Выписка статистика: Федеральная служба государственной статистики
Коды статистики Москва получить онлайн и распечатать Уведомление.
ТЕНДЕРЫ БИЗНЕС ПЛАНЫ МАРКЕТИНГОВЫЕ ИССЛЕДОВАНИЯ
Сформировать и распечатать уведомление с кодами статистики общероссийских классификаторов:
Юридическим лицам
Индивидуальным предпринимателям
В открывшейся вкладке можно получить коды статистики по ИНН, ОГРН или ОКПО. После нажатия кнопки Поиск должны отобразиться Ваши коды статистики Росстат, а также кнопка Сохранить или открыть в Word (печать). Нажав данную кнопку загрузится автоматически сформированное Уведомление в формате Word, которое и необходимо распечатать.
Адреса и контактные телефоны районных отделов территориального органа Федеральной службы государственной статистики по городу Москве для личного обращения:
Районные отделы статистики по городу Москва
Официальный сайт статистики по городу Москва
Что делать, если по моему запросу ничего не найдено?
После государственной регистрации информация поступает из налоговых органов в территориальный орган Федеральной службы государственной статистики, где вносится в базы данных. Информация в базах обновляется несколько раз в месяц, как правило, это происходит после 15 и 30-31 числа каждого месяца. Поэтому, если данных о Вас в базе ещё нет, а Уведомление нужно срочно, Вы можете лично с выпиской из ЕГРЮЛ или ЕГРИП обратиться в территориальную статистику по месту Вашей регистрации. Адреса и телефоны районных отделов статистики представлены выше.
Информация в базах обновляется несколько раз в месяц, как правило, это происходит после 15 и 30-31 числа каждого месяца. Поэтому, если данных о Вас в базе ещё нет, а Уведомление нужно срочно, Вы можете лично с выпиской из ЕГРЮЛ или ЕГРИП обратиться в территориальную статистику по месту Вашей регистрации. Адреса и телефоны районных отделов статистики представлены выше.
Внимание!
С 1 августа 2018 года осуществляется переход на единую базу Росстата, которая доступна по ссылке:
Получить Уведомление с кодами ОК ТЭИ
Сервис может не работать в выходные и праздничные дни. Возможно некорректное отображение в браузере Internet Explorer, работоспособность подтверждена в браузерах Chrome, Opera и Firefox. Если по каким-то причинам страница сервиса не открылась, обновите её, нажав клавишу F5, или попробуйте зайти позже.
ВЫБЕРИТЕ ВАШ СУБЪЕКТ РФ:
01 — Республика Адыгея
02 — Республика Башкортостан
03 — Республика Бурятия
04 — Республика Алтай
05 — Республика Дагестан
06 — Республика Ингушетия
07 — Кабардино-Балкарская Республика
08 — Республика Калмыкия
09 — Карачаево-Черкесская Республика
10 — Республика Карелия
11 — Республика Коми
12 — Республика Марий Эл
13 — Республика Мордовия
14 — Республика Саха (Якутия)
15 — Республ. Северная Осетия-Алания
Северная Осетия-Алания
16 — Республика Татарстан
17 — Республика Тыва
18 — Удмуртская Республика
19 — Республика Хакасия
20 — Чеченская Республика
21 — Чувашская Республика (Чувашия)
22 — Алтайский край
23 — Краснодарский край
24 — Красноярский край
25 — Приморский край
26 — Ставропольский край
27 — Хабаровский край
28 — Амурская область
29 — Архангельская область
30 — Астраханская область
31 — Белгородская область
32 — Брянская область
33 — Владимирская область
34 — Волгоградская область
35 — Вологодская область
36 — Воронежская область
37 — Ивановская область
38 — Иркутская область
39 — Калининградская область
40 — Калужская область
41 — Камчатский край
42 — Кемеровская область
43 — Кировская область
44 — Костромская область
45 — Курганская область
46 — Курская область
47 — Ленинградская область
48 — Липецкая область
49 — Магаданская область
50 — Московская область
51 — Мурманская область
52 — Нижегородская область
53 — Новгородская область
54 — Новосибирская область
55 — Омская область
56 — Оренбургская область
57 — Орловская область
58 — Пензенская область
59 — Пермский край
60 — Псковская область
61 — Ростовская область
62 — Рязанская область
63 — Самарская область
64 — Саратовская область
65 — Сахалинская область
66 — Свердловская область
67 — Смоленская область
68 — Тамбовская область
69 — Тверская область
70 — Томская область
71 — Тульская область
72 — Тюменская область
73 — Ульяновская область
74 — Челябинская область
75 — Забайкальский край (Читинская обл. )
)
76 — Ярославская область
77 — Город Москва
78 — Город Санкт-Петербург
79 — Еврейская автономная область
80 — Агинский Бурятский округ
83 — Ненецкий автономный округ
85 — Усть-Ордынский Бурятский округ
86 — Ханты-Мансийский АО — Югра
87 — Чукотский автономный округ
89 — Ямало-Ненецкий автономный округ
91 — Республика Крым
92 — Город Севастополь
Коды статистики Санкт-Петербург получить онлайн и распечатать Уведомление.
