелкие фрагменты.
Теперь нейронные сети заменили эти модели для полного распознавания речи, но марковские модели по-прежнему используются, например, для разбиения длинных аудиосигналов на более мелкие фрагменты.
В 2019 году, когда мы активно работали над этим проектом, уже существовало значительное количество архитектур распознавания речи, таких как DeepSpeech3 (SOTA 2018 на основе набора данных LibriSpeech). Он состоит из комбинации двух типов слоев — рекуррентного и сверточного. Повторяющиеся слои позволяют генерировать продолжения фраз с особым вниманием к ранее сгенерированным словам. А сверточные слои отвечают за извлечение признаков из спектрограмм. В статье об этой архитектуре авторы использовали для обучения CTC-loss. Это позволяет модели распознавать такие слова, как «Privye-e-e-et» и «Privyet» (по-английски «Hello-o-o-o» и «Hello») как одно и то же, не спотыкаясь о длину звука. Собственно, эта функция потерь используется и при распознавании рукописных текстов.
Чуть позже был выпущен wav2letter++ от FAIR. Что делало его уникальным, так это то, что он использовал только сверточные слои без авторегрессии (при авторегрессии мы смотрим на ранее сгенерированные слова и последовательно просматриваем их, что замедляет работу нейронной сети). Создатели wav2letter++ сосредоточились на скорости, поэтому он был создан с использованием C++. Мы начали с этой архитектуры при разработке нашего поиска голосовых сообщений.
Что делало его уникальным, так это то, что он использовал только сверточные слои без авторегрессии (при авторегрессии мы смотрим на ранее сгенерированные слова и последовательно просматриваем их, что замедляет работу нейронной сети). Создатели wav2letter++ сосредоточились на скорости, поэтому он был создан с использованием C++. Мы начали с этой архитектуры при разработке нашего поиска голосовых сообщений.
Использование полностью сверточных подходов открыло новые возможности для исследователей. Вскоре после этого появилась архитектура Jasper, которая также была полностью сверточной, но использовала идею остаточных соединений, как ResNet или трансформаторы. Затем появился QuartzNet от NVIDIA, основанный на Jasper. Это тот, который мы использовали.
Прямо сейчас есть Conformer, который является SOTA-решением на момент написания этой статьи.
Таким образом, независимо от того, какую архитектуру мы выбрали, нейронная сеть получает на вход спектрограмму и выводит матрицу распределения вероятностей каждой фонемы во времени. Эта таблица также называется эмиссионным набором.
Эта таблица также называется эмиссионным набором.
Используя жадный декодер, мы уже могли получить ответ из данных эмиссионного набора, выбрав наиболее вероятный звук для каждого момента времени.
Но этот подход мало что знает о правильном написании и, скорее всего, даст ответы с большим количеством ошибок. Чтобы исправить это, мы используем декодирование поиска луча с использованием взвешивания гипотез с использованием языковой модели.
После того, как мы получили набор эмиссии, нам нужно сгенерировать текст. Декодирование выполняется не только с использованием вероятностей, которые дает нам наша акустическая модель. Он также принимает во внимание «мнение» языковой модели. Это может сообщить нам, насколько вероятно встретить такое сочетание символов или слов в языке.
Для декодирования используем алгоритм поиска луча. Идея заключается в том, что мы не только выбираем наиболее вероятный звук для данного момента, но и вычисляем вероятность всей цепочки с учетом предыдущих слов и сохраняем лучших кандидатов на каждом шаге. В результате выбираем наиболее вероятный вариант.
В результате выбираем наиболее вероятный вариант.
При отборе кандидатов мы присваиваем каждому вероятность, принимая во внимание ответы акустической и языковой моделей. Вы можете увидеть формулу на картинке ниже.
Хорошо, мы рассмотрели расшифровку поиска луча. Теперь нам нужно посмотреть, на что способна языковая модель.
