Взносы вним расшифровка: Что такое ВНиМ \ Акты, образцы, формы, договоры \ КонсультантПлюс
кто и в какой срок должен платить — Контур.Эльба — СКБ Контур
6 февраля 2023 21 302
Организации платят страховые взносы за сотрудников, у ИП есть обязанность платить взносы за себя. В статье расскажем, какие взносы нужно платить и когда.
Содержание
- Страховые взносы ИП
- Взносы за сотрудников
Предприниматели без сотрудников платят страховые взносы за себя на обязательное пенсионное (ОПС) и медицинское страхование (ОМС). Сумма платежа состоит из двух частей: фиксированной и дополнительной:
Фиксированная часть одинакова для всех ИП. В 2022 году их сумма равна 43 211 ₽. Из них 34 445 ₽ приходится на ОПС, а 8 766 ₽ на ОМС.
Дополнительную часть платят предприниматели, у которых доход за год превысил 300 000 ₽. Они перечисляют 1 % с суммы превышения на ОПС.
Разберёмся, как это работает, на примере ИП Васильева, который за год заработал 950 000 ₽. Он заплатит 43 211 ₽ страховых взносов фиксированной части и (950 000 — 300 000) × 1 % = 6 500 ₽ — дополнительной.
Взносы ИП за себя нужно платить даже если ИП работает как сотрудник в организации. Работодатель заплатит взносы с его зарплаты, но они не относятся к бизнесу предпринимателя, поэтому взносы за себя ИП должен заплатить сам.
Крайний срок уплаты фиксированной части — 31 декабря текущего года, а дополнительной — 1 июля следующего. Но выгоднее платить частями каждый квартал, чтобы плавно уменьшать на них налог и не переплачивать.
Кроме обязательных взносов на ОПС и ОМС предприниматели могут добровольно зарегистрироваться в ФСС и заплатить взносы. Это позволит ИП получать пособия по больничному листу и декретные выплаты, но только со следующего года после регистрации.
Год онлайн-бухгалтерии на тарифе Премиум для ИП младше 3 месяцев
Попробовать бесплатно
Организации и предприниматели, которые наняли сотрудников, платят взносы с их зарплаты. За сотрудников по трудовому договору нужно заплатить:
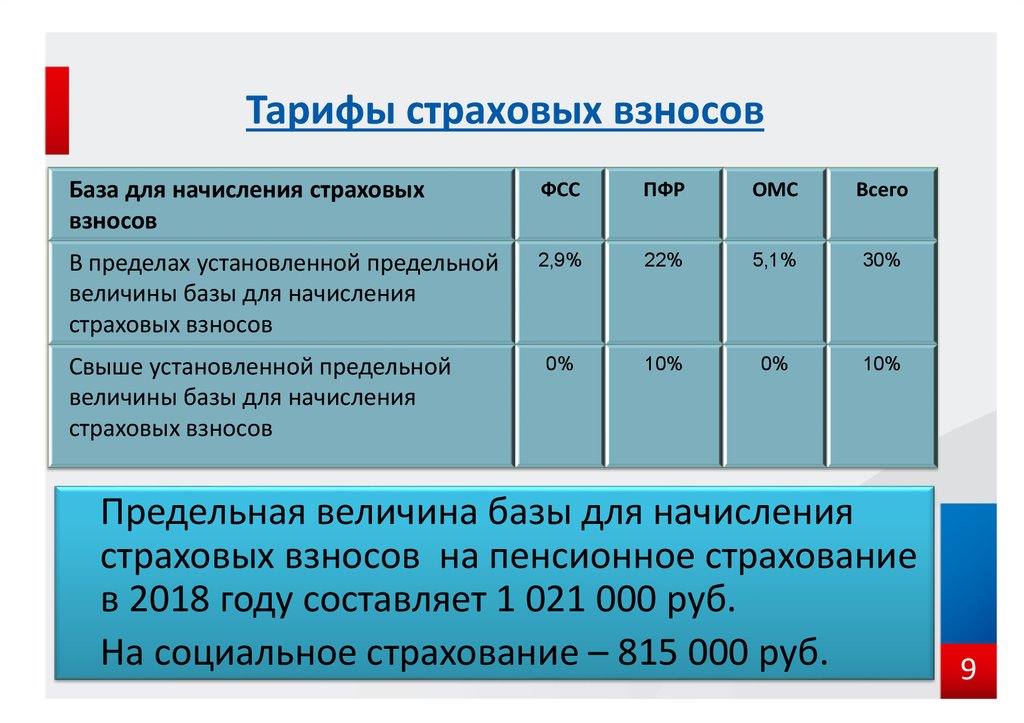
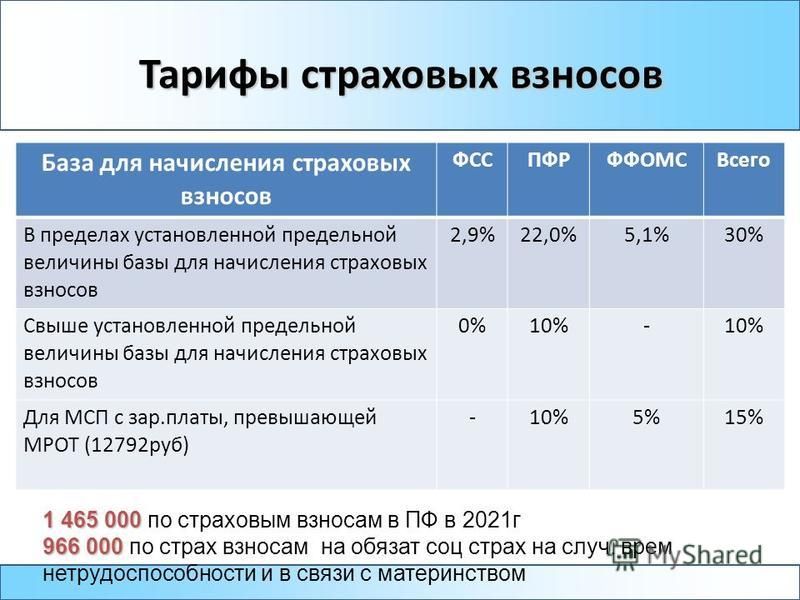
- 22 % на обязательное пенсионное страхование (ОПС) в налоговую;
- 5,1 % на обязательное медицинское страхование (ОМС) в ФФОМС;
- 2,9 % на случай временной нетрудоспособности и в связи с материнством (ВНиМ) в ФСС;
- от 0,2 до 8,5 % на травматизм в ФСС — ставка зависит от степени опасности бизнеса.
