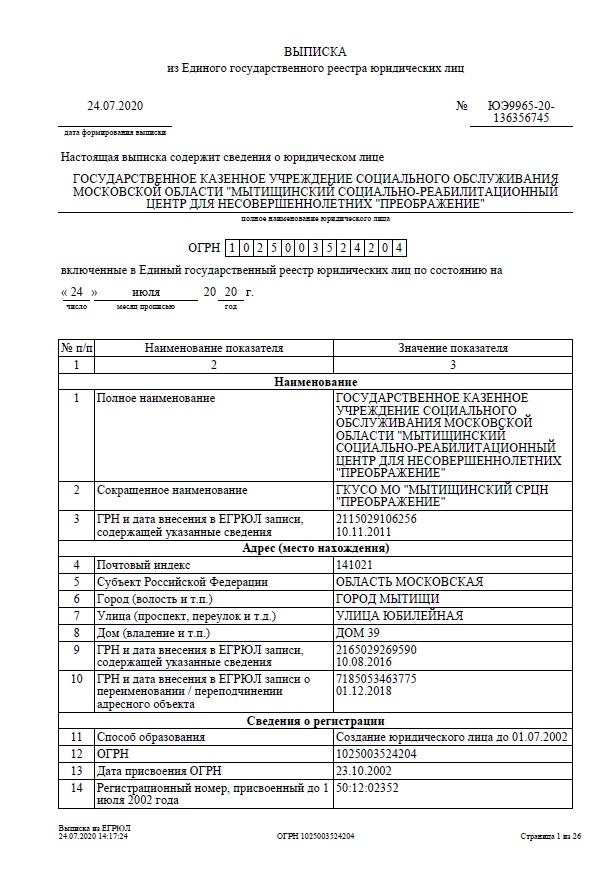
Выписка из егрюл как выглядит: Как выглядит выписка из ЕГРЮЛ – фото и образец документа
кто может сделать запрос, особенности оформления, для чего необходим документ
Главная / Калькулятор
Назад
Опубликовано: 06.04.2020
0
3
- 1 Сколько времени занимает оформление документа?
- 2 Как быстро заказать расширенную выписку из ЕГРН через интернет
- 3 Что такое ЕГРН и ЕГРП
- 4 Что нужно, чтобы заказать выписку их ЕГРН на физическое лицо
- 5 Бумажная или электронная выписка: какой формат выбрать?
- 6 Как быстро заказать расширенную выписку из ЕГРН через интернет
- 7 Остались вопросы?
- 8 Размер госпошлины
Как быстро заказать расширенную выписку из ЕГРН через интернет
Как выглядит расширенная выписка из ЕГРП? Справочные данные, распечатываемые на листах формата А4. В ней отражаются сведения из государственного реестра прав на недвижимость. С подобной документацией должен быть знаком каждый собственник имущества.
Виды выписок из ЕГРН бывают разными. Чаще всего пользуются обычной формой или ее расширенным вариантом.
Расширенная выписка из ЕГРН – как выглядит
В первом случае гражданин получает данные о конкретном объекте недвижимости. Соответствующие сведения хранит Росреестр РФ.
Что такое расширенная выписка из ЕГРН? Так называют сведения из Госреестра, которые дополняются сведениями о том, как переходили права на объект от человека к человеку, начиная с 1998 года.
Теперь выясним, как заказать расширенную выписку из ЕГРН на земельный участок или на иной объект недвижимости. Рассмотрим алгоритм действий по оформлению заказа в режиме оффлайн.
Расширенная выписка ЕГРН – план участка
1. Подготовить документы – паспорт, форму запроса, квитанцию с заранее внесенными средсвами, доверенность (если заявитель действует через представителя), правоустанавливающие документы на имущество.
2. Если ранее этого не было сделано, внести деньги на счет Росреестра.
3. Подать запрос в регистрирующий орган.
4. Подождать 3-10 дня и по паспорту забрать заказанную документацию.
Если требуется запросить данные о недвижимости, зарегистрированной до 1998 года, потребуется расширенная выписка из домовой книги. Она может быть запрошена в БТИ или в МФЦ.
Расширенная выписка из ЕГРН – раздел 2
Образец из домовой книги представлен выше. Иногда требуется осуществить заказ бумажек в срочном порядке. Возможно ли это? Или придется ждать несколько дней?
1. Перейти на сайт
Росреестра
.
2. Записать кадастровый номер. Также подойдет адрес имущества.
3. Выбрать конкретную недвижимость.
4. Определиться, какая именно справка потребуется в конечном итоге.
Рейтинг
( 1 оценка, среднее 4 из 5 )
Понравилась статья? Поделиться с друзьями:
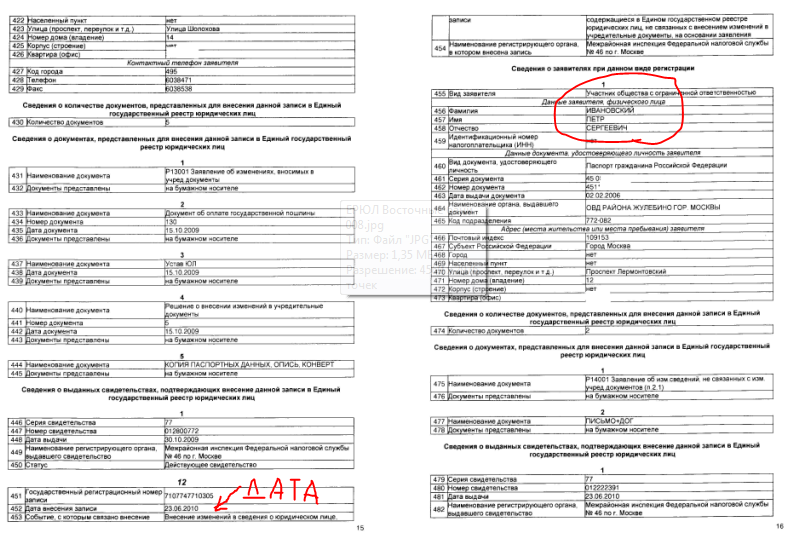
Проверяем сведения о недостоверности в выписках из ЕГРЮЛ.