В качестве языковой модели мы использовали n-граммы. С точки зрения архитектуры этот подход работает достаточно хорошо, пока мы говорим о серверных (а не мобильных) решениях. Ниже вы можете увидеть пример для n=2.
Что здесь гораздо интереснее, так это то, как мы предварительно обрабатываем данные для обучения.
При письме туда и обратно люди часто используют сокращения, цифры и другие символы. Наша акустическая модель знает только буквы, поэтому в наших обучающих данных нам нужно различать ситуации, когда «1» означает «первый», а когда означает «один» или «один». Трудно найти много текстов с непринужденной речью, где люди пишут «отдайте мне 386 рублей до 20 декабря» вместо «отдайте 386 рублей до 20 декабря». Поэтому мы обучили дополнительную модель нормализации.
Поэтому мы обучили дополнительную модель нормализации.
В качестве архитектуры мы выбрали трансформатор, который часто используется для машинного перевода. Наша задача по-своему похожа на МТ. Нам нужно перевести денормализованный язык в нормализованный язык, в котором используются только символы алфавита.
Языковая модель дает нам последовательность слов, которые есть в языке и «идут вместе» друг с другом. Его намного легче читать и понимать, чем вывод акустической модели. Но для длинных сообщений результат все равно не очень хорош, потому что может быть некоторая двусмысленность.
После того, как мы получим читаемую строку слов, мы можем добавить знаки препинания. Это особенно полезно, когда текст длинный. Предложения, разделенные точками, читать намного легче, а в русском языке активно используются другие виды пунктуации, например, запятые. Даже в коротких предложениях они должны быть.
Архитектура, на которой основана наша модель пунктуации, представляет собой кодировщик из преобразователя и линейный слой. Он выполняет умную классификацию, предсказывая, нужна ли точка, запятая, тире или двоеточие после каждого слова или нет.
Он выполняет умную классификацию, предсказывая, нужна ли точка, запятая, тире или двоеточие после каждого слова или нет.
Подход к созданию обучающих данных здесь аналогичен. Мы берем тексты со знаками препинания в них и искусственно «портим» эти данные, убирая знаки препинания. Затем обучаем модель, чтобы вставить их обратно.
Как я упоминал в начале статьи, когда мы начинали наше исследование, в открытых источниках русскоязычных данных для обучения систем распознавания речи не было. Какое-то время мы экспериментировали с английским языком. Затем мы пришли к пониманию, что в любом случае нам нужны записи как можно более непринужденной речи, а не профессионально прочитанные аудиокниги, как в LibriSpeech.
В конце концов, мы решили сами собирать данные для обучения. Для этого мы привлекли Тестеров ВКонтакте. Мы готовили короткие тексты из 3–30 слов, которые нам диктовали в голосовых сообщениях. Тексты, которые должны были быть записаны, мы создавали сами на отдельной модели, которую обучали на комментариях публичных сообществ.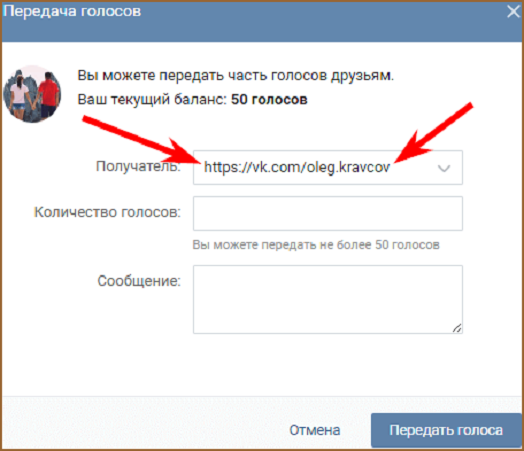 Таким образом, мы получили дистрибутив из того же домена, где распространены сленг и случайная речь. Мы попросили тестировщиков записывать голосовые сообщения в различных условиях и говорить как обычно, чтобы наши обучающие данные максимально походили на то, что будет использоваться в реальных жизненных ситуациях.