ТЕНДЕРЫ БИЗНЕС ПЛАНЫ МАРКЕТИНГОВЫЕ ИССЛЕДОВАНИЯ
Сформировать и распечатать уведомление с кодами статистики общероссийских классификаторов:
Юридическим лицам
Индивидуальным предпринимателям
В открывшейся вкладке можно получить коды статистики по ИНН, ОГРН или ОКПО. После нажатия кнопки Искать должны отобразиться Ваши коды статистики Росстат, а также кнопка Получить уведомление об учёте в статистическом регистре. Нажав данную кнопку загрузится автоматически сформированное Уведомление в формате Word, которое и необходимо распечатать.
Нажав данную кнопку загрузится автоматически сформированное Уведомление в формате Word, которое и необходимо распечатать.
Адреса и контактные телефоны районных отделов территориального органа Федеральной службы государственной статистики по городу Санкт-Петербургу для личного обращения:
Районные отделы статистики по городу Санкт-Петербургу
Официальный сайт статистики по городу Санкт-Петербургу
Что делать, если по моему запросу ничего не найдено?
После государственной регистрации информация поступает из налоговых органов в территориальный орган Федеральной службы государственной статистики, где вносится в базы данных. Информация в базах обновляется несколько раз в месяц, как правило, это происходит после 15 и 30-31 числа каждого месяца. Поэтому, если данных о Вас в базе ещё нет, а Уведомление нужно срочно, Вы можете лично с выпиской из ЕГРЮЛ или ЕГРИП обратиться в территориальную статистику по месту Вашей регистрации.
Внимание!
С 1 августа 2018 года осуществляется переход на единую базу Росстата, которая доступна по ссылке:
Получить Уведомление с кодами ОК ТЭИ
Сервис может не работать в выходные и праздничные дни. Возможно некорректное отображение в браузере Internet Explorer, работоспособность подтверждена в браузерах Chrome, Opera и Firefox. Если по каким-то причинам страница сервиса не открылась, обновите её, нажав клавишу F5, или попробуйте зайти позже.
ВЫБЕРИТЕ ВАШ СУБЪЕКТ РФ:
01 — Республика Адыгея
02 — Республика Башкортостан
03 — Республика Бурятия
04 — Республика Алтай
05 — Республика Дагестан
06 — Республика Ингушетия
07 — Кабардино-Балкарская Республика
08 — Республика Калмыкия
09 — Карачаево-Черкесская Республика
10 — Республика Карелия
11 — Республика Коми
12 — Республика Марий Эл
13 — Республика Мордовия
14 — Республика Саха (Якутия)
15 — Республ. Северная Осетия-Алания
Северная Осетия-Алания
16 — Республика Татарстан
17 — Республика Тыва
18 — Удмуртская Республика
19 — Республика Хакасия
20 — Чеченская Республика
21 — Чувашская Республика (Чувашия)
22 — Алтайский край
23 — Краснодарский край
24 — Красноярский край
25 — Приморский край
26 — Ставропольский край
27 — Хабаровский край
28 — Амурская область
29 — Архангельская область
30 — Астраханская область
31 — Белгородская область
32 — Брянская область
33 — Владимирская область
34 — Волгоградская область
35 — Вологодская область
36 — Воронежская область
37 — Ивановская область
38 — Иркутская область
39 — Калининградская область
40 — Калужская область
41 — Камчатский край
42 — Кемеровская область
43 — Кировская область
44 — Костромская область
45 — Курганская область
46 — Курская область
47 — Ленинградская область
48 — Липецкая область
49 — Магаданская область
50 — Московская область
51 — Мурманская область
52 — Нижегородская область
53 — Новгородская область
54 — Новосибирская область
55 — Омская область
56 — Оренбургская область
57 — Орловская область
58 — Пензенская область
59 — Пермский край
60 — Псковская область
61 — Ростовская область
62 — Рязанская область
63 — Самарская область
64 — Саратовская область
65 — Сахалинская область
66 — Свердловская область
67 — Смоленская область
68 — Тамбовская область
69 — Тверская область
70 — Томская область
71 — Тульская область
72 — Тюменская область
73 — Ульяновская область
74 — Челябинская область
75 — Забайкальский край (Читинская обл. )
)
76 — Ярославская область
77 — Город Москва
78 — Город Санкт-Петербург
79 — Еврейская автономная область
80 — Агинский Бурятский округ
83 — Ненецкий автономный округ
85 — Усть-Ордынский Бурятский округ
86 — Ханты-Мансийский АО — Югра
87 — Чукотский автономный округ
89 — Ямало-Ненецкий автономный округ
91 — Республика Крым
92 — Город Севастополь
Что такое извлечение данных? Определения и примеры
Статьи по теме
- Что такое хранилища данных?