 Склеиваем pdf на python / Хабр
Склеиваем pdf на python / ХабрВ настоящее время весьма актуальной темой остается возможность налогового органа исключить из ЕГРЮЛ общество всего лишь ”выявив” в отношении компании так называемые недостоверные сведения. Как показывает статистика с сентября 2018 года ФНС исключила из ЕГРЮЛ 90 тысяч организаций с записью о недостоверности сведений о руководителе, учредителе или адресе юрлица. Обнаружить тот факт, что в отношении компании имеются недостоверные сведения можно лишь просмотрев выписку из ЕГРЮЛ.
Выглядит это примерно следующим образом:
Проблема усугубляется тем, что данные о недостоверности могут появиться как по заявлению заинтересованного лица так и “сами по себе”, в результате действий налогового органа. Чтобы обезопасить себя от внезапного вылета из ЕГРЮЛ выписки требуется получать регулярно. Как это делать быстро и безболезненно при наличии в холдинге большого количества компаний, мы разобрали в предыдущем посте.
В этот раз разберем как искать сведения о недостоверности в выписках ЕГРЮЛ.
Будем считать, что у нас имеется n-е количество выписок, которые мы скачали с сайта ФНС. Выписки имеют расширение .pdf и какие-то наименования.
Все, что от нас требуется это осуществить поиск по слову “недост” в каждом pdf файле.
Открывать каждый pdf файл с выпиской и производить поиск не наш метод. Это может занять избыточно много времени. Можно склеить все файлы в Abbyy Finereader, но это тоже займет достаточно времени.
Напишем программу, которая склеит все pdf файлы в один. Python позволяет это сделать за секунды!
В дальнейшем мы сможем открыть созданный файл и провести поиск по требуемому слову сразу по всем выпискам из ЕГРЮЛ.
Начнем.
*Выписки из ЕГРЮЛ у нас находятся в директории С:\1.
В новом файле python импортируем модули для работы с pdf и системой в целом:
import PyPDF2, os
Далее создаем пустой список и перемещаемся в директорию C:\1, в которой будут находиться все наши выписки.
Данная директория не обязательно должна быть пустая. В программе мы предусмотрели обработку только тех файлов, которые имеют расширение pdf:
pdfFiles = []
os.chdir('C:\\1')
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
pdfFiles.append(filename)
pdfFiles.sort()
Следующий блок склеивает выписки между собой, добавляя каждую последующую выписку в конец:
pdfWriter = PyPDF2.PdfFileWriter()
# Loop through all the PDF files.
for filename in pdfFiles:
pdfFileObj = open(filename, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# Loop through all the pages and add them.
for pageNum in range(0, pdfReader.numPages):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
Осталось только сохранить результат:
pdfOutput = open('all.pdf', 'wb')
pdfWriter.write(pdfOutput)
pdfOutput.close()
Итак, после работы программы, мы получили файл all. pdf, по которому уже можно искать требуемую информацию о недостоверности сведений.
pdf, по которому уже можно искать требуемую информацию о недостоверности сведений.
Скачать программу для склейки pdf в один – здесь.
Продолжение от 08.11.2019
Нарезаем выписки ЕГРЮЛ, сохраняя от каждой выписки первые 4 страницы.
Сведения о недостоверности о юр. лице попадают в разные части выписки ЕГРЮЛ.
В конце выписки содержатся записи о недостоверности, которые были аннулированы налоговой.
Таким образом прогонять программу по целым выпискам ЕГРЮЛ вряд ли целесообразно: программа найдет и эти устаревшие записи.
Переместим все скачанные ранее выписки (pdf файлы) в условную папку по пути ‘C:\1\2’и выполним код python:
#! python3 import PyPDF2, os from datetime import datetime start = datetime.now() os.chdir('C:\\1\\2') pdfFiles = [] for filename in os.listdir('.'): if filename.endswith('.pdf'): pdfFiles.append(filename) pdfFiles.sort() pdfWriter = PyPDF2.PdfFileWriter() # Loop through all the PDF files. for filename in pdfFiles: pdfFileObj = open(filename, 'rb') pdfReader = PyPDF2.PdfFileReader(pdfFileObj) # Loop through all the pages and add them. for pageNum in range(0, 4): pageObj = pdfReader.getPage(pageNum) pdfWriter.addPage(pageObj) # Save the resulting PDF to a file. pdfOutput = open('all-small.pdf', 'wb') pdfWriter.write(pdfOutput) pdfOutput.close() print(datetime.now()- start)
 now()
os.chdir('C:\\1\\2')
pdfFiles = []
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
pdfFiles.append(filename)
pdfFiles.sort()
pdfWriter = PyPDF2.PdfFileWriter()
# Loop through all the PDF files.
for filename in pdfFiles:
pdfFileObj = open(filename, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# Loop through all the pages and add them.
for pageNum in range(0, 4):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
# Save the resulting PDF to a file.
pdfOutput = open('all-small.pdf', 'wb')
pdfWriter.write(pdfOutput)
pdfOutput.close()
print(datetime.now()- start)
now()
os.chdir('C:\\1\\2')
pdfFiles = []
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
pdfFiles.append(filename)
pdfFiles.sort()
pdfWriter = PyPDF2.PdfFileWriter()
# Loop through all the PDF files.
for filename in pdfFiles:
pdfFileObj = open(filename, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# Loop through all the pages and add them.
for pageNum in range(0, 4):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
# Save the resulting PDF to a file.
pdfOutput = open('all-small.pdf', 'wb')
pdfWriter.write(pdfOutput)
pdfOutput.close()
print(datetime.now()- start)
На выходе мы получим выписки ЕГРЮЛ, склеенные в единый pdf файл — «all-small.pdf». При чем от каждой выписки будут только первые 4 страницы.
