Яндекс роботс тхт: Директива Clean-param — Вебмастер. Справка
Директива Clean-param — Вебмастер. Справка
- Обучающее видео
- Как использовать директиву Clean-param
- Синтаксис директивы
- Дополнительные примеры
- Disallow и Clean-param
Примечание. Иногда для закрытия таких страниц используется директива Disallow. Рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели.
Как использовать директиву Clean-param. Посмотреть видео |
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Clean-param: ref /some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123
Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex Clean-param: utm
Совет. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла. Если вы указываете другие директивы именно для робота Яндекса, перечислите все предназначенные для него правила в одной секции. При этом строка
Clean-param: p0[&p1&p2&..&pn] [path]
В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots. txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
#для адресов вида: www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Clean-param: s /forum/showthread.php
#для адресов вида: www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae #robots.txt будет содержать: User-agent: Yandex Clean-param: sid /index.php
#если таких параметров несколько: www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311 www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896 #robots.txt будет содержать: User-agent: Yandex Clean-param: s&ref /forum*/showthread.php
#если параметр используется в нескольких скриптах: www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.example1.com/forum/index.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Clean-param: s /forum/index.php Clean-param: s /forum/showthread.php
Директива Clean-param не требует обязательного сочетания с директивой Disallow.
User-agent: Yandex Disallow: Clean-param: s&ref /forum*/showthread.php #идентично: User-agent: Yandex Clean-param: s&ref /forum*/showthread.php
Так как директива Clean-param межсекционная, ее можно указывать в любом месте файла, вне зависимости от расположения директив Disallow и Allow. Исполнение Disallow при этом имеет приоритет и, если адрес страницы запрещен к индексированию в Disallow и одновременно ограничен в Clean-param, страница проиндексирована не будет.
User-agent: Yandex Disallow:/forum Clean-param: s&ref /forum*/showthread.php
В этом случае страница https://example.com/forum?ref=page будет считаться запрещенной. Не указывайте директиву Disallow для страниц, если хотите только удалить из поиска варианты ссылок с GET-параметрами.
Справочник по ошибкам анализа robots.txt
- Ошибки
- Предупреждения
- Ошибки проверки URL
Перечень ошибок, возникающих при анализе файла robots. txt.
txt.
| Ошибка | Расширение Яндекса | Описание |
|---|---|---|
| Правило начинается не с символа / и не с символа * | Да | Правило может начинаться только с символа / или *. |
| Найдено несколько правил вида User-agent: * | Нет | Допускается только одно правило такого типа. |
| Превышен допустимый размер robots.txt | Да | Количество правил в файле превышает 2048. |
| Перед правилом нет директивы User-agent. | Нет | Правило должно всегда следовать за директивой User-agent. |
| Слишком длинное правило | Да | Правило превышает допустимую длину (1024 символа). |
| Некорректный формат URL файла Sitemap | Да | В качестве URL файла Sitemap должен быть указан полный адрес, включая протокол. Например, https://www.example.com/sitemap.xml |
| Некорректный формат директивы Clean-param | Да | В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом. |
 Возможно, файл содержит пустую строку после User-agent.
Возможно, файл содержит пустую строку после User-agent.Перечень предупреждений, возникающих при анализе файла robots. txt.
txt.
| Предупреждение | Расширение Яндекса | Описание |
|---|---|---|
| Возможно, был использован недопустимый символ | Да | Обнаружен спецсимвол, отличный от * и $. |
| Обнаружена неизвестная директива | Да | Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем. |
| Синтаксическая ошибка | Да | Строка не может быть интерпретирована как директива robots.txt. |
| Неизвестная ошибка | Да | При анализе файла возникла неизвестная ошибка. |
 Обратитесь в службу поддержки.
Обратитесь в службу поддержки.Перечень ошибок проверки URL в инструменте Анализ robots.txt.
| Ошибка | Описание |
|---|---|
| Синтаксическая ошибка | Ошибка синтаксиса URL. |
| Этот URL не принадлежит вашему домену | Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена. |
Robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL-адрес
- Как отслеживать изменения файла
- FAQ
Инструмент анализа Robots.txt поможет вам проверить, сканирует ли robots. txt файл правильный. Вы можете ввести содержимое файла, проверить его, а затем скопировать в robots.txt.
txt файл правильный. Вы можете ввести содержимое файла, проверить его, а затем скопировать в robots.txt.