Таким образом, мы получили дистрибутив из того же домена, где распространены сленг и случайная речь. Мы попросили тестировщиков записывать голосовые сообщения в различных условиях и говорить как обычно, чтобы наши обучающие данные максимально походили на то, что будет использоваться в реальных жизненных ситуациях.
Как всем известно, путь от описанных в статьях моделей (и даже их реализации специалистами по машинному обучению) до реального использования машинного обучения в продакшене — долгий путь. Поэтому наша инфраструктурная команда ВКонтакте начала работу над сервисом распознавания голосовых сообщений в самом начале 2020 года, когда у нас еще была первая версия модели.
Команда по инфраструктуре помогла превратить наши решения машинного обучения в высоконагруженный, надежный сервис с высокой производительностью и эффективным использованием серверных ресурсов.
Одна из проблем заключалась в том, что мы в исследовательской группе работаем с файлами моделей и кодом C++, который их запускает. Но инфраструктура ВКонтакте в основном написана на Go, и нашим коллегам нужно было найти способ заставить C++ работать с Go. Для этого мы использовали расширение CGO, чтобы код более высокого уровня можно было писать на Go, а декодирование и общение с моделями оставалось на C++.
Но инфраструктура ВКонтакте в основном написана на Go, и нашим коллегам нужно было найти способ заставить C++ работать с Go. Для этого мы использовали расширение CGO, чтобы код более высокого уровня можно было писать на Go, а декодирование и общение с моделями оставалось на C++.
Наша следующая задача заключалась в том, чтобы обрабатывать голосовые сообщения в течение нескольких секунд, но заставить эту обработку работать с ограничениями нашего оборудования и эффективно использовать ресурсы сервера. Чтобы это стало возможным, мы сделали так, чтобы распознавание голоса работало на тех же серверах, что и другие сервисы. Это вызвало проблему с общим доступом к ядрам GPU и CUDA из нескольких процессов. Мы решили эту проблему с помощью технологии MPS от NVIDIA. MPS сводит к минимуму влияние блоков и простоев, позволяя нам использовать видеокарту на полную катушку без необходимости переписывать клиент.
Другим важным моментом, который следует учитывать, является группировка данных в пакеты для эффективной обработки на графическом процессоре. Дело в том, что в пакете акустической модели все аудиофайлы должны быть одинаковой длины. Поэтому нам нужно было уравнять их, добавив нули к более коротким дорожкам. Однако они также проходят через акустическую модель и занимают ресурсы GPU. В результате выравнивания на разбор коротких сообщений уходило больше времени и ресурсов.
Дело в том, что в пакете акустической модели все аудиофайлы должны быть одинаковой длины. Поэтому нам нужно было уравнять их, добавив нули к более коротким дорожкам. Однако они также проходят через акустическую модель и занимают ресурсы GPU. В результате выравнивания на разбор коротких сообщений уходило больше времени и ресурсов.
Полностью избавиться от лишних нулей невозможно из-за вариативности длины записи, но их количество можно уменьшить. Для этого команда инфраструктуры придумала способ разбивать длинные голосовые сообщения на 23-25-секундные фрагменты, сортировать все треки и группировать похожие по длине в небольшие пакеты, которые уже находятся в пути для отправки через сеть. видеокарта. Это разделение голосовых сообщений было сделано с помощью алгоритма VAD от WebRTC. Он помогает распознавать паузы и отправляет в акустическую модель полные слова, а не их фрагменты. Продолжительность 23–25 секунд была выбрана в результате экспериментов. Более короткие фрагменты вызывали снижение показателей качества распознавания, а более длинные требовалось чаще выравнивать .
Подход с разбиением длинных записей, помимо оптимизации производительности, позволил нам транскрибировать аудио практически любой длины в текст и открыл поле для экспериментов с ASR для других задач продукта, таких как автоматические субтитры.