Теперь прогоним «all-small.pdf» через поиск фразы «недостов»:
#!/usr/bin/python import fitz,os filename = "all-small.pdf" search_term = "недостов" pdf_document = fitz.
 open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
Программа работает заметно быстрее, чем поиск в едином склееном pdf файле через ‘Аcrobat reader’ и при этом выводит в терминал страницы, на которых были найдена недостоверность.
Как извлечь часть строковой переменной с помощью регулярных выражений?
Обработка строк в Stata довольно проста из-за множества встроенных строковых
функции. Среди этих строковых функций есть три функции, связанные с
регулярные выражения, regexm для сопоставления, regexr для замены и регулярных выражения для подвыражений. Мы покажем несколько примеров использования
регулярное выражение для извлечения и/или замены части строковой переменной
используя эти три функции. Внизу страницы пояснение
все операторы регулярных выражений, а также функции, которые работают с
обычные выражения.
Примеры
Пример 1. Исследователь имеет адреса в виде строковой переменной и хочет создать новую переменную который содержит только почтовые индексы.
Пример 2: У нас есть переменная, которая содержит полные имена в порядке первых имя, а затем фамилию. Мы хотим создать новую переменную с полным именем в порядок фамилии, а затем имени через запятую.
Пример 2: Даты вводились как строковая переменная, в некоторых случаях год вводился в виде четырехзначного числа
значение (это то, что Stata обычно ожидает увидеть), но в других случаях оно вводилось как двузначное
стоимость. Мы хотим создать переменную даты в числовом формате на основе этой строки.
переменная. С этой задачей можно легко справиться с помощью обычных команд Stata, см. нашу страницу часто задаваемых вопросов.
«Моя переменная даты — это строка, как я могу превратить ее в переменную даты, которую Stata может
распознавать?» для получения информации о том, как это сделать. Мы включили этот пример
здесь для демонстрационных целей, а не потому, что регулярные выражения обязательно
лучший способ справиться с этой ситуацией.
В этих ситуациях можно использовать регулярные выражения для определения случаев, в которых строка содержит набор значений (например, определенное слово, число, за которым следует слово и т. д.) и извлечь этот набор значений из всей строки для использования в другом месте.
Пример 1. Извлечение почтовых индексов из адресов
Начнем с некоторых поддельных адресов.
адрес ввода str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» "673 Жасмин Стрит, Лос-Анджелес, Калифорния" "2376 Первая улица, Сан-Диего, Калифорния
" "Уэст Сентрал Стрит, 6, Темпе, AZ 80068" «1234 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» конец
Чтобы найти почтовый индекс, мы будем искать пятизначное число в адресе. Команда gen (сокращение от «генерировать») ниже указывает Stata создать новую переменную с именем zip . Остальная часть команды немного сложна, сначала оценивается «if», if(regexm(address, «[0-9][0-9][0-9][0-9][0-9]»))
 Мы указываем
что мы хотим пятизначное число, указав «[0-9]»
пять раз. Если иное не указано с помощью *, + или ? знак, один и только один из
символы, содержащиеся в скобках, будут совпадать. Это означает, что нанизывание пяти из этих
выражения вместе позволят нам найти строку ровно из пяти цифр.
Обратите внимание, что 0-9указывает, что выражение должно соответствовать любому символу 0
до 9 (т. е. 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9 совпадают).
Мы указываем
что мы хотим пятизначное число, указав «[0-9]»
пять раз. Если иное не указано с помощью *, + или ? знак, один и только один из
символы, содержащиеся в скобках, будут совпадать. Это означает, что нанизывание пяти из этих
выражения вместе позволят нам найти строку ровно из пяти цифр.
Обратите внимание, что 0-9указывает, что выражение должно соответствовать любому символу 0
до 9 (т. е. 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9 совпадают). gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]"))
список
+------------------------------------------------- -------------+
| почтовый индекс |
|------------------------------------------------- -------------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния |
3. | 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 6 West Central St, Tempe AZ 80068 80068 |
5. | 1234 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 |
+------------------------------------------------- -------------+ Пример 1, вариантный номер 1
В приведенном выше упрощенном примере ни один из адресов не содержит пятизначных номеров улиц. числа. Что делать, если есть адреса с пятизначными номерами улиц? Давайте посмотрим
в другом наборе данных поддельных адресов и посмотреть, что происходит, когда мы пытаемся использовать
тот же код выше.