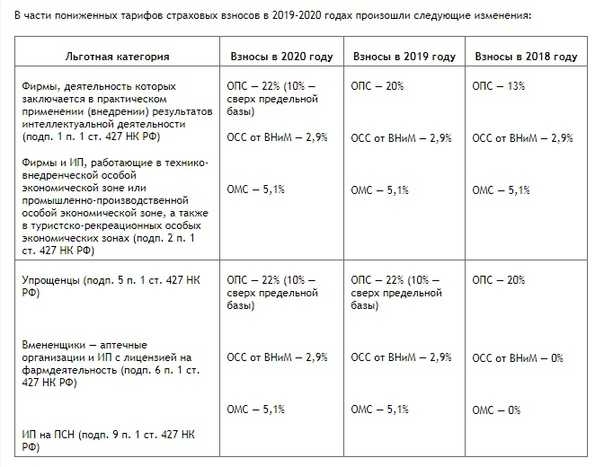
Если сотрудник принят по договору подряда (ГПХ), то до 2023 обязательными будут только взносы на ОПС и ОМС. Взносы на ВНиМ платят те работодатели, которые прописали этот пункт в договоре. А в 2023 году ко взносам за сотрудника на ГПХ добавятся взносы на ВНиМ в обязательном порядке.
Работодатели, бизнес которых принадлежит к малому или среднему, могут применять льготу по страховым взносам и платить меньше. О том, как рассчитать взносы по льготным ставкам, рассказали в статье «Как рассчитать сумму страховых взносов за сотрудников?».
Взносы за сотрудников платят ежемесячно — до 15 числа месяца, следующего за месяцем начисления выплат.
Уютный телеграм-канал, где переводят законы на человеческий язык
Подписаться
Подпишитесь на дайджест налоговых новостей
Подписаться
Подписываясь, вы соглашаетесь на обработку персональных данных и получение информационных сообщений от группы компаний СКБ Контур.
КБК по страховым взносам в ПФР, ФФОМС, ФСС для юридических лиц и ИП в 2023 году — Контур.
 Экстерн
Экстерн| 182 1 02 01000 01 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 01000 01 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Страховые взносы на обязательное пенсионное страхование
Взносы за расчетные периоды, начиная с 1 января 2023 года
| 182 1 02 01010 01 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 01010 01 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Взносы за расчетные периоды, начиная до 1 января 2023 года
| 182 1 02 14010 06 1001 160 | На выплату страховой пенсии за расчетные периоды с 1 января 2017 года по 31 декабря 2022 года |
| 182 1 02 14010 06 1101 160 | На выплату страховой пенсии за расчетные периоды до 1 января 2017 года |
Дополнительные страховые взносы на накопительную пенсию
| 182 1 02 02041 06 1100 160 | Сумма платежа |
Взносы работодателя в пользу лиц, уплачивающих допвзносы на накопительную пенсию
| 182 1 02 02041 06 1200 160 | Сумма платежа |
Сдавайте электронную отчетность через интернет. Экстерн дарит вам 14 дней бесплатно!
Экстерн дарит вам 14 дней бесплатно!
Попробовать бесплатно
Страховые взносы по дополнительному тарифу за застрахованных лиц, занятых на видах работ, указанных в п. 1 ч. 1 ст. 30 федерального закона от 28.12.13 № 400-ФЗ (список 1)
По тарифу, не зависящему от результатов специальной оценки условий труда (класса условий труда)
| 182 1 02 04010 01 1010 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 04010 01 3010 160 | Суммы денежных взысканий (штрафов) по платежу |
По тарифу, зависящему от результатов специальной оценки условий труда (класса условий труда)
| 182 1 02 04010 01 1020 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 04010 01 3020 160 | Суммы денежных взысканий (штрафов) по платежу |
Пени, штрафы и проценты по страховым взносам по доптарифу (список 1), начиная с 1 января 2017 года
| 182 1 02 02131 06 2110 160 | Пени по платежу |
| 182 1 02 02131 06 2210 160 | Проценты по платежу |
| 182 1 02 02131 06 3010 160 | Штрафы по платежу |
Страховые взносы по дополнительному тарифу за застрахованных лиц, занятых на видах работ, указанных в п.
 2 — 18 ч. 1 ст. 30 федерального закона от 28.12.13 № 400-ФЗ (список 2)
2 — 18 ч. 1 ст. 30 федерального закона от 28.12.13 № 400-ФЗ (список 2)По тарифу, не зависящему от результатов специальной оценки условий труда (класса условий труда)
| 182 1 02 04020 01 1010 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 04020 01 3010 160 | Суммы денежных взысканий (штрафов) по платежу |
По тарифу, зависящему от результатов специальной оценки условий труда (класса условий труда)
| 182 1 02 04020 01 1020 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 04020 01 3020 160 | Суммы денежных взысканий (штрафов) по платежу |
| 182 1 02 02000 01 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т. ч. по отмененному) ч. по отмененному) |
| 182 1 02 02000 01 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
на ОПС за расчетные периоды до 01.01.2023
| 182 1 02 14010 06 1005 160 | В фиксированном размере на выплату страховой пенсии за расчетные периоды с 1 января 2017 года по 31 декабря 2022 г. |
| 182 1 02 14010 06 1105 160 | В фиксированном размере на выплату страховой пенсии за расчетные периоды до 1 января 2017 года |
на ОМС за расчетные периоды до 01.01.2023
| 182 1 02 14030 08 1002 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
Сдавайте электронную отчетность через интернет. Экстерн дарит вам 14 дней бесплатно!