- Что такое интеграция данных клиентов (CDI)?
- Talend Шаблоны проектирования заданий и передовой опыт: Часть 4
- Talend Шаблоны проектирования заданий и передовой опыт: Часть 3
- Что такое миграция данных?
Сегодня у нас есть доступ к большему количеству данных, чем когда-либо прежде . Вопрос в том, как извлечь из этого максимальную пользу? Для многих самая большая проблема заключается в поиске инструмента интеграции данных, который может управлять и анализировать многие типы данных из постоянно меняющегося множества источников. Но прежде чем эти данные можно будет проанализировать или использовать, их необходимо сначала извлечь. В этой статье мы определим значение термина «извлечение данных» и подробно рассмотрим процесс ETL, чтобы понять критическую роль, которую извлечение играет в процессе интеграции данных.
Но прежде чем эти данные можно будет проанализировать или использовать, их необходимо сначала извлечь. В этой статье мы определим значение термина «извлечение данных» и подробно рассмотрим процесс ETL, чтобы понять критическую роль, которую извлечение играет в процессе интеграции данных.
Что такое извлечение данных?
Извлечение данных — это процесс сбора или извлечения разрозненных типов данных из различных источников, многие из которых могут быть плохо организованы или совершенно неструктурированы. Извлечение данных позволяет консолидировать, обрабатывать и уточнять данные, чтобы их можно было хранить в централизованном месте для преобразования. Эти местоположения могут быть локальными, облачными или гибридными.
Извлечение данных является первым шагом как в процессах ETL (извлечение, преобразование, загрузка), так и в процессах ELT (извлечение, загрузка, преобразование). ETL/ELT сами по себе являются частью полной стратегии интеграции данных.
Извлечение данных и ETL
Чтобы представить важность извлечения данных в контексте, полезно кратко рассмотреть процесс ETL в целом. По сути, ETL позволяет компаниям и организациям 1) консолидировать данные из разных источников в централизованном месте и 2) объединять различные типы данных в общий формат. Процесс ETL состоит из трех этапов:
По сути, ETL позволяет компаниям и организациям 1) консолидировать данные из разных источников в централизованном месте и 2) объединять различные типы данных в общий формат. Процесс ETL состоит из трех этапов:
- Извлечение : данные берутся из одного или нескольких источников или систем. Извлечение находит и идентифицирует релевантные данные, а затем подготавливает их к обработке или преобразованию. Извлечение позволяет объединять множество различных типов данных и в конечном итоге использовать их для бизнес-аналитики.
- Преобразование : После успешного извлечения данных их можно уточнить. На этапе преобразования данные сортируются, систематизируются и очищаются. Например, повторяющиеся записи будут удалены, отсутствующие значения удалены или дополнены, а проверки будут выполняться для получения надежных, непротиворечивых и пригодных для использования данных.
- Загрузка : Преобразованные высококачественные данные затем доставляются в единое унифицированное целевое место для хранения и анализа.