числа. Что делать, если есть адреса с пятизначными номерами улиц? Давайте посмотрим
в другом наборе данных поддельных адресов и посмотреть, что происходит, когда мы пытаемся использовать
тот же код выше.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас 77845» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния, » "2376 Первая улица, Сан-Диего, Калифорния
" "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238» конец gen zip = regexs(0) if(regexm(адрес, "[0-9][0-9][0-9][0-9][0-9]")) список +------------------------------------------------- ---------+ | почтовый индекс | |------------------------------------------------- ---------| 1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 77845 | 2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 66666 | 5.
 | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 12345 |
+------------------------------------------------- ---------+
| 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 12345 |
+------------------------------------------------- ---------+ Судя по всему, это работает некорректно, так как последние две строки переменная zip подобрали номера улиц для этих адресов вместо почтовых индексов. В этот набор данных, почтовый индекс появляется в конце адресной строки. Если мы предположим, что это относится ко всем адресам в данных, исправление будет очень просто. Мы можем указать «[0-9][0-9][0-9][0-9][0-9]$» который проинструктирует Stata найти пятизначное число в конце строки.
gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]$"))
список
+------------------------------------------------- ---------+
| почтовый индекс |
|------------------------------------------------- ---------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
|
3. | 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 66666 West Central St, Tempe AZ 80068 80068 |
5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 01238 |
+------------------------------------------------- ---------+  | 2376 Первая улица, Сан-Диего, Калифорния
| 2376 Первая улица, Сан-Диего, Калифорния Пример 1, номер варианта 2
Иногда почтовый индекс также включает четырехзначный добавочный номер и страну имя может также появляться в конце адреса, например, в некоторых адреса, указанные ниже.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния,» "2376 Первая улица, Сан-Диего, Калифорния
" "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» "12345 Мэйн-Сент-Соммервиль, Массачусетс, Массачусетс 01239.-2345" "12345 Мейн-Стрит Уотертвон, Массачусетс, Массачусетс, 01239, США" конец
В этом типе более реалистичной ситуации код в предыдущем
примеры не будут работать правильно, так как после zip есть лишние символы
код, который необходимо извлечь. Вот как мы можем это сделать, используя более сложный регулярный
выражение.
Вот как мы можем это сделать, используя более сложный регулярный
выражение.
gen zip = regexs(1) if regexm(address, "([0-9][0-9][0-9][0-9][0-9])[-]*[0-9 ]*[ a-zA-Z]*$")список+------------------------------------------------ --------------+ | почтовый индекс | |------------------------------------------------- -------------| 1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 | 2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 80068 | 5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 | |------------------------------------------------- -------------| 6. | 12345 Мейн-Стрит Соммервиль MA 01239-2345 01239 | 7. | 12345 Main St Watertwon MA 01239 США 01239 | +------------------------------------------------- -------------+
Мы добавили в регулярное выражение следующее: «[-]*[0-9]*[ a-zA-Z]*» . В этом регулярном выражении есть три компонента.
В этом регулярном выражении есть три компонента.
- [-]* – совпадение нуля или более дефисов «-»
- [0-9]* – совпадение нуля или более чисел
- [a-zA-Z]* — совпадение нуля или более пробелов или букв
Эти дополнения позволяют нам сопоставлять случаи, когда есть замыкающие символов после почтового индекса и для правильного извлечения почтового индекса. Заметь мы также использовали «регулярные выражения (1)» вместо «регулярных выражений (0)», как мы делали ранее, потому что мы теперь используют подвыражения, указанные парой скобок в « ([0-9][0-9][0-9][0-9][0-9]) «. Другая стратегия, которая может работать лучше в некоторых случаях, — это регулярное выражение
.gen zip2 = regexs(1) if(regexm(address, ".*([0-9][0-9][0-9][0-9][0-9])"))
В этом примере точка (т. е. «.») соответствует любому символу, а одна звездочка («*») соответствует любому
символы. Вместе, два
указать, что искомое число не должно встречаться в самом
начало строки, но может появиться в любом месте после.
Пример 2: Извлечение имени и фамилии и переключение их порядка
У нас есть переменная, которая содержит полное имя человека в порядке имени и затем фамилия. Мы хотим создать новую переменную для полного имени в порядке фамилия, а затем имя через запятую. Для начала давайте сделаем образец данных установлен.
прозрачный введите str40 полное имя "Джон Адамс" "Адам Смитс" "Мэри Смитс" "Чарли Уэйд" конец
Теперь нам нужно захватить первое слово и второе слово и поменять их местами. Здесь регулярное выражение для этой цели: (([a-zA-Z]+)[ ]*([a-zA-Z]+)).
Это регулярное выражение состоит из трех частей:
- ([a-zA-Z]+) — подвыражение , захватывающее строку, состоящую из буквы, как строчные, так и прописные. Это будет первое имя.
- [ ]* – совпадение с пробелами. Это расстояние между первым имя и фамилия.
- ([a-zA-Z]+) – подвыражение, захватывающее строку, состоящую из
буквы. Это будет фамилия.
 Это будет фамилия.
Это будет фамилия. gen n = regexs(2)+", "+regexs(1) if regexm(fullname, "([a-zA-Z]+)[ ]*([a-zA-Z]+)")
список
+-------------------------------+
| полное имя п |
|-------------------------------|
1. | Джон Адамс Адамс, Джон |
2. | Адам Смитс Смитс, Адам |
3. | Мэри Смитс Смитс, Мэри |
4. | Чарли Уэйд Уэйд, Чарли |
+---------------------------------------------+ Это действительно работает. Давайте посмотрим, как регулярных выражений работают в этом случае. регулярное выражение фактически идентифицирует ряд разделов на основе всего выражения, а также подвыражения. Следующий код использует регулярных выражения для размещения каждого из этих компоненты (подвыражения) в свою собственную переменную а затем отображает их.
gen n0 = regexs(0) if regexm(fullname, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n1 = regexs(2) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n2 = regexs(3) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
список полных имен n0 n1 n2
+------------------------------------------------+
| полное имя n0 n1 n2 |
|------------------------------------------------|
1. | Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+  | Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+
| Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+ Пример 3: Двух- и четырехзначные значения года.