Попробовать бесплатно
Страховые взносы по дополнительному социальному обеспечению членов летных экипажей и работников угольной промышленности
Взносы организаций, использующих труд членов летных экипажей воздушных судов гражданской авиации на выплату доплат к пенсии
| 182 1 02 08000 06 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т. ч. по отмененному) ч. по отмененному) |
| 182 1 02 08000 06 2100 160 | Пени по платежу
|
| 182 1 02 08000 06 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Взносы, уплачиваемые организациями угольной промышленности на выплату доплаты к пенсии
| 182 1 02 09000 06 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 09000 06 2100 160 | Пени по платежу |
| 182 1 02 09000 06 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Страховые взносы на обязательное медицинское страхование работающего населения
Взносы за расчетные периоды, начиная с 1 января 2023 года
| 182 1 02 01030 01 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 182 1 02 01030 01 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Взносы за расчетные периоды, истекшие до 1 января 2023 года
| 182 1 02 14030 06 1001 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т. |
| 182 1 02 14030 06 1101 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному за расчетные периоды до 1 января 2017 года) |
Страховые взносы на обязательное социальное страхование на случай временной нетрудоспособности и в связи с материнством
Взносы за расчетные периоды, начиная с 1 января 2023 года
| 182 1 02 01020 01 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по соответствующему платежу, в том числе по отмененному) |
| 182 1 02 01020 01 3000 160 | Суммы денежных взысканий (штрафов) по соответствующему платежу |
Взносы за расчетные периоды, истекшие до 1 января 2023 года
| 182 1 02 14020 06 1001 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т. ч. по отмененному за расчетные периоды с 1 января 2017 года по 31 декабря 2022 года) ч. по отмененному за расчетные периоды с 1 января 2017 года по 31 декабря 2022 года) |
| 182 1 02 14020 06 1101 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному за расчетные периоды до 1 января 2017 года) |
Страховые взносы на обязательное социальное страхование от несчастных случаев на производстве и профессиональных заболеваний
| 797 1 02 12000 06 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т.ч. по отмененному) |
| 797 1 02 12000 06 2100 160 | Пени по соответствующему платежу |
| 797 1 02 12000 06 2200 160 | Проценты по соответствующему платежу |
| 797 1 02 12000 06 3000 160 | Суммы денежных взысканий (штрафов) по платежу |
Сдавайте электронную отчетность через интернет. Экстерн дарит вам 14 дней бесплатно!
Попробовать бесплатно
Страховые взносы, уплачиваемые лицами добровольно вступившими в отношения по обязательному социальному страхованию на случай временной нетрудоспособности и в связи с материнством
| 797 1 02 06000 06 1000 160 | Сумма платежа (перерасчеты, недоимка и задолженность по платежу, в т. |
Как и почему модели-трансформеры преобразили НЛП
Все сообщенияЗиан (Энди) Ван 12 апреля 2023 г. в ИИ и инженерия
Поделиться
В этом сообщении блога
- Остаточный поток
- Многоголовое внимание
- Индукционные головки
- Универсальность моделей на основе трансформеров
Модель Transformer, представленная в статье « Attention is All You Need », повлияла практически на каждую последующую архитектуру или технику языкового моделирования. От новых моделей, таких как BERT , Transformer-XL и RoBERTa , до недавнего ChatGPT , который покорил Интернет как один из самых впечатляющих диалоговых чат-ботов. Понятно, что архитектура на основе трансформеров оставила неоспоримый след в сфере языкового моделирования и машинного обучения в целом. Они настолько сильны, что исследование Buck Shlegeris et al. обнаружили, что языковые модели на основе Transformer превзошли людей [1, см. ссылки ниже] в задачах прогнозирования следующего слова, при этом люди достигли точности 38% по сравнению с точностью 56% GPT-3. В Лекс Фридман 9Интервью подкаста 0023 , ученый-компьютерщик Андрей Капарти заявил, что «Трансформеры захватывают ИИ» и что он оказался «удивительно устойчивым», зайдя еще дальше, назвав его «дифференцируемым компьютером общего назначения».
обнаружили, что языковые модели на основе Transformer превзошли людей [1, см. ссылки ниже] в задачах прогнозирования следующего слова, при этом люди достигли точности 38% по сравнению с точностью 56% GPT-3. В Лекс Фридман 9Интервью подкаста 0023 , ученый-компьютерщик Андрей Капарти заявил, что «Трансформеры захватывают ИИ» и что он оказался «удивительно устойчивым», зайдя еще дальше, назвав его «дифференцируемым компьютером общего назначения».
Трансформеры и их варианты оказались невероятно эффективными в понимании и расшифровке сложной структуры языков. Их исключительная способность к логическому мышлению и пониманию текста вызвала любопытство относительно того, что делает их такими мощными.
В том же подкасте Капарти упомянул, что Transformer «эффективен в прямом проходе, потому что он может выражать […] общие вычисления […] как нечто похожее на передачу сообщений». Это приводит к первому критическому фактору, способствующему успеху Трансформатора, остаточному потоку. [2]
[2]
Остаточный поток
Как правило, большинство людей понимают нейронные сети как последовательные. По сути, каждый слой в сети получает тензор (для тех, кто не знаком, в нашем контексте «тензоры» — это просто обработанные матрицы из предыдущих слоев/входа) в качестве входных данных, обрабатывает его и выводит для использования последующим слоем. Таким образом, выходной тензор каждого слоя служит входом последующего слоя, создавая зависимость между слоями. Вместо этого модели на основе преобразователя работают, извлекая информацию из общего «остаточного потока», разделяемого всеми блоками внимания и MLP.
Модели на основе преобразователя, такие как семейство GPT, содержат сложенные остаточные блоки, состоящие из уровня внимания, за которым следует уровень многослойного персептрона (MLP). Независимо от MLP или головок внимания, каждый уровень считывает из «остаточного потока» и «записывает» в него свои результаты. Остаточный поток представляет собой совокупность выходных данных предыдущих уровней. В частности, каждый уровень считывает из остаточного потока через линейную проекцию и записывает в него через линейную проекцию с последующим добавлением.
В частности, каждый уровень считывает из остаточного потока через линейную проекцию и записывает в него через линейную проекцию с последующим добавлением.