Процесс ETL используется компаниями и организациями практически во всех отраслях для многих целей. Например, компании GE Healthcare требовалось извлекать множество типов данных из целого ряда локальных и облачных источников, чтобы оптимизировать процессы и обеспечить соответствие требованиям. Извлечение данных стало возможным консолидировать и интегрировать данные, связанные с уходом за пациентами, поставщиками медицинских услуг и страховыми случаями.
Точно так же розничные продавцы, такие как Office Depot, могут собирать информацию о клиентах через мобильные приложения, веб-сайты и транзакции в магазине. Но без возможности переноса и объединения всех этих данных его потенциал может быть ограничен. Здесь снова ключом является извлечение данных.
Извлечение данных без ETL
Может ли извлечение данных происходить вне ETL? Короткий ответ: да. Однако важно помнить об ограничениях извлечения данных за пределами более полного процесса интеграции данных. Необработанные данные, которые извлечены, но не преобразованы или загружены должным образом, скорее всего, будет трудно организовать или проанализировать, и они могут быть несовместимы с более новыми программами и приложениями. В результате данные могут быть полезны для архивных целей, но не более того. Если вы планируете переместить данные из устаревших баз данных в новую или облачную систему, вам лучше извлечь данные с помощью полного инструмента интеграции данных.
Необработанные данные, которые извлечены, но не преобразованы или загружены должным образом, скорее всего, будет трудно организовать или проанализировать, и они могут быть несовместимы с более новыми программами и приложениями. В результате данные могут быть полезны для архивных целей, но не более того. Если вы планируете переместить данные из устаревших баз данных в новую или облачную систему, вам лучше извлечь данные с помощью полного инструмента интеграции данных.
Другим последствием извлечения данных в качестве автономного процесса будет потеря эффективности, особенно если вы планируете выполнять извлечение вручную. Ручное кодирование может быть кропотливым процессом, который подвержен ошибкам и его трудно воспроизвести при нескольких извлечениях. Другими словами, сам код, возможно, придется перестраивать с нуля каждый раз, когда происходит извлечение.
Преимущества использования инструмента извлечения
Компаниям и организациям практически во всех отраслях и секторах рано или поздно потребуется извлекать данные.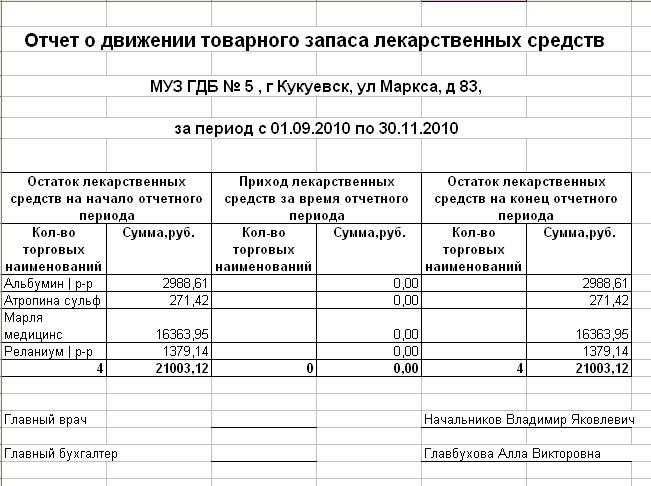 У некоторых потребность возникнет, когда придет время обновить устаревшие базы данных или перейти на облачное хранилище. Для других мотивом может быть желание консолидировать базы данных после слияния или поглощения. Компании также часто хотят оптимизировать внутренние процессы, объединяя источники данных из разных подразделений или отделов.
У некоторых потребность возникнет, когда придет время обновить устаревшие базы данных или перейти на облачное хранилище. Для других мотивом может быть желание консолидировать базы данных после слияния или поглощения. Компании также часто хотят оптимизировать внутренние процессы, объединяя источники данных из разных подразделений или отделов.
Если перспектива извлечения данных кажется сложной задачей, это не обязательно так. Фактически, большинство компаний и организаций теперь используют инструменты извлечения данных для управления процессом извлечения от начала до конца. Использование инструмента ETL автоматизирует и упрощает процесс извлечения, чтобы ресурсы можно было использовать для решения других задач. Преимущества использования инструмента извлечения данных включают:
- Больше контроля . Извлечение данных позволяет компаниям переносить данные из внешних источников в свои собственные базы данных. В результате вы можете избежать разрознивания данных из-за устаревших приложений или лицензий на программное обеспечение.