В этом примере у нас есть даты, введенные как строковая переменная. Стата может справиться
это с помощью стандартных команд (см. «Моя переменная даты является строкой, как я могу
превратить его в переменную даты, которую Stata может распознать?»), мы используем это как пример того, что
вы могли бы сделать с регулярными выражениями. Целью этого процесса является создание строки
переменная с соответствующим четырехзначным годом для каждого случая, который Stata может
затем легко преобразовать в дату. Для этого начнем с разделения
вывести каждый элемент даты (день, месяц и год из двух или четырех цифр) в
отдельная переменная, то мы будем присваивать случаям правильный четырехзначный год
где в настоящее время только две цифры, наконец, мы объединяем переменные, чтобы создать одну
строковая переменная, которая содержит месяц, день и год из четырех цифр.
Сначала введите даты:
ввод даты str18 20 января 2007 г. 16 июня 2006 г. 06 сентября 1985 г. 21 июня 2004 г. 4июля90 9 января 1999 г. 6 августа 99 г. 19 августа 2003 г. конец
Далее мы хотим определить день месяца и поместить его в переменную позвонил день . Для этого мы проинструктируем Stata найти день, глядя на начало строки (т.е. дата), для одного или нескольких значений от 0 до 9. (Другими словами, ищите номер в начале строки, так как мы знаем, что первая серия чисел день.) Создать новую переменную 9[0-9]+»)
Строка синтаксиса ниже находит месяц, ища одну или несколько букв вместе в строке. Затем генерирует переменную month и устанавливает ее равной месяцу, указанному в строке.
gen month = regexs(0) if regexm(date, "[a-zA-Z]+")
В этом году все становится сложнее. Обратите внимание, что значения для присвоения
столетия основаны на моем знании моих «данных». Прежде всего, мы извлекаем все
цифры для года. Мы используем оператор «$», чтобы указать, что поиск ведется из
конец строки. Затем мы превращаем строковую переменную в числовую переменную
используя функцию Stata «real». Следующее действие включает в себя работу с двузначными годами
начиная с «0». Это соответствует последним годам двадцать первого века.
Чтобы превратить их в четырехзначные годы, мы объединяем (используя +) строку
идентифицируется (год из двух цифр) строкой «20». Далее мы найдем
двузначные годы 10-9[1-9][0-9]$») gen date2 = день+месяц+год список +————————————————- —+
| дата день месяц год date2 |
|————————————————- —|
1. | 20 января 2007 г. 20 января 2007 г. 20 января 2007 г. |
2. | 16 июня 2006 г. 16 июня 2006 г. 16 июня 2006 г. |
3. | 06 сентября 1985 г. 06 сентября 1985 г. 06 сентября 1985 г. |
4. | 21 июня 2004 г. 21 июня 2004 г. 21 июня 2004 г. |
5. | 4июля90 4 июля 1990 г.
Прежде всего, мы извлекаем все
цифры для года. Мы используем оператор «$», чтобы указать, что поиск ведется из
конец строки. Затем мы превращаем строковую переменную в числовую переменную
используя функцию Stata «real». Следующее действие включает в себя работу с двузначными годами
начиная с «0». Это соответствует последним годам двадцать первого века.
Чтобы превратить их в четырехзначные годы, мы объединяем (используя +) строку
идентифицируется (год из двух цифр) строкой «20». Далее мы найдем
двузначные годы 10-9[1-9][0-9]$») gen date2 = день+месяц+год список +————————————————- —+
| дата день месяц год date2 |
|————————————————- —|
1. | 20 января 2007 г. 20 января 2007 г. 20 января 2007 г. |
2. | 16 июня 2006 г. 16 июня 2006 г. 16 июня 2006 г. |
3. | 06 сентября 1985 г. 06 сентября 1985 г. 06 сентября 1985 г. |
4. | 21 июня 2004 г. 21 июня 2004 г. 21 июня 2004 г. |
5. | 4июля90 4 июля 1990 г. 4 июля 1990 г. |
|————————————————- —|
6. | 9 января 1999 г. 9 января 1999 г. 9 января 1999 г. |
7. | 6 августа 1999 г. 6 августа 1999 г. 6 августа 1999 г. |
8. | 19 августа 2003 г. 19 августа 2003 г. 19 августа 2003 г. |
+————————————————- —+
4 июля 1990 г. |
|————————————————- —|
6. | 9 января 1999 г. 9 января 1999 г. 9 января 1999 г. |
7. | 6 августа 1999 г. 6 августа 1999 г. 6 августа 1999 г. |
8. | 19 августа 2003 г. 19 августа 2003 г. 19 августа 2003 г. |
+————————————————- —+
Регулярные выражения
Регулярные выражения, как правило, являются способом поиска и в некоторых случаях замены появление шаблона в строке на основе набора правил. Эти правила определяется набором операторов. Последующий Таблица показывает все операторы, которые принимает Stata, и поясняет каждый из них. Обратите внимание, что в Стате, регулярные выражения всегда заключаются в кавычки.
[ ] Квадратные скобки означают, что один из символов внутри скобки должны совпадать. Например, если я хочу найти одна буква между f и m, я бы набрал «[f-m]» а-я Диапазон указывает, что допустимо любое значение в этом диапазоне. . Точка соответствует любому символу. Позволяет сопоставлять символы, которые обычно являются регулярными выражениями операторы. Например, если вы хотите сопоставить «[«, введите [ вместо всего один [. * Совпадает с нулем или более символов в предыдущем выражении. Например если бы я хотел сопоставить число, состоящее из одной или нескольких цифр, если есть число, но все же хотите указать совпадение, если остальная часть выражения подходит, я мог бы указать [0-9″ указывает что следующее выражение должно появиться в начале строки. $ Если в конце выражения появляется символ «$», это означает, что предыдущее выражение должно стоять в конце строки. | Логический оператор или, указывающий, что либо выражение предшествующий это или следующее за ним квалифицируется как совпадение. ( ) Создает подвыражение внутри большего выражения. Полезно с оператор «или» (т.е. | ), и при извлечении и замене значений. Например, если я хочу извлечь числовое значение, которое, как я знаю, следует сразу после слова или набора букв, я мог бы использовать регулярное выражение «[a-zA-Z]+([0-9]+)» соответствует всему выражение, но позволяет выбрать часть в скобках (называется подстрокой). Обработка подстрок обсуждается в более подробно ниже. Эти выражения можно комбинировать для поиска самых разных строк.