Этот инструмент также поможет вам отслеживать изменения в файле и загружать его конкретную версию.
- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL
- Как отслеживать изменения в файле
- FAQ
- Если сайт был добавлен в Яндекс.Вебмастер и были права на управление сайтом Verified
Содержимое файла появится на странице анализа Инструменты → Robots.txt, как только будут подтверждены права на управление сайтом.
Если содержимое отображается на странице анализа Robots.txt, щелкните Проверить.
- Если сайт не добавлен в Яндекс.Вебмастер
Перейти на страницу анализа robots.txt.
В поле Проверяемый сайт введите адрес вашего сайта. Например, https://example.com.
Щелкните значок.
 Содержимое файла robots.txt и результаты анализа будут показаны ниже.
Содержимое файла robots.txt и результаты анализа будут показаны ниже.
В разделах, предназначенных для робота Яндекса (User-agent: Яндекс или User-agent: *), валидатор проверяет директивы, используя условия использования robots.txt. Остальные разделы проверяются на соответствие стандарту.
После проверки вы можете увидеть:
Предупреждения. Они сообщают об отклонении от правил, которое может быть исправлено самим инструментом. Предупреждения также указывают на потенциальную проблему с опечатками или неточностями в директивах.
Ошибки в файле. Это означает, что инструмент не может обработать строку, раздел или весь файл из-за серьезных синтаксических ошибок в директивах.
Дополнительные сведения см. в разделе Ошибки синтаксического анализа файла robots.txt.
При загрузке файла robots.txt в Яндекс.Вебмастер на странице анализа Robots.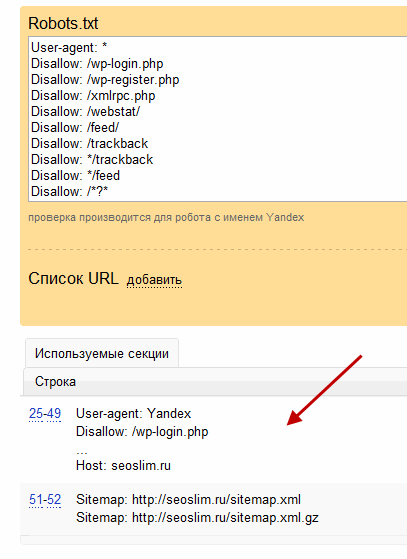 txt отображается блок Проверить, разрешены ли ссылки.
txt отображается блок Проверить, разрешены ли ссылки.
В поле списка URL введите адрес страницы, которую хотите проверить. Вы можете указать URL полностью или относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите Проверить.
Если URL-адрес разрешен для индексации ботами Яндекса, рядом с ним появится значок . В противном случае адрес будет выделен красным цветом.
Примечание. Доступна полугодовая история изменений. Максимальное количество сохраняемых версий — 100.
Чтобы оперативно узнавать об изменениях в файле robots.txt, настройте уведомления.
Яндекс.Вебмастер регулярно проверяет файл на наличие обновлений и сохраняет версии вместе с датой и временем изменения. Чтобы просмотреть их, перейдите в Инструменты → Анализ Robots.txt.
Список версий отображается при соблюдении всех следующих условий:
Вы добавили сайт в Яндекс.
 Вебмастер и подтвердили право на управление сайтом.
Вебмастер и подтвердили право на управление сайтом.Яндекс.Вебмастер хранит информацию об изменениях в robots.txt.
Вы можете:
- Просмотреть текущую и предыдущую версии файла
В списке версий robots.txt выберите версию файла. Поле ниже показывает файл robots.txt вместе с результатами синтаксического анализа.
- Скачать версию выбранного файла
В списке версий robots.txt выберите версию файла.