 Это ваши данные, и извлечение позволяет вам делать с ними все, что вы хотите.
Это ваши данные, и извлечение позволяет вам делать с ними все, что вы хотите. - Повышенная маневренность . По мере роста компаний им часто приходится работать с разными типами данных в отдельных системах. Извлечение данных позволяет объединить эту информацию в централизованную систему, чтобы объединить несколько наборов данных.
- Упрощенный обмен . Для организаций, которые хотят поделиться некоторыми, но не всеми своими данными с внешними партнерами, извлечение данных может быть простым способом предоставления полезного, но ограниченного доступа к данным. Извлечение также позволяет обмениваться данными в обычном удобном формате.
- Точность и точность . Ручные процессы и ручное кодирование увеличивают вероятность ошибок, а необходимость ввода, редактирования и повторного ввода больших объемов данных негативно сказывается на целостности данных. Извлечение данных автоматизирует процессы, чтобы уменьшить количество ошибок и сократить время, затрачиваемое на их устранение.

Типы извлечения данных
Извлечение данных — это мощный и адаптируемый процесс, который может помочь вам собрать множество типов информации, имеющей отношение к вашему бизнесу. Первый шаг к тому, чтобы извлечение данных работало на вас, — определить, какие типы данных вам понадобятся. Типы данных, которые обычно извлекаются, включают:
- Данные о клиентах : Это тип данных, которые помогают предприятиям и организациям понять своих клиентов и доноров. Он может включать имена, номера телефонов, адреса электронной почты, уникальные идентификационные номера, историю покупок, активность в социальных сетях и поиск в Интернете, и это лишь некоторые из них.
- Финансовые данные : Эти типы показателей включают объемы продаж, затраты на покупку, операционную прибыль и даже цены ваших конкурентов. Этот тип данных помогает компаниям отслеживать производительность, повышать эффективность и осуществлять стратегическое планирование.
- Данные об использовании, задачах или процессах : Эта широкая категория данных включает информацию, относящуюся к конкретным задачам или операциям.
 Например, розничная компания может запросить информацию о своей логистике доставки, или больница может захотеть отслеживать послеоперационные результаты или отзывы пациентов.
Например, розничная компания может запросить информацию о своей логистике доставки, или больница может захотеть отслеживать послеоперационные результаты или отзывы пациентов.
После того, как вы определились с типом информации, к которой хотите получить доступ и проанализировать, следующие шаги: 1) выяснить, где вы можете ее получить и 2) решить, где вы хотите ее хранить . В большинстве случаев это означает перемещение данных из одного приложения, программы или сервера в другое.
Типичная миграция может включать данные из таких служб, как SAP, Workday, Amazon Web Services, MySQL, SQL Server, JSON, SalesForce, Azure или Google Cloud. Это лишь некоторые примеры широко используемых приложений, но данные практически из любой программы, приложения или сервера могут быть перенесены.
Извлечение данных в движении
Готовы узнать, как извлечение данных может решить реальные проблемы? Вот как две организации смогли упростить и организовать свои данные, чтобы максимизировать их ценность.
Большие данные Domino’s
Domino’s — крупнейшая компания по производству пиццы в мире, и одной из причин этого является способность компании получать заказы с помощью широкого спектра технологий, включая смартфоны, часы, телевизоры и даже социальные сети. Все эти каналы генерируют огромные объемы данных, которые Domino’s необходимо интегрировать, чтобы получить представление о своих глобальных операциях и предпочтениях клиентов.
Для консолидации всех этих источников данных Domino’s использует платформу управления данными для управления своими данными от извлечения до интеграции. Работая на собственных облачных серверах Domino, эта система захватывает и собирает данные из систем торговых точек, 26 центров цепочки поставок и по таким различным каналам, как текстовые сообщения, Twitter, Amazon Echo и даже Почтовая служба США. Затем их платформа управления данными очищает, обогащает и сохраняет данные, чтобы к ним можно было легко получить доступ и использовать несколько команд.
Развитие образования с помощью интеграции данных
Ежегодно более 17 000 студентов посещают Ньюкаслский университет в Великобритании. Это означает, что школа генерирует 60 потоков данных по своим различным отделам, подразделениям и проектам. Чтобы собрать все эти данные в единый поток, Newcastle поддерживает архитектуру с открытым исходным кодом и комплексную платформу управления данными для извлечения и обработки данных из каждого источника происхождения. В результате получается экономичное и масштабируемое решение, которое позволяет университету направлять больше ресурсов на студентов и тратить меньше времени и денег на мониторинг процесса интеграции данных.