Как упоминалось выше, есть три типа функций, которые могут быть предварительно сформированы. с регулярными выражениями в Stata (если вы творческий человек, вы можете сделать любое количество другие вещи, использующие эти функции, но основными инструментами являются встроенные функции Stata).
- регулярное выражение — используется для поиска совпадающих строк, оценивается как единица, если есть совпадение, и ноль иначе
- регулярных выражений — используется для возврата n -й подстроки в выражении соответствует регулярному выражению (следовательно, регулярное выражение всегда должно запускаться перед регулярными выражениями, обратите внимание что «если» оценивается первым, даже если оно появляется позже в строке синтаксис).
- regexr — используется для замены совпадающего выражения чем-то другим.
Каждый из них имеет немного отличающийся синтаксис. Строка ниже показывает синтаксис для regexm , то есть функция, соответствующая вашему регулярному выражению, где строка может быть строкой, которую вы вводите сами, строкой из макроса или обычно имя переменной. Регулярное выражение является регулярным выражение для строки, которую вы хотите найти, обратите внимание, что оно должно появиться в кавычки.
регулярное выражение ( строка , " регулярное выражение ")Для регулярных выражений, то есть для вызова всей строки или ее части, используется следующий синтаксис:
регулярных выражений ( н )Где n — это номер, присвоенный подстроке, которую вы хотите извлечь. Подстроки фактически разделяются при запуске регулярного выражения. Вся подстрока возвращается нулем, и каждая подстрока последовательно нумеруется от 1 до n. За например, регулярное выражение(«907-789-3939», «([0-9]*)-([0-9]*)-([0-9]*)») возвращает следующее:
Подвыражение # Возвращенная строка 0 907-789-3939 1 907 2 789 3 3939 Обратите внимание, что в подвыражениях 1, 2 и 3 пропущены тире, так как они не заключаются в круглые скобки, которые отмечают подвыражения.
Вы можете еще раз взглянуть на то, как это работает, используя следующий синтаксис, который использует команду display для запуска функции.
отображать регулярное выражение("907-789-3939", "([0-9]*)-([0-9]*)-([0-9]*)") отображать регулярные выражения (0) отображать регулярные выражения (1) отображать регулярные выражения (2) отображать регулярные выражения (3)Поскольку это функции, команды регулярных выражений работают внутри других команд (например, генерировать), но не могут быть использованы сами по себе (т.е. вы не можете запустить команду в Stata с регулярное выражение(…)).
 Это чувствительно к регистру, поэтому az не совпадает с AZ, если любой регистр
может считаться совпадением, включая оба a-zA-Z. Числовые значения также
приемлемо в виде диапазонов (например, 0-9).
Это чувствительно к регистру, поэтому az не совпадает с AZ, если любой регистр
может считаться совпадением, включая оба a-zA-Z. Числовые значения также
приемлемо в виде диапазонов (например, 0-9). Стата имеет
отдельные команды для каждого из трех типов действий регулярных выражений могут
выполнить:
Стата имеет
отдельные команды для каждого из трех типов действий регулярных выражений могут
выполнить:
Артикул
Регулярные выражения: Использование модуля «re» для извлечения информации из строк | Мюриэль Косака
Различия между функциями findall(), match() и search() во встроенном модуле регулярных выражений Python. Photo by Abigail Lynn on Unsplash Регулярные выражения, также известные как Regex, пригодятся во множестве сценариев обработки текста. Вы можете искать шаблоны цифр, букв, знаков препинания и даже пробелов. Regex работает быстро и помогает избежать ненужных циклов в вашей программе для сопоставления и извлечения нужной информации. До недавнего времени я чувствовал, что Regex очень сложен, синтаксис выглядит разочаровывающим, и думал, что не смогу о нем узнать. Как и многие другие, мы разделяем это чувство.
Вы можете искать шаблоны цифр, букв, знаков препинания и даже пробелов. Regex работает быстро и помогает избежать ненужных циклов в вашей программе для сопоставления и извлечения нужной информации. До недавнего времени я чувствовал, что Regex очень сложен, синтаксис выглядит разочаровывающим, и думал, что не смогу о нем узнать. Как и многие другие, мы разделяем это чувство.
Прочитав много ресурсов в Интернете, я решил использовать этот пост, чтобы показать, как вы можете использовать модуль «re» в Python для решения определенных проблем с помощью функции findall() и кратко представить match(), и функции поиска(); все они похожи, но имеют разное применение.
Использование регулярных выражений в Python
Чтобы начать использовать Regex в Python, сначала необходимо импортировать модуль «re» Python
import re
Этот пост разделен на три раздела, в которых рассматриваются три простые функции для извлечения полезной информации из строк. с примерами.
с примерами.
- findall()
- match()
- search()
re.findall(): Поиск всех совпадений в строке/списке строк, содержащих все совпадения. Если шаблон не найден,
re.findall() возвращает пустой список. Давайте посмотрим, когда мы сможем использовать функцию findall() !- Извлечь все вхождения определенных слов
Используя следующий текстовый абзац, в котором описывается, как Рей, африканский пингвин, и Роза, самая старая морская выдра в Аквариуме залива Монтерей, нуждаются в глазных каплях.