Чтобы получить общее представление о том, как остаточный поток влияет на модели на основе Transformer, представьте себе группу специалистов по данным, работающих над проблемой машинного обучения. Они начинают со сбора и хранения большого набора данных в базе данных. Они делят между собой работу по своей специальности. Первые несколько членов команды, такие как инженеры данных и аналитики данных, выполняют начальную обработку данных. Они могут очистить и организовать его или определить закономерности и тенденции. Затем они передают «предварительно обработанные» данные инженерам по машинному обучению, которые используют их для построения и обучения прогностических моделей. В модели на основе трансформатора мы можем думать о каждом слое как о члене команды, где каждый слой (или серия слоев) имеет свою специализацию, и они могут научиться работать вместе, как настоящая команда, путем обучения.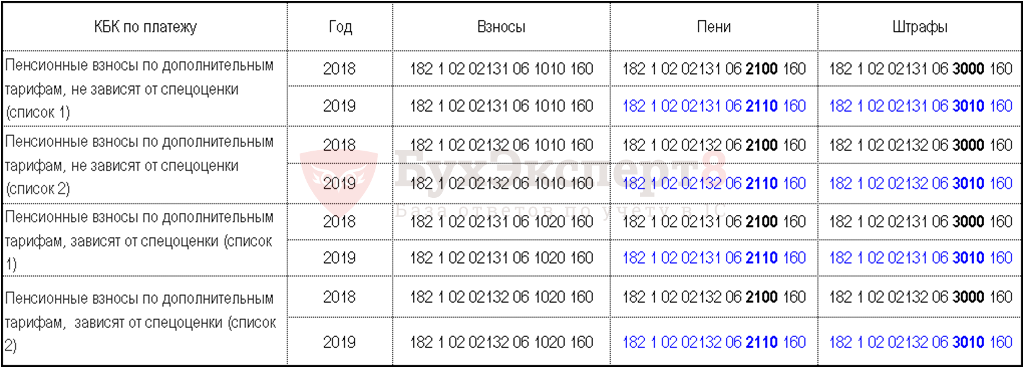 Например, набор блоков внимания может работать вместе, как команда «инженерии данных», отвечающая за перемещение и манипулирование выборками данных и удаление бесполезной информации (и да, на самом деле блоки внимания могут это делать!).
Например, набор блоков внимания может работать вместе, как команда «инженерии данных», отвечающая за перемещение и манипулирование выборками данных и удаление бесполезной информации (и да, на самом деле блоки внимания могут это делать!).
С другой стороны, ряд слоев MLP ближе к концу модели может действовать как крошечные ансамбли нейронных сетей для преобразования обработанного набора данных в значимые выходные данные. Кроме того, подобно тому, как настоящая команда требует сотрудничества для достижения успеха, каждый уровень в модели может взаимодействовать с любым уровнем перед ним! Какое отношение это имеет к остаточному потоку?
Остаточный поток — это основа, которая сшивает слои вместе, позволяя им функционировать подобно ролям и заданиям, описанным выше. Это «база данных», в которой хранится набор данных, и «приложение для обмена сообщениями», которое использует каждый уровень. Это пул совокупных знаний от каждого «члена команды». Любой из этих уровней инженерии данных может извлекать подмножество данных из базы данных, делать с ним какую-то причудливую «разработку функций» и возвращать его обратно в базу данных.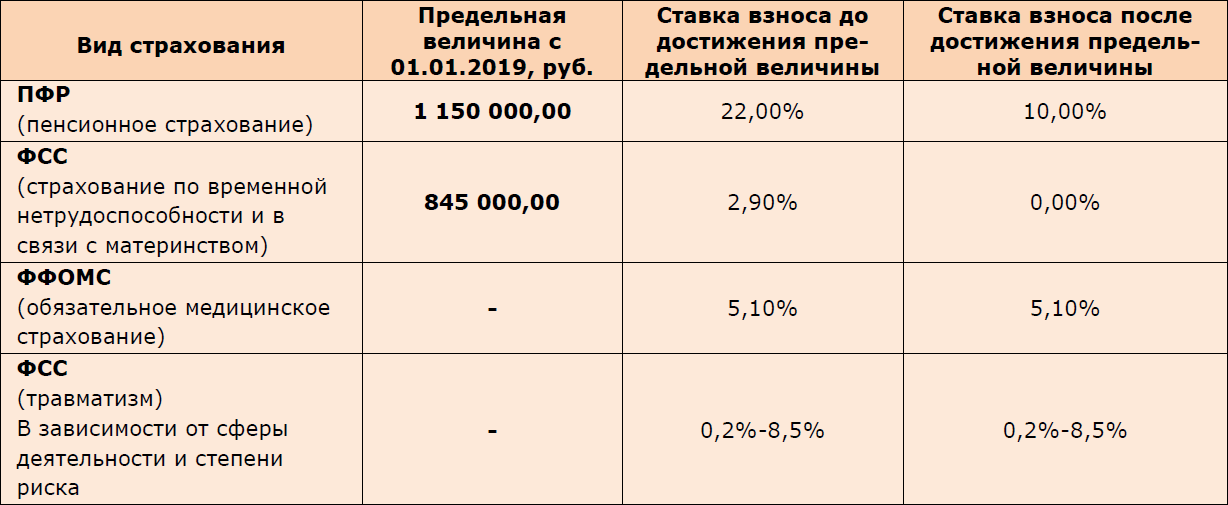 Точно так же любой слой может игнорировать данные, которые не «соответствуют» его специализации.
Точно так же любой слой может игнорировать данные, которые не «соответствуют» его специализации.
Кроме того, каждый уровень может отправлять «данные» любым будущим уровням, и только эти уровни могут получать эти «данные». Это позволяет обрабатывать определенное подмножество информации только слоями с соответствующими функциями. Коммуникация также может принимать форму уровней, «запрашивающих» информацию у набора предыдущих уровней. Наличие остаточного потока представляет собой совершенно другую схему обучения и значительную гибкость, которой не обладают типичные нейронные сети с прямой связью. Без него каждый уровень сети был бы «изолированным» специалистом по данным без особой специальности, поскольку каждый уровень должен иметь дело со всем набором данных. Только представьте, если бы каждый член команды мог разговаривать только с человеком, сидящим рядом с ним!