Облако, Интернет вещей и будущее извлечения данных
Появление облачных хранилищ и облачных вычислений оказало большое влияние на то, как компании и организации управляют своими данными. Помимо изменений в безопасности, хранении и обработке данных, облако сделало процесс ETL более эффективным и адаптируемым, чем когда-либо прежде. Теперь компании могут получать доступ к данным со всего мира и обрабатывать их в режиме реального времени без необходимости поддерживать собственные серверы или инфраструктуру данных. Благодаря использованию гибридных и облачных вариантов данных все больше компаний начинают перемещать данные из устаревших локальных систем.
Теперь компании могут получать доступ к данным со всего мира и обрабатывать их в режиме реального времени без необходимости поддерживать собственные серверы или инфраструктуру данных. Благодаря использованию гибридных и облачных вариантов данных все больше компаний начинают перемещать данные из устаревших локальных систем.
Интернет вещей (IoT) также меняет ландшафт данных. В дополнение к мобильным телефонам, планшетам и компьютерам данные теперь генерируются носимыми устройствами, такими как FitBit, автомобилями, бытовой техникой и даже медицинскими устройствами. Результатом является постоянно растущий объем данных, которые можно использовать для повышения конкурентоспособности компании после того, как данные будут извлечены и преобразованы.
Извлечение данных на ваших условиях
Вы приложили усилия для сбора и хранения огромных объемов данных, но если данные находятся в недоступном формате или в недоступном месте, вы упускаете важные идеи и возможности для бизнеса . И с каждым днем появляется все больше и больше источников данных, и проблема не будет решена без правильной стратегии и правильных инструментов.
И с каждым днем появляется все больше и больше источников данных, и проблема не будет решена без правильной стратегии и правильных инструментов.
Платформа управления данными Talend предоставляет полный набор инструментов для работы с данными, включая ETL, интеграцию данных, качество данных, сквозной мониторинг и безопасность. Адаптивное и эффективное управление данными избавляет вас от догадок из всего процесса интеграции, поэтому вы можете извлекать данные, когда они вам нужны, для получения бизнес-идеи, когда вам это нужно. Развертывайте где угодно: локально, гибридно или в облаке. Начните бесплатную пробную версию сегодня, чтобы увидеть, насколько легко извлекать данные на ваших условиях.
Готовы начать работу с Talend?
Связаться с отделом продаж
Другие статьи по теме
- Что такое хранилища данных?
- Что такое интеграция данных клиентов (CDI)?
- Talend Шаблоны проектирования заданий и передовой опыт: Часть 4
- Talend Шаблоны проектирования заданий и передовой опыт: Часть 3
- Что такое миграция данных?
- Что такое отображение данных?
- Что такое интеграция с базой данных?
- Что такое интеграция данных?
- Понимание миграции данных: стратегия и передовой опыт
- Шаблоны проектирования заданий Talend и передовой опыт: часть 2
- Шаблоны проектирования заданий Talend и передовой опыт: часть 1
- Что такое сбор данных об изменениях?
- Испытайте волшебство перетасовки столбцов в динамической схеме Talend
- День из жизни разработчика интеграции данных: как создать свою первую работу Talend
- Преодоление проблем интеграции данных в здравоохранении
- Таленд: Часть 3
- Руководство по Talend для разработчиков Informatica PowerCenter.
 Часть 2
Часть 2 - 5 Методы и стратегии интеграции данных
- Руководство по Talend для разработчиков Informatica PowerCenter. Часть 1 для использования переменных контекста с Talend: Часть 3
- Рекомендации по использованию переменных контекста с Talend: часть 4
- Рекомендации по использованию переменных контекста с Talend: часть 1
Что такое извлечение данных? Инструменты и методы извлечения данных
Если ваш бизнес похож на большинство других, у вас не возникнет проблем со сбором данных. Проблема заключается в том, чтобы использовать эти данные с пользой и получить ценную информацию, которая может помочь в принятии более эффективных решений. Решение этой проблемы требует поиска инструмента интеграции данных, который может управлять и анализировать многие типы данных из постоянно меняющегося набора источников. Но прежде чем эти данные можно будет проанализировать или использовать для получения ценности, их необходимо сначала извлечь.