аквариум='Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием. Это необычно для пингвина, и нашей команде по птицеводству было сложно помочь Рей преодолеть ее нерешительность. Медленно и неуклонно мы приучали ее к кормлению в воде, как и к остальной колонии пингвинов. Птицеводы также научили Рей принимать от них ежедневные глазные капли в рамках ее особого ухода за здоровьем.
 У Рей уже были хорошие отношения с некоторыми сотрудниками, и она чувствовала себя комфортно, когда они обращались с ней. Старший птицевод Ким Фукуда говорит, что команда построила эти связи, чтобы Рей привыкла получать глазные капли. «Она знает распорядок дня, — говорит Ким. «Обычно я даю ей глазные капли в одном месте выставки после того, как все пингвины получат свои витамины. Когда это происходит, она бежит туда и ждет меня». У Розы, нашей самой старой морской выдры, помимо других проблем со здоровьем, очень ограниченное зрение. Команда морских выдр уже обучила Розу осмотру ее глаз и, основываясь на этом доверии, ввела ей необходимые глазные капли».
У Рей уже были хорошие отношения с некоторыми сотрудниками, и она чувствовала себя комфортно, когда они обращались с ней. Старший птицевод Ким Фукуда говорит, что команда построила эти связи, чтобы Рей привыкла получать глазные капли. «Она знает распорядок дня, — говорит Ким. «Обычно я даю ей глазные капли в одном месте выставки после того, как все пингвины получат свои витамины. Когда это происходит, она бежит туда и ждет меня». У Розы, нашей самой старой морской выдры, помимо других проблем со здоровьем, очень ограниченное зрение. Команда морских выдр уже обучила Розу осмотру ее глаз и, основываясь на этом доверии, ввела ей необходимые глазные капли». Теперь вы хотите извлечь все вхождения Рей из текста, для чего вы должны сделать что-то вроде этого:
rey_occurences = "Рей"
re.findall(rey_occurences, аквариум)# Вывод
['Рей', ' Rey', 'Rey', 'Rey']
Функция findall() принимает два параметра, первый — это искомый шаблон, в нашем случае rey_occurrences , а второй параметр — это текст, который мы ищем, в нашем случае аквариум . Как видите, эта функция возвращает все непересекающиеся совпадения шаблона, который находится в rey_occurrences переменных, из второго параметра аквариум .
Как видите, эта функция возвращает все непересекающиеся совпадения шаблона, который находится в rey_occurrences переменных, из второго параметра аквариум .
Но подождите, есть еще один Рей, который не был учтен. Это произошло потому, что по умолчанию регулярные выражения чувствительны к регистру, поэтому наша функция findall() не вернула «rey», потому что это строчные, а не прописные буквы, как было определено в переменных rey_occurrences . Мы можем отредактировать наш предыдущий код, чтобы он включал значения искомого шаблона в нижнем регистре, включив третий параметр, флаги , которые можно использовать по разным причинам, например, чтобы шаблоны соответствовали определенным строкам, а не всему тексту, сопоставляли шаблоны, охватывающие несколько строк, и выполняли сопоставление без учета регистра. Для наших целей мы будем использовать флаг re.IGNORECASE , чтобы игнорировать регистр при выполнении поиска.
rey_occurences = "Rey"
re.findall(rey_occurences,aquarium,flags=re.IGNORECASE)# Вывод
['rey', 'Rey', 'Rey', 'Rey', 'Rey']
Мы можем также искать несколько шаблонов и извлекать все вхождения этих шаблонов. С нашим текущим текстом давайте также найдем вхождения «Розы», просто используя | Оператор для создания шаблона.
sea_animals="Рей|Роза"
re.findall(sea_animals,aquarium,flags=re.IGNORECASE)# Вывод
['rey', 'Rey', 'Rey', 'Rey', 'Rey', 'Rosa ', 'Роза']
| оператор — это специальный символ, который указывает Regex искать шаблон один или шаблон два в тексте. Если вы хотите найти вхождение «|» в вашем тексте вам нужно будет добавить его в свой шаблон с обратной косой чертой, «\| ». Эта обратная косая черта указывает Regex прочитать символ | оператор как символ без вывода его специального значения.
2. Извлечение слов, содержащих только буквы алфавита
Допустим, у вас есть текстовый документ, содержащий числа и слова, например:
подарки = "\
Баскетбол 2 25,63\
Футболка 4 53,92\
Кроссовки 1\
Mask 10 80.
GiftCard 2 50.00"
 54\
54\ Допустим, вы хотите извлечь только слова; мы можем сделать это, используя специальные последовательности и наборы Regex, чтобы указать шаблон, который мы ищем. Этот полезный сайт предоставляет хорошую шпаргалку по Regex.
words = '[az]+'
re.findall(words,gifts,flags=re.IGNORECASE)# Вывод
['Баскетбол', 'Футболка', 'Кроссовки', 'Маска', 'Подарочная карта']
При установке нашего шаблона на [az] это означает класс символов от «a» до «z», в то время как оператор + соответствует одному или нескольким повторениям предыдущего регулярного выражения или класса, который в нашем случае [az] . Обратите внимание, что шаблон [az] по-прежнему возвращает прописные буквы, это из-за нашего флага re.IGNORECASE .