Одним из важнейших следствий остаточного потока, как видно из приведенного выше сравнения, является то, что модель имеет тенденцию быть более локализованной, и каждый уровень имеет свою собственную свободу выборочно обрабатывать представленную им информацию.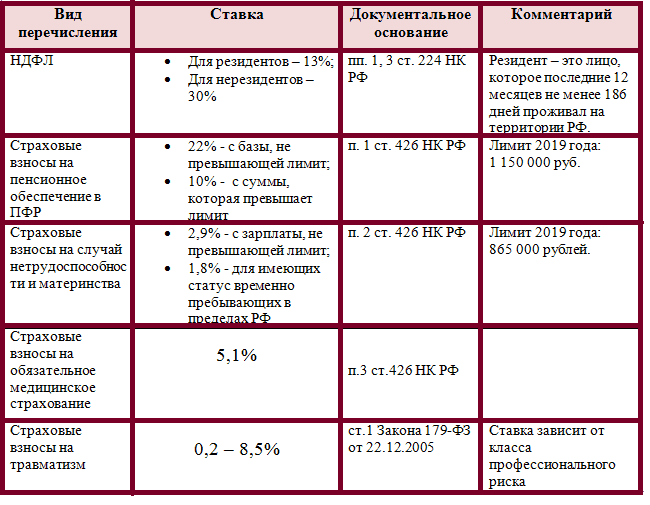 Эмпирически локализация в моделях на основе Transformer наблюдалась задолго до популяризации понятия остаточного потока. Например, в статье Яна Тенни и др. «BERT заново открывает конвейер NLP» [3] упоминается, что «синтаксическая информация более локализована, а веса, связанные с синтаксическими задачами, имеют тенденцию концентрироваться на нескольких слоях» при анализе BERT. модели. Кроме того, в статье AlphaFold2 [4] «Высокоточное предсказание структуры белка с помощью AlphaFold» John Jumper et al. обнаружить, что «для очень сложных белков, таких как ORF8 SARS-CoV-2 (T1064), сеть ищет и перестраивает элементы вторичной структуры для многих слоев, прежде чем остановиться на хорошей структуре».
Эмпирически локализация в моделях на основе Transformer наблюдалась задолго до популяризации понятия остаточного потока. Например, в статье Яна Тенни и др. «BERT заново открывает конвейер NLP» [3] упоминается, что «синтаксическая информация более локализована, а веса, связанные с синтаксическими задачами, имеют тенденцию концентрироваться на нескольких слоях» при анализе BERT. модели. Кроме того, в статье AlphaFold2 [4] «Высокоточное предсказание структуры белка с помощью AlphaFold» John Jumper et al. обнаружить, что «для очень сложных белков, таких как ORF8 SARS-CoV-2 (T1064), сеть ищет и перестраивает элементы вторичной структуры для многих слоев, прежде чем остановиться на хорошей структуре».
Документ AlphaFold2 подразумевает, что модель способна извлекать подмножества того, что уже было проанализировано другими слоями, дополнительно обрабатывать их и добавлять обратно к исходным данным. Затем уровни, расположенные ниже по сети, будут брать то же самое подмножество и продолжать пересматривать и улучшать анализ, выполненный предыдущими уровнями. Помните из приведенного выше сравнения, что прошлые слои могут отправлять информацию будущим слоям, которые не обязательно являются непосредственно соседними. Информация будет прочитана и понята только теми «принимающими слоями». Механизм такого рода «общения» довольно прост.
Помните из приведенного выше сравнения, что прошлые слои могут отправлять информацию будущим слоям, которые не обязательно являются непосредственно соседними. Информация будет прочитана и понята только теми «принимающими слоями». Механизм такого рода «общения» довольно прост.
Остаточный поток обычно представляет собой многомерное векторное пространство, которое во много раз «шире», чем размерность каждого уровня внимания. Здесь термин «ширина» относится к скрытому размеру (равному размеру встраивания) модели, который может достигать сотен, если не тысяч (1024/768 в случае BERT и GPT). Напротив, уровни внимания кодируют информацию из остаточного потока в меньшие размеры (64 в случае BERT и GPT). Когда каждый уровень внимания «записывает» информацию в остаточный поток, они могут записывать в совершенно разные подпространства в остаточном потоке и не взаимодействовать друг с другом. С другой стороны, каждый отдельный уровень внимания может также считывать из определенных подпространств, написанных другими головками внимания, эффективно достигая эффекта «коммуникации».
Интуитивно можно представить, что каждый уровень имеет свой собственный «язык кодирования», который кодирует вывод при записи в остаточный поток. Это приводит к различным типам сигналов в остаточном потоке, которые могут быть интерпретированы только уровнями, обладающими «языком декодирования», который позволяет им читать и понимать информацию от предыдущих уровней, пытающихся взаимодействовать с ними.
Теперь вы можете спросить: «Документ, в котором представлен Transformer, называется «Внимание — это все, что вам нужно», а не «Остаточные соединения — это все, что вам нужно», ResNets существовали задолго до Transformers; как уровни внимания способствуют успеху «Трансформеров»?» Вот тут-то и появляются специализированные головы, остаточный поток может служить «костяком» команды ML, но без интеллектуальных и эффективных «членов команды» Transformers ничем не отличались бы от типичного MLP. Тем не менее, прежде чем говорить о специализированных головках внимания, исследование предлагает другой способ увидеть функциональность слоев внимания с несколькими головками, чем обычное понимание.
Внимание с несколькими головками
В оригинальной статье Transformer «Внимание — это все, что вам нужно» [5] внимание с несколькими головками описывалось как операция конкатенации между каждой головкой внимания. Примечательно, что выходная матрица каждой головки внимания имеет вид конкатенированы по вертикали, а затем умножены на матрицу весов размера (скрытый размер, количество головок внимания). Однако обратите внимание, что матрица весов может быть «разложена» на векторы-столбцы, по одному для каждой головы внимания. Если мы проделаем алгебру, мы Обратите внимание, что внимание с несколькими головками — это просто аддитивный процесс, в котором выходные данные каждой головки внимания умножаются на ее собственную «матрицу результатов» и суммируются вместе!0007
Подведение итогов показывает, что каждая головка внимания работает совершенно независимо. Это означает, что каждая головка внимания не должна обеспечивать одинаковую функциональность, а каждая головка в каждом слое внимания может делать совершенно разные вещи. Первоначальное объяснение многоголового внимания в статье «Внимание — это все, что вам нужно» предлагает несколько размытую интерпретацию того, является ли каждая головка внимания функционально независимой. Конкатенация может быть более эффективной с вычислительной точки зрения, чем умножение, но определение суммирования более тесно согласуется с эмпирическими данными и выводами.
Первоначальное объяснение многоголового внимания в статье «Внимание — это все, что вам нужно» предлагает несколько размытую интерпретацию того, является ли каждая головка внимания функционально независимой. Конкатенация может быть более эффективной с вычислительной точки зрения, чем умножение, но определение суммирования более тесно согласуется с эмпирическими данными и выводами.