В этой статье мы расскажем, что такое извлечение данных, рассмотрим взаимосвязь между извлечением данных и приемом данных (с использованием процесса, называемого ETL), а также рассмотрим различные методы и инструменты извлечения данных. Наконец, мы рассмотрим некоторые связанные с API проблемы процесса извлечения данных, а также то, как извлечение данных поддерживает бизнес-аналитику, чтобы получить максимальную отдачу от ваших данных.
Извлечение данных — это процесс получения необработанных данных из источника и репликации этих данных в другом месте. Необработанные данные могут поступать из различных источников, таких как база данных, электронная таблица Excel, платформа SaaS, веб-скрапинг и другие. Затем его можно реплицировать в место назначения, например в хранилище данных, предназначенное для поддержки оперативной аналитической обработки (OLAP). Это могут быть неструктурированные данные, разрозненные типы данных или просто плохо организованные данные. После консолидации, обработки и уточнения данных их можно хранить в центральном месте — на месте, в облачном хранилище или в сочетании того и другого — для ожидания преобразования или дальнейшей обработки.
Предположим, организация хочет следить за своей репутацией на рынке. Для этого может потребоваться множество различных источников данных, включая онлайн-обзоры на веб-страницах, упоминания в социальных сетях и онлайн-транзакции. Инструмент ETL может извлекать данные из этих различных источников и загружать их в хранилище данных, где их можно анализировать и анализировать для понимания восприятия бренда.
Другие примеры, когда извлечение данных может принести пользу бизнесу, включают сбор различных типов данных о клиентах, чтобы получить более четкое представление о клиентах или донорах, финансовых данных, которые помогают компаниям отслеживать производительность и корректировать стратегию, а также данные о производительности, которые могут помочь улучшить процессы или отслеживать задачи.
Оптимизируйте процесс извлечения данных
Зарегистрируйтесь бесплатно → Свяжитесь с отделом продаж →
Извлечение данных — это первый этап двух процессов приема данных, известных как ETL (извлечение, преобразование и загрузка) и ELT (извлечение, загрузка, преобразование). Эти процессы являются частью полной стратегии интеграции данных с целью подготовки данных для анализа или бизнес-аналитики (BI).
Эти процессы являются частью полной стратегии интеграции данных с целью подготовки данных для анализа или бизнес-аналитики (BI).
Поскольку извлечение данных является лишь одним из компонентов общего процесса ETL, стоит более подробно рассмотреть каждый шаг. Полный процесс ETL позволяет организациям собирать данные из разных источников в одном месте.
Извлечение собирает данные из одного или нескольких источников. Процесс извлечения данных включает в себя поиск и идентификацию соответствующих данных, а затем подготовку к преобразованию и загрузке.
Преобразование — это место, где данные сортируются и упорядочиваются. Очистка, например удаление пропущенных значений, также происходит на этом этапе. В зависимости от выбранного места назначения преобразование данных может включать 90 207 типов данных 90 208 , 90 207 структур JSON 90 208 , 90 207 имен объектов и часовых поясов для обеспечения совместимости с местом назначения данных.
Загрузка — это последний шаг, на котором преобразованные данные доставляются в центральный репозиторий для немедленного или будущего анализа.
Независимо от того, является ли источником база данных, платформа SaaS, электронная таблица Excel, веб-скрапинг или что-то еще, процесс извлечения информации включает следующие шаги:
- Проверка изменений в структуре данных, включая добавление новых таблиц и столбцов. Измененные структуры данных должны обрабатываться программно.
- Получить целевые таблицы и поля из записей, указанных схемой репликации интеграции.
- Извлечь соответствующие данные, если таковые имеются.
Извлеченные данные загружаются в место назначения, которое служит платформой для отчетов бизнес-аналитики, например в облачное хранилище данных, такое как Amazon Redshift, Microsoft Azure SQL Data Warehouse, Snowflake или Google BigQuery. Процесс загрузки должен быть специфичным для пункта назначения.
Проблемы, связанные с API
Хотя возможно извлечь данные из базы данных с помощью SQL, процесс извлечения для продуктов SaaS зависит от интерфейса прикладного программирования (API) каждой платформы. Работа с API может быть сложной:
- API разные для каждого приложения.