3. Извлечение всех вхождений чисел
Мы показали только извлечение слов из текста, можем ли мы также извлекать числа? Конечно, используя регулярные выражения из другой полезной шпаргалки, мы можем извлечь числа из заданного текста:
text = "Шестьдесят шесть студентов бакалавриата городского колледжа в Нью-Йорке приняли участие в этом исследовании.
re.findall(numbers,text)# Результат
['36','18','52','20','52','6','97','10','18','28','23','5',' 12','36']
 Студенты участвовали в это исследование как часть требования для класса Девятнадцать участников были исключены из исследования за соответствие одному или нескольким критериям исключения, включая невыполнение задания на расшифровку предложений, непредоставление оценок по каждой из черт или невыполнение одного из двух проверки внимания, в результате чего общее число подходящих участников составило 47. Участниками были 36 женщин в возрасте от 18 до 52 лет (M = 20,52, SD = 6,9).7), 10 мужчин в возрасте от 18 до 28 лет (M = 23,5, SD = 12,36) и один человек, не сообщивший свой пол."numbers="\d+"
Студенты участвовали в это исследование как часть требования для класса Девятнадцать участников были исключены из исследования за соответствие одному или нескольким критериям исключения, включая невыполнение задания на расшифровку предложений, непредоставление оценок по каждой из черт или невыполнение одного из двух проверки внимания, в результате чего общее число подходящих участников составило 47. Участниками были 36 женщин в возрасте от 18 до 52 лет (M = 20,52, SD = 6,9).7), 10 мужчин в возрасте от 18 до 28 лет (M = 23,5, SD = 12,36) и один человек, не сообщивший свой пол."numbers="\d+" Установив наш шаблон в \d, это означает одну цифру, в то время как оператор + будет включать повторы цифр. Как вы можете видеть из нашего текста, у нас также есть десятичные дроби, но из нашего вывода они были разделены знаком «.» Мы можем исправить это, используя следующее регулярное выражение:
all_numbers="\d+\.
re.findall(all_numbers,text)# Вывод
['36', '18', '52', '20.52', '6.97', '10' , '18', '28', '23.5', '12.36']
Как мы видели ранее, наличие шаблона \d+ будет захватывать одну цифру, за которой следуют повторы цифр, чтобы включить десятичные дроби, мы используем шаблон .*? будет искать совпадение, используя как можно меньше символов.
4. Извлечение слов, за которыми следует определенный шаблон
При работе с текстовыми данными могут возникнуть ситуации, когда вам потребуется извлечь слова, за которыми следует специальный символ, например @ для имен пользователей или кавычек в данном тексте.
В нашем тексте аквариум есть две цитаты, давайте извлечем их из текста.
quotes='"(.*?)"'
re.findall(quotes,aquarium)# Output
['Она знает распорядок,',
'Обычно я даю ей глазные капли в одном месте выставки после все пингвины получают свои витамины. Когда это происходит, она бежит туда и ждет меня.
 ']
'] Мы устанавливаем наш шаблон на «(.+?)»‘, где одинарные кавычки представляют тело текста, а двойные кавычки представляют кавычки внутри текст. У нас есть скобка, которая создает группу захвата и .*? является нежадным модератором и извлекает только кавычки, а не текст между кавычками.
Как видите, функция findall() модуля Python Regex может быть очень полезна при поиске списка со всеми необходимыми совпадениями. Эту функцию иногда путают с функциями match() и search() одного и того же модуля. Кратко обсудим разницу.
re.match(): возвращает первое вхождение в тексте
В то время как re.findall() возвращает совпадения подстроки, найденной в тексте, re.match() ищет только с начала строки и возвращает объект соответствия, если он найден. Однако, если совпадение найдено где-то в середине строки, ничего не возвращается.
Выражение «w+» и «\W» будет соответствовать словам, начинающимся с буквы «r», и после этого все, что не начинается с «r», не идентифицируется. Чтобы проверить совпадение для каждого элемента в списке или строке, мы запускаем цикл for в этом примере Python re.match() :
Чтобы проверить совпадение для каждого элемента в списке или строке, мы запускаем цикл for в этом примере Python re.match() :
list = ["красная роза", "красный рубин", "розовый пион"]# Цикл.
для элемента в списке:
m = re.match("(r\w+)\W(r\w+)", element)if m:
print(m.groups())# Вывод
("красный", 'rose')
('ruby', 'red')
re.search(): Поиск шаблона в тексте
Функция re.search() будет искать шаблон регулярного выражения и возвращать первое вхождение. В отличие от Python re.match(), он проверяет все строки входной строки. Если шаблон найден, будет возвращен соответствующий объект, в противном случае возвращается «null».
Patterns=['penguin','Rosa']aquarium_short="Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием."for Pattern in Patterns:
print('Ищем "%s" в "%s" = '% (шаблон, аквариум_шорт), конец=" ")if re.search(шаблон, аквариум_шорт):
print("Соответствие найдено")
else:
print("Соответствие не найдено")# Результат
Поиск "пингвина" в "Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием.
 " = Совпадение найдено Ищет «Розу» в «Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием». = Совпадение не найдено
" = Совпадение найдено Ищет «Розу» в «Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием». = Совпадение не найдено В этом примере мы искали две строки «пингвин» и «Роза» в текстовой строке «Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием». Для «пингвина» мы нашли совпадение, поэтому он возвращает вывод «Совпадение найдено», а слово «Роза» не найдено в строке и возвращает «Совпадение не найдено».
В то время как re.search() ищет первое вхождение совпадения в строке, re.findall() ищет все вхождения совпадения, а re.search() совпадений в начало строки, а не в начале каждой строки. Дополнительные операции, которые можно использовать с модулем Python Regex, см. в документации.
re — Операции с регулярными выражениями — Документация по Python 3.9.1
Этот модуль обеспечивает операции сопоставления с регулярными выражениями, подобные тем, что используются в Perl.

Об авторе