Высокая выразительность и сложность понимания, которыми обладают модели на основе Transformer, проистекают из того факта, что каждый запрос, ключ и матрица значений из каждой головки внимания могут «общаться» через остаточный поток. Таким образом, головы внимания могут «работать вместе» для выполнения более сложных операций, чем просто анализ наивного представления токенов. Например, одна голова внимания может заменить фразы с расплывчатым значением их предполагаемыми токенами, найденными ранее в тексте. Затем из этих «замененных» фраз может быть составлена матрица запросов будущей головы внимания, что поможет лучше вычислить матрицу внимания. Помните, что эти изменения видны только тем слоям, которые в них «нуждаются», в то время как другие слои могут по-прежнему получать доступ к исходным, неизмененным данным, если это необходимо, благодаря большой «полосе пропускания» остаточного потока.
Помните, что эти изменения видны только тем слоям, которые в них «нуждаются», в то время как другие слои могут по-прежнему получать доступ к исходным, неизмененным данным, если это необходимо, благодаря большой «полосе пропускания» остаточного потока.
Индукционные головки
Вы когда-нибудь задумывались, как ChatGPT запоминает все, что вы говорите, с невероятной точностью? Что ж, ответ заключается в формировании этих специализированных головок внимания в моделях на основе трансформаторов, называемых индукционными головками. [6] В частности, эти заголовки являются причиной явления, называемого « обучение в контексте », когда потери модели уменьшаются по мере того, как больше токенов она предсказывает (вот почему ChatGPT может запоминать так далеко в ваших разговорах). Аналогично индуктивным рассуждениям, индуктивные головы заключают, что если за фразой/словом [A] следует [B] ранее в тексте, в следующий раз, когда мы встретим [A], за ним, вероятно, последует и [B]. Более того, индукционные головки более эффективны, чем просто распознавание и повторение шаблона. В больших языковых моделях головы индукции понимают более абстрактные представления, где они могут обобщить шаблон [A] -> [B] на фразы, которые не точно соответствуют [A], но представляют аналогичную идею во встраивании слова. Чтобы увидеть это довольно сложное «сопоставление с образцом», см. 9.0023 здесь для живой демонстрации.
Более того, индукционные головки более эффективны, чем просто распознавание и повторение шаблона. В больших языковых моделях головы индукции понимают более абстрактные представления, где они могут обобщить шаблон [A] -> [B] на фразы, которые не точно соответствуют [A], но представляют аналогичную идею во встраивании слова. Чтобы увидеть это довольно сложное «сопоставление с образцом», см. 9.0023 здесь для живой демонстрации.
Возьмем в качестве примера предложение «Кошка прыгнула со скалы». Индукционные головы помнят, что «кот» обычно ассоциируется с «прыгнувшим со скалы». В следующий раз, когда она встретит фразу «кот», значения внимания этих токенов будут указывать на предыдущее появление «спрыгнул с обрыва», тем самым увеличивая вероятность того, что модель выдаст «спрыгнул с обрыва». В более общем смысле индукционные головки ищут предыдущие вхождения текущего токена и копируют то, что следует за ним, в соответствии с текущим контекстом.
Однако, если мы «заглянем под капот», функциональность индукционных головок на самом деле представляет собой сотрудничество между несколькими головками внимания, охватывающими сеть. Голова внимания ранее в сети говорила ключевой матрице индукционных головок извлекать токены на одну позицию назад (помните, такого рода связь может быть достигнута через остаточный поток). Затем, когда индукционная головка вычисляет показатели внимания, матрица запроса будет искать аналогичные токены в ключевой матрице, на которые нужно обратить внимание. Но поскольку представление токена в ключевой матрице сдвинуто на одну позицию назад, вычисляемая матрица внимания фактически обращает внимание на позиции, следующие за фактической позицией слова, предоставленного ключевой матрицей. По сути, это создает эффект того, что модель обращает повышенное внимание на фразу «кошка» на фразу «спрыгнул со скалы», поскольку в ключевой матрице то, что должно быть «спрыгнул со скалы», заменяется на «кот» и его токены.
Голова внимания ранее в сети говорила ключевой матрице индукционных головок извлекать токены на одну позицию назад (помните, такого рода связь может быть достигнута через остаточный поток). Затем, когда индукционная головка вычисляет показатели внимания, матрица запроса будет искать аналогичные токены в ключевой матрице, на которые нужно обратить внимание. Но поскольку представление токена в ключевой матрице сдвинуто на одну позицию назад, вычисляемая матрица внимания фактически обращает внимание на позиции, следующие за фактической позицией слова, предоставленного ключевой матрицей. По сути, это создает эффект того, что модель обращает повышенное внимание на фразу «кошка» на фразу «спрыгнул со скалы», поскольку в ключевой матрице то, что должно быть «спрыгнул со скалы», заменяется на «кот» и его токены.
Помните, что приведенное выше объяснение является довольно интуитивной, не технической интерпретацией индукционных головок. Чтобы увидеть, как работает математика, обратитесь к здесь . Интересно, что не все индукционные головки в моделях на базе Transformer полагаются на головки внимания ранее в сети, копируя представление предыдущих токенов в ключевую матрицу индукционных головок. Головки внимания в некоторых сетях, таких как GPT-2, были наблюдаемыми для извлечения позиционного встраивания похожих токенов и «сообщения» индукционным головкам вращать эти позиционные вложения вперед, получая токены, следующие за текущим.
Интересно, что не все индукционные головки в моделях на базе Transformer полагаются на головки внимания ранее в сети, копируя представление предыдущих токенов в ключевую матрицу индукционных головок. Головки внимания в некоторых сетях, таких как GPT-2, были наблюдаемыми для извлечения позиционного встраивания похожих токенов и «сообщения» индукционным головкам вращать эти позиционные вложения вперед, получая токены, следующие за текущим.
Характеристика сопоставления с образцом индукционных головок может быть обобщена до запоминания определенного типа фразы, почти всегда соседствующей с каким-либо другим типом. Одним очевидным следствием или работой, которую выполняет индукционная головка, является обнаружение грамматических правил, например, как наречие всегда обращается к глаголу или как прилагательное всегда описывает существительное. В более широком масштабе индукционные головы могут поддерживать последовательный стиль письма и предоставлять контекстную информацию для токенов, расположенных позже в тексте.
Универсальность моделей на основе трансформатора
Конечно, индукционные головки и остаточный поток — не только единственные факторы, которые повлияли на исключительную производительность моделей на основе трансформатора, и даже не близко, но они, безусловно, играют огромную роль в «интеллект» Трансформеров. Особенно с современными большими языковыми моделями (LLM), содержащими сотни головок внимания, каждая из которых может служить отдельной цели в понимании входного текста почти на человеческом уровне, если не выше. Исследователи далеки от полной интерпретации LLM. Но одна повторяющаяся тема, наблюдаемая во всех попытках разбить модели на основе Transformer, — это важность остаточного потока и специализации каждого компонента, который он приносит.