- Многие API плохо документированы. Даже API от авторитетных, дружелюбных к разработчикам компаний иногда имеют плохую документацию. API
- со временем меняются. Например, подход Facebook «двигайся быстро и ломай вещи» означает, что компания часто обновляет свои API-интерфейсы отчетности, а Facebook не всегда заранее уведомляет пользователей API.
Задания извлечения могут быть запланированы, или аналитики могут извлекать данные по запросу в соответствии с потребностями бизнеса и целями анализа. Существует три основных типа извлечения данных, перечисленных здесь от самых простых до самых сложных:
Уведомление об обновлении
Самый простой способ извлечь данные из исходной системы — заставить эту систему выдавать уведомление, когда запись была изменена. Большинство баз данных предоставляют для этого механизм автоматизации, чтобы они могли поддерживать репликацию базы данных (сбор данных об изменениях или двоичные журналы), а многие приложения SaaS предоставляют веб-перехватчики, которые предлагают концептуально аналогичные функции. Важное замечание по поводу сбора данных об изменениях заключается в том, что он может предоставлять возможность анализа данных в режиме реального или близкого к реальному времени.
Большинство баз данных предоставляют для этого механизм автоматизации, чтобы они могли поддерживать репликацию базы данных (сбор данных об изменениях или двоичные журналы), а многие приложения SaaS предоставляют веб-перехватчики, которые предлагают концептуально аналогичные функции. Важное замечание по поводу сбора данных об изменениях заключается в том, что он может предоставлять возможность анализа данных в режиме реального или близкого к реальному времени.
Некоторые источники данных не могут предоставить уведомление о том, что произошло обновление, но они могут определить, какие записи были изменены, и предоставить выдержку из этих записей. На последующих этапах ETL код извлечения данных должен идентифицировать и распространять изменения. Одним из недостатков метода пошагового извлечения является то, что он может оказаться неспособным обнаружить удаленные записи в исходных данных, потому что невозможно увидеть запись, которой больше нет.
При первой репликации любого источника необходимо выполнить полное извлечение. Некоторые источники данных не имеют возможности идентифицировать данные, которые были изменены, поэтому повторная загрузка всей таблицы может быть единственным способом получить данные из этого источника. Поскольку полное извлечение связано с большими объемами данных, которые могут создать нагрузку на сеть, это не лучший вариант, если вы можете его избежать.
Некоторые источники данных не имеют возможности идентифицировать данные, которые были изменены, поэтому повторная загрузка всей таблицы может быть единственным способом получить данные из этого источника. Поскольку полное извлечение связано с большими объемами данных, которые могут создать нагрузку на сеть, это не лучший вариант, если вы можете его избежать.
Узнайте больше о следующем поколении ETL
Зарегистрируйтесь бесплатно →Связаться с отделом продаж →
Раньше разработчики писали собственные инструменты ETL для извлечения и репликации данных. Это прекрасно работает, когда имеется один или несколько источников данных.
Однако, когда источники многочисленны или сложны, этот подход требует много времени и плохо масштабируется. Чем больше источников, тем выше вероятность того, что что-то потребует обслуживания: как быть с изменением API? Что происходит, когда источник или место назначения изменяет свой формат? Что, если в сценарии есть ошибка, которая остается незамеченной и приводит к принятию решений на основе неверных данных? Не требуется много времени, чтобы простой скрипт превратился в головную боль при обслуживании.
Хорошей новостью является то, что извлечение данных не должно быть болезненной процедурой для вас или для вашей базы данных. Облачные инструменты ETL позволяют пользователям быстро подключать как структурированные, так и неструктурированные источники данных к местам назначения, не создавая и не поддерживая код, а также не беспокоясь о других подводных камнях, которые могут поставить под угрозу извлечение и загрузку данных. В свою очередь, тогда проще предоставить доступ к данным всем, кому они нужны для аналитики, включая руководителей, менеджеров и отдельные бизнес-подразделения.
Чтобы воспользоваться преимуществами программ аналитики и бизнес-аналитики, вы должны понимать контекст ваших источников и назначений данных и использовать правильные инструменты. Для популярных источников данных нет смысла создавать инструмент для извлечения данных.
Инструменты с открытым исходным кодом, такие как Stitch, предлагают простой в использовании инструмент ETL для репликации данных из источников в места назначения.

Об авторе