В июне 2020 года мы запустили в производство распознавание голосовых сообщений для сообщений длиной до 30 секунд (в эту продолжительность укладывается около 90% всех таких сообщений). Затем мы оптимизировали сервис, интегрировав более интеллектуальный способ нарезки треков. С ноября 2020 года мы можем распознавать голосовые сообщения продолжительностью до двух минут (9 минут).9% всех голосовых сообщений). Наша инфраструктура готова к будущим проектам и позволит нам обрабатывать аудиофайлы продолжительностью в несколько часов.
Конечно, с момента запуска год назад многое изменилось. Мы обновили архитектуру акустической и языковой модели и добавили шумоподавление.
На данный момент весь пайплайн выглядит так:
- Получаем звуковую дорожку, предварительно ее обрабатываем и превращаем в спектрограмму.

- Если трек длиннее 25 секунд, мы разрезаем его с помощью VAD на фрагменты по 23–25 секунд. Этот вариант помогает нам не сокращать слова пополам.
- Далее все фрагменты прогоняются через акустическую (на основе QuartzNet) и языковую (с использованием n-грамм) модели.
- Затем все фрагменты собираются вместе и проходят через модель пунктуации с помощью нашей пользовательской архитектуры. Перед этим этапом мы также разбиваем слишком длинные тексты на сегменты по 400 слов.
- Мы объединяем все сегменты и даем пользователю расшифровку текста, которую он может быстро прочитать в любое время и в любом месте, экономя свое время.
Все это вместе образует уникальную услугу. Он может не только распознавать обыденную речь, сленг, ругательства и новые слова в шумной обстановке, но делает это быстро и эффективно. Вот процентили полного времени обработки голосового сообщения (без учета загрузки и отправки клиенту):
- 95-й процентиль: 1,5 секунды
- 99-й процентиль: 1,9 секунды
- 99,9-й процентиль: 2,5 секунды количество голосовых сообщений, отправляемых во «ВКонтакте», выросло на 24% по сравнению с прошлым годом.
 Ежемесячно 33 миллиона человек слушают и отправляют голосовые сообщения. Для нас это означает, что нашим пользователям нужны голосовые технологии и стоит инвестировать в разработку новых решений.
Ежемесячно 33 миллиона человек слушают и отправляют голосовые сообщения. Для нас это означает, что нашим пользователям нужны голосовые технологии и стоит инвестировать в разработку новых решений.Существует множество возможностей и перспектив для ASR. Чтобы оценить перспективы его внедрения в ваш продукт, у вас нет большого штата исследователей. Для начала можно попробовать доработать решения с открытым исходным кодом под свои задачи, а затем проводить собственные исследования и создавать новые технологии.
ВК / Что такое ВК
ВК / Что такое ВКВКонтакте разрабатывает сервисы для
, помогающие миллионам людей справляться со своими
повседневных задач онлайн.Цифры говорят сами за себя
ВК
100 м
ежемесячная аудитория
15 миллиардов
сообщений в день
9 млрд
поста просмотрено за день
ОК
50 млрд
виртуальных подарков в год
3,2 млрд
рублей выплат разработчикам игр в год
1 млрд
записи просмотров видео в день
ВКонтакте Pay
20+ м
клиенты
60+ м
транзакций каждый месяц
20+ м
связанные карты
Капсула
х 4
продажи умной колонки Capsula в 2021 году выросли в 4 раза по сравнению с 2020 годом
Объявления ВКонтакте
>37 м
пользователей общая аудитория объявлений ВКонтакте
RuStore
>1,5 м
пользователи магазина приложений
Электронная почта
№1
46 млн активных пользователей электронной почты только в России
Медиа проекты
>1 млрд
просмотров страниц в месяц в медиапроектах
- Показать ещё
История
Краткий обзор наших достижений
1998
Запуск Mail.


Об авторе