В конце концов, остаточный поток открывает перед моделями возможность думать и учиться, как люди. Мы не черные ящики, которые складывают все, что мы знаем, в один поток операций: у нас есть возможность разбить проблему, проанализировать ее с разных точек зрения и синтезировать знания из разных областей, чтобы прийти к решению. Модели на основе трансформеров могут ссылаться на инструменты и стратегии, которые могут использовать люди; их архитектурный дизайн — это не просто огромный шаг в НЛП, а скорее революционная концепция машинного обучения. Было доказано, что модели на основе трансформеров выдержали испытание временем не только в области НЛП. Скорее, они являются одной из самых универсальных архитектур, активно используемых при обработке изображений [7, 8, 9].], табличных данных [10, 11] и даже в рекомендательных системах [12], обучении с подкреплением [13] и генеративном обучении [14. 15]. Трансформеры — это не просто дизайн модели, это еще один шаг к тому, чтобы позволить системам ИИ думать как люди.
Модели на основе трансформеров могут ссылаться на инструменты и стратегии, которые могут использовать люди; их архитектурный дизайн — это не просто огромный шаг в НЛП, а скорее революционная концепция машинного обучения. Было доказано, что модели на основе трансформеров выдержали испытание временем не только в области НЛП. Скорее, они являются одной из самых универсальных архитектур, активно используемых при обработке изображений [7, 8, 9].], табличных данных [10, 11] и даже в рекомендательных системах [12], обучении с подкреплением [13] и генеративном обучении [14. 15]. Трансформеры — это не просто дизайн модели, это еще один шаг к тому, чтобы позволить системам ИИ думать как люди.
Ссылки
Shlegeris et al (2022). Языковые модели лучше, чем люди, предсказывают следующий токен. https://arxiv.org/abs/2212.11281
Elhage, et al (2021). Математическая основа для трансформаторных цепей. Резьба цепей трансформатора.
Тенни И., Дас Д.
 и Павлик Э. (2019). BERT заново открывает классический конвейер НЛП. Ежегодное собрание Ассоциации компьютерной лингвистики.
и Павлик Э. (2019). BERT заново открывает классический конвейер НЛП. Ежегодное собрание Ассоциации компьютерной лингвистики.Джампер Дж.М., Эванс Р., Притцель А., Грин Т., Фигурнов М., Роннебергер О., Тунясувунакоол К., Бейтс Р., Зидек А., Потапенко А., Бриджланд А., Мейер К., Коль С.А., Баллард А., Коуи А., Ромера-Паредес Б., Николов С., Джейн Р., Адлер Дж., Бэк , Т., Петерсен С., Рейман Д.А., Клэнси Э., Зелински М., Штайнеггер М., Пачольска М., Бергхаммер Т., Боденштейн С., Сильвер Д., Виньялс, О., Старший, А.В., Кавуккуоглу, К., Кохли, П., и Хассабис, Д. (2021). Высокоточное предсказание структуры белка с помощью AlphaFold. Природа, 596, 583 — 589.
Васвани, А., Шазир, Н.М., Пармар, Н., Ушкорейт, Дж., Джонс, Л., Гомес, А.Н., Кайзер, Л., и Полосухин, И. (2017 ). Внимание — это все, что вам нужно. https://arxiv.org/abs/1706.03762.
Olsson, et al. (2022). Обучение в контексте и вводные заголовки. Резьба цепей трансформатора.
Досовицкий А.
 , Бейер Л., Колесников А., Вайссенборн Д., Чжай X., Унтертинер Т., Дегани М., Миндерер М., Хейгольд Г., Гелли , С., Ушкорейт, Дж., и Хоулсби, Н. (2020). Изображение стоит 16×16 слов: трансформеры для распознавания изображений в масштабе. https://arxiv.org/abs/2010.11929.
, Бейер Л., Колесников А., Вайссенборн Д., Чжай X., Унтертинер Т., Дегани М., Миндерер М., Хейгольд Г., Гелли , С., Ушкорейт, Дж., и Хоулсби, Н. (2020). Изображение стоит 16×16 слов: трансформеры для распознавания изображений в масштабе. https://arxiv.org/abs/2010.11929.Карион, Н., Масса, Ф., Синнаев, Г., Усюньер, Н., Кириллов, А., и Загоруйко, С. (2020). Сквозное обнаружение объектов с помощью трансформаторов. https://arxiv.org/abs/2005.12872.
Ян Ф., Ян Х., Фу Дж., Лу Х. и Го Б. (2020). Изучение сети преобразования текстур для изображений сверхвысокого разрешения. Конференция IEEE/CVF 2020 г. по компьютерному зрению и распознаванию образов (CVPR), 5790-5799.
Хуанг Х., Хетан А., Цвиткович М. и Карнин З.С. (2020). TabTransformer: моделирование табличных данных с использованием контекстных вложений. https://arxiv.org/abs/2012.06678.
Somepalli, G., Goldblum, M., Schwarzschild, A., Bruss, CB, & Goldstein, T. (2021).
 SAINT: улучшенные нейронные сети для табличных данных с помощью внимания к строке и контрастного предварительного обучения. https://arxiv.org/abs/2106.01342.
SAINT: улучшенные нейронные сети для табличных данных с помощью внимания к строке и контрастного предварительного обучения. https://arxiv.org/abs/2106.01342.Похан, Х.И., Варнарс, Х.Л., Соуито, Б., и Гаол, Ф.Л. (2022). Рекомендательная система с использованием модели трансформатора: систематический обзор литературы. 2022 г. 1-я Международная конференция по информационным системам и информационным технологиям (ICISIT), 376–381.
Чен Л., Лу К., Раджесваран А., Ли К., Гровер А., Ласкин М., Аббил П., Шринивас А. и Мордатч И. ( 2021). Преобразователь решений: обучение с подкреплением посредством моделирования последовательности. https://arxiv.org/abs/2106.01345.
Цзян Ю., Чанг С. и Ван З. (2021). TransGAN: два чистых трансформатора могут составить одну мощную GAN, которая может масштабироваться. Нейронные системы обработки информации.