Нажмите кнопку «Загрузить». Файл будет сохранен на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, вы включили зеркало в список URL вашего сайта. Например, http://example.com вместо http://www.example.com (технически это два разных URL-адреса). Технически это два разных URL. URL-адреса в списке должны принадлежать сайту, для которого проверяется файл robots. txt.
txt.
Укажите инструмент, в котором вы обнаружили ошибку, максимально подробно опишите ситуацию и, если необходимо, прикрепите скриншот, иллюстрирующий ее.
Заблокировать сканер Яндекса — Webmasters Stack Exchange
Задавать вопрос
спросил
Изменено 6 лет, 1 месяц назад
Просмотрено 1к раз
Последние несколько дней наш сайт ведет себя очень странно, много тайм-аутов и т.д. Наконец-то я нашел причину, бот Яндекса сканирует около 10000 страниц в час! Мне нужно остановить это как можно скорее, я думаю, что это создает около 50-100 ГБ пропускной способности в день.
Заблокированные IP-адреса (через https://myip.ms/info/bots/Google_Bing_Yahoo_Facebook_etc_Bot_IP_Addresses. html):
html):
100.43.90.0/24, 37.9.115.0/24, 37.140.165.0/24, 77.88.22.0/25, 77.88.29.0/24, 77.88.31.0/24, 77.88.59.0/24, 84.201.204,148,0 .148.0/24, 84.201.149.0/24, 87.250.243.0/24, 87.250.253.0/24, 93.158.147.0/24, 93.158.148.0/24, 93.158.151.0/24, 90.158.319,153.0 /24, 95.108.138.0/24, 95.108.150.0/23, 95.108.158.0/24, 95.108.156.0/24, 95.108.188.128/25, 95.108.234.0/24, 95.108.048.2.4/03, 18.0.0/24, , 130.193.62.0/24, 141.8.153.0/24, 178.154.165.0/24, 178.154.166.128/25, 178.154.173.29, 178.154.200.158, 178.154.202.0/24, 178.154.205.0/24, 178.154.239.0/24, 178.154.243.0/24, 37.9.84.253, 199.21.99.99, 178.154.162.29, 178.154.203.251, 178.154.211.250, 95.108 .246.252, 5.45.254.0/24, 5.255.253.0/24, 37.140.141.0/24, 37.140.188.0/24, 100.43.81.0/24, 100.43.85.0/24, 100.43.92.0/.22, 199.199.0.
Мой robots.txt:
User-agent: Яндекс Запретить: / Пользовательский агент: * Запретить: ... и т. д.
Но, как сообщает Cloudflare, он все еще ползает.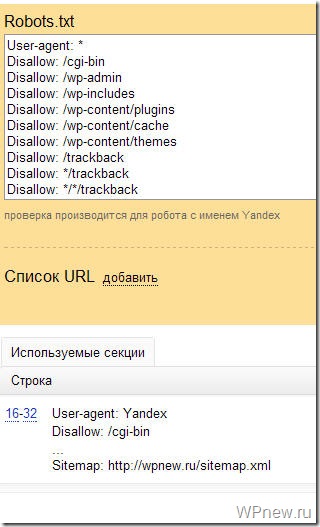
Что еще я могу сделать, чтобы остановить это?
- web-crawlers
- yandex
Прямо с сайта Яндекса
User-Agent Mozilla/5.0 (совместимый; Яндекс...) строка идентифицирует роботов Яндекса. Роботы может отправлять запросы GET (например, ЯндексБот/3.0) и HEAD (ЯндексВебмастер/2.0) к сервер. Обратный просмотр DNS можно использовать для проверки подлинности роботов Яндекса. Более информацию можно найти в разделе Как проверить принадлежность робота Яндексу помощь веб-мастера. Если у вас есть какие-либо вопросы о наших роботах, пожалуйста, свяжитесь с нашей службой поддержки: [email protected]. Если у вас возникли технические проблемы с нашими роботами рекомендуем прикрепить лог вашего сервера.
Вы можете написать их команде по электронной почте и попросить не сканировать ваш сервер и не блокировать правильный пользовательский агент. Если ваш сервер перегружен и не справляется с запросами робота на загрузку, вам следует использовать директиву Crawl-delay.

Об авторе