Хадсон, Д.А., и Зитник, К.Л. (2021). Генеративно-состязательные трансформеры. https://arxiv.
 org/abs/2103.01209
org/abs/2103.01209
Если у вас есть какие-либо отзывы об этом посте или о чем-то еще, связанном с Deepgram, мы будем рады услышать от вас. Пожалуйста, сообщите нам об этом в обсуждениях на GitHub. .
Еще с этими тегами:
Поделитесь своим мнением
Была ли эта статья полезной или интересной для вас?
Не заполняйте это поле, если вы человек. Не заполняйте это поле, если вы человек.Спасибо! Можете ли вы рассказать нам, что вам понравилось в нем? (Необязательно)
Спасибо. Что мы могли сделать лучше? (Необязательно)
Мы также можем обращаться к вам с обновлениями или вопросами, связанными с вашими отзывами и нашим продуктом. Если не возражаете, вы можете при желании оставить свой адрес электронной почты вместе с ваши комментарии.
Ваше сообщение*
Ваш адрес электронной почты
Не заполняйте это поле, если вы человек.
Спасибо!
Благодарим Вас за ответ.
Связанные ресурсы
LLMs 101: все, что вам нужно знать о больших языках…
- Хосе Николас Франциско
Представляем приложения Deepgram Starter
- Люк Олифф
Привлечение внимания: расшифровка успеха трансформатора…
- Зиан (Энди) Ван
Как состязательные примеры создают устойчивое машинное обучение…
- Брэд Никкель
Президент Square Enix подтверждает акцент на блокчейн-играх и тренде «Play-to-Contribute» технологии.
«Я вижу 2021 год не только как «Метавселенная: год первый», но и как «НФТ: год первый», учитывая, что это был год, когда НФТ были встречены с большим энтузиазмом быстро растущей пользовательской базой, — сказал Мацуда в новогоднем письме.
Президент также приписал большую часть импульса метавселенной «сложной технологии блокчейна», прежде чем повторить изменение стратегии Square Enix для соответствия этой новой среде.
«Чтобы учесть эти изменения в нашей бизнес-среде, среднесрочная бизнес-стратегия, которую мы представили в мае 2020 года, определила ИИ, облачные технологии и игры с блокчейнами как новые области, на которых мы должны сосредоточить наши инвестиции», — сказал он, добавив, что Square Enix вела «агрессивные» исследования и разработки в этих областях.
Это объявление не в первый раз, когда Square Enix фокусируется на связи между блокчейном и играми.
В ноябре прошлого года игровая компания впервые заявила о своем намерении исследовать пространство NFT, предлагая потребителям коллекционные предметы и видеоигры с блокчейном. В марте 2020 года японский разработчик также инвестировал в песочницу на базе Ethereum.
Будущее игр?
По словам Мацуды, между традиционными играми и играми с блокчейном существует фундаментальный контраст.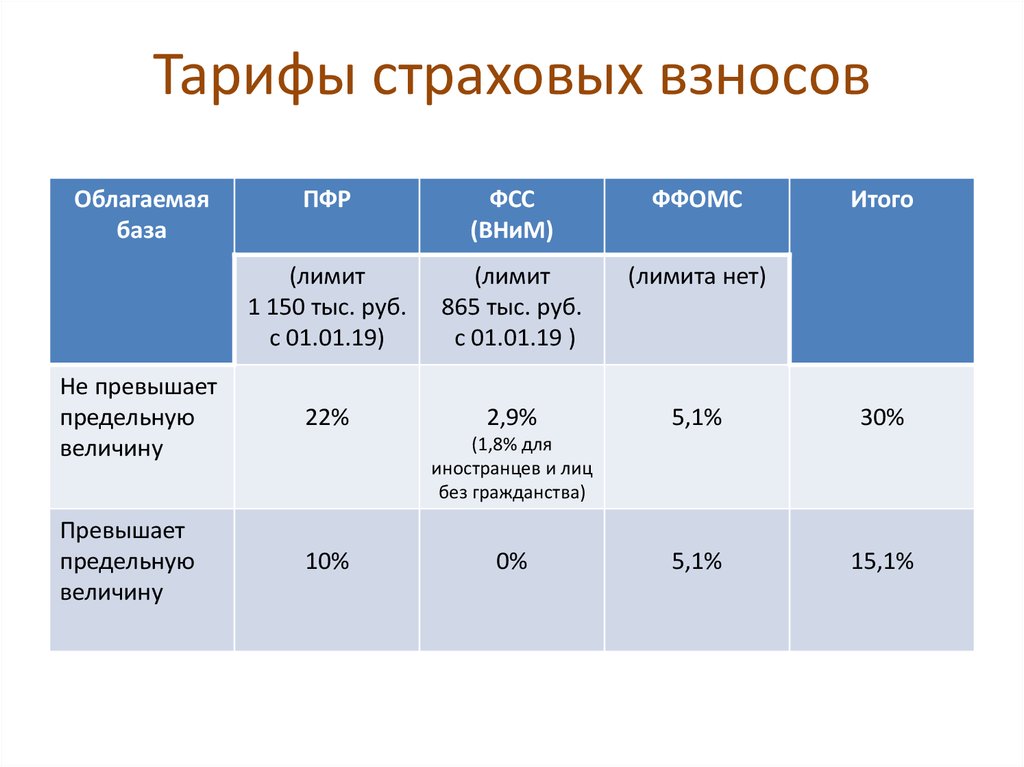
«Игры традиционно представляют собой однонаправленный поток, когда такие создатели, как мы, предоставляют игру потребителям, которые в них играют», — сказал он.
«Напротив, игры с блокчейном, которые вышли из зачаточного состояния и в данный момент вступают в фазу роста, построены на предпосылке экономики токенов и, следовательно, обладают потенциалом для обеспечения самоподдерживающегося роста игр», — он добавлен.
Мацуда также признал наличие напряженности между игроками или людьми, которые, по словам Мацуды, «играют, чтобы развлечься», и теми, кто «играет, чтобы внести свой вклад».
Эти демографические данные относятся к людям, которые играют, чтобы «сделать игру более захватывающей», сказал он.
«Традиционные игры не предлагали явного стимула для этой последней группы людей, которые руководствовались исключительно такими противоречивыми личными чувствами, как доброжелательность и добровольческий дух», — добавил он.
Это, однако, может измениться в 2022 году, по крайней мере, если Мацуда что-то скажет по этому поводу.

Об авторе